Emo-LiPO
Emo-LiPO: Listwise Preference Optimization for Fine-Grained Emotion Intensity Control in LLM-based Text-to-Speech
Emo-LiPO introduces a listwise preference optimization framework for fine-grained emotion intensity control in LLM-based text-to-speech systems. It uniquely models global intensity ordering within emotions to better align speech output with nuanced written emotional cues, surpassing prior pairwise preference methods.
Links
Paper & demos
Impact
Abstract
Large language model (LLM)-based text-to-speech (TTS) systems enable prompt-conditioned emotional control but struggle with fine-grained emotion intensity due to the semantic -- acoustic gap between text and speech. To address this challenge, we formulate emotion intensity control in LLM-based TTS as a learning-to-rank problem and propose Emo-LiPO, a listwise preference optimization framework that aligns prompt-conditioned speech generation with relative emotion intensity expressed in text. Emo-LiPO explicitly models global intensity ordering within each emotion under fixed transcripts, enabling more faithful and continuous emotional expression. We further construct ESD-plus, a multi-speaker dataset with explicit emotion intensity variations, to support fine-grained emotion modeling and evaluation. Experiments on ESD-plus demonstrate that Emo-LiPO significantly improves emotion accuracy and intensity controllability over both supervised- and DPO-based LLM TTS baselines, with particularly pronounced gains at high intensity levels.
Introduction
Emo-LiPO addresses fine-grained emotion intensity control in prompt-conditioned, LLM-based text-to-speech (TTS). The core problem is that modern LLM-TTS systems can follow natural-language prompts for emotion category, but they still struggle to render reliably ordered intensity levels such as slightly, moderately, or extremely. The paper attributes this to a semantic--acoustic gap: text can say that a sample should be more intense, but standard supervision does not force the generated speech to realize a globally consistent ordering across intensity levels.
The paper’s central idea is to recast emotion intensity control as a learning-to-rank problem. Instead of treating each prompt--speech pair independently, Emo-LiPO uses listwise preference supervision to align speech generation with the relative ordering implied by the prompt. This is intended to make the intensity signal explicit, continuous, and monotonic within each emotion category. The method is evaluated on a new dataset, ESD-plus, which is designed specifically for this setting.
The paper positions Emo-LiPO relative to two broad classes of prior systems: supervised LLM-TTS baselines, and preference-optimized methods such as DPO-based emotional TTS. The stated gap is that prior preference methods mainly model whether one output is better than another, but they do not explicitly encode the ordinal structure of intensity. Emo-LiPO is designed to fill that gap by using listwise comparisons rather than only pairwise comparisons.
Problem Formulation
The task is defined over a text transcript $t$ and an emotion prompt $P_{c,l}$ specifying an emotion category $c$ and, for non-neutral categories, an intensity level $l$. The set of categories is written as $\mathcal{C} = \mathcal{C}_{\text{emo}} \cup \{\textit{neutral}\}$, where $\mathcal{C}_{\text{emo}}$ includes emotions such as happy, sad, angry, and surprise. For each emotional category, the paper defines an ordered set of intensity levels $\mathcal{L} = \{l_1, l_2, \ldots, l_K\}$ with $l_i < l_j$ for $i < j$.
The generated speech $S = \pi_\theta(t, P_{c,l})$ is expected to satisfy three conditions: content fidelity, category correctness, and intensity ordering. The first two are standard TTS requirements, while the third is the paper’s main focus: speech generated from a stronger intensity prompt should be perceived as strictly stronger than speech generated from a weaker intensity prompt, under the same transcript and emotion category. The weakest emotional level is required to remain perceptually distinct from neutral speech.
The paper frames this as a ranking problem under fixed transcripts, which means that all candidates compared within a preference list share the same linguistic content. This is important because it isolates emotion and intensity as the variables of interest.
