PRISM
PRISM: Prosody-Integrated Multi-Agent Reasoning Framework for Empathetic Spoken Dialogue
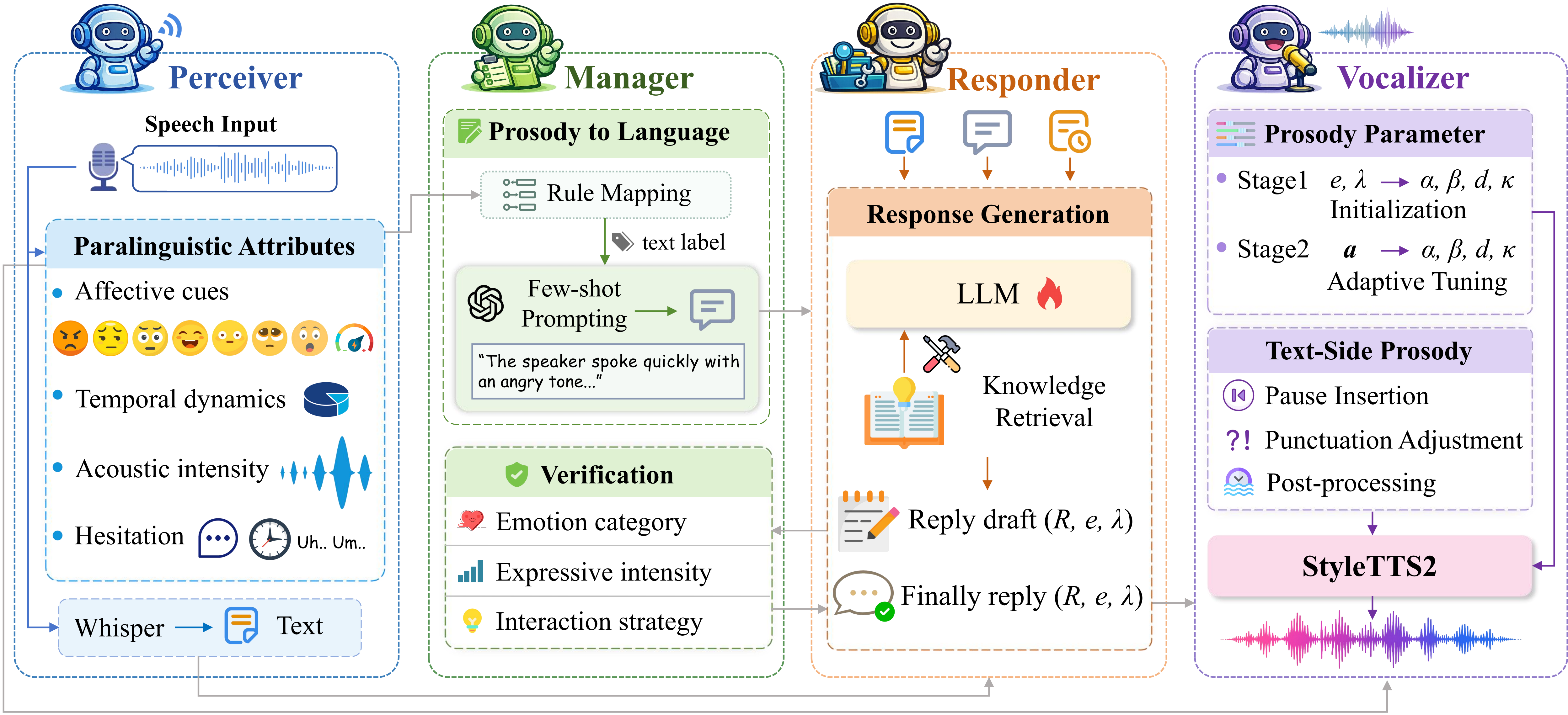
PRISM is a multi-agent empathetic spoken dialogue framework that integrates prosody in reasoning for emotionally aligned responses. It decouples speech perception, dialogue management, response generation, and speech synthesis to produce empathetic conversations with interpretable prosody and knowledge control.
