Pixel-TTS
Pixel-TTS: Image based Text Rendering for Robust Text-to-Speech
Pixel-TTS innovates text-to-speech by rendering text as images, enabling robust and visually grounded embeddings that improve synthesis quality, accelerate training, and enhance zero-shot multilingual generalization without needing embedding matrix expansion.
Links
Paper & demos
Abstract
Recent advances in pixel-based text modeling show that representing text as images enables models to exploit visual cues for language understanding. Grounding text in its visual form allows structurally similar characters with different Unicode encodings to produce similar embeddings, benefiting cross-lingual and zero-shot scenarios. Conventional text-based approaches treat each character independently, limiting generalization to unseen characters and requiring embedding expansion during cross-lingual adaptation. We propose Pixel-TTS, the first framework for visually grounded speech synthesis. It renders text as images and projects them through a 2D convolutional layer to generate embeddings. This design eliminates embedding matrix expansion during fine-tuning while improving robustness to unseen characters and orthographic variations. Extensive experiments show Pixel-TTS achieves competitive performance with strong baselines, faster convergence and robust zero-shot generalization.
Introduction
Pixel-TTS addresses a specific weakness of conventional text-to-speech systems: they typically represent characters as discrete Unicode tokens, which makes adaptation to unseen symbols, orthographic variants, and new languages brittle and often requires embedding-matrix expansion during fine-tuning. The paper proposes replacing the usual text embedding lookup with a visually grounded representation in which text is rendered as images and then projected into embeddings by a 2D convolution. The core motivation is that visually similar characters often share structure even when their Unicode encodings differ, so a pixel-based representation can make these relationships available to the synthesizer directly.
The paper positions Pixel-TTS as the first end-to-end speech synthesis framework based on pixel-level text representations. It builds on ADMA as a strong text-to-speech baseline and keeps the generative backbone and alignment strategy largely intact, while replacing the text front-end with a text-to-image pipeline. The reported goals are threefold: maintain synthesis quality, accelerate convergence, and improve robustness in zero-shot cross-lingual and orthographically noisy settings.
Method
High-level design
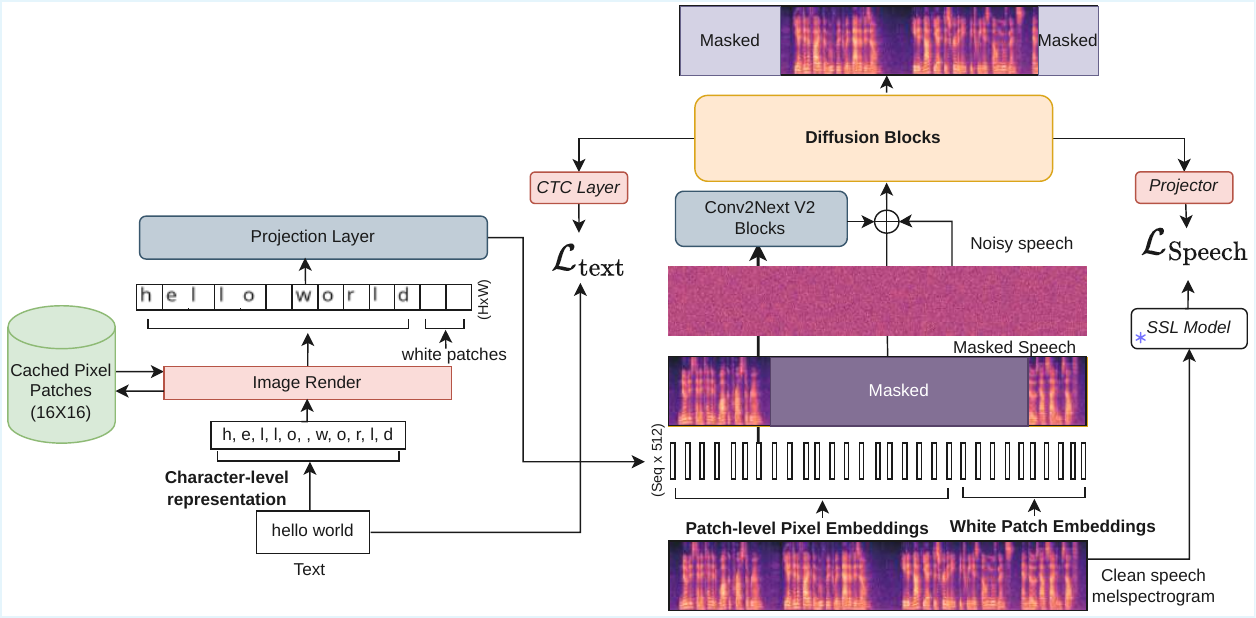
Pixel-TTS extends the ADMA text-to-speech framework with three main components: text-to-image rendering, projection of rendered pixels into text embeddings, and a training objective that combines conditional flow matching with auxiliary text-speech alignment losses. In the paper's formulation, the model preserves the overall ADMA architecture and training procedure, but changes the tokenization and embedding path so that character identity is mediated by visual appearance rather than by a learned token table.
