Avatar V
Avatar V: Scaling Video-Reference Avatar Video Generation

Avatar V conditions on the full token sequence of a reference video to generate talking-avatar videos that capture both static identity features and dynamic behaviors like talking rhythm and expressions, delivering high-fidelity, natural, long-duration avatar videos beyond prior image-based methods.
Demos
These demos highlight Avatar V's capability to generate high-resolution talking-head videos from a single reference video and driving audio. Evaluate the model on lip-sync accuracy, fine-grained identity preservation including facial details, and naturalness of motion that reflects both appearance and behavioral styles. Watch how well the generated avatar matches the original video across different scenes and expressions.
Links
Paper & demos
Impact
Abstract
Generating avatar videos that are not merely visually similar to a target individual but behaviorally recognizable, faithfully reproducing their talking rhythm, gestural tendencies, and expression dynamics, remains an open challenge. Existing methods predominantly condition on single static images, which provide insufficient identity information and cannot capture dynamic motion traits, while standard pixel-level objectives underserve the perceptually critical facial regions that determine avatar fidelity. We present Avatar V, a production-scale framework that addresses these limitations through video-reference-conditioned identity modeling. Rather than compressing identity into fixed-size embeddings, the model conditions directly on the full token sequence of a reference video, learning to reproduce both static identity attributes (facial geometry, skin texture) and dynamic behavioral patterns (talking rhythm, micro-expressions) through attention over the reference context. We introduce Sparse Reference Attention, an asymmetric mechanism achieving linear-complexity conditioning on arbitrarily long references; a motion representation stream enabling closed-loop talking style transfer; and an identity-aware super-resolution refiner inheriting the full reference conditioning. These are supported by a data engine curating 100M+ training clips from 50M raw videos, and a five-stage training pipeline with flow matching pre-training, personality fine-tuning, two-phase distillation (>10x acceleration), and RLHF alignment, deployed across thousands of GPUs. Avatar V generates 1080p videos of unlimited duration, achieving state-of-the-art identity preservation, lip synchronization, and generation quality on our cross-scene benchmark, consistently outperforming leading systems including Seedance 2.0, Kling O3 Pro, Veo 3.1, and OmniHuman 1.5 in both automated metrics and human evaluation.
Overview
Avatar V is a production-scale talking-avatar generation system built around a central design choice: instead of compressing identity into a single static image embedding, it conditions generation directly on the full token sequence of a reference video. The goal is not only visual resemblance, but also behavioral recognizability—matching the target person’s talking rhythm, micro-expressions, and gestural tendencies in addition to face shape, skin texture, and accessories.
The paper argues that the main bottlenecks in prior avatar generation systems are: (1) static-image conditioning, which lacks the dynamic cues needed for style transfer; (2) quadratic-cost concatenation of long video references; and (3) pixel-level training objectives that under-emphasize the lips, teeth, eyes, and other facial regions that matter most perceptually. Avatar V addresses these with a video-reference-conditioned Diffusion Transformer, a sparse attention scheme, a dedicated motion stream, an identity-aware super-resolution refiner, and a full-scale data/training/inference stack.
The system is trained on over 100M pretraining clips and 10M+ avatar fine-tuning clips derived from 50M+ raw videos, and is deployed across thousands of GPUs under a multi-cloud infrastructure. The reported end result is 1080p talking-avatar generation of unlimited duration with state-of-the-art performance on the paper’s cross-scene benchmark.
Problem Setting and Main Idea
The paper frames avatar generation as a combined identity, motion, and synchronization problem. A useful avatar should preserve static identity attributes such as facial geometry and skin texture, while also reproducing dynamic traits such as speaking cadence, habitual expressions, and co-speech gestures. Existing single-image methods can capture appearance from one viewpoint, but they cannot observe these behavioral regularities. Video-reference conditioning solves that by exposing the model to multiple frames, expressions, and viewpoints from the same person.