Method
Listwise preference construction
Emo-LiPO constructs a listwise preference set $\mathcal{T}_{c,l}$ for each prompt $P_{c,l}$. The list contains $K+2$ speech candidates that all share the same transcript $t$:
- a target sample $S_{c,l}$ with the exact emotion category and intensity level;
- $K-1$ same-emotion samples with the same category $c$ but different intensity levels $l' \in \mathcal{L} \setminus \{l\}$;
- one neutral sample $S_{\mathrm{neu}}$;
- one negative sample $S_{\bar{c}}$ from a randomly selected non-target emotion category.
The rule-based ranking strategy orders these candidates as follows:
$$ \mathcal{T}_{c,l} = [S_{c,l} \succ S_{c,l_{\text{closest}}} \succ \cdots \succ S_{c,l_{\text{farthest}}} \succ S_{\mathrm{neu}} \succ S_{\bar{c}}]. $$
The same-emotion candidates are ordered by absolute intensity distance from the target level $|l' - l|$, so candidates closer in intensity receive higher preference. Ties are randomly broken. This list encodes not only positive-versus-negative preference, but also a global ordinal structure within the same emotion.
The paper then assigns a real-valued preference vector $\psi_{c,l} \in [0,1]^{|\mathcal{T}_{c,l}|}$ using an index-based scheme:
$$ \psi_{c,l}(i) = 1 - \frac{i-1}{K+2}, \quad i = 1, \ldots, K+2. $$
Smaller indices correspond to stronger preference. This turns the ordered candidate list into a graded supervision signal rather than a simple binary preference relation.
LiPO objective
The paper follows the Listwise Preference Optimization (LiPO) formulation. The TTS model is initialized by supervised fine-tuning (SFT) on prompt--speech pairs, and the SFT model becomes the reference policy $\pi_{\mathrm{ref}}$ for the preference stage. In the SFT stage, the objective is standard token-level cross-entropy under teacher forcing:
$$ \mathcal{L}_{\mathrm{SFT}}(\pi_{\mathrm{base}}) = \mathbb{E}_{(x,S) \sim \mathcal{D}_{\mathrm{SFT}}}\left[-\log \pi_{\mathrm{base}}(S \mid x)\right]. $$
Here $x=(t,P_{c,l})$ is the joint text-and-prompt input. The subsequent LiPO stage optimizes the policy $\pi_\theta$ against the reference model using listwise preference data. For each candidate $S_i \in \mathcal{T}_{c,l}$, the ranking score is defined as
$$ s_i = \beta \log \frac{\pi_\theta(S_i \mid x)}{\pi_{\mathrm{ref}}(S_i \mid x)}. $$
The listwise loss aggregates ordered pairs $(i,j)$ for which $\psi_{c,l}(i) > \psi_{c,l}(j)$. The paper writes the ranking loss as
$$ r(\boldsymbol{\psi}_{c,l}, \mathbf{s}) = -\sum_{(i,j) \in \mathcal{\psi}_{c,l}} \lambda_{i,j}(s_i - s_j). $$
The key point is the distance-aware weight $\lambda_{i,j}$, which emphasizes ranking violations that correspond to larger implied intensity differences. The paper defines a gain term and a discount term as
$$ G(i) = 2^{\psi_{c,l}(i)} - 1, \qquad D(i) = \frac{1}{\log(1+i)}, $$
and then sets
$$ \lambda_{i,j} = \left|G(i) - G(j)\right| \cdot \left|\frac{1}{D(i)} - \frac{1}{D(j)}\right|. $$
According to the paper, larger $\lambda_{i,j}$ values correspond to larger implied intensity gaps and therefore stronger penalties when the order is violated. Conceptually, this is what lets Emo-LiPO go beyond local pairwise preferences and explicitly model global intensity structure.
