3DMEAD-ARKit Facial Animation
Deploying Speech-Driven 3D Facial Animation in Unreal Engine for Production-Ready Digital Humans
This paper introduces a deployable system that enables speech-driven 3D facial animation in Unreal Engine using ARKit-compatible blendshapes. It bridges academic research and production pipelines, allowing real-time, emotion-controllable digital human animation usable in game engines.
Demos
These demos showcase the AutoFaceARKit system for speech-driven 3D facial animation in Unreal Engine using ARKit blendshapes. They highlight the dataset pipeline, system architecture for live synthesis, and perceptual study interface. Evaluate realism, lip-sync, emotion control, and Unreal Engine integration quality.

Links
Paper & demos
Impact
Abstract
Speech-driven 3D facial animation research has shown promising results, but most methods rely on representations that are not compatible with production pipelines. In this work, we present a deployable system that bridges this gap by enabling speech-driven 3D facial animation directly in Unreal Engine (UE) using ARKit-compatible representations. We construct 3DMEAD-ARKit dataset by converting the MEAD corpus into blendshape sequences using MediaPipe, and retrain FaceDiffuser and ProbTalk3D-X to generate stochastic and emotion controllable animations. We further develop a modular UE plugin with a Python backend that supports model selection, and parameter control. We compare the results to two existing commercial tools: Epic Games' MetaHuman speech-driven animator and Nvidia Audio2Face with a perceptual user study. The results highlight the importance of comparisons among academic and commercial pipelines. We recommend watching the supplementary video. We also plan to do live demonstrations of our work at Siggraph 2026 conference.
Introduction
This paper tackles a practical gap in speech-driven facial animation research: many strong academic models generate motion in representations that are not directly usable in production pipelines, while game-engine workflows for digital humans typically rely on animator-friendly blendshape systems such as ARKit-compatible facial rigs. The authors focus on bridging that gap by enabling speech-driven 3D facial animation directly inside Unreal Engine (UE) using an ARKit-style output representation that can be applied to production-ready characters.
The core idea is not just to build another speech-to-face model, but to make a deployable system that connects research models, dataset processing, runtime inference, engine integration, and evaluation against commercial tools. The paper combines three main ingredients: (1) a new dataset pipeline that converts MEAD videos into ARKit blendshape sequences, (2) retraining of two existing speech-driven models to operate in that blendshape space with emotion and intensity control, and (3) a modular UE plugin with a Python backend that lets users select models, provide audio, control conditioning parameters, and generate engine-native animation assets.
The paper’s broader contribution is an end-to-end workflow for production-oriented digital humans: rather than stopping at offline benchmark metrics, it evaluates usability with practitioners and conducts perceptual comparisons against two commercial systems, NVIDIA Audio2Face and Epic Games’ MetaHuman speech-driven animator.
Problem Setting and Motivation
The paper identifies a mismatch between the representations common in research and the representations used in production. Recent speech-driven facial animation models often work on 4D scan data or pseudo-3D reconstructions and use non-semantic parametric head models. Those representations can be efficient for learning, but they do not map cleanly to animator-centric facial action coding workflows. In contrast, production environments such as UE often use semantic blendshape systems, especially ARKit-compatible sets, because they are editable, controllable, and easy to integrate into character rigs.
The limitation is not model capability alone, but the lack of large-scale, high-quality blendshape datasets and deployment tooling that would allow models to be used directly in an engine. This paper argues that closing that gap requires a system-level solution: dataset construction, model adaptation, deployment infrastructure, and evaluation in realistic production settings.
System Overview
The resulting system is organized around a frontend UE plugin connected to a local Python inference backend. A user can choose a speech-driven model, input either prerecorded audio or live microphone audio, select a target character, and control conditioning parameters such as speaking style, emotion, and intensity. The backend generates ARKit blendshape sequences, which are returned to UE as CSV data and converted into animation assets that can be previewed, saved, and reapplied to other compatible characters.