Avatar V treats personality embedding as a video-reference conditioning problem: the model attends directly to the full reference-video token sequence and learns identity through attention rather than through a bottleneck encoder. This is the paper’s core novelty. The reference can be short or long; longer references provide richer evidence of style, and the design scales without identity-specific fine-tuning at inference time.
The paper emphasizes three architectural objectives:
- Long-form temporal consistency across clips ranging from seconds to more than a minute.
- Audio-visual synchronization at the phoneme/lip-articulation level.
- Natural motion dynamics, including gestures, gaze shifts, and posture sway.
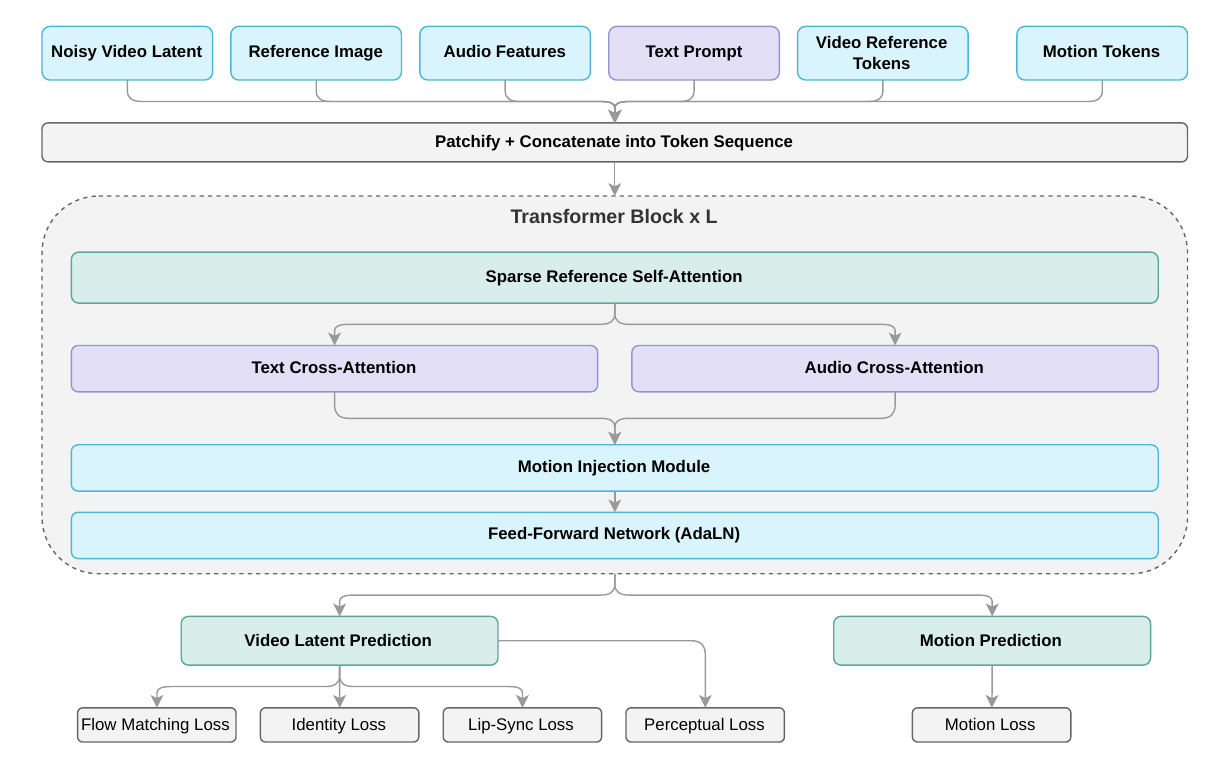
Model Architecture
VideoRef DiT Backbone
Avatar V is built on a Diffusion Transformer (DiT) with flow matching training. Its inputs are multimodal: reference video tokens, audio features, text-prompt embeddings, and latent video tokens. These are patchified into a single token sequence and processed by a stack of transformer blocks. Each block combines:
- Sparse Reference Self-Attention for identity conditioning from the reference video;
- Text and audio cross-attention for scene and speech control;
- Motion Injection to preserve and generate speaking style;
- AdaLN-modulated feed-forward layers for conditioning-aware feature updates.