Demos
The demos showcase PRISM's ability to produce empathetic spoken dialogue by combining multi-agent reasoning and prosody-aware speech synthesis. Evaluate how well the system preserves emotional prosody and generates contextually fitting, empathetic responses. Notice the clear, emotionally aligned speech output that integrates prosodic cues beyond text.
Links
Paper & demos
Code & resources
Impact
Abstract
Empathetic spoken dialogue systems require not only semantically appropriate responses but also emotionally aligned prosodic expression. However, cascade pipelines often discard acoustic cues during speech-to-text conversion, while end-to-end speech models lack interpretable control over emotion and knowledge integration. To address these challenges, we propose PRISM, a multi-agent framework for empathetic spoken dialogue that decouples speech perception, response generation, and speech synthesis into coordinated components. PRISM introduces a prosody-to-language translation mechanism to stabilize large language model reasoning and enables on-demand invocation of external knowledge tools for empathetic dialogue generation. Experimental results demonstrate that PRISM achieves consistent improvements in empathy, prosodic appropriateness, and text response generation quality across objective and subjective metrics. Our code is available at: https://github.com/Bxzfrm/PRISM.
Introduction
PRISM targets empathetic spoken dialogue, where a system must do more than produce semantically correct text: it must also generate speech whose prosody matches the user’s emotional state and conversational context. The paper motivates the work by contrasting two dominant paradigms. In a classic cascade pipeline ($\text{ASR} \rightarrow \text{text dialogue} \rightarrow \text{TTS}$), transcribing speech to text tends to discard acoustic and paralinguistic cues, so empathy is often preserved only at the text level. In end-to-end speech models, by contrast, prosody and emotion are usually latent and difficult to control or interpret, and it is harder to inject new knowledge or explicit reasoning strategies without extensive retraining.
The paper’s central claim is that these issues can be reduced by splitting the system into specialized agents that communicate through structured intermediate representations. PRISM stands for Prosody-Integrated Multi-Agent Reasoning Framework (the paper also describes it as a prosody-aware, feedback-driven coordination architecture). It decouples: (1) speech perception, (2) dialogue management and prosody interpretation, (3) response generation with optional knowledge augmentation, and (4) speech synthesis with explicit emotional control. The authors present PRISM as a framework for turning raw speech into empathetic responses while keeping the decision process interpretable and flexible.