Training pipeline
The overall training strategy is multi-stage. First, the backbone LLM-TTS model is supervised-fine-tuned to learn instruction following and basic emotional prompting. Then LiPO is applied for fine-grained intensity control. The paper states that the backbone used in experiments is CosyVoice-300M-Instruct. The authors also note that the model is trained as a conditional autoregressive speech-token generator, conditioned on the joint input $x=(t,P_{c,l})$ and a speaker embedding.
The paper’s method is therefore not a new TTS decoder architecture; rather, it is a training framework that changes how the model is optimized for emotional control. The inference pipeline remains the same as the underlying LLM-TTS backbone.
ESD-plus Dataset
To support the task, the paper introduces ESD-plus, a multi-speaker emotional speech dataset with explicit emotion intensity variations. It is built from the English portion of the ESD corpus and uses 350 parallel sentences as scripts. The dataset retains the original five emotion categories in ESD: four non-neutral emotions (happy, surprise, sad, angry) and neutral. For each non-neutral emotion, the paper adds three intensity levels, yielding 13 fine-grained labels in total.
| Dataset property | Value reported in the paper |
|---|---|
| Source corpus | English portion of ESD |
| Scripts | 350 parallel sentences |
| Emotion categories | happy, surprise, sad, angry, neutral |
| Fine-grained labels | 13 total labels |
| Intensity levels for non-neutral emotions | 3 per emotion |
| Speakers / voices | 10 official English voices, 4 male and 6 female |
| Total samples | 45,500 |
| Total duration | Approximately 36.89 hours |
| Average sample duration | 2.92 seconds |
| Split | 300 train / 20 dev / 30 test utterances |
| Manual verification | 91.23% of evaluated samples pass verification |
The dataset is synthesized using gpt-4o-mini-tts with structured prompts that combine a natural-language emotion description and a scalar intensity indicator. The intensity indicators are deliberately spaced apart, for example $1/5$, $3/5$, and $5/5$, rather than using adjacent increments. The paper says this spacing is intended to make the intensity differences perceptually distinguishable.
Data verification is applied to the development and test sets. Annotators compare samples within each emotion category to ensure that the generated intensity increases monotonically with the intended prompt. Samples that fail the ordering criterion are regenerated until the target ordering is satisfied. The training split is not modified during this process.
Experimental Setup
The paper evaluates Emo-LiPO against both supervised and preference-optimized LLM-TTS baselines. The baselines are:
- CosyVoice, a supervised LLM-TTS baseline;
- EmoVoice, a prompt-based emotional TTS system;
- Emo-DPO (R), trained on randomly sampled pairwise preferences $$(S_{c,l}, \bar{S}_{c,l})$$;
- Emo-DPO (E), trained on cross-emotion pairwise preferences at the same intensity $$(S_{c,l}, S_{\bar{c},l})$$;
- Emo-DPO (I), trained on within-emotion pairwise preferences across intensity levels $$(S_{c,l}, S_{c,\bar{l}})$$;
- Emo-LiPO, built on CosyVoice-300M-Instruct and trained with listwise preference optimization.
The metric suite is deliberately broad. Speech quality is measured using Word Error Rate (WER) from Whisper-Large-v3, plus three perceptual metrics: NISQA, DNSMOS, and UTMOS. Emotion relevance is evaluated with emotion2vec using two metrics: EmoSIM, which is cosine similarity in emotion embedding space, and Recall, which is the emotion-classification accuracy. Because the off-the-shelf emotion2vec model has limited out-of-domain performance, the paper additionally fine-tunes emotion2vec on ESD-plus and reports the resulting accuracy as Recall-ft.
