From Tokens to Faces
From Tokens to Faces: Investigating Discrete Speech Representations for 3D Facial Animation
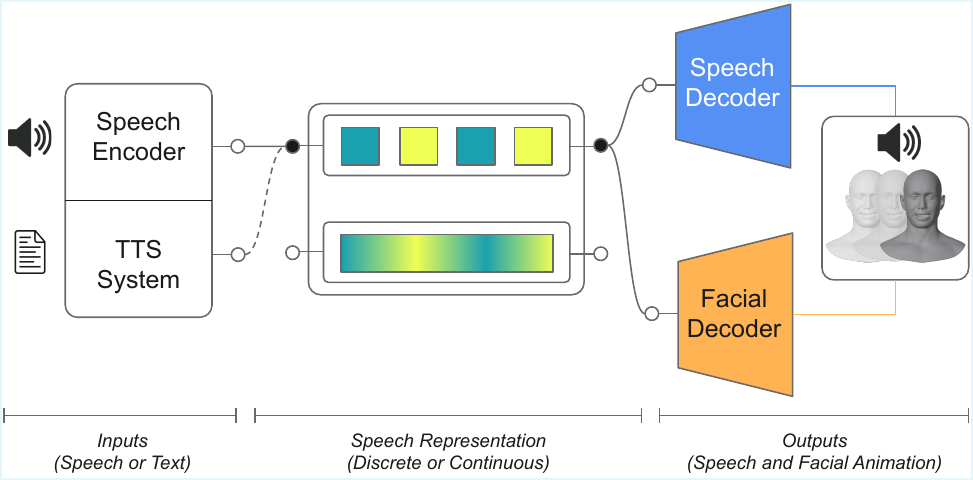
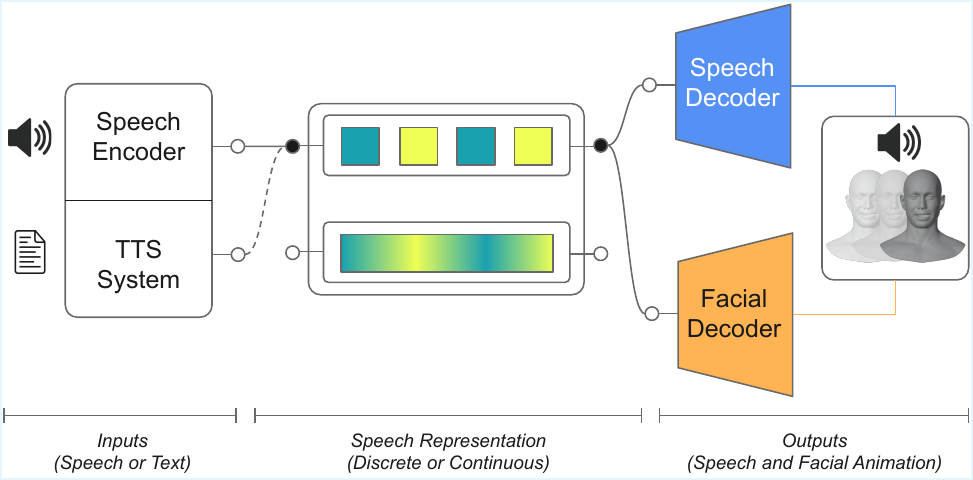
This paper investigates how discrete and continuous speech representations impact 3D facial animation, showing phonetic encoding boosts facial motion accuracy. It introduces a shared discrete space enabling synchronized speech synthesis and face animation for a new audio-visual text-to-speech pipeline.
Links
Paper & demos
Code & resources
Impact
Abstract
The choice of speech representation is critical in speech-driven 3D facial animation. Representations differ in what they encode: SSL features emphasize segmental and semantic cues, neural codecs yield latents optimized for acoustic reconstruction, and ASR-style objectives produce label-based spaces. We evaluate four speech representation families for 3D facial synthesis, comparing their facial reconstruction quality across two facial decoders using objective metrics and a perceptual evaluation. We additionally conduct probing analyses that relate tokenized representations to phonetic units and to articulatory deformations. We found that encoding phonetic classes is beneficial for accurate facial animation prediction on both semantic and label-based representations with comparable facial animation quality. From the latter, we introduce an Audio Visual Text-to-Speech (AVTTS) pipeline that leverages, as a shared space, discrete representations to decode speech and 3D facial motion.
