NaturalFlow
NaturalFlow: Reducing Disruptive Pauses for Natural Speech Flow in Simultaneous Speech-to-Speech Translation

NaturalFlow introduces a fluency-aware optimization for simultaneous speech-to-speech translation that balances low latency with natural speech flow by reducing disruptive pauses. It explicitly optimizes speech fluency to lower listener load without sacrificing translation quality.
Demos
These demos showcase NaturalFlow's ability to reduce disruptive pauses and silence in simultaneous speech-to-speech translation, resulting in smoother, more natural speech flow compared to baseline systems. Listen for fewer interruptions and observe continuous, fluent output that preserves translation accuracy and latency. The selected comparison image clearly illustrates these improvements in real examples.

Links
Paper & demos
Impact
Abstract
Simultaneous speech-to-speech translation aims to enable near-real-time communication by minimizing latency, offering a compelling, real-time alternative to the high latency of consecutive translation. However, the excessive pursuit of low latency often results in fragmented chunk-wise speech. Consequently, listeners are subjected to an unnatural acoustic flow punctuated by frequent pauses, which could increase their cognitive load. To bridge this gap, we introduce a fluency-aware optimization framework designed to discover the sweet spot between the low-latency benefits of simultaneous translation and the natural flow of consecutive translation. Our framework minimizes inter-chunk silences by leveraging model-internal signals, including linguistic diversity and induced temporal variability in speech durations. Experiments on short- and long-form benchmarks show that our framework produces natural speech flow while maintaining competitive latency and translation quality.
Overview
NaturalFlow addresses a specific weakness in simultaneous speech-to-speech translation (S2ST): although streaming systems reduce latency, they often do so by speaking in short chunks separated by frequent pauses. The paper argues that these pauses make the output acoustically fragmented and increase listener cognitive load, even when translation content is correct. The proposed solution is a fluency-aware optimization framework that explicitly targets silence ratio while preserving translation fidelity and latency. The method is built on the Hibiki S2ST architecture and trained with a preference-learning objective that uses automatically constructed pairwise preferences rather than human labels.
The main reported outcome is that NaturalFlow lowers inter-chunk silence on short- and long-form Fr-En benchmarks, with competitive translation quality and latency. The paper’s core novelty is not a new streaming architecture, but a new optimization target: instead of only balancing quality against delay, it also optimizes acoustic continuity.
Problem motivation and framing
The paper contrasts two translation paradigms. Consecutive translation produces natural continuous speech but has high latency, while simultaneous translation achieves near-real-time delivery but often becomes disfluent because the system must wait for context and then emit short bursts. The authors connect this to the human interpreting literature: pauses and hesitations are not just cosmetic, because listeners use temporal flow as a cue for fluency and quality.
NaturalFlow is motivated by the observation that large language model-based S2ST systems can often express the same meaning with different paraphrases of different lengths. The paper uses this flexibility to intentionally choose translations that slightly extend articulation time, giving the system more time to absorb incoming source audio without stopping the speech stream. In other words, the method tries to trade a small amount of lexical freedom for smoother acoustic delivery, rather than forcing the model into a rigid chunk-wise policy.

Base architecture and simultaneous S2ST setting
The optimization is applied on top of Hibiki, which is described as a simultaneous S2ST model that processes source speech while jointly generating target speech and text. The raw audio is discretized using Mimi, a neural audio codec operating at a frame rate of $12.5$ Hz with $16$ codebook levels. Hibiki predicts target audio tokens and a word-level aligned text stream, with text tokens padded so that text and audio remain temporally aligned at the same resolution.
Unlike approaches that rely on an external explicit policy for when to speak, Hibiki learns its own emission timing from weakly supervised temporally aligned training data. The paper describes this as identifying alignment points where the log-likelihood of the next target token sharply increases as more source context is accumulated. NaturalFlow does not replace this architecture; instead, it reorients the model’s behavior through preference optimization so that the learned timing is less pause-heavy.
Method
Preference data construction
The method has three main stages for constructing an offline preference dataset.
- Source data selection. The authors mix short- and long-form speech so that the preference data spans different temporal regimes. They randomly sample 10,000 utterances from the CVSS-C training set for short-form examples of roughly $0$ to $10$ seconds. For long-form examples of roughly $10$ to $60$ seconds, they build 6,000 snippets from mTEDx by concatenating consecutive segments from the same TED talk.
