Lip Forcing
Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
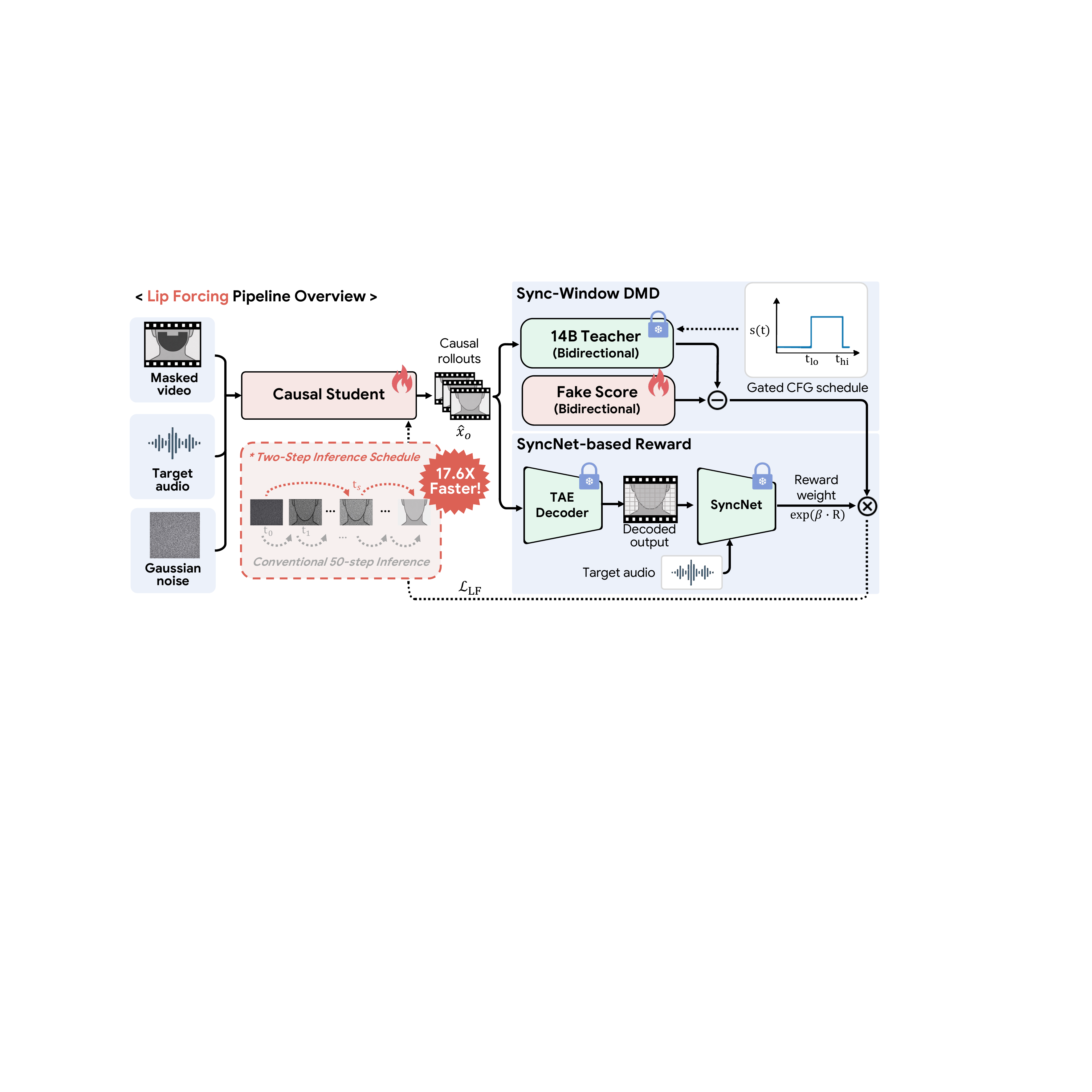
Lip Forcing is the first autoregressive diffusion method for real-time lip-sync in talking-head videos. It distills a large bidirectional diffusion teacher into fast causal students using a novel two-step inference and lip-sync rewards, enabling photorealistic lip motion in streaming applications.
