LentiAvatar
LentiAvatar: Pseudo-Multiview Reconstruction and Subpixel Prism Rendering for Real-Time Stereoscopic Communication
LentiAvatar reconstructs monocular head avatars optimized for glasses-free stereoscopic displays using pseudo-multiview supervision from natural head turns. It encodes multiple virtual views for real-time autostereoscopic telepresence without specialized capture rigs.
Links
Paper & demos
Impact
Abstract
Real-time stereoscopic video communication has long been a goal of immersive telepresence, yet practical systems still require specialized capture rigs or reduce remote users to a single portrait view. We present LentiAvatar, a Gaussian head-avatar system that connects monocular avatar capture with subpixel-encoded glasses-free lenticular display for real-time autostereoscopic communication. From a monocular portrait video, LentiAvatar reconstructs a controllable head avatar and optimizes it for the lateral viewing zones induced by the display. The method uses natural head turns as pseudo-multiview (PMV) supervision to constrain regions that are otherwise weakly observed in monocular training, including hair, ears, jaw contours, and neck boundaries. Reliable side frames are yaw-binned, aligned to virtual cameras, and supervised within a strict head-and-hair domain; contour-aware losses and staged regularization further suppress ghosting, alpha leakage, and depth instability while preserving lateral detail. At runtime, LentiAvatar renders 32 virtual views and encodes them into a 4K lenticular raster with calibrated subpixel-routing masks. The live-tracker prototype sustains 10.65 FPS, and a subject-specific distilled driver raises the same display pipeline to 38.49 FPS.
Introduction
LentiAvatar addresses a specific but important gap in real-time telepresence: how to reconstruct a monocular head avatar that is good enough not just for a frontal portrait renderer, but for a glasses-free stereoscopic display that exposes multiple laterally separated views at once. The paper’s central claim is that standard monocular avatar training underconstrains the side of the head. Hair silhouette, ears, jaw contour, and the rear-neck boundary are only weakly observed from a frontal camera, yet those are exactly the regions that become visible in lateral viewing zones on an autostereoscopic panel. If the avatar is not trained to behave well from those viewpoints, the display pipeline turns small geometric or alpha errors into ghosting, depth shimmer, and color fringing.
The proposed system, LentiAvatar, combines a Gaussian head avatar with pseudo-multiview supervision derived from natural head turns. Instead of treating turned frames as ordinary monocular training examples, the method selects side-looking frames, bins them by yaw, aligns them to virtual cameras, restricts supervision to a strict above-neck region, and uses contour-aware losses to reduce opacity leakage and boundary instability. The same trained avatar is then rendered from multiple virtual viewpoints and encoded into a 4K lenticular raster using calibrated subpixel-routing masks.
The paper positions itself at the intersection of monocular avatar reconstruction, real-time Gaussian rendering, and autostereoscopic display rendering. The key novelty is not the Gaussian primitive representation itself, but the coupling of reconstruction to the physical display: the avatar is trained to support the lateral viewing zones induced by the lenticular panel rather than only to match a single input camera.
The authors report two runtime configurations. A live tracker-driven prototype runs at 10.65 FPS end-to-end for the 4K, 32-view display pipeline. A subject-specific distilled driver raises the same display pipeline to 38.49 FPS, showing that the main bottleneck is control estimation rather than view rendering or subpixel composition.
Contributions reported by the paper:
- A reconstruction-to-display pipeline for glasses-free stereoscopic communication that renders 32 virtual views into a calibrated 4K autostereoscopic raster.
- Pseudo-multiview supervision that converts natural monocular head rotations into yaw-matched side observations.
- A reliability-aware side-view objective with strict head-and-hair masking, side-frame ranking, alignment gates, contour preservation, and shell/collar cleanup.