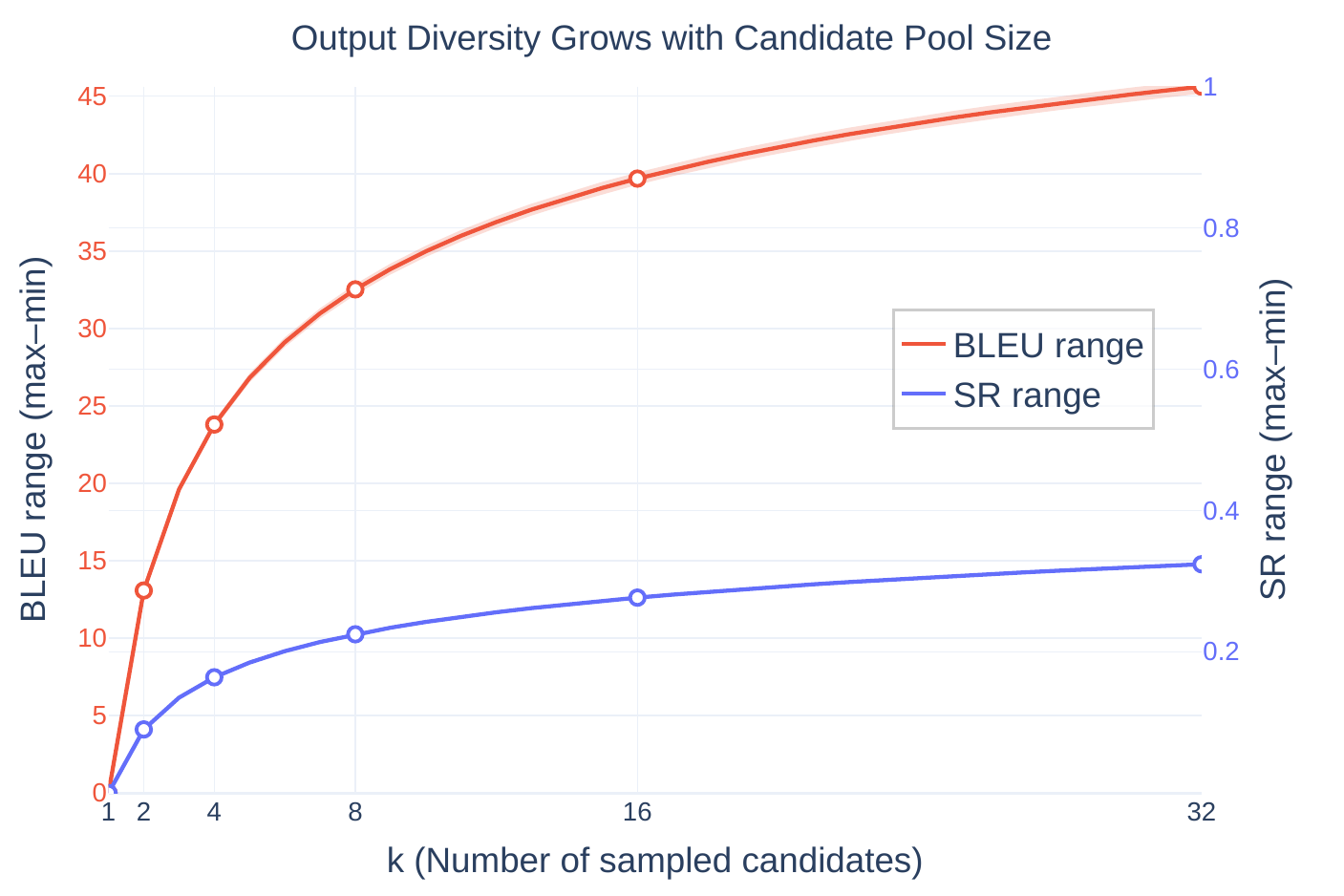
- Candidate generation. For each source utterance, they sample multiple translation candidates with decoding temperature $1.0$ to encourage lexical diversity. They vary the candidate pool size and measure the range of BLEU scores and silence ratios across candidates. The diversity curves plateau around $k=32$, so they use 32 candidates per utterance.
- Quality and fluency measurement. Each sampled candidate is scored along two axes: translation quality and acoustic fluency. Translation quality is computed by transcribing generated speech with Whisper-medium and measuring BLEU against the benchmark reference translation. Fluency is measured with Silence Ratio using Silero VAD and the default settings reported in the paper, including $\texttt{VAD\_THRESHOLD}=0.5$, $\texttt{MIN\_SPEECH\_DURATION\_MS}=250$, and $\texttt{MIN\_SILENCE\_DURATION\_MS}=100$.
