Speech-Text Alignment for Reasoning
Which Speech Representation Better Matches Text-Native Reasoning? A Study of Speech-Text Alignment on Frame Rate and Representation
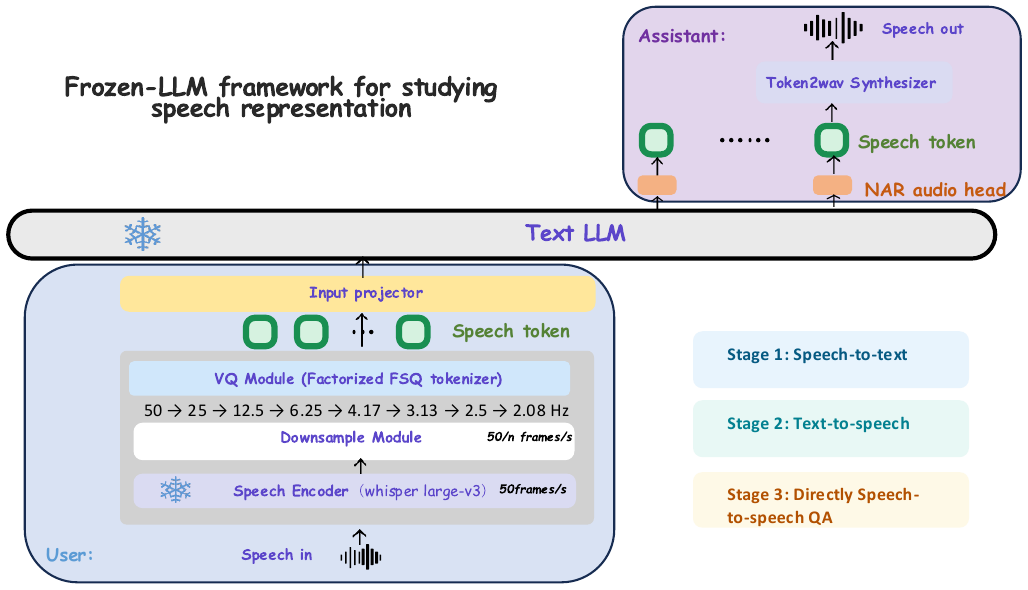
This paper studies how speech token design affects reasoning in frozen text LLMs by controlling frame rate and alignment. It introduces factorized quantization and a non-autoregressive audio head to enable efficient low-rate speech tokenization that aligns well with text embeddings for improved spoken dialogue.
Links
Paper & demos
Impact
Abstract
Spoken dialogue models typically start from text LLM backbones, yet reasoning often degrades when conditioning on speech instead of text. We attribute part of this modality gap to a temporal-granularity mismatch: speech tokens are temporally redundant and far longer than text under matched semantics, diluting per-token semantic density and weakening text-native reasoning dynamics. We study speech token design as a representation selection problem and sweep frame rates under a frozen LLM backbone with a fixed information rate. To make low frame rates feasible, we introduce factorized FSQ and a lightweight non-autoregressive audio LM head, scaling capacity to nearly 300\,bits/frame without sacrificing efficient prediction. With the bottleneck removed, we sweep frame rates (50$\rightarrow$2.08\,Hz) and alignment depth, and observe a consistent best regime for speech QA at 4.17\,Hz with intermediate-layer representation alignment.
Introduction
This paper studies a controlled version of the speech-to-dialogue problem: given a frozen text LLM backbone, what kind of speech representation best preserves the reasoning behavior that the backbone already has in text mode? The central observation is that spoken dialogue models often degrade when they are conditioned on speech rather than text, even when the underlying semantic content is the same. The authors argue that one important cause is a temporal-granularity mismatch: speech token streams are usually much longer than text token streams, so the LLM sees many more positions carrying redundant information. Under a frozen backbone, that redundancy weakens the per-token semantic density and interferes with the text-native reasoning dynamics the model was pretrained on.
Rather than fine-tuning the full LLM, the paper treats speech token design as a representation selection problem. The backbone is fixed, the information rate is held constant at $600$ bits/s, and the key variables are the speech token frame rate and the layer at which speech and text representations are aligned. This makes it possible to attribute performance changes to the speech representation itself rather than to backbone adaptation.