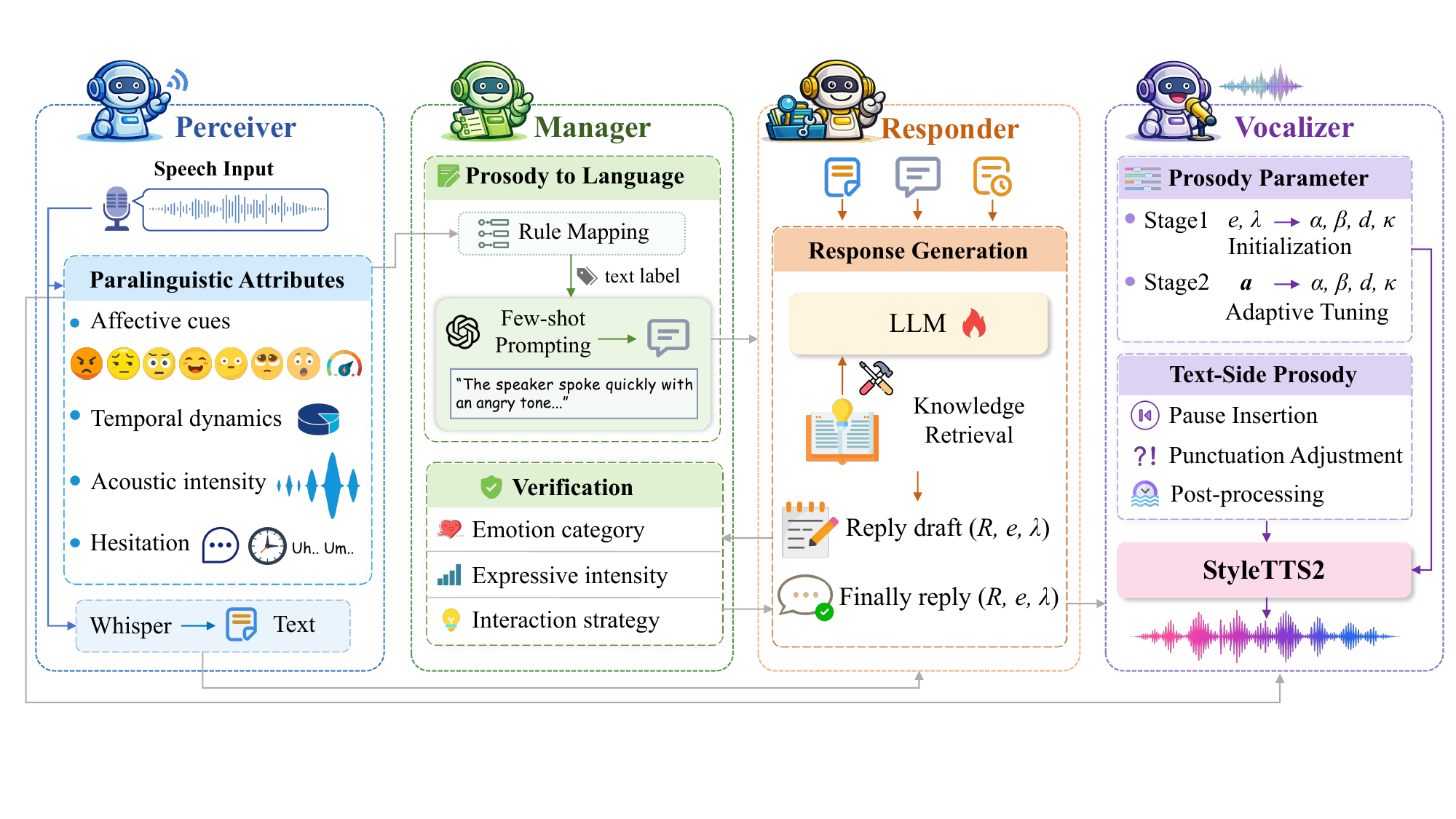
Problem Setting and Core Idea
The task is empathetic spoken dialogue generation: given a user’s spoken utterance and dialogue history, the system should understand not only the transcript but also affective and expressive cues, decide whether external commonsense knowledge is useful, generate an empathetic response, and synthesize that response in a matching speaking style. The paper argues that the key technical difficulty is not just recognition of content, but the integration of prosodic perception, emotional reasoning, knowledge use, and expressive generation without losing information in between modules.
PRISM’s main design principle is to translate low-level speech characteristics into a language-level description of prosody. This prosody-to-language translation acts as a stable intermediate representation for the large language model, making the user’s emotional and expressive state easier to reason about. The framework also supports on-demand tool invocation for knowledge augmentation, allowing the responder to retrieve commonsense information when needed rather than always or never using external knowledge.
Method
PRISM consists of four modules: Perceiver, Manager, Responder, and Vocalizer. The modules are coordinated in a multi-agent manner, with the Manager mediating between speech perception and the response/synthesis side.
Perceiver: speech transcription and paralinguistic state extraction
For an input speech signal $x$, the Perceiver produces a structured state $s = \{T, \mathbf{a}\}$, where $T$ is the transcript and $\mathbf{a}$ is a set of paralinguistic attributes. The attributes cover four categories:
- Affective cues: an utterance-level emotion label and its confidence score.
- Temporal dynamics: speaking rate and pause ratio.
- Acoustic intensity: energy statistics such as mean and standard deviation of RMS energy.
- Disfluency-related cues: filler rate and a heuristic expression-certainty score.
The implementation uses OpenAI Whisper for transcription and FunASR emotion2vec for utterance-level emotion recognition. The emotion recognizer outputs one of ten labels: angry, disgusted, fearful, happy, neutral, other, sad, surprised, melodious, or unknown, together with a top-1 confidence score. Speech is resampled to 16 kHz, and WebRTC voice activity detection is used to estimate speech and silence durations.
