Endpoint Anticipation
Endpoint Anticipation for Low-Latency Spoken Dialogue
This paper proposes a proactive forecasting method for turn-endpoints in spoken dialogue, enabling downstream speech-to-speech pipelines to begin processing before the user finishes speaking. Unlike prior reactive systems, it reduces latency by speculative execution with controlled trade-offs on computation redundancy.
Demos
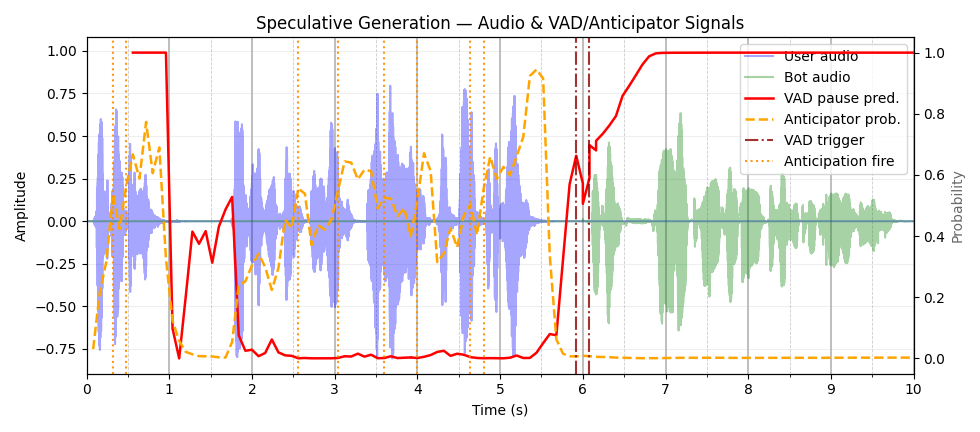
These demos show the Endpoint Anticipation model predicting end-of-turns up to 2.56 seconds early, enabling faster dialogue response by starting processing ahead of time. Evaluate how well the model anticipates turns versus reactive detection and its impact on reducing latency for smoother interaction.
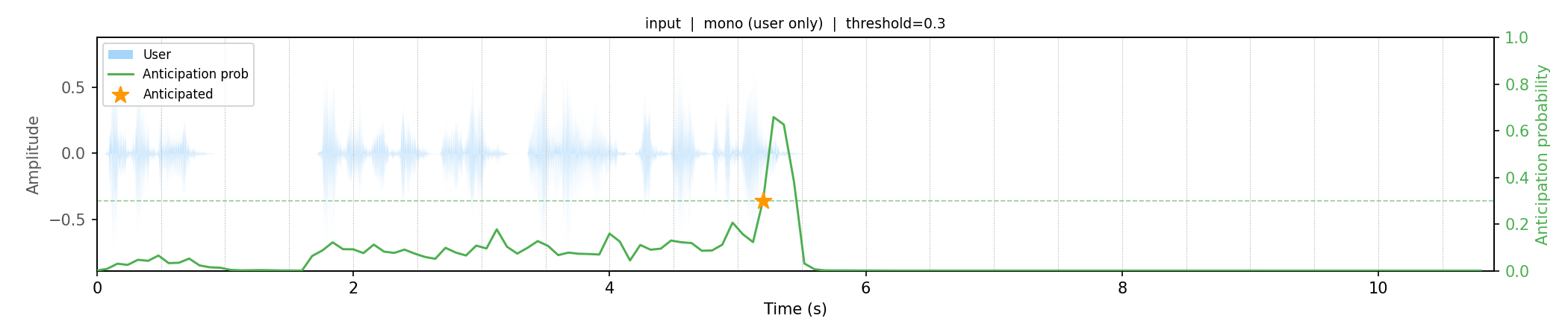
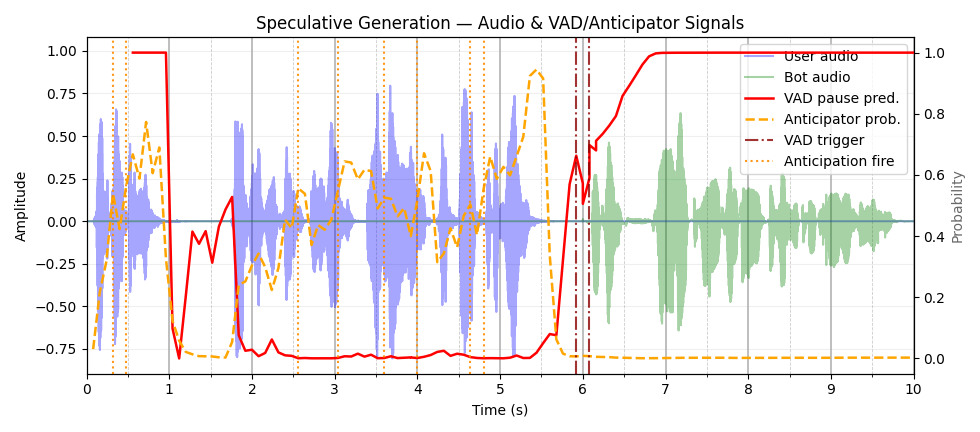
Links
Paper & demos
Code & resources
Impact
Abstract
While low-latency interaction is critical for spoken dialogue, cascaded architectures are often bottlenecked by reactive turn-completion detection. We propose Endpoint Anticipation, shifting from reactive detection to proactive forecasting of end-of-turn signals. Our speech-based model anticipates endpoints upto 2.56 seconds in advance, enabling speculative execution of LLM and TTS pipelines on partial context. We introduce metrics to quantify the trade-off between realized latency reduction and computational redundancy. Evaluation across conversational and task-oriented datasets shows our model consistently outperforms competitive VAP-based baselines. Integration with the Unmute framework demonstrates a 505 ms average latency reduction with a 28.4% increase in speculative computation, effectively masking sequential bottlenecks to enable complex reasoning in real-time speech-to-speech interaction.
Introduction
This paper tackles a central bottleneck in modular spoken dialogue systems: in cascaded speech-to-speech pipelines, downstream generation can only begin after an endpointer decides that the user has stopped speaking. That reactive design creates a latency floor for automatic speech recognition (ASR), large language model (LLM) reasoning, and text-to-speech (TTS) synthesis. The authors argue that this is increasingly problematic as real-time systems add more computation, such as reasoning, tool use, or retrieval, on top of a standard ASR-LLM-TTS stack.
