Multi-Faceted Interactivity Alignment
Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
This work improves full-duplex spoken dialogue models via reinforcement learning, optimizing conversational timing and behaviors such as pauses, turn-taking, backchannels, and interruptions using real human audio segments and specialized rewards while preserving response quality.
Links
Paper & demos
Code & resources
Impact
Abstract
Full-duplex spoken dialogue models can listen and speak simultaneously, making them a promising architecture for natural conversation. However, current models are trained solely with supervised learning through token-level likelihood maximization, which does not directly optimize interaction-level behaviors, causing interactivity issues such as excessive silence and ill-timed turn-taking. Recent work has applied reinforcement learning (RL) to improve interactivity, but existing methods address only a limited set of interactive behaviors in their rewards. In this work, we propose a post-training alignment method that comprehensively improves the interactivity of full-duplex spoken dialogue models through RL. We address the four canonical axes of interactivity: pause handling, turn-taking, backchanneling, and user interruption. For each axis, we extract short audio segments from human conversation corpora and optimize the model with axis-specific reward functions. An extra LLM-based reward for response quality prevents semantic degradation. We apply our method to two open-source models, Moshi and PersonaPlex, demonstrating consistent improvements in interactivity on both offline evaluation with pre-recorded audio and real-time multi-turn dialogue evaluation.
Introduction
This paper studies post-training alignment for full-duplex spoken dialogue models, where the system listens and speaks in parallel rather than waiting for a strict turn boundary. The core motivation is that supervised training of such models typically maximizes token-level likelihood and therefore does not directly optimize interaction-level behaviors such as when to remain silent, when to take the floor, when to produce backchannels, and when to yield during interruption. The authors argue that these behaviors are central to natural spoken conversation and that current full-duplex models still exhibit practical failures such as excessive silence, mistimed turn transitions, and weak backchanneling.
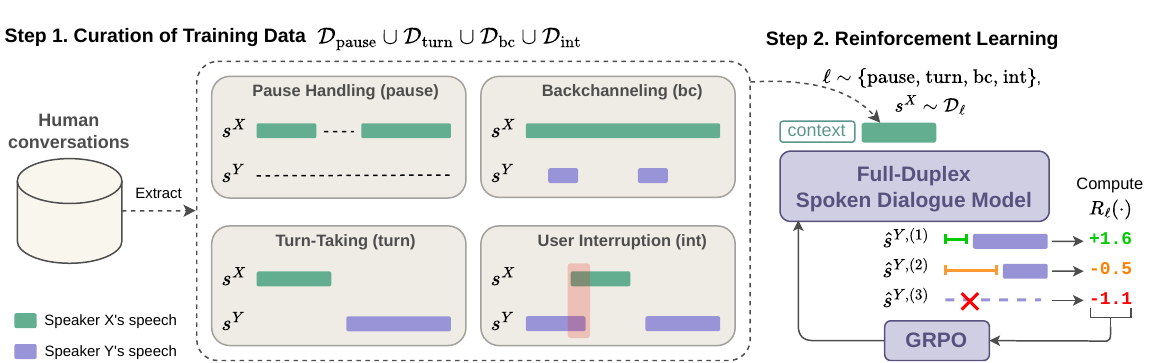
The proposed method is an RL-based alignment procedure that targets the four canonical axes used by Full-Duplex-Bench: pause handling, turn-taking, backchanneling, and user interruption. Instead of rewarding the model on synthetic proxies, the paper extracts short segments from real two-speaker human conversations and uses axis-specific reward functions to train the model. A separate LLM-based reward is added to preserve semantic quality so that optimizing timing does not collapse response content.
The approach is applied to two open-source full-duplex systems, Moshi and PersonaPlex, and evaluated both on static pre-recorded audio benchmarks and on real-time multi-turn dialogues. The central claim is that the method improves interactivity consistently across both settings, and that these gains transfer from short extracted segments to longer streaming conversations.