Introduction
This paper studies a foundational question for speech-driven 3D facial animation: what kind of speech representation is most useful as the input bottleneck for predicting facial motion? The authors position the work against the dominant practice of using continuous self-supervised learning (SSL) features such as HuBERT, wav2vec 2.0, or Whisper, and instead systematically examine discrete representations that are already central in modern speech generation. The core claim is that representation choice matters not only for acoustic reconstruction, but also for how much phonetic and articulatory information can be exposed to a facial decoder.
The paper compares four representation families: semantic SSL features (HuBERT), semantic+acoustic tokenization (SpeechTokenizer), acoustic tokenization (WavTokenizer), and label-based tokenization (CosyVoice2). These are evaluated for 3D facial synthesis using two temporal decoders, a GRU and a Transformer, on the BEAT2 dataset. The study is not just a benchmark: it also probes whether the learned token spaces align with phoneme classes and facial articulatory patterns, and it introduces a proof-of-concept Audio Visual Text-to-Speech (AVTTS) pipeline where the same discrete token sequence drives both speech generation and face animation.
Problem Setting and Main Contributions
The paper frames speech-driven facial animation as a representation-learning problem: a speech encoder produces a bottleneck sequence, and a temporal facial decoder maps that sequence to a trajectory of facial parameters. The authors emphasize that a good representation may need to expose phonetic classes, prosody, and articulatory dynamics, but it is not obvious which of these properties are actually necessary for high-quality facial animation.
- They benchmark four speech representation families across two facial decoders, resulting in eight encoder-decoder combinations.
- They probe the token spaces for phonetic and articulatory structure using entropy-based statistics and a ridge-regression probe.
- They show that discrete tokens can support a shared representation for text-to-speech and facial animation, enabling an AVTTS pipeline.
A central finding is that representations encoding phonetic classes are beneficial for accurate facial animation, and that the best discrete label-based representation can be competitive with the continuous SSL baseline in perceptual quality. At the same time, the probing analysis shows that these representations encode relatively little direct information about facial motion itself.
Method
Encoder family comparison
The experiments compare four frozen, pretrained speech encoders:
- HuBERT: the continuous SSL baseline, treated as a semantic representation.
- SpeechTokenizer: a hybrid semantic+acoustic tokenizer that uses multiple residual vector-quantized codebooks and distills HuBERT into its first layer.
- WavTokenizer: an acoustic tokenizer optimized for speech reconstruction with extreme compression.
- CosyVoice2: a label-based discrete representation learned with an ASR-style objective over characters and prosodic events.
The paper is careful to separate encoder information content from decoder capacity: the encoders are frozen, and only the facial decoders are trained. This makes the comparison about what information the representation exposes to the face model, not about end-to-end retraining of the speech encoder.
Facial decoder architectures
Two temporal decoders are used to map speech representations to face motion: a framewise GRU and a non-causal Transformer with self-attention. The target face parameterization is the BEAT2-provided FLAME motion, converted into $51$-dimensional ARKit blendshapes using the dataset authors’ transformation matrix.
The GRU is used as the denoising network in a diffusion-style setup inspired by FaceDiffuser, but with a notable modification: it is trained with an $L_1$ reconstruction loss for direct prediction rather than noise prediction. The Transformer uses cross-attention and is trained with $L_1$ reconstruction loss plus first-order and second-order motion smoothness penalties, i.e., velocity and acceleration losses, to encourage temporal coherence and reduce jitter.
Pipeline overview
The general pipeline is simple but important: speech is encoded into a latent sequence, and the same latent format can later be fed into a speech decoder or a facial decoder. The paper’s key architectural observation is that discrete tokens already used in speech generation can serve as a shared intermediate space for another modality, here 3D facial motion.
Dataset and Experimental Setup
All facial animation experiments are conducted on BEAT2, which the paper describes as containing approximately $27$ hours of English speech from $25$ speakers in scripted monologues, spanning $8$ basic emotions. The dataset provides time-aligned speech and 3D facial motion in FLAME space.
The test set used for objective evaluation comprises $265$ stimuli, or roughly $4$ hours. For probing, the authors rely on the dataset’s phone alignments and motion annotations. The paper does not provide a full breakdown of train/validation splits beyond describing the training and test usage, so the reported evaluation should be interpreted within the BEAT2 setup as presented in the manuscript.