Demos
These demos highlight Lip Forcing's real-time lip synchronization strength, achieving high fidelity and sync quality with two-step autoregressive diffusion. Watch for smooth, accurate lip movements tightly aligned with speech audio, demonstrating a new speed-quality tradeoff that beats prior methods. Comparison clips emphasize its superior lip sync and visual realism across datasets.
Links
Paper & demos
Impact
Abstract
Diffusion-based lip synchronization models achieve strong visual quality and audio-visual alignment, but full-sequence bidirectional attention and many denoising steps make them impractical for real-time inference. We present Lip Forcing, to our knowledge the first autoregressive diffusion method for video-to-video (V2V) lip synchronization, which distills a 14B audio-conditioned bidirectional video diffusion teacher into causal students. At inference, the students generate each chunk in only two denoising steps without inference-time CFG, enabling real-time lip synchronization. A lip-sync-specific teacher-trajectory analysis reveals a CFG fidelity-sync tradeoff: no-CFG predictions favor reference fidelity, whereas CFG-guided predictions favor synchronization within a mid-trajectory band. Lip Forcing translates this finding into three analysis-derived components: Sync-Window DMD, a two-step inference schedule, and a SyncNet-based reward. We validate Lip Forcing at two student scales, both distilled from the 14B teacher. The 1.3B student crosses into real-time streaming at 31 FPS, $17.6\times$ faster than its same-scale bidirectional model. The 14B student, the largest diffusion model reported for V2V lip synchronization, runs $39.8\times$ faster than its teacher at comparable reference fidelity. Time-to-first-frame is sub-millisecond at both scales, far below every diffusion baseline.
Problem Setting and Core Motivation
Lip Forcing addresses audio-driven video-to-video (V2V) lip synchronization: given a source talking-head video and target audio, synthesize a video that preserves identity, pose, and background while making the mouth motion match the audio. The paper argues that recent diffusion-based lip-sync models improve perceptual quality and audio-visual alignment, but remain too expensive for real-time use because they typically rely on full-sequence bidirectional attention and many denoising steps.
The key observation is that few-step distillation is not a generic drop-in solution for lip synchronization. The paper shows that the teacher’s denoising trajectory exhibits a CFG fidelity--sync tradeoff: classifier-free guidance (CFG) improves audio-visual synchronization but hurts reference fidelity, while no-CFG sampling better preserves the source video appearance and mouth-region detail. Lip Forcing turns this trajectory-level behavior into a distillation recipe that yields a causal streaming student with only two denoising calls per chunk at inference and no inference-time CFG.

High-Level Contribution
The paper’s central contribution is an analysis-driven distillation framework that compresses a 14B bidirectional video diffusion teacher into causal autoregressive students. The authors claim this is the first autoregressive diffusion method for V2V lip synchronization. The resulting system, Lip Forcing, is designed specifically for streaming deployment and is validated at two student scales: 1.3B and 14B.
The method has three analysis-derived components:
- Sync-Window DMD: apply CFG only in a teacher guidance window where it helps synchronization most.
- Two-step inference schedule: denoise each chunk in exactly two model calls, landing the second step at a trajectory point chosen by analysis.
- SyncNet-based reward: reweight the DMD generator gradient using a lip-sync confidence score computed by SyncNet on the student’s decoded output.
The paper’s central empirical claim is that these pieces together allow real-time streaming with strong fidelity at 1.3B, and very large-scale diffusion lip syncing at 14B with a substantial speedup over its teacher.
Teacher, Student, and Streaming Formulation
The teacher is a 14B lip-sync finetune of OmniAvatar, referred to in the paper as OmniAvatar-LS. It is a video diffusion transformer adapted from the Wan 2.1 backbone, with audio injected through an Audio Pack module. For lip synchronization, the input is recast as an inpainting problem over a lip-region mask: pixels inside the mouth/lower-face region are regenerated while the rest of the frame is treated as fixed context.