To reduce this delay, the paper introduces Endpoint Anticipation (EPA): instead of detecting the end of turn after the fact, the system forecasts that an endpoint is likely to occur within a fixed future horizon. The anticipated endpoint then triggers speculative execution of the downstream pipeline while the user is still speaking. If the forecast is correct, the system can hide most of the sequential cost; if it is premature, the speculative computation is discarded and retried at a later forecast. The key contribution is therefore not only a new prediction task, but also a practical systems view of the latency-versus-redundancy trade-off.
The paper claims four main contributions: a speech-based EPA task, a set of metrics for measuring latency savings and wasted speculative compute, evaluation across anticipation horizons from $320$ ms to $2560$ ms, and a reference integration with the Unmute full-duplex framework.
Method
Dual-stream audio representation
The model consumes two streaming audio channels: the user stream and the system stream. For each frame timestamp $t$, the encoder processes the user features $X^{(u)}_{\le t}$ and system features $X^{(s)}_{\le t}$ separately with two independent streaming Transformers:
$$ Z^{(u)}_{\le t} = T_u(X^{(u)}_{\le t}), \quad Z^{(s)}_{\le t} = T_s(X^{(s)}_{\le t}) $$
The two latent sequences are concatenated to form a unified context vector $Z_{\le t} = [Z^{(u)}_{\le t}; Z^{(s)}_{\le t}]$. This design lets the model use both sides of the conversation, which matters for turn-taking phenomena such as backchannels, overlap, and interruptions.
Endpoint Anticipation task definition
EPA is formulated as a family of binary classification tasks indexed by anticipation horizon $h$. The horizon set is $\mathcal{H} = \{320, 640, \dots, 2560\}$ ms. For each horizon, the target at time $t$ is:
$$ y_t^{(h)} = \begin{cases} 1 & \text{if } 0 \le t_{\mathrm{EOT}} - t \le h, \\ 0 & \text{otherwise} \end{cases} $$
where $t_{\mathrm{EOT}}$ is the true end-of-turn time for the user. In other words, the model should fire only during the fixed window immediately preceding the endpoint. The feature frame rate is $12.5$ Hz, so the smallest horizon, $320$ ms, corresponds to exactly four frames.