The paper’s main representational claim is that identity is not a fixed embedding but a rich set of visual and behavioral cues stored in the reference sequence. Static identity includes facial geometry, skin texture, hair, accessories, and dental structure. Dynamic identity includes talking rhythm, habitual smiles, expression dynamics, and gestural tendencies.
Sparse Reference Attention
The paper’s key efficiency mechanism is Sparse Reference Attention. Standard concatenation of reference and generation tokens creates quadratic cost in reference length. Avatar V instead uses an asymmetric pattern: generation tokens attend to all reference tokens, while reference tokens only self-attend. This preserves access to the full identity context while making conditioning scale approximately linearly with reference length. The paper positions this as essential for minutes-long references.
Because the reference video is encoded from clean, non-noisy frames, the reference context does not change across denoising steps. The inference system therefore caches the reference context and the reference key/value projections after the first step, avoiding repeated computation over the 24-step distilled sampler.
Talking Style Modeling via Motion Representation
Avatar V introduces a dedicated motion stream that serves both as a prediction target and a conditioning signal. This creates a closed-loop supervision signal for the target speaker’s motion style. The paper argues that talking style is not just lip motion; it includes the temporal pattern of mouth shapes, facial movement amplitudes, and head gestures. Training the model to jointly generate and condition on motion representations helps it transfer style to unseen speech content while retaining the target person’s behavior.
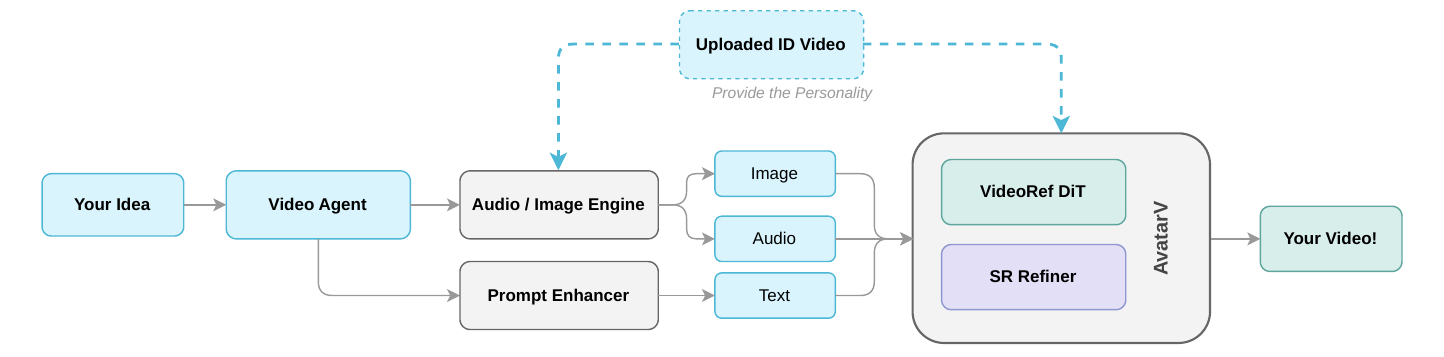
Identity-Preserving Image Engine
Before video synthesis, the system generates a high-fidelity scene image that serves as a visual anchor. Rather than relying on one reference frame, it samples diverse frames from the user’s video, spanning viewpoints and expressions. This gives the downstream generator a more robust identity estimate and supports scene diversity, photorealistic lighting, and flexible aspect ratios.
LLM-Based Voice Cloning Engine
The pipeline also includes a modular voice cloning engine built on a large language model backbone. From as little as a 10-second audio sample, it extracts speaker characteristics such as timbre, prosody, speaking rate, and accent. It can generate target-speaker speech from text, or pass through the user’s provided audio in audio-driven settings. The paper presents this as a separate module so voice synthesis can evolve independently from video generation.