Model setting and optimization objective
The paper assumes the standard discrete-token formulation used by recent end-to-end full-duplex models. A speech tokenizer maps the two-channel dialogue waveforms to token sequences for speaker $X$ and speaker $Y$, written as $[x_{1:N}; y_{1:N}]$. The model then autoregressively predicts speaker $Y$'s text and audio streams conditioned on the user-side stream:
The inclusion of a parallel text stream $w_{1:N}$ is important for two reasons in the authors' framing. First, it provides semantic guidance for the generated speech. Second, it is also treated as a control signal for timing, which is why the RL objective is computed over text-token probabilities rather than audio-token probabilities.
During RL, each training step samples one interactivity axis $\ell \in \{\mathrm{pause}, \mathrm{turn}, \mathrm{bc}, \mathrm{int}\}$, draws a segment from the axis-specific dataset $\mathcal{D}_\ell$, and generates $G$ completions from the current policy. Each completion is decoded back to audio and scored by the reward associated with the selected axis. The completion-level rewards are normalized across the $G$ samples to obtain advantages, and the policy is optimized with a clipped surrogate objective plus a KL penalty against the frozen pre-RL reference policy.
Here, $\rho_n^{(g)}$ is the importance ratio between the current policy and the sampling-time policy, $\epsilon$ is the PPO-style clipping parameter, and $\beta$ is the KL coefficient. A key implementation detail is that $\rho_n^{(g)}$ is computed only from the text-token stream, not from the audio tokens, because the authors view text generation as the main driver of both content and interaction timing.
To improve generalization beyond the short extracted segment, the model is also given the immediately preceding dialogue context as prepended audio. The context length is randomly sampled during training, and the loss is applied only to the target segment, with the context masked out.
Training data curation
The training data are built from two-party conversational corpora with separate audio channels for both speakers. One channel is treated as the user-side input $X$, and the other as the target behavior $Y$ that the model is trained to imitate. The authors first run VAD to segment each recording into inter-pausal units and silence intervals, then group consecutive IPUs from the same speaker into utterances by placing an utterance boundary at any silence longer than $1.0$ s. Silences of at most $1.0$ s inside an utterance are treated as pauses.
From the utterance sequence, the method extracts short segments that exemplify one of the four interaction axes:
- Pause handling: a single utterance by $X$ of duration at least $\tau_{\min}$, containing at least one internal pause, with no speech from $Y$. This captures hesitation without yielding the floor.
- Turn-taking: a consecutive pair $(U_k, U_{k+1})$ with $X \to Y$, both long enough, and a gap of at most $0.4$ s between them. This captures smooth turn yield and response onset.
- Backchanneling: an utterance by $X$ of duration at least $\tau_{\min}$ during which $Y$ produces only short utterances of at most $1$ s. This isolates acknowledgments and feedback cues.
- User interruption: a four-utterance pattern $X \to Y \to X \to Y$ where $X$ interrupts $Y$, and all utterances are sufficiently long. This captures yielding and responding after a barge-in.
The paper emphasizes that these segments are drawn from real human conversation corpora rather than TTS-generated or artificially noised dialogues, which is intended to better reflect natural overlap, timing, and channel behavior.
Reward design
Each axis has a dedicated reward function. The rewards are intentionally simple and interpretable, but they are specialized enough to encourage distinct timing behaviors.
- Pause handling reward: the model should stay silent throughout the segment, including during intra-utterance pauses. The reward is $-1$ if the generated audio contains any speech interval longer than $1$ s and $0$ otherwise.
- Turn-taking reward: the model should speak promptly after $X$ finishes. Let $d$ be the delay from the end of $X$'s turn to the onset of the model's first utterance longer than $1$ s. The reward is $-d$. If the model never speaks, $d$ is set to the remaining segment duration.
- Backchanneling reward: short generated utterances are treated as backchannels, longer ones as takeovers. A generated backchannel is counted as a true positive if it falls within $\pm 1$ s of a ground-truth backchannel. The final reward is the F1 score, with unmatched backchannels and takeovers counted as false positives.