Problem Setting and Core Idea
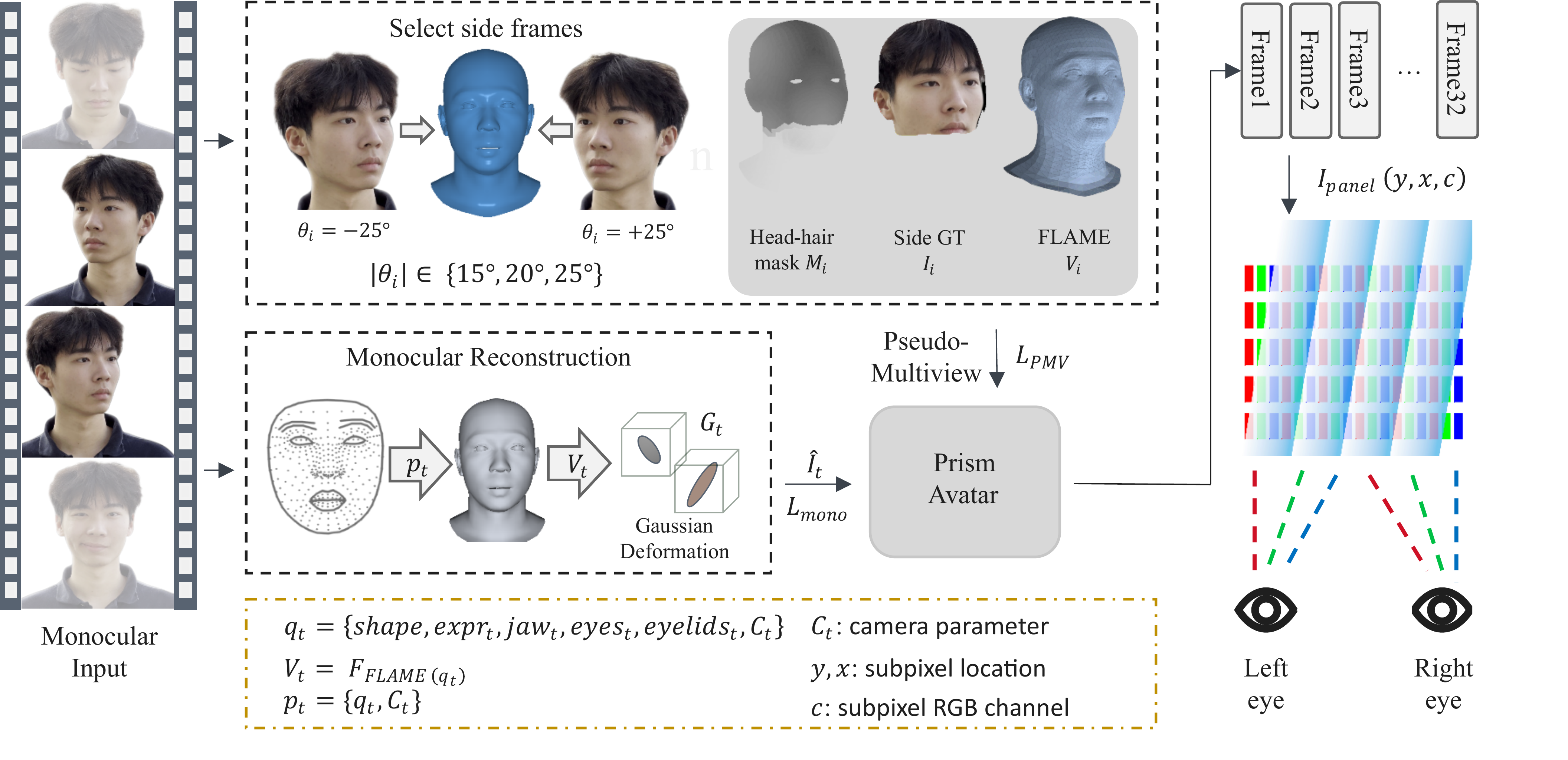
The input to training is a monocular portrait sequence $\{I_t, A_t, \mathbf{z}_t, y_t\}_{t=1}^{T}$, where $I_t$ is the RGB frame, $A_t$ is the foreground matte, $\mathbf{z}_t$ contains tracked expression and pose controls, and $y_t$ is the estimated camera-relative yaw. The paper assumes that the monocular camera is calibrated through the base avatar pipeline and that the display panel provides calibrated routing constants. The method has two coupled goals: reconstruct a side-stable avatar from monocular video and encode the rendered views into a subpixel raster suitable for glasses-free 3D presentation.