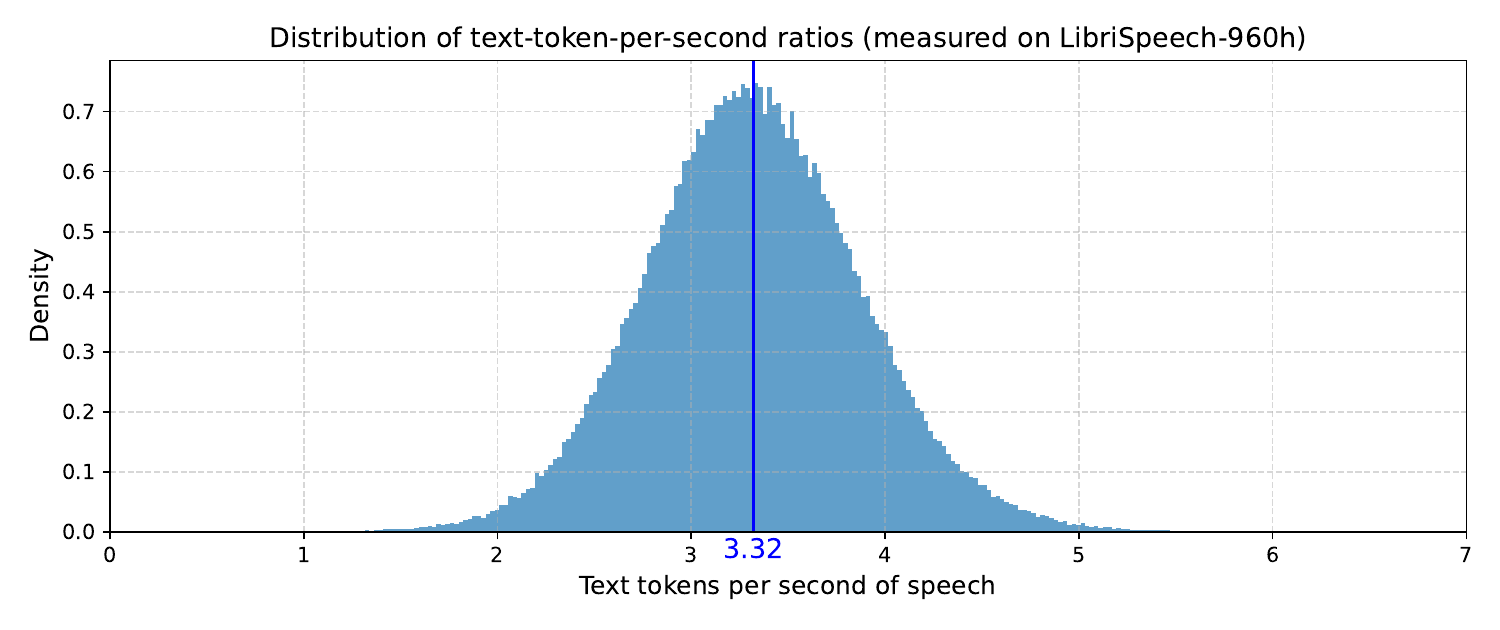
The paper’s main empirical claim is that speech QA works best in a moderately low-rate regime, not at the highest-rate tokenization used by many prior systems. After removing the bottleneck that normally prevents low-rate tokenization, the authors sweep frame rates from $50$ Hz down to $2.08$ Hz and find that the most consistent sweet spot is around $4.17$ Hz, with intermediate-layer contrastive alignment. This is slightly above the average text token rate they measure on LibriSpeech, $3.32$ Hz, and they argue that the extra margin helps accommodate utterance-level variation in speaking rate and token length.
Problem Setup and Core Hypothesis
The paper focuses on frozen-LLM spoken dialogue. This is important because freezing the LLM isolates the speech representation as the main design knob. In that setting, the authors identify two linked questions:
- Length alignment: how should the speech token frame rate relate to the text token rate?
- Representation alignment: at what depth in the LLM should speech and text embeddings be pulled together?
They measure the average text token rate on LibriSpeech-960h using the Qwen3 tokenizer and report a mean of about $3.32$ tokens/s. Typical speech tokenizers operate at $12.5$--$50$ Hz, which makes speech sequences dramatically longer than the corresponding text. The authors claim that this is a semantic-density problem: when speech is represented with too many tokens, each token carries less meaning, and self-attention is forced to process long runs of low-information positions.
Their working hypothesis is that a speech representation closer in temporal granularity to text should better match text-native reasoning, but only if the low-rate representation can still carry enough information. That is the motivation for their new tokenizer and audio prediction head.
Architecture Overview
The system uses a frozen Whisper-Large-v3 encoder to extract $50$ Hz speech features, then downsamples them to a target frame rate, quantizes them with factorized finite scalar quantization (FSQ), and projects the resulting speech tokens into a frozen Qwen3 text LLM. For generation, a lightweight non-autoregressive (NAR) audio head predicts speech tokens in parallel. Only the input projector, downsampling/quantization-related components, and the NAR head are trained; the text LLM backbone remains frozen.
The architecture is built to support a pure speech-token dialogue system, meaning it can perform speech-to-text understanding, text-to-speech token generation, and speech-to-speech QA without first translating everything into text as an intermediate representation.
Length Alignment: Why Frame Rate Matters
The first experimental question is whether reducing the speech frame rate toward the text token rate improves compatibility with a frozen LLM. The paper argues that frame rate should be treated as a first-class design variable rather than a fixed hyperparameter, because it changes both sequence length and per-token semantic density.