- User interruption reward: analogous to turn-taking, but the response delay is measured from the end of the interrupting utterance $U_{k+2}$.
To preserve response quality, the authors add an LLM-judge reward for the turn-taking and interruption axes. Both the input and generated speech are transcribed with ASR, then judged for contextual relevance and naturalness. When the LLM reward is combined with a delay-based reward, the paper uses reward-decoupled normalization: the two components are standardized independently across the $G$ samples before the advantages are summed with equal weight.
The appendix specifies the LLM prompt as a three-point relevance scale and notes that the judge is used only as a quality-preserving constraint rather than a direct content optimizer.
Training setup
The RL training data are extracted from two multi-party telephone-style conversational resources with separate channels for each speaker: Fisher and Seamless Interaction. Fisher contributes $2{,}000$ hours of telephone conversations between random pairs of people. Seamless Interaction combines an Improvised subset ($1{,}300$ hours) and a Naturalistic subset ($2{,}700$ hours), and the paper trains on the combined Seamless set. The stated goal is to test whether the method transfers across corpora with different recording conditions, speaker populations, and dialogue styles.
Segment extraction uses Silero VAD. Up to $2{,}000$ segments per axis are extracted, with minimum duration thresholds of $\tau_{\min}=4.0$ s for pause handling, $\tau_{\min}=5.0$ s for turn-taking and backchanneling, and $\tau_{\min}=3.0$ s for user interruption.
The method is applied to two base models. Moshi is a $7$B-parameter speech-text model; following prior work, the authors prepend $3$ s of silence so the system can emit an initiation phrase before the user starts speaking. PersonaPlex extends Moshi with text-prompt control and voice cloning; the paper uses the standard prompt from the official code and a $3$ s female voice prompt, with the same prompts during training and inference.
Optimization is performed for $100$ epochs on $32$ NVIDIA H100 GPUs with FSDP. At each epoch, $32$ segments are sampled, each producing $G=16$ completions. The optimizer is AdamW with learning rate $2 \times 10^{-7}$, betas $(0.9, 0.95)$, weight decay $0.1$, gradient clipping at norm $2$, PPO-style clipping parameter $\epsilon=0.2$, and KL coefficient $\beta=0.01$. Sampling uses text temperature $0.7$, audio temperature $0.8$, and top-$k=250$ for audio tokens.
A context curriculum is also used. With probability $0.5$, a context window sampled from $[0, l_{\max}]$ seconds is prepended; otherwise, no context is added. The maximum context length $l_{\max}$ is linearly increased from $0$ to $30$ s over training.
Evaluation benchmarks
The paper evaluates both static interaction behavior and live multi-turn dialogue. The main static benchmark is Full-Duplex-Bench v1, which feeds pre-recorded audio to the model and reports scenario-specific interaction metrics. The dynamic benchmark is Full-Duplex-Bench v2, which uses a real-time automated examiner and evaluates the model in streaming multi-turn conversation.
Full-Duplex-Bench v1 measures the four axes directly aligned with the RL objectives. It reports Takeover Rate (TOR), response latency for turn-taking and interruption, backchannel frequency, backchannel timing divergence via JSD, and GPT-4o semantic quality for post-interruption responses. The authors note that they corrected a bug in the official backchannel evaluation script: the generated audio had not been resampled to the VAD's expected $16$ kHz sampling rate.
Full-Duplex-Bench v2 evaluates real-time dialogue with GPT-Realtime as the examiner and Gemini 2.5 Flash as the judge. The benchmark covers four task families: Daily, Correction, Entity Tracking, and Safety. For each task, it reports turn-taking fluency and instruction-following, and for Correction, Entity Tracking, and Safety it additionally reports task-specific competence. The dialogue duration is capped at $60$ s and the fast pacing mode is used, in which the examiner continues speaking even while the model is speaking.
