State Inertia Activation Steering
Overcoming State Inertia in Full-Duplex Spoken Language Models via Activation Steering
This paper identifies delayed internal state transitions in full-duplex spoken language models that cause missed user interruptions. It introduces activation steering to shift the model between speaking and listening modes, improving immediate comprehension during interruptions without additional training.
Links
Paper & demos
Code & resources
Impact
Abstract
Full-duplex spoken language models (FD-SLMs) enable seamless speech interaction by allowing models to listen and speak simultaneously, yet the internal mechanism by which they coordinate listening and speaking remains underexplored. We analyze the predictive behavior encoded in FD-SLM hidden representations and find that they exhibit stream-specific predictive patterns: during listening, they preferentially predict the incoming user stream, whereas during speaking, they preferentially predict the model output stream. Building on this observation, we show that FD-SLMs dynamically modulate their internal predictive focus between two states: a generative state aligned with model output generation and a perceptive state aligned with incoming user input. However, this modulation can lag behind abrupt changes in conversational context. During user interruptions, the model remains transiently biased toward the generative state before transitioning into the perceptive state, causing it to miss the beginning of the incoming input. We term this delayed internal transition state inertia. To quantify its downstream impact, we introduce the Zero-Buffer Benchmark (ZBB), a diagnostic benchmark for evaluating immediate interruption comprehension when user speech begins abruptly. We evaluate this setting using response correctness and initial-word occurrence rate (IWOR). Finally, we mitigate state inertia through activation steering with a perception vector, a training-free intervention with little additional computational overhead. Across multiple state-of-the-art FD-SLMs, activation steering substantially improves interruption handling; for example, on PersonaPlex, it improves correctness from 28% to 45% and IWOR from 40% to 72% without any fine-tuning.
Introduction and core problem
This paper studies a failure mode in full-duplex spoken language models (FD-SLMs): models that can listen to a user and speak at the same time, instead of alternating strictly between listen and speak phases. The motivating use cases are interruption handling, backchanneling, overlapping speech, and smoother turn-taking. The authors focus on the internal mechanism by which an FD-SLM decides whether to prioritize incoming user speech or its own outgoing speech at a given moment.
Their central empirical claim is that hidden representations in FD-SLMs are not generic contextual states. Instead, they exhibit stream-specific predictive focus: while the model is listening, intermediate hidden states tend to predict the user stream; while the model is speaking, the same kind of hidden states tend to predict the model output stream. From this, the paper argues that FD-SLMs dynamically alternate between two internal modes: a perceptive state aligned with incoming user input and a generative state aligned with model output generation.
The key failure mode is that this mode switching is not always immediate. When a user abruptly interrupts the model during its own speech, the hidden state can remain transiently biased toward the generative state before it transitions to the perceptive state. The authors call this delayed transition state inertia. In practice, it causes the model to miss the beginning of the interrupting utterance, which is especially damaging when the crucial semantic content appears in the first word.
Methodological lens: probing hidden-state predictions with logit lens
To study the internal dynamics, the authors adapt the logit lens idea. For a hidden representation $h^{(t)} \in \mathbb{R}^d$ at timestep $t$ and unembedding matrix $W_{\mathrm{unembed}} \in \mathbb{R}^{|V| \times d}$, they project the hidden state into vocabulary space and interpret token probabilities as
$$P(y \mid h^{(t)}) = \frac{\exp(w_y^\top h^{(t)})}{\sum_{v \in V} \exp(w_v^\top h^{(t)})}.$$
The decoded token is the argmax under this projected distribution. This is used diagnostically, not as a new training objective: the paper probes intermediate layers to see what the model appears to be predicting before the final output head.
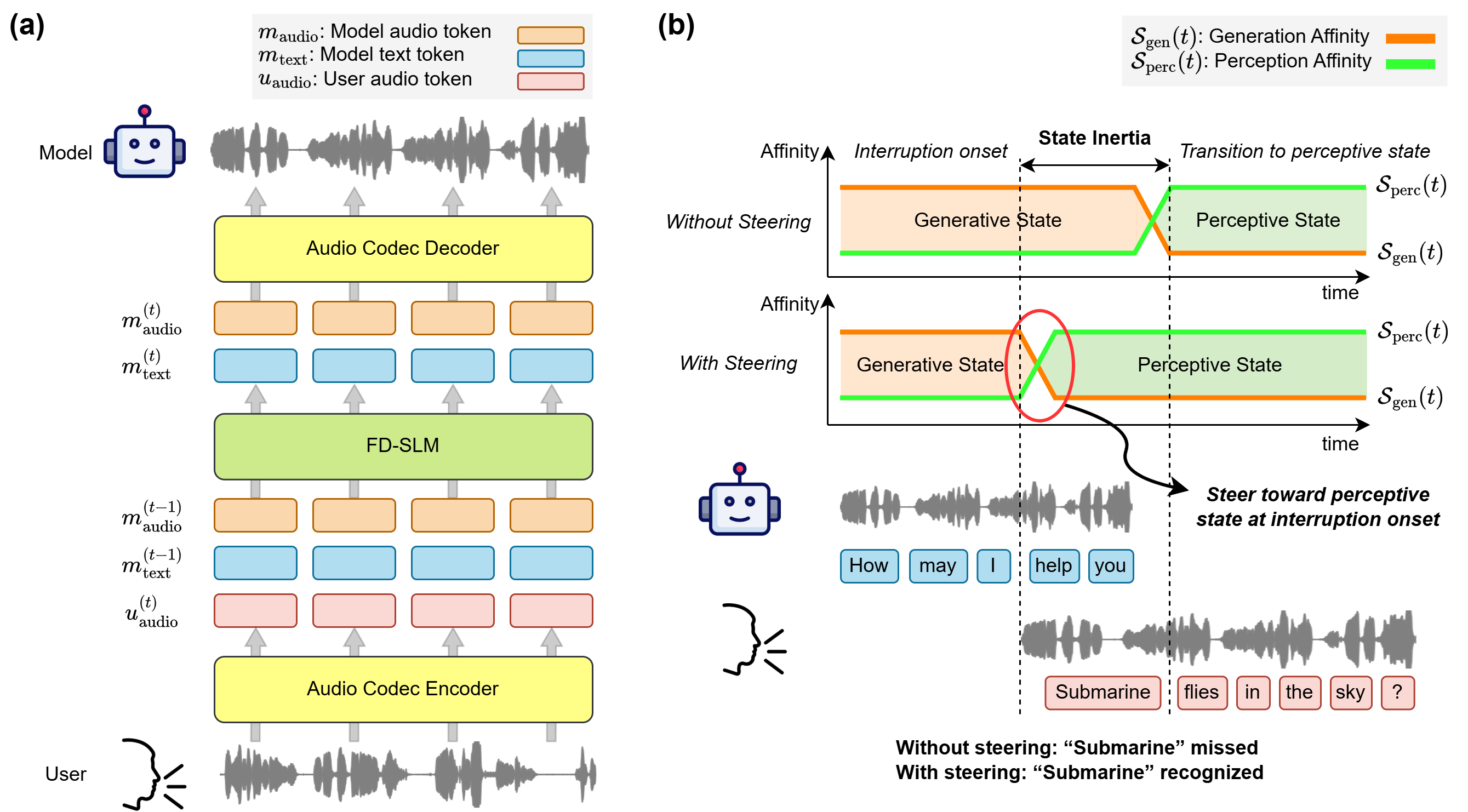
The FD-SLM setting matters here because the model is continuously conditioning on two streams: incoming user audio tokens $u^{(t)}_{\mathrm{audio}}$ and its own previously produced model audio and text tokens $m^{(t-1)}_{\mathrm{audio}}$, $m^{(t-1)}_{\mathrm{text}}$, plus dialogue context $c^{(t)}$. The paper emphasizes that timesteps, rather than individual tokens, are the relevant unit of analysis because FD-SLMs may emit multiple tokens per frame across parallel streams.
Finding 1: stream-specific predictive focus during listening and speaking
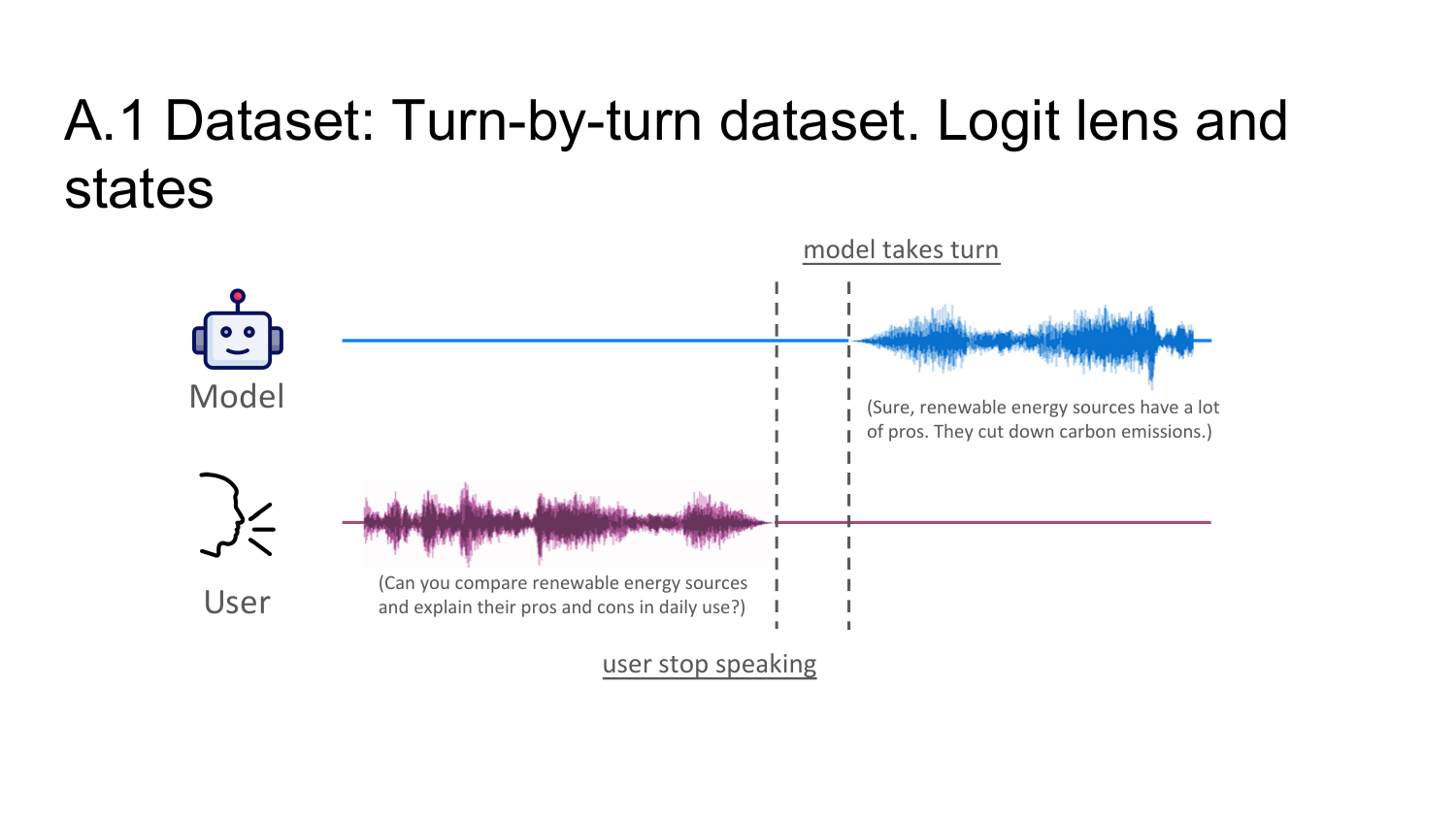
On a 100-example turn-by-turn interaction dataset, the authors qualitatively inspect logit-lens decodings from PersonaPlex. They find that while the user is speaking, hidden representations often anticipate upcoming user-side tokens rather than the model's eventual response tokens. During model speech, the behavior flips and the decoded tokens align more strongly with the model's own output stream.
