BayLing-Duplex
BayLing-Duplex: Native Full-Duplex Speech Dialogue with a Single Autoregressive LLM
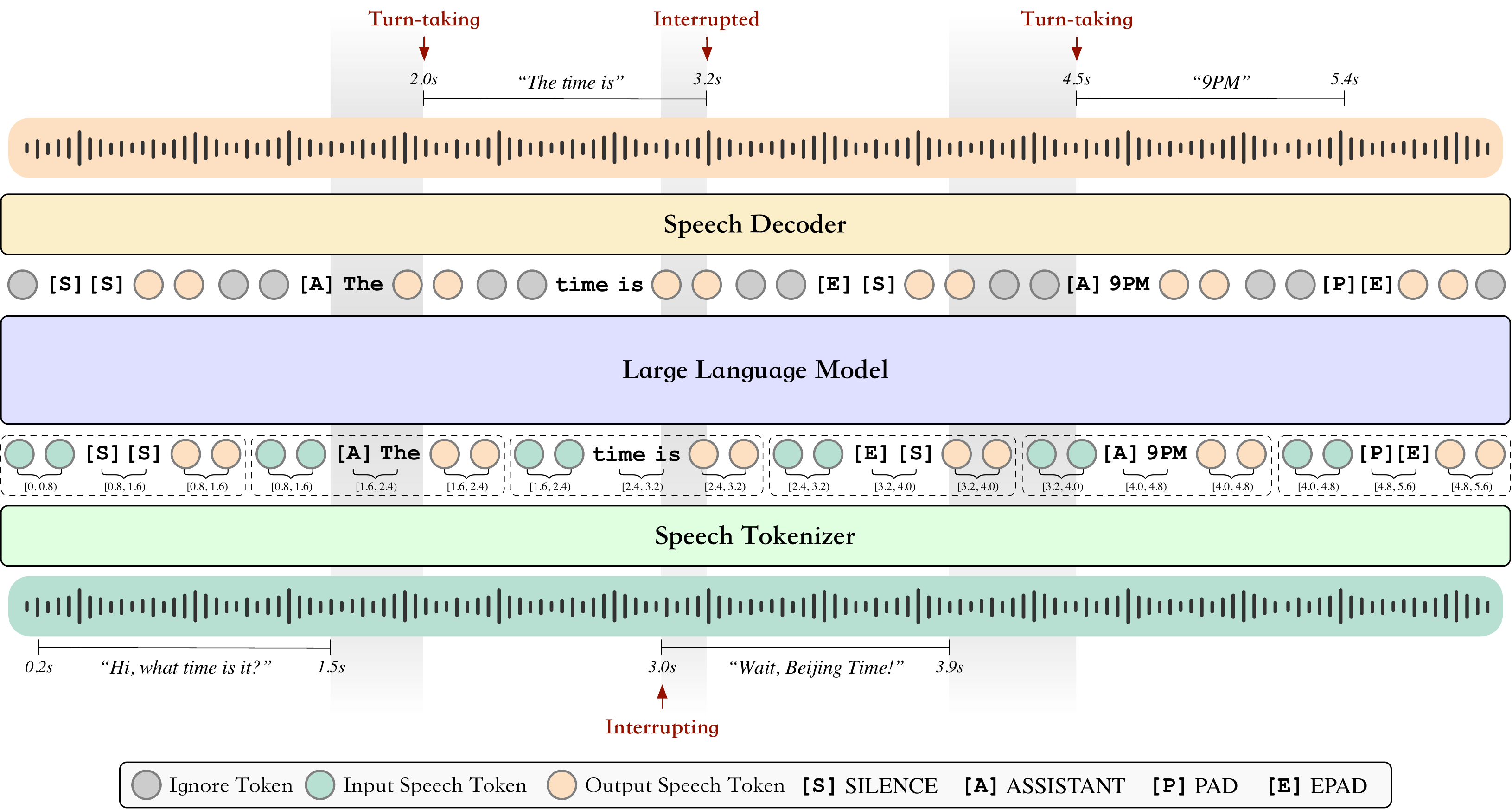
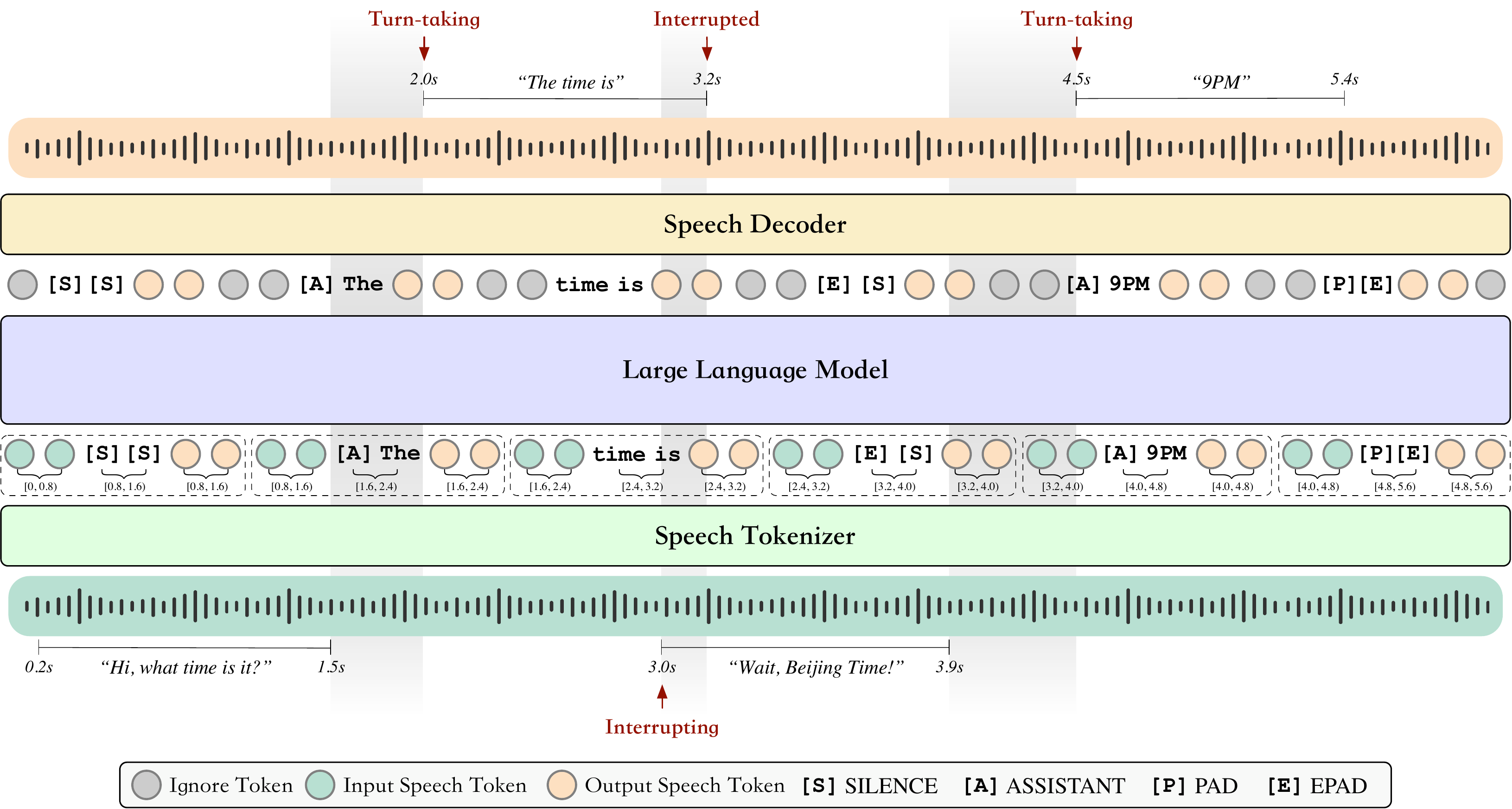
BayLing-Duplex is a full-duplex speech dialogue system that uses a single autoregressive LLM to listen and speak simultaneously, handling overlaps and interruptions without external turn-taking modules. It models dialogue states as token predictions, enabling real-time, seamless interaction.