The design goal is production readiness: the generated output is immediately usable as UE animation assets rather than as an intermediate research representation. The plugin also maintains an internal animation library so generated sequences can be reused and retargeted.
Dataset Construction: 3DMEAD-ARKit
A major technical contribution is 3DMEAD-ARKit, a dataset constructed from the MEAD corpus. MEAD contains 47 speakers, 40 sentences, 8 basic emotions, and 3 emotion-intensity levels. The authors process the RGB videos frame by frame using MediaPipe to detect 3D facial landmarks and then regress those landmarks into ARKit blendshape coefficients.
This transformation is important because it converts a large speech corpus into a blendshape supervision signal that can train models in an ARKit-compatible space. Because the conversion is automatic, the dataset can be constructed at scale, but the paper explicitly notes that the resulting blendshape sequences contain noise and temporal jitter for several subjects. After visual inspection of the reconstructed animations, the authors filter out noisy subjects and keep a final subset of 24 subjects for retraining.
The dataset is therefore best understood as a practical bridge dataset: it is not a perfect ground-truth facial capture corpus, but a scalable way to obtain large amounts of ARKit-formatted training data from an existing video corpus. The authors emphasize that this scalability comes with quality limitations that affect downstream performance.

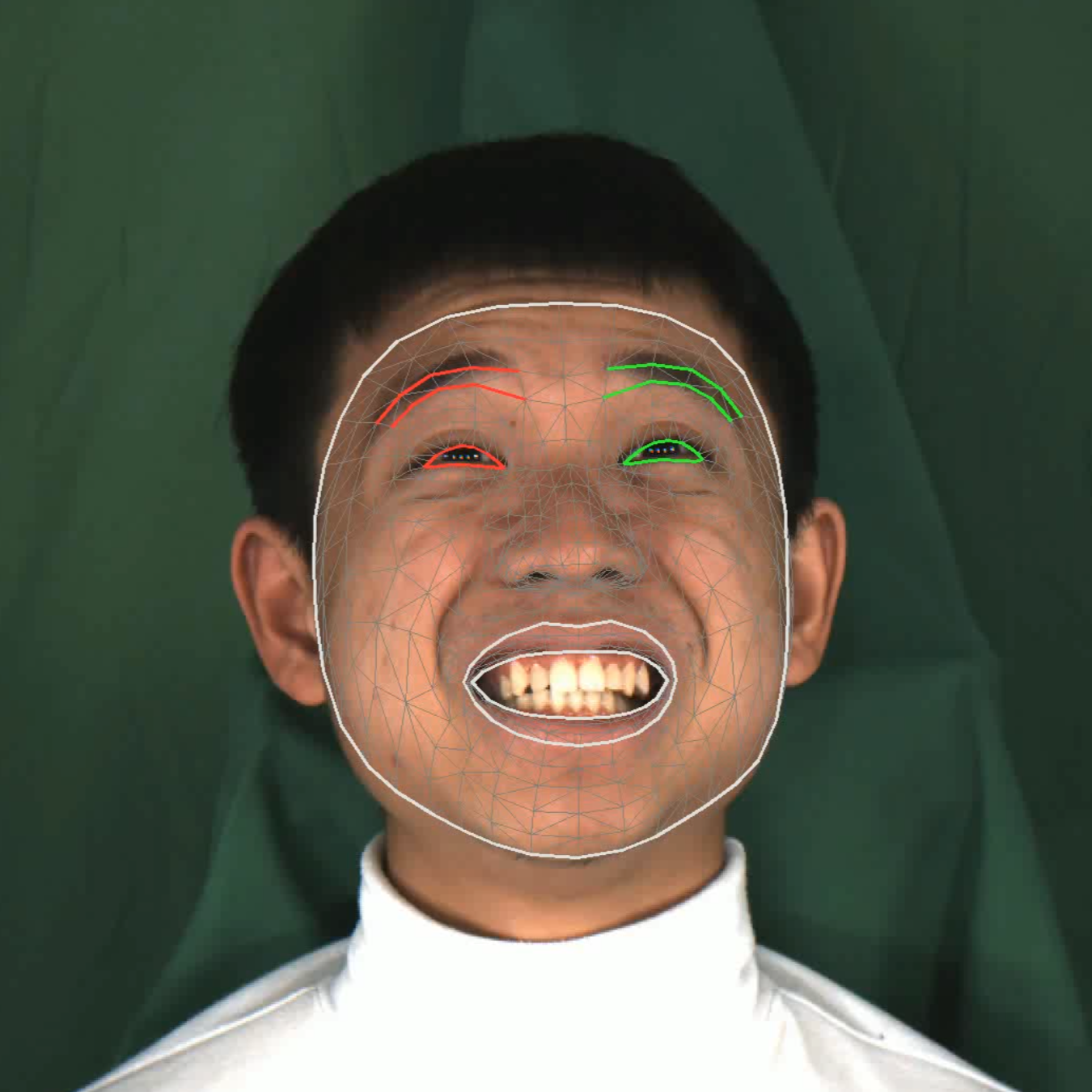

The supplementary material illustrates the pipeline from a raw MEAD video frame, to MediaPipe facial landmarks, to the resulting ARKit blendshape-driven rendering on an ARKit-compatible face model.
Model Adaptation and Training
The paper retrains two prior models from the authors’ earlier work: FaceDiffuser and ProbTalk3D-X. Both are adapted to operate on the newly constructed ARKit blendshape sequences, with the explicit goal of generating speech-driven animation that can encode both emotion and intensity conditions.
The paper does not introduce a new generative model architecture from scratch; instead, it retools existing models to fit the target representation and deployment setting. This makes the work particularly relevant for engineering teams, because it exposes what needs to change in an existing research system to make it useful in production.
FaceDiffuser-ARKit
