SARA
SARA: A Dual-Stream VAE for High-Fidelity Speech Generation via Integrating Semantic and Acoustic Representations
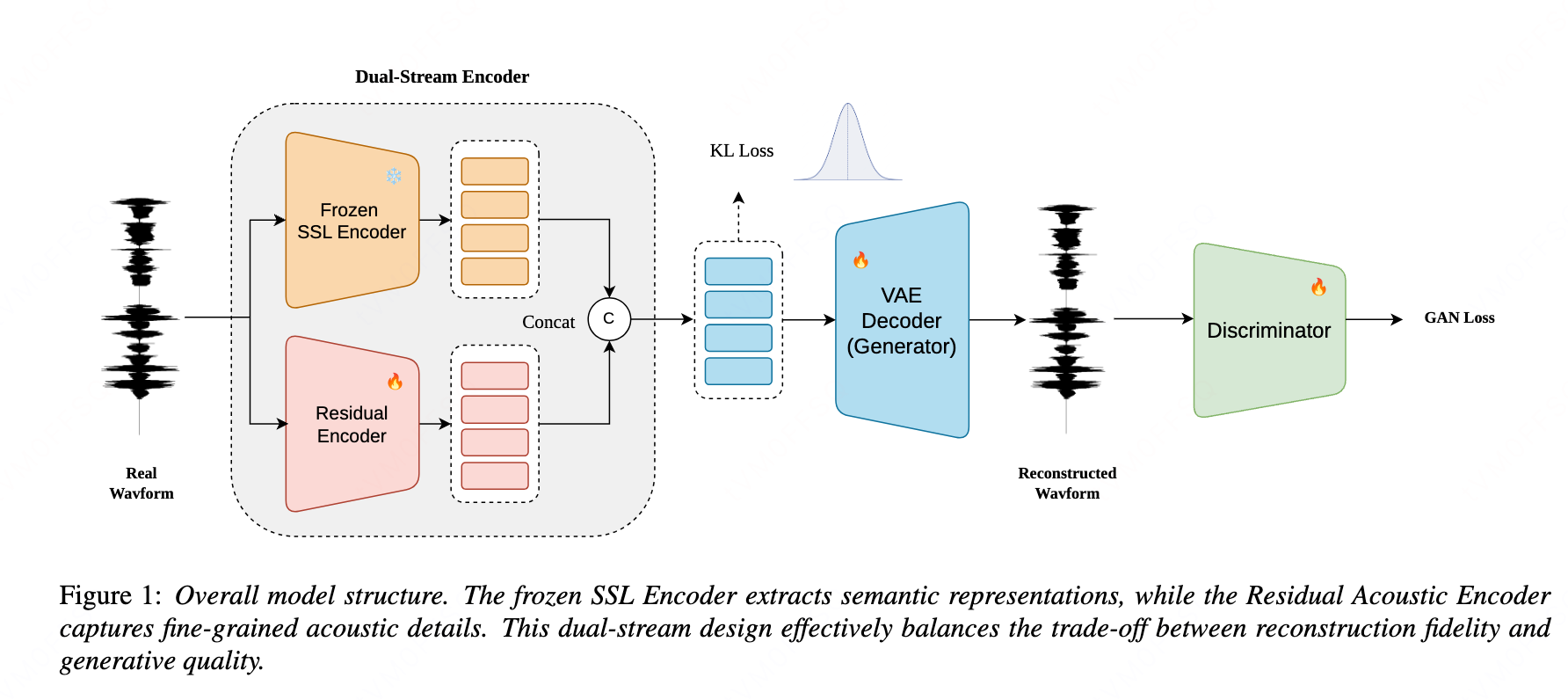
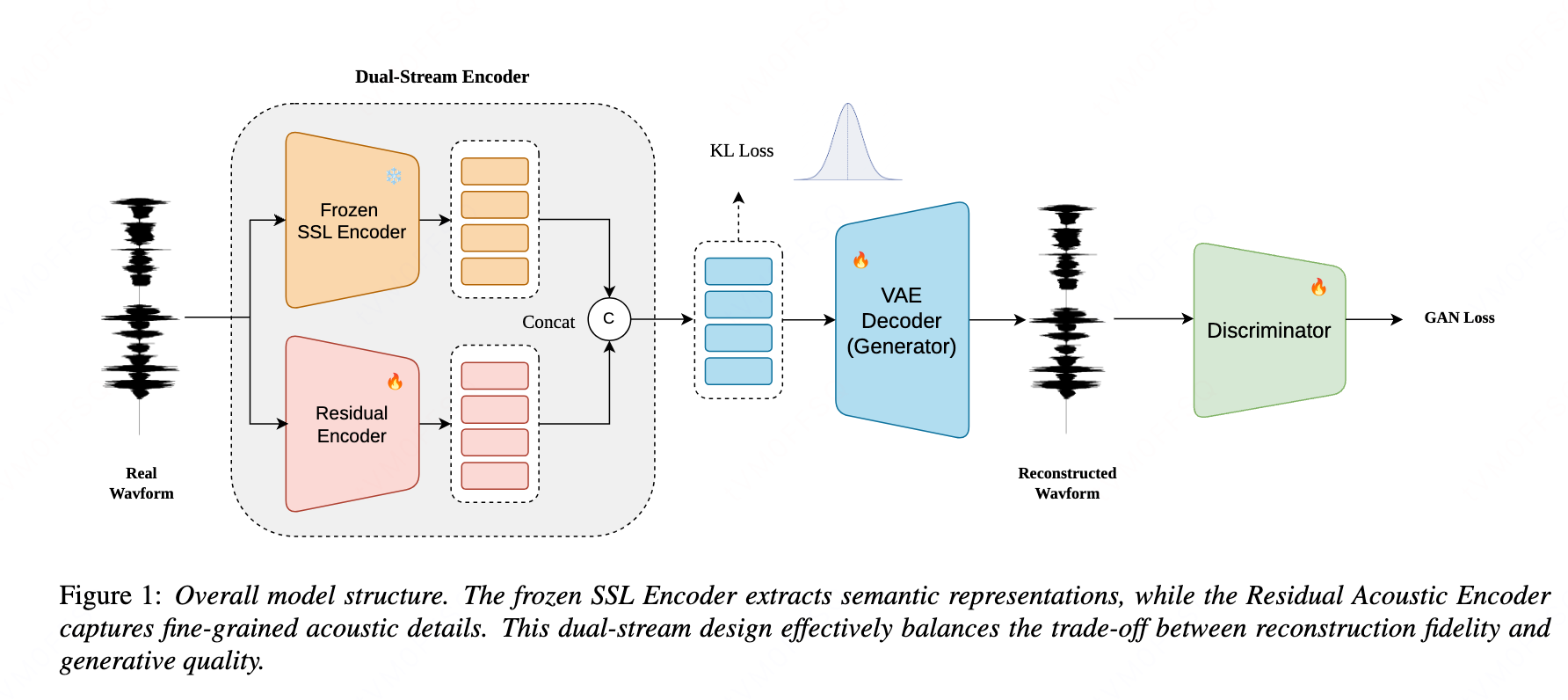
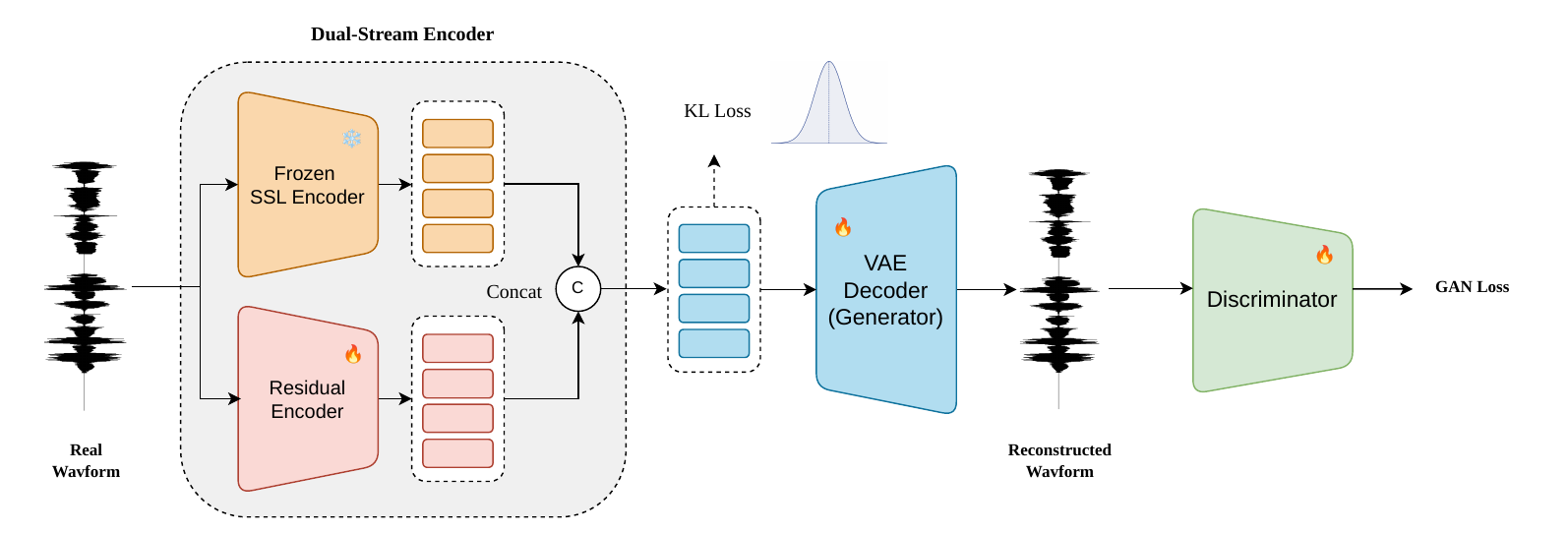
SARA is a dual-stream VAE that integrates frozen semantic and residual acoustic representations to improve zero-shot text-to-speech. This fusion balances speech fidelity with content accuracy, enabling natural, expressive, and efficient speech generation without complex regularization.
Demos
The demos showcase SARA's dual-stream VAE for speech generation, emphasizing superior reconstruction and natural, expressive synthesis over strong baselines. Watch for the balance between synthesis speed, computational cost, and fidelity. The architecture illustrates integration of semantic and acoustic features to overcome prior limitations.
Links
Paper & demos
Impact
Abstract