Demos
The BayLing-Duplex demo highlights native full-duplex speech dialogue where the model listens and speaks simultaneously without external controllers. It showcases smooth turn-taking, interruption handling, and natural speech generation from a single autoregressive model predicting text and speech tokens. Evaluate how seamlessly it integrates listening, planning, and speaking in real-time dialogue.
Links
Paper & demos
Code & resources
Impact
Abstract
Real-time, full-duplex speech interaction is a key feature of next-generation spoken chatbots, allowing the model to listen and speak at the same time and to handle natural phenomena such as overlap, hesitation, and barge-in. Existing speech language models (SpeechLMs) such as LLaMA-Omni and GLM-4-Voice are still turn-based and rely on an external Voice Activity Detection (VAD) module to mark the end of the user's turn, which fundamentally limits their interactive ability. In this paper, we introduce BayLing-Duplex, a native full-duplex SpeechLM where a single autoregressive LLM decides when to listen, when to speak, and when to stop, with no auxiliary turn-taking module. The design adds only a few special tokens to the standard vocabulary, so it transfers across LLMs and reuses existing training and serving stacks with no architectural adaptation. Starting from the public GLM-4-Voice checkpoint and using only 400K full-duplex samples for fine-tuning followed by a lightweight DPO stage, BayLing-Duplex reaches 92% turn-taking success and 100% interruption success on InstructS2S-Eval, while improving the speech-response score from 2.17 to 3.39 over Moshi. BayLing-Duplex also matches or surpasses its turn-based counterpart on Llama Questions, Web Questions, and Alpaca-Eval, showing that simultaneous listen-and-speak modeling does not sacrifice response quality.
Introduction
BayLing-Duplex is a native full-duplex speech dialogue model built to remove the usual turn-based assumption from spoken chatbots. The paper targets the setting where the assistant must listen and speak at the same time, handle overlap and barge-in, and decide internally when to start and stop talking. The main claim is that these decisions can be represented as ordinary next-token prediction in a single autoregressive LLM, without an external voice activity detection module or a separate turn-taking controller.
The motivation is that existing speech language models such as LLaMA-Omni and GLM-4-Voice still rely on turn segmentation: a front-end VAD marks the end of the user turn, then the model responds. The paper argues that this hard codes a brittle interface boundary, because VAD cannot use dialogue semantics and therefore struggles with mid-utterance pauses, user interruptions, and short backchannels. BayLing-Duplex instead models these temporal decisions inside the language model itself.
The design is intentionally minimal. Starting from the public GLM-4-Voice checkpoint, the authors add only a small set of dialogue-state tokens to the standard vocabulary and keep the rest of the training and serving stack unchanged. The model is fine-tuned on 400K full-duplex samples and then refined with a lightweight preference optimization stage. The paper reports strong gains in turn-taking and interruption timing while preserving, and in some cases improving, response quality on spoken question answering and standard text benchmarks.
Core idea and architecture
The backbone is GLM-4-Voice, which itself combines three components: a speech tokenizer, a decoder-only LLM, and a speech decoder. The speech tokenizer is a modified Whisper-large-v3 encoder with a vector quantizer that maps 16 kHz waveforms to discrete tokens at $f_s = 12.5$ Hz, i.e. one token every 80 ms. The language model is a 9B-parameter decoder-only Transformer initialized from GLM-4-9B with the speech tokens added to its vocabulary. The speech decoder is a flow-matching model followed by a HiFi-GAN vocoder, adapted from CosyVoice.
The method’s key novelty is a multi-channel interleaved sequence. Instead of a single stream of user tokens followed by a single assistant response, BayLing-Duplex interleaves three channels block by block:
- user speech tokens,
- assistant text tokens, and
- assistant speech tokens.
Each block contains $N$ user-speech tokens, $M$ text tokens, and $N$ assistant-speech tokens, i.e. an $N{:}M{:}N$ layout. In practice the paper uses $N = 10$ and $M = 5$, which gives a block duration of $b4t = 0.8$ s and an average text rate of 6.25 tokens per second. The authors explicitly discuss the trade-off: smaller blocks can make response timing jittery because there are too few text slots, while larger blocks increase minimum latency because the assistant can only react at block boundaries.
