ReFree-S2V
ReFree: Towards Realistic Co-Speech Video Generation via Reward-Free RL and Multilevel Speech Guidance

ReFree-S2V generates realistic talking head videos with accurate lip-sync and natural expressions using multi-level speech features and reward-free reinforcement learning to improve animation quality without manual rewards or labels.
Links
Paper & demos
Impact
Abstract
Speech-driven talking character animation seeks to generate life-like portrait videos that convey natural conversation behavior, aligning facial motion with spoken audio. Although recent advances in video generation have substantially improved realism in video-based animation, achieving both accurate lip articulation and expressive behavior remains challenging. Existing approaches typically trade off precise phoneme-to-lip synchronization against dynamic facial expressions and head motion, yielding animations that are either accurate yet rigid, or expressive but poorly synchronized. We address this challenge by proposing ReFree-S2V, a flow-matching speech-to-portrait animation framework that builds upon a pretrained video generation model to achieve fine-grained speech articulation and high-level expressive cues in speech-driven portrait animation. This model introduces a multi-level speech representation capturing phonetic and prosodic information at both local and global granularities. These representations are selectively injected into transformer blocks via learnable level selectors, enabling both accurate lip synchronization and natural expressive motion. To achieve natural head movements, we further introduce a novel reward-free reinforcement learning scheme into flow-matching training to discourage perceptually implausible motion without relying on handcrafted synchronization metrics or reward models, or the high cost of human preference annotation. Extensive experiments demonstrate that ReFree-S2V achieves state-of-the-art performance, significantly outperforming existing methods in both quantitative lip-sync accuracy and qualitative human evaluations of naturalness and expressivity.
Overview
ReFree-S2V is a speech-to-portrait video generation framework for realistic co-speech animation. The paper targets the central tension in talking-head generation: methods often achieve either strong lip synchronization with rigid or under-expressive motion, or expressive head motion and facial dynamics with weaker speech-to-lip alignment. ReFree-S2V is designed to reduce that trade-off by combining (1) a multi-level speech representation that exposes both local phonetic detail and global prosodic context to different parts of the video model, and (2) a reward-free reinforcement-learning-style fine-tuning stage that improves realism without handcrafted rewards, pretrained reward models, or human preference labels.
The framework builds on a pretrained Wan 5B video generation model and trains in two stages. In supervised fine-tuning, speech is encoded at multiple temporal scales and injected into the diffusion transformer using multi-head FiLM blocks. In the second stage, the model is further refined with an automatically ranked set of synthetic negatives created by progressively masking the speech input. This curriculum is used to steer the model away from implausible motion while preserving strong speech alignment.

At a high level, the method is motivated by two observations from speech-driven human behavior. First, lip articulation depends on fine-grained, local phonetic evidence around each word or syllable. Second, expressive behavior such as eyebrow motion, head turns, and anticipatory gestures often depends on broader prosodic or semantic context, including information that can precede the visible speech event. The proposed model therefore explicitly separates and recombines speech information at multiple temporal scales instead of relying on a single flat audio embedding.
Problem setup and design goals
The task is portrait animation from a reference image and an input speech signal. The generated video should preserve identity, align the lips with the acoustic content, and maintain natural, conversation-like facial dynamics. The paper frames the challenge as balancing two objectives:
- Speech-to-lip synchronization: the mouth motion should match phonemes perceptually and temporally.
- Human-like expressivity: the head and face should move naturally, with prosody-driven expressions and plausible motion dynamics beyond the lip region.
Prior keypoint-based portrait animation methods can be accurate but often produce static or constrained expressions. More recent video-generation-based methods improve realism, but supervised fine-tuning alone does not reliably enforce fine-grained articulation or prevent implausible motion. ReFree-S2V is presented as a way to address both failures in a single framework.
Method
Backbone and training philosophy
The model is built on a pretrained flow-matching video diffusion transformer. The paper states that the base model is fine-tuned with low-rank adaptation on the pretrained DiT blocks, while the newly introduced speech-conditioning modules and multi-level speech encoder are fully trained. The overall system is then refined with a second optimization stage that discourages unrealistic motion through automatically generated negative samples.
Rather than using a hand-designed reward such as a synchronization score or a learned reward model, the paper constructs relative preferences from the data itself. This is central to the paper’s claimed novelty: realism is learned from comparisons between ground-truth samples and systematically degraded synthetic samples, not from external reward supervision.
