UR-BERT
UR-BERT: Scaling Text Encoders for Massively Multilingual TTS Through Universal Romanization and Speech Token Prediction
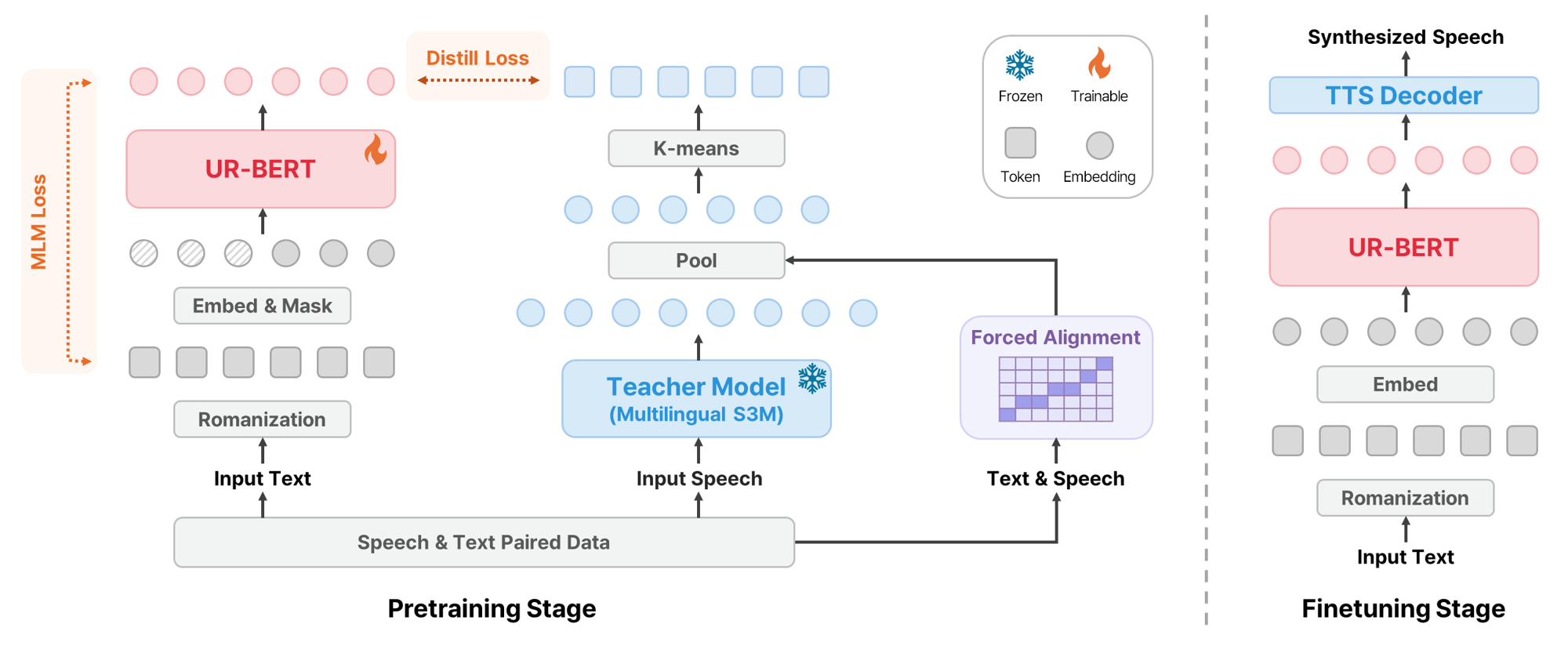
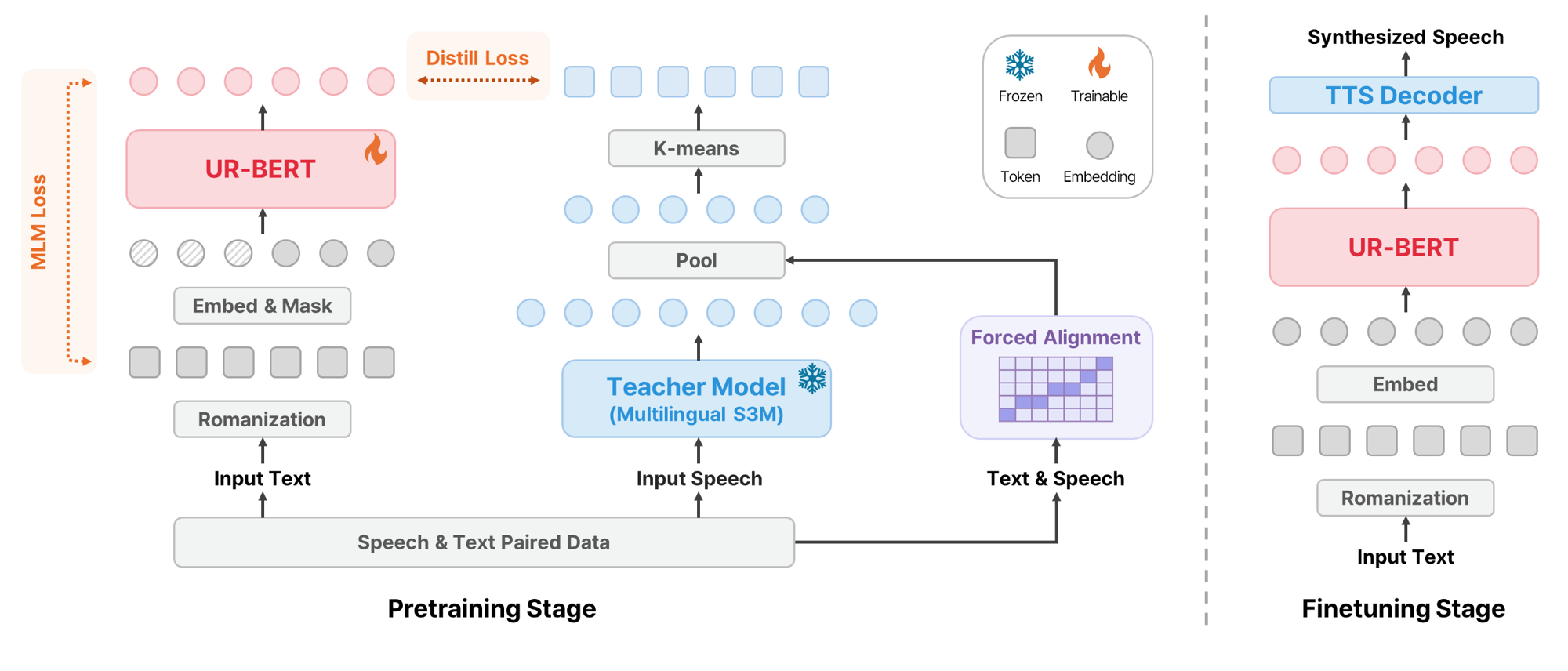
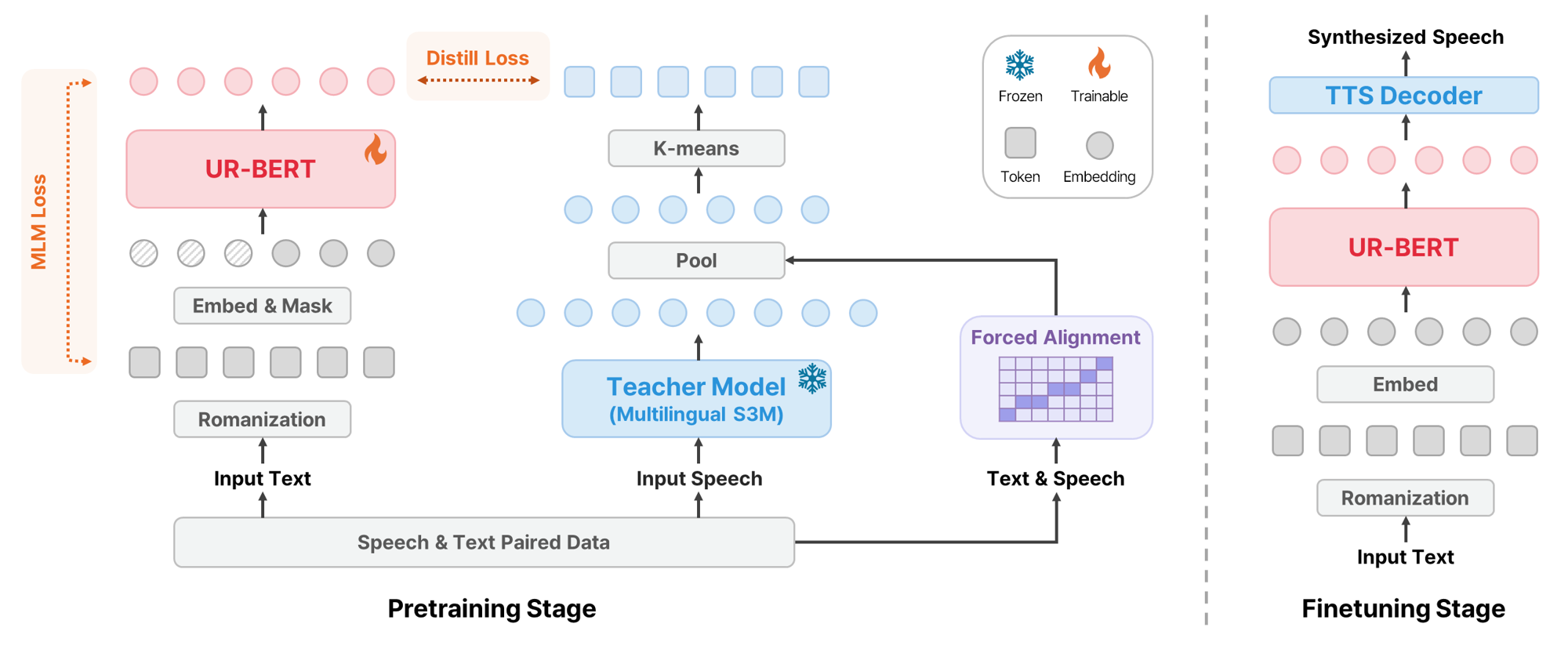
UR-BERT is a Romanized transcription-based text encoder for massively multilingual TTS. It scales to 495 languages without phoneme systems and uses speech token prediction to improve phonetic fidelity and alignment, enabling strong results especially for low-resource and unseen languages.
Demos
The demos illustrate UR-BERT's architecture and its capability to scale massively multilingual TTS using universal Romanization and speech token prediction. When evaluating, note the model's support for 495 languages, improved phonetic fidelity, alignment, and stronger generalization to new languages. The architecture overview highlights the core design enabling these advances.