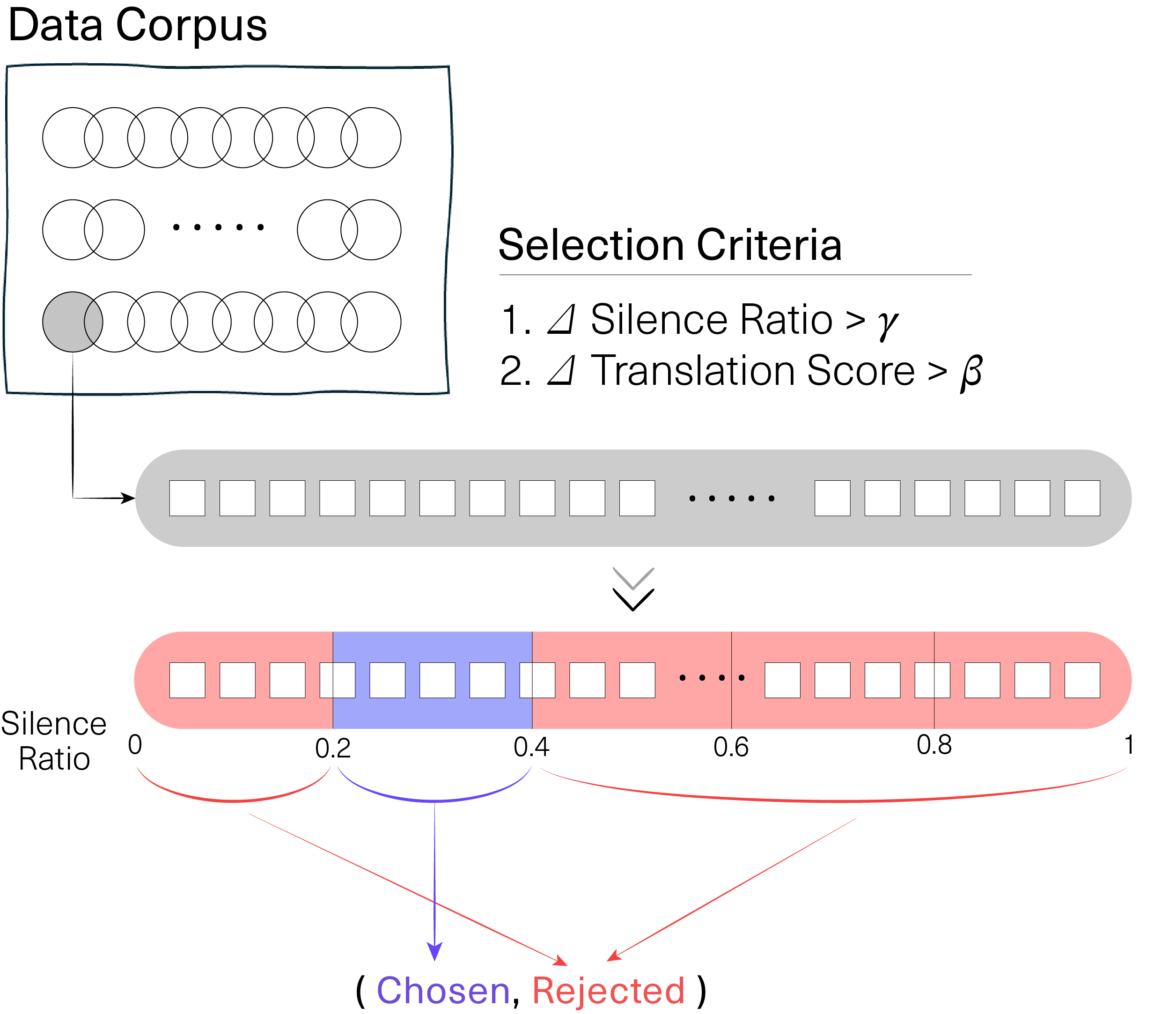
Silver-Medal Preference
The key dataset-design novelty is the paper’s Silver-Medal Preference rule. Standard preference construction would select the lowest-silence samples as “chosen,” but the authors argue that this can push the model into a pathological regime where it suppresses silences so aggressively that translation quality collapses. To avoid that failure mode, they divide the 32 candidates into five quintiles by silence ratio and deliberately choose the second quintile—the top 20–40% rather than the very best silence ratio—as the preferred set. The lowest-silence quintile is not treated as preferred; it is part of the rejected pool. This is intended to keep the optimization centered in a region where the model can improve fluency without over-optimizing silence at the cost of semantics.
