Disfluency-Aware ASR
Learning to Hear Hesitation: Continual Learning for Disfluency-Aware ASR
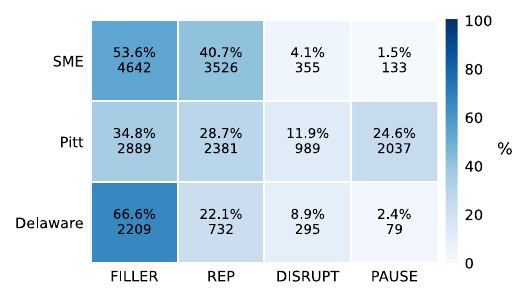
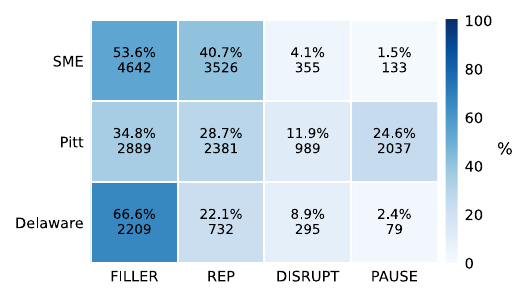
This work presents a continual-learning method to enable ASR models to detect and emit disfluency markers like fillers and pauses. It balances the trade-off between maintaining transcription accuracy and learning disfluency detection, using explicit tokens and adapted training strategies.
Demos
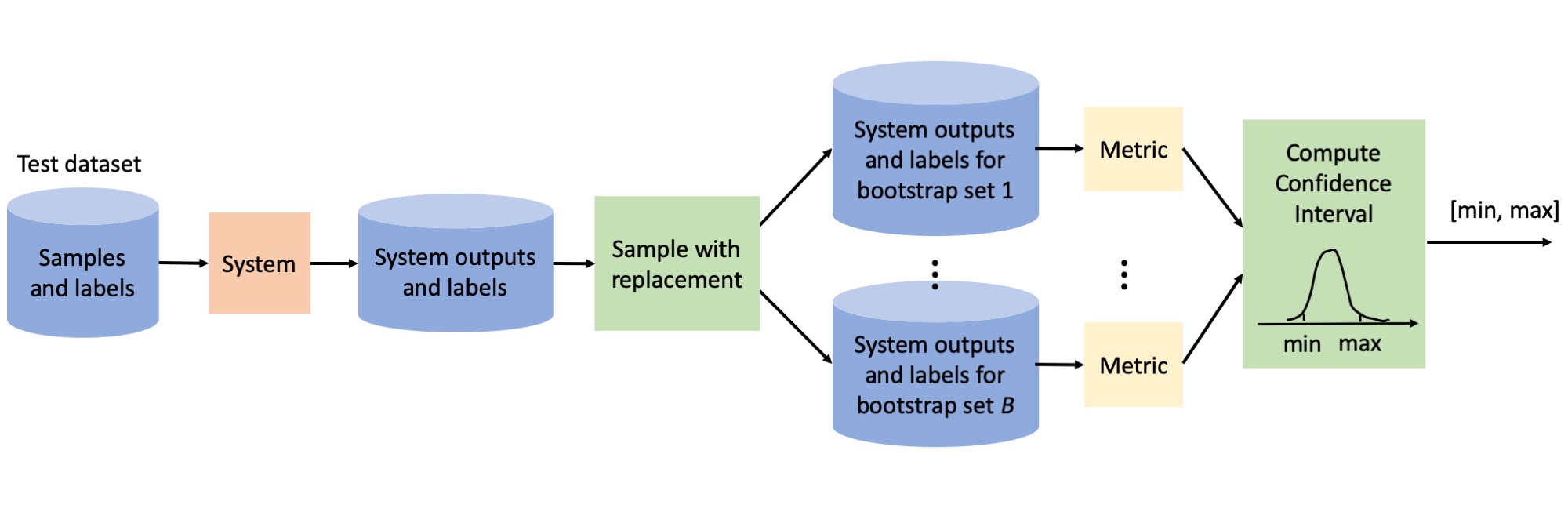
The demo shows the bootstrapping process for computing confidence intervals in machine learning evaluation, emphasizing its ability to handle correlated samples like those from different speakers. When evaluating, focus on how this method estimates performance variability and provides reliable confidence intervals that reflect true system robustness across various conditions.