Links
Paper & demos
Code & resources
Impact
Abstract
We propose UR-BERT, a Romanized transcription-based text-to-speech (TTS) encoder for massively multilingual TTS systems. Conventional grapheme-to-phoneme (G2P)-based approaches are limited to around 100 languages due to the availability of reliable G2P resources. In contrast, UR-BERT scales to 495 languages by unifying diverse writing systems into a shared Romanization representation. To further enhance phonetic fidelity and text-speech alignment, we introduce a speech token prediction objective during training, which encourages the encoder to learn speech-aware phonetic representations in a data-efficient manner. Experiments show that TTS systems built on UR-BERT consistently outperform recent text encoder baselines across a wide range of languages and resource conditions, and demonstrate strong generalization to unseen languages.
Introduction and Motivation
The paper tackles a specific bottleneck in massively multilingual text-to-speech (TTS): text encoders that rely on language-specific grapheme-to-phoneme (G2P) toolkits do not scale to the long tail of the world’s languages. The authors argue that the encoder side of modern encoder-decoder TTS has been comparatively underexplored, even though encoder quality strongly affects text-speech alignment and phonetic accuracy. Prior BERT-style TTS encoders improved naturalness, but they usually operate on phoneme sequences produced by G2P systems, which limits language coverage to roughly one hundred languages and creates a structural dependency on external linguistic resources.