Identity-Aware Super-Resolution Refiner
Base video generation happens at lower resolution for tractability. The final output is then upsampled by an identity-aware super-resolution refiner that inherits the same reference-conditioning machinery as the base model. This is important because a naive SR model can hallucinate facial details that conflict with identity. Avatar V’s refiner is therefore conditioned on the reference video, audio, and motion streams, and uses sparse temporal attention so that high-resolution inference remains practical.
The inference section states that the refiner upsamples in a single denoising step after the low-resolution latent has been noised to $\sigma = 0.6$. This concentrates compute on detail recovery, especially around the mouth region where lip-sync fidelity matters most.
Training Strategy
The training pipeline is explicitly progressive and has five stages: text-to-video pretraining, audio-to-video pretraining, personality supervised fine-tuning, two-phase distillation, and reinforcement learning from human feedback. The paper’s claim is that this curriculum gradually builds the system from generic motion priors to identity-specific avatar behavior and then to efficient, preference-aligned inference.

Stage 1: Text-to-Video General Pretraining
The first stage learns broad video priors from the large pretraining corpus. The model is trained on both text-to-video and image-to-video tasks. The paper says the system follows a progressive curriculum in resolution and duration: it starts with short, low-resolution clips and gradually scales to longer and higher-resolution sequences. The objective is rectified flow matching, with a logit-normal timestep distribution that emphasizes intermediate noise levels. A distributed Muon optimizer is used for 2D+ tensors, while AdamW is used for embeddings and 1D parameters.
Stage 2: Audio-to-Video Pretraining
The second stage specializes the backbone for talking-head generation. The model is adapted to accept a conditioning image plus driving audio, and learns synchronized lip motion and natural head movement on broad talking-head video data spanning different speakers, languages, and speaking styles. This stage introduces audio cross-attention modules and trains them jointly with the visual backbone.
Stage 3: Personality Supervised Fine-Tuning
Personality SFT uses the curated same-identity-different-scene data described later. Here, the model sees reference videos from the same identity via Sparse Reference Attention, plus a target clip from another scene. This forces it to extract identity-invariant cues rather than copying background or pose. The motion representation stream is active, and human-aware auxiliary losses are progressively enabled. These losses are computed in learned representation spaces rather than pixel space, and target identity consistency, motion fidelity, lip-sync, and perceptual quality.
Stage 4: Distillation for Fast Inference
Avatar V uses a two-phase distillation pipeline to reduce cost by more than $10\times$. First, classifier-free guidance distillation internalizes multiple CFG streams into a single forward pass, eliminating the need for repeated conditional/unconditional evaluations. Second, an improved Distribution Matching Distillation stage reduces the number of denoising steps further. The paper describes a three-model setup with a student, a fake teacher, and a frozen real teacher, and notes that the implementation adds stability improvements over vanilla DMD. The distilled system runs with 24 denoising steps.
Stage 5: Human Feedback Alignment
The final stage aligns the model with human preferences using RLHF. The paper uses reward functions that cover identity fidelity, motion naturalness, and visual quality, with Group Relative Policy Optimization as the main RL method and Direct Preference Optimization as a complementary option. The RL setup is adapted to the flow-matching diffusion setting, and KL regularization is used to prevent drift from the pre-RLHF model.
Data Curation and Annotation
The data pipeline is one of the paper’s major contributions. It starts from 50M raw videos and produces more than 100M pretraining clips and 10M+ avatar fine-tuning clips. The pipeline has over 25 processing stages and uses 20+ specialized AI models across CPU and GPU infrastructure.