Zero-shot text-to-speech (TTS) relies on robust speech representations. However, current speech tokenizers face a fundamental trade-off: acoustic codecs preserve high-fidelity audio but lack linguistic constraints, causing content errors during generation, whereas semantic tokens from self-supervised learning (SSL) models ensure precise text alignment but discard some acoustic information. To bridge this gap, we propose SARA, a dual-stream VAE that directly fuses a frozen SSL semantic anchor with a dedicated residual acoustic encoder. This effectively mitigates the dilemma, creating an efficient and compact latent space without relying on complex regularizers. SARA achieves superior reconstruction quality over strong baselines. Furthermore, in downstream zero-shot TTS tasks, it yields highly natural and expressive synthesis quality, and maintains robust generation performance even under accelerated inference, offering a favorable trade-off between synthesis speed and computational cost.
Introduction
SARA addresses a central bottleneck in modern zero-shot text-to-speech (TTS): the speech representation used by the downstream generator must simultaneously preserve enough acoustic detail for natural-sounding reconstruction and enough linguistic structure for accurate content generation. The paper frames this as a trade-off between two families of tokenizers and codecs. Acoustic codecs retain fine-grained waveform information such as harmonics, timbre, and environmental detail, but their latent spaces are weakly constrained linguistically and can lead to content errors when used for generation. In contrast, semantic tokens extracted from self-supervised learning (SSL) models are strongly aligned with content and help downstream TTS models preserve text, but they discard important acoustic attributes needed for fidelity and expressiveness.