Text-to-image rendering
The input text is represented at the character level, following the alignment style of F5-TTS. Each character is rendered as a fixed $16 \times 16$ grayscale patch, following the PIXEL framework. To preserve monotonic alignment with the acoustic sequence, white $16 \times 16$ patches are used as filler tokens when needed. The number of patches is matched to the target acoustic frame length through padding or truncation. All patches are stacked along the width dimension to form an image $X \in \mathbb{R}^{H \times W}$ with $H = 16$, and the character patches are pre-computed and cached to reduce training overhead.
This design is central to the paper's claim of improved robustness: since the model sees the rendered glyph rather than a discrete symbol ID, visually related characters can induce similar internal representations even if they are orthographically distinct in Unicode.
Projection from pixels to embeddings
The rendered image $X$ is projected into a sequence of embeddings with a 2D convolutional layer. The convolution uses $1$ input channel, $512$ output channels, a $16 \times 16$ kernel, and $16 \times 16$ stride. This maps each character patch to one embedding vector, giving an embedding sequence $E \in \mathbb{R}^{\text{seq} \times 512}$ where $\text{seq} = W / 16$ matches the temporal resolution of the mel-spectrogram.
After this projection, the embeddings are processed by four stacked ConvNeXtV2 blocks at fixed width $512$. The paper argues that this stage lets the model learn visually grounded character features while remaining compatible with the rest of the text-to-speech backbone. Importantly, because the character representation is generated from pixels, Pixel-TTS avoids the need to expand a character embedding matrix during cross-lingual fine-tuning.
Training objective
Pixel-TTS uses conditional flow matching as the main generative objective, following F5-TTS. The flow-matching loss learns a time-dependent vector field that transports Gaussian noise toward the target speech distribution through continuous-time flow integration. In Pixel-TTS, that loss is conditioned on the pixel-derived text embeddings.
Following ADMA, the model also includes two alignment terms. First, a CTC-based text alignment loss is applied at an intermediate layer to encourage early character-level correspondence. Second, a speech representation alignment loss uses HuBERT features extracted from the 21st transformer layer on $16$ kHz waveforms, optimized through cosine similarity. The full objective is
$$ \mathcal{L} = \mathcal{L}_{\mathrm{CFM}} + \lambda_{\text{text}}\mathcal{L}_{\text{text}} + \lambda_{\text{speech}}\mathcal{L}_{\text{speech}}, $$
with $\lambda_{\text{text}} = 0.1$ and $\lambda_{\text{speech}} = 1.0$. In the paper's interpretation, this combination preserves high-quality generation while improving alignment between rendered text and speech.
Training setup
The model follows the original ADMA implementation in its small configuration, with approximately $159$M parameters, $18$ Transformer layers, $12$ attention heads, and hidden size $768$. Waveform synthesis is performed with the pre-trained Vocos vocoder, which was trained on LibriTTS for $1.2$M steps.
Optimization uses AdamW with learning rate $7.5 \times 10^{-5}$, $20$k warmup steps, and linear decay afterward. Experiments are run on $8$ NVIDIA A100 GPUs. Audio is processed at $24$ kHz. Mel-spectrograms use a $1024$-sample window, $256$-sample hop, and $100$ mel bins. For evaluation, the paper reports word error rate (WER), character error rate (CER), speaker similarity (SIM), and UTMOS as proxies for intelligibility, speaker preservation, and naturalness.
Datasets and evaluation protocol
The training corpus is LibriTTS, a $585$-hour multi-speaker English dataset derived from LibriSpeech and sampled at $24$ kHz. The main evaluation protocol follows F5-TTS and uses the LibriSpeech-PC test set, which contains $2.2$ hours and $1{,}127$ utterances of length $4$ to $10$ seconds. Evaluation is done in a cross-sentence generation setting where prompt and reference come from the same speaker.
For zero-shot cross-lingual evaluation, the paper tests on German, French, and Dutch from Common Voice, all of which were unseen during training. The authors emphasize that these languages are Latin-script but contain out-of-vocabulary characters relative to the LibriTTS vocabulary, including diacritics, umlauts, and numerals. For low-resource adaptation, they also fine-tune on German Common Voice subsets of $10$ hours and $50$ hours.
| Setting | Lang | Hrs | LibriTTS vocab | Unique OOV | Total OOV | Total chars | OOV (%) |
|---|---|---|---|---|---|---|---|
| Zero-shot test set | German | 24.97 | 75 | 25 | 3959 | 83411 | 4.75 |
| French | 23.39 | 75 | 39 | 2769 | 73058 | 3.79 | |
| Dutch | 13.15 | 75 | 17 | 250 | 44148 | 0.56 | |
| German fine-tuning | DE-10h | 10 | 75 | 23 | 5938 | 427331 | 1.39 |
| DE-50h | 50 | 75 | 51 | 29760 | 2136559 | 1.39 |
Quantitative results on LibriSpeech-PC
The paper first tracks convergence on LibriSpeech-PC over training updates. Pixel-TTS is not uniformly better at the very earliest stage: at $40$k updates, Text-TTS has lower WER and CER. However, by $60$k updates Pixel-TTS is already competitive, and by $120$k updates it is clearly ahead on intelligibility. At $300$k updates, Pixel-TTS achieves lower WER and CER than Text-TTS while retaining similar SIM and UTMOS. The authors interpret this as evidence that pixel-level character similarity leads to faster convergence and better final recognition quality.