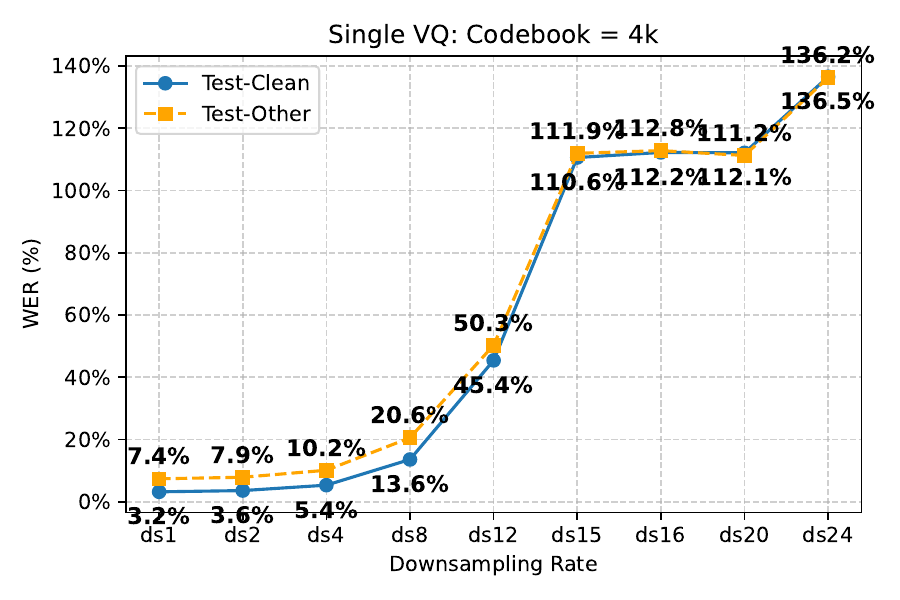
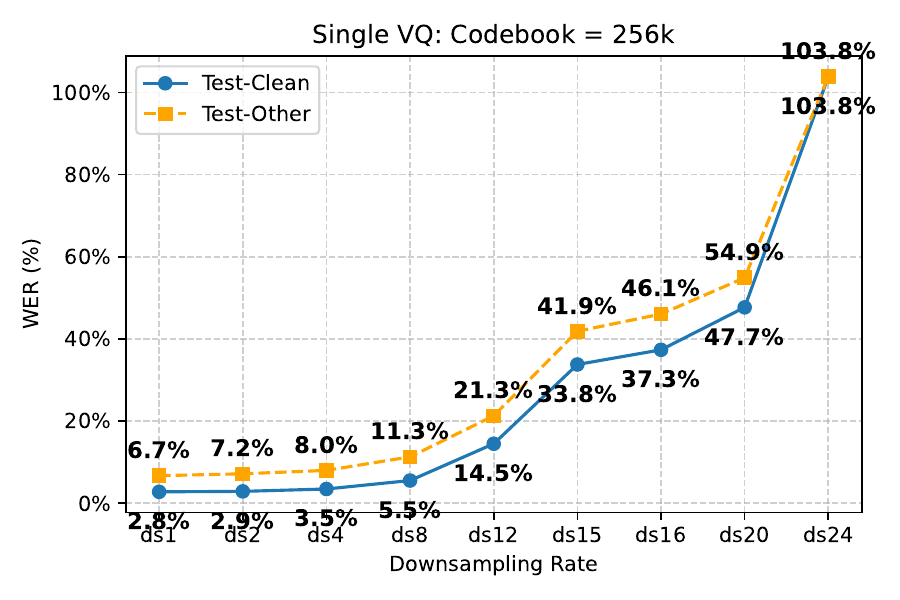
To show that standard low-rate tokenization is not straightforward, the authors run a controlled ASR experiment using Whisper-Large-v3 features downsampled at various rates and then quantized with a standard single-codebook setup. They report that with a $4$k codebook ($2^{12}$), WER deteriorates sharply once the downsampling rate exceeds $4\times$ (below $12.5$ Hz). Even enlarging the codebook to $262$k ($2^{18}$) does not keep WER acceptable below $8\times$ (below $6.25$ Hz). This shows that simply lowering frame rate under a standard single-codebook, single-head design causes a severe information bottleneck.
Factorized FSQ for Low-Rate Tokenization
To remove this bottleneck, the authors keep the LLM frozen but redesign the speech tokenizer and prediction head. They use factorized FSQ, which exploits the fact that each dimension of a feature vector can be scalar-quantized independently. Instead of predicting from an exponentially large monolithic codebook, they split the feature dimensions into $n$ groups and predict each group in parallel.
Let $z_t \in \mathbb{R}^d$ be the downsampled speech feature at frame $t$, split into $n$ groups $z_t^{(g)} \in \mathbb{R}^{d_g}$ with $d = n d_g$. Each scalar is quantized as
$$q_{t,g,k} = Q\left(z^{(g)}_{t,k}\right) \in \{0,1,\ldots,L-1\}, \quad k=1,\ldots,d_g.$$
The group token is then represented as a mixed-radix index
$$y_{t,g} = \sum_{k=1}^{d_g} q_{t,g,k} L^{k-1}, \qquad K = L^{d_g}.$$
This yields a per-frame capacity of $n \log_2 K$ bits and an implicit codebook size of $K^n = L^d$, while avoiding the explicit parameter explosion of a single softmax over $L^d$ classes. At inference, each predicted group token is deterministically dequantized by recovering the scalar codes, mapping them back through the inverse FSQ levels, and concatenating the group vectors.
In other words, the paper’s trick is not merely to enlarge the vocabulary, but to factorize the vocabulary so that low-rate tokenization becomes computationally feasible.
Lightweight NAR Audio Head
Even with factorized FSQ, a low frame rate implies that each frame must carry substantial information. A plain linear classifier is not expressive enough, so the authors replace the standard linear head with a lightweight NAR transformer consisting of two transformer layers with hidden size matched to the LLM. The head processes all group queries in parallel and models inter-group dependencies before prediction.
For each frame position, if $h_t \in \mathbb{R}^H$ is the frozen LLM hidden state, the model creates group-specific queries using learned slot embeddings $s_g$:
$$u_{t,g} = h_t + s_g, \qquad g = 1,\ldots,n.$$
The NAR head outputs $v_{t,g}$ for each group, and a shared classifier predicts the next-step token for each group:
$$\ell_{t,g} = W v_{t,g} + b, \qquad p(y_{t+1,g} = k \mid h_t) = \operatorname{softmax}(\ell_{t,g})_k.$$
Training uses causal next-token prediction with teacher forcing:
$$\mathcal{L}_{\text{audio}} = - \sum_{t=1}^{T-1} \sum_{g=1}^{n} \log p(y^\star_{t+1,g} \mid h_t).$$
The authors fix the overall information rate as
$$R = r\, n\, \log_2 K,$$
where $r$ is the frame rate. In practice, they keep $K$ fixed per group and vary $n$ to maintain a constant throughput of $600$ bits/s across the frame-rate sweep.