Links
Paper & demos
Code & resources
Impact
Abstract
Despite advances in large-scale Automatic Speech Recognition (ASR), disfluent speech remains challenging, as state-of-the-art systems are often optimized to omit disfluencies, leading to information loss and hallucinations. Prior work has focused on verbatim transcription and the integration of disfluency markers, but adapting models on limited datasets can lead to catastrophic forgetting of general-domain knowledge. We address this gap by leveraging continual learning (CL) with explicit disfluency tokens. We first introduce these tokens into a pretrained ASR model to establish stable token mechanisms, and then continue training on additional datasets with varying disfluency distributions. Through a detailed analysis of model dynamics during training, we identify a trade-off between marker learning and ASR performance, and a consistent cross-attention head mechanism shared across CL methods.
Introduction and problem setting
This paper studies disfluency-aware automatic speech recognition (ASR) under a continual learning (CL) regime. The core motivation is that large pretrained ASR systems are usually optimized to produce clean transcripts, which often means they omit disfluencies such as fillers, repetitions, repairs, pauses, and related speech events. In disfluent speech, this omission can cause information loss, reduced transparency, and even hallucinated or fabricated output.
The paper argues that existing approaches to verbatim transcription and disfluency-marker insertion typically adapt models on comparatively small datasets, which can trigger catastrophic forgetting of general-domain ASR capability. The proposed response is to combine explicit disfluency tokens with CL methods so that a pretrained ASR backbone can absorb new marker behavior while preserving performance on standard speech.
The study contributes both methodologically and analytically: it evaluates several CL strategies for introducing and retaining disfluency tokens, and it probes internal model behavior with attention-head attribution. The headline finding is a persistent trade-off: methods that are better at preserving general ASR quality tend to be weaker at learning disfluency markers, while methods that learn markers reliably incur a measurable ASR cost. The paper also reports that successful marker emission is associated with a small, shared set of specialized decoder cross-attention heads across CL methods.
Data and task formulation
The experiments use three TalkBank-derived datasets with manually annotated CHAT-style disfluency markup, enabling a direct mapping from transcription symbols to disfluency tokens:
- SME Corpus (Standard Malaysian English): $11.79$ hours of English speech from Malaysian university students who are second-language learners.
- Pitt Corpus: $21.30$ hours of speech from elderly speakers with dementia or Alzheimer's disease; the CL setup uses only $12.11$ hours to reduce dataset-size effects.
- Delaware Corpus: $9.72$ hours of speech from people with mild cognitive impairment.
Pitt and Delaware include healthy control speech; the paper splits the control portion evenly between training and validation. All datasets use the unified CHAT transcription format, which helps standardize label syntax across corpora. A small subset of LibriSpeech is also included as a rehearsal buffer in replay-based CL methods and as an example of non-disfluent speech.
The task is framed as ASR with explicit disfluency token prediction. The authors aggregate disfluencies into four token types: FILLER (e.g., "um", "uh"), REP (repetitions/revisions at word or phoneme level), DISRUPT (e.g., coughs, laughs), and PAUSE.
For general ASR quality, the paper uses preprocessed word error rate ($\text{pWER}$), computed after removing punctuation, special characters, and disfluency markers from the reference and hypothesis transcripts. For disfluency markers, the paper reports micro- and macro-averaged F1 scores, computed with a bag-of-words formulation.
For CL analysis, the paper adapts standard CL metrics using pWER and marker F1 in place of accuracy. These include average and incremental variants of error and marker scores, as well as backward transfer, forgetting, forward transfer, and intransigence measures.
Method overview
The backbone model is $\texttt{whisper-small.en}$, a pretrained monolingual ASR model. The paper does not modify the fundamental encoder-decoder architecture, but it introduces explicit disfluency tokens into the vocabulary and studies how well the model can learn to emit them under CL.
The overall training idea is two-stage:
- Disfluency token introduction: fine-tune the pretrained model on SME so that the model learns to emit disfluency markers while keeping clean-speech performance high.
- Sequential continual adaptation: continue training the best checkpoint from stage 1 on Pitt and then Delaware, evaluating retention of both ASR quality and marker behavior under distribution shift.