At inference time, the model outputs a probability $p_t^{(h)}$ that an endpoint lies inside the target window. A binary decision is made by thresholding this probability with a fixed operating threshold $\theta$:
$$ \hat{y}_t^{(h)} = \begin{cases} 1 & \text{if } p_t^{(h)} \ge \theta, \\ 0 & \text{otherwise} \end{cases} $$
The first frame that crosses threshold becomes the trigger for speculative execution. The threshold therefore controls the core engineering trade-off: a lower threshold increases realized anticipation but also raises the chance of premature triggers and discarded downstream computation.
EPA-S and EPA-M architectures
The paper studies two architectural variants. EPA-S is single-target learning: a separate model is trained for each horizon, with a horizon-specific sigmoid head:
$$ p_t^{(h)} = \sigma(\mathbf{W} \mathbf{Z}_{\le t} + b) $$
This is simple and flexible, but the number of models scales linearly with the number of horizons. EPA-M is multi-target learning: a single shared dual-stream backbone is used for all horizons, and only the final layer branches into horizon-specific heads:
$$ p_t^{(h)} = \sigma(\mathbf{W}_h \mathbf{Z}_{\le t} + b_h), \quad \forall h \in \mathcal{H} $$
EPA-M is the more parameter-efficient design, and the experiments show that it is also the strongest overall configuration. The authors note that, unlike VAP-style setups, the loss is computed only for the primary speaker, while the other stream provides conversational context.
Metrics for latency reduction and redundancy
A major methodological contribution is the metric suite. The paper argues that conventional precision/recall is insufficient for a real-time system because it does not directly measure the latency reduction delivered to the downstream pipeline or the waste incurred by incorrect early triggers. The proposed metrics are:
| Metric | What it measures | Interpretation for deployment |
|---|---|---|
| Median Realized Anticipation (MRA) | Median of $t_{\mathrm{EOT}} - t_{\mathrm{pred}}$ over successful triggers inside the valid anticipation window | Actual latency saved before the endpoint |
| Premature Anticipation Rate (PAR) | Percentage of turns with at least one trigger before the valid anticipation window | How often the system speculates too early |
| Expected Redundant Computation (ERC) | Mean fraction of premature anticipations relative to the maximum possible number of speculative attempts for the turn length | Expected discarded downstream work |
| Horizon Entry Accuracy (HEA) | Binary accuracy for triggering at the target boundary, with a two-frame collar around the boundary counted as correct | How well the model matches the requested anticipation horizon |
Metrics are computed only for turns longer than the horizon, and results are examined as latency-versus-early-trigger curves over different prediction thresholds.
Experimental setup
Datasets and supervision
The model is trained and evaluated on two 8 kHz corpora: SpokenWOZ for task-oriented dialogue and Switchboard for conversational speech. The user stream in SpokenWOZ and the Speaker A stream in Switchboard are treated as the primary speakers. To obtain clean endpoint supervision, raw turn boundaries are refined with Silero VAD to remove trailing silence.
The training setup also explicitly suppresses unreliable supervision. The loss is masked for turns shorter than $2$ seconds, and for Switchboard the paper additionally requires a minimum of three words. Backchannels are masked as well, because they do not provide enough context for anticipating a meaningful turn completion.
Baseline: adapted VAP
The main baseline is pretrained Voice Activity Projection (VAP). Since VAP outputs $50$ Hz turn-taking probabilities over discrete bins rather than a continuous fixed-horizon forecast, the authors adapt it to the EPA evaluation protocol. They take the non-active speaker probability from the $p_{\mathrm{future}}$ distribution, downsample it to $12.5$ Hz via four-frame mean pooling, and tune the bin selection to the horizon being evaluated. To make the comparison as strong as possible, they search over bin combinations and report the best results: bins $[0,1]$ for the $640$ ms horizon and bins $[1,2]$ for the $1280$ ms window.
Training and model configuration
The feature frontend is Mimi neural codec, using the first eight codebooks. Audio is upsampled to $24$ kHz, features are extracted at $12.5$ Hz with zero lookahead, and the backbone is frozen so the same extractor can be reused downstream. The anticipation model is a $25$M-parameter streaming Transformer with $6$ encoder layers, $4$ attention heads, and feed-forward dimension $1024$. For long-form streaming, the authors use RoPE and causal masking with a fixed $250$-frame left context.