Representation Alignment: Matching Speech and Text Hidden States
Once sequence length is brought closer to text, the authors argue there can still be a semantic mismatch between speech and text representations inside the LLM. To address this, they add a contrastive alignment loss that explicitly pulls speech and text utterance embeddings together in the same latent space.
Crucially, alignment is applied at an intermediate hidden layer rather than only at the input embedding layer. The paper’s reasoning is that the embedding space is already partially handled by the input projector, while deeper layers contain more meaningful semantic structure. Intermediate layers may therefore provide a better tradeoff between semantic abstraction and task relevance.
For each speech-text pair, the hidden states at a selected layer $\ell$ are temporally averaged and L2-normalized to obtain vectors $\hat{h}_s$ and $\hat{h}_t$. The alignment objective is InfoNCE with temperature $\tau = 0.07$:
$$\mathcal{L}_{\text{align}} = - \sum_{i=1}^{B} \log \frac{\exp\left(\langle \hat{h}_{s,i}, \hat{h}_{t,i} \rangle / \tau\right)}{\sum_{j=1}^{B} \exp\left(\langle \hat{h}_{s,i}, \hat{h}_{t,j} \rangle / \tau\right)}.$$
The final loss is
$$\mathcal{L} = \mathcal{L}_{\text{CE}} + \lambda_{\text{align}}\, \mathcal{L}_{\text{align}},$$
with $\lambda_{\text{align}} = 0.1$. Gradients from the alignment term flow only through the speech pathway; the frozen backbone receives no updates.
Training Pipeline and Experimental Setup
The paper uses a three-stage progressive pipeline: speech-to-text (ASR), text-to-speech token generation (TTS), and speech-to-speech QA. This design is meant to probe complementary aspects of the speech representation: understanding, generation, and end-to-end spoken QA. In all stages, the same frozen text LLM backbone is retained.
- Stage 1: Speech-to-text. Train the downsampling layer, FSQ, and input projector so that the frozen LLM decodes text from speech tokens.
- Stage 2: Text-to-speech. Reuse the tokenizer established in Stage 1, freeze it, and train the input projector plus NAR audio head so the LLM generates speech tokens from text.
- Stage 3: Speech-to-speech QA. Initialize from Stage 2 and train on speech QA with a multi-task objective combining speech-to-speech QA, speech-to-text QA, and text-to-speech QA.
The backbone is Qwen3-4B for the main experiments, and the paper also reports a Qwen3-8B variant. The speech encoder is Whisper-Large-v3, producing $50$ Hz features. The authors test downsampling factors of $1\times$, $2\times$, $4\times$, $8\times$, $12\times$, $16\times$, $20\times$, and $24\times$, corresponding to $50$, $25$, $12.5$, $6.25$, $4.17$, $3.13$, $2.5$, and $2.08$ Hz.
The trainable parameter count is about $100$M for the 4B backbone configuration and about $150$M for the 8B configuration, while the LLM itself stays frozen. The paper emphasizes that this makes the study a low-parameter adaptation of a large text model rather than full-model speech pretraining.
Speech-to-Text: ASR Results and Reconstruction Quality
In the ASR stage, the model is trained on LibriSpeech-960h for $5$ epochs with AdamW and a learning rate of $3 \times 10^{-4}$, using linear warmup over the first $3\%$ of steps. The authors use transcripts from LibriSpeech-PC that preserve capitalization and punctuation, rather than normalized transcripts, because they found text normalization hurts downstream speech-to-speech QA transfer by removing textual patterns learned by the LLM.