The assistant side uses a causal shift: at block $b$, the model has already observed the user tokens up to time $(b+1)b4t$, while the assistant text and speech tokens generated for that block correspond to the wall-clock interval $[(b+1)b4t, (b+2)b4t)$. In other words, the model predicts what should happen slightly ahead of the user stream, and playback is offset by one block.
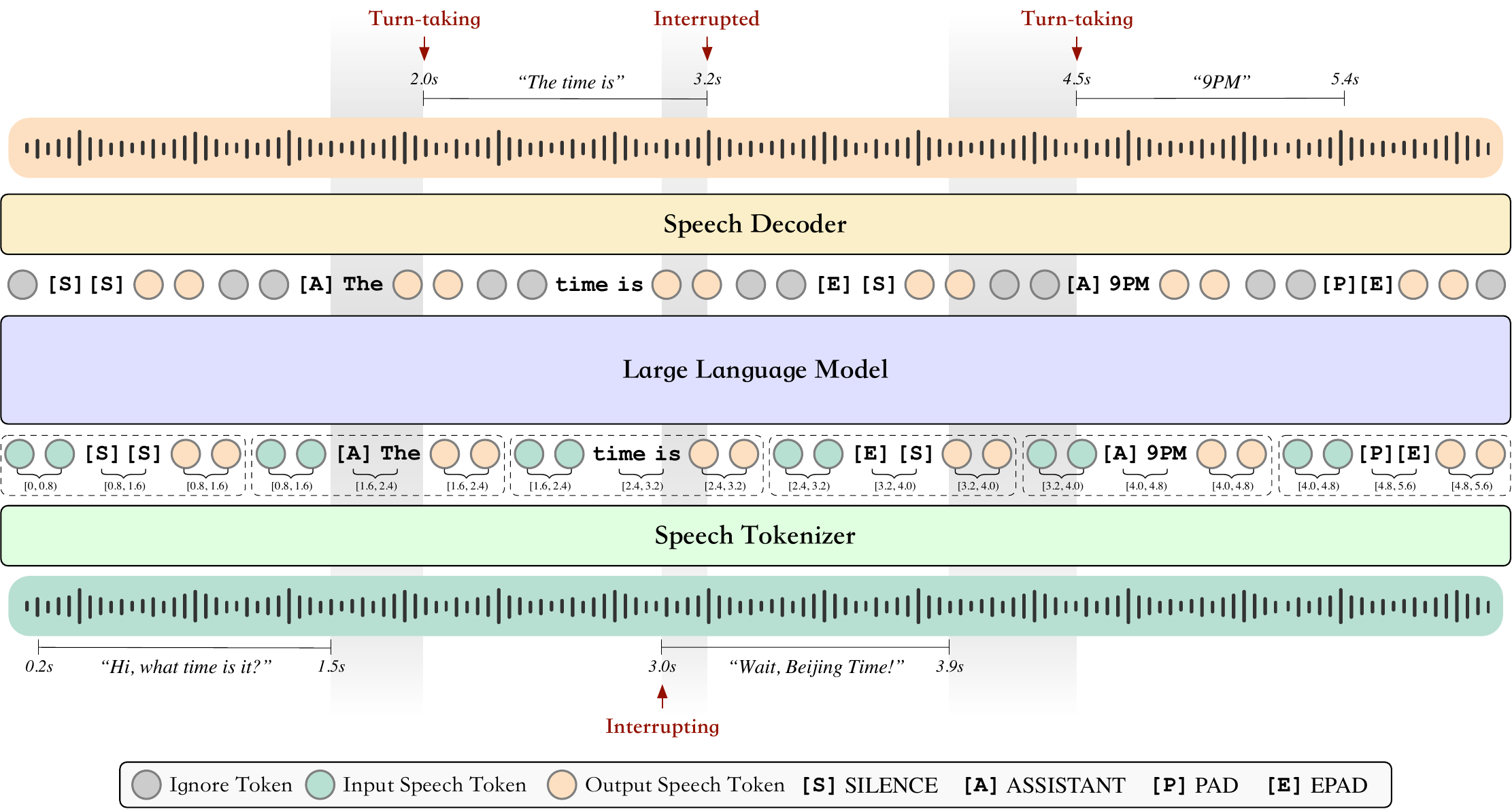
The text channel acts like an inner monologue that never reaches the user but conditions the assistant speech within the same block. It is initialized with [SILENCE] and overwritten when the assistant begins a reply. Four dialogue-state tokens encode the high-level conversational state:
- [SILENCE]: the assistant should remain silent.
