Flex4DHuman
Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
Flex4DHuman generates synchronized dense multi-view videos from monocular or sparse multi-view inputs without explicit geometry priors, enabling flexible 4D human reconstruction. It uses relative camera-pose conditioning and supports long temporal rollout for continuous multi-view video synthesis.
Links
Paper & demos
Code & resources
Impact
Abstract
We present Flex4DHuman, a multi-view video diffusion model that transforms a monocular or sparse multi-view video of a dynamic subject into synchronized dense multi-view videos using only relative camera-pose conditioning. Unlike prior human-centric methods that rely on skeletons, depth maps, normals, or rendered target-view geometry, Flex4DHuman requires no explicit geometry priors and instead conditions generation through relative camera-pose positional encoding. The generated videos can be directly ingested by downstream reconstruction pipelines to create dynamic 4D Gaussian splats. Built on the Wan 2.1 1.3B text-to-video model, Flex4DHuman preserves the backbone architecture and encodes camera and view information through a five-axis positional encoding that extends spatio-temporal RoPE with view indices and continuous SE(3) relative camera geometry. A three-stage curriculum progressively trains the model for pose following, flexible reference-to-target view generation, and temporal rollout. To support temporal rollout, we train with clean historical target-view tokens. We also add multi-view captions to enable test-time text control. Combined with an off-the-shelf 4D Gaussian Splatting stage, our framework lifts monocular static-camera videos into dynamic 4D Gaussian splats. Experiments on DNA-Rendering and ActorsHQ show that Flex4DHuman surpasses prior state-of-the-art methods, while the same formulation generalizes to animal categories after mixed human-animal training. These capabilities make Flex4DHuman a practical step toward scalable 4D content creation from casual monocular videos for simulation, gaming, AR/VR, and video re-shooting.
Introduction
Flex4DHuman is a multi-view video diffusion model for turning a monocular or sparse multi-view recording of a dynamic subject into synchronized dense multi-view videos. The key practical goal is to make those generated videos suitable as an intermediate representation for downstream 4D reconstruction, especially 4D Gaussian splatting. The paper's central claim is that this can be done without explicit geometry priors such as skeletons, depth maps, normals, or rendered target-view geometry; instead, generation is conditioned only on relative camera pose plus text.
The work is motivated by a gap between camera-controlled novel-view synthesis and reconstruction pipelines. Dynamic 3D assets are most useful when multi-view outputs are temporally coherent and cross-view consistent, because such outputs can be reconstructed into dynamic 3D representations and composed into larger scenes. Existing human-centric diffusion systems often inject explicit geometric signals, which can make them brittle to estimation errors, tied to human body models, or constrained to specific rig assumptions. Flex4DHuman instead aims for a camera-rig-agnostic formulation that can accept one or more reference-view videos and generate target views under arbitrary reference/target layouts.
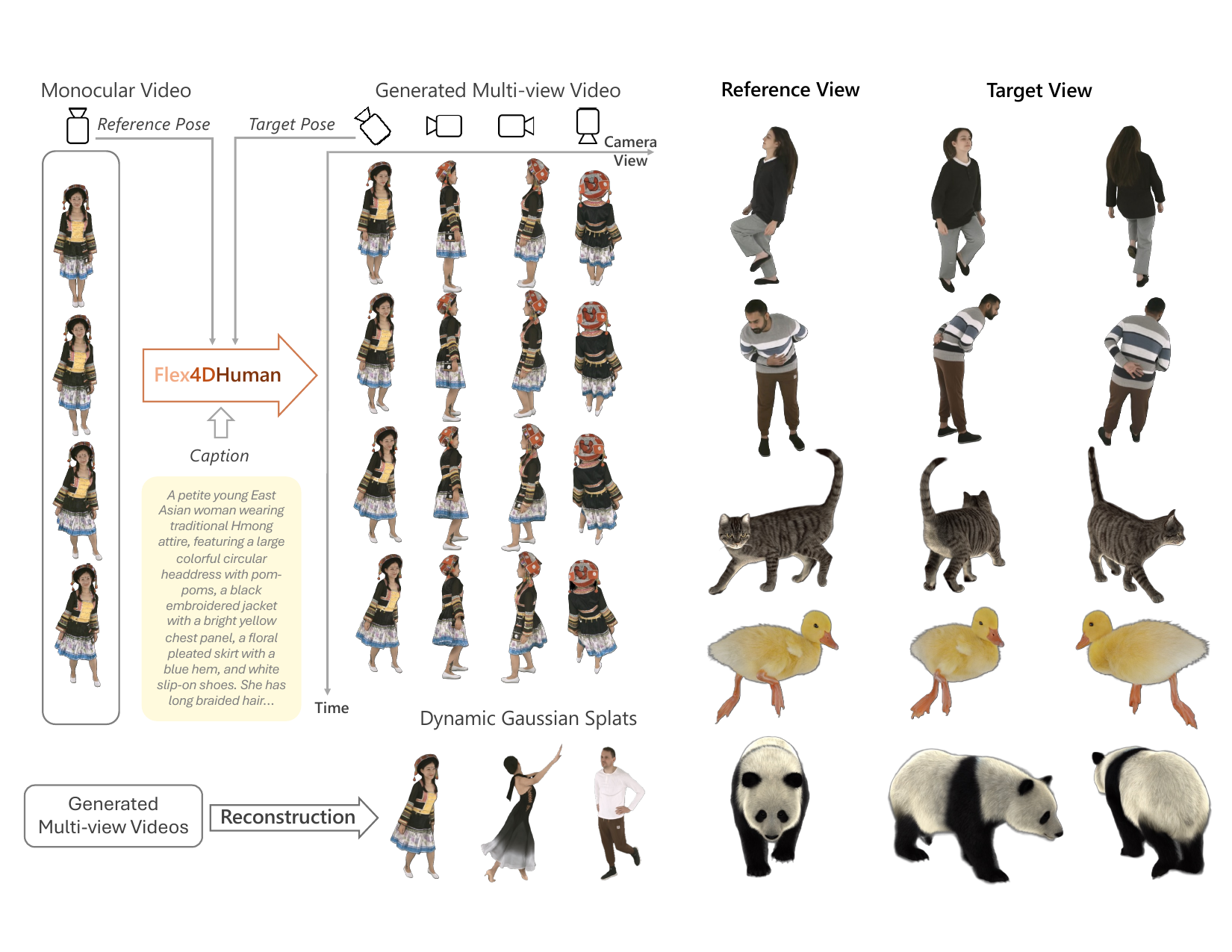
At a high level, the model preserves the Wan 2.1 1.3B text-to-video DiT backbone and changes only how positional information is injected into self-attention. It replaces standard spatio-temporal rotary positional encoding with a five-axis scheme that combines spatial coordinates, frame index, discrete view-slot index, and continuous $\mathrm{SE}(3)$ camera geometry. A staged curriculum then adapts the backbone from the easiest single-reference setting, to flexible sparse-reference multi-view synthesis, and finally to temporal rollout over longer sequences than seen in training.