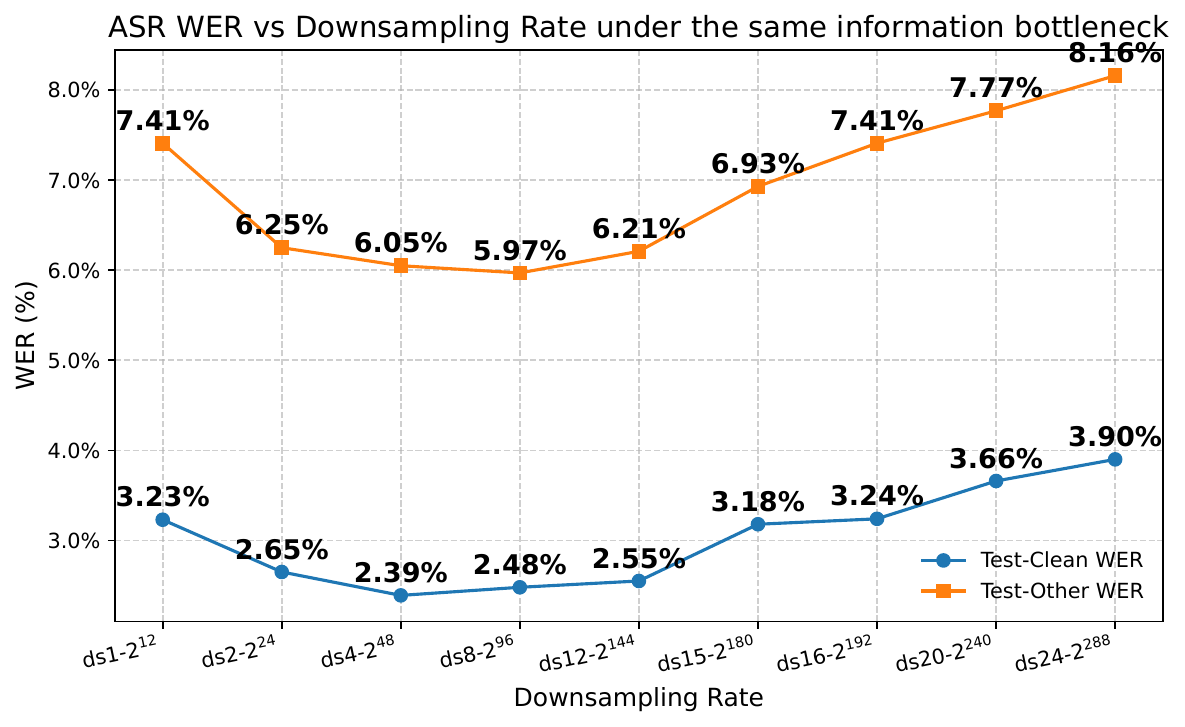
When the factorized tokenizer is used under a fixed bitrate of $600$ bits/s, ASR WER remains in a relatively narrow band across frame rates: roughly $5.97$--$8.16$ on test-other and $2.39$--$3.90$ on test-clean. This is the key evidence that factorized FSQ removes the low-rate information bottleneck.
The ASR curve is not monotonic. Instead, the paper reports a U-shaped trend: performance worsens when the sequence is very long because the LLM must process many redundant frames, and it also worsens when the sequence becomes too short because each token has too much information to encode. The best ASR region is in the intermediate frame-rate range, especially around $12.5$, $6.25$, and $4.17$ Hz.
The paper also evaluates tokenizer reconstruction using a token-to-waveform system on SeedTTS test-en. It reports three metrics: WER, speaker similarity (SIM, using cosine similarity between WavLM-TDNN embeddings), and UTMOS for speech quality. The results show that the proposed tokenizer remains reconstructable even at low frame rate.
| Tokenizer | WER ↓ | SIM ↑ | UTMOS ↑ |
|---|---|---|---|
| CosyVoice2 (25 Hz) | 4.10 | 0.68 | 3.65 |
| Ours (25 Hz) | 3.04 | 0.67 | 3.71 |
| Ours (4.17 Hz) | 3.37 | 0.65 | 3.79 |
The authors interpret these results as showing that the lower frame rate does not create an inherent reconstruction bottleneck. At $25$ Hz, their tokenizer improves WER and UTMOS over the CosyVoice2 baseline, and even at $4.17$ Hz it keeps strong speech quality and speaker similarity. The explanation they give is that the factorized FSQ representation can allocate substantially more discrete capacity per frame than the CosyVoice2 semantic-token baseline.
Text-to-Speech: Why Low Rates Become Harder for Generation
In the TTS stage, the LLM receives text tokens and must generate speech tokens. The tokenizer from ASR is reused and frozen, and only the projector and NAR audio head are trained. This stage is especially informative because it tests whether the frozen LLM can produce the high-density speech token stream, not just read it.
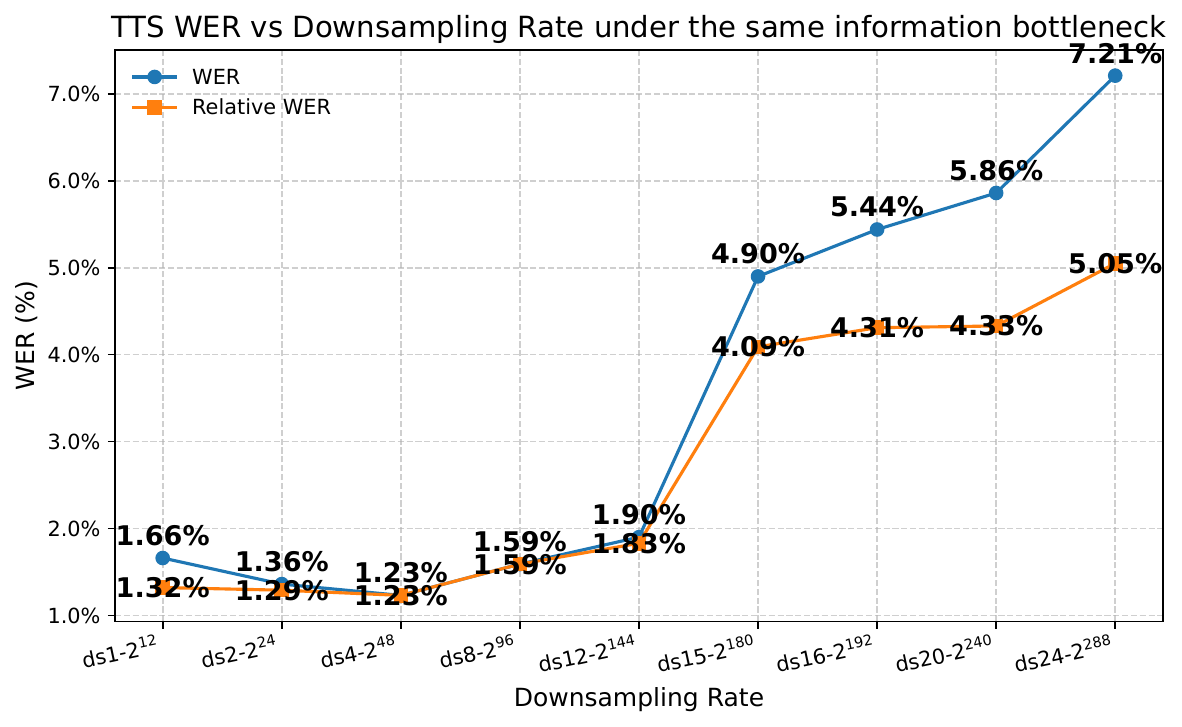
A crucial ablation shows that the NAR transformer in the audio head is not optional. At $4.17$ Hz, removing the NAR component and using a linear head increases WER from $1.83/1.90$ to $10.17/12.73$ on test-clean/test-other. This indicates that inter-group dependencies matter strongly when each frame must carry many bits of information.