- [ASSISTANT]: the start of an assistant reply.
- [PAD]: text for the reply has been written, but speech is still being emitted.
- [EPAD]: both text and speech for the current reply are complete.
These tokens are crucial because they let turn-taking and interruption decisions become regular vocabulary prediction instead of a separate classification problem. The paper emphasizes that there is no extra head, no scheduler, no state machine, and no architecture change beyond the token additions.
Formal sequence formulation
For a dialogue represented as aligned user and assistant audio tracks, the tokenizer yields user tokens $\mathbf{X} = (x_1, \dots, x_{T_s})$ and assistant tokens $\mathbf{Y} = (y_1, \dots, y_{T_s})$. The text channel is $\mathbf{Z} = (z_1, \dots, z_{T_z})$, with $T_z = T_s \cdot M/N$. Each block is organized as:
$$ \text{Block } b: \quad x_{bN+1:(b+1)N},\; z_{bM+1:(b+1)M},\; y_{bN+1:(b+1)N}. $$
The paper describes the sequence as autoregressive over the combined stream, with the user channel acting as conditioning input and the model predicting the text and assistant-speech positions.
The supervised loss is computed only on the text and assistant-speech positions. If $\mathcal{V}$ is the set of supervised positions, then the token loss is $\ell_i = -\log p_\theta(s_i \mid s_{<i})$. Because silence dominates most of the sequence and role tokens are rare, BayLing-Duplex uses per-token weights:
$$ \mathcal{L}_{\text{SFT}} = \frac{\sum_{i \in \mathcal{V}} \omega_i \ell_i}{\sum_{i \in \mathcal{V}} \omega_i}. $$
The paper tunes two weights in particular: $\omega_{\text{sil}}$ for [SILENCE], and $\omega_{\text{role}}$ for [ASSISTANT] and [EPAD]. The intuition is that without reweighting, the model is dominated by the large number of silence tokens and can collapse toward staying silent too often.
Training recipe
Training is done in two stages starting from the public GLM-4-Voice checkpoint. The speech tokenizer and speech decoder are frozen; the LLM is fully fine-tuned. The paper explicitly states that no new parameters or auxiliary heads are added.
Stage I: supervised fine-tuning
Stage I is supervised fine-tuning on the full-duplex training dialogues. The paper uses 400K full-duplex samples in total, split evenly between turn-taking and interruption scenarios. Optimization runs for one epoch with batch size 32, peak learning rate $10^{-5}$, cosine schedule, and 10% warm-up. Training uses the LLaMA-Factory codebase.
The key data-generation idea is to reuse a multi-turn speech-to-speech corpus built from Alpaca and UltraChat through rewriting with Llama-3.3-70B-Instruct and synthesizing speech with CosyVoice zero-shot voice cloning. The user instructions are synthesized with diverse voices, while assistant responses use a uniform voice so each dialogue has consistent assistant timbre but varied user voices.
For the two full-duplex scenarios, the paper constructs aligned training sequences as follows:
- Turn-taking: insert a 0.8 s gap from the end of the user utterance to the start of the assistant response; the gap between the assistant response and the next user utterance is sampled from $\mathrm{Uniform}(0.5, 3.0)$ s.
- Interruption: let the user re-enter during the assistant response, and stop the assistant after a reaction delay $\delta_{\text{react}} \sim \mathrm{Uniform}(0.8, 2.0)$ s.
The final SFT mixture is 1:1 between turn-taking and interruption samples, with 200K examples for each scenario.
Stage II: Direct Preference Optimization
Stage II applies DPO to improve temporal decisions without changing the content of the responses. The positive examples are the SFT samples, while the negative examples are generated by perturbing only the timing of the assistant. For turn-taking, the 0.8 s gap is replaced by a larger delay sampled from $\mathrm{Uniform}(2, 5)$ s, which makes the model over-predict [SILENCE] after the user finishes speaking. For interruption, the reaction delay is replaced by a delay sampled from $\mathrm{Uniform}(3, 5)$ s, so the assistant continues speaking too long after the user barges in.