The proposed solution is SARA, a Semantic-Acoustic Residual Autoencoder, implemented as a dual-stream variational autoencoder (VAE). Rather than adding auxiliary semantic regularizers to an acoustic codec objective, SARA makes the semantic/acoustic complementarity part of the architecture itself: a frozen SSL encoder provides a stable semantic anchor, while a dedicated residual acoustic encoder captures the acoustic information that the SSL branch omits. The two streams are aligned in time, fused directly, and compressed into a compact latent representation that is intended to be both reconstruction-friendly and useful as a conditioning representation for downstream zero-shot TTS.
The paper’s core claim is that this structural fusion resolves the traditional tension between reconstruction fidelity and generative controllability without relying on complex balance-sensitive losses. In the reported experiments, SARA improves reconstruction quality over strong VAE baselines and substantially improves zero-shot TTS content accuracy while maintaining speaker similarity and naturalness. It also remains effective under accelerated inference settings, suggesting a favorable quality-speed trade-off for conversational and speech-generation systems.
Problem Setting and Design Motivation
The paper begins from the observation that the latent space produced by a speech tokenizer strongly constrains the ceiling of downstream generation quality and stability. For zero-shot TTS systems, the representation must support both content preservation and speech realism. The authors argue that existing approaches tend to over-optimize one side of this trade-off:
- Acoustic codecs reconstruct audio well, but because they lack explicit linguistic constraints, they can produce content drift and higher word error rate (WER) in generation.
- Pure semantic representations from SSL or ASR models preserve linguistic content, but they discard speaker identity, emotion, and prosody, reducing perceptual quality and similarity.
- Semantic regularization methods such as the cited Semantic-VAE approach add content-oriented losses during VAE training, but the paper characterizes these as indirect and hard to balance.
SARA’s novelty is therefore architectural: it directly injects a frozen SSL semantic encoder into the VAE encoder stack and pairs it with a residual acoustic encoder that compensates for the missing detail. Because the SSL and acoustic streams are temporally aligned, the method can concatenate them directly along the channel dimension and compress them through a linear projection into a compact latent space. This lets the representation carry both semantic anchor points and residual acoustic information in a single bottleneck.
Method
SARA is implemented as a dual-stream VAE operating on 24 kHz waveforms. The encoder maps an input signal $x$ to a latent variable $z$, and the decoder reconstructs the waveform $\hat{x}$. Training follows the standard evidence lower bound (ELBO):
$$ \mathrm{ELBO} = \mathbb{E}_{q_\phi(z \mid x)}[\log p_\psi(x \mid z)] - D_{\mathrm{KL}}\bigl(q_\phi(z \mid x) \| p(z)\bigr), $$
where the prior is the standard Gaussian $p(z) = \mathcal{N}(0, I)$. The paper minimizes the negative ELBO with a weighted sum of reconstruction, KL, adversarial, and feature-matching terms:
$$ \mathcal{L}_{\mathrm{VAE}} = \lambda_{\mathrm{recon}} \mathcal{L}_{\mathrm{recon}} + \lambda_{\mathrm{KL}} \mathcal{L}_{\mathrm{KL}} + \lambda_{\mathrm{adv}} \mathcal{L}_{\mathrm{adv}} + \lambda_{\mathrm{feat}} \mathcal{L}_{\mathrm{feat}}. $$
The reconstruction loss is a multi-scale mel-spectrogram loss consistent with DAC. To improve perceptual quality, the authors add adversarial training with a multi-period discriminator and a multi-band, multi-scale STFT discriminator. The adversarial branch is stabilized by an $L_1$ feature-matching loss.