Multi-level speech representation
The core conditioning idea is that speech contains information at different temporal scales. Local windows help with phonetic detail, while larger windows encode broader context such as prosody and longer-range dependencies. The encoder therefore uses multiple levels, where each level includes a CNN with kernel size $K_l$ and a shared MLP conditioned on a level-index embedding. Kernel sizes increase from the lowest to highest level so that the representation spans a continuum from local to global context.
The resulting multi-level feature set is denoted as a collection of level outputs $\mathbf{L}_1, \dots, \mathbf{L}_L$. A learnable selector forms a weighted aggregate:
$$\mathbf{A} = \sum_{i=1}^{L} \operatorname{softmax}(\mathbf{w})_i\, \mathbf{L}_i.$$
Here, $\mathbf{w}$ is a learnable vector of selection weights. The key point is that the model does not force every transformer block to consume the same speech granularity; instead, it can select an appropriate level depending on the block’s function.
This design is motivated by the fact that not all layers need the same receptive field. Lower-level blocks may benefit from local phonetic cues, while other blocks may need broader context for anticipatory or expressive motion. The paper explicitly notes that some facial motions begin before the speech event itself, so future speech information can be important for correct generation.
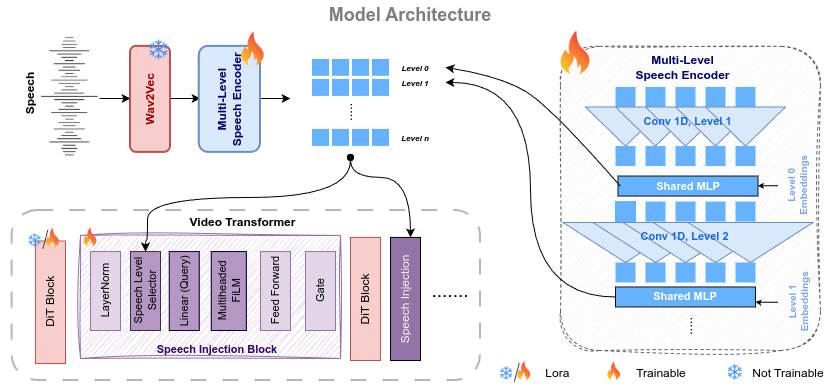
Speech injection via multi-head FiLM
The multi-level speech summary is injected into the video transformer through a speech-injection block based on multi-head FiLM rather than windowed cross-attention. The paper argues that this provides more flexible modulation because FiLM can learn both multiplicative scaling and additive shifting of visual features.
For each injection block, the speech levels are combined into a single conditioning vector $\mathbf{A}$, which is then used to parameterize per-head FiLM transformations. If $\mathbf{H}_{\text{in}}$ are the hidden video tokens and $K$ is the number of heads, the per-head operation is:
$$\mathbf{F}_k = \gamma_k \odot \mathbf{H}_k + \beta_k, \qquad k = 1, \dots, K,$$
followed by concatenation across heads. The paper emphasizes that this is more expressive than the windowed cross-attention used in some prior speech-to-video systems, because attention in that constrained form can behave like a primarily additive update, whereas FiLM gives explicit scale-and-shift control over the latent video features.
Reward-free RL fine-tuning
The second stage is the paper’s most distinctive optimization component. Instead of optimizing against a reward model, the method constructs an ordered set of synthetic samples from the same reference and same initial noise, but with progressively more speech masking. For each ground-truth item $s_0$, the model generates synthetic variants such as $s_1, s_2, \dots, s_N$, where each successive sample uses a higher masking ratio on the speech input. The paper describes a concrete curriculum with samples at 0%, 20%, and 40% masking.
The intuition is that stronger masking makes the generated video less synchronized, less expressive, and more artifact-prone. Because the samples share the same initial noise, the primary difference comes from the available speech guidance, making the ranking signal relatively clean. The ground-truth sample is treated as the most preferred item, and the degraded samples are treated as progressively worse negatives.
The optimization objective is a DPO-style pairwise ranking loss over all ordered pairs $(i,j)$ with $i<j$:
$$\mathcal{L}_{\mathrm{DPO}}^{\mathrm{all}} = -\mathbb{E}_{t \sim \mathcal{U}(0,1)} \sum_{i<j} \log \sigma\!\left(-\beta\,\omega_t\,[\Delta_\theta - \Delta_{\mathrm{ref}}]\right),$$
with
$$\Delta_u = \lVert \mathbf{v}_i - u(\mathbf{s}_i^t, t) \rVert^2 - \lVert \mathbf{v}_j - u(\mathbf{s}_j^t, t) \rVert^2.$$
Here, $u$ is either the current model or the reference model, $\mathbf{v}_i$ and $\mathbf{v}_j$ are velocity targets, $\omega_t$ is a timestep weight, and $\beta$ is the temperature parameter. The paper also updates the reference model with an exponentially moving average (EMA), gradually shifting the reference distribution as training progresses.