The authors report a small but important architectural modification to FaceDiffuser when training it on the ARKit representation. In the adapted version, the style embedding is fused with the audio hidden representation before the latent is passed to the GRU decoder. They state that the original fusion order used in the earlier blendshape version failed to generate emotion cues. To improve training dynamics and motion quality, the adapted model also adds weighted velocity and acceleration losses.
These changes reflect a practical lesson: once the target representation changes, the conditioning pathway and temporal losses may need to be rebalanced to preserve controllability and expressive motion.
ProbTalk3DX-ARKit
For ProbTalk3D-X, the authors keep the original architecture but modify the output dimension to match the 3DMEAD-ARKit target space. They also simplify the reconstruction objective because ARKit coefficients are already normalized to the $[0,1]$ range, unlike the original weighted reconstruction loss used for the FLAME-based dataset in the prior version.
In the authors’ quantitative evaluation, this adapted ProbTalk3DX-ARKit model performs better than FaceDiffuser-ARKit on all reported metrics, making it the stronger of the two ARKit-trained academic baselines used in the plugin.
Deployment in Unreal Engine
The UE plugin is one of the paper’s most practically relevant components. It serves as the interface layer between speech-driven animation models and an actual engine-based digital-human workflow. The plugin supports model selection, character selection, prerecorded or live audio input, and controllable conditioning parameters such as speaking style, emotion, and intensity. Inputs are sent to a local Python server that performs inference and returns ARKit blendshape sequences as CSV files.
On the UE side, the plugin uses LiveLinkFaceImporter to convert the returned coefficients into animation sequences stored as Level Sequence assets. These are then immediately applied to the selected ARKit-compatible character. Generated sequences are also saved inside an internal animation library, enabling reuse and retargeting to other compatible characters in the scene.
This architecture matters because it turns model output into engine-native assets, which is a critical requirement for actual production pipelines. The system is thus not only an inference interface but also a content-management layer for generated facial motion.