The paper defines speaking rate as
$$r = \frac{N_{\text{tok}}(T)}{t_{\text{sp}}},$$
where $N_{\text{tok}}(T)$ is the number of transcript tokens and $t_{\text{sp}}$ is the speech duration. Disfluency is quantified with filler rate
$$f = \frac{N_f}{\max\left(N_{\text{tok}}(T), 1\right)},$$
where $N_f$ is the count of predefined filler expressions. For the certainty score, the paper normalizes speaking rate, pause ratio, and filler rate as
$$\tilde{r} = \operatorname{clip}\left(\frac{r - 2}{4}, 0, 1\right), \quad \tilde{p} = \operatorname{clip}(p, 0, 1), \quad \tilde{f} = \operatorname{clip}\left(\frac{f}{0.2}, 0, 1\right),$$
and then combines them into
$$c = \operatorname{clip}\left(0.55\,\tilde{r} + 0.25\,(1 - \tilde{p}) + 0.20\,(1 - \tilde{f}), 0, 1\right).$$
The resulting state is intended to compactly capture not only what was said, but also how it was said, in a form usable by later modules.
Manager: prosody-to-language translation and response verification
The Manager is the central coordination module. It performs two main functions.
First, prosody-to-language translation. The Manager converts the structured paralinguistic attributes into a concise natural-language description $D$. The transformation is two-stage: numerical attributes are first mapped to descriptive labels using rule-based thresholds, then a large language model is prompted in a few-shot setting to produce a coherent description. The paper emphasizes that this intermediate description makes prosodic information interpretable and easier for the responder to reason over than raw numeric cues.
Second, response-level verification. A lightweight alignment-check module examines whether the generated response matches the prosodic description in emotion category, expressive intensity, and interaction strategy. If mismatches are detected, the module supplies minimal revision suggestions. The paper presents this as a post-hoc stabilization mechanism rather than a heavyweight constrained decoding method.
Responder: empathetic generation with optional knowledge use
The Responder generates the final response text $R$ and also predicts the target emotion category $e$ and expressive intensity $\lambda$ for downstream synthesis control. Its inputs are the current transcript $T$, the prosody description $D$, and dialogue history $H$.
A key design choice is that the model jointly decides whether external knowledge is needed and how to integrate it, instead of splitting tool selection and response generation into rigidly separate stages. When the model judges that commonsense or contextual enrichment is helpful, the system retrieves multi-dimensional commonsense information through external tools and injects it into the generation context in textual form. The paper notes that this architecture enables plug-and-play knowledge updates by changing the external tools without retraining the base model.
The paper does not introduce a new learning objective for the responder beyond fine-tuning the underlying language model on the relevant dialogue data; rather, it uses the model’s instruction-following and tool-calling ability to decide when to use knowledge and how to compose an empathetic response.
Vocalizer: expressive speech synthesis with adaptive control
The Vocalizer converts the text response into speech using StyleTTS2, a diffusion-based TTS model that supports reference-based voice cloning and controllable prosody. The synthesis control is expressed through four parameters: timbre similarity $\alpha$, prosody strength $\beta$, number of diffusion refinement steps $d$, and expressive scaling factor $\kappa$.
These are computed as
$$\left(\alpha, \beta, d, \kappa\right) = V(e, \lambda, \mathbf{a}).$$
The paper describes a two-stage process. First, base values are initialized from the responder’s target emotion $e$ and intensity $\lambda$. Higher intensity leads to stronger prosodic variation and more refinement steps, while lower intensity produces flatter and more neutral delivery. Then the user’s paralinguistic attributes $\mathbf{a}$ are used to adapt those values. For example, if the user exhibits low certainty or frequent pauses, the model reduces prosody strength and expressive scaling to create a gentler delivery; if strong negative emotion is detected, prosody strength is increased to better match the empathetic requirement.
