ModeratorLM
Adaptive Turn-Taking for Real-time Multi-Party Voice Agents
ModeratorLM is a role-conditioned voice agent for real-time multi-party conversations that adapts turn-taking based on explicitly assigned roles, improving precision and reducing interruptions compared to traditional methods by integrating role-specific reasoning and behavior.
Links
Paper & demos
Impact
Abstract
Turn-taking in multi-party spoken conversations remains a fundamental challenge for voice-based agents, particularly under dynamic floor competition and varying user expectations. We propose ModeratorLM, a role-playing voice agent that conditions turn-taking behavior on an explicitly assigned role in multi-party settings. The system is built on a speech large language model operating in chunk-wise streaming manner. We further introduce a reasoning-augmented variant that incorporates chain-of-thought reasoning over conversational context and the assigned role. We construct RolePlayConv, a large-scale synthetic dataset of spoken multi-party conversations with diverse assistant roles. Experiments on real-world meeting data and RolePlayConv show improved turn-taking precision by over 40% and recall by more than 70%, while substantially reducing false-positive interruptions compared to non-role-conditioned baselines.
Introduction
This paper addresses turn-taking for real-time voice agents in multi-party spoken conversations, where the agent must decide not only when to speak but also whether to intervene at all. The setting is substantially harder than dyadic dialogue because of overlapping speech, dynamic floor competition, negotiated speaker selection, and varying expectations about the assistant’s role. The core idea is that an assistant should not use a single universal turn-taking policy; instead, its behavior should be conditioned on an explicitly assigned role such as a facilitator, observer, or more passive listener.
The paper’s main contribution is ModeratorLM, a role-playing voice agent built on a speech large language model that operates in a chunk-wise streaming regime. ModeratorLM conditions turn-taking decisions on a role description and can either remain silent or take the floor and generate a response. The authors also introduce ModeratorLM-Think, a reasoning-augmented variant that generates chain-of-thought style intermediate reasoning over the current conversational context and role before deciding whether to speak.
To train and evaluate these models, the authors create RolePlayConv, a large synthetic dataset of spoken multi-party conversations with diverse assistant roles. Across a real meeting dataset and the synthetic evaluation set, the paper reports large gains over non-role-conditioned baselines in precision, recall, and false-positive control, indicating that explicit role conditioning is an effective behavioral constraint for multi-party voice agents.
Problem Setting and Core Design
The paper frames turn-taking as a chunk-level binary decision problem. For each incoming audio chunk, the model must decide either:
- Turn-taking + response: emit a control token indicating the assistant should take the floor, followed by the assistant’s textual response;
- No-turn: emit an empty output sequence, meaning the assistant remains silent for the current chunk.
This is important because the model is evaluated in a streaming setting, so decisions are made repeatedly as audio arrives. Unlike systems that rely on a separate voice-activity-detection or turn-boundary module, ModeratorLM delegates the entire turn-taking decision to the speech LLM itself.
The paper emphasizes that role conditioning matters because user expectations are context dependent. A facilitator, moderator, or active participant should behave differently from a passive listener. By binding the decision policy to a role description, the model can learn not just conversation dynamics but also role-specific obligations about interruption, deference, and responsiveness.