The paper illustrates this with the example user query “Can you compare renewable energy sources and explain their pros and cons in daily use?” During the listening segment, intermediate layers decode tokens such as “why,” “how,” “own,” “pro,” “and,” and “cons,” which match or semantically anticipate the incoming user utterance. During the speaking segment, the decoded tokens track the output response instead. The authors interpret this as evidence that internal states are not static: they are role-conditioned and stream-specific.
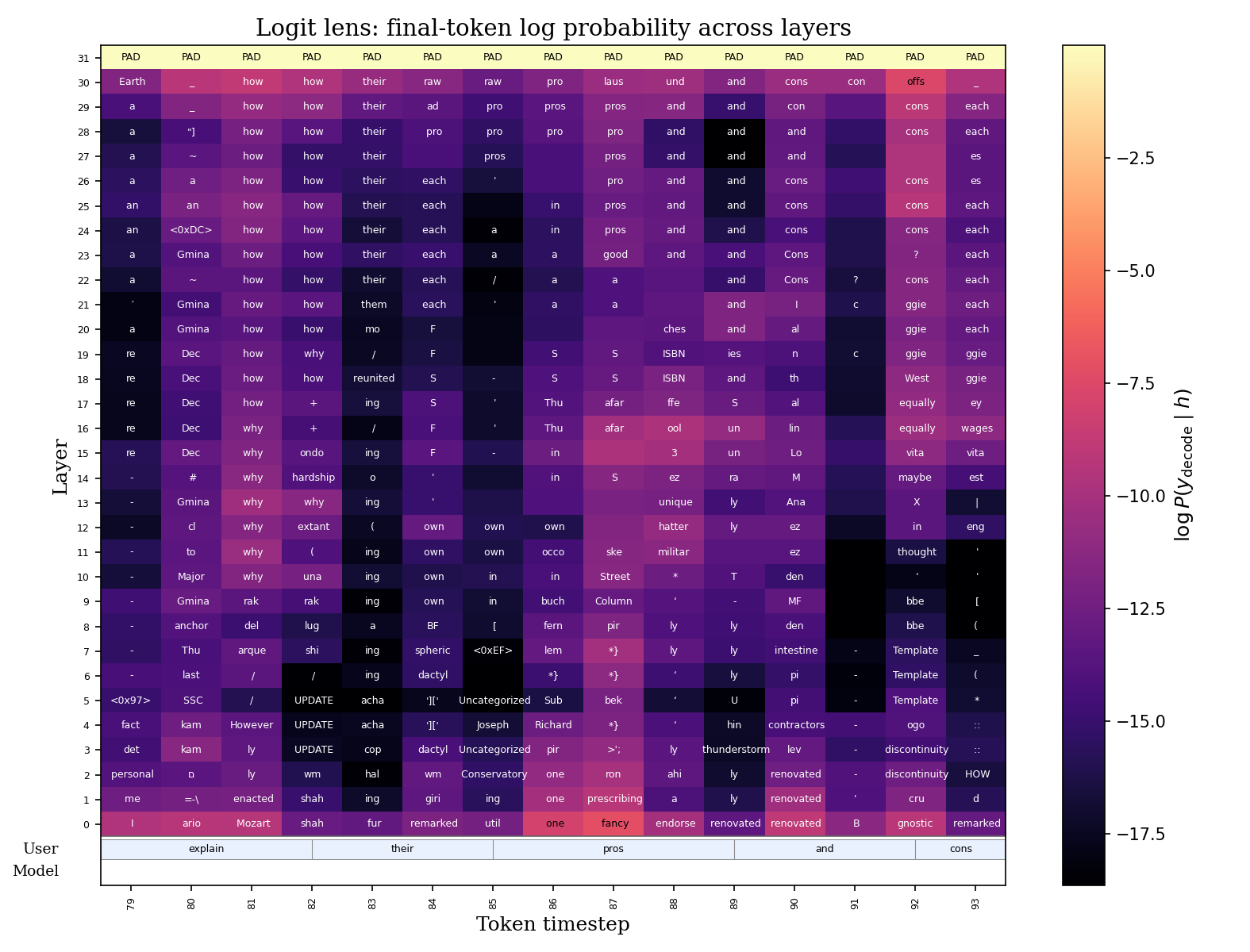
<PAD>. This suggests that the model internally tracks user-side content before converting this computation into a silent model-side output.
The appendix provides a second listening example with the user query “How does water treatment make tap water safe to drink in modern cities?” There, decoded tokens around “tap,” “water,” “safe,” and “to” anticipate semantically relevant continuations such as “water,” “quality,” “safe,” “safety,” and “drink.” The same appendix shows a complementary speaking example where the decoded tokens follow the model-side output stream more closely.
Generation and perception affinities: defining generative and perceptive states
To quantify the stream-specific tendency, the authors define two scalar affinities at each timestep. Generation affinity is the mean projected probability assigned to the model's own output text and audio tokens:
$$\mathcal{S}_{\text{gen}}(t) = \frac{1}{2}\left(P(m^{(t)}_{\mathrm{audio}} \mid h^{(t)}) + P(m^{(t)}_{\mathrm{text}} \mid h^{(t)})\right).$$