UR-BERT is proposed as a multilingual, speech-aware TTS text encoder that removes the G2P dependency by using Romanization as a shared text interface across writing systems. The model is pretrained on speech-text pairs from 495 languages and adds an auxiliary speech token prediction objective so that the text encoder learns not just textual context but also acoustic structure. The intended outcome is a text encoder that can be used in TTS systems for both high-resource and low-resource languages, while remaining usable for unseen languages.
Core claims from the paper:
- Romanization can serve as a scalable replacement for phoneme conversion in multilingual TTS.
- Speech token prediction injects acoustic information into the text encoder and improves alignment.
- UR-BERT outperforms prior BERT-style TTS encoders across the evaluated languages and resource conditions.
Positioning Against Prior Work
The related-work discussion centers on multilingual PLBERT (m-PLBERT) and XPhoneBERT. m-PLBERT follows the PL-BERT idea and is pretrained on phoneme sequences from 15 languages generated with Phonemizer. XPhoneBERT extends this to 88 languages using CharsiuG2P. Both improve multilingual TTS, but both remain constrained by the availability and quality of G2P systems, and their language distribution is still skewed toward better-resourced European and Asian languages.
UR-BERT’s novelty is therefore not only larger language coverage, but also a change in representation: it avoids phoneme inventories and instead maps diverse scripts into Romanized strings. This is meant to make the encoder language-agnostic and to reduce the engineering burden associated with maintaining per-language phoneme resources.
| Model | Languages used for training | Languages supported | Text pretraining data | Speech data |
|---|---|---|---|---|
| m-PLBERT | 15 | 127 | 150K sentences | None reported |
| XPhoneBERT | 88 | 99 | 330M sentences | None reported |
| UR-BERT | 495 | 1162 empirically validated in prior studies | 8M sentences | 13K hours |
UR-BERT Method
Architecture
UR-BERT uses a standard BERT-base-style encoder with a character-level tokenizer and 12 Transformer encoder layers. The encoder is pretrained on speech-text pairs rather than text alone. During pretraining it combines masked language modeling with an auxiliary speech token prediction objective.
The paper does not provide a closed-form loss equation in the LaTeX source shown here, but conceptually the training signal is the sum of the usual masked-text reconstruction objective and a prediction objective over discrete speech tokens aligned to characters.
Romanization as the text interface
The first design choice is to Romanize all input text into Latin characters. The motivation is practical as well as representational. Compared with phoneme-based encodings, Romanization avoids dependence on language-specific G2P systems and keeps the symbol inventory compact. The authors contrast this with IPA-style phoneme encodings, which can require very large symbol sets and complicated tokenization rules, especially when diacritics and suprasegmental markers are treated inconsistently.
In the paper’s framing, Romanization reduces the token inventory to roughly 30 alphabetic symbols, while still preserving sufficient phonetic information for TTS. The authors cite the Uroman toolkit as a practical example of a transliteration approach that can scale across writing systems.
Speech token prediction
Romanization improves coverage, but it also introduces ambiguity because multiple pronunciations can collapse onto the same Romanized form. To recover phonetic detail, UR-BERT uses a knowledge-distillation-style pretraining target called speech token prediction (STP). A pretrained multilingual speech self-supervised model serves as the teacher, and the student encoder learns to predict discrete speech tokens derived from the teacher’s representations.
The paper describes the STP pipeline as three steps: extract speech representations from a multilingual self-supervised speech model, align them to text at the character level, and discretize the aligned vectors into a token codebook. The teacher model used for extraction is omnilingual-ASR-W2V-300M, and the representation is taken from layer 16 because intermediate layers are expected to contain more phonetic information than higher semantic layers.