The paper compares four CL strategies commonly used in domain-incremental ASR:
- Elastic Weight Consolidation (EWC): regularizes parameters deemed important for previous tasks using the diagonal Fisher information matrix.
- Experience Replay (ER): mixes current training data with a rehearsal buffer of old samples.
- A-GEM: constrains updates by comparing gradients from current data and rehearsal data and discouraging opposing directions.
- Weight Averaging (WA): keeps a copy of old weights, trains on new data, and averages old and new weights at the end of training.
The authors emphasize that these methods represent different stability-plasticity trade-offs: EWC and WA are more preservation-oriented, while ER and A-GEM preserve old knowledge via replay or gradient constraints.
Explainability and head-level analysis
To probe whether disfluency handling emerges in specialized subcircuits, the paper uses a head-masking method inspired by Michel et al. A learnable gate $\xi_h$ is associated with each attention head $h$, and token-level head importance is estimated by the sensitivity of a token objective to that gate:
$$I_h = \mathbb{E}_{x \sim X_t}\left[\frac{\partial \mathcal{L}(x)}{\partial \xi_h}\right]$$
Heads are then ranked by their importance for disfluency tokens, and a top-10 lift is computed by comparing the probability that a head appears among the top-ranked heads for disfluency tokens versus baseline tokens:
$$\text{Lift}_h = P(h \in \text{Top-}k \mid X_t) - P(h \in \text{Top-}k \mid X_{\text{base}})$$
The authors use this ranking to identify candidate heads for zero-masking ablations, checking whether suppressing them changes marker emission without substantially harming pWER. This is important because it tests whether the observed attention specialization is merely correlational or actually causal.
Training protocol
All train/test splits are speaker-disjoint and use an $80/20$ partition. The rehearsal buffer samples $10\%$ of the training data from each dataset, with greedy prioritization of rare disfluency markers so that the buffer better matches the full token distribution. Each dataset is trained for $10$ epochs with a learning rate of $2\times 10^{-5}$ and batch size $16$. Results are averaged over three runs.
For replay-based methods, $25\%$ of old data is included per batch. For EWC, the importance parameter is set to $1000$. The paper reports that these settings were chosen based on the literature and empirical validation.
The experimental design is explicitly intended to avoid unrealistic joint retraining on all historical disfluency data, since the authors argue that continual data accumulation is more realistic for speech scenarios with privacy constraints and ongoing data collection.
Experiment 1: introducing disfluency tokens on SME
The first experiment asks whether a pretrained ASR model can be taught to emit disfluency markers without sacrificing too much general ASR quality. SME is the closest domain to the backbone and mainly contains the two marker types FILLER and REP, making it a suitable starting point for token introduction.
The table below reports the main outcome after $10$ epochs of fine-tuning on SME: pWER on SME, pWER on LibriSpeech test-clean, and marker micro-F1 on SME.
| Method | SME pWER $\downarrow$ | LibriSpeech pWER $\downarrow$ | SME marker micro-F1 $\uparrow$ |
|---|---|---|---|
| Backbone | 15.97 | 3.47 | 0.00 |
| FT | 12.21 $\pm$ 0.18 | 5.06 $\pm$ 0.02 | 0.73 $\pm$ 0.01 |
| A-GEM | 12.17 $\pm$ 0.17 | 4.39 $\pm$ 0.07 | 0.75 $\pm$ 0.01 |
| ER | 12.47 $\pm$ 0.03 | 4.55 $\pm$ 0.13 | 0.73 $\pm$ 0.01 |
| EWC | 10.34 $\pm$ 0.47 | 4.43 $\pm$ 0.07 | 0.21 $\pm$ 0.07 |
| WA | 9.64 $\pm$ 0.08 | 3.41 $\pm$ 0.01 | 0.00 $\pm$ 0.00 |
The principal result is a clear trade-off between pWER and marker learning. WA is the strongest method for preserving or even slightly improving non-disfluent ASR quality on LibriSpeech and also achieves the lowest pWER on SME, but it fails to reliably emit disfluency markers at all. EWC improves SME pWER substantially compared with plain fine-tuning but also under-learns markers. In contrast, FT, ER, and A-GEM emit markers reliably, with micro-F1 around $0.73$ to $0.75$, but they do not achieve the same pWER reduction on SME.