Problem formulation and core idea
The model takes as input one or more reference-view videos, their camera poses, optional text describing appearance, and the desired target camera poses. It outputs RGB frames for the target cameras, generated jointly across time and views within each temporal chunk. Because the generation is synchronized across all target views, the outputs can be directly fed into reconstruction methods such as 4D Gaussian splatting.
The paper emphasizes three design requirements:
- No explicit geometry priors. The model does not require skeleton fitting, depth, normals, or target-view rendering during training or inference.
- Flexible view counts and layouts. A single checkpoint should handle variable numbers of reference views, variable target-view arrangements, and different camera rigs.
- Temporal rollout. The model should support long sequences by rolling out chunk by chunk while reusing prior predictions as clean history tokens.
To achieve this, Flex4DHuman uses a relative camera encoding inside attention. The intuition is that if the model can reason over relative pose directly, then the same learned synthesis process can generalize across different rigs and different choices of reference camera. A discrete view index also helps distinguish camera identities in a permutation-invariant way, while the continuous $\mathrm{SE}(3)$ term provides geometric grounding.
Method overview
Flex4DHuman is built on Wan 2.1's 1.3B text-to-video DiT. The paper keeps the backbone architecture intact and changes the input representation plus self-attention positional encoding. Tokens are packed in view-major order so each token can be indexed by both view and time. Generation is performed jointly across all views and frames inside a chunk, rather than separately per view.
Reference and target views are encoded with a shared 36-channel layout:
- 16 channels of noisy latents,
- 16 channels of conditioning latents,
- 4 channels of binary conditioning mask.
For reference views, the conditioning channels carry encoded reference-view latents and the mask is all ones. For target views, the conditioning channels are zeroed. This lets the model distinguish observed content from content to be synthesized while allowing information to flow through a single attention stack across views and time. Because Wan 2.1 originally expects 16 channels, the input projection is expanded to 36 channels by copying pretrained weights for the original channels and zero-initializing the new parameters.
The per-view features are passed through a spatial patch downsampler, a $1 \times 2 \times 2$ 3D convolution, then flattened into token sequences and processed by the DiT backbone. The paper's architectural change is therefore minimal in parameterization, but substantial in how attention is conditioned.
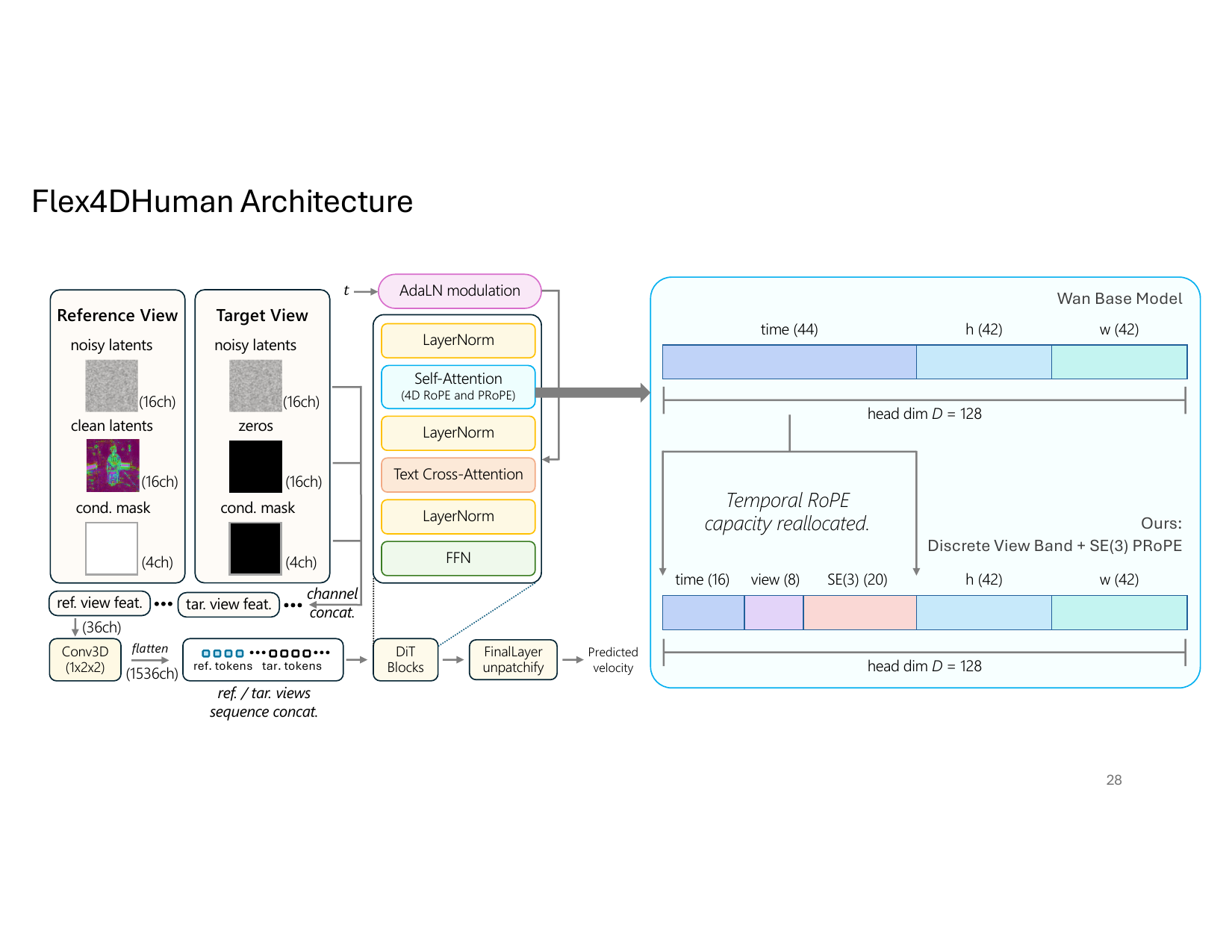
Projective positional encoding
The camera-conditioned mechanism builds on PRoPE, which extends rotary positional encoding to continuous camera transforms. For each token, a dedicated slice of the query and key vectors is transformed according to that token's camera pose. In the paper's notation, if $\mathbf{T}_i$ and $\mathbf{T}_j$ are the camera poses associated with tokens $i$ and $j$, then the camera-aware sub-vectors are transformed as
$$Q_i^{\text{SE(3)}} \leftarrow \mathbf{T}_i^{\top} Q_i^{\text{SE(3)}}, \qquad K_j^{\text{SE(3)}} \leftarrow \mathbf{T}_j^{-1} K_j^{\text{SE(3)}}.$$