Main Results
The paper reports that Emo-LiPO achieves the strongest emotion relevance overall, while maintaining competitive speech quality. In particular, it obtains the best Recall and Recall-ft among all methods, and the best EmoSIM is also close to the top. The main improvement is not simply better categorical emotion recognition, but more faithful translation of prompt-specified intensity into speech that becomes easier to recognize as intensity increases.
| Model | WER ↓ | NISQA ↑ | DNSMOS ↑ | UTMOS ↑ | EmoSIM ↑ | Recall ↑ | Recall-ft ↑ |
|---|---|---|---|---|---|---|---|
| CosyVoice | 4.47 | 4.71 | 3.16 | 4.30 | 81.87 | 25.10 | 29.90 |
| EmoVoice | 5.40 | 4.79 | 3.29 | 4.27 | 89.84 | 20.56 | 28.51 |
| Emo-DPO (R) | 12.78 | 4.37 | 3.04 | 3.90 | 91.52 | 24.77 | 33.46 |
| Emo-DPO (E) | 4.78 | 4.66 | 3.23 | 4.06 | 91.73 | 24.08 | 34.92 |
| Emo-DPO (I) | 6.79 | 4.60 | 3.21 | 4.00 | 91.85 | 26.87 | 37.21 |
| Emo-LiPO | 4.26 | 4.79 | 3.26 | 4.18 | 91.93 | 27.56 | 39.54 |
| Emo-LiPO w/o $\lambda$ | 4.15 | 4.79 | 3.24 | 4.17 | 92.30 | 26.21 | 37.59 |
From these numbers, the main pattern is clear. Compared with supervised baselines, preference optimization improves emotion alignment substantially. Among the DPO variants, the intensity-aware version, Emo-DPO (I), is stronger than random preference training and the emotion-category variant, which supports the paper’s thesis that intensity-related supervision is useful. Emo-LiPO then improves further, especially on Recall-ft, where it reaches 39.54, the best reported value.
Speech quality is preserved reasonably well. CosyVoice remains strong on UTMOS, while EmoVoice has the best DNSMOS among the baselines. Emo-LiPO stays competitive on all quality metrics and also achieves the best NISQA among the compared models at 4.79, tied with EmoVoice. The WER values show that preference optimization can degrade transcription quality if not handled carefully, as seen in Emo-DPO (R), but Emo-LiPO avoids that collapse and remains close to the supervised baselines.
Human evaluation
The paper also reports Arena-style human evaluation comparing Emo-LiPO against CosyVoice, Emo-DPO (E), and Emo-DPO (I) across three perceptual dimensions: speech quality, emotion expression, and intensity control. The evaluation uses pairwise comparisons and allows ties.
| Dimension | CosyVoice | Emo-DPO (E) | Emo-DPO (I) |
|---|---|---|---|
| Speech Quality | 94.29% | 79.37% | 89.28% |
| Emotion Expression | 90.34% | 80.65% | 78.24% |
| Intensity Control | 86.08% | 66.44% | 58.33% |
The paper interprets these results as evidence that Emo-LiPO is perceptually preferred not only for intensity control but also for maintaining speech quality. The strongest advantage is on intensity control, where the win rate is especially large against the category-based and intensity-based DPO baselines.