Dual-stream encoder
The encoder is composed of two parallel branches:
- Residual acoustic encoder: built from residual CNN blocks with Snake activations and multiple convolution layers with different dilation rates, followed by a two-layer unidirectional LSTM to model longer-range dependencies.
- Frozen semantic encoder: W2v-BERT 2.0 is used as a frozen SSL model to extract robust semantic representations.
The acoustic encoder follows a cumulative downsampling factor of $480$ through five strided stages with factors $[2, 3, 4, 4, 5]$, which converts the 24 kHz input into a $50$ Hz acoustic latent stream $z_{\mathrm{ac}}$. W2v-BERT 2.0 produces semantic features $z_{\mathrm{sem}}$ at the same $50$ Hz rate. Because the two streams are aligned in time, SARA concatenates them channel-wise and applies a linear projection to obtain the final latent $z$ with dimensionality $64$.
This design is central to the paper’s claim of an efficient and compact latent space: the model avoids hand-designed semantic regularization losses and instead uses a structurally aligned fusion of complementary content and acoustic cues.
Decoder
The decoder is based on HiFi-GAN and uses multi-receptive field fusion to synthesize a waveform from the integrated latent representation. In the paper’s framing, the decoder and adversarial training jointly target perceptual naturalness and faithful reconstruction.
Training and Experimental Setup
Data
SARA is trained on a large-scale mixture of LibriTTS and LibriHeavy. LibriHeavy contributes approximately 50,000 hours of audiobook speech originally sampled at 16 kHz, and LibriTTS contributes 585 hours of multi-speaker speech at 24 kHz. All training audio is resampled to 24 kHz, resulting in a corpus of over 50,000 hours. For the downstream zero-shot TTS task, the model is trained exclusively on the LibriHeavy subset.
The paper evaluates two different aspects of utility:
- Speech reconstruction and latent utility on the LibriSpeech test-clean split, including objective reconstruction metrics and cross-sentence generation-style checks of content and speaker consistency.
- Downstream zero-shot TTS on the LibriSpeech-PC test-clean set, using F5-TTS as the generation backbone.
Metrics
For reconstruction, the paper reports PESQ, STOI, and UTMOS. For latent utility and generated speech, it reports WER, speaker similarity (SIM), and subjective CMOS and SMOS. WER is computed with Whisper-large-v3, and SIM is computed as cosine similarity between speaker embeddings extracted from a pre-trained WavLM-TDCNN model. The subjective metrics are used as follows: CMOS evaluates overall audio quality, clarity, naturalness, and high-fidelity details; SMOS evaluates speaker similarity in terms of timbre and prosody.
Optimization details
The VAE is trained for 200k iterations with a global batch size of 256. Audio clips are segmented into 1-second windows and resampled to 24 kHz, yielding roughly 256 seconds of audio per batch. Optimization uses AdamW with an initial learning rate of $10^{-4}$. A linear warm-up is applied to both the learning rate and the KL coefficient during the first 10,000 updates, followed by exponential decay with factor $\gamma = 0.9999996$.
The loss weights are set to $\lambda_{\mathrm{KL}} = 0.01$, $\lambda_{\mathrm{adv}} = 1$, $\lambda_{\mathrm{feat}} = 1$, and $\lambda_{\mathrm{recon}} = 15$.
For downstream zero-shot TTS, the authors use F5-TTS as the backbone and replace mel-spectrogram conditioning with latent representations extracted from the SARA encoder. The downstream model is optimized with AdamW at a peak learning rate of $7.5 \times 10^{-5}$, using a 20,000-step warm-up followed by linear decay. Inference follows the F5-TTS protocol with sway sampling and an Euler ODE solver.
Main Results
The paper reports three main empirical findings: SARA improves zero-shot TTS accuracy and similarity, reconstructs speech more faithfully than the baselines, and remains effective when the generator is run with fewer inference steps.