Optimization uses a learning rate of $3 \times 10^{-4}$, batch size $16$, and fixed $500$-frame segments, corresponding to $40$ seconds. To handle class imbalance, the loss weights positive frames and negative frames in a $10:1$ ratio. Training uses early stopping with patience $6$ based on mean accuracy across horizon and non-horizon frames.
Speech-to-speech integration with Unmute
The paper does not stop at offline anticipation accuracy. It integrates EPA into the Unmute speech-to-speech framework, which contains streaming ASR, LLM, and TTS modules coordinated by a semantic VAD endpointer. The reported setup uses Gemma 3 4B as the LLM, hosted with vLLM, and a Rust-based WebSocket backend with a Python client handling turn-taking and interruption logic.
EPA is used as a speculative execution trigger. On anticipation of an endpoint, the system forks conversation state and starts generating a short look-ahead buffer, described as roughly $10$ tokens. Those tokens are synthesized by TTS and stored in a speculative cache. If Unmute confirms that the turn actually ended within the horizon, the cache is released immediately and generation continues from the speculative prefix. If the endpoint does not arrive in time, the speculative response is discarded and the process restarts at the next anticipation event.
The intended effect is that, when speculation is successful, the user experiences latency close to the endpoint detector's response time rather than the full ASR-LLM-TTS chain.
Results and discussion
The paper presents three main sets of results: direct comparison against VAP, comparison across dataset types, and end-to-end system integration with Unmute. Two figures from the paper are reproduced below.
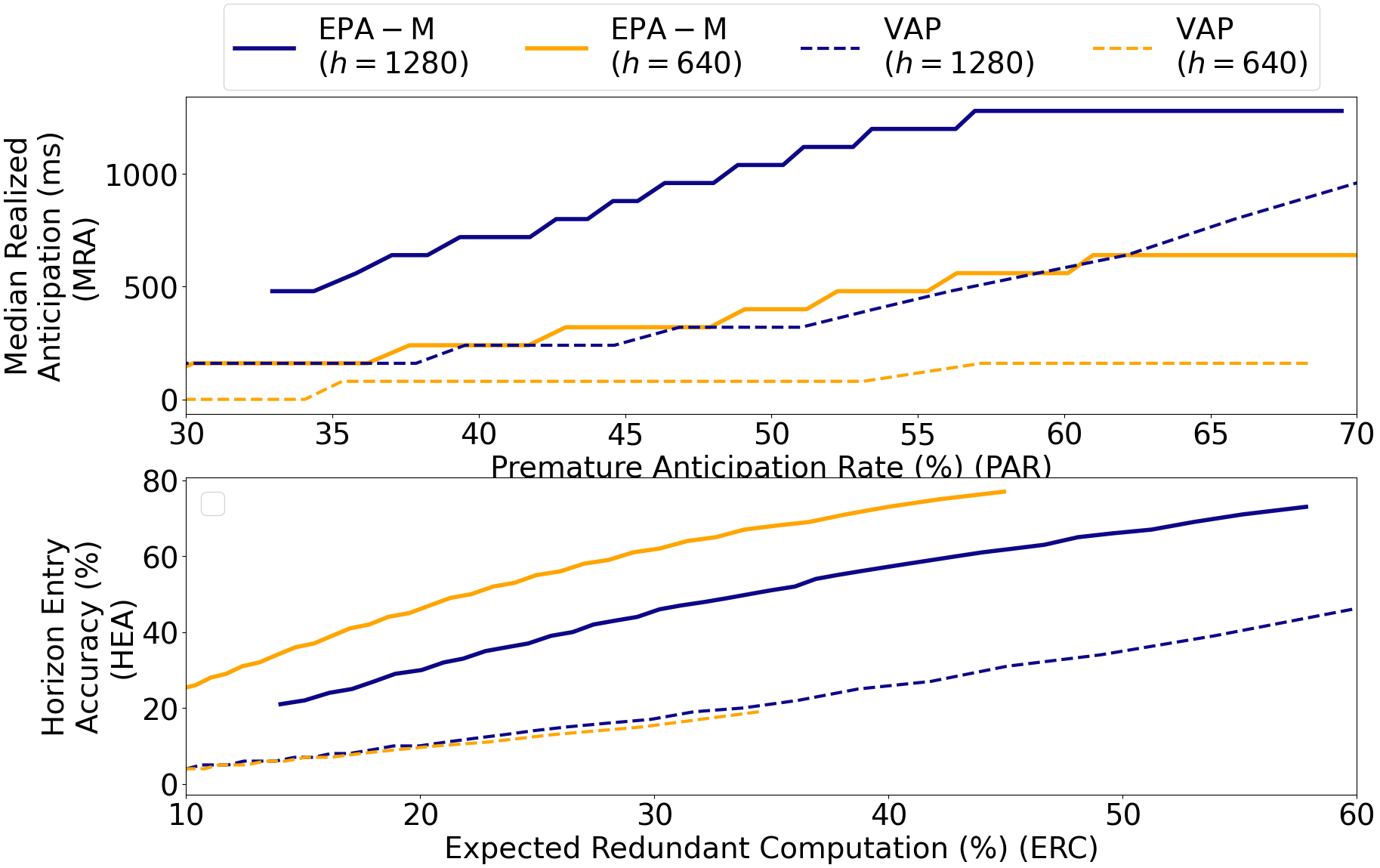
Comparison with VAP on SpokenWOZ
The first figure and the operating-point table show that EPA-M substantially outperforms the adapted VAP baseline on SpokenWOZ. The superiority is clearest in the metrics that matter most for deployment: MRA and HEA. VAP sometimes achieves slightly lower premature-trigger rates in a given operating regime, but it does so at the cost of much weaker anticipation precision and much smaller realized latency savings.