The key geometric assumption is conservative: in carefully selected side frames, the head and hair approximately co-rotate with the tracked yaw, but the lower neck, collar, and background do not. That is why the paper refuses to supervise all pixels of a turned frame. Instead, it converts only reliable lateral evidence into pseudo-multiview supervision, while explicitly masking out the ambiguous lower regions that would otherwise teach the model to hallucinate skin-colored collars or rear-neck opacity shells.
Method
The system uses an explicit Gaussian avatar representation. Each primitive stores a position $\boldsymbol{\mu}_j$, covariance $\boldsymbol{\Sigma}_j$, opacity $o_j$, and color features $\mathbf{c}_j$. The covariance is parameterized as
$$\boldsymbol{\Sigma}_j = R_j S_j S_j^{\top} R_j^{\top},$$
which ensures positive semidefinite anisotropic support. The canonical avatar is deformed by the tracked control code and rendered from a requested virtual-view yaw $\theta$ using a standard front-to-back alpha-compositing Gaussian renderer. In the notation of the paper, the rendered image and alpha map are obtained from a deformed avatar $\mathcal{G}_{t,\theta}$ and its camera $\Pi_{\theta}$.
1. Gaussian head avatar representation
The authors explicitly state that the primitive representation is not their main contribution. They build on 3D Gaussian Splatting and recent Gaussian head-avatar systems for real-time rendering. Their contribution is the way side-view supervision is selected and used, plus the way the resulting views are routed to the panel.
2. Yaw-binned side-frame selection
LentiAvatar does not use every turned frame. It only accepts frames whose yaw falls into a narrow range around a small set of display-relevant bins. The lateral bins are $15^\circ$, $20^\circ$, and $25^\circ$. For each frame, the method computes the nearest bin and accepts the frame only if $14^\circ \leq |y_t| \leq 27^\circ$ and $| |y_t| - b_t | \leq 2.5^\circ$. The supervised virtual-view yaw is then set to $\hat{y}_t = \operatorname{sign}(y_t)b_t$, while the pose context is rewritten so that the frame acts as a side observation rather than as an ordinary monocular training view.
This design matters because the paper treats side views as a one-to-one supervision signal for the display’s lateral zones. The display is not asking for arbitrary novel views; it is asking for a fixed set of views that line up with the panel optics. Yaw binning makes the training signal match the display geometry.
3. Side-frame ranking and reliability gating
Yaw alone is not enough. A large side turn can still contain motion blur, expression changes, poor matte boundaries, or collar contamination. The paper therefore scores each yaw-valid candidate using a weighted sum of positive terms minus risk terms:
$$q_t = \sum_m w_m Q_m(t) - \sum_n \lambda_n R_n(t).$$
The positive terms reward yaw agreement, temporal and expression stability, matte cleanliness, and visible lateral face or hair support. The risk terms penalize unstable boundaries and collar contamination. Only high-scoring frames are retained, and the resulting pseudo-multiview set is balanced across left and right side views.
After yaw selection, the method aligns the real side frame to the virtual camera using a bounded local search over camera parameters, followed by a small image-space warp. The alignment gate is intentionally strict:
$$g_t^{\mathrm{align}} = \mathbf{1}[\operatorname{IoU} \geq 0.32] \mathbf{1}[\operatorname{IoU}_e \geq 0.12] \mathbf{1}[d_\mu \leq 28\text{ px}].$$
Failed matches are downweighted rather than trusted as full supervision.