Practitioner Evaluation
To assess usability, the authors conducted two think-aloud practitioner sessions with students from a university Computer Animation master’s course who had prior experience in facial animation and UE. Each session lasted about 30 minutes and required participants to complete three tasks using the plugin. According to the paper, both participants completed all tasks with minimal assistance.
The practitioner study is qualitative rather than statistical, but it provides evidence that the plugin can be used by people familiar with the target workflow. The paper reports that the sessions helped surface interface and workflow issues for future refinement.
Practitioner feedback
- The plugin was seen as well integrated with native Unreal Engine workflows.
- It was considered useful for rapid animation prototyping.
- It supported previewing generated facial animations on multiple characters.
- Workflow clarity issues were noted around the animation library and sequence re-application flow.
- The microphone recording workflow was described as unintuitive, with extra interaction steps and unclear file handling.
- The authors also note requests for clearer output-file location cues, better camera navigation after generation, improved audio preview, and broader export options beyond UE-specific sequence assets.
Perceptual User Studies
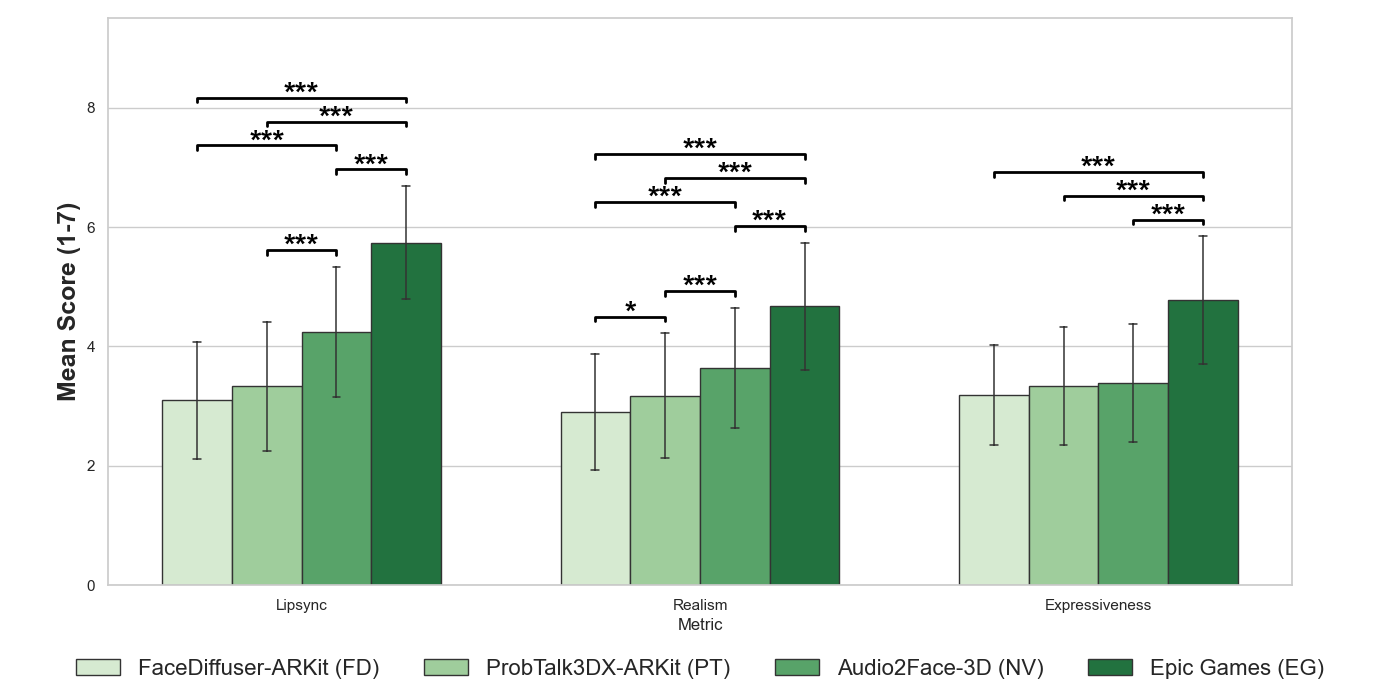
The paper’s main experimental evaluation is a perceptual comparison of four systems: FaceDiffuser-ARKit (FD), ProbTalk3DX-ARKit (PT), NVIDIA Audio2Face (NV), and Epic Games’ MetaHuman speech-driven animator (EG). The authors evaluate three dimensions on 7-point Likert scales: Lip-Sync, Realism, and Expressiveness. Unlike simple A/B preference tests, they use within-subject repeated-measures ANOVA with Bonferroni-corrected pairwise comparisons.