Zero-shot TTS on LibriSpeech-PC test-clean
| Model | #Param. | Sample Rate | Frame/s | WER (%) ↓ | SIM ↑ | CMOS ↑ | SMOS ↑ |
|---|---|---|---|---|---|---|---|
| GT | - | - | - | 2.23 | 0.69 | +0.12 | 3.92 |
| Vocoder Resynthesized | - | 24k | - | 2.32 | 0.66 | +0.10 | 3.91 |
| Cosyvoice | 300M | 24k | - | 3.59 | 0.66 | -0.14 | 3.95 |
| E2 TTS | 333M | 24k | - | 2.95 | 0.69 | -0.08 | 3.98 |
| F5-TTS | 336M | 24k | - | 2.42 | 0.66 | -0.06 | 3.99 |
| F5-TTS-Small | 159M | 24k | 93.75 | 2.23 | 0.60 | -0.10 | 3.85 |
| + Semantic-VAE* | 159M | 16k | 40 | 1.95 | 0.64 | - | - |
| + SARA (Ours) | 159M | 24k | 50 | 1.79 | 0.63 | -0.03 | 3.89 |
| F5-TTS-Base + SARA | 336M | 24k | 50 | 1.74 | 0.655 | 0.00 | 3.90 |
On the zero-shot TTS task, SARA improves the content accuracy of F5-TTS-Small from WER $2.23$ to $1.79$ while also maintaining strong speaker similarity and subjective quality. The paper highlights that this result is particularly notable because it surpasses larger baselines such as Cosyvoice, E2 TTS, and the standard F5-TTS in WER, despite using the smaller backbone. When scaled to F5-TTS-Base, SARA reaches the best reported WER in the table at $1.74$ and the best SIM at $0.655$.
The comparison with Semantic-VAE is also important for the paper’s argument. Semantic-VAE improves WER to $1.95$, but it operates at $16$ kHz and $40$ frames/s. SARA achieves better WER at a higher $24$ kHz bandwidth and $50$ frames/s, which the authors present as a stronger high-fidelity alternative that does not require the same kind of explicit semantic regularization.
Speech reconstruction on LibriSpeech test-clean
| Model | Frame/s | Dim | PESQ ↑ | STOI ↑ | UTMOS ↑ |
|---|---|---|---|---|---|
| GT | - | - | - | - | 4.086 |
| Vocos | 93.75 | 100 | 3.605 | 0.977 | 3.625 |
| Semantic-VAE | 40 | 64 | 3.968 | 0.981 | 4.129 |
| Vanilla VAE | 50 | 64 | 4.076 | 0.983 | 4.095 |
| SARA (Ours) | 50 | 64 | 4.389 | 0.993 | 4.100 |
On reconstruction, SARA yields the best PESQ and STOI among the compared methods, with PESQ $4.389$ and STOI $0.993$. The paper emphasizes that this is a stronger result than both the vanilla VAE and the Semantic-VAE baseline, supporting the claim that the residual acoustic stream recovers fine-grained detail that a semantic-only branch cannot preserve. UTMOS remains competitive at $4.100$, close to the best value in the table and above the ground-truth reference score reported in the table.
Ablation Studies
The ablation experiments are designed to isolate the contribution of each branch in the dual-stream encoder. They are reported on the LibriSpeech-PC test-clean set using reconstruction-oriented metrics plus WER and SIM versus the reference audio.
| Model | PESQ ↑ | STOI ↑ | UTMOS ↑ | WER (%) ↓ | SIM ↑ |
|---|---|---|---|---|---|
| GT | - | - | 4.097 | 2.23 | 0.690 |
| SARA | 4.366 | 0.992 | 4.110 | 2.32 | 0.685 |
| - Res Encoder | 2.655 | 0.930 | 3.944 | 2.41 | 0.640 |
| - SSL Encoder | 4.074 | 0.983 | 4.113 | 2.41 | 0.683 |
The ablation results reinforce the paper’s design argument. Removing the residual acoustic encoder substantially harms perceptual reconstruction and speaker similarity: SIM drops from $0.685$ to $0.640$, and PESQ falls sharply from $4.366$ to $2.655$. This shows that the frozen SSL branch alone is insufficient to reproduce the timbre and fine acoustic detail present in the original audio.