At the $640$ ms horizon, EPA-M achieves the full target MRA of $640$ ms, while VAP reaches only $160$ ms. HEA also jumps from $19.2\%$ for VAP to $67.0\%$ for EPA-M, with PAR remaining in the same general range. At $1280$ ms, the gap remains large: EPA-M reports MRA of $1120$ ms versus $320$ ms for VAP, and HEA of $49.7\%$ versus $20.8\%$.
Under the stricter operating regime with ERC near $15\%$, EPA-M still provides useful anticipation, reporting MRA of $480$ ms and HEA of $22.1\%$, while VAP drops to MRA of $80$ ms and HEA of $7.2\%$. The authors' interpretation is that VAP can be a reasonable turn-taking model in general, but it is not well matched to fixed-horizon endpoint forecasting; EPA is explicitly optimized for that deployment objective.
| Model | $h$ | MRA (ms) | HEA (%) | PAR (%) | ERC (%) |
|---|---|---|---|---|---|
| VAP | 640 | 160 | 19.2 | 68.3 | 34.5 |
| EPA-S | 640 | 640 | 66.3 | 66.5 | 33.9 |
| EPA-M | 640 | 640 | 67.0 | 66.2 | 33.8 |
| VAP | 1280 | 320 | 20.8 | 51.0 | 33.8 |
| EPA-S | 1280 | 1200 | 50.3 | 53.9 | 33.7 |
| EPA-M | 1280 | 1120 | 49.7 | 52.8 | 33.2 |
| VAP | 1280 | 80 | 7.2 | 28.8 | 15.4 |
| EPA-S | 1280 | 480 | 22.0 | 34.4 | 15.1 |
| EPA-M | 1280 | 480 | 22.1 | 34.3 | 15.1 |
The table above reproduces the operating points reported in the paper for the two highlighted ERC regimes, around $33\%$ and around $15\%$. The important takeaway is that EPA-M consistently improves the quality of the anticipation signal, especially in terms of matching the target horizon.
EPA-S versus EPA-M
The paper's architecture comparison shows that EPA-S and EPA-M are both viable, but the differences are small enough that the authors prefer EPA-M on practical grounds. EPA-M reaches essentially the same or slightly better scores without needing horizon-specific retraining. This means one shared model can serve multiple anticipation targets, which is operationally attractive when a system needs to expose several latency budgets.
In the reported operating points, EPA-M is never meaningfully worse than EPA-S, and sometimes marginally better in HEA and PAR. The main distinction is efficiency: EPA-M avoids training and storing separate models for each horizon.