The Vocalizer also includes text-side shaping and post-processing: pause markers can be inserted for users who pause often, punctuation can be adjusted to intensify positive emotion or calm sad/soothing responses, and optional time-stretching or amplitude scaling can be applied after synthesis.
Experimental Setup
Datasets
The paper uses two datasets in the overall system description and evaluation:
- TOOL-ED: a tool-augmented extension of the ED dataset for empathetic dialogue with external knowledge annotations. It contains dialogue context, empathetic responses, and labels indicating whether external knowledge should be invoked.
- AvaMERG: a multimodal empathetic dialogue dataset extending ED with speech and facial-expression annotations. The experiments evaluate on the standard audio-subset split of AvaMERG.
According to the implementation details, the responder models are fine-tuned on TOOL-ED, while the baselines are fine-tuned on the AvaMERG training set using their original recommended hyperparameters or official implementations.
Baselines
The paper compares PRISM against several representative systems:
- ASR+LLM: a cascade using Whisper transcription followed by an LLM.
- SpeechGPT: an end-to-end speech dialogue system.
- SALMONN-7B and SALMONN-13B: dual-encoder speech understanding and response generation models.
- OSUM-EChat: an emotion-aware speech dialogue system.
- Qwen2.5-Omni-7B: a multimodal unified speech, vision, and text dialogue model.
- LLaMA-Omni2: a speech-enabled LLaMA-style multimodal dialogue model.
- OpenS2S: an open-source speech-to-speech dialogue model.
Implementation details
Only the Responder is fine-tuned in PRISM. The paper fine-tunes Qwen2.5-7B-Instruct and Llama-3.1-8B-Instruct as responder backbones, using LLaMA-Factory on NVIDIA A6000 48 GB GPUs. The Manager is implemented with GPT-3.5-Turbo via the OpenAI API. For external knowledge augmentation, the system uses COMET-BART, a BART-based commonsense generation model.
Results
The paper reports three complementary evaluation views: automatic text metrics, human evaluation, and GPT-4o-based pairwise evaluation. The headline conclusion is that PRISM improves both response quality and prosodic appropriateness, with particularly strong gains in text generation metrics and broad improvements in subjective judgments.
Automatic evaluation on AvaMERG
Automatic evaluation uses ROUGE, BERTScore, BLEU, and Distinctness. The paper reports the following results on the AvaMERG test set.
| Model | ROUGE-1/2/L | BERTScore | BLEU-1/2/3/4 | Dist-1/2 |
|---|---|---|---|---|
| ASR+LLM | 0.1690/0.0271/0.1406 | 0.8652 | 0.1431/0.0514/0.0250/0.0132 | 0.0286/0.1722 |
| SpeechGPT | 0.1437/0.0228/0.1126 | 0.8534 | 0.1189/0.0543/0.0304/0.0180 | 0.0306/0.1340 |
| OSUM-EChat | 0.1546/0.0263/0.1146 | 0.8673 | 0.1381/0.0485/0.0226/0.0111 | 0.0342/0.2133 |
| SALMONN-7B | 0.1598/0.0321/0.1226 | 0.8684 | 0.1415/0.0616/0.0357/0.0217 | 0.0225/0.1346 |
| SALMONN-13B | 0.1666/0.0381/0.1289 | 0.8705 | 0.1464/0.0570/0.0303/0.0174 | 0.0218/0.1327 |
| Qwen2.5-Omni-7B | 0.1880/0.0542/0.1555 | 0.8746 | 0.1737/0.0831/0.0530/0.0352 | 0.0375/0.2380 |
| LLaMA-Omni2 | 0.1703/0.0329/0.1330 | 0.8674 | 0.1565/0.0646/0.0354/0.0205 | 0.0460/0.2376 |
| OpenS2S | 0.1759/0.0356/0.1408 | 0.8691 | 0.1883/0.0700/0.0355/0.0192 | 0.0428/0.2329 |
| PRISM (Qwen) | 0.2254/0.0745/0.1872 | 0.8792 | 0.2041/0.1142/0.0792/0.0571 | 0.0390/0.2519 |
| PRISM (Llama) | 0.2027/0.0649/0.1743 | 0.8801 | 0.2318/0.1223/0.0805/0.0555 | 0.0409/0.2574 |
The authors highlight that both PRISM variants outperform the baselines on nearly all automatic metrics. PRISM (Qwen) achieves the strongest ROUGE scores and the best BLEU-4, while PRISM (Llama) attains the highest BERTScore and Dist-2. The paper interprets these improvements as evidence that the prosody description and the multi-agent structure improve content relevance and generation quality.