4. Strict head-and-hair supervision domain
One of the most important design choices is the strict target matte. The paper rasterizes semantic support for the positive side-head region and a risk region for the neck and jaw-neck boundary, then forms a support mask
$$P_t(u) = \mathbf{1}[S_t(u) > \tau_s]\,\mathbf{1}[R_t(u) < \tau_r].$$
The actual PMV matte is then built from the aligned target alpha, a 25-pixel dilation, and a bottom gate derived from the projected support boundary:
$$M_t^{\mathrm{hh}}(u) = A_t^{*}(u) \odot \mathcal{D}_{25}(P_t)(u) \odot B_t(u).$$
This is the main mechanism that prevents collar, lower-neck, and background pixels from supervising the side-view avatar. The paper emphasizes that this strict domain is the key difference from naive pseudo-multiview training.
5. Reliability-gated PMV objective
The training objective is scheduled and staged. The total loss is
$$\mathcal{L}(k) = \mathcal{L}_{\mathrm{base}} + \gamma(k)\mathcal{L}_{\mathrm{pmv}},$$
with
$$\mathcal{L}_{\mathrm{pmv}} = \lambda_I \mathcal{L}_I + \lambda_{\alpha} \mathcal{L}_{\alpha} + \lambda_{\mathrm{bg}} \mathcal{L}_{\mathrm{bg}} + \lambda_{\mathrm{mesh}} \mathcal{L}_{\mathrm{mesh}} + \lambda_e \mathcal{L}_e + \lambda_s \mathcal{L}_s.$$
The base loss includes photometric, SSIM, foreground-alpha, background-alpha, and regularization terms. The PMV terms are specialized as follows:
- $\mathcal{L}_I$ and $\mathcal{L}_{\alpha}$ supervise safe RGB and head-domain alpha pixels.
- $\mathcal{L}_{\mathrm{bg}}$ and $\mathcal{L}_{\mathrm{mesh}}$ suppress opacity outside the target support and dilated FLAME mesh.
- $\mathcal{L}_e$ preserves alpha gradients at ears, hair, and jaw boundaries.
- $\mathcal{L}_s$ penalizes semi-transparent smear through the response $4\hat{\alpha}(1-\hat{\alpha})$.
The paper gives concrete weights for reproducibility. The base weights for L1, SSIM, foreground alpha, and background alpha are $(1.0, 0.08, 0.05, 0.35)$. The PMV weights for side learning are $(0.016, 0.012, 0.025, 0.012, 0.035, 0.004)$, and for color fine-tuning they are $(0.016, 0.004, 0.012, 0.006, 0.026, 0.010)$. PMV begins at iteration 320, ramps linearly for 700 iterations, and is capped at $\gamma(k) \leq 0.65$. Later no-PMV stages disable the PMV loss entirely.
6. Staged stabilization
The final training recipe is four stages:
- PMV side learning with auto-alignment, strict head-and-hair masking, shell cleanup, and contour preservation.
- PMV color fine-tuning with milder alpha and background weights.
- No-PMV low-weight monocular color correction with blend features and the weight module frozen.
- A short no-PMV cleanup stage with base and blend color features frozen.
The authors describe this as a way to let lateral evidence shape the avatar first, then remove residual leakage without globally pruning valid face, hair, ear, or jaw detail.
7. Runtime driving and subject-specific distillation
The live prototype uses a metrical tracker to estimate the driving controls, but the paper also includes a subject-specific distilled driver. The student is a MobileNetV3-Small backbone with a two-layer MLP head that predicts the normalized 129-D control vector from a cropped $224 \times 224$ portrait frame. The distillation loss is a group-weighted smooth-$L_1$ objective over expression, neck, jaw, eye, eyelid, and translation groups. At inference time, the predicted control vector is denormalized using subject statistics and sent through the same Gaussian deformation module as the tracker output. This module does not alter the avatar renderer or the display compositor; it only reduces control-estimation latency.