Emotion Intensity Control Analysis
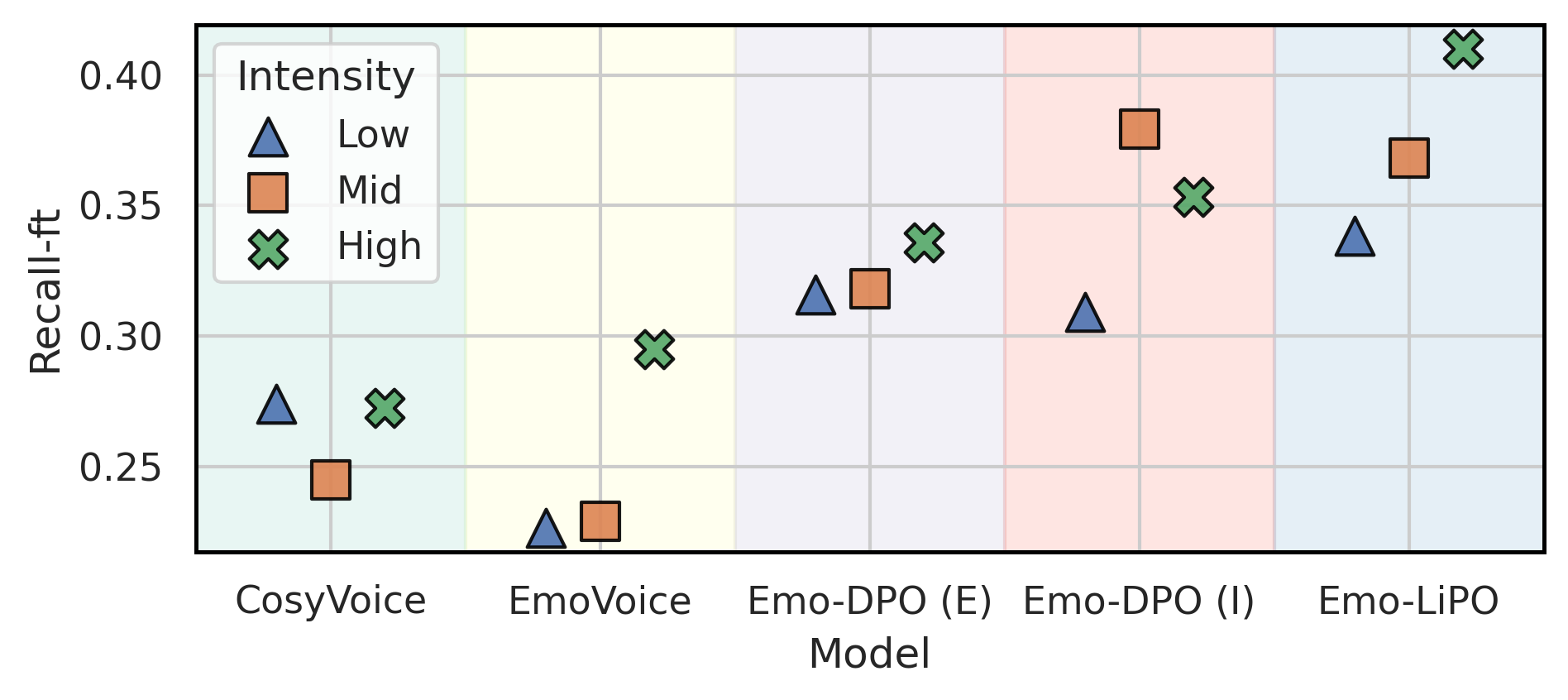
A key analysis in the paper examines Recall-ft as a function of intensity level. The expected trend is that higher emotional intensity should be easier to recognize. Emo-LiPO is reported to be the only model that exhibits a clear and stable monotonic increase from low to high intensity. Other baselines show weaker or non-monotonic behavior, meaning that stronger prompts do not always translate into stronger perceptual intensity. This is one of the paper’s main empirical claims: listwise supervision better preserves the intended ordinal structure of emotion intensity.