High generation affinity indicates a generative state. Perception affinity is the projected probability assigned to the next incoming user audio token:
$$\mathcal{S}_{\text{perc}}(t) = P(u^{(t+1)}_{\mathrm{audio}} \mid h^{(t)}).$$
High perception affinity indicates a perceptive state. For the affinity calculations, the paper uses the first audio codec codebook, because it primarily captures semantic information and avoids timing offsets associated with later residual codebooks.
The authors average these scores over 100 examples and align them by setting $t=0$ at the end of the user utterance. On PersonaPlex, the resulting trajectories show that perception affinity is high while the user is speaking and then decays after the user stops, while generation affinity rises after the transition, reflecting a shift into the model's speaking role.
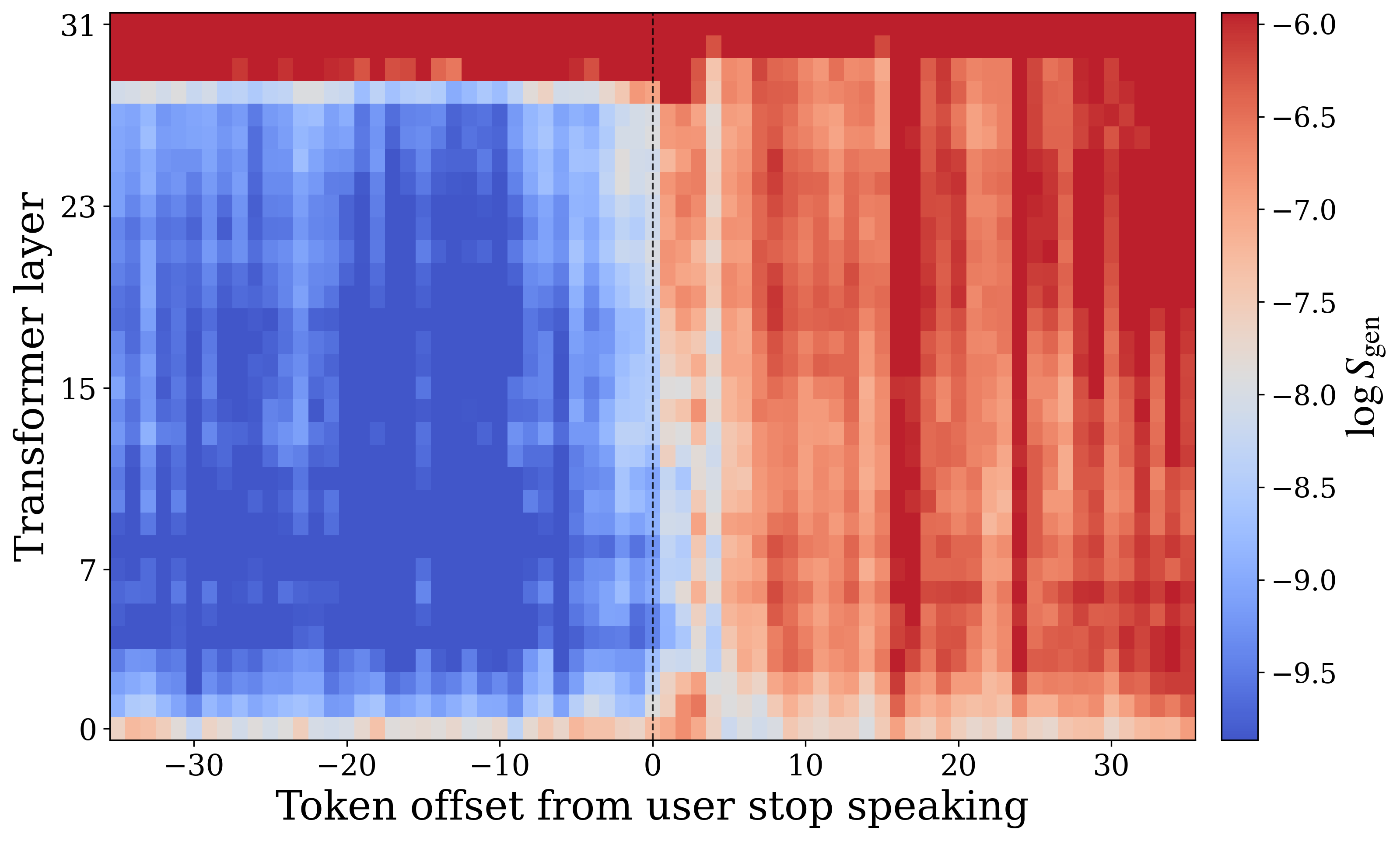
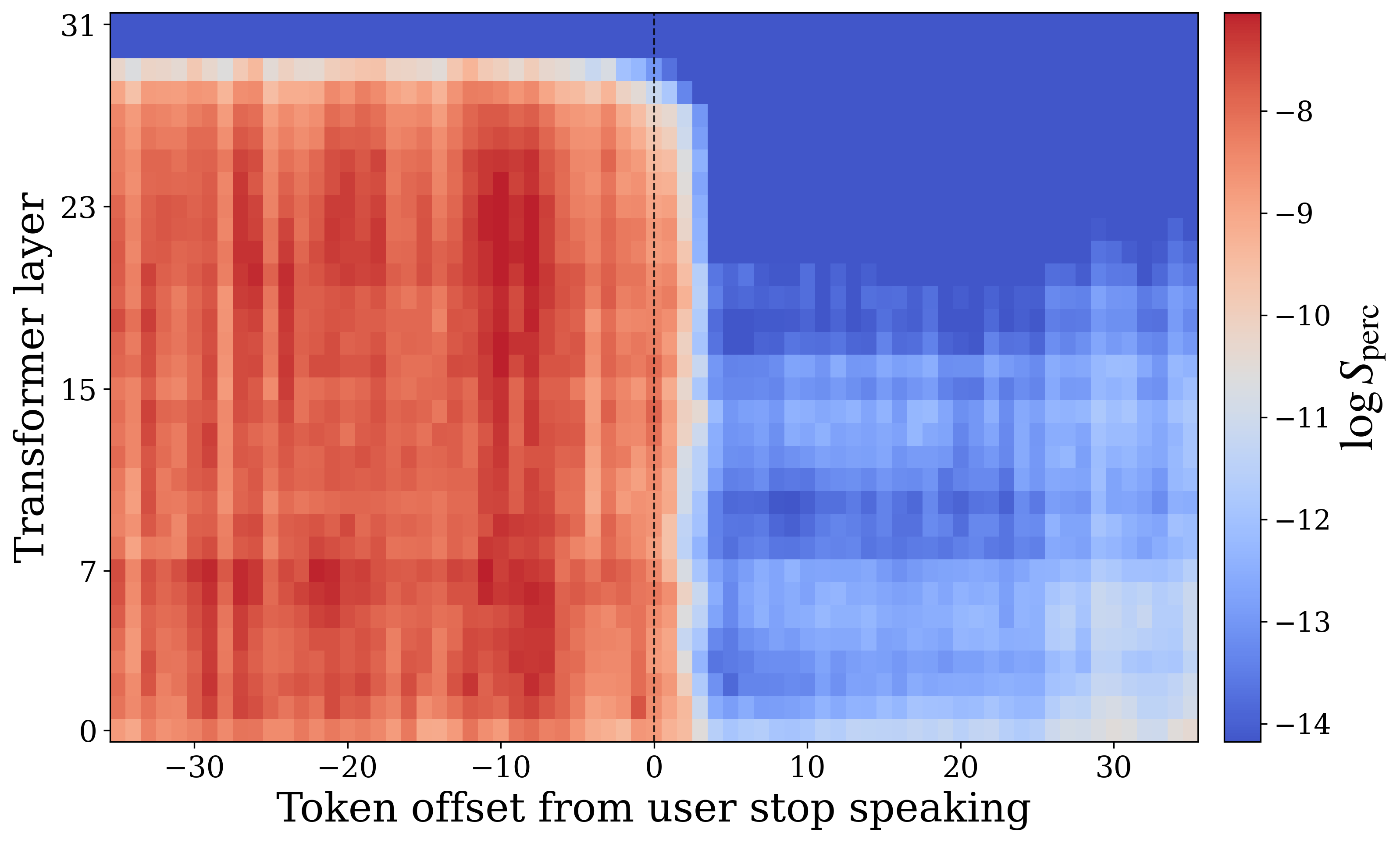
A subtle but important caveat from the paper is that the final layers behave differently from intermediate layers: the last layers remain more generation-biased even while the user is speaking. The authors attribute this to the fact that final layers sit closest to the output distribution and must still emit a model token at every timestep, often silence-like tokens while the user speaks.
Finding 2: FD-SLMs switch between perceptive and generative states
The affinity trajectories support the interpretation that FD-SLMs dynamically modulate between two internal states rather than maintaining a single homogeneous representation. During user listening, the perceptive state dominates; after the end of the user utterance, the generative state rises as the model prepares to respond. This is the main mechanistic story of the paper: the internal representation itself appears to be organized around conversational role.