The paper also enforces large-margin pair selection. A chosen sample must exceed a rejected sample by at least 5 BLEU in translation score and by 15% of the group’s normalized silence ratio. The stated purpose is to ensure that preference gradients are driven by clear, unambiguous differences rather than near-ties.
Preference optimization objective
NaturalFlow is trained with Direct Preference Optimization (DPO), but with two important modifications: length normalization and an explicit focus on the text stream rather than the raw acoustic tokens.
For a preference triple $(x, y_c, y_r)$ with source context $x$, chosen output $y_c$, and rejected output $y_r$, the paper models the joint probability as
$$p_\theta(y \mid x) = p_\theta(A^y \mid x, S^y)\, p_\theta(T^y \mid x, A^y, S^y),$$
where $A^y$ is the target audio stream, $T^y$ is the target text stream, and $S^y$ is the concurrently arriving source audio stream. Because direct optimization over acoustic tokens is described as unstable and the acoustic space is intractable to marginalize, the paper applies preference learning to the text stream only, defining
$$p_\theta^T(y \mid x) := p_\theta(T^y \mid x, A^y, S^y).$$
The final objective is a length-normalized DPO loss:
$$ \mathcal{L}_{\mathrm{DPO-LN}}^T = -\mathbb{E}_{(x,y_c,y_r)}\left[\log \sigma\left( \frac{\beta}{|T^{y_c}|}\log\frac{p_\theta^T(y_c\mid x)}{p_{\mathrm{ref}}^T(y_c\mid x)} - \frac{\beta}{|T^{y_r}|}\log\frac{p_\theta^T(y_r\mid x)}{p_{\mathrm{ref}}^T(y_r\mid x)} \right)\right]. $$
The paper’s discussion emphasizes that length normalization is important to avoid unfairly penalizing longer but semantically accurate translations. In the earlier preliminary section, the standard DPO form is also given with a KL-style coefficient $\beta_{kl}$; in experiments the reported value is $\beta_{kl}=0.1$.
Training and implementation details
- Base model: Hibiki-2B.
- Parameter-efficient tuning: LoRA with rank $r=128$.
- Additional hyperparameters: text padding weight $0.5$, duration $102.4$.
- Optimization: DPO with length normalization and KL penalty coefficient $\beta_{kl}=0.1$.
- Training length: 400 steps.
- Effective batch size: 32.
- Peak learning rate: $2 \cdot 10^{-6}$.
- Warmup: 5% one-cycle warmup schedule.
- Hardware: 4 NVIDIA L40S GPUs and 2 NVIDIA RTX PRO 6000 Blackwell GPUs.
Benchmarks
The paper evaluates on four Fr-En benchmarks spanning short and long utterances.
- CVSS-C: Fr-En test split, derived from Common Voice with CoVoST 2 text, average duration $5.6$ s.
- VoxPopuli S2S Interpretation: Fr-En subset, with 1,000 randomly sampled test examples, average duration $11.4$ s.
- Audio-NTREX-4L: Fr-En test split, synthesized from NTREX translations using high-quality TTS, average duration $42.1$ s.
- mTEDx: constructed by concatenating semantically contiguous segments from test and validation splits into 20–60 second long-form examples, average duration $35.8$ s.
Evaluation metrics
Translation quality
- ASR-BLEU: generated speech is transcribed using Whisper-medium, then BLEU is computed against the benchmark’s ground-truth translation text with SacreBLEU.
- ASR-COMET: the same transcriptions are scored with XCOMET-XL against the benchmark reference translation.
Latency
- Start Offset: time until the first output speech segment begins.
- End Offset: how long output continues after the source ends.
- Length-Adaptive Average Lagging (LAAL): a word-emission delay metric computed from WhisperX timestamps relative to an oracle schedule based on $\max(n_{\mathrm{gen}}, n_{\mathrm{ref}})$, where $n_{\mathrm{gen}}$ and $n_{\mathrm{ref}}$ are the generated and reference word counts.