Because queries and keys are transformed with the appropriate relative camera operators, attention becomes a function of relative pose rather than absolute pose. This is important for generalization: the model can be trained on one camera arrangement and applied to other camera layouts without adding learned camera embeddings or extra input channels. The paper notes that this formulation naturally generalizes to arbitrary reference and target configurations.
The RoPE budget originally used by Wan 2.1 is repartitioned from $(D_t, D_h, D_w) = (44, 42, 42)$ to $(D_{\text{time}}, D_{\text{view}}, D_{\text{SE(3)}}, D_h, D_w) = (16, 8, 20, 42, 42)$. The discrete view band provides a camera identity, while the continuous $\mathrm{SE}(3)$ band encodes relative geometry directly inside attention. To stabilize the camera representation, all poses are normalized per sequence by expressing cameras relative to the first camera and scaling translations to unit distance.
Conceptually, the architecture is trying to solve a harder version of view synthesis than a standard camera-conditioned generator: it must produce not only a single novel frame, but a synchronized video across many target views, with consistent appearance over time and across views.
Training objective and curriculum
Training uses the same flow-matching objective as Wan 2.1. Given clean latent $\mathbf{x}_1$, Gaussian noise $\mathbf{x}_0 \sim \mathcal{N}(0, I)$, and time $t \in [0,1]$ sampled from a logit-normal schedule, the interpolant is
$$\mathbf{x}_t = (1 - t)\mathbf{x}_0 + t\mathbf{x}_1.$$
The model predicts velocity $\mathbf{v}_\theta(\mathbf{x}_t, t)$ and minimizes
$$\mathcal{L} = \mathbb{E}\left[\left\|\mathbf{v}_\theta(\mathbf{x}_t, t) - (\mathbf{x}_1 - \mathbf{x}_0)\right\|_2^2\right].$$
The loss is averaged uniformly over all tokens. Clean reference and history tokens are supplied through the conditioning channels, so the model learns to preserve observed tokens while denoising target tokens. Text conditioning is dropped to a zero embedding with probability $0.1$ for classifier-free guidance.
The model is trained with a three-stage curriculum that progressively expands the difficulty axis along reference views, camera layouts, and temporal horizon.

- Stage 1: single-reference, single-target, single-frame training at $256^2$. This adapts the pretrained Wan 2.1 backbone to the new camera- and view-aware positional encoding.
- Stage 2: dynamic reference-view sampling with $N_{\text{ref}} \in \{1, \dots, 15\}$ under a fixed total view count $V = 16$ and $T = 1$. This stage first trains at $256^2$ and then scales to $512^2$ for finer detail. It also adds random background-drop augmentation.
- Stage 3: temporal training at $512^2$ with teacher-forced history conditioning. The model multitasks several $(V \times T)$ layouts under a shared token budget, including $ {32 \times 1, 16 \times 2, 8 \times 4}$ and $\{8 \times 8, 4 \times 16, 2 \times 32\}$.
Stage 3 is particularly important for long-horizon generation. The model is trained to use clean historical target-view tokens, so it can continue a sequence by conditioning on its own previous predictions. This makes chunked rollout possible at inference time, where each chunk is denoised across all views and then the overlap from the previous chunk is fed back as clean history tokens.