Human evaluation
Human evaluation was conducted by three researchers specializing in empathetic dialogue systems. They randomly sampled 100 dialogue instances, and each instance was independently rated by all annotators on a 5-point Likert scale across six dimensions: Empathy, Informativity, Fluency, Consistency, Prosodic Appropriateness, and Audio-Text Alignment. The reported inter-annotator agreement is an average ICC of 0.81, which the paper describes as substantial agreement.
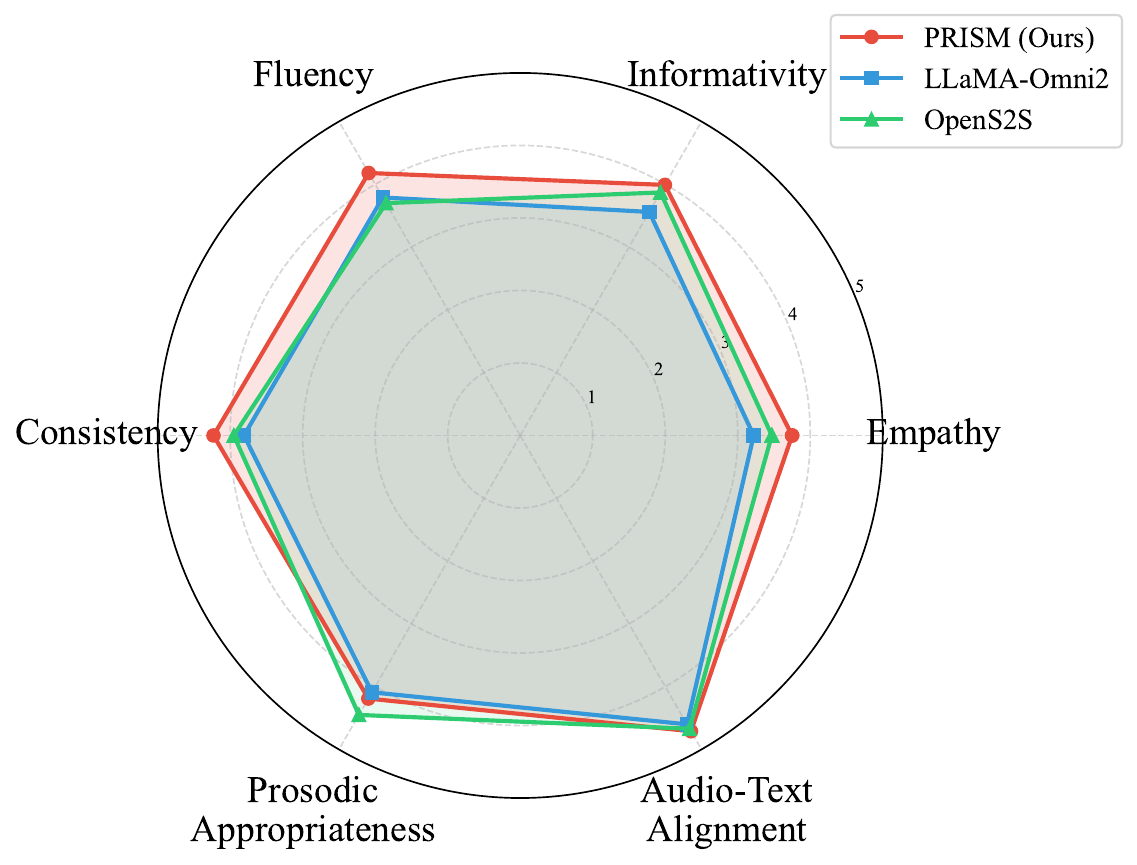
The radar chart shows PRISM performing comparably or better than the strong speech-native baselines LLaMA-Omni2 and OpenS2S on most dimensions, with especially salient gains in prosodic appropriateness and audio-text alignment. This is important because those metrics are directly tied to the paper’s premise that empathy in spoken dialogue must be evaluated at both the textual and acoustic levels.