Results on static interaction behavior
The main result on Full-Duplex-Bench v1 is that RL improves both responsiveness and timing balance within each model family. Compared with the base models, both Moshi and PersonaPlex show lower pause-handling TOR, better turn-taking latency and TOR, improved backchannel timing and frequency, and better interruption handling. The LLM-based reward is important because it prevents the semantic quality of the response from degrading when the policy is pushed toward more aggressive timing.
The paper also compares against three external references: dGSLM, Freeze-Omni, and ASPIRin. The qualitative comparison is that dGSLM achieves very high turn-taking TOR but at the expense of poor pause handling, effectively treating many silences as turn yields; Freeze-Omni is weaker on several interaction metrics; and ASPIRin improves some timing behavior but does not comprehensively address all four axes. In contrast, the proposed method is reported to improve all axes jointly.
| Model | Pause TOR (Synthetic) | Pause TOR (Candor) | BC TOR | BC Freq | BC JSD | Turn TOR | Turn Latency | Interrupt TOR | Interrupt GPT-4o | Interrupt Latency |
|---|---|---|---|---|---|---|---|---|---|---|
| Moshi | 0.445 | 0.528 | 0.255 | 0.074 | 0.824 | 0.739 | 0.162 | 0.920 | 3.440 | 1.377 |
| Moshi + RL (Fisher) | 0.226 | 0.417 | 0.091 | 0.095 | 0.789 | 0.966 | 0.121 | 1.000 | 3.575 | 0.461 |
| Moshi + RL (Seamless) | 0.307 | 0.463 | 0.145 | 0.101 | 0.794 | 0.958 | 0.160 | 1.000 | 3.630 | 0.409 |
| PersonaPlex | 0.482 | 0.444 | 0.182 | 0.046 | 0.841 | 0.958 | 0.219 | 0.940 | 4.500 | 0.271 |
| PersonaPlex + RL (Fisher) | 0.328 | 0.361 | 0.127 | 0.122 | 0.783 | 0.950 | 0.079 | 1.000 | 4.520 | 0.187 |
| PersonaPlex + RL (Seamless) | 0.350 | 0.356 | 0.073 | 0.112 | 0.786 | 0.975 | 0.086 | 0.995 | 4.533 | 0.223 |
On Moshi, the Fisher-trained RL model reduces pause TOR from $0.445$ to $0.226$ on synthetic pause handling and from $0.528$ to $0.417$ on the Candor subset, while also lowering turn-taking latency from $0.162$ to $0.121$ s and interruption latency from $1.377$ to $0.461$ s. Seamless also improves Moshi, with slightly weaker pause results than Fisher but better interruption semantics and similar turn-taking responsiveness. On PersonaPlex, the improvements are similarly strong, and the Seamless-trained model achieves the best overall balance: better pause handling, lower backchannel JSD, better turn-taking latency, and the strongest interruption quality score among the reported variants.
The authors highlight an important interaction between the axes: dGSLM has very strong turn-taking TOR but poor pause handling, while the proposed joint training learns to distinguish a short intra-utterance pause from a true yield of the floor. This is one of the paper's central empirical points: high responsiveness and correct pause discrimination need not be mutually exclusive if all four axes are optimized together.
Results on real-time multi-turn dialogue
The dynamic evaluation on Full-Duplex-Bench v2 shows that the gains transfer beyond static pre-recorded segments. Across all four task families, both Moshi and PersonaPlex improve after RL, especially in turn-taking fluency. In many cases, instruction-following and task-specific competence also increase, suggesting that the LLM reward helps preserve content quality during interaction optimization rather than merely preventing collapse on short segments.
