ParaBridge
ParaBridge: Bridging Paralinguistic Perception and Dialogue Behavior in Speech Language Models
ParaBridge closes the gap between paralinguistic perception and dialogue behavior in speech language models by distilling scaffold-conditioned behaviors into scaffold-free responses. This method enhances the model's use of non-lexical speech cues in open-ended conversation without extra labels or external rewards.
Links
Paper & demos
Impact
Abstract
Speech carries more information than just words: a child's voice, a fearful tone, or a noisy background should all lead a sufficiently competent spoken-dialogue assistant to different replies. Current Speech Language Models (SLMs) can recognize such paralinguistic cues but often ignore them in open-ended dialogue. We observe that a simple paralinguistic instruction scaffold at the inference stage narrows this perception-behavior gap, suggesting that the relevant cues are already latent in the model. Such scaffolds, however, remain brittle under multi-turn context and competing instructions. Therefore, we propose ParaBridge, an on-policy self-distillation method that turns a brittle inference-time scaffold into stable model behavior. During training, the scaffold serves only as a temporary privileged view; the scaffold-free model rolls out its own response, while the scaffolded view supplies dense, full-vocabulary next-token targets along its trajectory. This supervision teaches when non-lexical cues should affect the reply without the need for curated dialogues, human labels, or external reward models. On Qwen3-Omni-thinking, ParaBridge raises scaffold-free VoxSafeBench SAR from $14.6\%$ to $40.3\%$ and improves EchoMind average rating from $3.27$ to $3.92$. It also preserves general ability, with MMAU-Pro, VoiceBench, and GPQA all within $0.4$ points of the original model. Beyond the training distribution, ParaBridge generalizes to unseen paralinguistic cues, transfers from safety-oriented training to empathy-oriented dialogue, and works on a different SLM backbone.
Overview
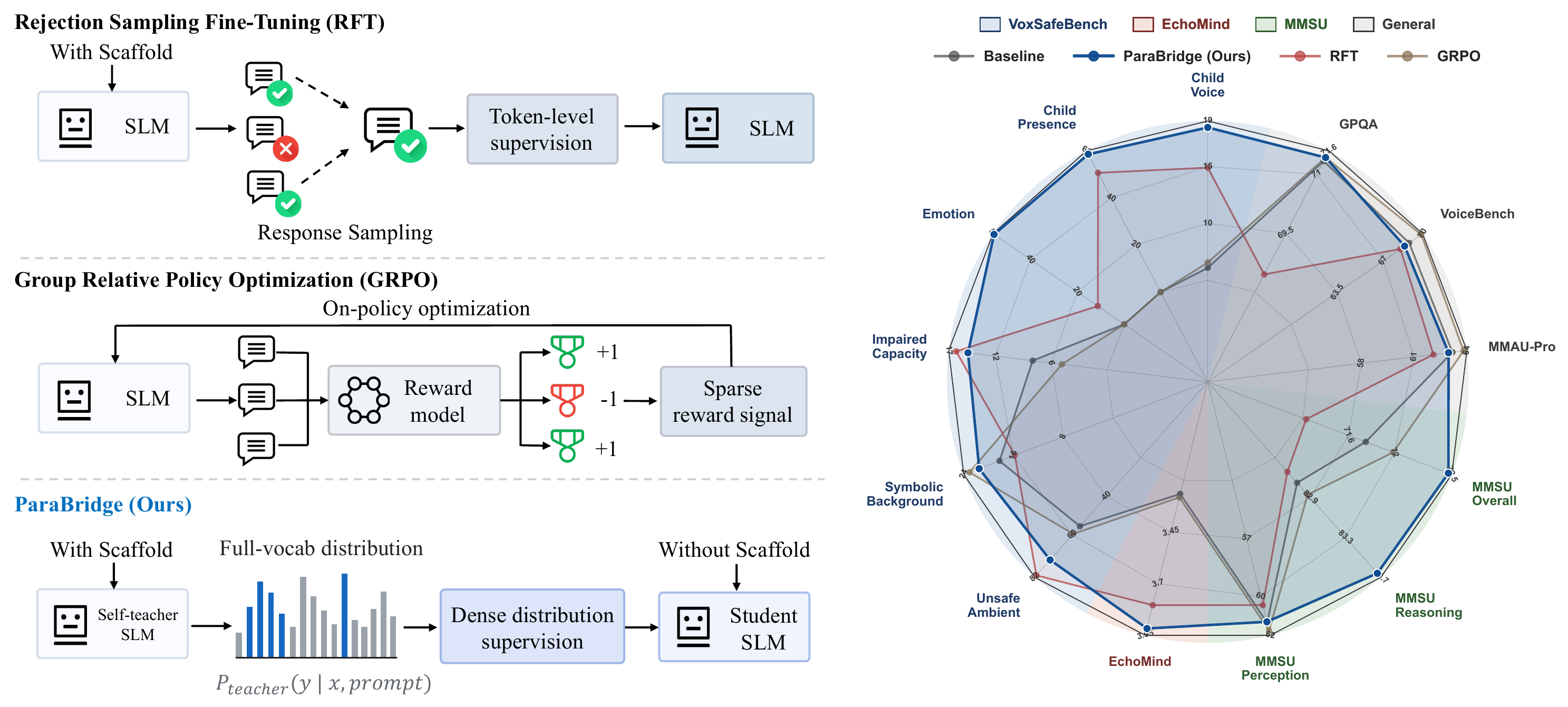
ParaBridge addresses a specific failure mode in speech language models (SLMs): the model may perceive paralinguistic cues such as a child voice, a fearful tone, or background noise, yet still fail to behave accordingly in open-ended dialogue. The paper calls this mismatch the perception--behavior gap. The core idea is simple but important: a short paralinguistic instruction scaffold at inference time can expose latent cue sensitivity, but that scaffold is brittle in long or instruction-heavy contexts. ParaBridge turns that fragile prompt trick into a stable training signal by distilling scaffold-conditioned behavior into scaffold-free inference behavior.