Two experiments were run. Experiment 1 uses 12 test-set audio clips from the dataset, balanced by gender, and includes emotion recognition against ground-truth emotion labels. Experiment 2 uses 8 in-the-wild movie audio clips and omits emotion recognition because no ground-truth labels are available. Participants were recruited via Prolific and each experiment yielded 30 valid responses after attention-check filtering.
Stimulus design
The authors carefully control the perceptual study setup. All stimuli are rendered using MetaHuman characters to standardize the appearance across methods. For male and female characters they use the MetaHuman presets Aera and Isaiah. A three-point lighting setup and a medium-dark green background are used to keep facial motion visible and consistent.
For FD and PT, the authors use speaker-specific styles corresponding to MEAD subjects M003 and W009. For NV, they use the Claire model for female audio and James for male audio. For EG, they use the default decoder. Emotion intensity values for NV and EG are mapped to $0.33$, $0.67$, and $1.0$ for low, medium, and high intensity, respectively. The paper also notes that not all emotion labels are shared across models, so the comparison is restricted to comparable affective categories.
Experiment 1 results
Experiment 1 shows significant main effects for all three perceptual dimensions, rejecting the null hypothesis for Lip-Sync, Realism, and Expressiveness. The reported statistics are:
| Metric | $F(3,87)$ | $p$ | $\epsilon$ | $\eta_g^2$ |
|---|---|---|---|---|
| Lip-Sync | 139.20 | $< 0.001$ | 0.63 | 0.51 |
| Realism | 77.56 | $< 0.001$ | 0.55 | 0.31 |
| Expressiveness | 70.10 | $< 0.001$ | 0.72 | 0.31 |
Post-hoc tests show that EG significantly outperforms all methods on all three perceptual dimensions ($p < 0.001$). NV is the second-best performer for Lip-Sync and Realism, significantly outperforming FD and PT on those dimensions ($p < 0.001$), while PT performs better than FD in Realism ($p < 0.05$). For Expressiveness, the paper reports no significant differences among FD, PT, and NV. In rank order, the mean scores are EG highest, followed by NV, PT, and FD.
The emotion-recognition question in Experiment 1 further favors EG, which achieves 71.11% accuracy. The other methods score 55.00% for NV, 51.11% for FD, and 49.72% for PT.