The student is causal and autoregressive. Instead of full-sequence bidirectional attention, it generates chunks sequentially conditioned only on previously generated clean outputs, cached keys/values, and the audio conditioning. The paper uses a rolling cache with a sink frame plus a short temporal window, and it applies dynamic RoPE so that cache-slot positions stay consistent as the rollout extends.
In the paper’s streaming setup, each chunk contains three latent frames. The first chunk produces nine pixel frames after decoding, and subsequent chunks produce twelve. The cache consists of a one-frame sink plus a six-frame rolling window, for a total of seven latent frames. This keeps memory bounded regardless of rollout length.
Rectified Flow and DMD Preliminaries
The method builds on rectified flow. Given clean data $x_0$ and noise $\epsilon$, the interpolation is
$$x_t = (1-t)x_0 + t\epsilon,$$
with $t\in[0,1]$ where $t=1$ is noise and $t=0$ is data. The model predicts a velocity field that supports deterministic backward updates. A direct estimate of the clean sample is
$$\hat{x}_0 = x_t - t\,v_\theta(x_t,t).$$
For distillation, the paper adopts Self Forcing on top of Distribution Matching Distillation (DMD). The student’s clean prediction is re-noised and compared to a frozen teacher score and a learned fake-score network. The teacher score uses CFG:
$$S^{\mathrm{CFG}}_{\mathrm{real}}(x_t,t,c;s)=S_{\mathrm{real}}(x_t,t,\emptyset)+s\big(S_{\mathrm{real}}(x_t,t,c)-S_{\mathrm{real}}(x_t,t,\emptyset)\big),$$
where $s=1.0$ means no-CFG and $s>1$ means CFG-guided sampling.
Teacher Trajectory Analysis
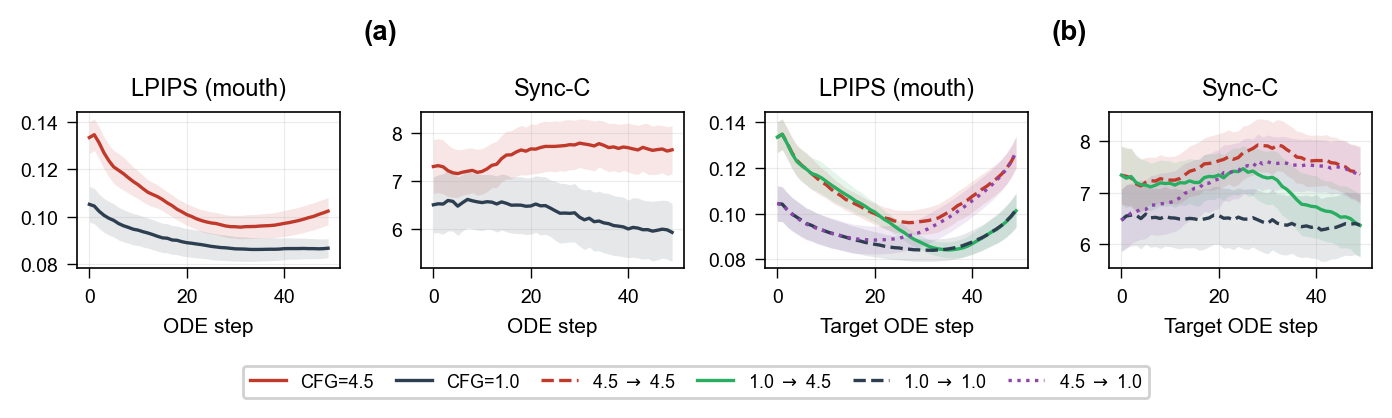
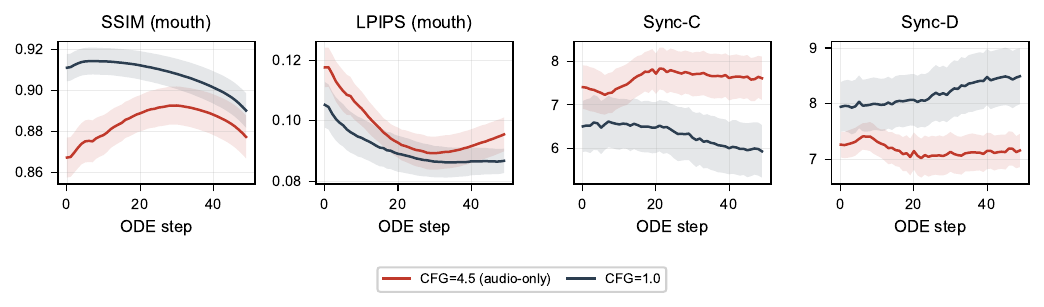
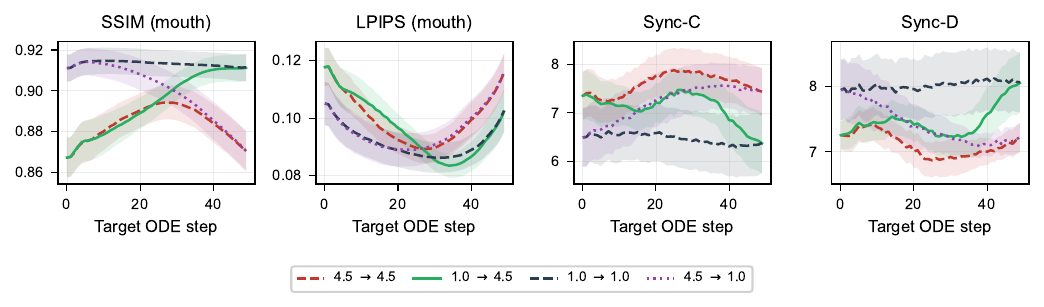
A central empirical section analyzes the 14B teacher on 10 held-out Hallo3 clips. The authors save per-step predictions across the 50-step shifted ODE schedule and evaluate mouth-region LPIPS for reference fidelity and SyncNet Sync-C for synchronization. This analysis is the basis for every major design choice in the method.
The first finding is the CFG fidelity--sync tradeoff: CFG improves Sync-C but worsens mouth-region LPIPS, while no-CFG preserves fidelity better but yields weaker synchronization. The paper also notes that even a one-step prediction preserves coarse facial structure and approximate mouth timing, indicating that strong lip-sync conditioning makes the task amenable to aggressive few-step compression.