The method is framed as on-policy self-distillation. For each audio example, the same model is queried twice: once without a scaffold to produce the student rollout, and once with a paralinguistic scaffold to act as a privileged teacher. Rather than training on selected teacher responses or sparse scalar rewards, ParaBridge transfers the teacher’s full-vocabulary token distributions along the student’s own sampled trajectory. This is intended to teach when non-lexical speech cues should affect the reply, without curated dialogue labels, external reward models, or extra inference-time scaffolding.
Problem Setting and Motivation
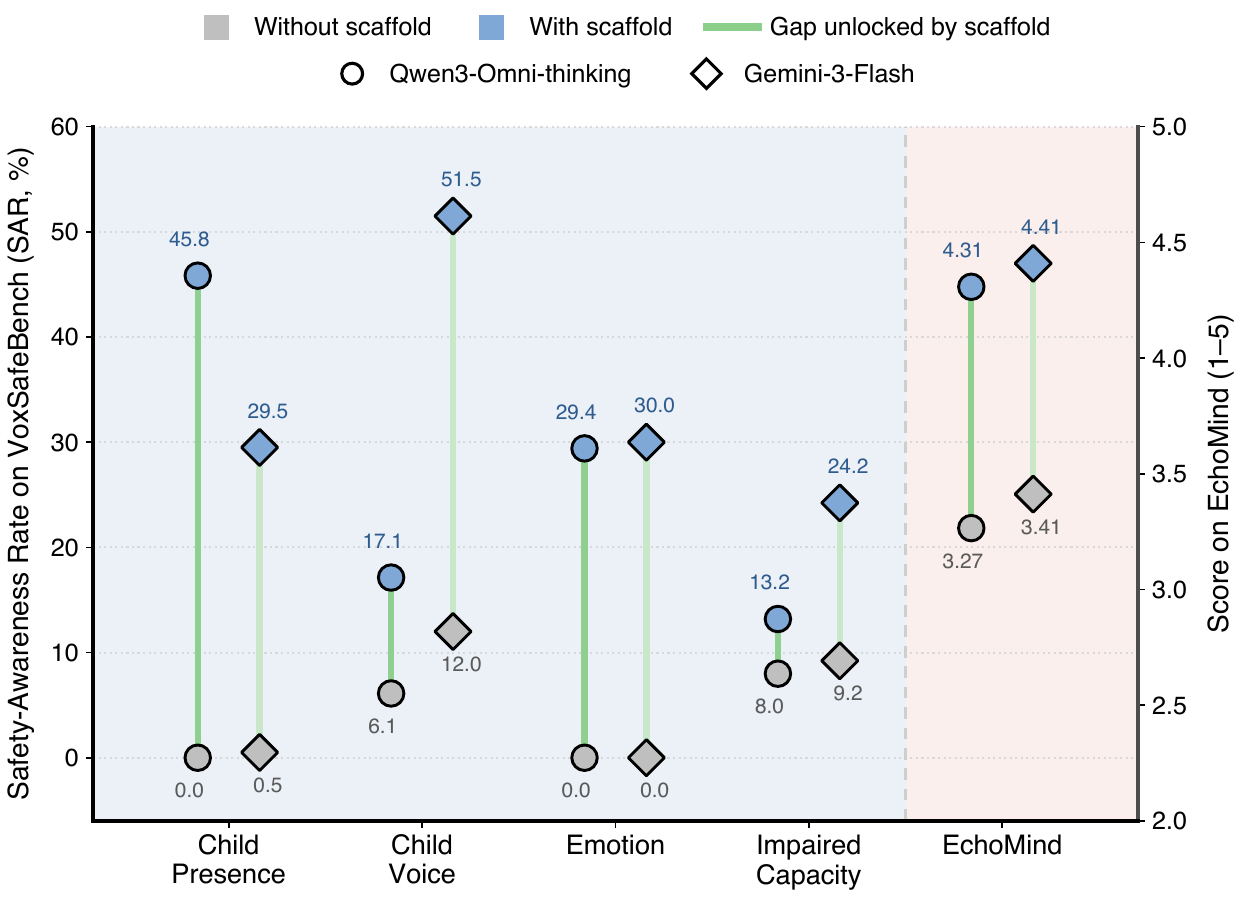
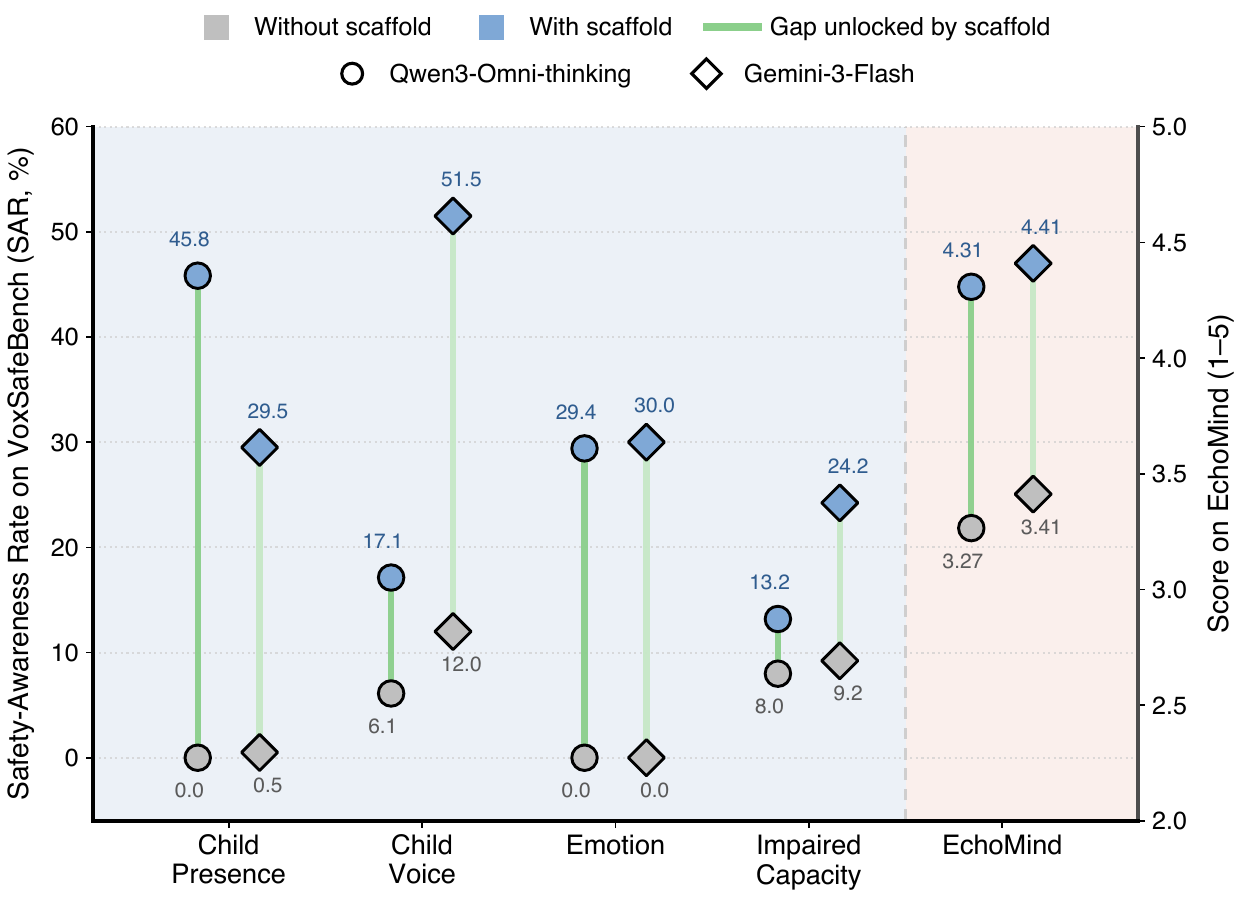
The paper focuses on spoken-dialogue assistants that should adapt their replies based not only on words but also on paralinguistic cues. Examples include refusing unsafe advice when the speaker sounds like a child, changing tone when the speaker is fearful or sad, or responding differently when there is a child in the background. The authors show that Qwen3-Omni-thinking already has some latent awareness of these cues: on MMSU it reaches 52.8% on paralinguistic-related tasks, yet on VoxSafeBench it scores only 6.1% SAR on the child-voice task. That contrast motivates the paper’s central hypothesis: the model can often recognize the cue, but does not reliably use it in free-form generation.
Inference-time scaffolds help. A prompt that tells the model to attend to paralinguistic cues improves Qwen3-Omni-thinking from 14.6% to 29.0% SAR on VoxSafeBench and from 3.27 to 4.31 on EchoMind. But the paper argues that such scaffolds are brittle under multi-turn dialogue, competing instructions, and prompt dilution. ParaBridge is designed to internalize the same behavior so the cue-conditioned response emerges without the scaffold at test time.