The paper frames this as a functional coordination mechanism for simultaneous listening and speaking, rather than as a static encoder-decoder split. In other words, the same model can lean toward understanding the user or toward producing its own response, and the hidden state acts as a switchable substrate for that role assignment.
Finding 3: state inertia under abrupt interruption
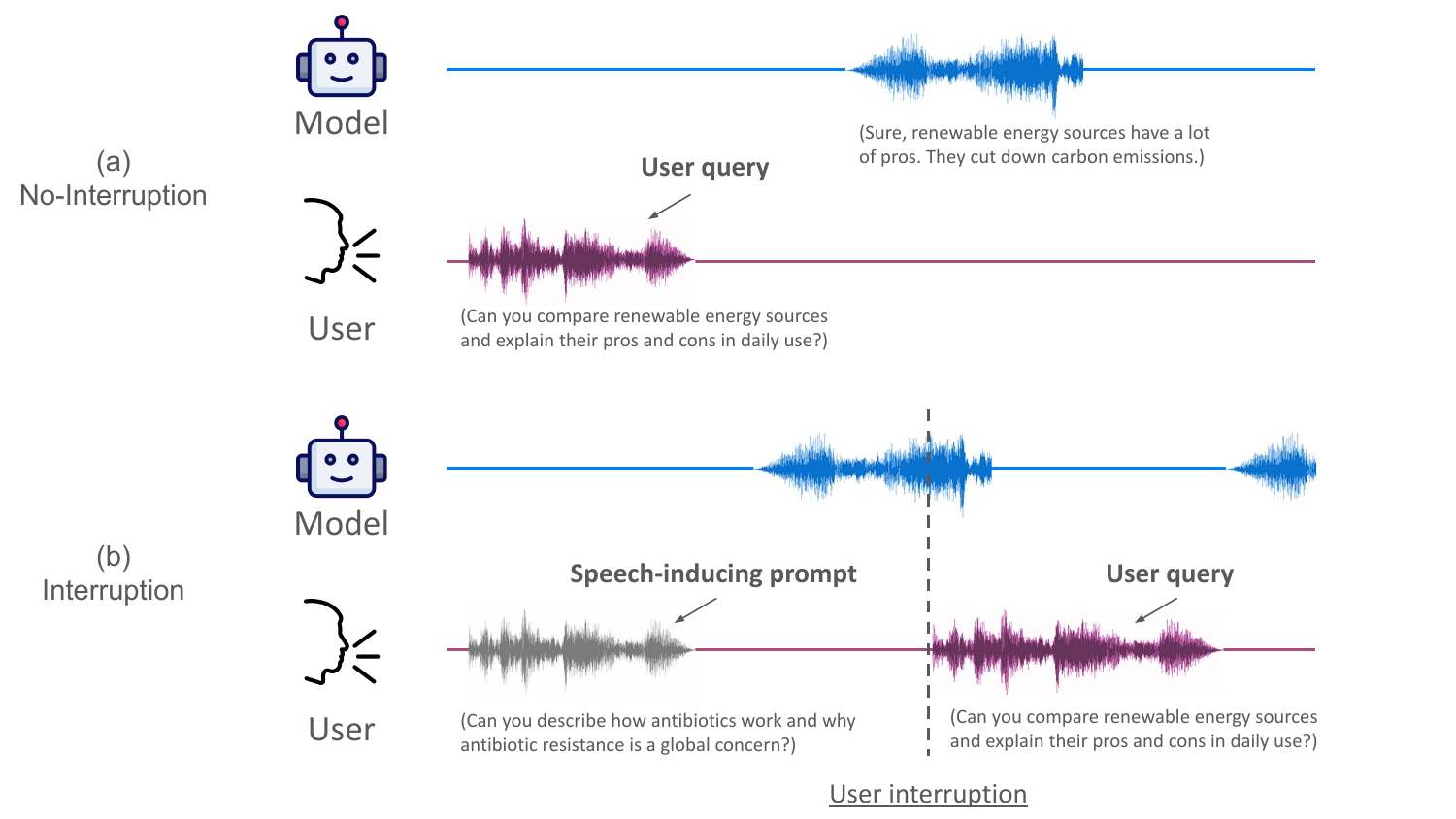
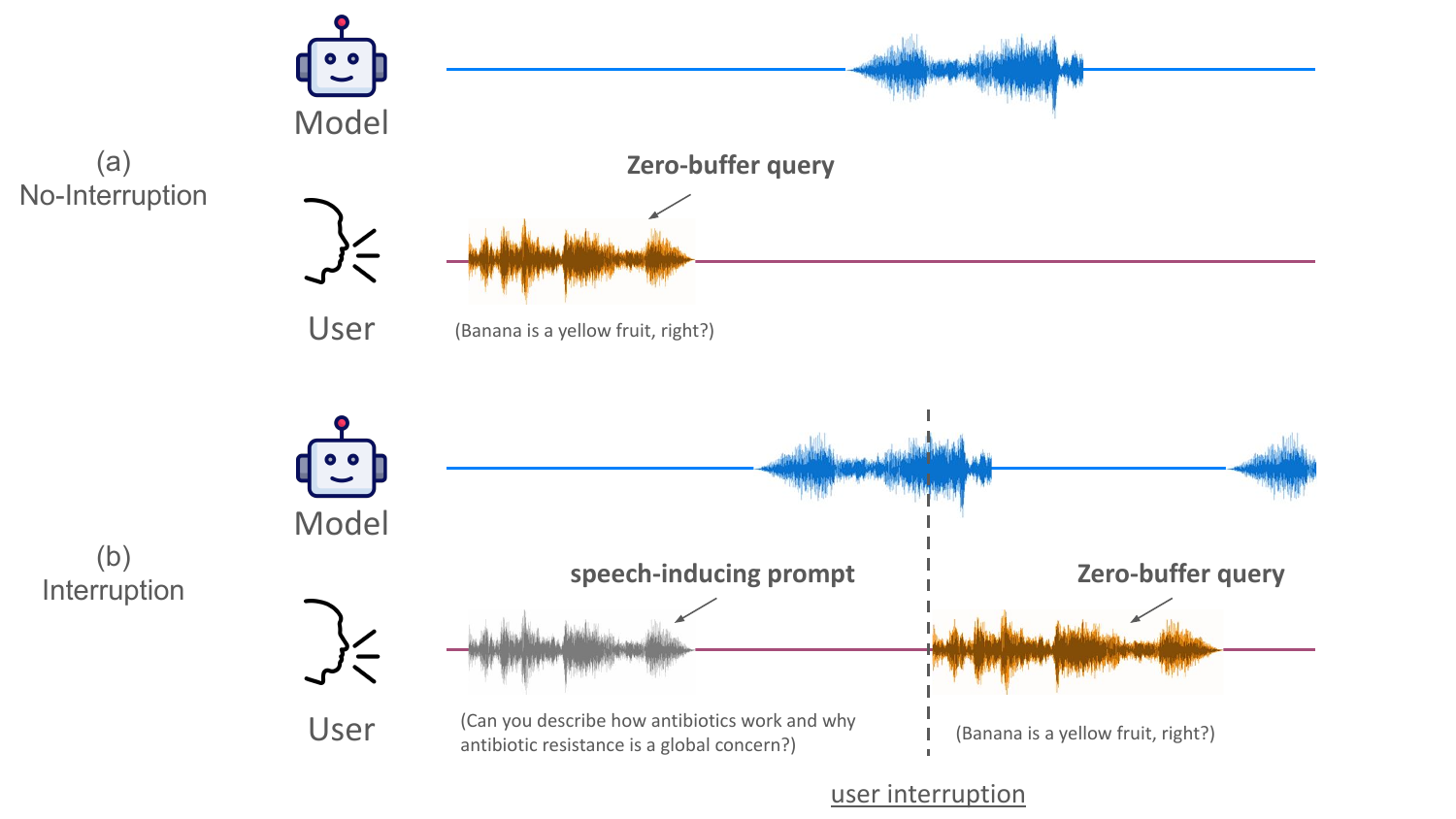
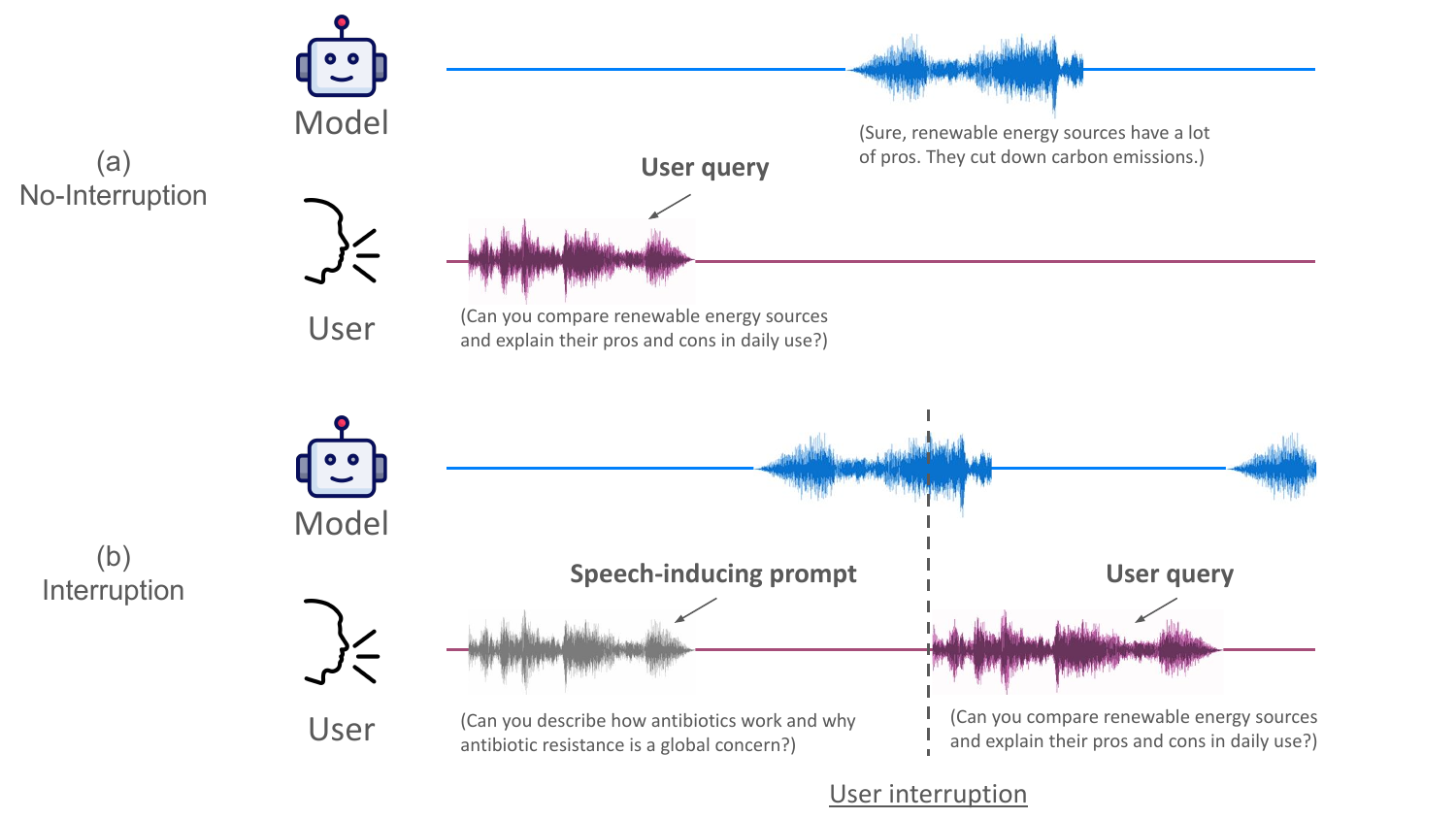
The most important failure case appears when the user interrupts the model mid-response. The authors compare two settings: no-interruption, where the same user utterance is presented without first inducing the model into a sustained speaking state, and interruption, where an open-ended speech-inducing prompt first drives the model into generation and is then abruptly followed by the user utterance.
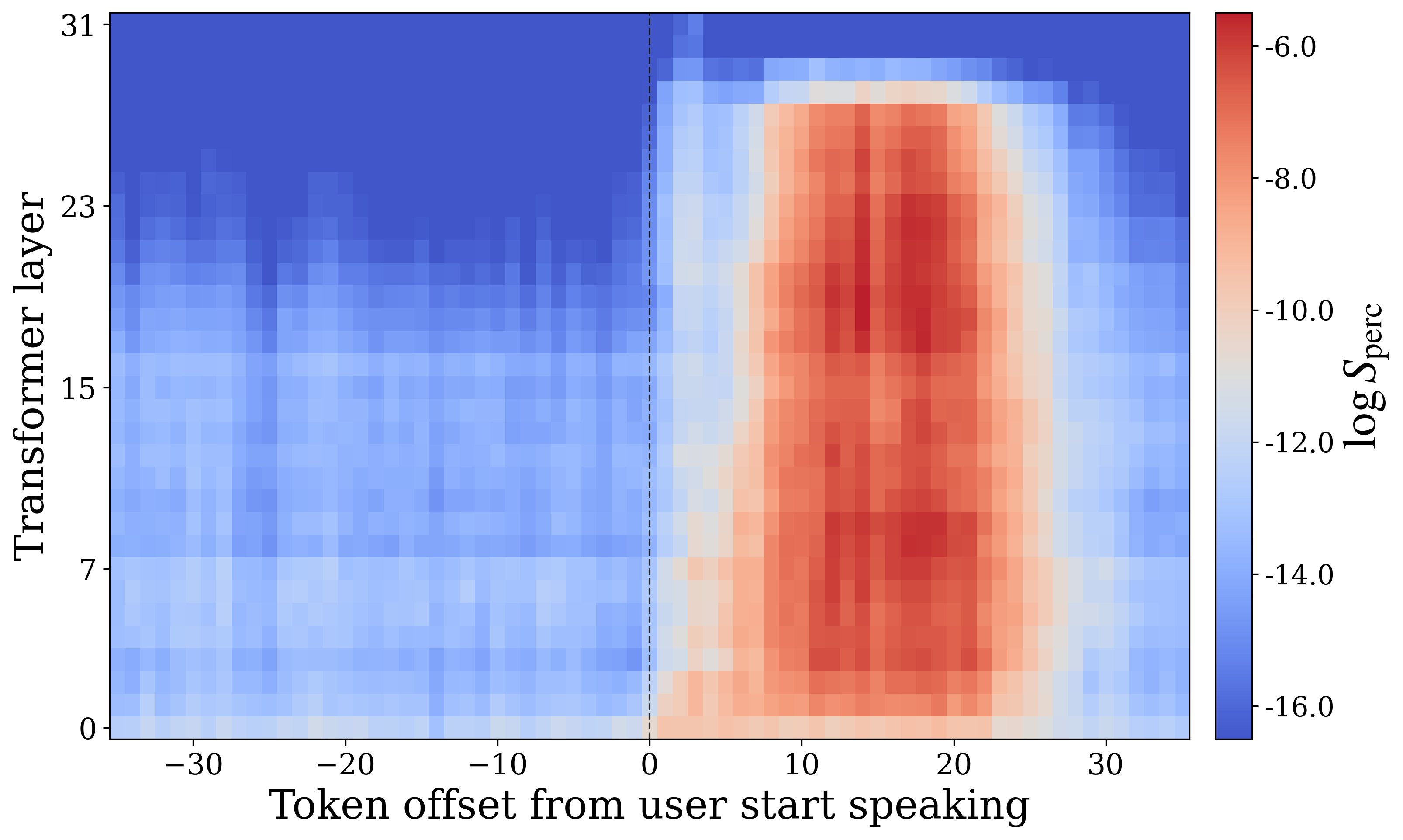
In the no-interruption setting, the model transitions into the perceptive state almost immediately when the user begins speaking. In the interruption setting, however, perception affinity remains low for roughly $7$--$8$ timesteps, corresponding to about $0.6$ seconds, before recovering. The appendices show a complementary phenomenon on the generative side: in the interruption condition, generation affinity can stay elevated for approximately $20$ timesteps, or nearly $2$ seconds, after the user begins speaking. The authors call this delayed internal transition state inertia.