The authors interpret this as evidence that marker learning requires parameter updates that partially conflict with low-cost ASR domain adaptation. In other words, a model can either adapt efficiently for transcription quality or commit more strongly to a marker-emitting behavior, but the two goals are not perfectly aligned.
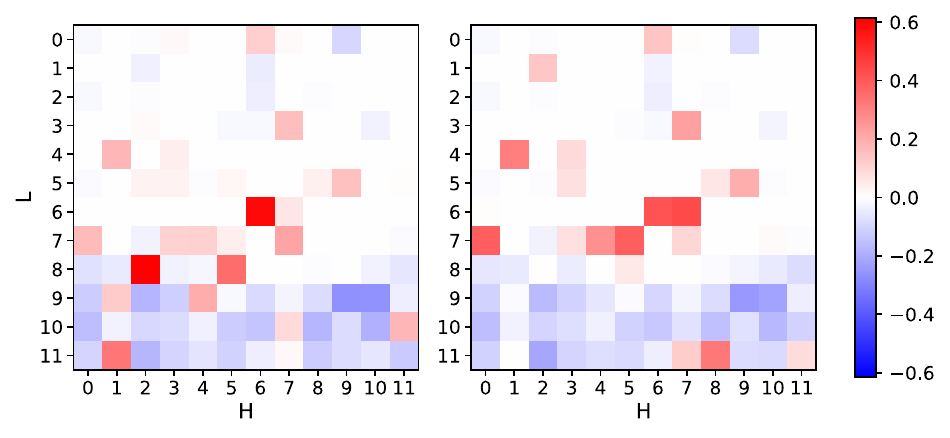
The attention analysis suggests that when markers are learned successfully, the model repeatedly relies on a small number of specialized decoder cross-attention heads. Importantly, this pattern appears across different CL methods, suggesting a shared mechanism rather than method-specific hacks or idiosyncratic optimization artifacts.
The ablation study supports this interpretation. Zero-masking the top-5 cross-attention heads associated with FILLER or REP substantially reduces marker emission while leaving pWER nearly unchanged. This is strong evidence that these heads are causally involved in disfluency token generation.
| Ablation | $\Delta$ FILLER | $\Delta$ REP | $\Delta$ pWER |
|---|---|---|---|
| FILLER: Top-5 | -57.0 $\pm$ 5.2 | -7.1 $\pm$ 3.8 | +0.42 $\pm$ 0.64 |
| REP: Top-5 | -2.8 $\pm$ 1.1 | -15.7 $\pm$ 4.2 | +0.13 $\pm$ 0.46 |
| Union of top-5 heads | -62.2 $\pm$ 5.2 | -21.2 $\pm$ 9.8 | +0.44 $\pm$ 0.68 |
| Random-head control | +0.2 $\pm$ 0.5 | +0.4 $\pm$ 1.2 | +0.15 $\pm$ 0.21 |
The random-head control leaves both marker emission and pWER almost unchanged, reinforcing that the effect is not a generic consequence of masking arbitrary attention heads. The authors highlight that roughly half of emitted FILLER markers can be removed by targeted ablation with only a negligible pWER change.
Experiment 2: sequential continual adaptation on Pitt and Delaware
The second experiment starts from the best checkpoint from stage 1, selected using SME marker-F1 together with SME pWER. The chosen checkpoint is the A-GEM seed 2 model, which reliably emits markers. From there, the model is trained sequentially on Pitt and then Delaware, simulating incremental adaptation to more difficult and changing disfluency distributions.
Pitt introduces a larger number of PAUSE markers and more DISRUPT events, while Delaware contains the fewest markers overall, making it a particularly strong test of marker retention.
The paper reports a broad set of CL metrics after the sequential adaptation stage:
- A-WER / A-F1: average performance at the current step.
- AI-WER / AI-F1: average incremental performance across the CL trajectory.
- BWT: backward transfer, summarizing retained performance on earlier tasks.
- FM: forgetting measure.
- FWT: forward transfer.
- IM: intransigence measure.