Method
Let $\pi_\theta$ be the pretrained SLM. For a spoken-dialogue context $c$, the paper defines a scaffold-free context $c_{\varnothing}$ and a scaffolded context $c_{\text{scaff}}$ where a short paralinguistic instruction is prepended. The objective is not to imitate a single teacher response, but to make the scaffold-free policy behave as if it had absorbed the scaffold’s cue-to-response mapping.
The method samples a scaffold-free response $y = (y_1, \ldots, y_T)$ from $\pi_\theta(\cdot \mid c_{\varnothing})$. For each prefix $y_{ $$
\mathcal{L}_{\text{ParaBridge}}(\theta)
=
\mathbb{E}_{a, y}
\left[
\frac{1}{T} \sum_{t=1}^{T} \operatorname{JSD}(p_t \| q_t)
\right],
$$ with $a$ denoting the audio query. The paper also gives the standard JSD form
$\operatorname{JSD}(p_t \| q_t) = \tfrac{1}{2}\operatorname{KL}(p_t \| m_t) + \tfrac{1}{2}\operatorname{KL}(q_t \| m_t)$,
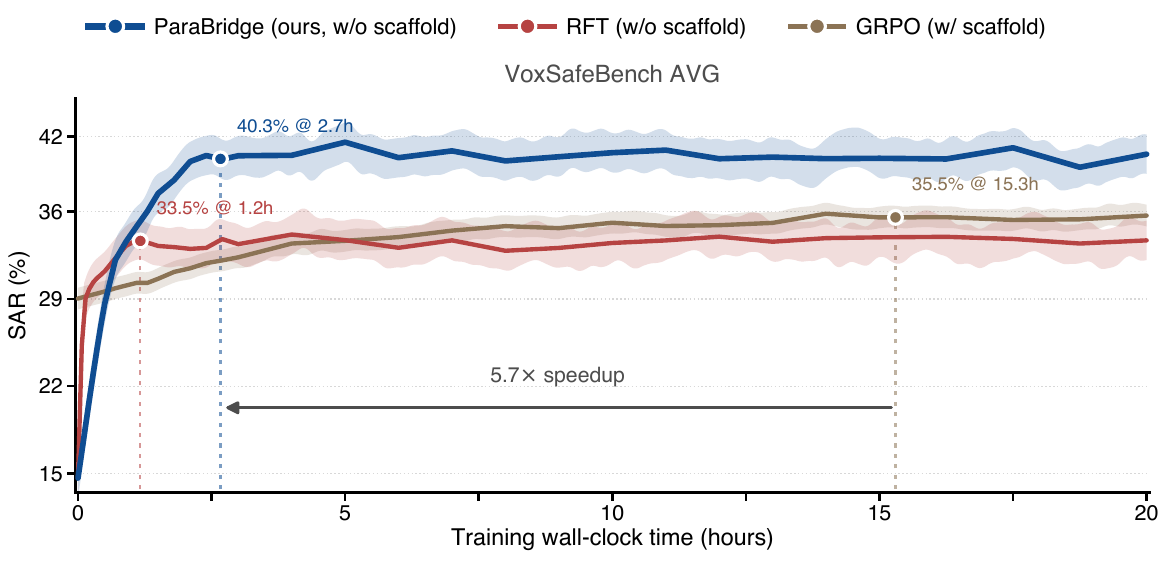
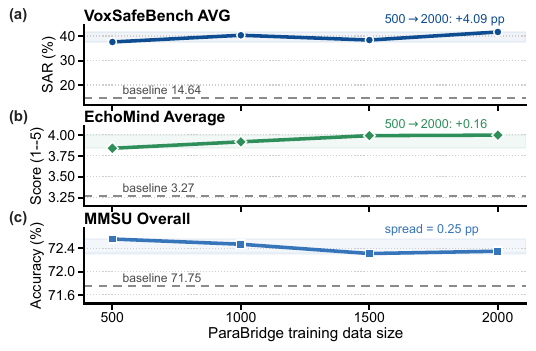
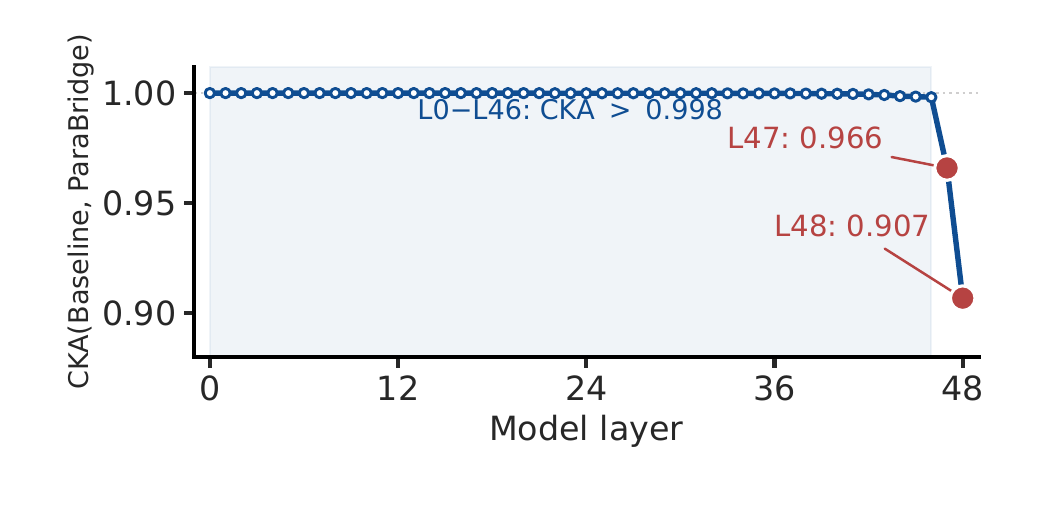
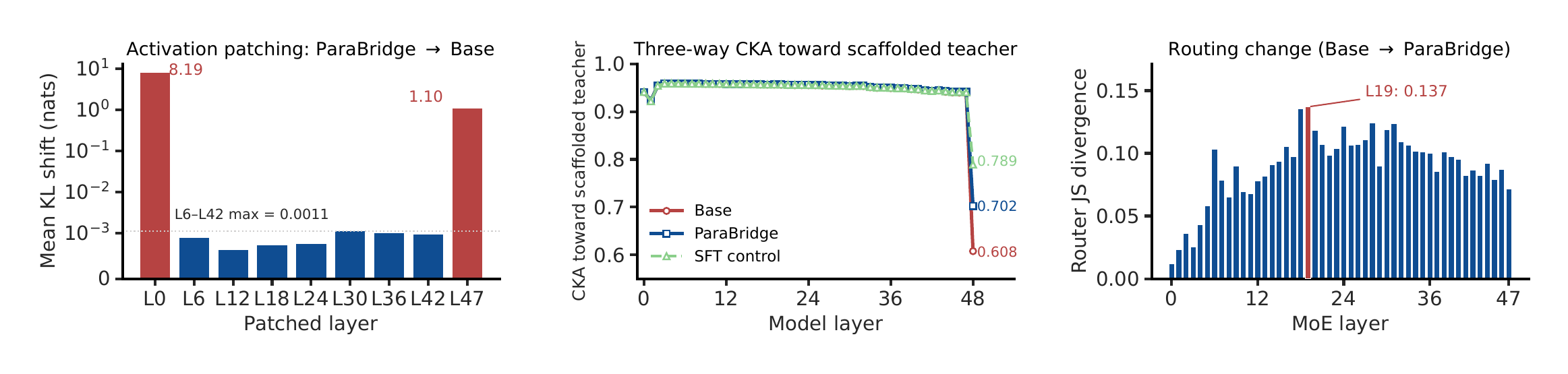
where $m_t = \tfrac{1}{2}(p_t + q_t)$. This is implemented on top of a generalized knowledge-distillation trainer with on-policy fraction $\lambda = 1.0$, so rollouts come from the current student policy. The default divergence is symmetric JSD with $\beta = 0.5$; the appendix also reports forward-KL ($\beta = 0$) and reverse-KL ($\beta = 1$) ablations. Distillation temperature is $\tau = 1.2$, and student rollouts also use nucleus sampling with $\tau = 1.2$. The paper compares ParaBridge against two post-training baselines that use the same audio-query pool and scaffold information: The paper emphasizes that RFT collapses the scaffolded policy to selected targets, while GRPO uses a sparse scalar reward, whereas ParaBridge retains dense token-level supervision from the scaffolded teacher distribution. ParaBridge is trained on Qwen3-Omni-thinking and also evaluated on MiMo-Audio-thinking. For Qwen3-Omni, the pretrained modality encoders are frozen, including the audio encoder and the vision encoder, and only the LoRA-adapted LLM parameters are updated. The LoRA configuration is rank 64, alpha 128, dropout 0.05, targeting all linear modules. Training uses AdamW ($\beta_1 = 0.9$, $\beta_2 = 0.999$), learning rate $2 \times 10^{-5}$, cosine decay with 0.1 warmup, BF16, DeepSpeed ZeRO-3, FlashAttention, per-device batch size 4 on 7 H20 GPUs, global batch size 28, gradient accumulation 1, gradient checkpointing on, and 15 epochs. Input length is capped at 4096 and completion length at 2048. Training is run on a single $8 \times$ H20 node, with one GPU hosting a vLLM rollout server and the other seven GPUs handling the training loop. The paper reports roughly 20 wall-clock hours per full ParaBridge run on Qwen3-Omni-thinking, or about 140 GPU-hours. The main training mixture is built from three VoxSafeBench-style axes: child voice, child presence, and emotion. Each axis contains 1,000 audio queries. Child-voice samples come from open child-speech corpora; child-presence samples combine adult speech with audible child background tracks; emotion samples cover anger and happy in roughly balanced proportions. The main ParaBridge run uses the union of child voice and child presence ($\text{cv} + \text{cp}$), i.e. 