| Head | test-clean ↓ | test-other ↓ |
|---|---|---|
| Linear (without NAR) | 10.17 | 12.73 |
| NAR (ours) | 1.83 | 1.90 |
The TTS curve is monotonic: as downsampling increases and the frame rate decreases, WER gets worse. The paper emphasizes that once the speech sequence becomes shorter than the average text length, the frozen LLM struggles to generate such high-density tokens. This differs from ASR, where the LLM can still aggregate semantics from redundant long sequences; generation is more fragile because every token index must be produced correctly.
Speech-to-Speech QA: The Main End-to-End Task
The main evaluation target is speech-to-speech QA. The authors train on the InstructS2S-200k dataset, which they say contains $1{,}500$ hours of speech QA data. Training lasts $3$ epochs with learning rate $10^{-4}$. The loss combines speech-to-speech QA as the primary objective with speech-to-text QA and text-to-speech QA as auxiliary tasks; the speech-to-text auxiliary loss has weight $5$, and the other tasks have weight $1$. The alignment loss is used throughout training.
Evaluation is carried out on questions from Web Questions, Llama Questions, and TriviaQA, following prior work. The model decodes its speech-token answer into text using the Stage 1 ASR model, and GPT-4o judges correctness against the ground-truth answer.
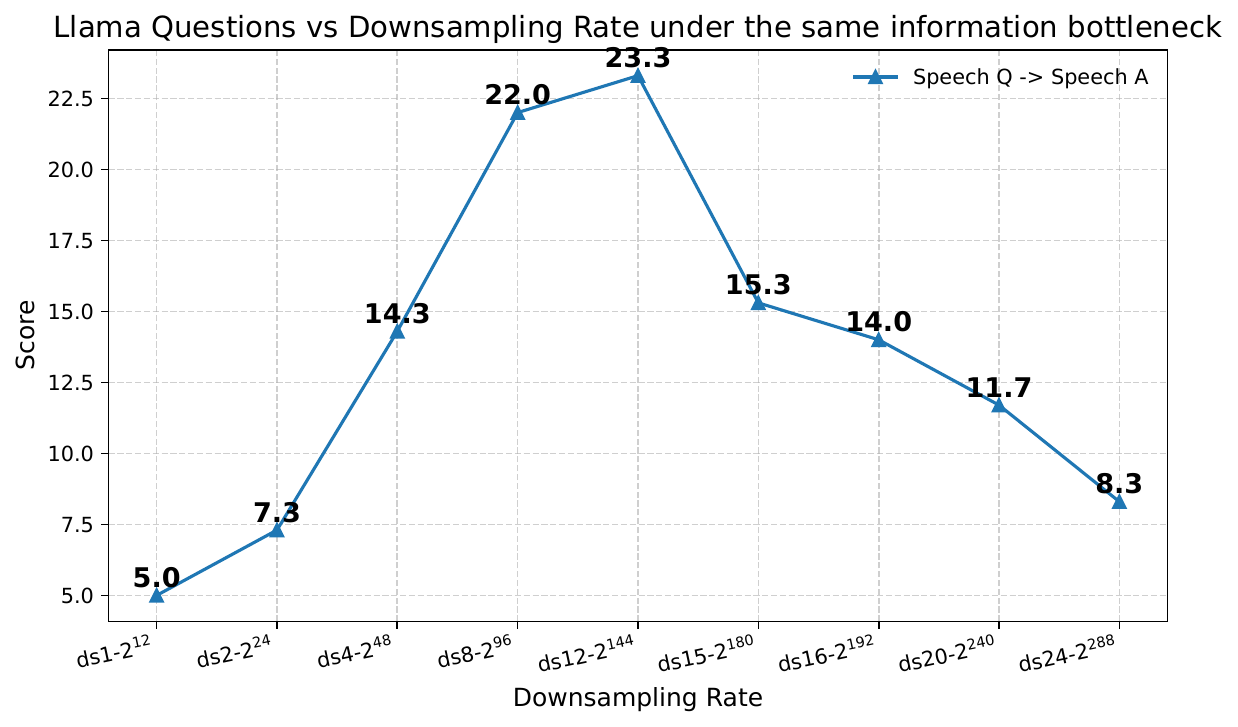
The resulting QA curve is inverted-U shaped: performance rises as the frame rate is reduced from very high values, peaks around $4.17$ Hz and $6.25$ Hz, and then falls again at very low rates. The poor result at $50$ Hz is especially important: even though ASR and TTS can each work reasonably well there, the spoken QA task is weak because the sequence is about $15\times$ longer than the text counterpart, making reasoning over speech tokens difficult for the frozen LLM.