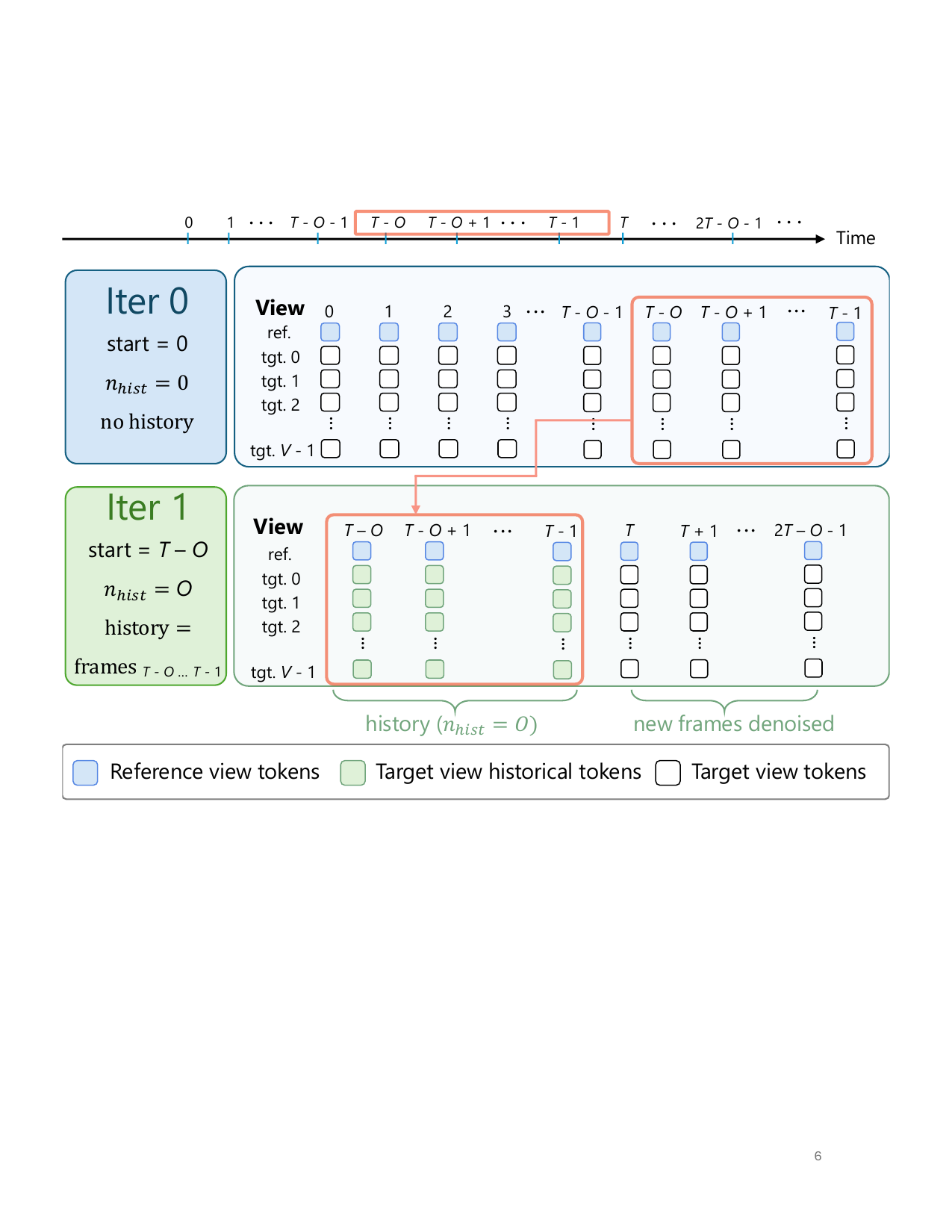
In practice, this strategy lets the same checkpoint generalize across different numbers of reference views, different camera layouts, and different temporal lengths. The curriculum is therefore not just a training recipe, but a mechanism for making a single model flexible enough to operate as a general multi-view video generator.
Multi-view captioning and training data
The paper builds a multi-view caption corpus over three datasets: DNA-Rendering, ActorsHQ, and Dynamic Furry Animals (DFA). Dense natural-language descriptions are generated using Gemini 3 Flash. The captions are intended to support text conditioning during both training and inference.
For each dataset, sequences are divided into non-overlapping temporal windows. Within each window, frames are uniformly sampled and arranged into a $2 \times 2$ grid from four roughly orthogonal viewpoints centered on the foreground subject with background masked out. This grid-frame sequence is given to the captioning model with a prompt to describe appearance attributes such as body shape, hair or fur, clothing, accessories, visible text, or logos. For animals, the prompt additionally asks for high-level behavioral descriptions such as gait, head posture, and tail movement.
The authors explicitly avoid fine-grained motion descriptions for humans because pilot studies found that motion direction is often misidentified when subjects are viewed from non-canonical angles. They report that this kind of noisy supervision can hurt training. The chosen strategy is to emphasize appearance, which is more stable across viewpoints. For animals, higher-level behavior descriptions are retained because they are more body-centric and typically remain meaningful across views.
| Source | Subject | #IDs | #Seqs | #Views | Resolution | FPS | #Frames | Window | Captions | Average words |
|---|---|---|---|---|---|---|---|---|---|---|
| DNA-Rendering | Human | 548 | 1,038 | 48 | 1024 × 1024 | 15 | 229.2k | 10 fr / 0.7 s | 23,410 | 268 |
| ActorsHQ | Human | 8 | 14 | 160 | 747 × 1022 | 25 | 31.2k | 20 fr / 0.8 s | 1,566 | 269 |
| DFA | Animal | 9 | 23 | 36 / 72 | 1920 × 1080 | 30 | 4.0k | 60 fr / 2.0 s | 55 | 238 |
| Total | 565 | 1,075 | 264.4k | 25,031 | 268 |
During training, each sampled clip is paired with the caption for the temporal window containing its start frame. As a result, the same sequence can appear with different text descriptions over time, increasing caption diversity and reducing overfitting to a single static description. The paper reports an average caption length of 268 words across the full corpus.
Experimental setup
The main training data comes from DNA-Rendering. The model is trained on the three-stage curriculum with $32$ H100 GPUs. In the experiments section, the authors state that Stage 1 runs for 30k iterations, Stages 2.1 and 2.2 each run for 30k iterations, and Stage 3 runs for 15k iterations. At inference time, they use 40 denoising steps and a text classifier-free guidance weight of 3.0.