The DPO objective is the standard preference form against the Stage I checkpoint as the reference policy $\pi_{\text{ref}}$, with an auxiliary SFT term to avoid forgetting:
$$ \mathcal{L} = \mathcal{L}_{\text{DPO}} + \lambda_{\text{ftx}} \mathcal{L}_{\text{SFT}}(\mathbf{s}^+), $$
where
$$ \mathcal{L}_{\text{DPO}} = -\log \sigma\left(\beta\left[\log\frac{\pi_\theta(\mathbf{s}^+)}{\pi_{\text{ref}}(\mathbf{s}^+)} - \log\frac{\pi_\theta(\mathbf{s}^-)}{\pi_{\text{ref}}(\mathbf{s}^-)}\right]\right). $$
In the default setting, the paper uses $\beta = 0.5$ and $\lambda_{\text{ftx}} = 0.5$. DPO is trained for 200 steps with peak learning rate $3 \times 10^{-7}$ and 5% warm-up.
Inference behavior
Inference is block-wise and strictly autoregressive. For each block, the model receives $N$ user tokens from the live stream, then generates $M$ text tokens with a vocabulary mask restricted to text and state tokens, then generates $N$ assistant-speech tokens with a mask restricted to speech tokens. The generated speech tokens are decoded and played at $(b+1)\u00b4t$ for block $b$.
The masking is only applied at inference; during training the full cross-entropy loss naturally discourages invalid cross-channel tokens. The authors note that without masking, the model can occasionally emit tokens from the wrong channel and corrupt the speech decoder input. During silence, the user channel is still streamed and tokenized rather than zero-padded. If the user barges in mid-block, the in-flight assistant speech is allowed to finish for that block, and the model reconditions on the new user audio in the next block. This keeps the entire process autoregressive and avoids any noncausal intervention.
Evaluation setup
The paper evaluates BayLing-Duplex on three tasks: spoken question answering, full-duplex turn-taking, and full-duplex interruption. Sampling uses temperature 0.8. Assistant audio is transcribed by Whisper-large-v3 and segmented by Silero VAD. Importantly, the VAD is used only for evaluation, not for inference.
For spoken QA, the paper uses two datasets: Llama Questions with 300 items and Web Questions with 2032 items, the latter synthesized into speech by CosyVoice. The system listens to the spoken question and decides when to answer without any external VAD. Accuracy is exact match, computed by case-insensitive substring match between the reference answer and the Whisper transcription.
For turn-taking and interruption, the paper follows InstructS2S-Eval, which contains 199 spoken instructions filtered from Alpaca-Eval. Turn-taking measures how quickly the assistant starts speaking after the user ends. Interruption creates 199 two-utterance audios by pairing adjacent items so the second utterance starts while the assistant is already speaking. The evaluation then measures whether the assistant stops quickly and whether the response to the interrupting question is relevant.
The reported metrics are:
- TT SR@3s: fraction of cases where the assistant starts replying within 3 s of the user’s end.
- S2S Score: a 1--5 GPT-4o judgment of the transcribed reply for helpfulness, relevance, fluency, and suitability for speech interaction.
- Overlap: time in seconds from user barge-in to assistant stop; lower is better.
- ISR@2s: fraction of cases where overlap is at most 2 s.
- Q2 S2S: S2S Score for the assistant’s reply to the second, interrupting question.
The main baseline is Moshi, using the publicly released Moshika checkpoint. The paper also includes a turn-based SFT baseline trained on the same data and the same GLM-4-Voice backbone for a direct quality comparison.