Figure: Reasoning and Turn-Taking Behavior
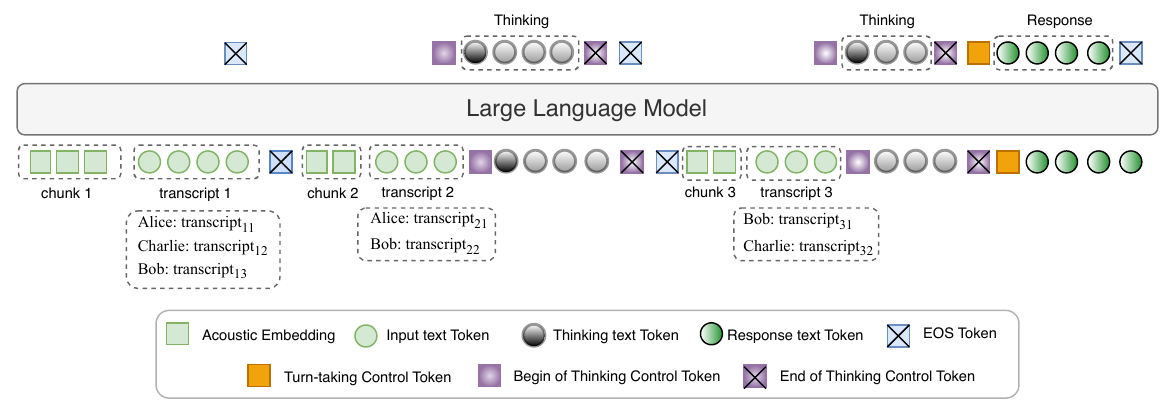
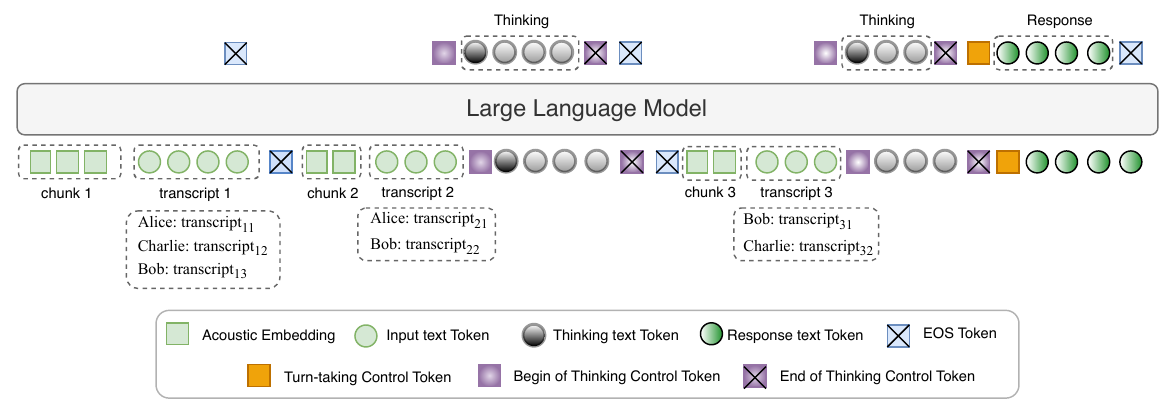
The figure illustrates the intended separation between internal deliberation and speaking. In the first chunk, the model produces no reasoning trace. In the second chunk, it can generate a reasoning trace while still choosing not to intervene. In the third chunk, the assistant takes the floor. This is the behavioral pattern the paper aims to learn: explicit role-aware reasoning that can remain silent when appropriate.
Method: ModeratorLM Architecture
ModeratorLM consists of two main components: a speech encoder and a backbone LLM. Incoming audio is first processed chunk by chunk by the speech encoder, which produces chunk-level embeddings. These embeddings are projected into the LLM embedding space through a trainable linear projection layer. The paper notes that multi-channel audio is downmixed to a single channel before encoding.
The chunk embeddings are appended sequentially to the LLM context in streaming fashion. For each chunk, the model also receives the corresponding text transcription with speaker annotations. This combination of speech and text is used so that the LLM can exploit both acoustic continuity and lexical content when deciding whether the assistant should respond.
ModeratorLM is trained to produce one of two output types. In the non-speaking case, it emits no tokens. In the speaking case, it emits a control token and then the assistant’s text response. The response itself is generated as text rather than speech codes; the authors explicitly note that a streaming text-to-speech module could be attached downstream, or speech token generation could be integrated directly in the future.
ModeratorLM-Think extends this setup by inserting a chain-of-thought reasoning step at potential turn-taking points. The model first reasons about the conversational context and the assigned role, and only then decides whether to speak. In the examples and results, this explicit reasoning improves both responsiveness and role fidelity.