The authors explicitly train all encoder-decoder combinations under the same frozen-encoder regime on BEAT2. This is important because the paper’s conclusion depends on fair comparison across representation families rather than on re-optimizing each encoder for the downstream task.
Evaluation Metrics
Objective facial metrics
The objective evaluation uses three facial metrics:
- Lips Vertex Error (LVE), adapted to the blendshape space and focused on lips, jaw, and mouth error.
- Jitter, computed from acceleration, to measure motion smoothness.
- Bilabial Closure Score (BCS), a task-specific metric for the ability to close the lips during bilabial phones such as /b/, /p/, and /m/.
For BCS, the authors derive a closure threshold from ground-truth bilabial frames using the $70\%$ percentile and then compute the fraction of predicted bilabial frames that meet this threshold. In the paper’s interpretation, BCS is more tightly aligned with perceived lip-speech correspondence than generic reconstruction losses such as LVE.
Perceptual evaluation
The perceptual study uses a MUSHRA-like protocol on Prolific. Participants first inspect a reference video, then rate four videos for each stimulus: three systems plus a hidden reference identical to the reference video. Fifteen stimuli are rated per participant, and the analysis retains only participants whose hidden-reference rating is sufficiently high. After exclusion, the final sample is $30$ participants.
The authors fit a beta regression model to the scores and use post-hoc pairwise comparisons at $p<0.05$.
Probing analysis
To inspect what the representations encode, the paper performs two kinds of probing. First, it probes the relationship between tokens and phonetic classes. Second, it probes the relationship between tokens and facial pose clusters, called visemes in the paper.
For the viseme probe, ground-truth blendshape vectors are clustered into $32$ visemes using $k$-means. Tokens are aligned to frame-level phonetic labels and facial motion using nearest-neighbor temporal matching at $30$ FPS. The main discrete association metric is a normalized conditional entropy:
$$ \hat{H}(\mathcal{X}\mid t)=\frac{-\sum_{i=1}^{K} p(x_i\mid t)\log_2 p(x_i\mid t)}{\log_2 K} $$
where $\mathcal{X}$ is either the phoneme set $\mathcal{P}$ or the viseme set $\mathcal{V}$, and $K$ is the number of classes. The value is normalized to lie between $0$ and $1$: lower values mean the token is more predictive of the target class.
The paper also fits a ridge-regression probe from one-hot token features to the continuous $51$-dimensional blendshape vector and reports the median $R^2$ across blendshapes. This probe is meant to capture whether tokens preserve a linearly decodable trace of articulatory motion, not just class-like events.

Reported Results
Objective facial animation results
The paper evaluates eight encoder-decoder combinations on the BEAT2 test set. The main message is that Transformer decoders generally improve discrete representations, while the HuBERT baseline remains very strong on direct reconstruction metrics. The authors also emphasize that the lip-closure metric tracks human perception better than LVE in this study.
| Speech representation | Decoder | Type | LVE ↓ | Jitter ↓ | BCS (%) ↑ | $\hat{H}(\mathcal{P}\mid t)$ (%) ↓ | $\hat{H}(\mathcal{V}\mid t)$ (%) ↓ | $R^2$ ↑ |
|---|---|---|---|---|---|---|---|---|
| HuBERT | GRU | semantic | 0.26 | 80.3 | 57.5 | 44.4 | 91.5 | 0.25 |
| HuBERT | Transformer | semantic | 0.26 | 45.5 | 27.6 | 44.4 | 91.5 | 0.25 |
| SpeechTokenizer | GRU | semantic+acoustic | 0.53 | 74.4 | 3.4 | 39.6 | 90.4 | 0.04 |
| SpeechTokenizer | Transformer | semantic+acoustic | 0.34 | 35.2 | 2.3 | 39.6 | 90.4 | 0.04 |
| WavTokenizer | GRU | acoustic | 0.84 | 93.3 | 0.4 | 73.2 | 91.4 | 0.08 |
| WavTokenizer | Transformer | acoustic | 0.33 | 43.6 | 6.2 | 73.2 | 91.4 | 0.08 |
| CosyVoice2 | GRU | label-based | 0.46 | 76.5 | 3.9 | 57.7 | 84.3 | 0.10 |
| CosyVoice2 | Transformer | label-based | 0.28 | 50.3 | 47.0 | 57.7 | 84.3 | 0.10 |
In reconstruction terms, the HuBERT baseline gives the best or tied-best LVE, but the authors note that LVE is not the most reliable perceptual indicator. The more meaningful quality indicators in this work are BCS and the MUSHRA-like study. Under those criteria, the discrete CosyVoice2+Transformer model becomes much more competitive than its LVE value alone would suggest.