The central table in the paper shows that all CL methods outperform plain fine-tuning in some respect, but the best method depends on whether the goal is transcription quality or marker retention. The table below reproduces the reported values.
| Method | A-WER $\downarrow$ | A-F1 $\uparrow$ | AI-WER $\downarrow$ | AI-F1 $\uparrow$ | BWT (pWER) $\uparrow$ | BWT (F1) $\uparrow$ | FM (pWER) $\downarrow$ | FM (F1) $\downarrow$ | FWT (pWER) $\uparrow$ | FWT (F1) $\uparrow$ | IM (pWER) $\downarrow$ | IM (F1) $\downarrow$ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| JOINT | 17.95 $\pm$ 0.28 | 0.47 $\pm$ 0.01 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- |
| FT | 20.24 $\pm$ 0.14 | 0.39 $\pm$ 0.02 | 19.00 $\pm$ 0.06 | 0.49 $\pm$ 0.01 | -3.18 $\pm$ 0.26 | -0.16 $\pm$ 0.02 | 3.48 $\pm$ 0.35 | 0.19 $\pm$ 0.02 | -3.81 $\pm$ 0.10 | -0.05 $\pm$ 0.01 | 0.44 $\pm$ 0.07 | -0.03 $\pm$ 0.01 |
| A-GEM | 20.15 $\pm$ 0.68 | 0.36 $\pm$ 0.02 | 18.88 $\pm$ 0.24 | 0.48 $\pm$ 0.01 | -3.46 $\pm$ 0.78 | -0.19 $\pm$ 0.03 | 3.50 $\pm$ 0.72 | 0.21 $\pm$ 0.03 | -3.39 $\pm$ 0.24 | -0.07 $\pm$ 0.01 | 0.16 $\pm$ 0.16 | -0.02 $\pm$ 0.00 |
| ER | 19.71 $\pm$ 0.23 | 0.49 $\pm$ 0.01 | 18.17 $\pm$ 0.10 | 0.53 $\pm$ 0.01 | -2.57 $\pm$ 0.48 | 0.01 $\pm$ 0.01 | 2.59 $\pm$ 0.46 | 0.02 $\pm$ 0.00 | -3.63 $\pm$ 0.52 | -0.06 $\pm$ 0.00 | 0.32 $\pm$ 0.34 | -0.03 $\pm$ 0.00 |
| EWC | 19.01 $\pm$ 0.08 | 0.44 $\pm$ 0.01 | 18.28 $\pm$ 0.05 | 0.52 $\pm$ 0.00 | -1.40 $\pm$ 0.08 | -0.09 $\pm$ 0.02 | 2.18 $\pm$ 0.16 | 0.13 $\pm$ 0.02 | -3.75 $\pm$ 0.20 | -0.05 $\pm$ 0.01 | 0.40 $\pm$ 0.13 | -0.03 $\pm$ 0.01 |
| WA | 18.90 $\pm$ 0.19 | 0.46 $\pm$ 0.00 | 17.57 $\pm$ 0.04 | 0.51 $\pm$ 0.01 | -0.55 $\pm$ 0.34 | -0.01 $\pm$ 0.00 | 1.35 $\pm$ 0.20 | 0.05 $\pm$ 0.01 | -4.43 $\pm$ 0.13 | -0.10 $\pm$ 0.00 | 0.85 $\pm$ 0.09 | 0.00 $\pm$ 0.00 |
The most important patterns are:
- WA gives the best overall pWER retention and the most stable incremental pWER behavior, with the strongest average and incremental ASR performance among the CL methods.
- ER gives the best marker retention and generalization, with the highest average and incremental marker F1 and essentially no forgetting on marker performance.
- A-GEM achieves the best forward transfer on pWER and the lowest intransigence on pWER, but not the best overall marker behavior.
- EWC is competitive on pWER retention but is not the strongest for marker acquisition or marker stability.