RolePlayConv: Synthetic Multi-Party Role-Conditioned Data
The paper argues that existing spoken conversational datasets are not well suited to role-conditioned assistant training. Text-only role-playing corpora exist, and spoken multi-party corpora such as MELD provide multiple speakers, but they do not encode the notion of an assistant role. To fill this gap, the authors construct RolePlayConv, a large synthetic corpus designed specifically for role-playing voice agents.
The dataset construction pipeline is multi-stage:
- Role creation. The authors curate 125 detailed assistant roles, including demographic information, conversational style, tone, and preferred behavior. The examples include roles such as a confident CEO or a thoughtful literature student.
- Dialogue generation. For each conversation, one role is sampled and used to condition dialogue generation. Amazon Nova Pro is used to generate coherent multi-party conversations with three to six speakers.
- Topic alignment. Topics and subtopics are constrained to match the selected role so that the content is coherent with the persona and conversational style.
- Length control. Individual dialogue turns are limited to fewer than 15 words to better reflect spoken interaction and to keep exchanges concise.
- Reasoning supervision. After the base conversations are generated, all assistant turns and a subset of non-assistant turns are augmented with LLM-generated reasoning traces. These traces supervise ModeratorLM-Think.
- Speech synthesis. The textual conversations are synthesized into speech using Zonos-v0.1 TTS. Speakers are assigned demographic attributes and mapped to reference voices, with separate speaker pools for train and evaluation splits to avoid leakage. Silence intervals between turns are sampled from a distribution estimated from real conversational data.
The resulting training corpus contains approximately 75K conversations, with each conversation averaging roughly two minutes in duration. The paper positions this dataset as a large-scale synthetic resource for studying role-conditioned multi-party voice interaction.
Training Pipeline
The backbone models are Qwen3-4B-Instruct-2507 for ModeratorLM and Qwen3-4B-Thinking-2507 for ModeratorLM-Think. The speech encoder is an in-house model trained with variable lookahead, enabling block-wise attention during inference on variable-sized chunks.
To obtain streaming training inputs, the authors use the Montreal Forced Aligner to compute word-time alignments and derive chunk boundaries. Chunk lengths are randomly sampled between $0.5$ s and $3$ s during training, which makes the model robust to different chunking policies. The training procedure also ensures that some chunks end at speaker boundaries, because these are natural turn-taking points.
The paper uses a three-stage training pipeline:
- Speech–LLM alignment. The projection layer is trained on ASR data to align speech embeddings with the LLM input space. This stage uses about 90K hours of public speech data, including VoxPopuli, MLS, Common Voice, and People’s Speech. All parameters except the projection layer are frozen.
- Conversation pretraining. The model is then trained on AMI and Fisher multi-party conversations. Since these corpora do not define an assistant speaker, the paper simulates one by rotating the assistant role among all speakers except the conversation initiator, creating $N-1$ instances for a conversation with $N$ participants.
- Role-conditioning training. The final stage fine-tunes on RolePlayConv, with the assistant role specified in the system prompt.
For the second and third stages, the LLM is fine-tuned using LoRA, while the speech encoder remains frozen throughout. The total number of trainable parameters is reported as 13.4M. Optimization uses Adam with a two-phase learning-rate schedule and peak learning rate $1 \times 10^{-5}$.
Inference and Evaluation Protocol
The paper evaluates turn-taking at the chunk level, treating each incoming chunk as a potential intervention point. During evaluation, chunk durations are uniformly sampled between $0.5$ s and $3$ s, and segmentation always occurs at speaker boundaries. Because dynamic chunking introduces stochasticity, the authors average metrics over 10 evaluation runs.