Conceptually, the paper positions this as a reward-free alternative to RL fine-tuning: the model learns from automatically synthesized preference tuples instead of external preference annotation or manually composed reward terms. The authors argue that realism and physical plausibility should emerge from direct comparison against unrealistic samples, rather than from an imperfect scalar reward that may overemphasize one aspect such as lip synchronization.
Training details
The supervised stage trains the model for approximately 50,000 steps on eight NVIDIA H100 GPUs. The optimizer is AdamW, with learning rate $10^{-4}$ for the first 30,000 steps and $10^{-5}$ for the remaining 20,000 steps. The paper also applies regional loss weighting in the SFT stage: the lip region gets weight 100, the rest of the face gets weight 30, and the remaining video frames use weight 1.
For the reward-free fine-tuning stage, the paper samples approximately 20,000 examples from CelebV-HQ and forms tuples containing the ground truth plus masked generations. This stage runs for around 5,000 steps with effective batch size 8, learning rate $10^{-5}$, and $\beta = 2500$. The optimizer is again AdamW. The paper states that the EMA reference model is important for slowly moving both policies toward higher realism.
Datasets and evaluation protocol
The training set combines three sources: Hallo3, CelebV-HQ, and Seamless Interaction. The Seamless Interaction data are described as studio-quality and useful for accurate speech-lip correspondence, but because they are not in-the-wild, they are sampled with lower probability during training.
For evaluation, the paper uses two settings:
- HDTF: approximately 200 clips, following prior work.
- In-the-wild: 50 randomly selected videos from the Hallo3 dataset.
All videos are resized to 480×480 and standardized to 15 FPS to ensure fair comparisons.
The baseline methods reported in the main experiments are Sonic, FantasyTalking, and Hallo3. The paper notes that these cover different backbone and conditioning choices: Sonic is built on Stable Video Diffusion, FantasyTalking uses a larger Wan 14B backbone, and Hallo3 uses CogVideoX with cross-attention audio injection.
Quantitative evaluation
The paper evaluates synchronization with Sync-C and Sync-D, overall realism with FID and FVD, facial-expression quality with mesh-FID, and motion richness with Dynamic Degree. For the in-the-wild comparisons, it additionally reports ID-Consistency, Subject Dynamics, Background Dynamics, and Aesthetic.
HDTF results
| Method | Sync-C ↑ | Sync-D ↓ | FID ↓ | FVD ↓ | Mesh-FID ↓ | Dyn. Deg. ↑ |
|---|---|---|---|---|---|---|
| Sonic | 7.406 | 7.444 | 13.242 | 72.142 | 0.0507 | 0.238 |
| FantasyTalking | 3.518 | 11.072 | 16.488 | 122.167 | 0.1094 | 0.021 |
| Hallo3 | 5.949 | 9.181 | 14.656 | 70.372 | 0.0336 | 0.516 |
| Ours w/o RL | 7.687 | 7.160 | 12.319 | 88.015 | 0.0290 | 0.534 |
| Ours | 7.999 | 7.011 | 11.643 | 86.182 | 0.0099 | 0.559 |
On HDTF, the full model achieves the best or tied-best results on almost every metric. Relative to the non-RL variant, the reward-free fine-tuning improves synchronization and visual quality further, producing the best Sync-C, Sync-D, FID, and mesh-FID, while keeping FVD highly competitive. The paper highlights that the improvement is not only quantitative but also visible in the qualitative examples, where lip shapes are aligned more accurately with phonemes and the facial motion is more varied.

In-the-wild results
| Method | Sync-C ↑ | Sync-D ↓ | FID ↓ | FVD ↓ | Mesh-FID ↓ | Dyn. Deg. ↑ |
|---|---|---|---|---|---|---|
| Sonic | 5.990 | 8.224 | 34.979 | 270.047 | 0.1340 | 0.22 |
| FantasyTalking | 3.001 | 11.294 | 37.877 | 277.888 | 0.2249 | 0.02 |
| Hallo3 | 5.041 | 9.669 | 38.762 | 281.060 | 0.1204 | 0.36 |
| Ours w/o RL | 6.064 | 8.096 | 36.921 | 277.768 | 0.1017 | 0.76 |
| Ours | 6.651 | 7.781 | 33.345 | 258.755 | 0.1304 | 0.58 |
In the unconstrained in-the-wild setting, the RL-enhanced model is best on Sync-C, Sync-D, FID, and FVD. The non-RL version, however, has the best Dynamic Degree and Mesh-FID. The authors interpret this as evidence that the reward-free RL stage damps overly explosive motion and makes generation more realistic, even if that slightly reduces raw motion magnitude. In other words, the optimization trades some exuberance for grounded realism.