The second finding comes from an Euler-step factorial study over two teacher calls. The authors vary the guidance scales for the first and second steps, $s_0$ and $s_1$, and sweep the landing step of the second call. They find that a mixed schedule, specifically no-CFG at the first call and CFG at the second call, yields the best compromise near step 30. A plateau around landing steps $j_1\in[25,32]$ is reported in the appendix, and the paper chooses $j_1=30$ as the representative operating point.
The shifted teacher schedule uses 50 inference steps over nodes $\tau_j$, with the mapping concentrated at high noise. Representative checkpoints include $\tau_{20}=0.882$, $\tau_{30}=0.769$, and $\tau_{40}=0.555$. The two-step student schedule is chosen as $J_{LF}=(0,30)$.

Method Details
Sync-Window DMD
Standard DMD uses a fixed teacher CFG scale across all re-noising timesteps. Lip Forcing replaces this with a timestep-gated guidance schedule. If the sampled DMD timestep corresponds to ODE index $j$, then the teacher uses CFG scale $4.5$ only for $20\leq j\leq 40$ and uses $1.0$ elsewhere:
$$s_{\mathrm{SW}}(j)=\begin{cases}4.5,&20\leq j\leq 40,\\1.0,&\text{otherwise}.\end{cases}$$
This window is chosen to match the analysis-derived sync-favoring band. The paper emphasizes that this is a training-time schedule only; the deployed student does not use CFG at inference. The guiding idea is to preserve reference fidelity where guidance is harmful, while still exploiting CFG in the trajectory band where it most improves lip articulation.
Two-Step Inference Schedule
At inference, the student uses exactly two denoising model calls per chunk, with $J_{LF}=(0,30)$. The first call denoises near-pure noise; the second call lands at the analysis-derived step and then projects to the clean latent using the rectified-flow clean estimate. There is no inference-time CFG. The paper frames step 30 as a deliberate fidelity-leaning choice: earlier landings improve sync, while later landings improve fidelity, and the chosen point balances the two once the reward term is added.