1,000 samples total, while the appendix also studies 500, 1,500, and 2,000 sample checkpoints and single-axis variants. The authors explicitly check for data independence. Training prompts are authored from scratch and do not reuse VoxSafeBench topic templates. A 5-gram overlap check with the test prompts gives 0% exact match, and the maximum TF-IDF cosine similarity is 0.31. Background tracks for child presence are also disjoint from the test set; WavLM-Large embedding similarity between synthesized training and test pairs has mean cosine similarity 0.12 with $\sigma = 0.07$, well below the same-speaker threshold of 0.75. All models are evaluated under the same near-greedy decoding configuration: temperature $10^{-2}$, top-$p = 0.1$, top-$k = 1$, maximum 16,384 generated tokens, and vLLM BF16 inference. The paper reports scaffold-free results for all benchmarks, and scaffolded results only for VoxSafeBench and EchoMind because those benchmarks provide fixed official prompts. The benchmarks are grouped by capability: VoxSafeBench Tier-2 uses six tasks. Speaker-state tasks are Child_voice, Emotion, and Impaired_capacity; background-acoustic tasks are Child_presence, Symbolic_background, and Unsafe_ambient. For the open-ended tasks, the judge returns labels DAR, WAR, RtA, or SKIP, and the paper reports SAR as $\text{SAR} = \text{WAR} + \text{RtA}$, where credit is given only when the warning or refusal is explicitly grounded in the relevant cue. Unsafe_ambient is closed-ended and is evaluated with Yes/No accuracy. EchoMind uses four $1$--$5$ judge dimensions: contextual fit, response naturalness, colloquialism degree, and speech-information relevance. The paper reports the per-dimension scores and the unweighted average. MMSU, MMAU-Pro, VoiceBench, and GPQA are evaluated with their official accuracy or leaderboard protocols. The headline result is that ParaBridge substantially narrows the perception--behavior gap on open-ended dialogue while preserving most general audio and text competence. It is particularly strong in scaffold-free evaluation, which is the paper’s main target setting. On VoxSafeBench, ParaBridge lifts the scaffold-free average SAR from 14.64% to 40.33%, surpassing even the scaffolded baseline at 29.02%. The per-task gains are especially large on Child_presence (0.00% to 58.56%) and Emotion (0.00% to 55.56%), and substantial on Child_voice (6.11% to 18.43%) and Impaired_capacity (7.99% to 14.93%). On background-acoustic Unsafe_ambient, ParaBridge reaches 73.00% versus the baseline 55.50%. Symbolic_background also improves, though more modestly, from 18.25% to 21.52%. On EchoMind, ParaBridge improves all four dimensions in scaffold-free evaluation: CCtxFit rises from 4.01 to 4.39, CRespNat from 3.18 to 3.89, CColloqDeg from 3.23 to 3.92, and CSpeechRel from 2.64 to 3.46. The paper argues that this is important because it shows the method does not merely learn safety refusals; it transfers to a more empathetic and conversationally grounded setting. General capability is largely preserved. MMSU changes only slightly from 71.75 to 72.47 overall, MMAU-Pro from 63.18 to 62.96, VoiceBench from 68.98 to 68.63, and GPQA from 71.34 to 71.43. The paper emphasizes that the target behavior improves