LLM-based evaluation
The paper also uses GPT-4o for A/B testing, focusing on empathy, fluency, and consistency. The evaluation compares PRISM against baselines and reports win/loss outcomes (ties omitted).
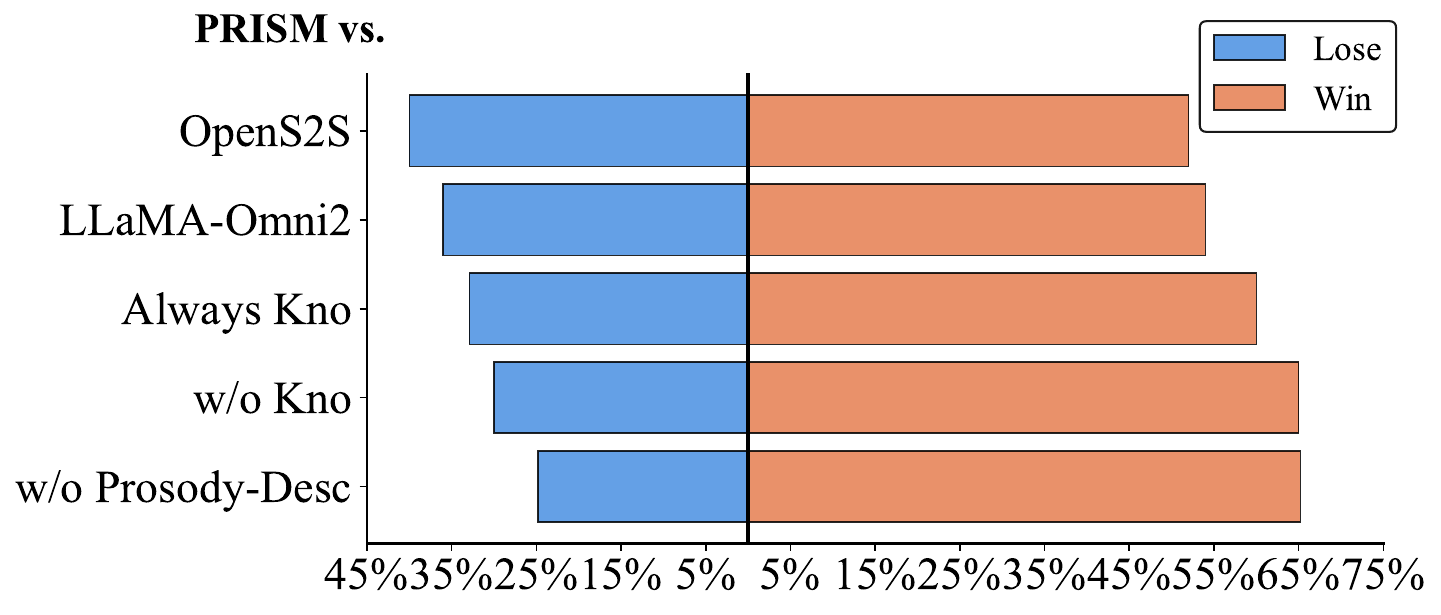
The paper states that PRISM achieves a higher win rate against both OpenS2S and LLaMA-Omni2, reinforcing the human-evaluation trend that the framework is competitive or better on subjective quality dimensions.