The decoder matters substantially for discrete encoders: Transformer versions consistently outperform GRU versions on smoothness, and often improve facial accuracy as well. For example, WavTokenizer improves dramatically when moving from GRU to Transformer, and CosyVoice2 also benefits strongly from the Transformer decoder.
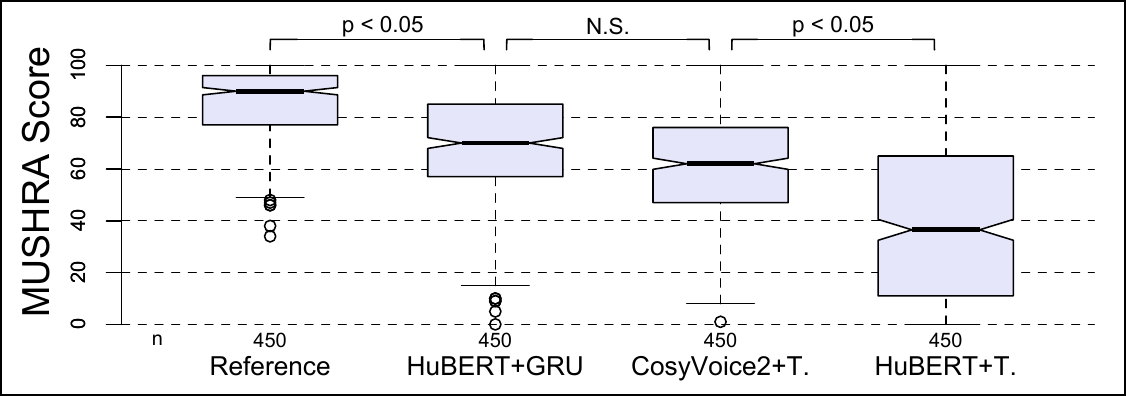
Perceptual study
The perceptual results form three clear groups: the hidden reference is best, HuBERT+GRU and CosyVoice2+Transformer form a statistically indistinguishable middle tier, and HuBERT+Transformer trails behind them. The paper interprets this as evidence that the label-based discrete representation, when paired with a stronger temporal decoder, can reach perceptual quality close to the continuous baseline.
Probing results
The probing analysis reveals a clear asymmetry between phonetic and facial information. Across the tokenized representations, phonetic structure is much more accessible than facial pose structure, while the continuous HuBERT baseline retains the strongest continuous articulatory trace.
The paper’s main probing conclusions are:
- SpeechTokenizer gives the strongest phoneme-related encoding, consistent with its HuBERT distillation objective.
- CosyVoice2 is comparatively strong on viseme-related probing among the discrete models, which the authors attribute to its supervised discrete training objective.
- All tokenized models have very low $R^2$ compared to HuBERT, indicating weak linear recoverability of continuous blendshape trajectories.
The paper also reports that the label-based representation performs better than the others in the viseme-related entropy metric, but even there the overall articulatory information remains low. This supports the broader interpretation that discrete token sequences can be highly predictive of phonetic classes without directly encoding much facial motion.
Interpretation and Discussion
The discussion in the paper is more nuanced than a simple “discrete beats continuous” conclusion. The strongest result is that phonetic class information appears to be necessary, but not sufficient for facial animation. The semantic HuBERT baseline and the label-based CosyVoice2 representation both expose useful phonetic structure, and both can support good facial synthesis when the decoder is strong enough.
At the same time, the hybrid SpeechTokenizer representation, despite achieving the best phonetic probing score, performs poorly on facial prediction. The authors interpret this as a sign that low-structured acoustic information may be detrimental if it is mixed with phonetic information in a way that does not help the facial decoder. In their view, the most useful token spaces are not simply those that preserve more information, but those that expose the right kind of structure for the downstream articulatory mapping.