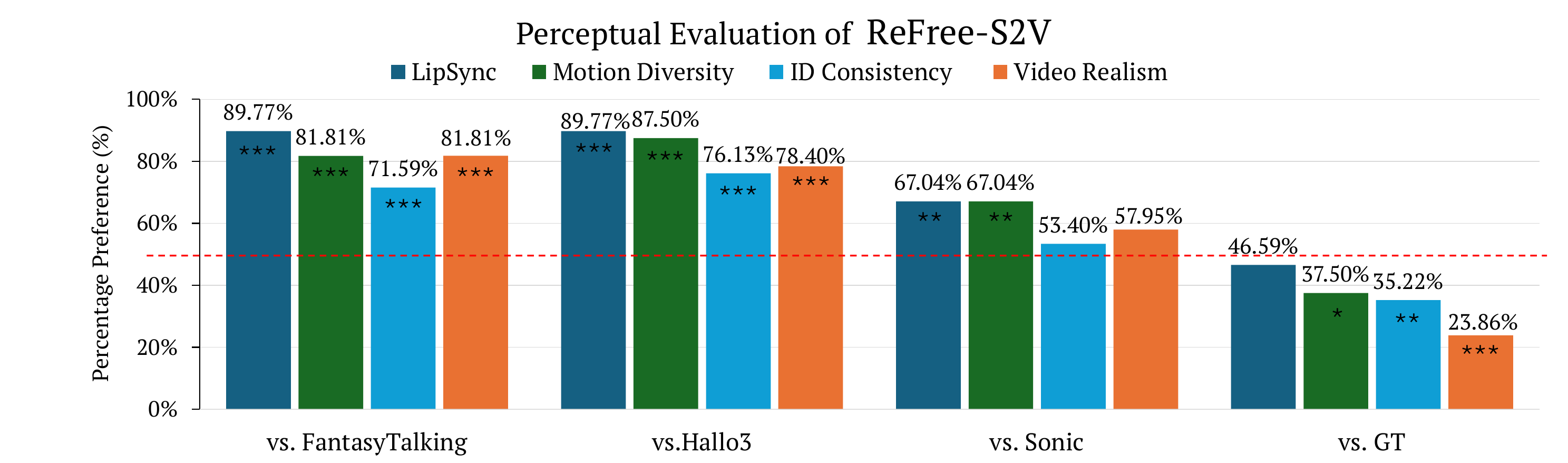
The user study reports pairwise preferences against four baselines. The paper states that ReFree-S2V outperforms all baselines across the evaluated perceptual dimensions, with especially strong gains in lip synchronization and realism. Against ground truth, the method achieves near-parity in lip sync and is preferred over GT in about 24% of cases for realism, indicating that users sometimes find the generated outputs more visually appealing or natural than the source recordings.
Ablations
Effect of multi-level speech and speech injection
The component ablation isolates two main design choices: the multi-level speech embedding and the multi-head FiLM injection mechanism. Removing the multi-level encoder causes the largest drop in synchronization, which is consistent with the paper’s thesis that different blocks benefit from different temporal neighborhoods. Replacing multi-head FiLM with cross-attention also reduces performance, though the drop is smaller. The paper concludes that the combination of multi-level guidance and FiLM-based conditioning is more effective than a flatter single-resolution audio representation and windowed cross-attention.