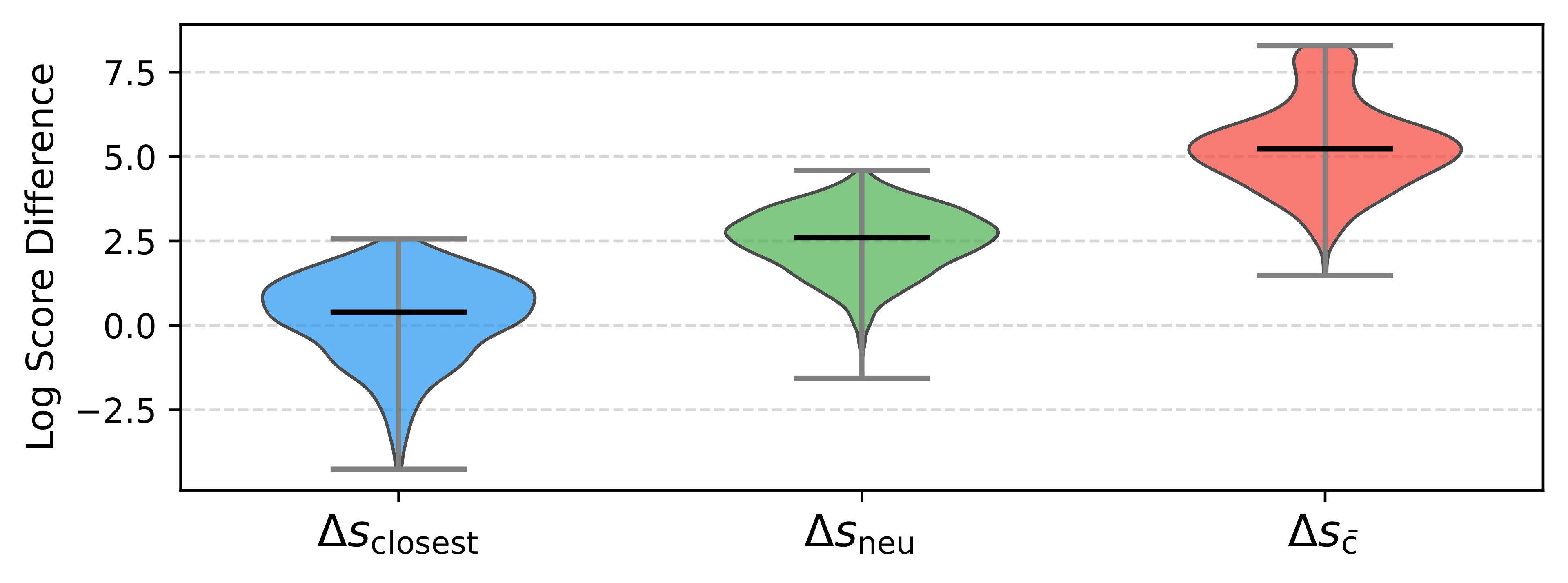
The paper further inspects the learned score margins between the target sample and the different candidate types in the list. It computes absolute score gaps between the target and the closest same-emotion sample, the neutral sample, and the other-emotion sample. The reported hierarchy is consistent and interpretable: the margin to the other-emotion sample is largest, the margin to neutral is intermediate, and the margin to the closest same-emotion sample is smallest. This indicates that the learned scoring landscape respects the difficulty structure of the task: cross-emotion separation is easiest, while distinguishing nearby intensity levels within the same emotion is the hardest.
Ablations and Design Choices
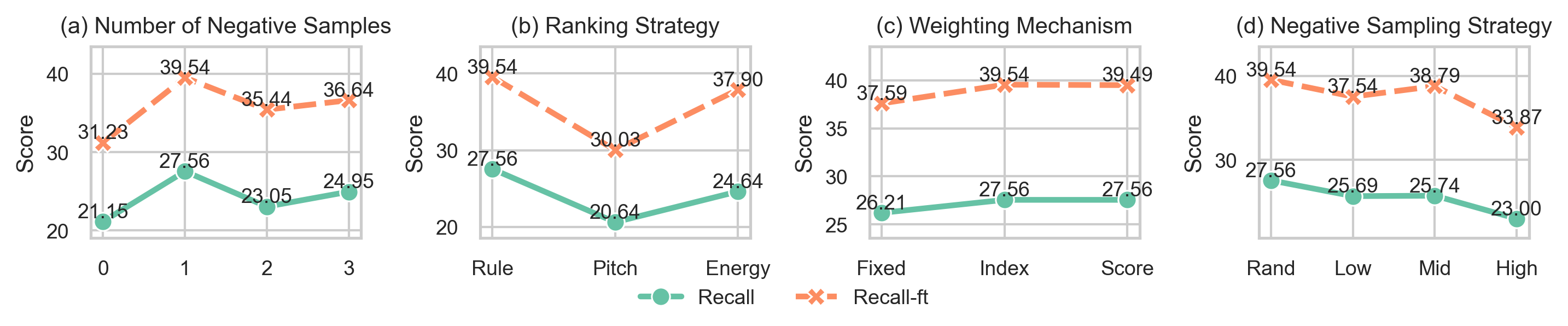
The ablations focus on four design axes: the number of negative samples, the ranking strategy used to build the list, the weighting mechanism $\lambda$, and the strategy for sampling negatives across intensity levels. The paper’s conclusions are fairly consistent across these studies: moderate list construction and distance-aware weighting help, while overly aggressive negative sampling can hurt.