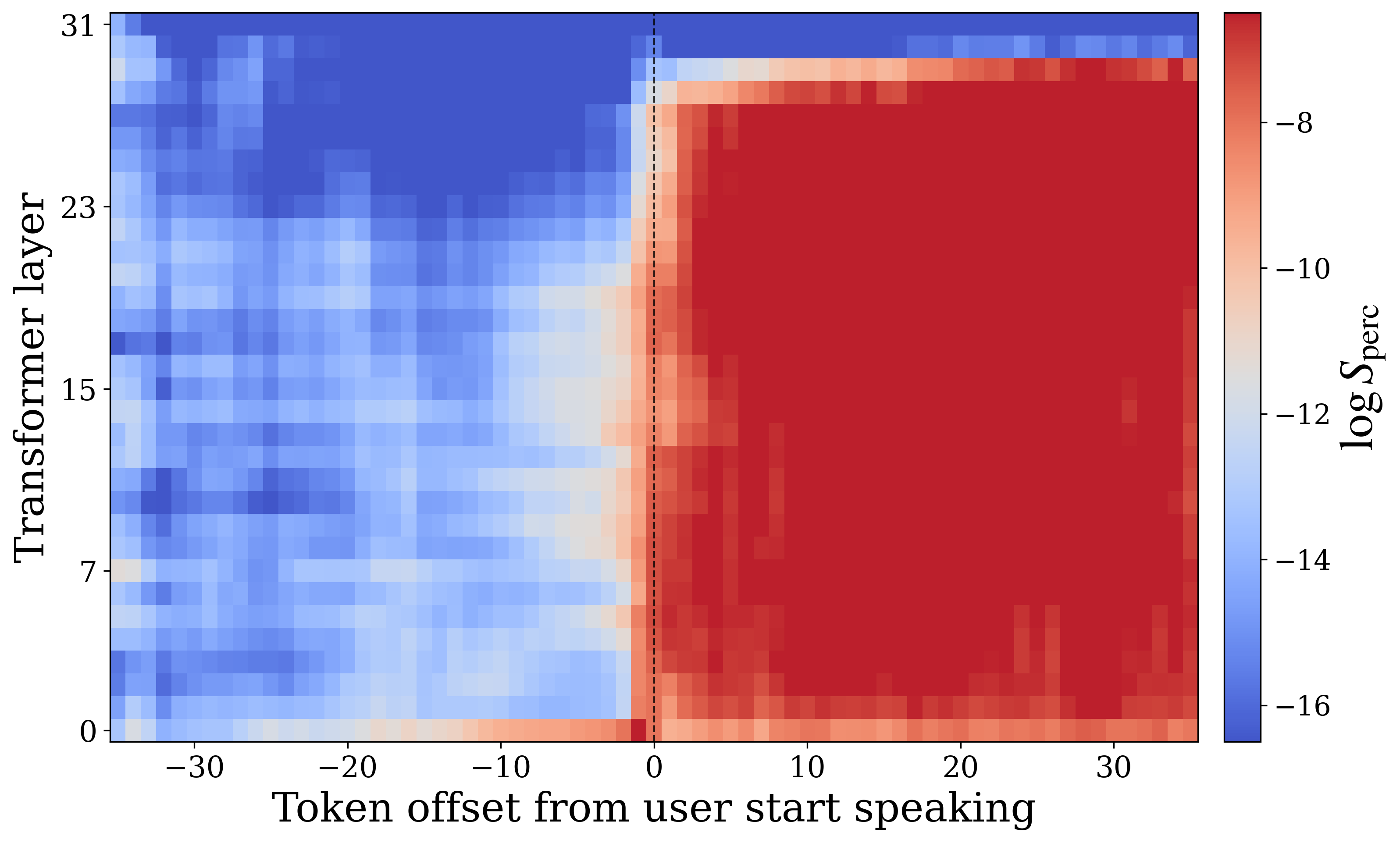
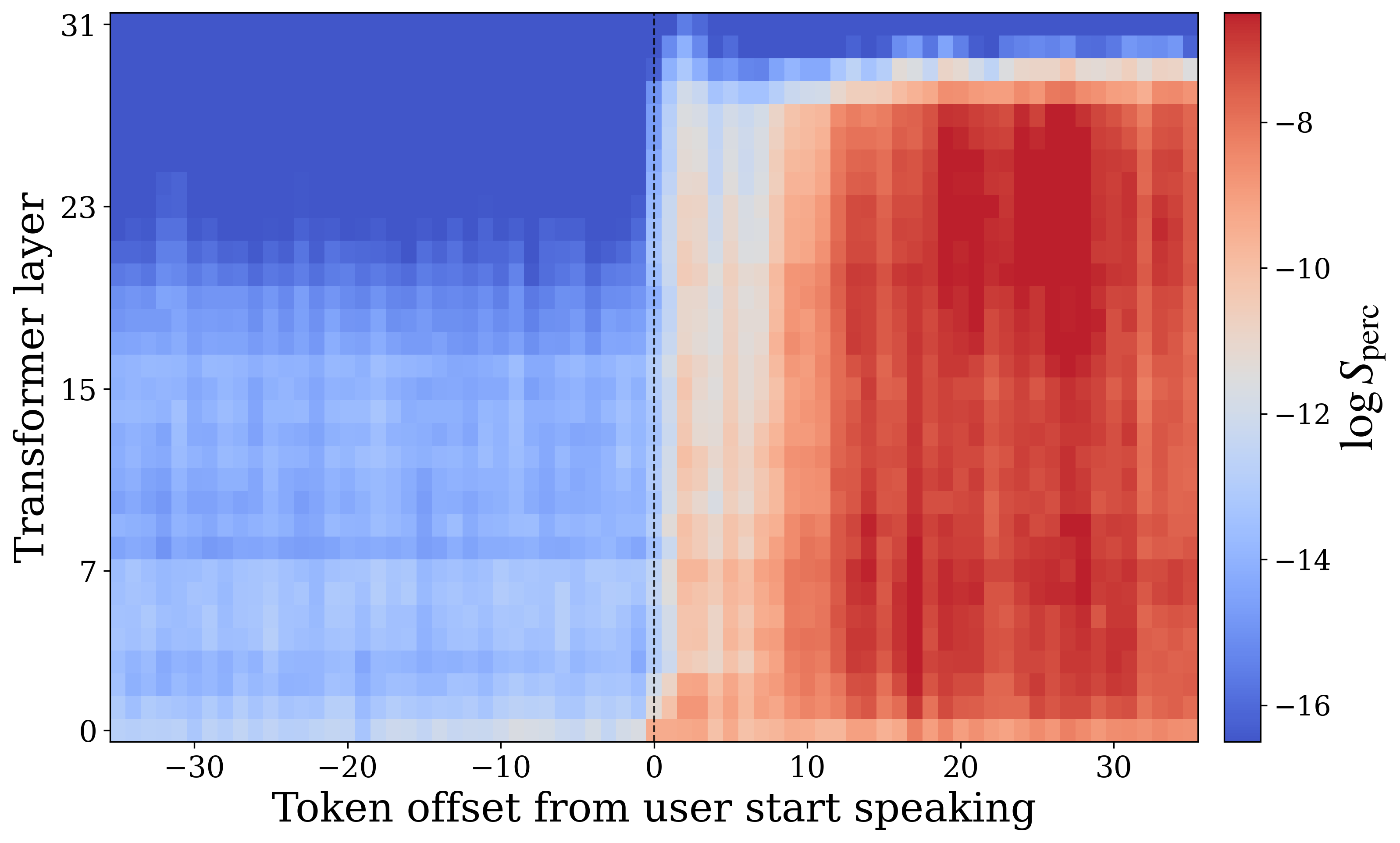
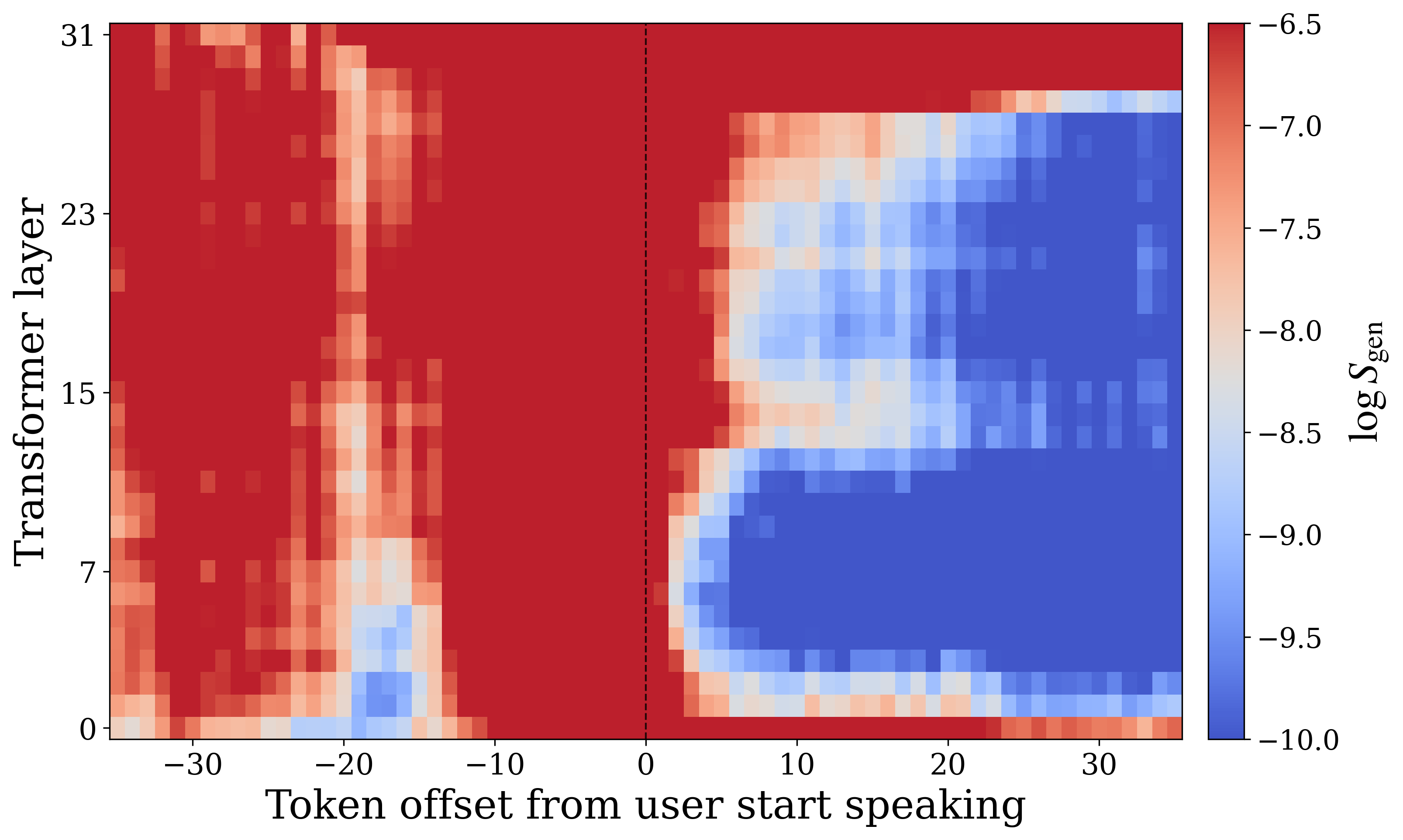
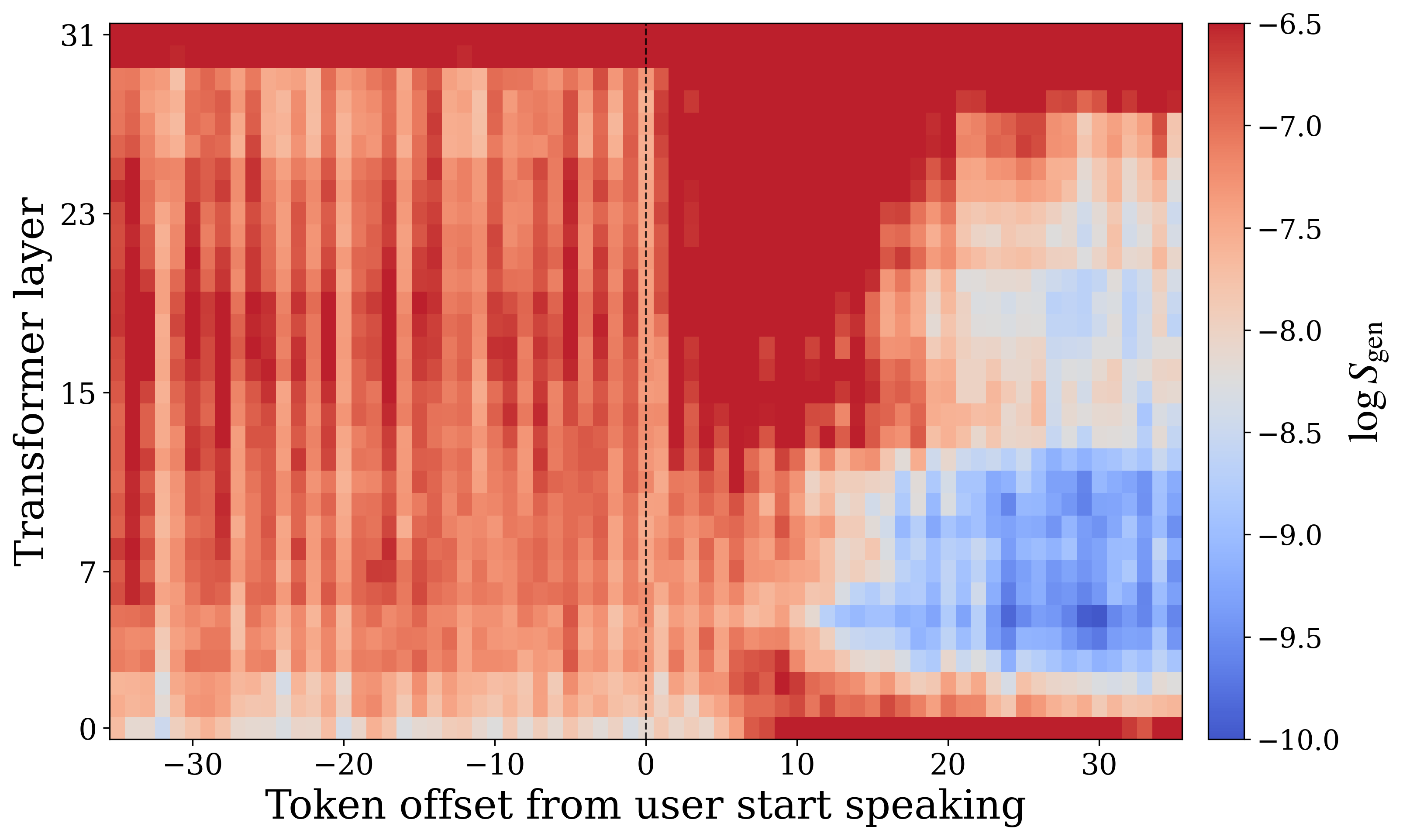
The paper explicitly connects this effect to the practical conversational problem of interrupting a spoken assistant. If the model keeps “thinking like a speaker” for too long after the user starts talking, it can fail to ingest the crucial first part of the new utterance. The authors note a conceptual resemblance to human speech-induced suppression in auditory processing, where speaking can temporarily suppress auditory responsiveness.