| Method configuration | Sync-C ↑ | Sync-D ↓ |
|---|---|---|
| Ours (full) | 1.721 | 12.505 |
| Without multi-headed FiLM (cross-attention) | 1.653 | 12.476 |
| Without multi-level embedding | 1.405 | 12.740 |
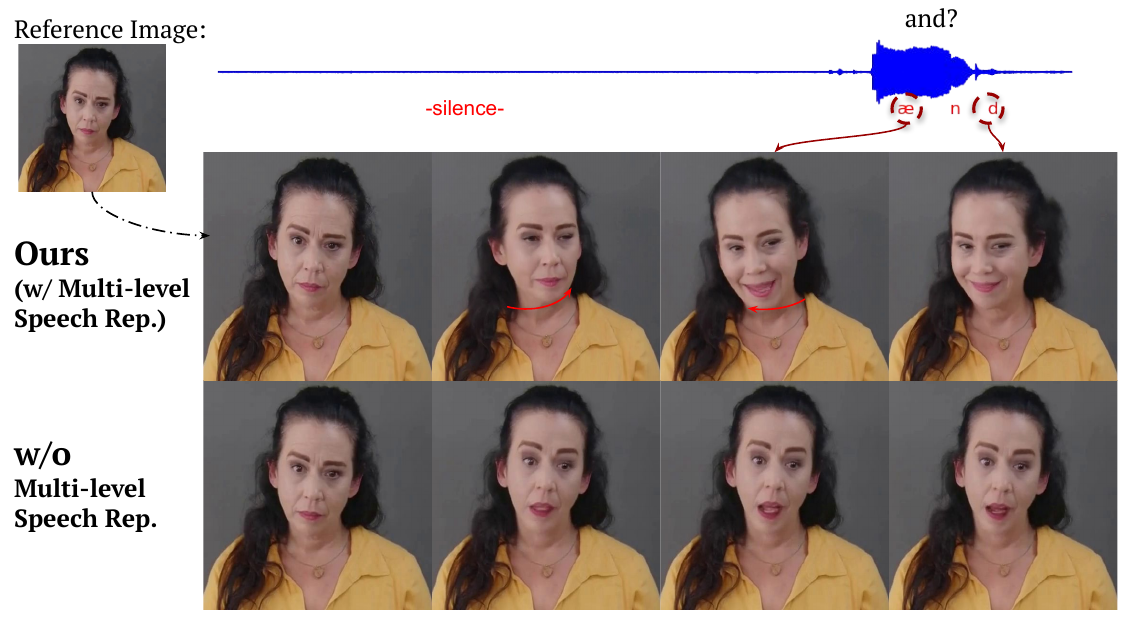
The qualitative ablation is particularly important because it demonstrates an anticipatory motion effect: with multi-level guidance, the model can begin motion before the related speech segment occurs. This is a concrete example of the long-range dependence the authors claim is lost when the speech encoder does not expose multiple temporal scales.
Effect of the reward-free RL strength
The paper studies the temperature parameter $\beta$ in the reward-free optimization. The values tested are 2500, 5000, and 7500. The resulting trade-off shows that different $\beta$ values favor different metrics, with smaller values generally better for some motion and synchronization outcomes, while larger values can improve some realism-related metrics but may reduce dynamism.
| Beta value | Sync-C ↑ | Sync-D ↓ | FID ↓ | FVD ↓ | Mesh-FID ↓ | Dyn. Deg. ↑ |
|---|---|---|---|---|---|---|
| 2.5k | 6.671 | 7.952 | 42.207 | 362.084 | 0.1922 | 0.84 |
| 5k | 6.665 | 7.904 | 43.962 | 307.885 | 0.2608 | 0.68 |
| 7.5k | 6.527 | 8.155 | 40.780 | 270.773 | 0.3232 | 0.60 |
The paper does not present a single universally best setting from this ablation; instead, the values expose the balance between synchronization, perceptual realism, and motion magnitude. The reported main model uses $\beta = 2500$ in the fine-tuning stage.
Efficiency and practical considerations
The appendix includes a simple efficiency comparison. ReFree-S2V uses 30.6 GB of VRAM and runs at about 0.7 FPS, which is more efficient than FantasyTalking and Hallo3 in the reported setup, though not as light as Sonic. The paper attributes the remaining computational cost to the underlying base video generator and notes that faster inference, few-step distillation, and efficient sampling are promising future directions.
| Method | VRAM (GB) ↓ | FPS ↑ |
|---|---|---|
| Sonic | 13.8 | 0.8 |
| FantasyTalking | 36.1 | 0.2 |
| Hallo3 | 48.3 | 0.1 |
| Ours | 30.6 | 0.7 |
Limitations, risks, and takeaways
The main limitation stated in the paper is efficiency: the model remains constrained by the base video generator, which keeps runtime and memory usage relatively high. The authors also note that future work should focus on fewer denoising steps and more efficient sampling.
In the appendix, the paper additionally flags broader social risks, including the potential misuse of talking-head generation for deceptive content and privacy violations. It recommends informed consent, transparent disclosure, and watermarking to distinguish synthetic outputs from real footage.
Overall, the paper’s technical contribution is a two-part recipe for realistic co-speech portrait generation: a multi-level speech-conditioning hierarchy for better alignment across local and global speech contexts, and a reward-free preference optimization scheme that uses automatically ranked masked samples to improve realism without human annotations or explicit reward engineering. The reported results show consistent gains over strong baselines on both controlled and in-the-wild data, with especially strong improvements in synchronization, visual fidelity, and perceived naturalness.