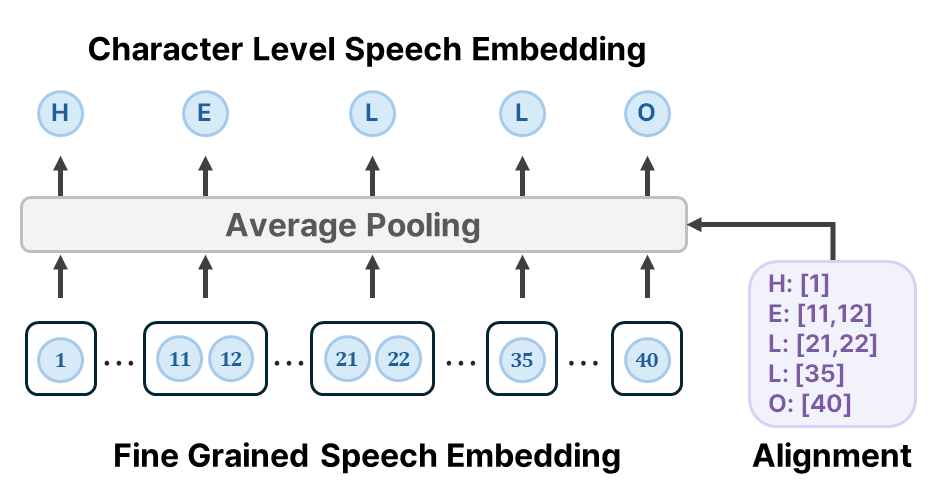
For alignment, the authors use CTC-based forced alignment with MMS-FA, followed by average pooling over the aligned frames for each character. This converts a long speech sequence into a sequence of character-level acoustic representations. Those vectors are then clustered with k-means to form a discrete codebook.
The codebook size is fixed at 257: index 0 is a mute token, and indices 1 through 256 represent acoustic tokens. The authors explicitly avoid larger codebooks because they may capture speaker-specific or paralinguistic variation instead of phonetic content, and because larger vocabularies can destabilize training given the compact text side. This design choice is presented as a balance between representational capacity and phonetic abstraction.
Pretraining Data and Optimization
The pretraining corpus combines three ASR-style speech-text datasets: FLEURS, Common Voice, and the Omnilingual ASR corpus. The reported corpus contains approximately 13K hours of speech, 8M sentences, and 495 languages. FLEURS contributes 102 read-speech languages, Common Voice covers 131 languages, and Omnilingual ASR contributes 348 low-resource languages.
The appendix adds two important preprocessing details. First, samples containing digits or parenthetical expressions were removed because their pronunciations can be ambiguous or inconsistently realized across languages. Second, the longer Omnilingual ASR utterances were segmented into chunks of up to 30 seconds using MMS-FA to reduce padding and computation while better matching the duration distribution of FLEURS and Common Voice.
Pretraining runs for 150K steps with batch size 1024 using gradient accumulation. Optimization uses AdamW and a tri-stage learning-rate schedule with warm-up, peak, and decay ratios of 0.1, 0.5, and 0.4, respectively, and a peak learning rate of 1e-4.
Downstream TTS Setup
For downstream synthesis experiments, the paper uses VITS as the backbone TTS model and swaps in different text encoders: the original VITS encoder, m-PLBERT, XPhoneBERT, and UR-BERT. All datasets are resampled to 22,050 Hz.
The evaluation spans 11 languages. The high-resource group contains English, German, and Mandarin Chinese, each with 20 hours of training data. The low-resource group contains eight languages: Javanese and Sundanese at 5 hours each, Khmer at 3 hours, Afrikaans, Nepali, Setswana, and Xhosa at 2 hours each, and Sinhala at 1 hour.
Training follows the protocols of prior work: low-resource models are trained for 100K steps and high-resource models for 300K steps, both with batch size 32. The text encoder is frozen for the first 25 percent of training steps, and warm-up is omitted during fine-tuning to stabilize the monotonic alignment search module.
Evaluation Protocol
The paper uses one subjective measure and four objective measures. Subjective quality is assessed with mean opinion score on a 1-to-5 scale, with phonetic guidance. Ratings are collected on 520 samples from 44 participants with diverse regional backgrounds.