SyncNet-Based Reward
Because the windowed schedule leaves a residual sync gap relative to the full CFG teacher, the authors add an explicit reward based on SyncNet confidence between the conditioning audio and the student’s decoded prediction. The reward weight is
$$w(\hat{x}_0)=\exp\big(\beta\,R(D(\hat{x}_0),\mathbf{a})\big),$$
with $\beta=2$, where $D$ is the Tiny AutoEncoder decoder and $R$ is SyncNet confidence. The weight is forward-only: gradients flow through the DMD objective but not through SyncNet or the decoder. The paper notes that this follows the Re-DMD style of reward-weighted generator gradients, but replaces the video-dynamics reward with explicit lip-sync supervision.
Teacher and Student Training Pipeline
The training pipeline has two stages. First, the causal student is pretrained with Diffusion Forcing on real data, where each chunk is independently noised at a sampled timestep and trained with rectified-flow matching. This stage provides a clean conditional initialization before distillation. Second, the student is distilled with Self Forcing DMD using the analysis-derived recipe.
The teacher and student share the same data pipeline. Training uses a mixture of VoxCeleb2, Hallo3, and HDTF. VoxCeleb2 contributes large-scale in-the-wild AV diversity; HDTF adds high-resolution talking faces with clean audio; Hallo3 adds dynamic backgrounds and varied camera viewpoints. The final filtered pool contains approximately 30K clips.
Preprocessing follows a face-alignment pipeline: videos are resampled to 25 fps, audio to 16 kHz, shot boundaries split clips into 5--10 second segments, and faces are aligned with InsightFace to a canonical pose at $512\times512$ resolution. Clips with SyncNet confidence below 3 or HyperIQA below 40 are removed, and the audio-visual offset is adjusted to zero for the remaining clips.
Each training sample uses an 81-frame window, which corresponds to about 3.24 seconds at 25 fps. The reference frame is sampled uniformly from the source clip and broadcast across time; a separate reference frame sequence is sampled outside the input window when possible, providing additional identity and motion priors.
Teacher finetuning uses LoRA on attention and feed-forward layers, with all other parameters frozen. The main training hyperparameters reported in the appendix are: AdamW with weight decay 0.01, gradient clipping at 10.0, mixed precision in bf16, and 4 NVIDIA H200 GPUs for the main runs. Stage 1 runs for 5K steps at learning rate $10^{-5}$ with 1K-step warmup. Stage 2 runs for 600 steps at learning rate $2\times10^{-6}$, with student-to-fake-score update ratio 5:1. The paper reports total project compute of about 3,800 H200-hours including preliminary experiments.
Experimental Setup
The main evaluation uses the HDTF test set of 33 clips. Metrics include FID, SSIM, FVD, CSIM, Sync-C, Sync-D, FPS, and time-to-first-frame (TTFF). The system is evaluated at two student scales: 1.3B and 14B. Inference and throughput are measured on a single NVIDIA H100 GPU. For latency, the authors measure from the first VAE encode through the end of the first chunk’s last VAE decode.
The paper also reports additional evaluations on Hallo3, TalkVid, long HDTF videos up to 6 minutes, and cross-identity audio drive on HDTF. A MOS user study compares Lip Forcing against six baselines on four axes: synchronization, video quality, identity preservation, and naturalness.
Main Quantitative Results
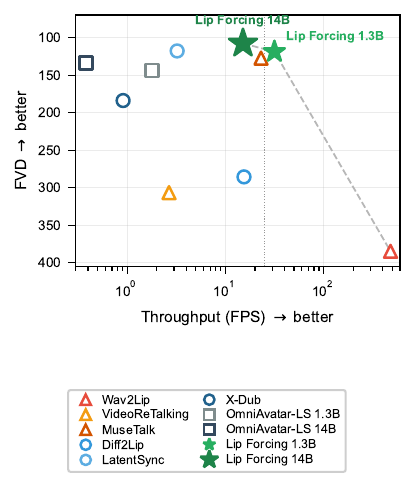
The headline result is that the 1.3B student crosses into real-time streaming at 31.58 FPS with 0.32 ms TTFF, while the 14B student achieves strong quality and remains 39.8× faster than its teacher at comparable reference fidelity. The 1.3B student is 17.6× faster than the same-scale OmniAvatar-LS baseline. The 14B student also becomes the largest diffusion model reported for V2V lip synchronization in the paper.