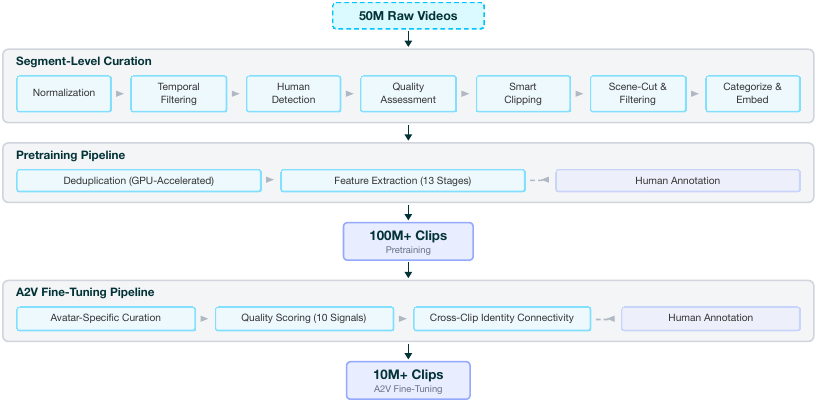
Pretraining Data Pipeline
The pretraining branch begins with segment-level curation. Raw segments are normalized to a longest side of 640 pixels and 25 fps. Temporal pre-filtering removes static or choppy content using frame-difference analysis and perceptual hashing. Human detection verifies that the content contains people and identifies eligible temporal intervals. Motion statistics from optical flow and quality scores from Q-Align are then used in a constrained smart-clipping optimization that balances clip duration, quality, motion, and face presence.
The pipeline also performs scene-cut detection, VLM-based content filtering to reject screencasts, game footage, and photo-like content, semantic categorization across 15 dimensions for balancing, and near-duplicate removal using video embeddings and GPU-accelerated nearest-neighbor search. Deduplicated clips are then passed through parallel extraction stages for OCR, lip-sync scoring, pose estimation, anatomical quality scoring, synthetic-audio detection, language ID, diarization, ASR, captioning, text embedding pre-encoding, and latent pre-encoding with multiple VAE architectures.
Avatar Fine-Tuning Data
The avatar-specific branch adds finer quality signals for talking-head use cases, including eye gaze and blink patterns, face clarity, teeth and hand quality, mouth openness, camera shake, choppy-frame detection, lighting consistency, and secondary-speaker presence. The paper stresses that these signals can be combined into quality tiers without rerunning heavy inference.
Human Annotation System
Avatar V relies on a distributed annotation platform with 100+ freelance annotators. Tasks include quality scoring, pairwise preference labeling, bad-case filtration, generation evaluation, competitive benchmarking, and attribute annotation such as gaze direction, emotion, gesture type, and speaking style. The platform uses a three-tier workflow: production annotators, reviewers, and task designers. The paper reports inter-annotator agreement above 85% across task types.
Preference data from this pipeline is used both for DPO and for reward-model training in RLHF. This is important because the paper’s human evaluation protocol is closely tied to the same annotation infrastructure that generates training signals.
Cross-Clip Identity Connectivity
A key data innovation is the cross-clip identity graph. Two clips are linked if they show the same individual, verified by high face similarity, but in visually distinct scenes, verified by low background similarity. These links create paired training examples that force the model to disentangle identity from scene context. The resulting graph supports sampling of cross-scene reference pairs organized by resolution, duration, and demographic balance.
Inference and Systems Optimizations
The paper treats inference as a first-class systems problem. Avatar V’s distilled model is used at deployment time, and the inference pipeline is structured into preprocessing, DiT generation, super-resolution, and streaming decode. The preprocessing stage encodes the reference video once into reusable tokens and embeddings, extracts audio features, and encodes prompts; the scene image is generated in parallel by the identity-preserving image engine.
Chunk-Based Long-Form Generation
For unlimited-length synthesis, the model generates video in chunks of 41 latent frames, corresponding to 161 pixel frames at 25 fps, or about 6.4 seconds per chunk. The first chunk uses a reference-to-video mode, and later chunks use prefix-to-video mode where the final frames of the previous chunk become the prefix for the next. Adjacent chunks overlap by 2 frames. A global appearance anchor from the first generated chunk helps preserve identity across long sequences.
Sampling
The paper notes that deterministic ODE solvers struggle with fine details when the number of steps is reduced. Avatar V instead uses an improved stochastic Euler procedure: each step overshoots the target noise level and then renoises with fresh Gaussian noise. This helps recover high-frequency details like hands, teeth, and skin texture under a low-step budget.