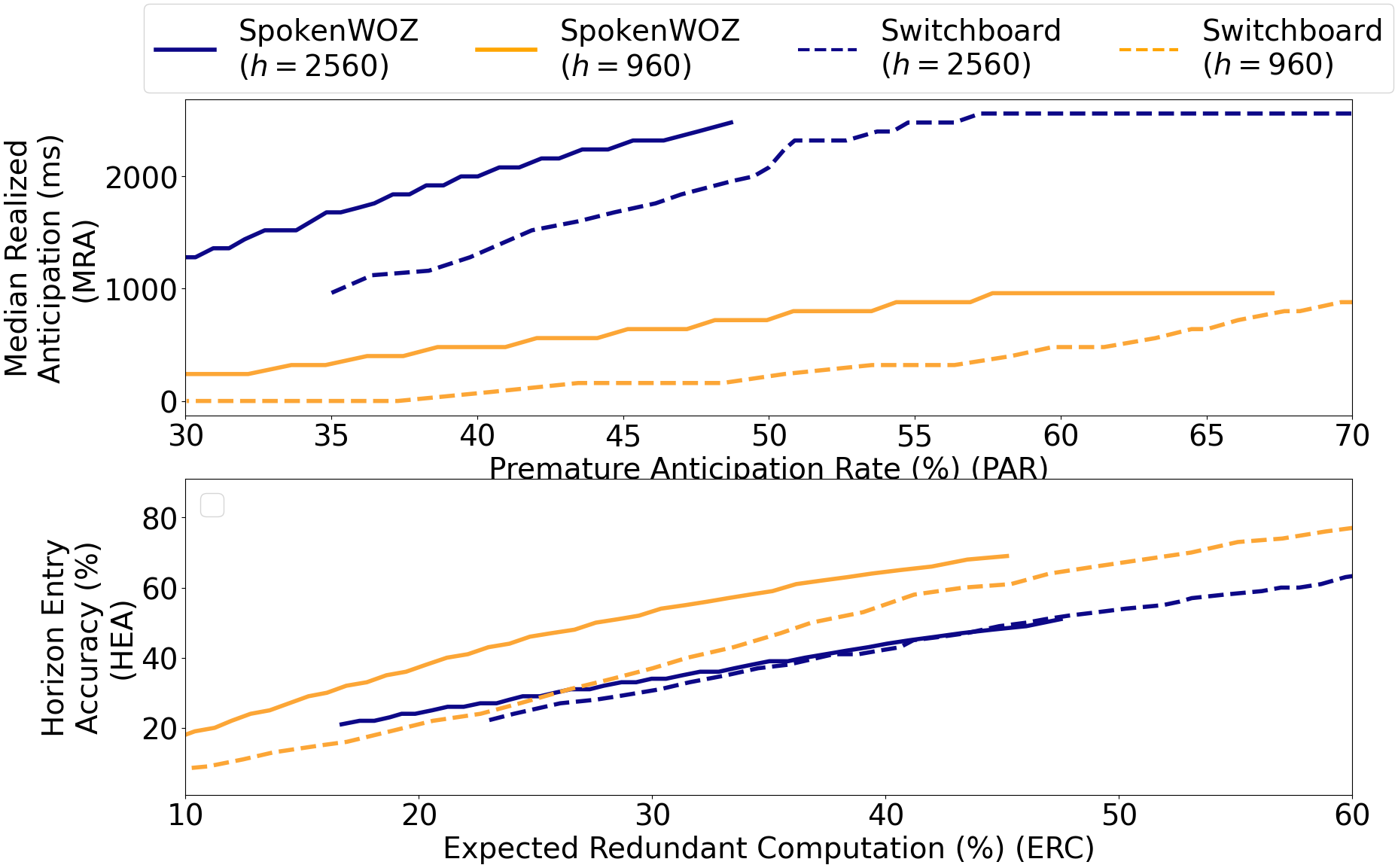
Task-oriented versus conversational speech
The second figure compares SpokenWOZ and Switchboard and makes an important point about domain difficulty. Across both shorter and longer horizons, the model performs better on SpokenWOZ than on Switchboard. The paper states that, for any fixed PAR, SpokenWOZ gives higher MRA, and for any fixed ERC budget it gives higher HEA. This indicates that structured task-oriented dialogue is easier for endpoint anticipation than open-domain conversational speech.
The authors interpret this as evidence that conversational spontaneity, including unpredictable continuation, is a major obstacle for fixed-horizon forecasting. As a result, the method is currently most attractive for structured applications, where turn endings are more regular and the model can better infer when the user is about to stop speaking.