On HDTF, Lip Forcing deliberately sits on the reference-leaning side of the sync-fidelity tradeoff: it improves FID, FVD, and identity preservation strongly, while leaving some Sync-C on the table relative to the strongest sync-leaning methods. The user study suggests this perceived sync deficit is smaller than the metric gap implies.
| Method | Steps | FPS | TTFF (ms) | Sync-C | Sync-D | CSIM | FID | FVD | SSIM |
|---|---|---|---|---|---|---|---|---|---|
| Ground truth | -- | -- | -- | 7.95 | 6.92 | -- | -- | -- | -- |
| Wav2Lip | -- | 479.60 | 0.17 | 8.56 | 6.70 | 0.946 | 24.15 | 384.82 | 0.911 |
| VideoReTalking | -- | 2.67 | 3.76 | 8.22 | 6.70 | 0.910 | 24.59 | 306.63 | 0.883 |
| MuseTalk | 1 | 23.07 | 2.72 | 7.94 | 6.95 | 0.957 | 9.68 | 127.44 | 0.943 |
| Diff2Lip | 25 | 15.47 | 5.04 | 8.35 | 6.32 | 0.943 | 20.32 | 285.69 | 0.907 |
| LatentSync | 20 | 3.23 | 6.29 | 8.10 | 6.51 | 0.967 | 6.90 | 117.91 | 0.950 |
| X-Dub | 30 | 0.91 | 163.64 | 7.58 | 7.66 | 0.898 | 14.76 | 183.99 | 0.831 |
| OmniAvatar-LS (1.3B) | 50 | 1.79 | 45.36 | 8.04 | 6.99 | 0.927 | 8.06 | 143.75 | 0.904 |
| OmniAvatar-LS (14B) | 50 | 0.38 | 213.72 | 8.98 | 6.11 | 0.934 | 6.71 | 133.87 | 0.911 |
| Self Forcing (1.3B) | 4 | 27.48 | 0.38 | 7.12 | 7.80 | 0.939 | 7.51 | 124.78 | 0.915 |
| Lip Forcing (1.3B) | 2 | 31.58 | 0.32 | 6.88 | 7.93 | 0.943 | 6.76 | 118.86 | 0.919 |
| Lip Forcing (14B) | 2 | 15.11 | 0.54 | 7.59 | 7.23 | 0.949 | 7.01 | 107.88 | 0.938 |
The strongest direct speed comparison is against same-scale bidirectional models: the 1.3B student is 17.6× faster than OmniAvatar-LS (1.3B), and the 14B student is 39.8× faster than OmniAvatar-LS (14B). The paper also reports that the 14B student is 4.7× faster than LatentSync at comparable reference fidelity.
Ablations and Design Validation
The ablations isolate the contributions of the CFG schedule, the reward, the landing step, and the number of denoising steps. The broad pattern is that windowing CFG improves fidelity metrics relative to static CFG, while the SyncNet reward recovers some synchronization. More steps improve FVD, but the proposed two-step operating point captures most of the gain at a lower inference cost.