The best result is not exactly at the average text rate of $3.32$ Hz, but slightly above it at $4.17$ Hz. The authors explain this using utterance-length variability: if the system matches the average exactly, shorter utterances can fall below the LLM’s tolerance range. A slightly higher frame rate leaves a buffer that keeps most utterances within the LLM’s usable sequence-length window.
Why 4.17 Hz Can Beat the Average Text Rate
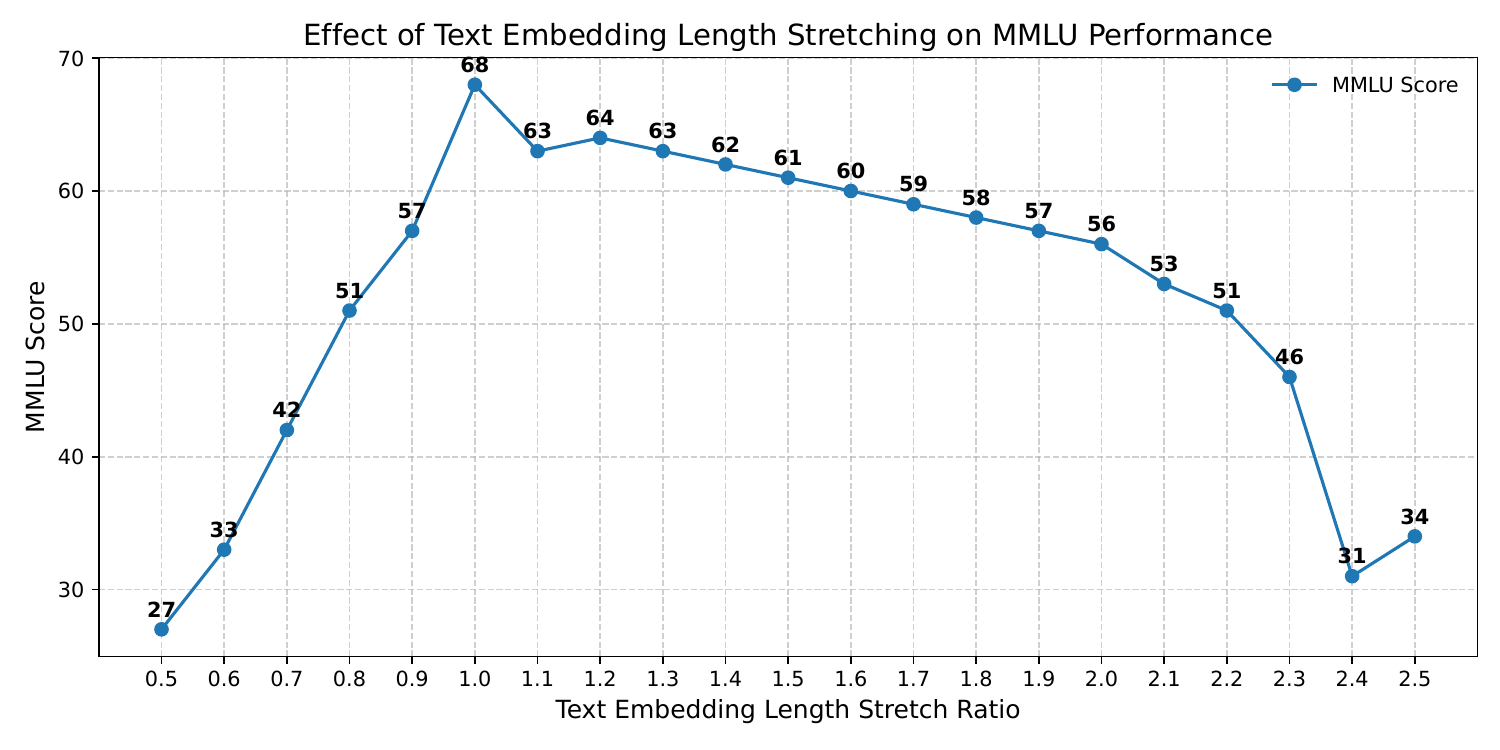
To support the claim that sequence length tolerance is part of the explanation, the paper performs an auxiliary analysis by stretching Qwen3-4B text embeddings and evaluating MMLU. Accuracy stays above $50\%$ for scaling factors between $0.8\times$ and $2.2\times$, but drops sharply below $0.8\times$. This suggests that the backbone tolerates some length variation, but not too much compression.
That result is used to explain why $3.13$ Hz can be too short for many utterances, while $4.17$ Hz and $6.25$ Hz stay within the backbone’s empirically measured tolerance range. In other words, matching the mean text rate is not enough; the system should target a rate that covers the utterance distribution.
Representation Alignment Experiments
The second main axis of the study is representation alignment depth. The authors test alignment at the input embedding layer, an early layer at $L/4$, a middle layer at $L/2$, and a late layer at $3L/4$, using the $4.17$ Hz setting. The result is clear: intermediate-layer alignment is best.