8. Subpixel prism encoding for the lenticular panel
The display-side contribution is a calibrated subpixel routing model. Instead of conventional full-pixel image compositing, the method treats rasterization as a subpixel view-assignment problem. Let $E \in [0,1]^{H \times W \times 3}$ be the encoded panel raster and $V_i \in [0,1]^{H_v \times W_v \times 3}$ the rendered image for view $i$. The panel constants include the raster slant coefficient $C_r$, routing period $\Delta_r$, reference offset $s_{\mathrm{ref}}$, and reference view index $i_{\mathrm{ref}}$.
For each view, the row-dependent offset is
$$s_i = s_{ {ref}} - \frac{\Delta_r}{N}(i - i_{\mathrm{ref}}).$$
For row $y$ and integer period index $m$, the candidate subpixel coordinate is
$$b_i(y,m) = 3C_r y + s_i + m\Delta_r.$$
A view contributes to a subpixel when its coordinate matches the routed position under the calibrated lenticular geometry. This defines a binary mask $M_i(p)$, and the encoded raster is
$$E(p) = \sum_{i=1}^{N} M_i(p)\,V_i(u_p).$$
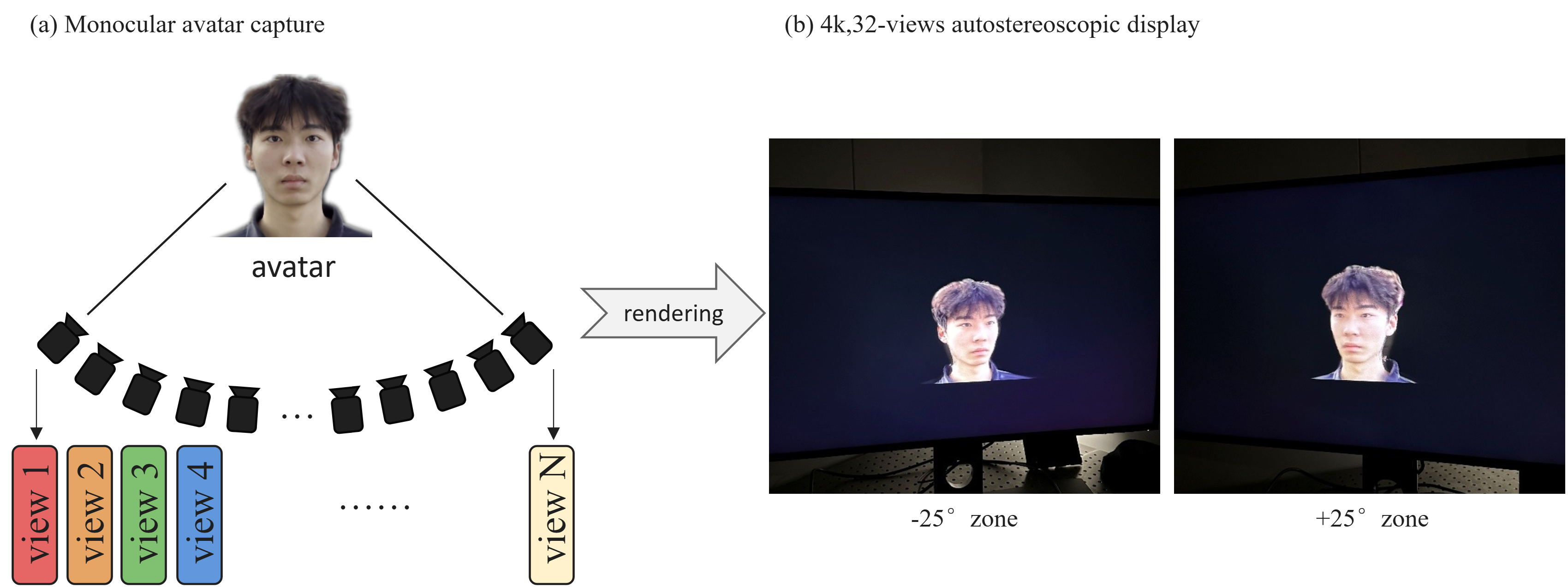
In runtime, the system renders $N=32$ virtual views at $960 \times 540$, uniformly sampled over the angular range $[-25^\circ, +25^\circ]$, and composes them into a $3840 \times 2160$ panel raster. The calibrated masks are precomputed into sparse GPU tables with primary and secondary view selectors; configurations with more than two active views at a subpixel are rejected.