Fluency
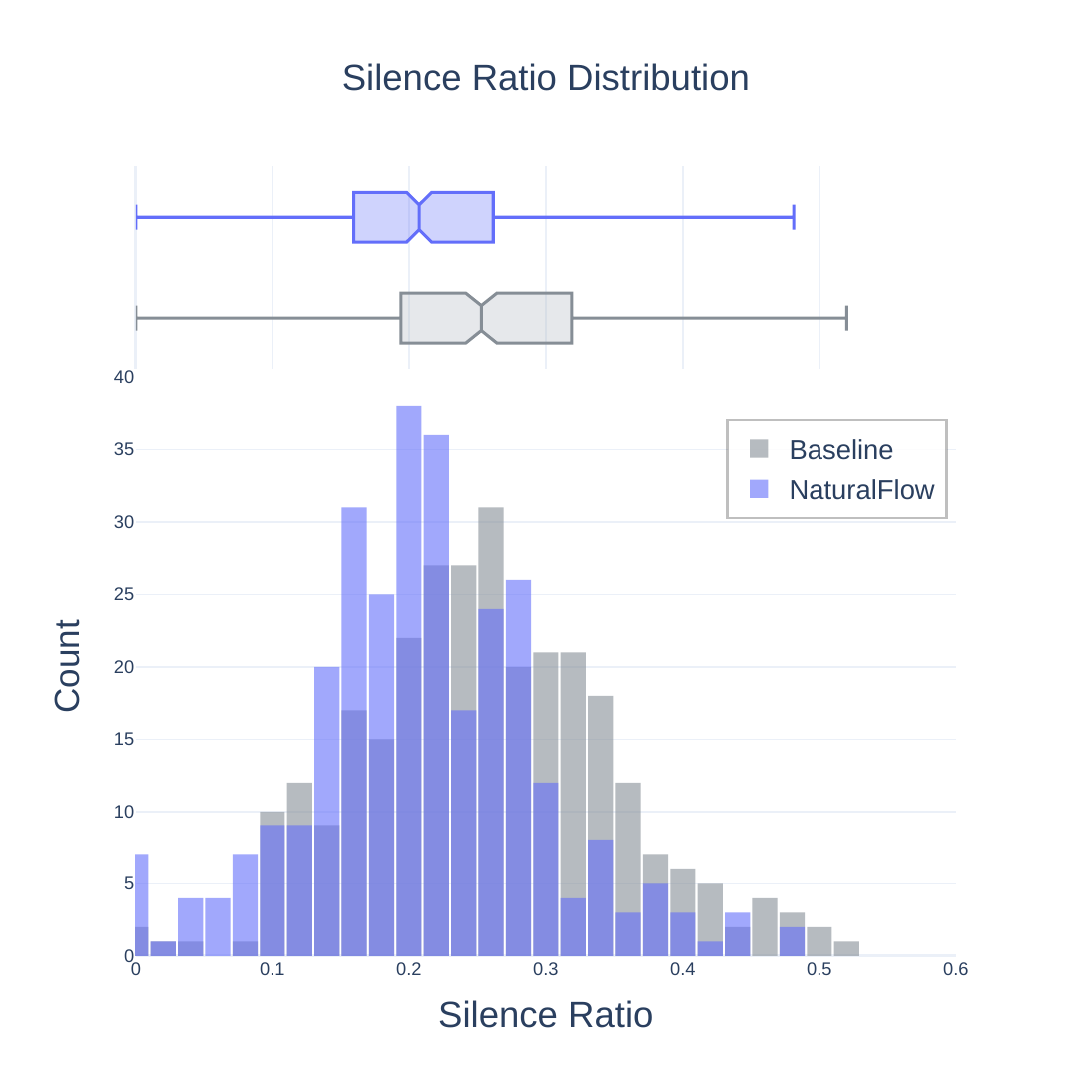
The main fluency metric is Silence Ratio (SR), defined as the fraction of the output speech span occupied by silence:
$$ \mathrm{SR} = \frac{D_{\mathrm{sil}}}{D_{\mathrm{span}}} = 1 - \frac{D_{\mathrm{voice}}}{D_{\mathrm{span}}}. $$
The paper computes SR from Silero VAD output and uses a minimum silence cutoff of 100 ms, so very short pauses are not counted as silence. On CVSS-C, because many clips naturally have SR close to zero, the paper additionally reports mean SR over the top 25% highest-SR examples ranked by Hibiki’s SR values.
Experimental setup and baselines
The main baselines are SeamlessStreaming, StreamSpeech, and Hibiki. The paper describes SeamlessStreaming as a multilingual streaming S2ST system, StreamSpeech as a multi-task simultaneous S2ST model, and Hibiki as a direct S2ST model that jointly emits text and audio tokens without an external control policy.
For SeamlessStreaming and StreamSpeech, the authors use SimulEval and then reconstruct the original streaming timeline by reinserting the inter-chunk silence intervals from the delay log before running VAD and ASR. This is important because the raw SimulEval waveform concatenates emitted chunks without preserving the actual stream-time silences, which would otherwise make the fluency metrics inconsistent with real-time behavior.