Main results
BayLing-Duplex improves both interaction timing and response quality. The largest gains are on interruption, where the model must stop speaking after a barge-in and then answer the new question.
| Model | TT SR@3s ↑ | S2S ↑ | Overlap (s) ↓ | ISR@2s ↑ | Q2 S2S ↑ |
|---|---|---|---|---|---|
| Moshi | 71.9 | 2.17 | 2.07 | 81.9 | 2.45 |
| BayLing-Duplex (SFT) | 88.9 | 3.23 | 1.51 | 91.4 | 2.95 |
| BayLing-Duplex (+DPO) | 92.0 | 3.39 | 1.10 | 100.0 | 3.27 |
On InstructS2S-Eval, the SFT model already substantially outperforms Moshi, and DPO improves it further. Turn-taking success rises from 71.9% for Moshi to 88.9% after SFT and 92.0% after DPO. The GPT-4o speech-response score rises from 2.17 to 3.23 and then 3.39. Interruption improves even more strongly: overlap drops from 2.07 s to 1.51 s and then 1.10 s; ISR@2s increases from 81.9% to 91.4% and finally 100.0%; Q2 S2S rises from 2.45 to 2.95 and then 3.27. The paper notes that interruption benefits the most because the DPO negatives directly postpone the [EPAD] token.
Spoken question answering
| Model | Llama Questions (300) ↑ | Web Questions (2032) ↑ |
|---|---|---|
| Moshi | 21.0 | 9.2 |
| BayLing-Duplex (SFT) | 44.3 | 18.0 |
| BayLing-Duplex (+DPO) | 46.0 | 18.1 |
In spoken QA, BayLing-Duplex nearly doubles Moshi’s accuracy on Llama Questions and roughly doubles it on Web Questions. The DPO stage gives a small additional gain, suggesting that improving timing can also help content reliability. The paper interprets this as evidence that the multi-channel layout preserves the content-modeling ability of the GLM-4-Voice backbone rather than degrading it.
Response quality versus a turn-based baseline
| Model | Llama Questions Acc. ↑ | Web Questions Acc. ↑ | Alpaca S2S ↑ |
|---|---|---|---|
| Turn-based SFT | 45.3 | 15.9 | 3.16 |
| BayLing-Duplex | 44.3 | 18.0 | 3.23 |
The authors compare the duplex SFT model to a turn-based SFT baseline trained on the same data and backbone. The duplex model is slightly worse on Llama Questions, but better on Web Questions and Alpaca-Eval. Their conclusion is that full-duplex training does not sacrifice response quality and can even improve some benchmarks.
Ablation studies
The paper includes two main ablations: token weights in Stage I and DPO hyperparameters in Stage II. These ablations are important because they show that the turn-taking behavior is sensitive to how the model is taught to predict the rare dialogue-state tokens.
Stage I token weighting
| $\omega_{\text{role}}$ | $\omega_{\text{sil}}$ | TT SR@3s ↑ | S2S ↑ | Overlap (s) ↓ | ISR@2s ↑ | Q2 S2S ↑ |
|---|---|---|---|---|---|---|
| 1 | 1 | 60.3 | 3.19 | 1.79 | 100.0 | 2.82 |
| 1 | 0.1 | 82.4 | 3.13 | 1.53 | 89.6 | 2.78 |
| 10 | 1 | 73.9 | 3.02 | 1.53 | 88.5 | 2.81 |
| 10 | 0.1 | 88.9 | 3.23 | 1.51 | 91.4 | 2.95 |
The key takeaway is that uniform weighting collapses toward excessive silence: TT SR@3s falls to 60.3%, even though ISR@2s becomes trivially high because the model barely speaks. Down-weighting [SILENCE] alone helps, and increasing the role-token weight to 10 helps further. The best setting uses both $\omega_{\text{sil}} = 0.1$ and $\omega_{\text{role}} = 10$, confirming that the rare role tokens need explicit emphasis.