A second important theme is the relationship between facial quality and motion structure. The best results tend to occur when the representation includes either continuous articulatory information or a discrete representation that is well aligned with phonetic classes. However, the probing scores show that direct facial information in the token spaces remains weak, so the decoder still has to infer much of the mouth motion from a representation that is primarily linguistic rather than visual-articulatory.
The paper also makes a methodological point: for this task, BCS correlates more closely with perceptual judgments than LVE does. That is, a model can have a respectable reconstruction score yet still fail to produce convincing bilabial closure, which matters more to how the animation is perceived.
AVTTS: Unified Text-to-Speech and Face Generation
The AVTTS section is presented as a proof-of-concept rather than a fully benchmarked system. The key observation is that CosyVoice2 already produces discrete speech tokens as part of its text-to-speech process. The authors exploit this by reusing the Transformer facial decoder trained on CosyVoice2 tokens: the same token sequence is decoded in parallel by the original speech decoder and by the facial decoder.
Conceptually, this removes the usual two-stage pipeline in which text is first converted to speech audio and then passed through a separate audio-driven face model. Instead, speech and face are synchronized by construction because they share the same intermediate discrete representation. The paper argues that this opens a path toward more unified multimodal generation systems in which a frozen language backbone can feed multiple decoders.
The visual comparison suggests that AVTTS produces somewhat less contrast in lip motion than the audio-driven CosyVoice2+Transformer setting. The authors therefore treat AVTTS as promising but still immature, and explicitly frame it as a direction for dedicated future work rather than a finished solution.
Limitations and Scope
The paper is quite explicit, both in the results and in the discussion, that the discrete representations do not solve facial animation completely. The major limitations evident from the manuscript are:
- The probe results indicate that the token spaces encode limited continuous facial information, especially compared to HuBERT.
- The AVTTS system is only a proof-of-concept and is shown qualitatively rather than with a full quantitative benchmark.
- The study is evaluated on BEAT2, so the reported conclusions are grounded in one dataset with English scripted monologues, $25$ speakers, and $8$ emotions.
- The paper focuses on a single facial parameterization, namely $51$ ARKit blendshapes derived from FLAME.
- Although the authors compare encoder families carefully, the study does not claim that discrete tokens universally outperform continuous representations; instead, it argues that the right token structure can be competitive for facial animation.
Another practical limitation is that the representations are frozen off-the-shelf encoders. This is methodologically sound for analysis, but it also means the study does not explore jointly optimizing speech representations specifically for facial animation.
Conclusion
The paper’s bottom line is that discrete speech representations are viable inputs for 3D facial animation, but not all discrete tokens are equally useful. Representations that encode phonetic classes well can support competitive facial synthesis, especially with a Transformer decoder. Among the tested systems, the label-based CosyVoice2 representation is the strongest discrete alternative in perceptual terms, while HuBERT remains the strongest baseline on reconstruction-style metrics.
The work’s broader contribution is conceptual: it shows that facial animation can be driven from tokenized speech spaces that also support text-to-speech, enabling a shared intermediate representation for audio and face generation. This makes the paper relevant not just for talking-head synthesis, but for any future multimodal speech-language model that wants to decode multiple outputs from a frozen discrete backbone.
Code & Implementation
This repository contains the code to reproduce the experiments and results presented in the paper "From Tokens to Faces: Investigating Discrete Speech Representations for 3D Facial Animation." It is organized primarily into two main parts: comparison and probing.
- comparison/: This folder contains implementations of different speech encoding and facial decoding models used to evaluate various discrete speech representations for 3D facial animation. It includes architectures based on GRU and Transformer facial decoders linked to specific speech encoders such as CosyVoice, WavTokenizer, and SpeechTokenizer.
- probing/: This folder houses code for probing analyses that relate speech tokens to phonetic classes and articulatory information, supporting the qualitative and quantitative analyses discussed in the paper.
The repository references pretrained models and dataset placeholders under pretrained_models/ and data/, respectively.
Users can recreate experimental environments via conda environments detailed in each submodule, and run the facial decoders to generate blendshape vectors directly from encoded speech representations.
Overall, the codebase mirrors the paper's pipeline by providing discrete speech representation extraction combined with facial animation models, enabling objective and perceptual evaluations as well as probing investigations described in the study.