The paper further breaks down marker performance by type after sequential training. FILLER is the easiest and remains reasonably strong across methods, while REP is more method-sensitive. PAUSE is the hardest marker type overall, and ER provides the clearest advantage there.
| Method | FILLER | REP | DISRUPT | PAUSE |
|---|---|---|---|---|
| Joint | 0.71 $\pm$ 0.01 | 0.54 $\pm$ 0.02 | 0.42 $\pm$ 0.02 | 0.25 $\pm$ 0.02 |
| FT | 0.69 $\pm$ 0.02 | 0.42 $\pm$ 0.02 | 0.34 $\pm$ 0.00 | 0.09 $\pm$ 0.06 |
| A-GEM | 0.68 $\pm$ 0.01 | 0.35 $\pm$ 0.03 | 0.34 $\pm$ 0.03 | 0.05 $\pm$ 0.02 |
| ER | 0.75 $\pm$ 0.01 | 0.61 $\pm$ 0.00 | 0.38 $\pm$ 0.01 | 0.23 $\pm$ 0.02 |
| EWC | 0.72 $\pm$ 0.01 | 0.49 $\pm$ 0.02 | 0.37 $\pm$ 0.02 | 0.16 $\pm$ 0.01 |
| WA | 0.73 $\pm$ 0.00 | 0.63 $\pm$ 0.01 | 0.37 $\pm$ 0.01 | 0.09 $\pm$ 0.01 |
This breakdown shows that the marker story is not uniform across disfluency types. REP appears especially sensitive to the CL strategy, and PAUSE is the most difficult token category overall. The fact that ER leads on aggregate marker F1 is driven by particularly strong performance on REP and PAUSE, not just by a single easy marker type.
The paper also checks non-disfluent retention after sequential adaptation using LibriSpeech pWER. The ranking mirrors the disfluent-speech retention trend: WA is best at $4.68\%$, followed by EWC at $6.45\%$, ER at $7.14\%$, and A-GEM at $8.36\%$, which is almost the same as the FT baseline at $8.37\%$. This reinforces the claim that WA is the strongest method when the priority is preserving general ASR capability.
Interpretation and main findings
The study's main conceptual result is that disfluency marker learning and general ASR preservation are partially competing objectives. Methods that preserve pWER well, especially WA and EWC, do not necessarily learn the marker vocabulary robustly. Methods that reliably emit markers, especially FT, ER, and A-GEM in stage 1, pay a cost in pWER.
A second main result is mechanistic: successful marker learning is not diffuse across the decoder, but concentrated in a small number of cross-attention heads. The same heads appear across multiple token-emitting methods, implying a stable specialized pathway for disfluency emission. The causal ablation results strengthen this conclusion by showing that masking these heads removes marker output with only a minimal change in pWER.
In the sequential setting, ER is the best choice when the goal is marker generalization and retention across heterogeneous disfluency corpora. WA is the best choice when the goal is minimizing forgetting and maintaining clean-speech and disfluent-speech ASR quality. The paper therefore does not present one universally superior CL method; instead, it maps methods to different priorities.
Limitations stated or implied by the paper
- The study uses one backbone, $\texttt{whisper-small.en}$, so the results are not yet shown to generalize across architectures or model sizes.
- The sequential CL study follows one task ordering and one realistic adaptation path: SME $\rightarrow$ Pitt $\rightarrow$ Delaware.
- The datasets are all from TalkBank and CHAT-annotated corpora, so the findings are strongest for this family of disfluency annotations and domains.
- The paper focuses on explicit disfluency tokens and does not claim to solve all forms of impaired speech or all possible verbatim transcription objectives.
- The analysis emphasizes decoder cross-attention head specialization; other possible mechanisms are not exhaustively studied.
Even with these constraints, the authors present the work as one of the first CL studies for disfluency modeling and as a practical step toward verbatim ASR systems that preserve more of what was actually spoken.
Conclusion
The paper shows that continual learning can be used to introduce and retain disfluency tokens in a pretrained ASR system, but the outcome depends strongly on the CL method and on the objective being optimized. For stage-1 marker introduction on SME, there is a sharp trade-off between pWER and marker-F1: WA is best for pWER but does not learn markers, while FT, ER, and A-GEM learn markers well but at higher pWER. For sequential adaptation on Pitt and Delaware, ER is strongest for marker retention and generalization, whereas WA is strongest for pWER stability and clean-speech retention.
Mechanistically, the paper argues that disfluency emission is mediated by a consistent, small set of decoder cross-attention heads. This shared head specialization helps explain why disfluency markers can be learned reliably in some CL settings and why targeted ablation can suppress them. Taken together, the work provides both an empirical benchmark and a mechanistic account for disfluency-aware ASR under continual adaptation.