Experiments
The experiments test two claims: first, that PMV reconstruction improves side-view robustness for monocular avatars; and second, that the reconstructed avatar can be routed to a 4K glasses-free display at interactive rates. The paper evaluates qualitative behavior on public INSTA benchmark sequences with stable horizontal head turns and uses Marcel for quantitative diagnostics at $-25^\circ$ and $+25^\circ$ from frame 0 under a common aligned crop and a 9-pixel FLAME-mask dilation.
Qualitative comparison on public benchmark sequences
The comparison baseline set is RGBAvatar, HRAvatar, FlashAvatar, and INSTA. The paper emphasizes that the displayed probe is not the frontal portrait but the lateral rendering at $-25^\circ$, because that is where the display-coupled failure modes become visible. The side-view comparisons show that frontal fidelity alone is not enough: some methods preserve plausible reference-view appearance while producing floating opacity, weak side contours, or neck and collar contamination when rendered laterally.

Evaluation metrics
Because standard image metrics do not isolate display-specific side-view artifacts, the paper introduces six lower-is-better diagnostics. They measure outside-support alpha, neck-rear ghosting mass and density, translucency smear, and color-fringe heat. The evaluation is designed to detect exactly the artifacts that are amplified by the lenticular display’s multi-view routing. A separate contour metric, side-contour edge energy $E_c$, is used in the ablation study, where higher is better.
| Method | $O_{\alpha}$ | $G_{\mathrm{m}}$ | $G_{\mathrm{d}}$ | $S_{\mathrm{n}}$ | $S_{\alpha}$ | $F_{\mathrm{c}}$ |
|---|---|---|---|---|---|---|
| LentiAvatar | 0.0691 | 0.0237 | 0.0297 | 0.0304 | 0.0149 | 0.2145 |
| RGBAvatar | 0.0768 | 0.0303 | 0.0384 | 0.0357 | 0.0182 | 0.2117 |
| HRAvatar | 0.0889 | 0.0314 | 0.0397 | 0.0177 | 0.0085 | 0.2017 |
| FlashAvatar | 0.0746 | 0.0368 | 0.0435 | 0.0851 | 0.0901 | 0.1685 |
| INSTA | 0.0779 | 0.0227 | 0.0280 | 0.0330 | 0.0270 | 0.2315 |
On Marcel, LentiAvatar obtains the lowest outside-support alpha $O_{\alpha}$ among the compared methods, with a value of 0.0691. It is also competitive on the two neck-rear ghost measures and on translucency smear. INSTA is slightly better on neck-rear ghost mass and density, while HRAvatar or FlashAvatar are lower on some selected translucency or color-fringe scores. The paper’s interpretation is that these are display-specific trade-offs: LentiAvatar prioritizes suppressing off-surface side opacity while retaining sufficient lateral structure for the 32-view routing pipeline. That is the behavior that matters when one conversational frame is expanded into many routed views on the panel.
Component ablation of PMV reconstruction
The paper presents a progressive ablation that isolates the contribution of each reconstruction component: no PMV, naive PMV, strict head-and-hair matte supervision, side-frame ranking and yaw-bin selection, alignment refinement, and the final staged model. The results show that naive side supervision improves some contour energy but also increases leakage and color-fringe heat, demonstrating that side views alone are not sufficient. Strict masking and alignment are needed to turn raw side turns into reliable supervision.