Objective quality is measured with the UTokyo MOS Prediction System, reported as relative degradation against ground-truth samples. Intelligibility is measured with character error rate from transcriptions generated by Omnilingual-ASR-CTC-1B, also reported as relative degradation against ground truth. Spectral and prosodic differences are captured by mel-cepstral distance and log-F0 root mean squared error.
The appendix provides additional MOS protocol details: participants were recruited through community outreach, all were fluent in English, and several had exposure to other language regions. Participants were instructed to evaluate in a quiet environment with headphones, and loudspeakers were prohibited. Grapheme transcriptions and Romanized transcriptions were shown as phonetic guidance, along with the language identity for each sample.
Sampling was designed for fair comparison. The authors randomly sampled 10 utterances per configuration, reused the same text prompts across models within a language, and evaluated 110 ground-truth samples plus 410 generated samples. To reduce fatigue, the 520 samples were split into four disjoint groups of 130 utterances, with 11 participants assigned to each group.

Results on High-Resource Languages
UR-BERT improves over VITS, m-PLBERT, and XPhoneBERT on all three high-resource languages in terms of MOS, and it also achieves the best or near-best objective scores. The qualitative conclusion is that Romanization plus STP does not merely expand coverage; it also yields a stronger encoder for languages already well represented in TTS benchmarks.
A notable result is that UR-BERT was trained on 8M sentences, which the authors note is only 2.5 percent of the text used for XPhoneBERT, yet it still surpasses XPhoneBERT on most metrics. The paper attributes this data efficiency to the compact Romanized token space and to the acoustic guidance supplied by STP.
| Language | Model | MOS | Rel. UTM degradation | Rel. CER degradation | MCD | Log-F0 RMSE |
|---|---|---|---|---|---|---|
| English | GT | 4.61 | - | - | - | - |
| VITS | 3.78 | 0.29 | 6.15 | 5.71 | 0.162 | |
| m-PLBERT | 1.83 | 0.58 | 66.50 | 8.34 | 0.163 | |
| XPhoneBERT | 4.11 | 0.23 | 4.79 | 5.17 | 0.152 | |
| UR-BERT | 4.35 | 0.12 | 3.78 | 5.23 | 0.149 | |
| German | GT | 4.02 | - | - | - | - |
| VITS | 3.45 | 0.53 | 6.37 | 5.36 | 0.188 | |
| m-PLBERT | 2.65 | 0.57 | 67.78 | 6.93 | 0.203 | |
| XPhoneBERT | 3.53 | 0.53 | 5.85 | 4.77 | 0.171 | |
| UR-BERT | 3.78 | 0.33 | 3.07 | 4.66 | 0.170 | |
| Mandarin Chinese | GT | 4.35 | - | - | - | - |
| VITS | 3.65 | 0.46 | 29.28 | 5.17 | 0.102 | |
| m-PLBERT | 2.88 | 0.35 | 67.45 | 5.90 | 0.105 | |
| XPhoneBERT | 3.49 | 0.30 | 25.98 | 5.16 | 0.097 | |
| UR-BERT | 3.88 | 0.36 | 21.83 | 4.95 | 0.098 |
The strongest subjective gains are visible in all three languages. In English and German, UR-BERT is best on every reported metric. In Mandarin Chinese, UR-BERT is best on MOS, relative UTM degradation, relative CER degradation, and MCD, while XPhoneBERT is slightly better on log-F0 RMSE. The paper also highlights that m-PLBERT can degrade sharply when plugged into VITS, producing speech that may sound fluent but is often phonetically incorrect.
Results on Low-Resource and Zero-Shot Languages
The low-resource experiments are where UR-BERT’s scale advantage becomes especially clear. Phoneme-based baselines do not support many of the languages because reliable G2P resources are unavailable, whereas UR-BERT can still be used through Romanization. Across the reported languages, UR-BERT achieves the highest MOS in every case.