The paper evaluates on three benchmarks. On DNA-Rendering and DFA, generated target views are compared directly against ground-truth target frames. On held-out ActorsHQ, generated multi-view videos are first fit with FreeTimeGS and then re-rendered at the ground-truth ActorsHQ camera poses before computing metrics. All metrics are computed on the subject foreground using PSNR, SSIM, and LPIPS.
Comparison methods are chosen to reflect the single-reference setting. The main baselines are Diffuman4D-GT-skeleton, Diffuman4D-mono-skeleton, and MV-Performer. Diffuman4D-GT-skeleton uses SMPL skeletons triangulated from all reference and target views, which is an oracle-like setting not available in real single-reference deployments. Diffuman4D-mono-skeleton replaces that oracle input with a skeleton lifted from the single reference using Sapiens-Pose and Sapiens-Depth, anchored to the ground-truth hip location and body height. MV-Performer estimates monocular depth and human normals, splats a point cloud into target views, and refines the renderings with diffusion.
Results on DNA-Rendering
DNA-Rendering is evaluated on the 16-scene Diffuman4D test split with 1 reference view and 47 target views. Because the baseline methods operate on foreground-only inputs, the paper reports Flex4DHuman in two settings: foreground-only, using a matted reference, and whole-scene, using the full RGB reference.
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| MV-Performer | 17.44 | 0.7204 | 0.2697 |
| Diffuman4D-mono-skeleton | 16.12 | 0.8760 | 0.1580 |
| Diffuman4D-GT-skeleton | 24.23 | 0.9479 | 0.0744 |
| Flex4DHuman-unmatted | 25.27 | 0.9268 | 0.0977 |
| Flex4DHuman-fg | 25.44 | 0.9516 | 0.0617 |
The foreground-only variant is the strongest overall on DNA-Rendering. The paper reports gains of +9.32 dB PSNR over Diffuman4D-mono-skeleton and +8.00 dB PSNR over MV-Performer. Even relative to Diffuman4D-GT-skeleton, Flex4DHuman-fg improves PSNR by +1.21 dB, SSIM by +0.0037, and LPIPS by -0.0127, despite requiring less information at inference. Flex4DHuman-unmatted is also competitive, indicating that the model can work with full RGB inputs rather than only segmented foregrounds.

Qualitatively, the paper notes that the largest advantage appears on rear-facing target views, where monocular human pose estimation is most error-prone. Since Flex4DHuman avoids pose lifting and explicit target-view geometry, it is less vulnerable to these failure modes.
Analysis on DNA-Rendering
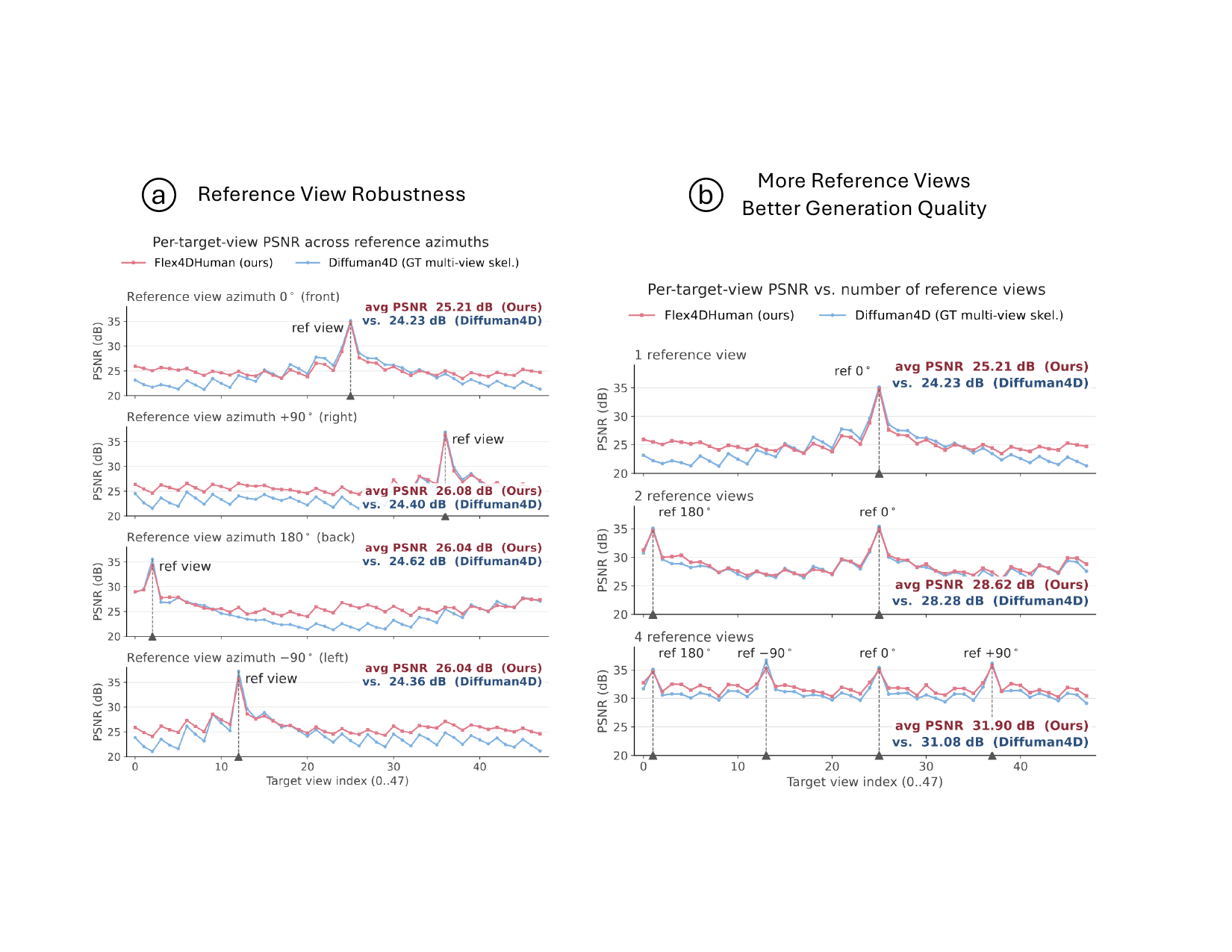
The paper analyzes the model along three axes: reference-view robustness, reference-view scaling, and temporal rollout.