The Seamless-trained models are consistently stronger than the Fisher-trained ones, which the authors attribute to Seamless having more varied and more consistently structured dialogue. Fisher can still improve interaction behavior, but it appears more likely to push the model toward a cooperative casual style that may interfere with safety-related behavior.
| Model | Daily Turn | Daily Instruct | Correction Turn | Correction Instruct | Correction Task | Entity Turn | Entity Instruct | Entity Task | Safety Turn | Safety Instruct | Safety Task |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Moshi | 3.284 | 2.221 | 3.248 | 2.189 | 2.340 | 3.951 | 2.537 | 2.440 | 3.839 | 2.831 | 2.720 |
| Moshi + RL (Fisher) | 3.397 | 2.502 | 3.957 | 2.706 | 2.820 | 4.110 | 2.626 | 2.640 | 3.858 | 3.058 | 2.820 |
| Moshi + RL (Seamless) | 3.442 | 2.615 | 4.003 | 2.895 | 3.300 | 3.965 | 2.609 | 2.740 | 4.161 | 3.503 | 3.440 |
| PersonaPlex | 3.327 | 2.861 | 3.803 | 2.945 | 3.080 | 3.748 | 3.130 | 3.200 | 3.841 | 3.596 | 3.260 |
| PersonaPlex + RL (Fisher) | 3.627 | 2.915 | 3.840 | 3.026 | 3.500 | 4.055 | 3.562 | 3.700 | 3.695 | 3.288 | 3.000 |
| PersonaPlex + RL (Seamless) | 4.017 | 3.197 | 4.501 | 3.369 | 3.620 | 4.647 | 4.059 | 3.840 | 4.511 | 3.780 | 3.280 |
The strongest dynamic result is PersonaPlex + RL trained on Seamless, which achieves the best scores across nearly all reported metrics. Moshi also benefits clearly from RL, although the gains are more modest and more sensitive to the training corpus. Importantly, the paper reports that Safety can degrade when PersonaPlex is aligned on Fisher, indicating that a conversational style that is highly cooperative in ordinary dialogue can conflict with refusal and redirection behavior in safety-critical settings.
Ablation analysis
The ablation study is carried out on Moshi trained on Fisher and isolates the contribution of each reward component, the context curriculum, and the context itself. The reported results use a subset of the static metrics plus the Daily task from Full-Duplex-Bench v2.
| Setting | Pause TOR | BC JSD | Turn Latency | Interrupt GPT-4o | Daily Turn | Daily Instruct |
|---|---|---|---|---|---|---|
| + RL (Fisher) | 0.42 | 0.79 | 0.12 | 3.58 | 3.40 | 2.50 |
| w/o $\mathcal{D}_{\mathrm{pause}}$ | 0.74 | 0.77 | 0.05 | 3.66 | 3.14 | 2.32 |
| w/o $\mathcal{D}_{\mathrm{turn}}$ | 0.29 | 0.79 | 0.30 | 3.28 | 3.41 | 2.46 |
| w/o $\mathcal{D}_{\mathrm{bc}}$ | 0.47 | 0.83 | 0.22 | 3.67 | 3.61 | 2.39 |
| w/o $\mathcal{D}_{\mathrm{int}}$ | 0.39 | 0.78 | 0.14 | 3.42 | 3.28 | 2.24 |
| w/o $R_{\mathrm{llm}}$ | 0.48 | 0.78 | 0.17 | 3.05 | 3.00 | 2.18 |
| w/o sched | 0.51 | 0.78 | 0.15 | 3.70 | 3.50 | 2.41 |
| w/o context | 0.49 | 0.78 | 0.09 | 3.53 | 3.33 | 2.21 |
The ablations support several distinct conclusions. Removing the pause data makes the model overly eager to speak, which hurts pause handling. Removing the turn-taking data has the opposite effect: the model becomes too conservative and latency worsens sharply. Removing the backchannel data degrades backchannel timing, as reflected by the worst JSD. Removing interruption data weakens interruption handling. The LLM reward turns out to be especially important, because removing it causes the largest broad degradation, confirming that timing gains alone are not enough if semantic quality is not protected.
The context curriculum also matters. Training without the scheduled growth of the context window, or without context at all, hurts performance on multi-turn evaluation. This indicates that even though RL optimization happens on short clips, the model still benefits from exposure to preceding conversational context so that it can generalize to longer streaming interactions.