For each test chunk, the ground-truth conversation context is teacher-forced together with the audio chunk before generation. Greedy decoding is used by default. If the model emits a special thinking token, the system switches to sampling for the reasoning tokens. Likewise, once a turn-taking control token is emitted, sampling is used to generate the response. The sampling parameters are temperature $0.7$, top-$p$ $0.8$, and top-$k$ $20$.
The paper reports the following metrics:
- Precision, Recall, F1, and Macro-accuracy for chunk-level turn-taking decisions;
- False Positive Rate, to measure spurious interruptions;
- Reactive Miss Rate, which measures the fraction of missed opportunities where a speaker directly addresses the assistant.
To evaluate subjective role fidelity, the authors also use an LLM-as-a-judge setup with Claude-Sonnet-3.5. The judge receives the role description and the conversation history and scores (i) appropriateness of the turn-taking decision on a $0$–$1$ scale and (ii) response role fidelity on a $1$–$10$ scale. A 100-instance human evaluation yields a Spearman correlation of $\rho = 0.87$ with the LLM-based judgments, suggesting that the automated subjective evaluation tracks human preference reasonably well.
The baselines are:
- Moshi (using the Moshika female-voice variant), which is designed primarily for dyadic conversations. Because it emits continuous streaming outputs at 12.5 Hz, evaluation uses a $\pm 0.5$ s tolerance window around ground-truth turn-taking points.
- MP-Baseline, which is the same model as ModeratorLM after conversation pretraining but without role conditioning. This baseline isolates the effect of role-aware fine-tuning.
Main Results
The main results show that role conditioning materially improves turn-taking behavior, especially in multi-party settings. Moshi, despite being a strong real-time voice model, generalizes poorly to these settings: it has low recall and very high false-positive rates. MP-Baseline improves over Moshi on multi-party data, but still lacks the precision and role adherence needed for assistant-style behavior. Both proposed models substantially outperform these baselines.
| Model | NOTSOFAR-1 | RolePlayConv | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Accuracy | FPR | RM | Precision | Recall | F1 | Accuracy | FPR | RM | |
| Moshi | 0.14 | 0.10 | 0.11 | 0.21 | 0.66 | -- | 0.15 | 0.34 | 0.21 | 0.50 | 0.47 | -- |
| MP-Baseline | 0.58 | 0.33 | 0.38 | 0.69 | 0.05 | -- | 0.40 | 0.48 | 0.42 | 0.67 | 0.14 | -- |
| ModeratorLM | 0.77 | 0.51 | 0.57 | 0.77 | 0.01 | 0.08 | 0.71 | 0.57 | 0.61 | 0.76 | 0.05 | 0.14 |
| ModeratorLM-Think | 0.81 | 0.74 | 0.76 | 0.86 | 0.01 | 0.02 | 0.79 | 0.82 | 0.79 | 0.91 | 0.03 | 0.03 |
On NOTSOFAR-1, ModeratorLM improves precision to $0.77$ and recall to $0.51$, while ModeratorLM-Think raises them further to $0.81$ and $0.74$. On RolePlayConv, ModeratorLM reaches $0.71$ precision and $0.57$ recall, while ModeratorLM-Think reaches $0.79$ precision and $0.82$ recall. The strongest pattern is that role conditioning drastically reduces false positives, and explicit reasoning recovers a large fraction of missed opportunities.
The paper’s subjective evaluation mirrors the objective metrics:
| Model | Turn-Taking | Response |
|---|---|---|
| MP-Baseline | 0.58 | 4.6 |
| ModeratorLM | 0.68 | 6.9 |
| ModeratorLM-Think | 0.72 | 7.4 |
These judge scores indicate that role-conditioned fine-tuning not only improves the decision of when to speak but also improves the quality and appropriateness of what is said. ModeratorLM-Think again performs best, suggesting that explicit reasoning acts as an alignment layer between conversational context, role obligations, and response generation.