- Reference-view robustness: choosing one reference from each cardinal azimuth yields a cross-azimuth mean between 25.2 and 26.1 dB, with less than 1 dB variation. This suggests the relative camera encoding is robust to the choice of reference view.
- Reference-view scaling: increasing the number of reference views improves PSNR monotonically from 25.21 to 28.62 to 31.90 dB for 1, 2, and 4 reference views, respectively. The same checkpoint absorbs the extra reference evidence without retraining.
- Temporal rollout: chunked rollout with $T = 4$ and $T = 16$ under overlap $\mathcal{O} = 1$ gives similar PSNR, 24.79 dB and 24.86 dB, on the same 42-frame window. This indicates the teacher-forced history conditioning supports stable long-horizon generation.
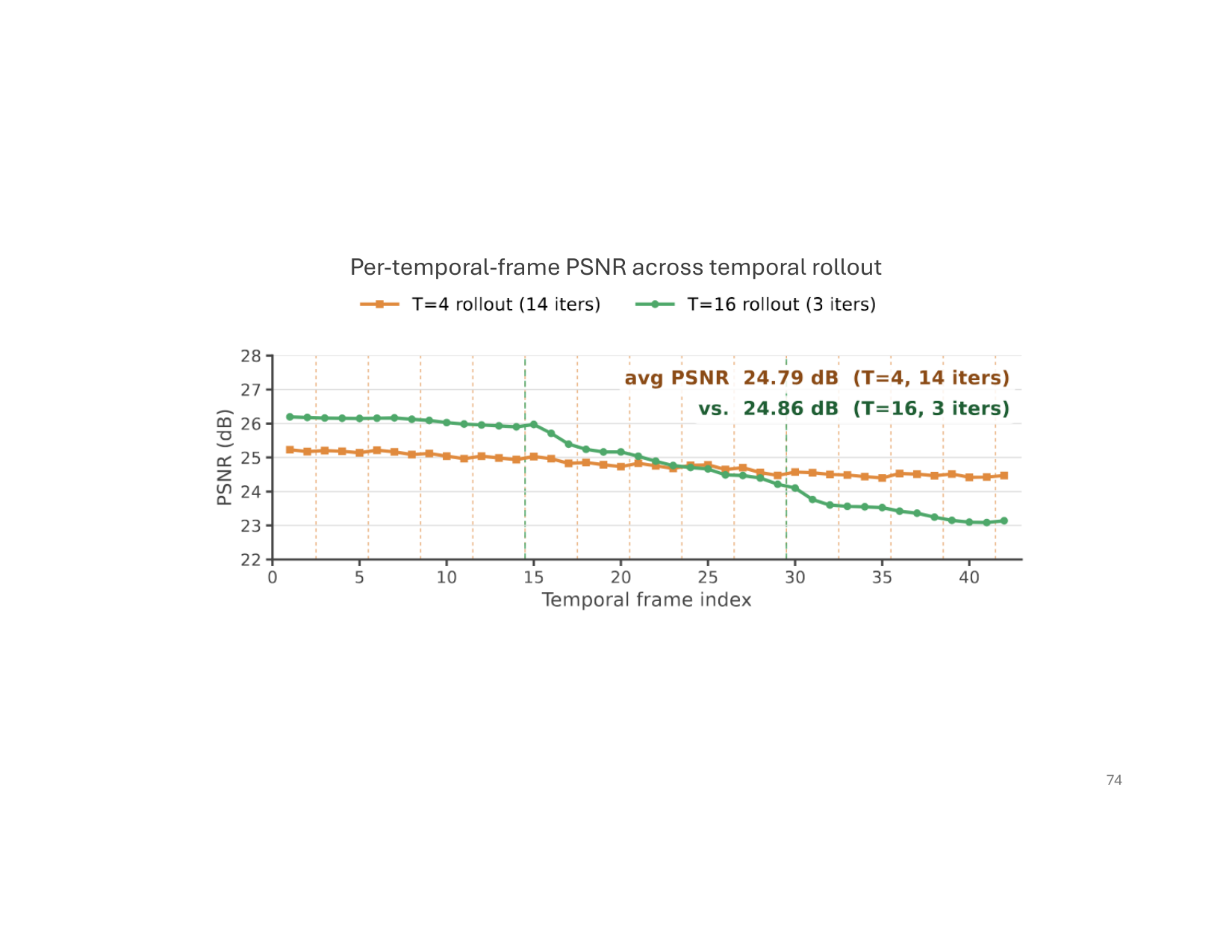
The rollout experiment highlights a useful tradeoff: short chunks can be more memory efficient and still maintain quality, while longer chunks reduce the number of rollout iterations. The important empirical point is that both settings remain stable under the same checkpoint.
Zero-shot generalization on ActorsHQ
ActorsHQ is held out from training and uses a different camera rig from DNA-Rendering, making it a more stringent test of cross-rig generalization. For evaluation, the model generates synchronized multi-view videos on a fixed synthetic target rig, FreeTimeGS is fit to the generated views, and the reconstructed 4D Gaussian splats are re-rendered at the ground-truth ActorsHQ cameras. The protocol evaluates 14 sequences over 200 frames each, including the 12 sequences used by Diffuman4D and two additional sequences: Actor04_Sequence2 and Actor06_Sequence2.