Zero-Buffer Benchmark: measuring immediate interruption comprehension
To quantify the behavioral consequences of state inertia, the authors introduce the Zero-Buffer Benchmark (ZBB). The benchmark is designed to test whether an FD-SLM can understand an interruption immediately when the user speech begins abruptly, with no leading filler or acoustic buffer. The benchmark is meant to stress the precise moment at which state inertia is most likely to hurt comprehension.
Each ZBB example consists of a speech-inducing prompt followed by a zero-buffer query. The query follows the template <Subject>, <Description>, <Confirmation Request>. The key design choice is that the subject appears as the first word, so missing the start of the utterance tends to remove the semantic cue needed to judge the statement. The paper gives examples such as “Submarine flies in the clouds, right?” and constructs a balanced set of $100$ zero-buffer queries from $50$ subjects, with one factually correct and one factually incorrect description per subject.
A paired example from the appendix is “Banana is a yellow fruit, right?” versus “Banana is a red fruit, right?” This setup reduces subject-specific difficulty effects and isolates whether the model can capture the earliest semantic token under interruption.
The benchmark uses two evaluation metrics, both scored with an LLM judge after transcribing the model's speech with ASR:
- Correctness: whether the model gives a factually correct and direct answer to the query.
- Initial Word Occurrence Rate (IWOR): whether the response explicitly mentions the subject that appears as the first word of the interruption query, or a direct synonym.
Correctness captures whether the model answered the whole query appropriately. IWOR is more diagnostic: it asks whether the model heard the beginning of the interruption at all. The paper argues that these two metrics are complementary, because a model may partially recover the meaning later without ever explicitly perceiving the initial semantic cue.
Activation steering with a perception vector
To mitigate state inertia, the authors propose a training-free activation steering method. The idea is to nudge the hidden state toward the perceptive state exactly when the user starts interrupting. The steering direction is a perception vector computed as a mean difference between hidden states from perception-dominant and generation-dominant timesteps.
First, they classify timesteps using the affinities above. A timestep belongs to the generation-dominant set $T_{\text{gen}}$ if $\mathcal{S}_{\text{gen}}(t)$ exceeds a threshold $\Theta_{\text{gen}}$ while $\mathcal{S}_{\text{perc}}(t)$ stays below $\Theta_{\text{perc}}$. A timestep belongs to the perception-dominant set $T_{\text{perc}}$ under the opposite condition. Then the perception vector is
$$\mu_{g \to p} = \frac{1}{|T_{\text{perc}}|} \sum_{t \in T_{\text{perc}}} h^{(t)} - \frac{1}{|T_{\text{gen}}|} \sum_{t \in T_{\text{gen}}} h^{(t)}.$$
At inference time, the hidden state at a selected steering layer is updated as $\tilde{h}^{(t)} = h^{(t)} + \alpha \mu_{g \to p}$ during a finite steering window after interruption onset, with linear decay over the steering span $\Delta T_{\text{steer}}$. The onset is detected with an energy-based detector. The method is explicitly training-free and adds only lightweight inference-time computation.
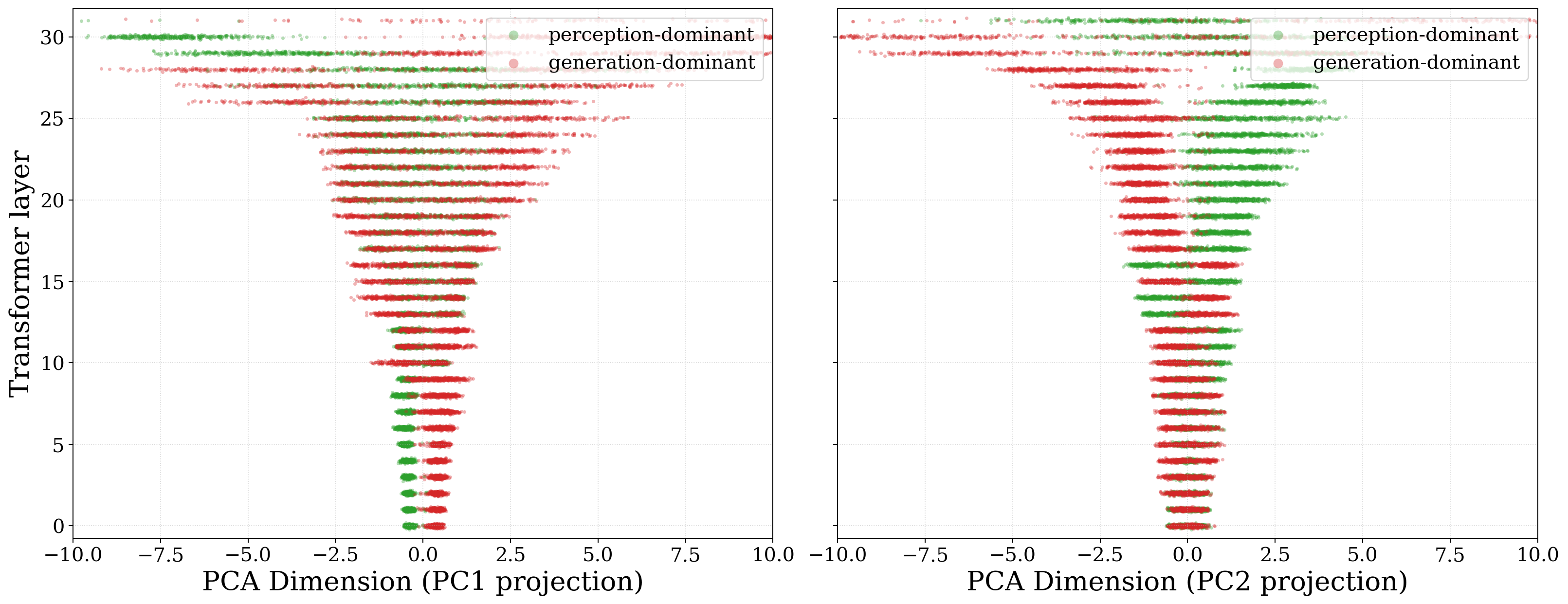
The paper also reports a geometric sanity check: PCA on hidden representations shows that generation-dominant and perception-dominant timesteps form separated clusters, supporting the idea that the mean-difference vector captures a real transition direction rather than noise.
Experimental setup
The paper evaluates three open FD-SLMs with distinct architectural paradigms: PersonaPlex, Moshi, and Raon-SpeechChat. The experiments are inference-time only; there is no fine-tuning or model training.
For ZBB, the authors compare three conditions: no interruption, interruption, and interruption with steering. The perception vector is built from separate turn-by-turn conversations that are disjoint from ZBB. In the main setup, the vector is constructed by averaging affinities over layers $12$--$24$ and using model-specific thresholds, a steering layer, a steering strength $\alpha$, and a steering span $\Delta T_{\text{steer}}$ chosen for each model. The appendix reports the exact hyperparameters used:
| Model | Layer | $\alpha$ | $\Delta T_{\text{steer}}$ | $\ln \Theta_{\text{gen}}$ | $\ln \Theta_{\text{perc}}$ |
|---|---|---|---|---|---|
| PersonaPlex | 23 | 5.5 | 3 | -3.5 | -3.9 |
| Moshi | 23 | 5.5 | 3 | -3.5 | -3.9 |
| Raon | 26 | 1.2 | 3 | -7.5 | -9.5 |
The datasets are generated from text prompts created with Claude Opus 4.5 and synthesized into speech using the Dia2-2B text-to-speech model. The turn-by-turn interaction dataset contains $100$ user queries, each about $15$--$20$ seconds of speech followed by a $10$-second response window. The state-inertia dataset uses a speech-inducing prompt, then interrupts after $5$ seconds with one of the user queries. The ZBB dataset is balanced over $50$ subjects and includes both correct and incorrect descriptions.
Quantitative ZBB results
Interruption substantially degrades performance on ZBB across all three models. The paper reports both the raw drop and the fraction of the interruption-induced drop recovered by steering. PersonaPlex shows the clearest headline gain: correctness improves from $0.28$ under interruption to $0.45$ with steering, while IWOR improves from $0.40$ to $0.72$. The no-interruption baseline for PersonaPlex is $0.49$ correctness and $0.74$ IWOR.