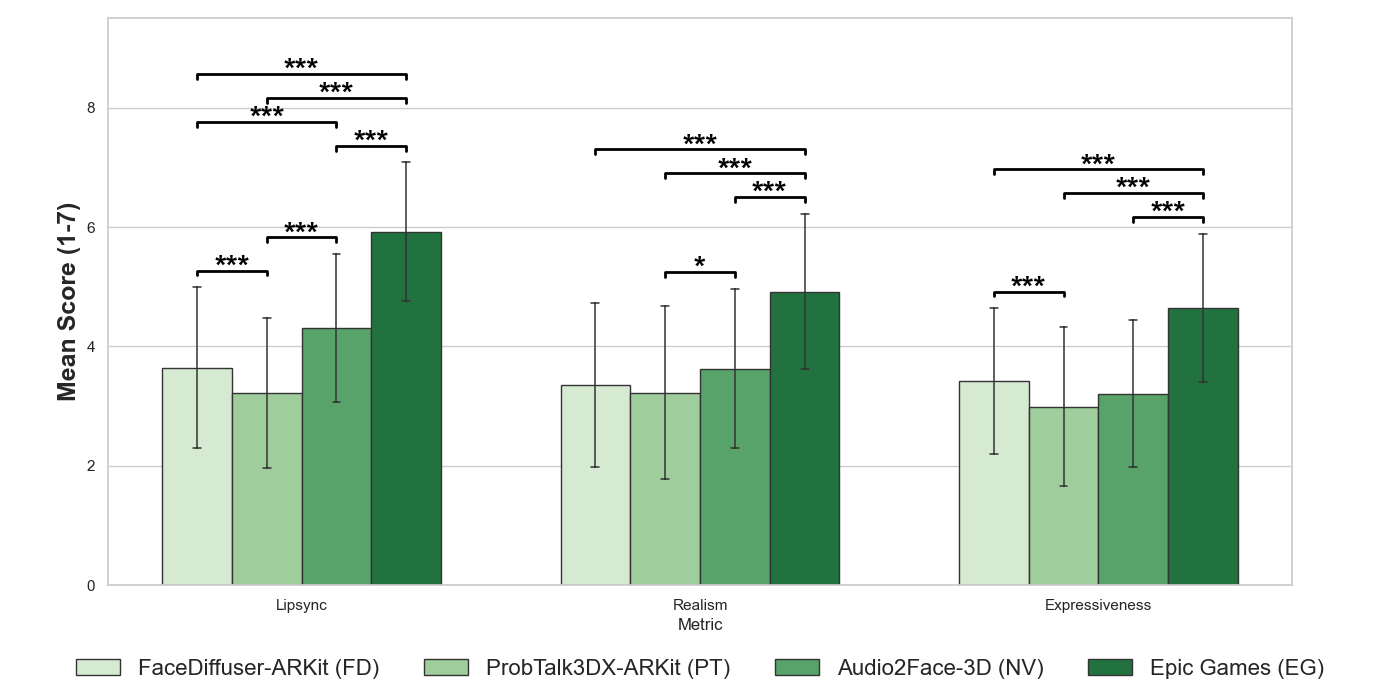
Experiment 2 results
Experiment 2 repeats the same evaluation on in-the-wild neutral audio clips and again finds significant main effects for all three metrics:
| Metric | $F(3,87)$ | $p$ | $\epsilon$ | $\eta_g^2$ |
|---|---|---|---|---|
| Lip-Sync | 98.89 | $< 0.001$ | 0.51 | 0.41 |
| Realism | 47.81 | $< 0.001$ | 0.51 | 0.20 |
| Expressiveness | 60.24 | $< 0.001$ | 0.62 | 0.21 |
The ordering again favors EG across all metrics, with NV second for Lip-Sync and Realism. The paper reports that FD outperforms PT in Lip-Sync and Expressiveness, while FD and NV do not differ significantly in Realism or Expressiveness. As in Experiment 1, the overall ordering is EG, NV, FD, PT.