| Schedule | Sync-C | Sync-D | FVD | SSIM |
|---|---|---|---|---|
| all-CFG | 7.13 | 7.85 | 138.32 | 0.916 |
| no-CFG | 6.14 | 8.39 | 120.85 | 0.921 |
| windowed | 6.81 | 7.85 | 119.88 | 0.920 |
| reverse | 6.98 | 7.81 | 126.62 | 0.917 |
| Config. | Sync-C | Sync-D | FVD | SSIM |
|---|---|---|---|---|
| static | 7.13 | 7.85 | 138.32 | 0.916 |
| static + R | 7.24 | 7.76 | 135.94 | 0.917 |
| windowed | 6.81 | 7.85 | 119.88 | 0.920 |
| windowed + R | 6.88 | 7.93 | 118.86 | 0.919 |
| # of Steps | Sync-C | Sync-D | FVD | SSIM |
|---|---|---|---|---|
| 1 | 6.81 | 7.92 | 131.50 | 0.926 |
| 2 (uniform, $j_1=25$) | 6.95 | 7.85 | 124.57 | 0.926 |
| 2 (ours, $j_1=30$) | 6.81 | 7.85 | 119.88 | 0.920 |
| 4 | 6.81 | 8.01 | 117.80 | 0.923 |
| $j_1$ | Sync-C | Sync-D | FVD | SSIM |
|---|---|---|---|---|
| 13 | 6.79 | 7.92 | 135.22 | 0.927 |
| 25 | 6.95 | 7.85 | 124.57 | 0.926 |
| 30 | 6.81 | 7.85 | 119.88 | 0.920 |
| 37 | 6.73 | 7.87 | 114.78 | 0.920 |
The ablations support the paper’s interpretation of the trajectory analysis. Static CFG gives the strongest synchronization among the configurations shown, but windowed CFG greatly improves FVD and SSIM. The reward mostly helps Sync-C and Sync-D, while the two-step landing at $j_1=30$ is chosen as a balanced point inside the plateau rather than the most sync-leaning point.
Additional Benchmarks
The appendix reports results on Hallo3, TalkVid, long-form HDTF, and cross-identity audio. These tests probe different aspects of generalization beyond the main HDTF setting.
Hallo3
| Method | FVD | FID | SSIM | CSIM | Sync-D | Sync-C |
|---|---|---|---|---|---|---|
| Wav2Lip | 271.55 | 19.70 | 0.9262 | 0.9411 | 6.60 | 8.70 |
| VideoReTalking | 190.21 | 21.36 | 0.9011 | 0.8996 | 6.94 | 7.83 |
| MuseTalk | 136.16 | 8.88 | 0.9317 | 0.9234 | 8.38 | 6.17 |
| Diff2Lip | 178.64 | 20.11 | 0.9217 | 0.9321 | 6.22 | 8.26 |
| LatentSync | 109.21 | 6.84 | 0.9443 | 0.9424 | 6.71 | 8.38 |
| X-Dub | 199.85 | 13.67 | 0.8518 | 0.8792 | 7.79 | 7.47 |
| Lip Forcing (1.3B) | 101.25 | 7.83 | 0.9321 | 0.9300 | 8.78 | 5.96 |
| Lip Forcing (14B) | 87.85 | 7.12 | 0.9482 | 0.9464 | 8.23 | 6.58 |
On Hallo3, the 14B student achieves the best FVD, FID, SSIM, and CSIM among the listed methods, but does not lead on Sync-C. The 1.3B model is still competitive on quality but weak on synchronization, consistent with the main paper’s fidelity-leaning operating point.
TalkVid
| Method | FVD | FID | SSIM | CSIM | Sync-D | Sync-C |
|---|---|---|---|---|---|---|
| Wav2Lip | 382.64 | 50.28 | 0.7777 | 0.9553 | 7.14 | 8.11 |
| VideoReTalking | 318.22 | 54.61 | 0.7242 | 0.9301 | 7.20 | 7.74 |
| MuseTalk | 294.84 | 29.46 | 0.7312 | 0.9497 | 8.89 | 5.77 |
| Diff2Lip | 286.86 | 46.47 | 0.7689 | 0.9585 | 6.45 | 8.41 |
| LatentSync | 171.96 | 25.39 | 0.7928 | 0.9629 | 6.75 | 8.78 |
| X-Dub | 191.23 | 14.62 | 0.8202 | 0.9245 | 7.90 | 7.63 |
| Lip Forcing (1.3B) | 118.32 | 9.17 | 0.9095 | 0.9542 | 8.53 | 6.29 |
| Lip Forcing (14B) | 111.98 | 8.79 | 0.9300 | 0.9649 | 7.69 | 7.24 |
On TalkVid, the 14B model again leads on FVD, FID, SSIM, and CSIM, while synchronization remains below the sync-leaning baselines. This reinforces the paper’s thesis that the method prioritizes fidelity and identity while preserving acceptable lip alignment.