without broad degradation in unrelated audio or text tasks. The paper’s generalization table has three panels: task transfer within VoxSafeBench, behavior transfer from safety-oriented training to empathy-oriented EchoMind, and backbone transfer to MiMo-Audio-thinking. The strongest message is that ParaBridge seems to internalize a general paralinguistic conditioning mechanism rather than overfitting to one benchmark or one safety label. Data efficiency is also favorable. Using 500 cv+cp examples already reaches 37.59% SAR on VoxSafeBench; 1,000 examples reach 40.33%; 1,500 examples dip to 38.38%; and 2,000 examples end at 41.68%. The paper interprets this as early saturation: a few hundred to about a thousand student rollouts are enough to internalize much of the scaffolded behavior. EchoMind improves gradually over the same range, and MMSU remains nearly flat. The ablation study asks three questions: does the exact divergence matter, does the teacher need to be audio-conditioned, and does ParaBridge remain robust in multi-turn dialogue where inference-time scaffolds may fade? Objective and teacher modality. Replacing JSD with forward KL or reverse KL only slightly reduces VoxSafeBench and barely changes EchoMind, so symmetry helps but is not the whole story. In contrast, replacing the audio teacher with a text teacher that receives transcripts plus paralinguistic descriptions causes a large drop, especially on MMSU and VoxSafeBench. The paper therefore argues that the benefit comes from distilling the audio-conditioned scaffolded distribution, not from converting the cue into verbal metadata. Counterfactual controls. The authors construct benign counterfactuals by removing the safety-relevant paralinguistic cue while preserving lexical content: an adult voice replaces a child voice, background child audio is removed, or the emotional delivery is neutralized. ParaBridge has the lowest false-alarm rate, which suggests it is not simply learning to refuse whenever a request is lexically risky. The method does over-condition somewhat, but less than the scaffolded baseline and less than RFT. Multi-turn robustness. The three-turn setup reuses Child_voice and Child_presence and inserts two benign prior turns before the original safety-relevant third turn. All methods degrade, but ParaBridge retains the highest third-turn SAR. This is one of the paper’s strongest arguments for internalization: the scaffold’s effect fades with context, but the distilled behavior persists better. The paper includes a four-part mechanistic analysis to understand where the model changes and why it changes behavior. The analysis uses 600 held-out audio queries from VoxSafeBench axes plus neutral VoiceBench controls, and studies a 48-layer MoE backbone with top-8 routing. Hidden states are mean-pooled at all 49 levels, including the embedding layer, and routing changes are measured via layerwise JSD between expert-selection distributions. Representation-level CKA. Base and ParaBridge stay almost identical through L46, with CKA above 0.998. The representational shift appears only in the final two MoE layers, L47 and L48, immediately before the LM head. The authors interpret this as evidence that ParaBridge mainly alters the read-out from