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Diffuman4D-mono-skeleton | 17.97 | 0.815 | 0.307 |
| Flex4DHuman-fg | 21.32 | 0.856 | 0.277 |
Flex4DHuman improves over Diffuman4D-mono-skeleton by +3.35 dB PSNR, +0.041 SSIM, and -0.030 LPIPS. The paper says the qualitative gap is most visible on rear-facing target views, where monocular pose estimation is less reliable. Because Flex4DHuman does not rely on explicit human geometry priors, it is more robust to camera-rig shifts.
Beyond humans: DFA animal generation
To test whether the formulation transfers beyond humans, the authors fine-tune the Stage 3 checkpoint on the Dynamic Furry Animal dataset (DFA). Two regimes are reported: within-animal, where all species appear in training but test clips are held out, and cross-animal, where the target species are excluded from training. Generated views are evaluated directly against ground-truth target views at $T = 1$ with frame stride 8.
| Regime | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|
| Within-animal mean ($n = 6$) | 22.16 | 0.9079 | 0.0925 |
| Cross-animal mean ($n = 3$) | 20.32 | 0.8757 | 0.1097 |
The cross-animal setting drops by only about 1.8 dB PSNR on average, suggesting that the same model formulation can generalize beyond humans with limited fine-tuning and without human-specific priors. This is one of the clearest indications in the paper that the method's benefit is not simply human-body specialization.
Applications: monocular video to 4D asset creation
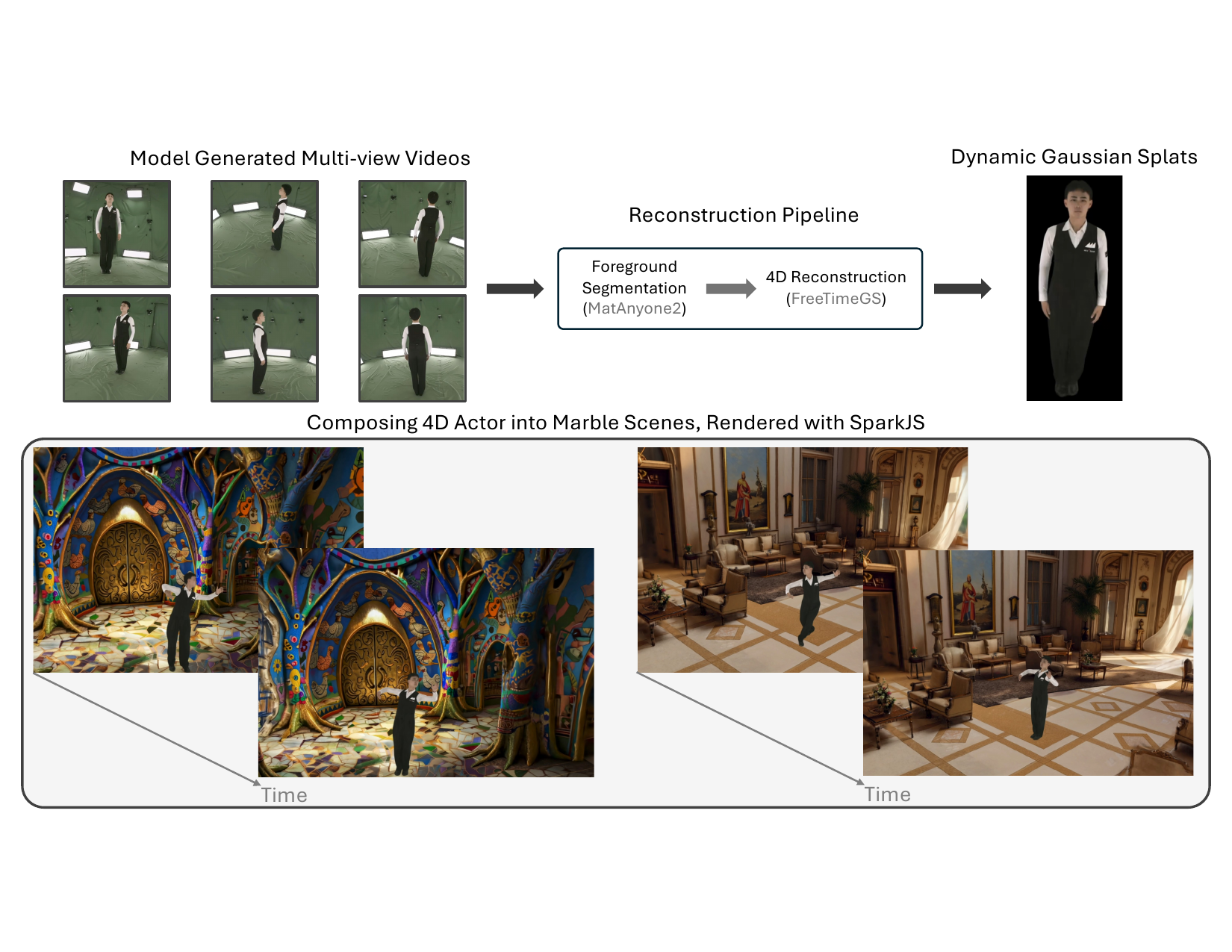
The paper shows a concrete downstream workflow for using generated multi-view videos as an intermediate representation for 4D content creation. Given a monocular or sparse-view actor video, Flex4DHuman generates synchronized dense multi-view videos. The foreground actor is then segmented with MatAnyone2, reconstructed into dynamic Gaussian splats using FreeTimeGS, and composed into generated 3D scenes such as Marble worlds. The result is rendered interactively in a browser with SparkJS.