Ablation Studies
The ablations focus on two issues: the effect of chunking policy and the effect of transcript availability. The default setup uses fully dynamic chunking, whereas the alternatives are a fixed 2-second chunking policy and a turn-fixed policy in which chunk size is constant within each speaker turn but may vary across turns.
| Setup | ModeratorLM | ModeratorLM-Think | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | Accuracy | Precision | Recall | Accuracy | |
| Default | 0.71 | 0.57 | 0.76 | 0.79 | 0.82 | 0.91 |
| No Transcription | 0.42 | 0.14 | 0.57 | 0.39 | 0.42 | 0.57 |
| ASR Hypotheses | 0.68 | 0.56 | 0.76 | 0.75 | 0.80 | 0.90 |
| GT Thoughts | -- | -- | -- | 0.95 | 0.95 | 0.97 |
| Fixed (2 s) | 0.88 | 0.78 | 0.88 | 0.82 | 0.82 | 0.91 |
| Turn-Fixed | 0.84 | 0.60 | 0.80 | 0.75 | 0.81 | 0.91 |
The ablations support several important conclusions:
- Text transcripts matter. Removing transcription causes a large drop in performance, especially for ModeratorLM, showing that lexical context is heavily used for turn-taking decisions.
- ASR noise is tolerable. Replacing ground-truth text with ASR hypotheses from Kyutai-STT-2.6B, which has a word error rate of 6.7%, causes only minor degradation.
- Reasoning helps robustness. ModeratorLM-Think is less sensitive to chunking strategy than ModeratorLM, and with ground-truth thoughts it reaches near-perfect performance.
- Fixed chunking can be misleading. Although fixed chunking often appears to improve precision and recall, the paper argues that this is partly an evaluation artifact because fixed segmentation assumes access to boundaries that are unavailable in realistic streaming inference.
The authors also explicitly note that dynamic chunking is important during training: without it, models can overfit to chunk length rather than learning the conversational context that truly determines whether a turn should be taken.
Interpretation of the Findings
The main empirical message is that role conditioning is a strong control signal for turn-taking. A model trained only on generic multi-party conversations can learn to reduce interruptions, but it does not know how aggressive or conservative it should be under a particular role. Adding a role description significantly improves this behavior, and adding explicit reasoning improves it further.
The results also highlight a behavioral trade-off. ModeratorLM is relatively conservative: it achieves high precision with very low false-positive rates, but it can miss valid opportunities to intervene. ModeratorLM-Think alleviates this conservatism, producing a better precision–recall balance and especially improving responsiveness at reactive turn-taking points.
Another important conclusion is that the model is not purely acoustic. It depends heavily on textual transcriptions, and it benefits from realistic ASR outputs. This suggests that for practical deployment, robust streaming ASR remains a critical component of the overall voice-agent pipeline.
Limitations and Future Work
The paper does not present a dedicated limitations section, but several constraints are clear from the experiments and discussion. First, the response output is text-only, so the system is not yet a fully end-to-end spoken agent. Second, the method depends on chunked streaming inference and teacher-forced conversation context during evaluation, which means real deployment must handle imperfect online context more fully. Third, the role-conditioned dataset is synthetic, so the role distribution and conversational patterns are controlled rather than organically collected.
The conclusion explicitly points to future work on full-duplex multi-party voice agents and on turn-taking under simultaneous listening and speaking. That direction is natural given the current model’s chunk-level turn-taking formulation and the fact that the model already operates in a streaming regime.
Conclusions
The paper presents a clear and practical recipe for improving turn-taking in multi-party voice agents: make the assistant’s role explicit, train on synthetic multi-party conversations that reflect role-specific behavior, and optionally add reasoning to stabilize the decision process. ModeratorLM and ModeratorLM-Think both outperform non-role-conditioned baselines on real meeting data and on the synthetic RolePlayConv benchmark, with large gains in recall and substantial reductions in false-positive interruptions.
Overall, the work is notable for connecting role-playing language-agent ideas with real-time speech interaction. It shows that persona or role information is not just a stylistic preference but can function as a useful behavioral prior for when a voice agent should intervene in dense multi-party conversations.