The objective metrics are mostly favorable as well, but not uniformly so for every language. This is worth emphasizing because it shows that subjective quality and some objective measures can diverge slightly on very small data sets. Even so, UR-BERT is consistently strong and often best on relative UTM degradation and relative CER degradation.
| Language | Setting | Model | MOS | Rel. UTM degradation | Rel. CER degradation | MCD | Log-F0 RMSE |
|---|---|---|---|---|---|---|---|
| Afrikaans | Seen by XPhoneBERT and UR-BERT | GT | 4.21 | - | - | - | - |
| Afrikaans | Seen by XPhoneBERT and UR-BERT | VITS | 2.80 | 0.59 | 26.03 | 6.41 | 0.127 |
| Afrikaans | Seen by XPhoneBERT and UR-BERT | XPhoneBERT | 2.85 | 0.38 | 18.54 | 6.25 | 0.122 |
| Afrikaans | Seen by XPhoneBERT and UR-BERT | UR-BERT | 3.34 | 0.37 | 15.82 | 6.09 | 0.121 |
| Khmer | Seen by XPhoneBERT and UR-BERT | GT | 3.58 | - | - | - | - |
| Khmer | Seen by XPhoneBERT and UR-BERT | VITS | 2.96 | 0.51 | 15.51 | 6.17 | 0.117 |
| Khmer | Seen by XPhoneBERT and UR-BERT | XPhoneBERT | 2.98 | 0.50 | 12.40 | 5.72 | 0.113 |
| Khmer | Seen by XPhoneBERT and UR-BERT | UR-BERT | 3.21 | 0.52 | 6.88 | 5.59 | 0.112 |
| Javanese | Seen only by UR-BERT | GT | 3.90 | - | - | - | - |
| Javanese | Seen only by UR-BERT | VITS | 2.80 | 0.61 | 23.50 | 6.42 | 0.107 |
| Javanese | Seen only by UR-BERT | UR-BERT | 3.05 | 0.52 | 28.03 | 6.64 | 0.105 |
| Nepali | Seen only by UR-BERT | GT | 4.35 | - | - | - | - |
| Nepali | Seen only by UR-BERT | VITS | 3.33 | 0.47 | 13.55 | 7.10 | 0.071 |
| Nepali | Seen only by UR-BERT | UR-BERT | 3.66 | 0.46 | 6.71 | 6.76 | 0.068 |
| Setswana | Seen only by UR-BERT | GT | 3.92 | - | - | - | - |
| Setswana | Seen only by UR-BERT | VITS | 2.51 | 0.78 | 32.27 | 5.38 | 0.118 |
| Setswana | Seen only by UR-BERT | UR-BERT | 2.92 | 0.77 | 25.50 | 5.13 | 0.113 |
| Xhosa | Seen only by UR-BERT | GT | 4.20 | - | - | - | - |
| Xhosa | Seen only by UR-BERT | VITS | 3.05 | 0.58 | 17.70 | 6.96 | 0.112 |
| Xhosa | Seen only by UR-BERT | UR-BERT | 3.48 | 0.54 | 10.74 | 6.13 | 0.106 |
| Sinhala | Seen only by UR-BERT | GT | 4.11 | - | - | - | - |
| Sinhala | Seen only by UR-BERT | VITS | 3.49 | 0.48 | 13.09 | 5.31 | 0.095 |
| Sinhala | Seen only by UR-BERT | UR-BERT | 3.82 | 0.39 | 9.49 | 4.75 | 0.091 |
| Sundanese | Zero-shot for UR-BERT | GT | 4.25 | - | - | - | - |
| Sundanese | Zero-shot for UR-BERT | VITS | 3.15 | 0.59 | 14.86 | 4.98 | 0.078 |
| Sundanese | Zero-shot for UR-BERT | UR-BERT | 3.43 | 0.47 | 13.46 | 5.08 | 0.077 |
Two notable nuances appear in the low-resource table. First, UR-BERT is not universally best on every objective metric for every language: for example, Javanese keeps better relative CER and MCD under VITS, while Sundanese keeps slightly better MCD under VITS. Second, despite those metric-level exceptions, UR-BERT still wins on MOS throughout and usually improves the most interpretable speech-quality and intelligibility indicators.