Reference Caching and Sparse Attention
The inference system uses two layers of caching. First, the full reference context is computed once at the first denoising step and reused thereafter. Second, the reference key/value tensors are cached in GPU memory so they do not need to be recomputed at every transformer block and denoising step. Invalid reference tokens, such as frames without visible faces, are masked out to avoid wasted computation.
Distributed Inference
The paper uses Ulysses Sequence Parallelism across 8 GPUs, partitioning the token sequence across ranks. It also uses FSDP2 with CPU offloading for parameter shards, which helps co-locate multiple model variants and frees GPU memory for large activations. Forward prefetching overlaps communication with computation.
For production latency, the authors report three major bottlenecks: kernel-launch overhead, inter-GPU synchronization, and hardware frequency variance. They address these with a custom compiler using agentic kernel synthesis, NVSHMEM-based sequence parallelism, and system tuning such as NUMA-aware pinning and GPU clock locking. The paper reports roughly a $3\times$ latency reduction over the unoptimized baseline and a 33% reduction over the torch inductor-optimized version.
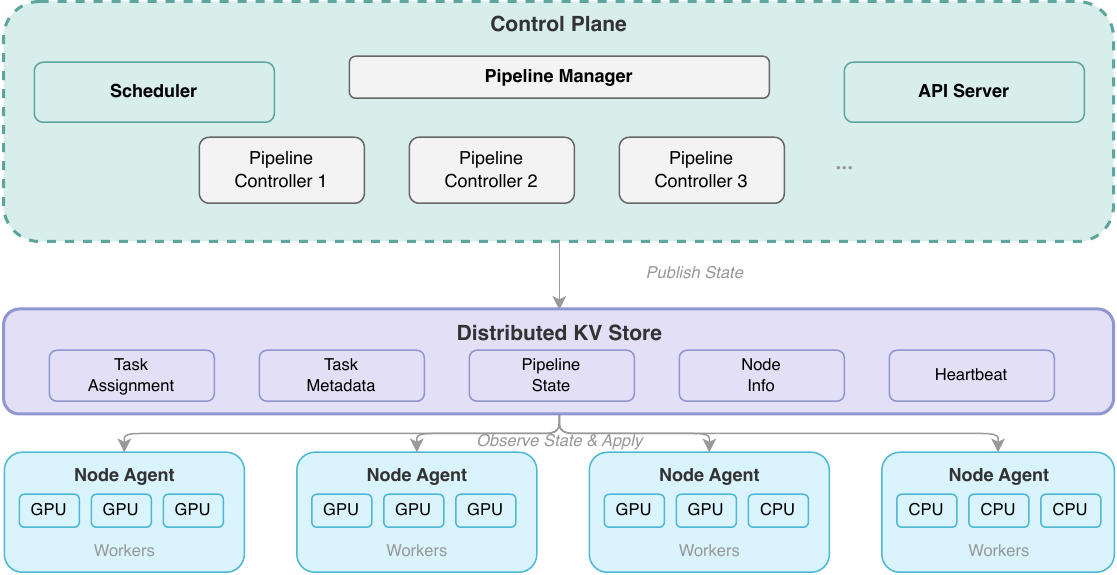
Infrastructure
Beyond the model itself, the paper describes two production infrastructure systems: HELIOS and a custom data processing engine. HELIOS is a unified multi-cloud GPU orchestration platform managing more than 5,000 GPUs across 5+ providers, 10+ regions, and 15+ standardized cells. It standardizes onboarding, uses a cell-based architecture, and runs a two-stage QoS-aware scheduler that improved GPU utilization by 15% and reduced non-productive GPU time by approximately 20%.
The custom data engine replaces Ray after the authors found that the Ray Global Control Store became a bottleneck at more than 2k nodes, with excessive memory use, CPU load, and coordination failures. The replacement uses a declarative observe-diff-reconcile architecture with a distributed key-value store. Its four layers are scheduler, pipeline controllers, node agents, and workers. The paper reports GPU utilization above 95%, node-failure detection in under 30 seconds, linear scaling to 5,000+ GPU nodes and 200K+ concurrent tasks, and zero-downtime deployments.