Main results
The primary claim is that NaturalFlow reduces silence ratio while keeping translation quality and latency competitive. The results are strongest on long-form benchmarks, where the model consistently improves fluency without collapsing into poor translation quality. On short-form benchmarks, the quality gains are more mixed, but the latency and silence improvements remain stable.
| Model | CVSS-C | VoxPopuli | Audio-NTREX | mTEDx | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SR | LAAL | Start | End | BLEU | COMET | SR | LAAL | Start | End | BLEU | COMET | SR | LAAL | Start | End | BLEU | COMET | SR | LAAL | Start | End | BLEU | COMET | |
| Human speech | 0.02 | - | - | - | - | - | 0.06 | - | - | - | - | - | 0.08 | - | - | - | - | - | 0.23 | - | - | - | - | - |
| StreamSpeech | 0.25 (0.49) | 1.96 | 1.97 | 1.77 | 22.15 | 0.61 | 0.36 | 2.26 | 1.31 | -1.26 | 7.06 | 0.34 | 0.60 | 4.51 | 1.22 | -18.24 | 0.76 | 0.20 | 0.62 | 5.47 | 1.92 | -14.74 | 1.13 | 0.21 |
| Seamless | 0.14 (0.42) | 3.24 | 3.40 | 2.85 | 35.74 | 0.83 | 0.27 | 3.65 | 2.67 | 5.05 | 19.74 | 0.73 | 0.27 | 4.63 | 2.82 | 3.30 | 25.34 | 0.37 | 0.65 | 7.72 | 3.43 | 21.28 | 27.55 | 0.41 |
| Hibiki | 0.08 (0.24) | 3.65 | 3.84 | 3.17 | 30.25 | 0.77 | 0.12 | 3.54 | 3.23 | 3.15 | 19.18 | 0.73 | 0.17 | 3.65 | 3.05 | 2.85 | 24.07 | 0.32 | 0.26 | 3.69 | 3.16 | 0.97 | 32.94 | 0.46 |
| NaturalFlow | 0.08 (0.11) | 3.46 | 3.33 | 2.96 | 25.30 | 0.70 | 0.10 | 3.36 | 2.70 | 3.03 | 17.40 | 0.66 | 0.13 | 3.49 | 2.79 | 2.53 | 23.96 | 0.34 | 0.21 | 3.38 | 2.58 | 0.82 | 33.27 | 0.46 |
Short-form findings. On CVSS-C, NaturalFlow matches the baseline Hibiki SR on the full set and improves SR on the high-SR subset, while keeping latency close to the baselines. Its translation scores are below the strongest quality baseline Seamless and below Hibiki on BLEU/COMET, but not by a large margin. On VoxPopuli, NaturalFlow attains the lowest SR and also slightly improves End Offset relative to the baseline Hibiki, though BLEU and COMET remain below Seamless and Hibiki.
Long-form findings. The fluency gains are clearer on Audio-NTREX and mTEDx. NaturalFlow achieves the lowest SR on both long-form benchmarks, the best LAAL on both, and the best or tied-best end-offset behavior. On mTEDx it also achieves the highest BLEU among the compared systems and ties the best COMET. On Audio-NTREX, its BLEU is slightly below Hibiki and Seamless, but it remains competitive while still reducing silence.