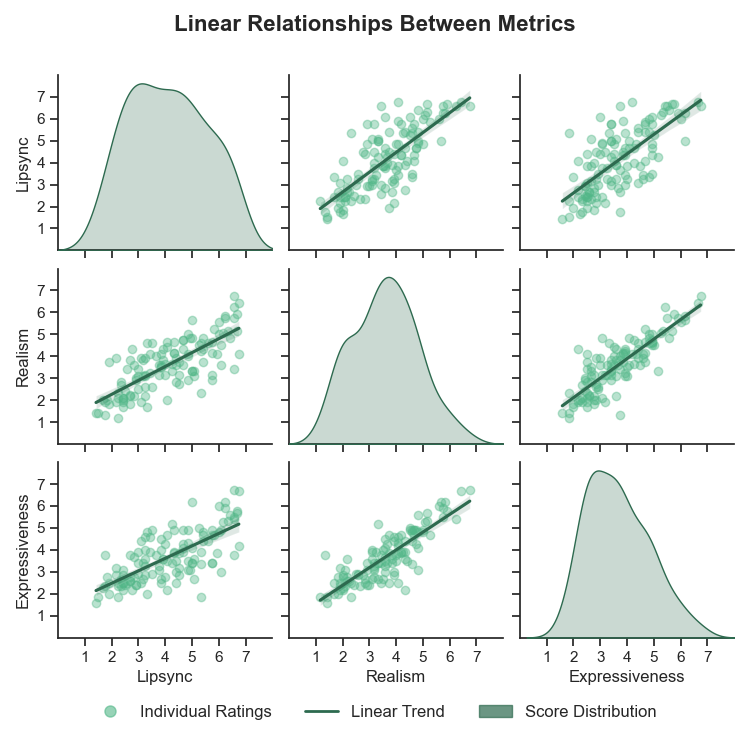
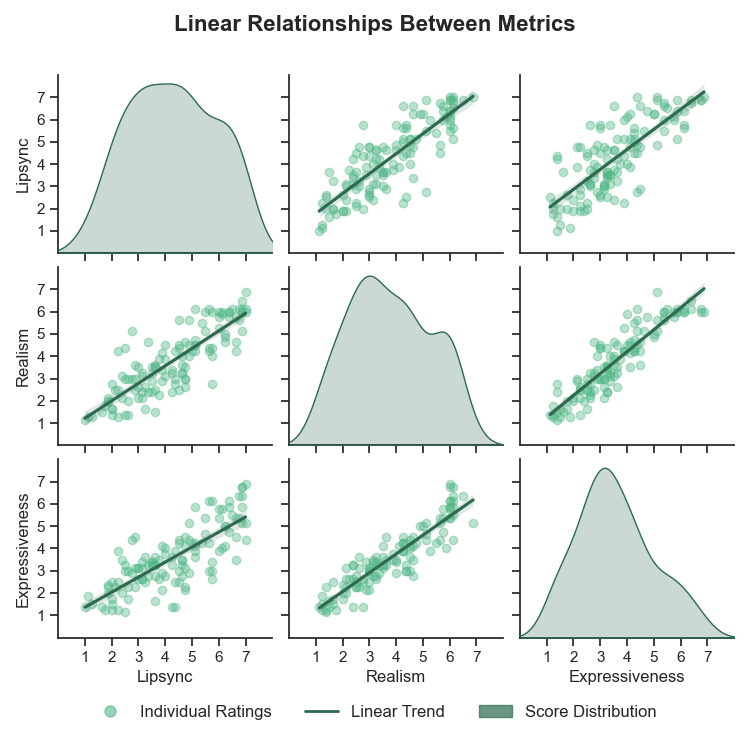
Correlation analysis
The appendix also reports strong positive correlations among Lip-Sync, Realism, and Expressiveness, indicating that raters tend to perceive them as related components of overall quality rather than independent attributes. For Experiment 1, the repeated-measures correlations are very high: Lip-Sync vs. Realism $r = 0.93$, Realism vs. Expressiveness $r = 0.88$, and Lip-Sync vs. Expressiveness $r = 0.82$, all with $p < 0.001$. Experiment 2 shows a similar pattern with $r = 0.88$, $0.89$, and $0.82$, again all significant at $p < 0.001$.
The authors also report significant model-by-metric interactions in a two-way RMANOVA: $F(6,174)=26.71$ for Experiment 1 and $F(6,174)=22.04$ for Experiment 2, both with $p < 0.001$. This means superiority over one metric does not transfer uniformly to the others.
Quantitative Comparison of the Retrained Models
The supplementary material includes a quantitative comparison of the two retrained ARKit models on the 3DMEAD-ARKit dataset, using metrics from prior work. The paper reports that metrics are computed in ARKit blendshape space rather than vertex space.