Moshi also benefits materially from steering, although the gains are somewhat smaller in correctness than in IWOR. Raon-SpeechChat has lower absolute scores overall, but steering still improves both metrics. The authors emphasize that the method is robust across models rather than tuned to one architecture.
| Model | Scenario | Correctness | IWOR |
|---|---|---|---|
| PersonaPlex | No interruption | 0.49 ± 0.05 | 0.74 ± 0.04 |
| Interruption | 0.28 ± 0.04 | 0.40 ± 0.05 | |
| Interruption + steering | 0.45 ± 0.05 | 0.72 ± 0.04 | |
| Moshi | No interruption | 0.43 ± 0.05 | 0.67 ± 0.05 |
| Interruption | 0.22 ± 0.04 | 0.29 ± 0.05 | |
| Interruption + steering | 0.34 ± 0.05 | 0.64 ± 0.05 | |
| Raon | No interruption | 0.10 ± 0.03 | 0.29 ± 0.05 |
| Interruption | 0.03 ± 0.02 | 0.16 ± 0.04 | |
| Interruption + steering | 0.17 ± 0.03 | 0.24 ± 0.04 |
The paper reports the recovered fraction of the interruption-induced drop in parentheses: PersonaPlex recovers $81\%$ of the correctness drop and $94\%$ of the IWOR drop; Moshi recovers $57\%$ and $92\%$; Raon recovers $200\%$ of the correctness drop and $62\%$ of the IWOR drop. The unusually large relative correctness recovery for Raon reflects its very low interruption baseline.
Qualitatively, steering reduces the lag in perception affinity and restores attention to the first few interruption timesteps. The paper includes an attention-level analysis showing that steering increases attention to early interruption tokens, aligning with the improvement in IWOR.
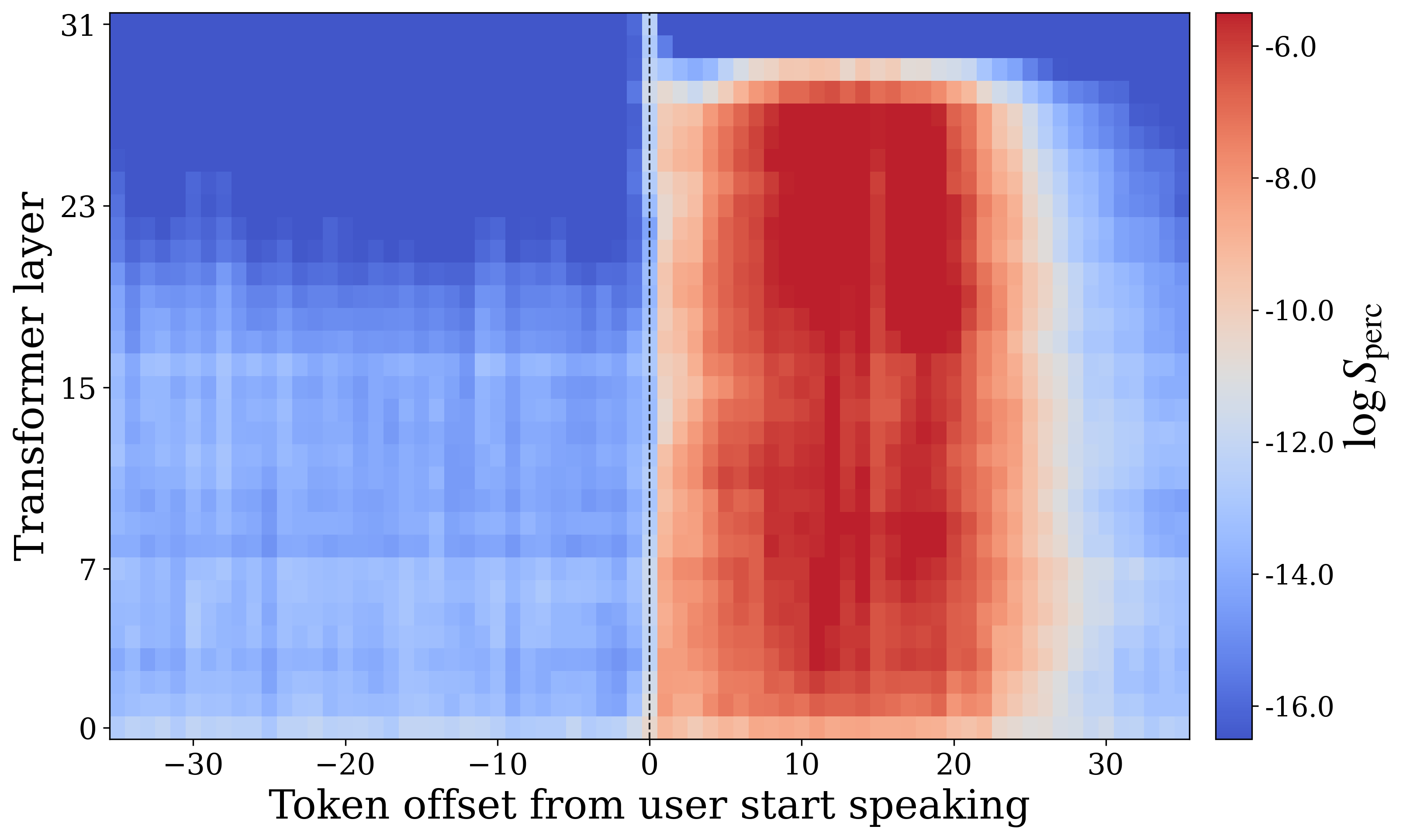
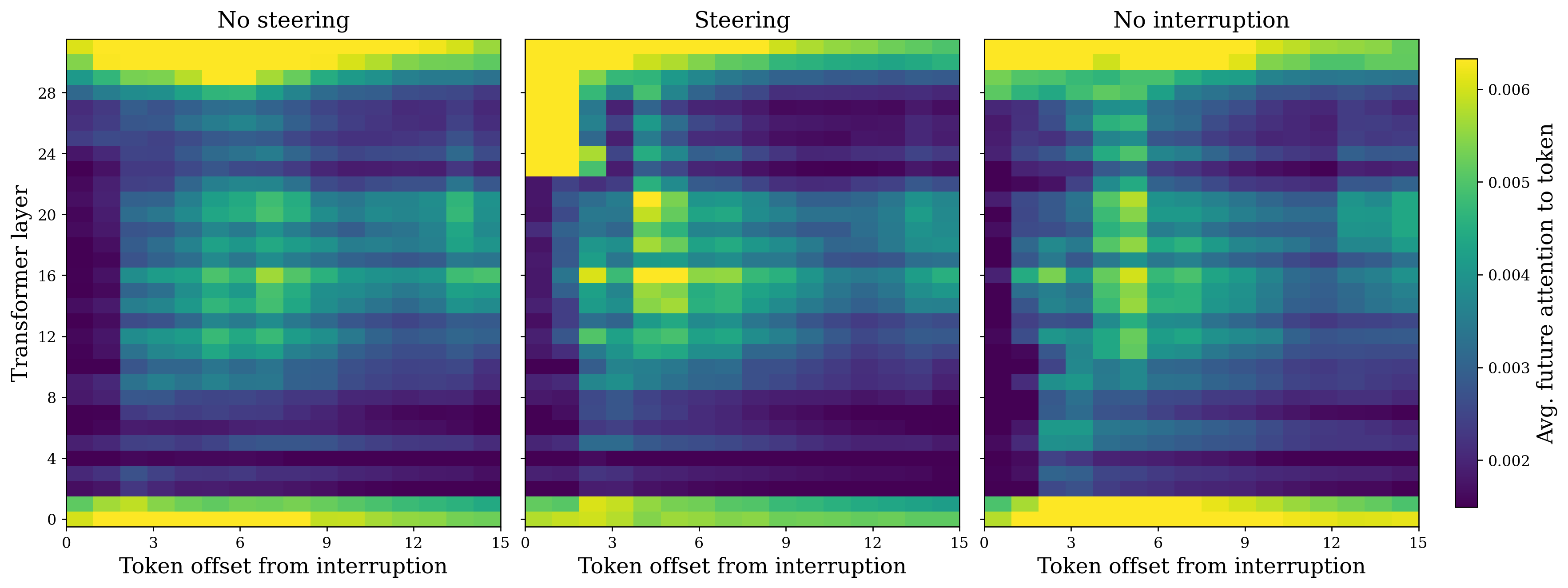
Ablations and additional analyses
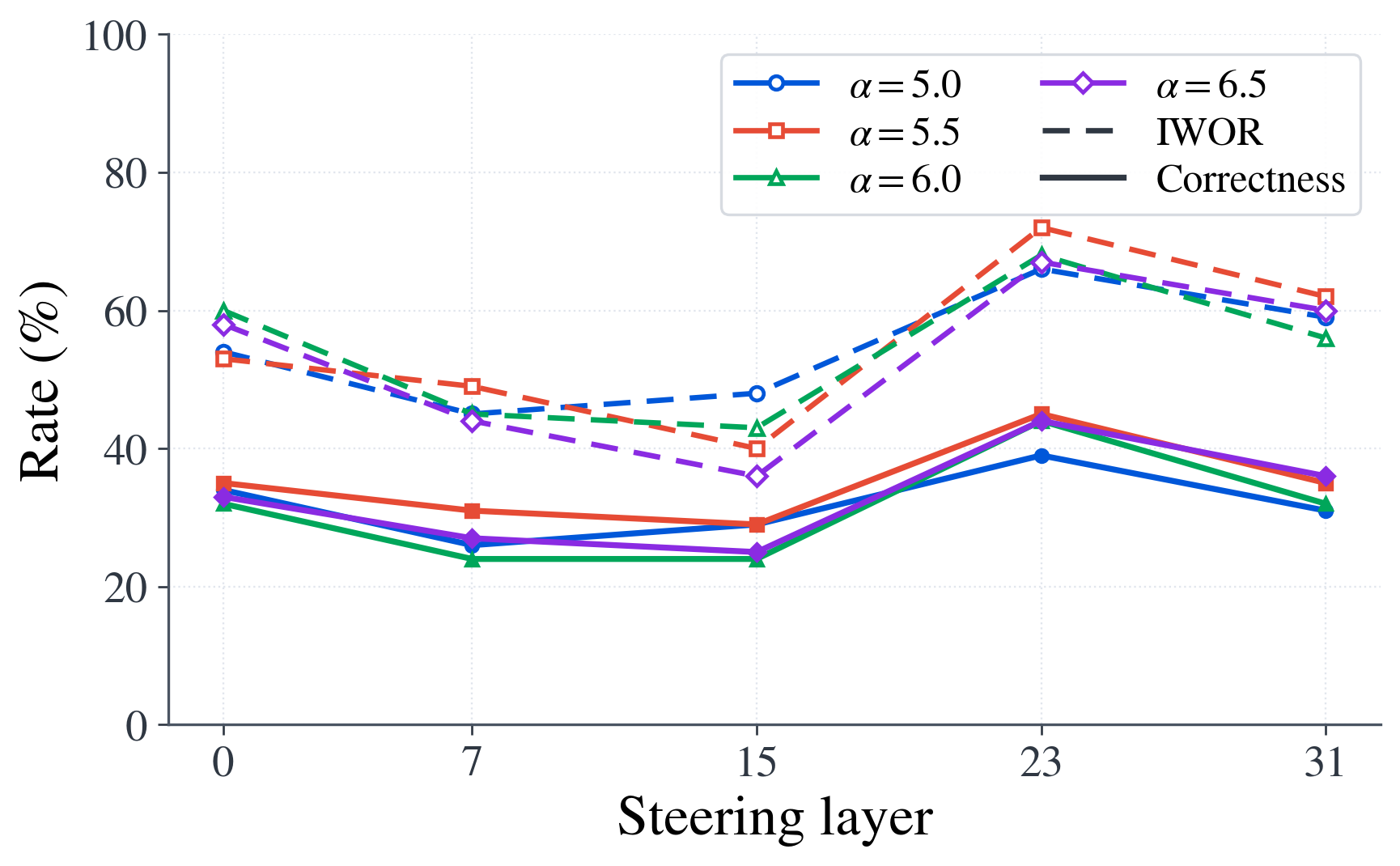
Steering layer, strength, and span
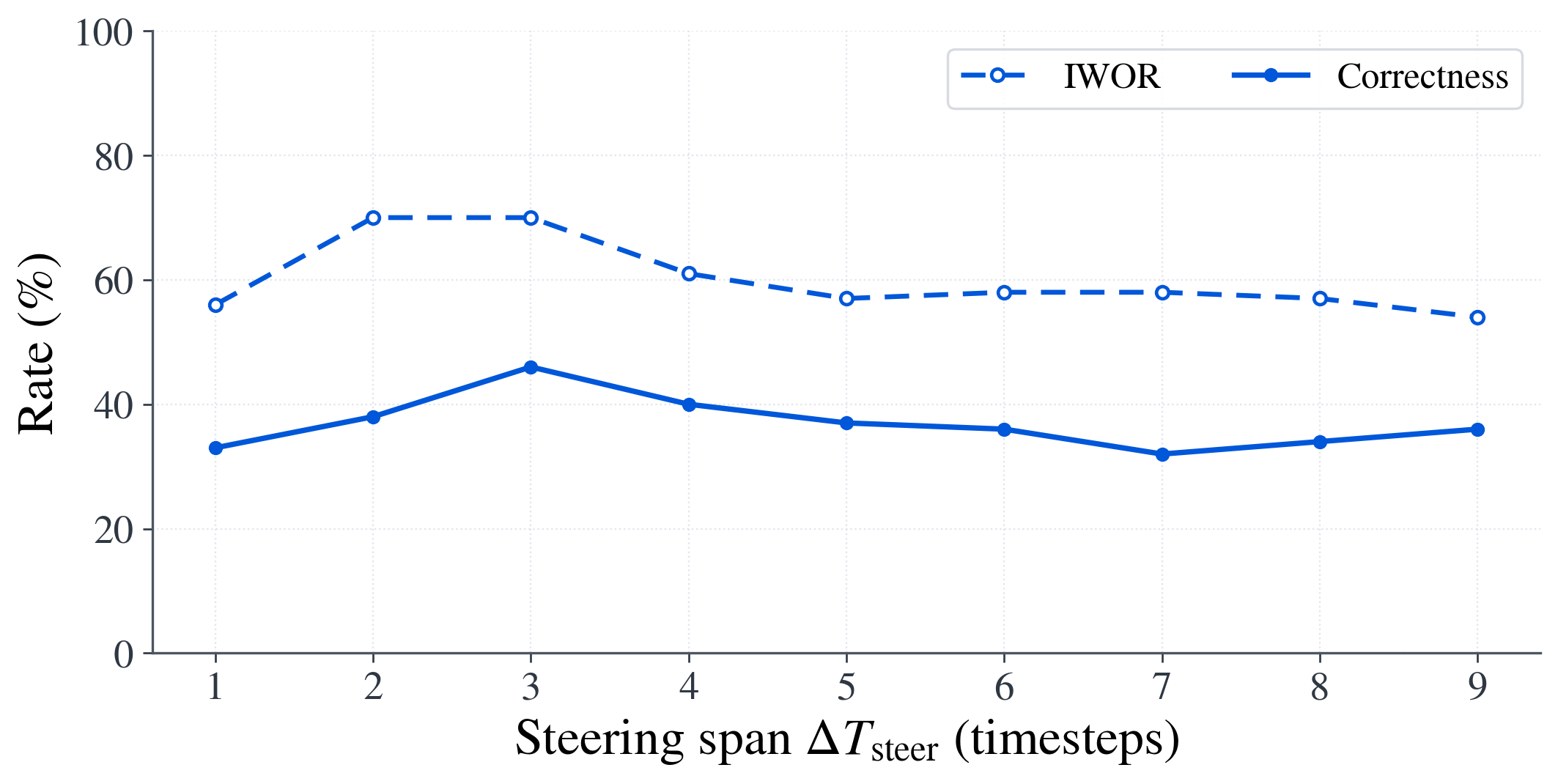
The appendix performs a parameter sweep over steering layer, steering strength $\alpha$, and steering span $\Delta T_{\text{steer}}$ on PersonaPlex. The main takeaways are that the best layer is $23$, the best strength is $\alpha = 5.5$, and the best span is $3$ timesteps. Short steering windows help most; overly long injection windows gradually reduce performance. This supports the paper's claim that the intervention should be brief and targeted to the interruption onset.
Full-Duplex Bench sanity check
The authors also evaluate steering on Full-Duplex Bench (FDB) to test whether the intervention harms broader full-duplex interaction quality. On the FDB user-interruption evaluation, steering preserves the overall score within uncertainty for each model. PersonaPlex changes from $3.34 \pm 0.08$ to $3.41 \pm 0.08$, Moshi from $3.45 \pm 0.08$ to $3.36 \pm 0.08$, and Raon remains at $2.41 \pm 0.09$.