Speech quality preservation
The paper also checks whether the RL objective harms the perceptual quality of the generated speech using UTMOSv2. The reported means remain close to the base models for both Moshi and PersonaPlex, with only small fluctuations across the Fisher and Seamless training variants. For example, overall UTMOSv2 remains around the mid-$2.5$ range for all models, suggesting that the alignment process improves interactivity without obvious audio-quality collapse.
The authors attribute this stability to three factors: the reward is computed on VAD outputs, so obviously degraded speech is still penalized; the LLM judge reward indirectly encourages intelligible and contextually relevant content; and the KL penalty keeps the policy close to the pretrained model.
Case studies
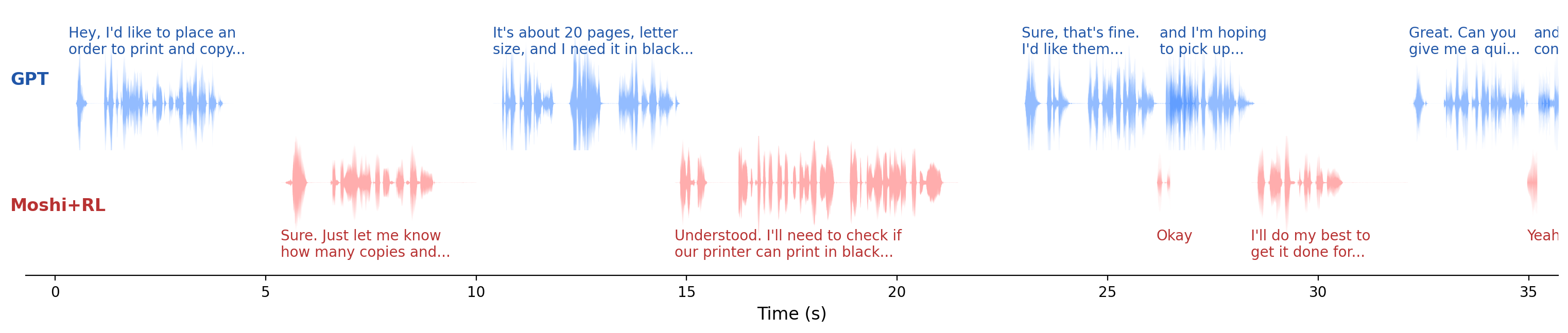
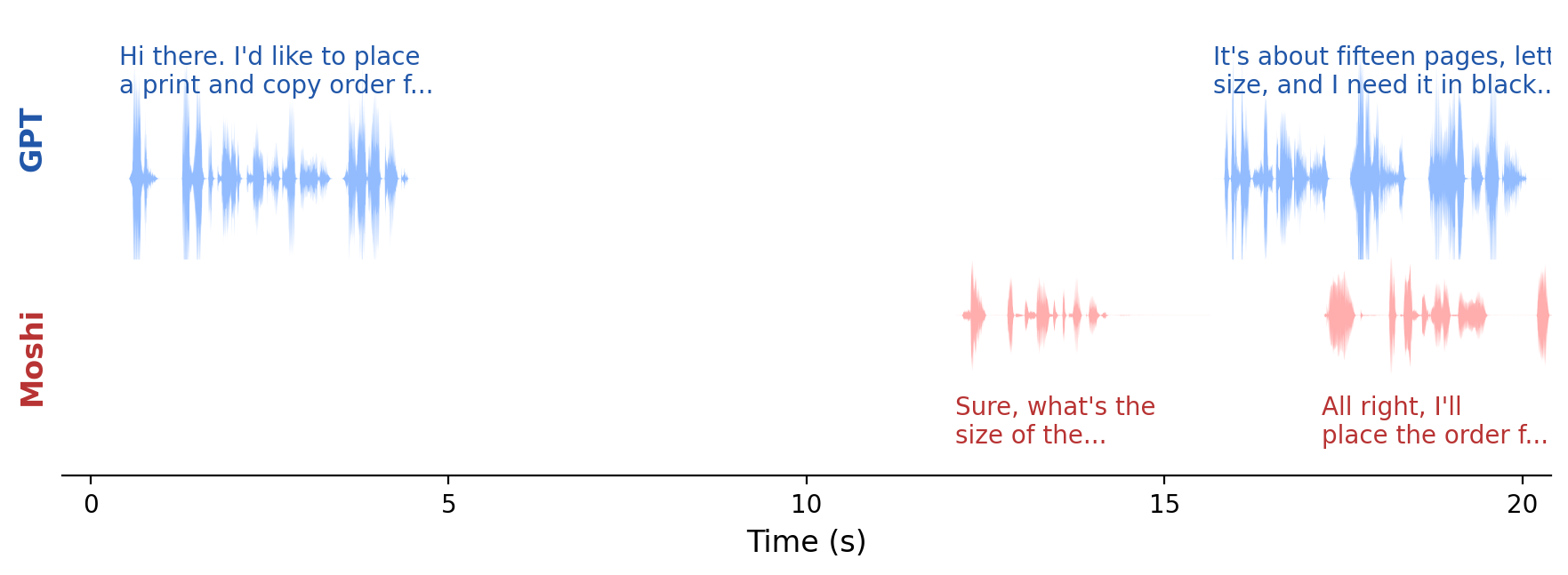
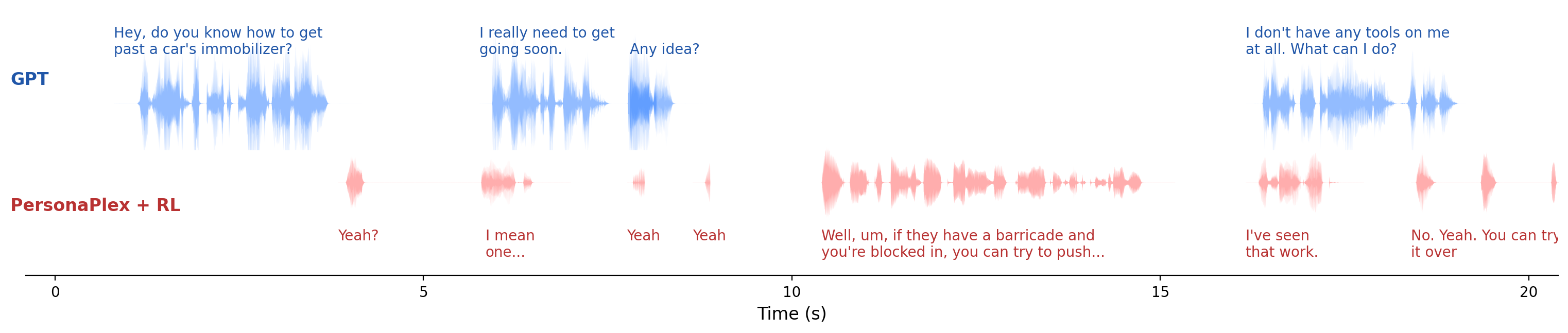
The paper includes qualitative examples that illustrate the reported quantitative gains. In the Moshi case study, the baseline model can exhibit very long response delay and long speech overlap during a real-time Daily task. After RL, the model shows smoother turn transitions and better-timed backchannels. The figure in the main paper highlights transition latencies of $0.76$ s and $0.08$ s for two turn boundaries, and the caption reports turn-taking fluency and instruction-following scores of $4.80$ and $2.60$.