The zero-shot Sundanese result is important because Sundanese is excluded from the pretraining corpus. Even in that setting, UR-BERT outperforms VITS on MOS, relative UTM degradation, relative CER degradation, and log-F0 RMSE, showing that the Romanized representation transfers beyond the languages seen during pretraining.
Ablation on Speech Token Prediction
The paper’s ablation removes the STP objective and compares MOS. The overall pattern is clear: STP helps most languages, especially where the phonetic mapping is harder or the resource level is lower. The authors interpret this as evidence that STP counteracts the phonetic abstraction introduced by Romanization and stabilizes text-speech alignment.
| Language | MOS with STP | MOS without STP |
|---|---|---|
| English | 4.35 | 4.00 |
| German | 3.78 | 3.64 |
| Mandarin Chinese | 3.88 | 3.75 |
| Afrikaans | 3.34 | 3.04 |
| Khmer | 3.21 | 3.23 |
| Javanese | 3.05 | 2.65 |
| Nepali | 3.66 | 3.66 |
| Setswana | 2.92 | 2.70 |
| Xhosa | 3.48 | 3.34 |
| Sinhala | 3.82 | 3.52 |
| Sundanese | 3.43 | 3.41 |
The improvement is especially visible in English, Afrikaans, Javanese, Setswana, Xhosa, and Sinhala. There are two near-neutral cases: Khmer is very slightly better without STP in MOS, and Nepali is tied. Even with those exceptions, the overall trend supports the claim that acoustic-token prediction is useful for multilingual TTS pretraining.
Practical Implications and Limitations
The paper does not include a dedicated limitations section, but several practical constraints are clear from the method. UR-BERT still depends on paired speech-text corpora for pretraining, a pretrained multilingual speech teacher, and forced alignment through MMS-FA. It therefore removes the dependence on language-specific G2P toolkits, but not the dependence on substantial multilingual speech resources.
Another important tradeoff is that Romanization intentionally compresses the symbol inventory, which can blur pronunciation differences. STP is introduced specifically to recover some of that lost detail, but the reported results show that objective metrics can still vary by language, especially in very low-resource or zero-shot settings. The authors also note that they did not consider larger speech-token codebooks, because such codebooks may begin to encode speaker or paralinguistic information rather than the phonetic content needed for TTS.
So, the method is best understood as a scalable compromise: it sacrifices some phonemic specificity in exchange for language coverage and token efficiency, then partially restores acoustic fidelity through speech-aware pretraining.
Conclusion
UR-BERT is a multilingual TTS text encoder that combines universal Romanization with speech token prediction. The paper’s main contribution is a practical route to scaling text encoders to 495 languages without relying on per-language G2P systems, while still keeping the encoder speech-aware enough to support high-quality synthesis. In the reported experiments, UR-BERT improves MOS across high-resource, low-resource, and zero-shot languages, and it usually improves the objective metrics as well. The resulting system is presented as a building block for more universal and inclusive multilingual TTS.
Code & Implementation
This repository implements the UR-BERT model described in the paper, designed for massively multilingual text-to-speech (TTS) with universal Romanization and speech token prediction.
The codebase is organized into two main stages:
- Pretraining: This stage includes training the UR-BERT encoder using masked language modeling (MLM) and optionally MLM with distillation objectives. The relevant code is under the
pretraining/directory, including training scripts, configuration files, and preprocessing utilities. - Finetuning: This stage builds multilingual TTS models based on VITS architecture with various encoders such as UR-BERT, PLBERT, and XPhoneBERT. The finetuning scripts and configurations reside in the
finetuning/directory, which also includes inference capabilities for synthesized speech generation.
The repository provides a Hugging Face model export of the UR-BERT backbone for easy integration. The pretraining focuses on learning robust phonetic representations across 495 languages, while finetuning adapts the model for TTS tasks. Configuration files define experiment-specific parameters, facilitating repeatable trainings and evaluations.
Typical usage includes running train.py in pretraining/ for initial UR-BERT encoder training, followed by TTS model training using train.py in finetuning/, and finally speech synthesis via inference.py.