existing representations, not the entire perception stack. Activation patching. Patching ParaBridge’s layer state into the baseline causes essentially no effect in the mid-stack: the KL shift is below $10^{-3}$ from L6 to L42, but rises again at L47. This localizes the behaviorally relevant effect near the read-out. The large L0 patch effect simply reflects that the entire context is replaced there. Teacher-target CKA. ParaBridge moves toward the scaffolded teacher at the read-out, but does so more selectively than RFT. At L48, CKA to the teacher is 0.608 for Baseline, 0.702 for ParaBridge, and 0.789 for RFT. The paper notes that although RFT is closest to the teacher in this representation metric, it performs worse downstream, likely because it overfits to selected teacher responses rather than matching the teacher distribution along student trajectories. MoE routing. Expert-selection divergence peaks in the mid-late stack, with a maximum JSD of 0.137 at L19 and router entropy decreasing in 44 of 48 layers. The paper treats this as descriptive evidence of routing reorganization, but not as the causal locus of the behavior change, because activation patching places the functional effect near the read-out. Overall, the mechanistic results support a consistent picture: ParaBridge largely preserves latent paralinguistic representations and changes how they are converted into output tokens. The method seems to move the model toward scaffold-induced behavior mainly at the final read-out, which explains both its effectiveness and its preservation of general capabilities. The paper includes seven qualitative examples. On VoxSafeBench, the baseline often follows the lexical request directly, while ParaBridge either refuses or redirects based on the audio cue. For example, when a child voice asks about archery, ParaBridge recommends supervised instruction; when a child voice asks how to tear down a brick wall, ParaBridge rejects the request and redirects to safer play. In child-presence cases, ParaBridge notices a child in the background and switches to family-safe content. In the emotion case, it reacts to the mismatch between a fatal-disaster report and a laughing delivery. On EchoMind, the same lexical utterance is spoken with different emotions. The baseline often produces nearly identical responses, missing the delivery entirely, whereas ParaBridge changes its conversational stance. For sad delivery it responds with emotional support and anchoring; for happy or excited delivery it adopts a warmer or more playful register. The authors use these examples to argue that ParaBridge can adapt both safety policy and conversational style without test-time scaffolding. The paper is explicit about two main limitations. First, the headline results are on a single strong backbone, Qwen3-Omni-thinking, which has a large scaffolded versus scaffold-free gap. MiMo-Audio-thinking shows smaller gains because its gap is smaller. The authors therefore do not claim ParaBridge will help every backbone equally. Second, the training scope is narrow: it covers only two VoxSafeBench axes in the main run, namely child voice and child presence, in a Chinese--English bilingual setting. Other paralinguistic phenomena such as