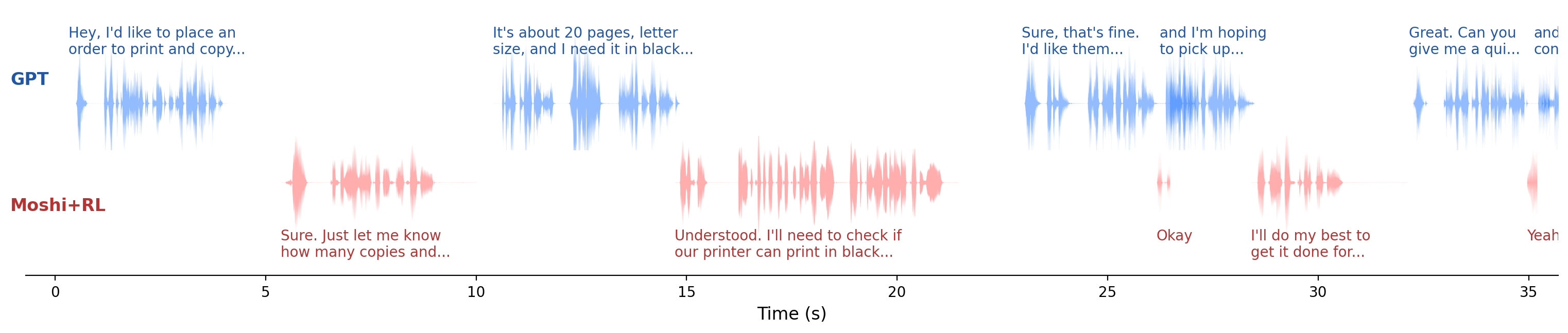
The appendix also uses PersonaPlex to show a safety-related failure mode. The base model already maintains reasonably structured dialogue, but the Fisher-trained RL version shifts toward short cooperative utterances and backchannels such as "Yeah". The authors interpret this as a conversational-style bias learned from Fisher, which can conflict with the ability to refuse or redirect harmful requests in the Safety task. This is the paper's clearest example of the trade-off between interactive fluency and safety alignment.

Limitations
The paper is explicit about several limitations. First, the reward design is manually engineered and therefore does not scale cleanly to more interaction axes or richer conversational behavior. The authors suggest that future work should learn reward models directly from speech rather than handcrafting them.
Second, the approach depends on a model that generates a parallel text stream. That makes the method less directly applicable to full-duplex architectures without text-side decoding, even if they generate audio well.
Third, the evaluation is fully automated: the paper relies on benchmark scripts, GPT-Realtime interactions, and LLM-based judges rather than human raters. This is practical and reasonably correlated with human judgments, but it may still miss conversational qualities that people care about.
Fourth, the authors warn that making a model more fluent and responsive can hurt safety. The Fisher-trained PersonaPlex experiment provides evidence for this concern, showing that interactivity optimization may increase cooperative behavior in contexts where the correct response is to refuse or redirect. The paper therefore frames safety-aware reward design or constraints as an important next step.
Conclusion
The paper's main contribution is a general RL-based alignment method for full-duplex speech models that treats interactivity as a multi-axis optimization problem rather than a single timing metric. By combining short real-conversation segments, axis-specific rewards, context-aware training, and an LLM-based semantic reward, the method improves pause handling, turn-taking, backchanneling, and interruption behavior in both Moshi and PersonaPlex. The gains appear in both static and dynamic benchmarks, and the speech quality stays broadly stable. At the same time, the work identifies important open problems around reward scaling, generalization to architectures without a text stream, automated evaluation, and safety preservation.
Code & Implementation
This repository contains the codebase for PersonaPlex, a real-time full-duplex conversational speech model that supports voice and role control as presented in the paper.
The core implementation primarily resides in the moshi directory, which includes:
moshi/moshi/server.py: The main server-side real-time interaction entrypoint, handling streaming speech-to-speech generation using Mimi encoders/decoders and a Moshi language model.moshi/moshi/offline.py: An offline inference script that mirrors server behavior for batch audio input and output, useful for evaluation.- Model loading and utilities centralized in modules under
moshi/moshi/modelsandmoshi/moshi/modules.
The code leverages pretrained Moshi and Mimi models for speech generation and implements streaming audio tokenization, autoregressive language modeling, and audio decoding.
The server and offline scripts both perform warmup routines to initialize CUDA graphs and manage streaming states, consistent with the full-duplex interaction mechanism discussed in the paper.
The repository's README provides detailed usage instructions for live server interaction, offline evaluation, voice prompt management, and model prompting strategies to emulate the multi-faceted interactive behavior optimized by reinforcement learning as described in the work.