Evaluation Setup
The evaluation uses a cross-scene benchmark of 70 test cases sourced from public online videos. Each test case includes two clips of the same person in different scenes. One clip provides the reference video; the first frame and audio from the other clip serve as driving inputs. The authors evaluate three scene conditions:
- Same-scene: the target scene image is from the same scene as the reference.
- Cross-scene: the target scene image comes from a different real video of the same person.
- Generated-scene: the scene image is produced by the identity-preserving image engine.
The paper compares Avatar V against Kling O3 Pro, Veo 3.1, OmniHuman 1.5, and Seedance 2.0. Some competitors reject celebrity-likeness inputs for policy reasons, so not all pairwise comparisons are available for every competitor.



Objective Metrics
The automated evaluation uses four metrics. All per-frame metrics are sampled at 2 fps and aggregated as 10% trimmed means. SyncNet is used for audio-visual synchronization, ArcFace cosine similarity for identity preservation, and Q-Align for perceptual quality.
- Sync-C: higher is better.
- Sync-D: lower is better.
- Face similarity: higher is better.
- Q-Align IQA: higher is better.
| Method | Sync-C ↑ | Sync-D ↓ | Face Sim ↑ | Q-Align ↑ |
|---|---|---|---|---|
| Ground Truth | 7.93 | 6.76 | 0.861 | 4.75 |
| Kling O3 Pro (2026) | 5.16 | 10.07 | 0.838 | 4.80 |
| Veo 3.1 (2025) | 8.05 | 7.28 | 0.714 | 4.95 |
| OmniHuman 1.5 (2025) | 7.53 | 8.25 | 0.732 | 4.70 |
| Seedance 2.0 (2026) | 8.86 | 6.99 | 0.823 | 4.85 |
| Avatar V | 8.97 | 6.75 | 0.840 | 4.85 |
On the objective metrics, Avatar V leads on SyncNet confidence, Sync-D, and face similarity. Notably, its SyncNet score of 8.97 and Sync-D of 6.75 slightly exceed the ground-truth values reported in the paper’s benchmark. It ties Seedance 2.0 for second-best Q-Align at 4.85, while Veo 3.1 posts the highest Q-Align score at 4.95 but with much weaker identity preservation.
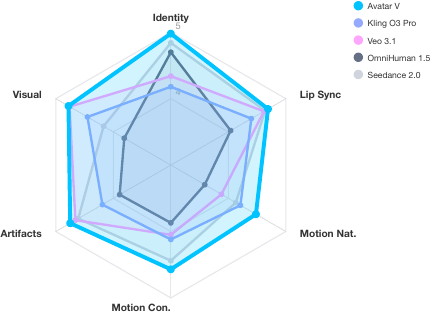
Mean Opinion Score
Human raters evaluated six dimensions: identity consistency, lip-sync accuracy, motion naturalness, motion consistency, artifact control, and visual quality. Each video was rated by at least two annotators in randomized, blinded order.
| Method | Identity ↑ | Lip Sync ↑ | Motion Nat. ↑ | Motion Con. ↑ | Artifacts ↑ | Visual ↑ |
|---|---|---|---|---|---|---|
| Kling O3 Pro (2026) | 4.18 | 4.40 | 4.21 | 4.12 | 4.19 | 4.45 |
| Veo 3.1 (2025) | 4.34 | 4.62 | 3.88 | 4.05 | 4.66 | 4.76 |
| OmniHuman 1.5 (2025) | 4.70 | 4.04 | 3.59 | 3.87 | 3.89 | 3.81 |
| Seedance 2.0 (2026) | 4.84 | 4.64 | 4.13 | 4.44 | 4.61 | 4.17 |
| Avatar V | 4.98 | 4.69 | 4.48 | 4.57 | 4.75 | 4.78 |
Avatar V achieves the best MOS on all six dimensions. The paper highlights especially strong gains in motion naturalness and motion consistency, which it attributes to the dedicated motion representation stream. This supports the claim that the model captures behavioral identity, not only appearance.