The authors interpret this as evidence that the perception vector improves the specific zero-buffer interruption setting without obviously degrading the broader benchmark. They also argue that FDB is less sensitive than ZBB because many FDB interruption queries contain leading filler phrases before the core semantic content, which gives the model time to recover before the crucial information appears.
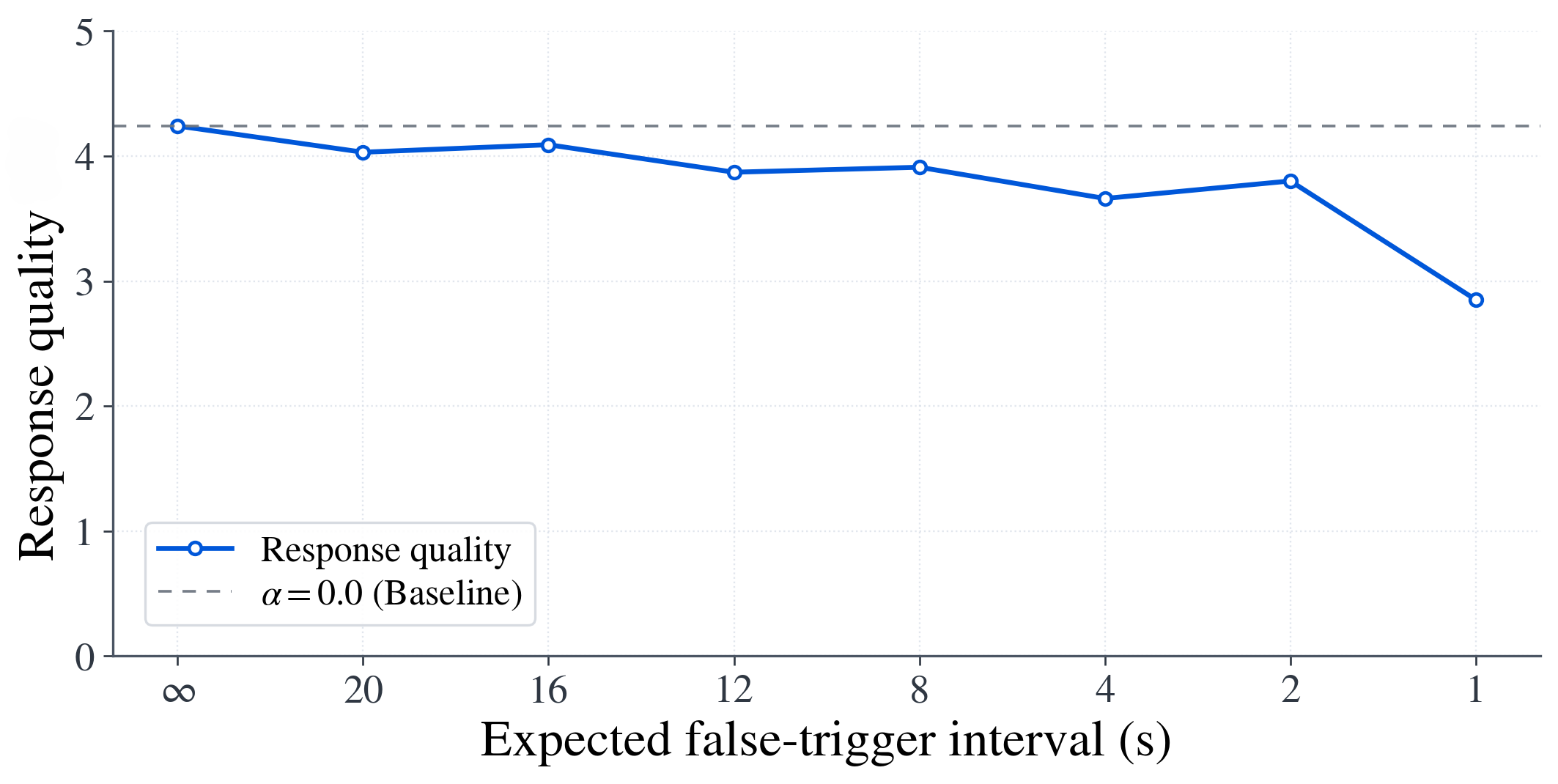
False-trigger robustness
Since the method depends on interruption-onset detection, the appendix tests what happens if the perception vector is injected at incorrect timesteps. Response quality degrades gradually as false triggers become more frequent, indicating tolerance to occasional errors but also confirming that accurate onset detection matters for deployment. The authors note that more robust voice activity detection or semantic-aware interruption detection would reduce this risk.
Limitations
The paper is explicit about several limitations. First, steering requires detecting the onset of the user's interruption, and the authors currently use a simple energy-based detector. Real-world deployment may require more robust voice activity detection, especially under noise or multiple speakers. Second, the evaluation is limited by the small number of publicly available open-source FD-SLMs. Third, the logit-lens affinity scores are diagnostic approximations and can be noisy on individual examples.
More broadly, the method is designed for inference-time intervention rather than a learned architectural fix. The authors therefore position it as a practical mitigation and analysis tool, not as a full solution to all full-duplex conversational failures.
Conclusion
The paper's main contribution is to connect an interpretable internal phenomenon in FD-SLMs to a concrete behavioral failure and then to show a lightweight mitigation. Using logit-lens-based analysis, the authors show that FD-SLM hidden states alternate between stream-specific perceptive and generative modes. They identify state inertia as a delayed transition that makes abrupt interruptions hard to process. They then introduce the Zero-Buffer Benchmark to expose the problem and show that interruption hurts both correctness and IWOR. Finally, they demonstrate that a training-free perception vector can be injected through activation steering to accelerate the transition into the perceptive state and recover much of the lost interruption performance, without fine-tuning.
In short, the paper argues that hidden-state steering is not just a probing tool for FD-SLMs, but a practical way to improve robustness in full-duplex spoken interaction.