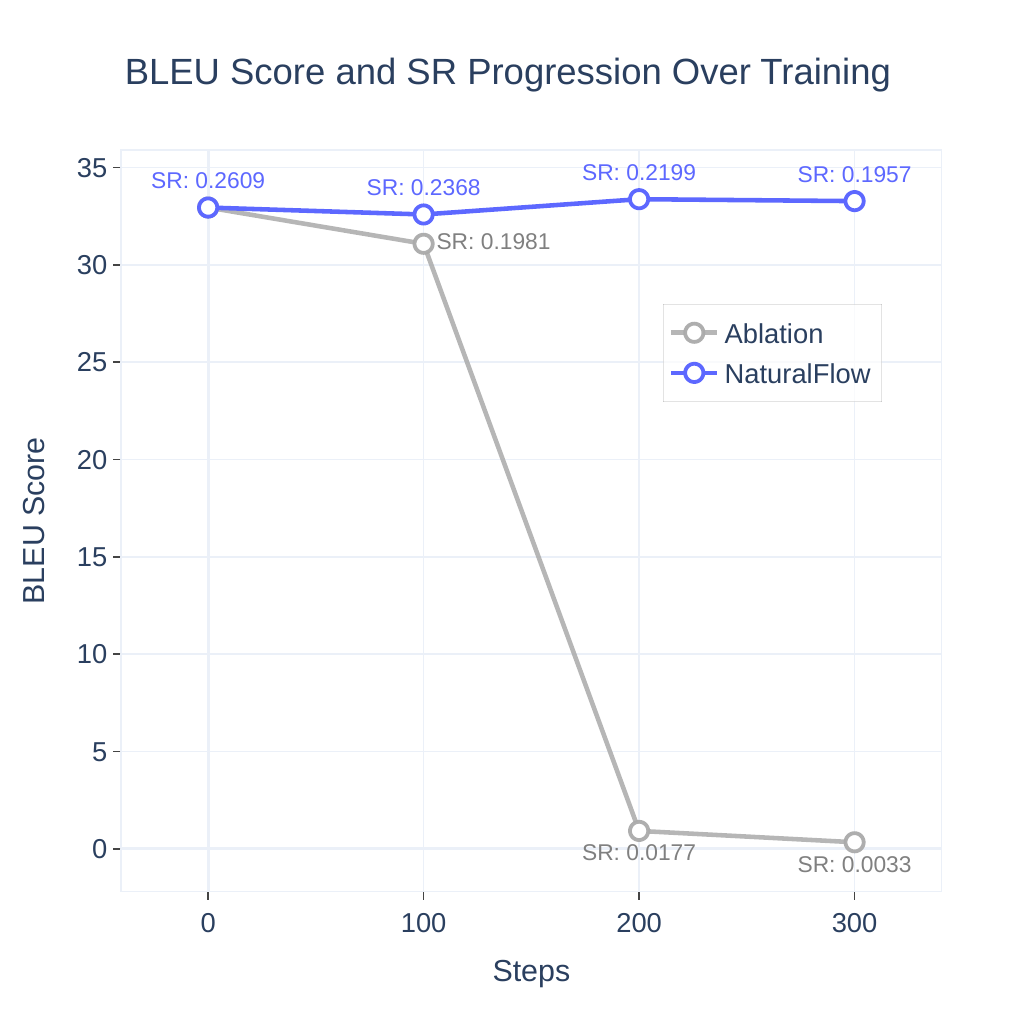
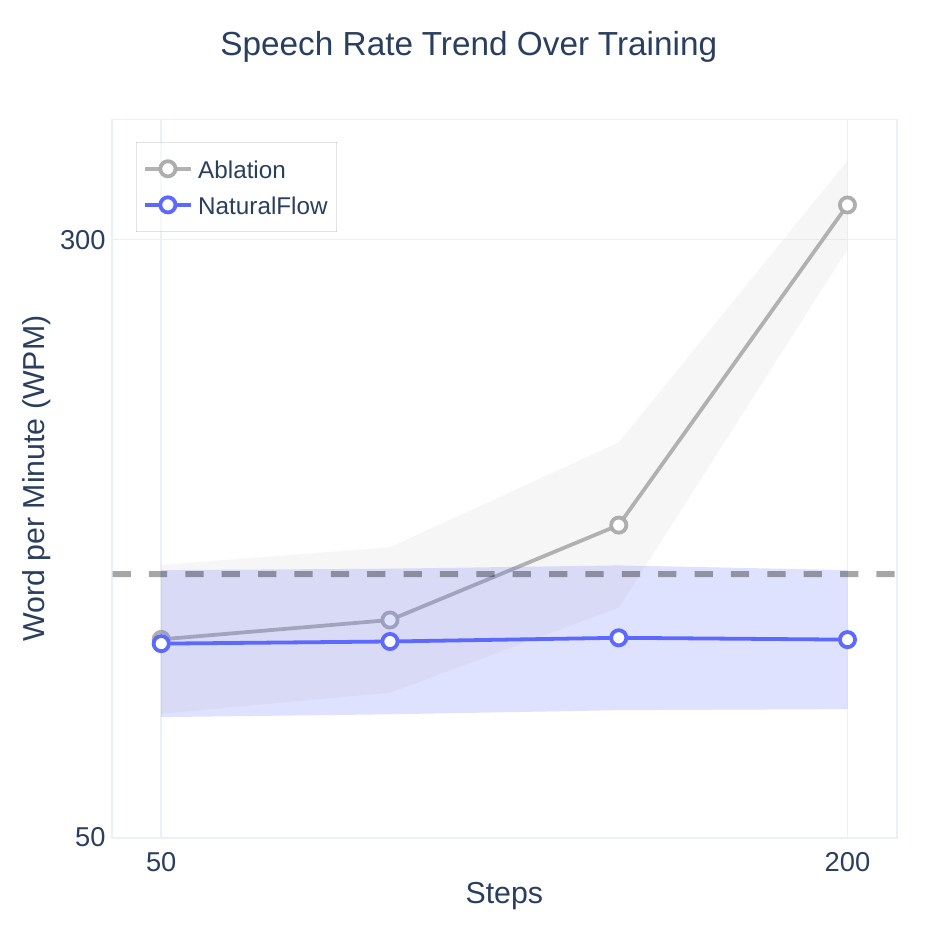
Ablation studies
The paper uses two ablations to test whether the Silver-Medal Preference design is actually needed or whether ordinary low-silence preference selection is sufficient. Both ablations are reported to fail in a similar way: they reduce silence aggressively but collapse translation quality.