Long-form HDTF and Cross-Identity Audio
Long-video evaluation on HDTF shows that the causal AR rollout remains stable over horizons up to 6 minutes, well beyond the 81-frame training chunk. Cross-identity audio drive pairs source video with a different speaker’s audio and assesses whether the method follows the new audio while retaining source identity and visual quality. The paper reports that Lip Forcing maintains identity and stability under these harder conditions, though absolute synchronization drops relative to sync-focused baselines.


User Study
The MOS study uses a 30-clip pool drawn from HDTF and TalkVid, with four 5-point Likert scores: synchronization, video quality, identity preservation, and naturalness. Lip Forcing (14B) receives the best scores on quality, identity, and naturalness, and is second-best on synchronization.
| Method | Sync | Qual. | ID | Nat. |
|---|---|---|---|---|
| Wav2Lip | 3.43 | 2.60 | 3.32 | 2.75 |
| VideoReTalking | 3.49 | 3.00 | 3.43 | 3.21 |
| MuseTalk | 3.47 | 3.34 | 3.56 | 3.16 |
| Diff2Lip | 3.15 | 2.25 | 3.12 | 2.47 |
| LatentSync | 3.96 | 3.54 | 3.82 | 3.53 |
| X-Dub | 4.40 | 4.13 | 4.25 | 3.97 |
| Lip Forcing (14B) | 4.38 | 4.33 | 4.46 | 4.32 |
The authors interpret this as evidence that the model’s slight metric deficit in synchronization does not strongly hurt human perception when overall video quality and identity fidelity are high.
Interpretation of the Results
The paper’s experimental story is that trajectory-aware distillation can shift the speed-quality frontier for lip synchronization. The 1.3B student is the real-time streaming variant, while the 14B student preserves much of the teacher’s fidelity while gaining a substantial speedup. The method does not try to maximize SyncNet scores at any cost; instead, it deliberately operates at a reference-leaning point that better preserves the source video, which the authors argue is more suitable for practical streaming deployments such as live translation, virtual avatars, and interactive agents.
The appendix also reports that the CFG fidelity--sync tradeoff and the guidance-window structure persist under audio-only CFG-drop mode, supporting the claim that the analysis is not an artifact of a specific drop configuration.
Limitations
The paper is explicit about several limitations. First, the recipe assumes a teacher with a CFG fidelity--sync tradeoff and a sync-favoring trajectory band. If a future teacher does not exhibit this structure, the windowed schedule and landing choices would need to be re-derived. Second, the cutoffs are characterized on one OmniAvatar-based teacher lineage, so the paper does not claim that the same numbers transfer to other architectures without analysis. Third, the 1.3B student is fast enough for real-time streaming but trails the 14B model on fidelity, so applications prioritizing visual quality should prefer the larger model.
The SyncNet-based reward is also a known limitation: because some baselines can exceed ground-truth Sync-C, aggressive optimization of SyncNet may diverge from perceptual realism. The paper mitigates this with a capped reward strength $\beta=2$ and by balancing Sync-C against fidelity metrics, but leaves more principled alignment objectives for future work.
Broader Impact
The authors frame lip synchronization as a dual-use technology. Positive applications include accessibility, dubbing, film and game post-production, and human-computer interaction. At the same time, the same efficiency improvements can lower the cost of producing manipulated or misleading video. The paper recommends provenance signaling, watermarking, and user authentication, and notes that detector research will likely need to adapt to outputs from systems like Lip Forcing.
Bottom Line
Lip Forcing demonstrates that a lip-sync-specific analysis of teacher denoising trajectories can be converted into a practical distillation recipe for streaming video generation. The main takeaway is not merely fewer steps, but where to spend those steps and when to use guidance. By combining a guidance window, a carefully chosen two-step landing, and a SyncNet-weighted DMD objective, the method reaches real-time throughput at 1.3B and scales to a 14B causal student that substantially outpaces its teacher while retaining competitive fidelity and strong human-rated quality.