End-to-end Unmute integration
The most systems-relevant result is the integration experiment with Unmute. The baseline system reports average latency of $1195$ ms, while the EPA-M integration reduces that to $690$ ms, a reduction of $505$ ms. The corresponding ERC is $28.4\%$.
| System | Avg. latency (ms) | ERC (%) |
|---|---|---|
| Unmute baseline | 1195 | -- |
| Unmute + EPA-M | 690 | 28.4 |
The authors decompose the residual latency into three sources: turns where anticipation is not strong enough to trigger early speculation, semantic VAD trigger delay, and inter-process WebSocket overhead. They also note that the experiment uses local LLM and TTS components, so the benefit would likely be even larger with API-based systems that have higher intrinsic latency.
From a systems perspective, this integration is the clearest demonstration of the paper's thesis: endpoint anticipation can mask the sequential bottleneck of cascaded dialogue systems without changing the rest of the stack. In other words, the framework enables modular systems to behave more like low-latency full-duplex systems, even though generation remains internally sequential.
Limitations and practical implications
The paper is explicit that endpoint anticipation is not universally easy. Performance is better on structured task-oriented speech than on open-domain conversational speech, which means deployment quality will vary by domain. The metric design also highlights an inherent tension: better realized anticipation comes at the cost of more speculative compute if the model fires too early. The reported ERC values quantify that overhead, but they also show that the overhead does not vanish entirely.
The authors further indicate that the current evaluation focuses on turn completion and does not attempt to re-solve broader turn-taking problems such as interruption handling; those capabilities are treated as orthogonal and left to the underlying system. In the conclusion, they also identify semantic edge cases as future work, specifically mid-turn backtracking and late-arriving critical information. Those cases matter because a model that anticipates too aggressively may be correct at the acoustics level but wrong at the semantic level.
Still, the paper's practical message is clear: if a system needs modular ASR, reasoning, and TTS, anticipating the endpoint can substantially hide the latency of the downstream stack. The reported gains are large enough to matter in real conversational settings, and the multi-target EPA-M formulation is the recommended version because it is both effective and operationally flexible.
Conclusion
Endpoint Anticipation reframes low-latency turn taking as a forecasting problem rather than a detection problem. By predicting endpoints up to $2.56$ seconds ahead, the model allows speculative LLM and TTS computation to begin before the user has actually finished speaking. Across SpokenWOZ and Switchboard, EPA-M consistently outperforms the adapted VAP baseline on the paper's task-specific metrics, especially on realized anticipation and horizon entry accuracy. When integrated into Unmute, it reduces average latency from $1195$ ms to $690$ ms while incurring $28.4\%$ redundant speculative computation.
For a conversational-AI stack, the main engineering takeaway is that endpoint anticipation can partially hide the sequential cost of cascaded pipelines, enabling modular systems to support more complex reasoning without paying the full end-of-turn delay.
Code & Implementation
This repository contains two main components that implement the method described in the paper:
-
Anticipation Model (
anticipation-model/)A streaming, speech-based endpoint anticipation model predicting end-of-turn probabilities up to 2.56 seconds in advance using a causal transformer architecture over neural audio codec (NAC) features. It supports dual-stream audio configurations and outputs per-frame probabilities to forecast turn completion.
The code includes data preparation, training, and inference pipelines, with model configurations supporting multiple forecast horizons. Inference can be run on single audio files using
infer.py. Pretrained model checkpoints are available on HuggingFace. -
Unmute Integration (
unmute-integration/)This builds upon the Unmute real-time spoken dialogue framework, integrating the anticipation model into the orchestration of the dialogue system:
- The anticipation model triggers speculative calls to the LLM and TTS pipelines during the user's turn before the actual end-of-turn is detected.
- Speculative audio is buffered and conditionally committed once voice activity detection (VAD) confirms the turn's end, effectively reducing latency.
- A continuation mechanism ensures smooth transition from speculative generation to final LLM output and TTS synthesis.
Scripts for offline evaluation of latency reduction and computational trade-offs are included. The integration uses existing high-quality Unmute components for ASR, VAD, LLM (vLLM), and TTS.
The provided README files in each subdirectory offer detailed instructions for setup, training, inference, and evaluation. The anticipation model can be invoked via run.py with configuration files specifying datasets, model parameters, and checkpoints. The Unmute integration requires running multiple services and demonstrates usage on benchmark datasets with example scripts.