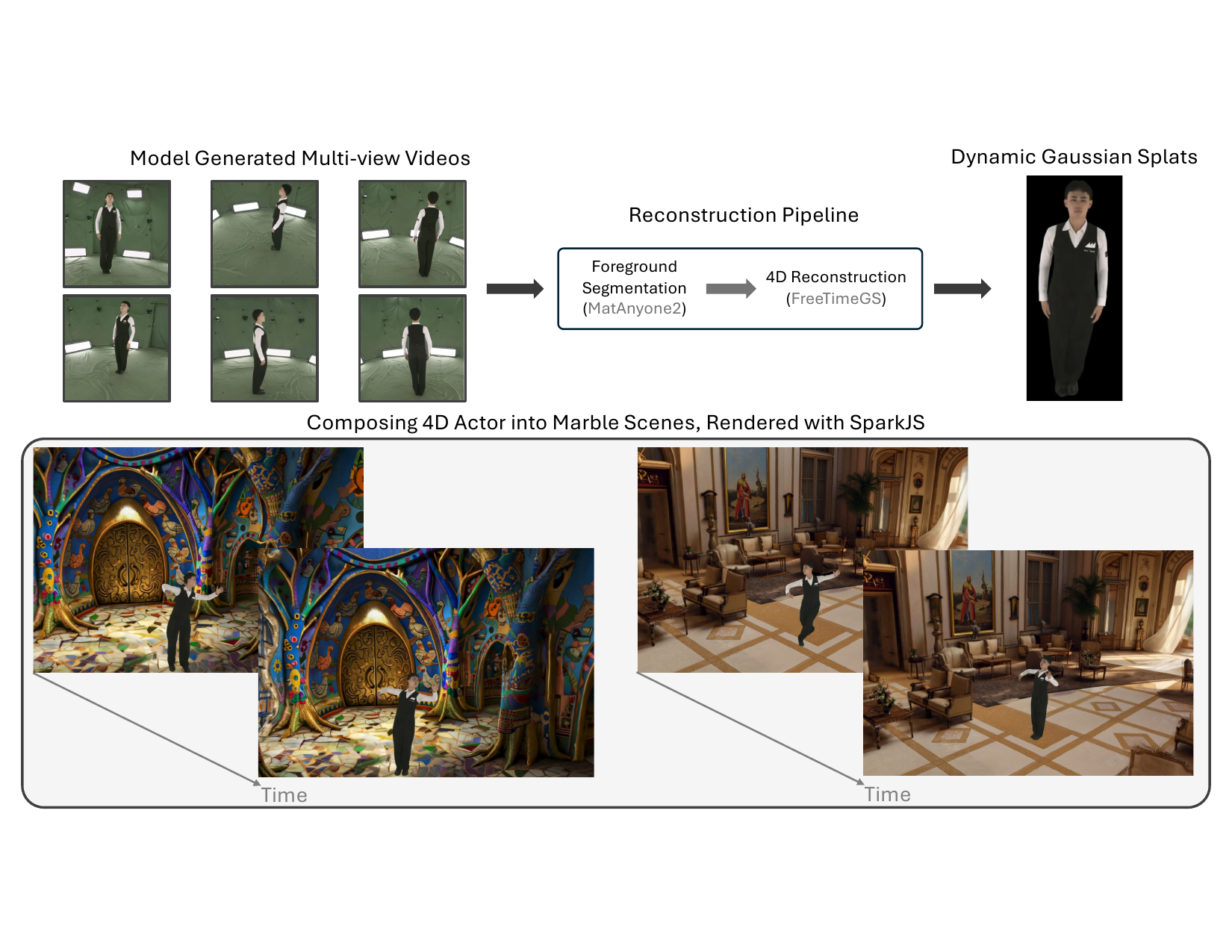
This application matters because it demonstrates that the output of the diffusion model is not just visually plausible, but structured enough for a 4D reconstruction pipeline to consume. The paper frames this as a path toward AR/VR, gaming, simulation, and video re-shooting workflows.
Limitations
The authors are explicit about several limitations. First, the training data is still dominated by static studio-capture rigs, which limits generalization to dynamic camera motion, in-the-wild scenes, and extreme out-of-distribution viewpoints such as top-down or highly tilted views. Although the PRoPE conditioning can represent arbitrary per-frame camera transforms, the model would likely benefit from dynamic multi-camera capture data.
Second, temporal rollout is still bounded by drift issues over longer horizons. Teacher-forced history conditioning helps, but longer sequences may require additional mitigation strategies such as self-forcing or diffusion forcing. The paper frames this as future work rather than a solved problem.
These limitations are important because they identify where the method is strong today: camera-conditioned synthesis under reasonably structured capture settings, and reconstruction-friendly outputs. They also clarify where the method is not yet robust enough for fully unconstrained deployment.
Conclusion
Flex4DHuman turns a pretrained text-to-video diffusion transformer into a flexible multi-view video generator for 4D human reconstruction. Its main novelty is not a new 3D representation, but a camera-rig-agnostic conditioning mechanism: relative $\mathrm{SE}(3)$ pose encoding combined with a discrete view-slot encoding, inserted into the attention layers of a strong video backbone. Together with a staged curriculum, multi-view caption supervision, and clean-history rollout, the model handles variable reference counts, variable target layouts, and longer temporal sequences.
Across DNA-Rendering, ActorsHQ, and DFA, the paper reports strong empirical gains over human-centric baselines that depend on skeletons, depth, normals, or rendered geometry. The generated videos are also demonstrated as a usable intermediate for downstream 4D Gaussian splatting and scene composition. In the framing of the paper, this is a practical step toward scalable 4D content creation from casual monocular videos.
Code & Implementation
This repository currently serves as a placeholder with a detailed README and demo GIF illustrating the Flex4DHuman method. No source code or implementation files are present in the repo as of now.
As stated in the README, the code release is in preparation and will be made available in the future. The README comprehensively covers the project overview, methodology, and data used, aligning with the paper's description of a multi-view video diffusion model for 4D human reconstruction.