Removing the SSL encoder instead yields a model close to a vanilla VAE and mainly degrades linguistic stability. In that condition, WER worsens from $2.32$ to $2.41$, while speaker similarity remains much closer to the full model than in the “- Res Encoder” case. The two ablations together support the complementary roles of the branches: the SSL encoder anchors content, and the residual encoder restores detail.
Inference-step trade-off for downstream generation
| Model | NFE | WER (%) ↓ | SIM ↑ | RTF ↓ |
|---|---|---|---|---|
| F5-TTS-Small | 8 | 3.51 | 0.58 | 0.061 |
| F5-TTS-Small | 32 | 2.23 | 0.60 | 0.115 |
| F5-TTS-Small + SARA | 6 | 2.27 | 0.57 | 0.058 |
| F5-TTS-Small + SARA | 8 | 1.82 | 0.62 | 0.079 |
| F5-TTS-Small + SARA | 32 | 1.79 | 0.63 | 0.184 |
The NFE ablation shows that SARA provides a more favorable speed-quality trade-off for the flow-matching generator. With only $8$ inference steps, F5-TTS-Small + SARA reaches WER $1.82$ and SIM $0.62$, which is better than the plain F5-TTS-Small at the same step count and close to the $32$-step baseline in content quality. The authors interpret this as evidence that the dual-stream latent space is better conditioned, allowing the generator to converge more quickly.
The table also makes an important practical point: SARA adds encoder-side cost, so the overall RTF at $32$ steps is higher than the plain baseline. However, at lower step counts the quality remains strong, and the method can therefore be attractive when inference acceleration is desired. In the authors’ framing, SARA improves the trade-off between synthesis speed and computational cost rather than removing the cost entirely.
Interpretation of the Paper’s Contributions
- Architectural fusion instead of loss balancing: the paper’s main methodological contribution is to replace explicit semantic regularization with a dual-stream encoder that structurally combines semantic and acoustic information.
- Temporal alignment at $50$ Hz: both streams are aligned to the same frame rate, enabling direct concatenation and a compact $64$-dimensional bottleneck.
- Compatibility with existing generators: SARA is inserted into F5-TTS by swapping mel features for latent representations, showing that the learned space is usable as a drop-in conditioning interface for a strong zero-shot TTS model.
- Better reconstruction and generation: the method improves objective reconstruction metrics, zero-shot content accuracy, and speaker similarity in the reported experiments.
- Efficient inference behavior: the latent space is reported to remain effective even under reduced NFE settings, which is particularly relevant for conversational systems that care about latency.
Limitations and Future Work
The paper does not include a standalone limitations section, but it does explicitly acknowledge one practical cost: the dual-stream encoder introduces extra inference overhead, even though it improves the speed-quality trade-off at reduced generator steps. The reported results therefore suggest a better balanced system, not a universally cheaper one.
In the conclusion, the authors identify two future directions: multilingual scaling and integration with autoregressive models. These are the only future-facing extensions stated in the paper, and they indicate that the current work is positioned as a foundation for broader speech-generation systems rather than a complete endpoint.
Conclusion
SARA is a dual-stream VAE for speech representation learning that combines a frozen SSL semantic encoder with a residual acoustic encoder. Its core technical idea is to fuse temporally aligned semantic and acoustic streams into a compact $50$ Hz, $64$-dimensional latent space, trained with a VAE objective plus adversarial and feature-matching losses. Across reconstruction, zero-shot TTS, and inference-step ablations, the reported results show that SARA better preserves content while retaining high-fidelity acoustic detail, outperforming strong baselines in the paper’s measured settings. For a talking-head or conversational-AI team, the main takeaway is that SARA provides a representation layer that is simultaneously more semantically stable than a pure acoustic codec and more acoustically faithful than a purely semantic tokenization pipeline.