The reported metrics are Mean Blendshape Error (MBE), Landmark Blendshape Error (LBE), Mouth Expression Error (MEE), Category Error (CE), Facial Diversity Distance (FDD), and Diversity. The lower-error metrics are better when marked with downward arrows, while diversity is better when higher.
| Model | MBE $\downarrow$ ($\times 10^{-1}$) | LBE $\downarrow$ ($\times 10^{-1}$) | MEE $\downarrow$ ($\times 10^{-1}$) | CE $\downarrow$ ($\times 10^{-1}$) | FDD $\downarrow$ ($\times 10^{-2}$) | Diversity $\uparrow$ ($\times 10^{-1}$) |
|---|---|---|---|---|---|---|
| FaceDiffuser-ARKit | 5.3783 | 3.8115 | 3.7742 | 3.6933 | 3.9647 | 0.8832 |
| ProbTalk3DX-ARKit | 5.0289 | 3.5639 | 3.3078 | 3.2269 | 1.6042 | 2.5384 |
ProbTalk3DX-ARKit is better on all reported metrics. The paper uses this result to justify selecting both FaceDiffuser-ARKit and ProbTalk3DX-ARKit for plugin deployment, while acknowledging that ProbTalk3DX-ARKit is the stronger model objectively.
Discussion, Interpretation, and Limitations
The perceptual studies consistently favor the commercial systems, especially Epic Games’ MetaHuman speech-driven animator, which outperforms all academic models across Lip-Sync, Realism, and Expressiveness in both experiments. NVIDIA Audio2Face is generally the second-strongest system for Lip-Sync and Realism. The paper attributes this gap to the commercial systems’ training on high-quality proprietary datasets and model-specific optimization. The authors note that MetaHuman uses control-rig-specific capture pipelines and that Audio2Face is trained on subject-specific 4D scans adapted to ARKit blendshapes.
The paper is explicit that the new 3DMEAD-ARKit dataset is only a partial solution to the dataset bottleneck. Because the data are derived automatically from monocular video using MediaPipe, they contain noise and temporal jitter. This likely limits the upper bound of the retrained models. The authors expect that higher-quality datasets and more optimization would close the gap to commercial systems.
Another limitation concerns character type. The perceptual study uses high-end MetaHuman characters, and the authors speculate that ARKit-based models may score better on simpler or more stylized characters. This is an important caveat for interpretation: the ranking may depend on how well the facial rig and the model output space align with the visual complexity of the target character.
Methodologically, the paper also stresses the importance of comparing academic methods to industry systems. One of its key messages is that research evaluations often omit commercial baselines, making it difficult to understand how a deployable academic system would perform in practice. Here, the authors deliberately include those baselines and use statistically rigorous within-subject analysis rather than informal preference tests.
Contributions and Takeaways
- A production-oriented speech-driven facial animation system integrated directly into Unreal Engine.
- The 3DMEAD-ARKit dataset, built by converting MEAD videos into ARKit blendshape sequences using MediaPipe.
- Two retrained ARKit-compatible speech animation models: FaceDiffuser-ARKit and ProbTalk3DX-ARKit.
- A modular UE plugin with Python backend support for model choice, audio input, conditioning controls, animation storage, and retargeting.
- Practitioner validation showing the plugin is usable for animation workflows, along with concrete UI/UX improvement feedback.
- Perceptual comparisons against NVIDIA Audio2Face and Epic MetaHuman speech-driven animation, using repeated-measures ANOVA and pairwise tests.
Overall, the paper’s main value is system integration rather than a novel generator architecture. It demonstrates that bringing speech-driven facial animation into production requires a coherent stack: dataset preparation, representation alignment, model adaptation, engine-native asset generation, and evaluation against both research and commercial systems. The paper makes a strong case that ARKit-compatible representations are a practical target for deployment, but it also shows that dataset quality and commercial-scale optimization remain major barriers to matching proprietary tools.