Effect of negative samples
When the number of cross-emotion negatives is varied, the paper reports that a single negative sample works best overall and produces the clearest monotonic trend. Adding two or three negatives does not improve results and instead degrades performance. The interpretation is that a small amount of cross-emotion contrast is sufficient, whereas too many negatives dilute the supervision for intensity ordering.
Effect of ranking strategy
The paper compares the proposed rule-based ranking with acoustic alternatives that rank candidates by distance in average pitch or energy. The rule-based order performs best, energy-based ranking is intermediate, and pitch-based ranking is worst. The conclusion is that a ranking derived from a single acoustic cue is weaker than the explicit structured ordering used by Emo-LiPO.
Effect of the weighting term $\lambda$
The weighting mechanism is tested by setting $\lambda_{i,j}=1$ for all pairs, which removes distance-aware weighting. The paper reports that the unweighted variant can slightly improve EmoSIM but consistently hurts the emotion-control metrics. This suggests that $\lambda$ is not mainly about boosting category-level similarity; instead, it sharpens ordinal consistency and improves controllability. The result also matches the main table, where the unweighted variant has slightly better WER but worse Recall and Recall-ft than the full model.
Negative sampling strategy
The paper also studies how to choose the single negative sample $S_{\bar{c}}$. Sampling it uniformly at random across intensity levels performs best. Restricting negatives to a single intensity level, such as low, mid, or high, consistently hurts performance. The paper interprets this as evidence that diverse negatives provide more balanced supervision than biased, single-level negatives.
Contributions and Novelty
- It reformulates fine-grained emotion intensity control in LLM-TTS as a learning-to-rank problem rather than a binary preference problem.
- It introduces Emo-LiPO, a listwise preference optimization framework that explicitly models global intensity ordering within each emotion category.
- It constructs ESD-plus, a multi-speaker dataset with 13 fine-grained emotion labels and explicit intensity variation.
- It evaluates both automatic and human perceptual metrics and shows that listwise supervision improves intensity controllability while keeping speech quality competitive.
- It provides ablation evidence that rule-based list construction, one negative sample, and distance-aware weighting are all important for stable performance.
Relative to DPO-based approaches, the novelty is not merely switching from pairwise to listwise supervision; it is the explicit encoding of intensity order among same-emotion candidates under a fixed transcript. That makes the supervision closer to the actual task objective: a prompt should not just select an emotion category, it should induce a predictable position on an intensity ladder.
Conclusion and Scope
The paper concludes that listwise preference modeling is an effective way to improve fine-grained emotional control in prompt-conditioned LLM-TTS. Emo-LiPO is reported to consistently outperform strong supervised and DPO-based baselines on emotion accuracy and intensity controllability, while preserving high speech quality. The empirical evidence points to a useful design principle: if the target behavior is ordinal, then the training signal should also be ordinal.
The paper does not include a separate limitations section, but the reported scope is clearly bounded: experiments are carried out on ESD-plus, which contains four non-neutral emotions plus neutral, three intensity levels per non-neutral emotion, and a single LLM-TTS backbone, CosyVoice-300M-Instruct. The dataset is synthesized with ten official English voices, and the human verification procedure is applied to the development and test splits. These details define the operational scope of the reported evidence.