Ablation Studies
The ablations focus on two design decisions: autonomous knowledge invocation and prosody description. All ablations are run on the Qwen2.5-7B-Instruct-based configuration.
| Variant | ROUGE-1/2/L | BERTScore | BLEU-1/2/3/4 | Dist-1/2 |
|---|---|---|---|---|
| PRISM (Qwen) | 0.2254/0.0745/0.1872 | 0.8792 | 0.2041/0.1142/0.0792/0.0571 | 0.0390/0.2519 |
| Always Kno | 0.1611/0.0204/0.1301 | 0.8667 | 0.1606/0.0560/0.0259/0.0133 | 0.0258/0.1550 |
| w/o Kno | 0.1624/0.0205/0.1300 | 0.8633 | 0.1601/0.0549/0.0254/0.0129 | 0.0250/0.1495 |
| w/o Prosody-Desc | 0.1521/0.0202/0.1262 | 0.8641 | 0.1727/0.0583/0.0271/0.0137 | 0.0280/0.1617 |
The paper’s conclusion from the ablations is straightforward: forcing knowledge use every turn harms performance, removing knowledge entirely also degrades performance, and removing the prosody description causes a clear drop. In other words, both selective knowledge invocation and prosody-to-language translation are necessary for the reported gains.
Interpretation and Technical Takeaways
- Structured prosody helps reasoning. By converting acoustic and temporal cues into text, PRISM makes prosodic information easier for an LLM to condition on than raw numeric features.
- Tool use is integrated, not bolted on. The responder decides whether commonsense retrieval is needed during generation, rather than relying on a fixed retrieval stage.
- Speech synthesis is explicitly controlled. The vocalizer conditions on the predicted emotion and intensity as well as the user’s paralinguistic state, tying synthesis behavior to the dialogue context.
- The system is modular and update-friendly. The paper emphasizes that external knowledge sources can be changed by modifying the tools, without retraining the full system.
Limitations and Scope Notes
The paper does not include a dedicated limitations section, so the following points should be understood as scope notes rather than author-stated limitations. Based only on the reported method and experiments, the system depends on several external components and heuristics: Whisper for transcription, emotion2vec for emotion recognition, WebRTC VAD for pause estimation, GPT-3.5-Turbo for the Manager, COMET-BART for knowledge augmentation, and StyleTTS2 for synthesis. This means the framework’s behavior is partly coupled to the quality and availability of those components. The prosody-to-language translation also relies on rule-based thresholding and prompt design, so performance may depend on how well those thresholds and prompts transfer across domains. Finally, the experiments are reported on AvaMERG’s audio split, with responder fine-tuning on TOOL-ED; the paper does not report broader cross-dataset generalization studies in the provided text.
Conclusion
PRISM proposes a multi-agent framework for empathetic spoken dialogue that explicitly bridges speech perception, reasoning, and synthesis. Its core novelty is the combination of a prosody-to-language translation mechanism with selective knowledge invocation and prosody-aware speech synthesis control. On AvaMERG, the paper reports consistent gains over a range of text and speech baselines, with supporting human and GPT-4o evaluations, and ablations showing that both prosody description and adaptive knowledge use are important to the final system.
Code & Implementation
This repository implements the PRISM framework for empathetic spoken dialogue, organizing core components that map closely to the conceptual multi-agent design described in the paper.
- Speech Perception: Handled by modules like
perceiver.pyand invoked inmain.pyviaSpeechPerceiverwhich encapsulates speech-to-text (using Whisper) and emotion/prosody embedding extraction. - Prosody Description Management: The
manager.pymodule implements theSpeechDescriptionManager. It generates natural language descriptions of prosodic features from speech and performs post-hoc verification of generated responses to ensure emotional and prosodic alignment. - Response Generation: Implemented by
responder.py, which produces empathetic replies integrating prosody and external knowledge cues, as coordinated by the multi-agent system inmain.py. - Speech Synthesis: The
vocalizer.pymodule contains theGenerationAgentresponsible for synthesizing speech with controlled prosodic characteristics guided by the prior components' outputs.
The main.py script orchestrates the full pipeline: loading models, processing audio inputs, generating prosody-aware text replies, verifying alignment, revising responses, and synthesizing final audio outputs. Outputs including prosody descriptions, textual replies, and generated audio are saved per dialogue turn.
The README provides dataset references and notes that StyleTTS2 is used as the backbone TTS model.