| Variant | $O_{\alpha}$ | $G_{\mathrm{m}}$ | $G_{\mathrm{d}}$ | $S_{\mathrm{n}}$ | $S_{\alpha}$ | $F_{\mathrm{c}}$ | $E_{\mathrm{c}}$ |
|---|---|---|---|---|---|---|---|
| No PMV | 0.0625 | 0.0170 | 0.0223 | 0.0276 | 0.0187 | 0.2412 | 0.1201 |
| Naive PMV | 0.0649 | 0.0167 | 0.0215 | 0.0255 | 0.0239 | 0.2474 | 0.1234 |
| + HH matte | 0.0631 | 0.0161 | 0.0204 | 0.0364 | 0.0409 | 0.2403 | 0.1242 |
| + Rank/bin | 0.0646 | 0.0172 | 0.0225 | 0.0263 | 0.0202 | 0.2477 | 0.1233 |
| + Align | 0.0630 | 0.0186 | 0.0242 | 0.0269 | 0.0195 | 0.2374 | 0.1233 |
| LentiAvatar | 0.0607 | 0.0164 | 0.0214 | 0.0291 | 0.0181 | 0.2300 | 0.1268 |
The final staged model gives the best overall balance. Relative to the no-PMV baseline, the paper reports reductions of 2.9% in outside-support alpha, 3.1% in alpha translucency smear, and 4.6% in color-fringe heat, while increasing side-contour energy by 5.6%. The interpretation is that the early PMV stages recover missing side structure, and the later stabilization stages preserve that structure while removing residual opacity and chromatic boundary artifacts.
Autostereoscopic display profiling
The runtime profile is measured on an RTX 4090 after initialization. The system renders 32 views at $960 \times 540$ and composes them into a $3840 \times 2160$ lenticular raster. The paper compares the live tracker with the subject-specific student driver while holding the trained avatar, view set, renderer, and subpixel compositor fixed.
| Runtime component or metric | Live tracker | Student driver |
|---|---|---|
| End-to-end FPS | 10.65 | 38.49 |
| Tracking stage (ms) | 109.15 | 4.68 |
| Render 32 views (ms) | 18.59 | 16.09 |
| Subpixel composition (ms) | 1.67 | 1.67 |
| Display presentation (ms) | 1.23 | 0.79 |
| Total loop (ms) | 109.15 | 26.15 |
The runtime results show that subpixel routing is not the bottleneck. Composing the 4K raster takes only 1.67 ms, and rendering all 32 views stays below 19 ms in both settings. The dominant cost is control estimation: the live tracker’s 109.15 ms stage limits the end-to-end system to 10.65 FPS. Replacing it with the distilled subject-specific driver reduces that stage to 4.68 ms and raises the same display pipeline to 38.49 FPS. The paper’s conclusion from this profiling is that future system work should focus on reducing or generalizing the driving stage rather than on the display compositor.
Limitations and Future Work
The method depends on informative horizontal head turns in the monocular training video. If side frames are sparse, misaligned, blurred, or affected by hair motion or poor mattes, the PMV signal weakens. The strict above-neck domain also excludes lower-neck and clothing reconstruction, so the system is intentionally head-only and does not attempt full-body stereoscopic communication.
The paper also notes that side-view quality remains below synchronized multi-view capture, especially for challenging hair, ears, and rear-neck regions. On the runtime side, the live metrical tracker dominates frame time, even though the view rendering and subpixel composition are relatively efficient. The distilled driver improves throughput but is subject-specific and requires a separate distillation stage. The paper suggests future work on reducing tracking and multiview rendering latency, improving the perceived realism on the glasses-free panel, jointly tuning virtual-camera baselines with panel routing, and extending the approach beyond heads.
Conclusion
LentiAvatar presents a monocular Gaussian head-avatar system designed specifically for subpixel-routed glasses-free stereoscopic communication. Its core idea is to transform natural head turns into strict above-neck pseudo-multiview supervision so that the avatar learns the lateral content that a lenticular panel will actually expose. This reduces off-surface alpha leakage and side-view instability while preserving the detail needed for identity and depth continuity. At runtime, the trained avatar is rendered into 32 views and encoded into a 4K autostereoscopic raster, and a subject-specific distilled driver can push the same pipeline above 30 FPS.