| Model | CVSS-C | mTEDx | ||||
|---|---|---|---|---|---|---|
| SR | ASR-BLEU | ASR-COMET | SR | ASR-BLEU | ASR-COMET | |
| Ours | 0.11 | 25.30 | 0.70 | 0.21 | 33.27 | 0.46 |
| Ablation 1 | 0.01 | 1.50 | 0.26 | 0.00 | 1.41 | 0.18 |
| Ablation 2 | 0.00 | 1.60 | 0.25 | 0.00 | 0.92 | 0.17 |
Ablation 1: Standard setting. The chosen set is the top 20% lowest-silence candidates and rejected samples are randomly drawn from the rest, with a strict margin. This setup rapidly drives SR down, but BLEU collapses to near-zero levels on mTEDx and drops sharply on CVSS-C, showing that the model learns to speak almost continuously at the expense of intelligibility.
Ablation 2: Removing the low-SR group. When the lowest-silence group is removed from the rejection signal, the model becomes even more extreme. The paper describes this as producing excessively fast speech with near-zero silence, again destroying translation quality.
These ablations support the central design claim: the Silver-Medal strategy is not a cosmetic dataset heuristic. It is the mechanism that prevents preference optimization from collapsing into a degenerate “speak as fast as possible” regime.
Human evaluation
The paper includes a subjective evaluation on Amazon Mechanical Turk to test whether the automated SR improvements are perceptible to listeners. Because over half of CVSS-C examples naturally have SR $=0$ for both systems, the authors restrict the evaluation to samples from the top 25% of the baseline SR distribution. Raters see paired translation audio and choose the more natural and fluent output.
The paper reports approximately 150 judgments from 30 independent raters.
| Compared model | Preferred NaturalFlow | Tie | Preferred compared model |
|---|---|---|---|
| Baseline | 55% | 11% | 34% |
| Without Silver-Medal Preference | 68% | 8% | 24% |
The authors note that these results are statistically significant by a binomial test. The takeaway is that NaturalFlow’s lower silence ratio translates into a better perceived listening experience, and that the constrained Silver-Medal design itself is preferred over the ablated alternative.
What the paper claims as its main contribution
- It reframes simultaneous S2ST optimization to include acoustic continuity rather than only latency and translation quality.
- It introduces Silence Ratio as the primary fluency objective and evaluates it alongside standard translation and latency metrics.
- It proposes Silver-Medal Preference, a preference-construction rule that intentionally avoids selecting only the most silence-minimized candidates so that the model does not collapse into over-fast, low-quality speech.
- It applies length-normalized DPO to the text stream of a simultaneous S2ST model, using the acoustically grounded text policy rather than raw audio-token optimization.
- It shows that the method can lower silence ratio on both short- and long-form Fr-En benchmarks while keeping latency and translation quality competitive.
Scope and limitations reported or implied by the paper
The paper does not include a standalone limitations section, so the following are best understood as scope constraints visible from the experiments and method description rather than as explicitly enumerated caveats. The evaluation is limited to Fr-En benchmarks, and all reported experiments build on Hibiki-2B as the base architecture. The preference dataset is automatically constructed from sampled model outputs rather than from human preference annotations, so the optimization signal depends on the quality of the candidate generation and the chosen scoring pipeline. The paper also emphasizes that aggressively optimizing silence ratio without the proposed constraints can collapse translation quality, which suggests the method must be carefully balanced and may not transfer naively to other settings without retuning the preference construction rules.
Conclusion
NaturalFlow shows that simultaneous S2ST can be optimized for more than the traditional quality-latency trade-off. By constructing preferences that reward improved speech continuity but avoid extreme low-silence collapse, the model produces more natural acoustic flow while maintaining competitive translation and timing behavior. The strongest evidence comes from the long-form benchmarks and the human preference study, both of which support the claim that reducing disruptive pauses can materially improve the listener experience.