On Llama Questions, the scores are $23.3$ with no alignment, $21.7$ with embedding-level alignment, $25.0$ with $L/4$, $30.7$ with $L/2$, and $27.7$ with $3L/4$. This makes the middle layer the strongest by a meaningful margin. The authors interpret this as evidence that the most transferable semantic information lives in intermediate layers, while embedding-level alignment is too shallow and late-layer alignment is too specialized to text generation.
| None | Emb | $L/4$ | $L/2$ | $3L/4$ |
|---|---|---|---|---|
| 23.3 | 21.7 | 25.0 | 30.7 | 27.7 |
This layer-wise result is one of the paper’s clearest design recommendations: if the goal is to help speech tokens match text-native reasoning, alignment should not stop at the input space. Instead, the speech pathway should be encouraged to land in the LLM’s semantic middle ground, where representations are neither too raw nor too task-specialized.
Speech Encoder Ablation
The authors also test whether the framework depends on a specific frozen speech encoder. Using the same $4.17$ Hz setup with middle-layer alignment, they compare Whisper-Large-v3, HuBERT-Large, and WavLM-Large on Llama Questions. Whisper-Large-v3 performs best, which the paper attributes to its ASR-supervised features being closer to text semantics.
| Speech encoder | Llama Q. |
|---|---|
| Whisper-Large-v3 | 30.7 |
| HuBERT-Large | 25.7 |
| WavLM-Large | 27.3 |
The important takeaway is not that Whisper is the only viable encoder, but that the overall frame-rate/alignment story holds across multiple speech encoders. Stronger encoders help, but the representation-selection conclusions still apply.
Comparison with Other Spoken Dialogue Systems
The paper compares its pure speech-token QA system against prior work, emphasizing that the comparison is at the level of speech-to-speech generation rather than thinker-talker pipelines that first produce text answers. The authors explicitly avoid direct comparison with systems that rely on text guidance because that changes the task definition.
The reported comparison shows that a $4$B frozen-backbone model with about $100$M trainable parameters and only $2.5$k hours of data can outperform Moshi on all three QA benchmarks, despite Moshi using a $7$B backbone, $7$M hours of data, and full-parameter training. The $8$B variant further closes the gap to much larger interleaved-training systems.
| Model | Train Params | Data | Web Q. | Llama Q. | Trivia QA |
|---|---|---|---|---|---|
| Moshi 7B | 7B | 7M hrs | 9.2 | 21.0 | 7.3 |
| Scaling Interleave 9B (600B tok) | 9B | 600B tok | 15.9 | 50.7 | 26.5 |
| Scaling Interleave 9B (200B tok) | 9B | 200B tok | 13.3 | 44.0 | 18.7 |
| Scaling Interleave 9B (100B tok) | 9B | 100B tok | 9.3 | 37.0 | 11.7 |
| Ours 4B | $\sim$100M | 2.5k hrs | 7.9 | 30.7 | 11.9 |
| Ours 8B | $\sim$150M | 2.5k hrs | 12.2 | 39.3 | 17.6 |
The 8B version improves substantially over the 4B version, with gains of $+4.3$ on Web Questions, $+8.6$ on Llama Questions, and $+5.7$ on Trivia QA. The paper uses this to argue that stronger backbones can be swapped in without changing the overall framework, since the speech side is trained with only a relatively small number of parameters.
Key Findings and Interpretation
- Frame rate is highly consequential. Under the same $600$ bits/s budget, QA can differ by up to roughly $4\times$ across frame rates.
- The best range is intermediate. For speech QA, the strongest regime is consistently around $4.17$--$6.25$ Hz.
- Matching the average text rate is not enough. The average text token rate is $3.32$ Hz, but the best result is slightly above that because utterance-length variance matters.
- Factorized FSQ removes the low-rate bottleneck. It lets the model allocate high effective capacity per frame without a monolithic huge softmax.
- The NAR head is essential. Inter-group dependencies matter a lot once each frame carries high information density.
- Intermediate-layer alignment is best. Aligning at $L/2$ is better than aligning at the input embedding or later layers.
- Length and representation alignment are complementary. Structural alignment of sequence length and semantic alignment of hidden states work together.
The paper’s conceptual framing is that a text LLM is pretrained to reason over a single discrete stream with text-like granularity. If speech tokens are too long, they are wasteful and noisy; if they are too compressed, they become hard to predict. The solution is to find a middle ground where speech token rate roughly matches the LLM’s native temporal expectations, while also aligning the latent space where the reasoning happens.
Limitations
The paper is explicit about several limitations. First, the comparisons against prior systems are not perfectly controlled because the baselines use different backbones and the original training code/data are not publicly available, so the comparison is more about data efficiency than method-to-method equivalence. Second, the LLM backbone is frozen, which may cap performance relative to fully fine-tuned models. Third, the experiments are limited to English read speech and the InstructS2S-200k QA setting, so robustness on noisy, conversational, or multilingual speech is not demonstrated. Fourth, the main conclusions are based on Qwen3-4B and Qwen3-8B; transfer to other LLM families is plausible but not proven. Finally, the speech side relies on Whisper-Large-v3 features and does not address acoustic modeling in a broader sense.
Conclusion
The paper presents a controlled study of speech representation choice for frozen-LLM spoken dialogue. Its central result is that the best match to text-native reasoning is not the highest-rate speech tokenization, but a moderately compressed one: about $4.17$--$6.25$ Hz under a fixed $600$ bits/s budget. This regime is enabled by factorized FSQ and a lightweight NAR audio head that together make low-rate prediction feasible. On top of that, the strongest gains come from intermediate-layer contrastive alignment, especially at $L/2$. The overall message is practical: if the goal is to make speech behave more like text for a pretrained LLM, then one should compress redundant temporal detail, preserve enough capacity per frame, and align speech and text in the middle of the model where semantics are richest.