DPO hyperparameters
| $\beta$ | $\lambda_{\text{ftx}}$ | TT SR@3s ↑ | S2S ↑ | Overlap (s) ↓ | Q2 S2S ↑ |
|---|---|---|---|---|---|
| 0.1 | 0.3 | 86.4 | 3.36 | 1.01 | 3.09 |
| 0.1 | 0.5 | 89.4 | 3.31 | 1.05 | 3.07 |
| 0.1 | 1.0 | 89.4 | 3.30 | 1.10 | 3.10 |
| 0.3 | 0.3 | 89.4 | 3.38 | 1.01 | 3.06 |
| 0.3 | 0.5 | 87.9 | 3.30 | 1.05 | 3.13 |
| 0.3 | 1.0 | 87.4 | 3.36 | 1.11 | 3.22 |
| 0.5 | 0.3 | 90.1 | 3.35 | 1.01 | 3.17 |
| 0.5 | 0.5 | 92.0 | 3.39 | 1.10 | 3.27 |
| 0.5 | 1.0 | 89.4 | 3.37 | 1.12 | 3.11 |
Across all settings, ISR@2s stays at 100.0%, so DPO is consistently effective at getting the assistant to stop when interrupted. The best overall trade-off is the default $\beta = 0.5$ and $\lambda_{\text{ftx}} = 0.5$, which gives the highest turn-taking score and S2S score. The paper also notes that smaller $\lambda_{\text{ftx}}$ values weaken the auxiliary SFT anchor, while too much auxiliary SFT slightly reduces the DPO effect. Lower $\beta$ values let the model drift farther from the SFT policy and slightly reduce S2S quality.
What the experiments imply
Across the reported tasks, the paper’s central empirical message is that timing can be learned as part of the language modeling problem rather than delegated to a VAD module. The model learns when to speak, how to stop, and how to resume after an interruption, while maintaining content quality. The paper’s strongest evidence for this claim is the combination of: (1) large gains over Moshi on turn-taking and interruption; (2) no loss, and in some cases a gain, on spoken QA; and (3) the fact that the method works with a relatively small 400K-sample full-duplex fine-tuning stage rather than massive duplex pretraining.
The paper also makes a broader architectural point. The interleaved-block formulation preserves the strengths of the underlying native SpeechLM stack: the model still uses the ordinary LLM vocabulary, existing decoder-only training infrastructure, and standard speech tokenization/decoding components. The full-duplex capability comes from how the sequence is organized and how the model is supervised, not from a new specialized module.
Limitations
The paper is explicit about several limitations. First, all training and evaluation audio is synthesized: it is single-speaker, near-field, and noise-free. Real-world deployment will need to handle background noise, reverberation, and competing speakers, all of which can shift user-channel boundaries and cause spurious turn-taking. The authors suggest that additive noise, room impulse response augmentation, and distractor speakers may help, but they do not provide a controlled study.
Second, the analysis focuses on turn-taking and interruption. Other conversational phenomena such as backchannels, multi-party dialogue, and emotion-aware turn-taking are not studied. Third, the chosen block size $N = 10$ sets a lower bound of 0.8 s on response latency; smaller blocks would reduce latency but compress the per-block text budget, and the paper leaves a sweep over $N$ for future work. Finally, the model inherits the limitations of GLM-4-Voice, including weaknesses on rare languages, code-switching, and out-of-distribution acoustic conditions.
Concise takeaway
BayLing-Duplex shows that a standard autoregressive SpeechLM can be converted into a native full-duplex dialogue model by adding a small set of dialogue-state tokens and training on a blockwise interleaved sequence. The method removes the need for external VAD-based turn segmentation, supports barge-in and re-starting behavior, and does so with a modest fine-tuning recipe rather than full-scale duplex pretraining. On the reported benchmarks, it substantially improves over Moshi on both interaction timing and spoken QA while remaining competitive with a turn-based baseline on response quality.
Code & Implementation
The BayLing-Duplex repository provides the implementation of the native full-duplex speech dialogue model described in the paper. The core source code is located primarily in the bayling_duplex/ package, with the central class BayLingDuplex defined in duplex.py. This class encapsulates the model loading, tokenization, audio decoding, and inference logic for full-duplex speech interaction, leveraging autoregressive decoding for joint speech and text token prediction.
The implementation uses Hugging Face Transformers for the autoregressive LLM and incorporates specialized speech tokenizers and audio decoders from the bayling_duplex_runtime/ directory. Key data classes such as DuplexResult and ResponseSegment represent the structured outputs of the model including text and audio segments and turn-taking metadata.
The repository README provides detailed guidance on downloading pretrained model weights, setting up the tokenizers and decoder, and running inference using a command-line interface or a Python API. Notably, it includes instructions for specifying model paths, input audio files, and output formats, supporting GPU acceleration for real-time usage.
Overall, the codebase aligns closely with the paper's described method of multi-channel interleaved autoregressive sequences for simultaneous listening and speaking without auxiliary turn-taking modules.