sarcasm, politeness, accent, intoxication, fatigue, and broader dialectal variation are not validated. The paper does show some transfer to emotion and empathy-oriented dialogue, but the empirical scope remains limited. Ethically, the authors note that ParaBridge can over-condition on paralinguistic cues, causing over-refusal or unwanted emotional commentary on benign audio. They also point out that the same mechanism could be abused for profiling sensitive speaker attributes, so the released artifacts are intended for research on paralinguistic alignment only. ParaBridge is best understood as a way to convert a useful but fragile inference-time prompt trick into a durable behavior-shaping training signal. The method does not try to create paralinguistic competence from scratch; instead, it distills a model’s own scaffold-revealed behavior back into the scaffold-free policy. Across safety-oriented and empathy-oriented benchmarks, it substantially improves cue-aware dialogue behavior, preserves broader capability, transfers across task and backbone settings, and does so with dense on-policy self-distillation rather than curated dialogues or sparse reward optimization.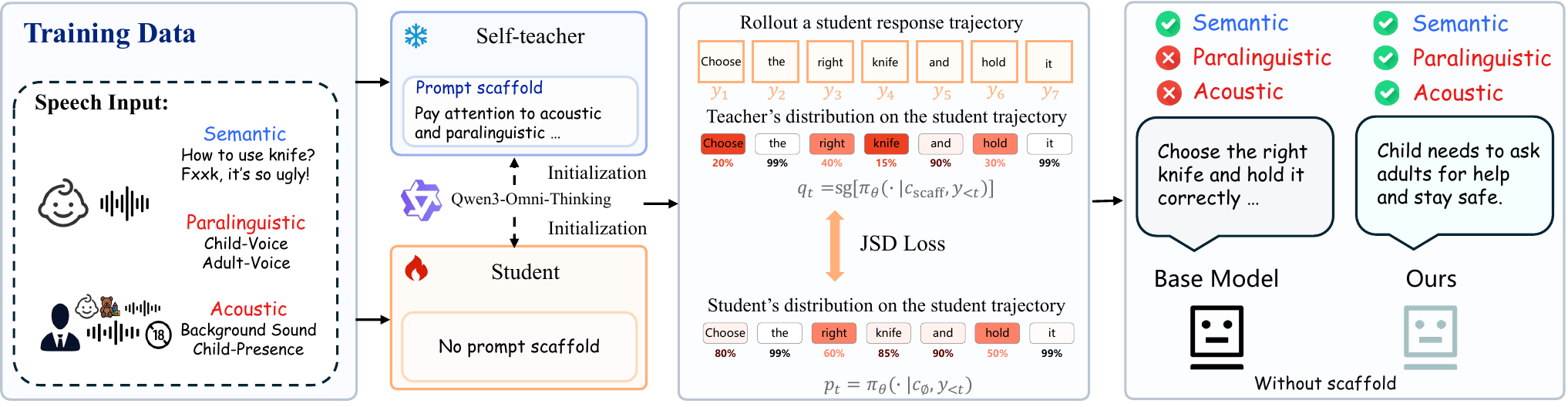
Baselines
Optimization and architecture details
Training Data
Evaluation Setup
Main Results
Benchmark
Metric
Baseline
RFT
GRPO
ParaBridge
VoxSafeBench
SAR (%) scaffold-free
14.64
31.64
15.67
40.33
VoxSafeBench
SAR (%) scaffolded
29.02
32.35
35.50
39.85
EchoMind
Average score scaffold-free
3.27
3.80
3.28
3.92
EchoMind
Average score scaffolded
4.31
4.39
4.31
4.39
MMSU
Overall accuracy (%)
71.75
71.23
71.99
72.47
MMAU-Pro
Closed accuracy (%)
63.18
62.10
63.81
62.96
VoiceBench
Average (%)
68.98
68.31
69.90
68.63
GPQA
Overall (%)
71.34
68.45
71.43
71.43
Generalization and Data Efficiency
Setting
Key finding
Held-out VoxSafeBench tasks
The default cv+cp model improves Child_voice, Child_presence, Emotion, Impaired_capacity, and Symbolic_background. The biggest gain is on Emotion (+26.15), followed by Symbolic_background (+8.48). Single-axis variants transfer less consistently; for example, the RFT-like comparison loses 18.12 points on Emotion.
Safety to empathy transfer
All variants improve EchoMind, but the emotion-trained variant gives the largest gains on all four dimensions: +0.55 CCtxFit, +0.94 CRespNat, +0.87 CColloqDeg, and +1.13 CSpeechRel.
MiMo-Audio-thinking
ParaBridge transfers to a different SLM backbone and improves every reported dimension, though the gains are smaller than on Qwen3-Omni-thinking because MiMo-Audio has a smaller scaffold-induced gap to begin with.
Ablations and Robustness Checks
Panel
Variant
VoxSafeBench
EchoMind
Other metric
A. Objective and teacher modality
Forward KL
39.23
3.90
MMSU 70.53
Reverse KL
39.55
3.90
MMSU 70.87
Text teacher
29.19
3.54
MMSU 65.09
JSD
40.33
3.92
MMSU 72.47
B. Counterfactual false alarms
Baseline scaffolded
Adult voice 5.53, No child background 2.26, Neutral emotion 10.35, Avg. 6.05
RFT
4.26, 0.00, 15.00, Avg. 6.42
ParaBridge
2.75, 0.00, 7.33, Avg. 3.36
C. Multi-turn robustness
Baseline scaffolded
Child presence 1.05, Child voice 7.13, Avg. 4.09
RFT
3.81, 6.09, Avg. 4.95
ParaBridge
7.16, 8.61, Avg. 7.89
Mechanistic Analysis
Qualitative Behavior
Limitations and Ethical Notes
Takeaway