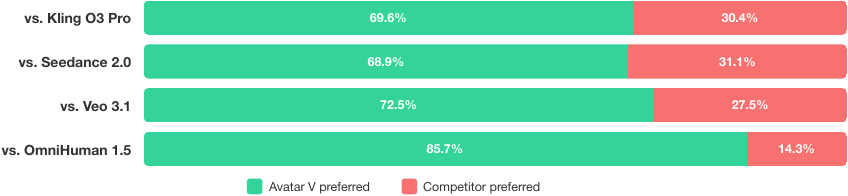
Pairwise Preference Tests
For side-by-side comparisons, raters choose the overall preferred video. Each pair is judged by three annotators, and majority vote determines the winner.
| Competitor | Win ↑ | Lose ↓ | #Cases |
|---|---|---|---|
| Kling O3 Pro | 69.6% | 30.4% | 69 |
| Seedance 2.0 | 68.9% | 31.1% | 45 |
| Veo 3.1 | 72.5% | 27.5% | 40 |
| OmniHuman 1.5 | 85.7% | 14.3% | 70 |
Avatar V is preferred against all competitors, with the strongest margin over OmniHuman 1.5. The qualitative feedback summarized in the paper points to two recurring strengths: generation stability and holistic identity consistency. Competing systems are said to fail more often through skin smoothing, over-enhancement, motion mismatches, and frame-to-frame artifacts.
Avatar Turing Test
The paper also performs an Avatar Turing Test, asking annotators to identify which of two clips is real when shown an Avatar V output and the corresponding ground-truth recording.
| Metric | Value |
|---|---|
| Real identification accuracy | 77.8% |
| Fooled rate (Avatar V mistaken as real) | 22.2% |
| Chance level | 50.0% |
| Cases fooling ≥ 1 annotator | 11/18 (61.1%) |
This is an important nuance: Avatar V is highly realistic, but not yet fully indistinguishable from real footage. The paper explicitly notes that a measurable gap remains, even though the generated videos frequently deceive at least one trained evaluator in a case.
Key Contributions and Novelty
- Reference-video identity conditioning instead of single-image identity embeddings.
- Sparse Reference Attention for asymmetrical, scalable conditioning on long references with approximately linear complexity in reference length.
- Motion representation stream for closed-loop modeling of speaking style and motion behavior.
- Identity-aware super-resolution that preserves the same reference conditioning at high resolution.
- Large-scale data curation and cross-clip identity connectivity to produce same-identity, different-scene training pairs.
- Five-stage training curriculum spanning generic video pretraining, avatar specialization, distillation, and human feedback alignment.
- Systems-level optimization stack for low-latency production deployment at large GPU scale.
Limitations and Safety Notes
The paper’s own evaluation indicates that generated videos are still distinguishable from real footage in aggregate: the Avatar Turing Test yields 77.8% real identification accuracy, so the system is not yet perceptually indistinguishable. The authors also note that some competitor APIs reject inputs containing celebrity likenesses, which affects the completeness of the pairwise comparison set. Beyond this, the excerpt does not provide a dedicated ablation table, so the evidence in the supplied LaTeX is primarily end-to-end rather than component-by-component quantitative ablation.
On the safety side, the paper states that the production platform requires explicit consent verification for custom avatar creation and supports a moderation pipeline covering fraud, harassment, child safety, misinformation, and intellectual property concerns. This is relevant for any conversational-AI or talking-head deployment team considering the system.
Conclusion
Avatar V is presented as a full-stack avatar generation system that scales video-reference conditioning from model architecture to data curation, training, inference, and infrastructure. Its main technical thesis is that identity should be modeled from reference video directly, not compressed into a single bottleneck embedding. The combination of sparse reference attention, motion-style modeling, identity-aware super-resolution, and large-scale infrastructure is reported to yield state-of-the-art identity preservation, lip synchronization, and perceptual quality on the paper’s cross-scene benchmark.