| Updates (K) | Text-TTS | Pixel-TTS | ||||||
|---|---|---|---|---|---|---|---|---|
| WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | |
| Ground truth | 2.47 | 0.695 | 4.098 | 0.93 | 2.47 | 0.695 | 4.098 | 0.93 |
| 40 | 37.45 | 0.353 | 2.927 | 26.29 | 63.89 | 0.322 | 2.830 | 44.83 |
| 60 | 21.95 | 0.458 | 3.507 | 15.02 | 22.01 | 0.472 | 3.672 | 14.80 |
| 120 | 7.43 | 0.548 | 3.945 | 4.71 | 5.68 | 0.558 | 3.967 | 3.40 |
| 180 | 3.76 | 0.571 | 3.999 | 1.92 | 3.28 | 0.573 | 3.995 | 1.53 |
| 240 | 2.84 | 0.582 | 4.020 | 1.33 | 2.53 | 0.583 | 4.018 | 0.98 |
| 300 | 2.53 | 0.591 | 4.061 | 1.16 | 2.28 | 0.579 | 4.013 | 0.81 |
At $300$k updates, the paper reports WER $2.53$ versus $2.28$ and CER $1.16$ versus $0.81$ for Text-TTS and Pixel-TTS, respectively. SIM and UTMOS are close: Text-TTS reaches $0.591$ SIM and $4.061$ UTMOS, while Pixel-TTS reaches $0.579$ SIM and $4.013$ UTMOS. The main takeaway is that the pixel-based front-end improves linguistic accuracy without a noticeable degradation in speech quality metrics.
Zero-shot cross-lingual evaluation
The zero-shot experiments are the strongest evidence for the paper's central claim. Pixel-TTS is evaluated on German, French, and Dutch using only the English-trained LibriTTS model. The paper reports that conventional Text-TTS tends to treat unseen characters as filler tokens, whereas Pixel-TTS renders them directly and therefore does not require character-vocabulary expansion.
| Language | Ground truth | Text-TTS | Pixel-TTS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | |
| German | 6.21 | - | 2.481 | 2.18 | 71.49 | 0.481 | 3.290 | 31.50 | 66.48 | 0.481 | 3.303 | 27.36 |
| French | 12.35 | - | 2.238 | 5.39 | 63.95 | 0.411 | 3.217 | 31.71 | 62.56 | 0.400 | 3.233 | 29.57 |
| Dutch | 4.67 | - | 2.612 | 1.60 | 47.14 | 0.469 | 3.460 | 18.58 | 44.30 | 0.462 | 3.472 | 16.41 |
Across all three languages, Pixel-TTS reduces WER and CER relative to Text-TTS. The absolute gains are modest in WER but more consistent in CER, and UTMOS is similar or slightly better for Pixel-TTS. German shows the clearest CER improvement, with $27.36$ versus $31.50$; French improves from $31.71$ to $29.57$; Dutch improves from $18.58$ to $16.41$. The paper also reports that SIM is not computed for ground-truth audio because speaker information is unavailable in that setting.
Low-resource fine-tuning on German Common Voice
To test adaptation efficiency, the authors fine-tune both models from the $300$k checkpoint on German Common Voice subsets of $10$ hours and $50$ hours using learning rate $7.5 \times 10^{-6}$. For Text-TTS, the embedding matrix must be expanded to accommodate new German characters and numeric symbols not seen in LibriTTS. The paper states that the original LibriTTS vocabulary has $75$ characters, which expands to $98$ for DE-10h and $126$ for DE-50h. New embeddings are initialized as the average of existing embeddings and then learned from scratch. Pixel-TTS does not need this expansion because each character is rendered visually.
The reported results show that Pixel-TTS adapts faster and consistently attains lower WER and CER than Text-TTS. The two systems are much closer in SIM and UTMOS, suggesting that the main advantage of Pixel-TTS is stronger lexical accuracy and faster adaptation rather than a radical shift in the acoustic quality of the generated speech.
| Language | Updates (K) | Text-TTS | Pixel-TTS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | WER ↓ | SIM ↑ | UTMOS ↑ | CER ↓ | ||
| DE-10h | 10 | 125.00 | 0.361 | 2.347 | 88.70 | 61.02 | 0.512 | 3.268 | 24.87 |
| 30 | 115.79 | 0.485 | 2.520 | 83.04 | 38.54 | 0.582 | 3.211 | 15.61 | |
| 50 | 100.88 | 0.558 | 2.743 | 65.26 | 24.03 | 0.601 | 3.123 | 9.14 | |
| 70 | 50.63 | 0.592 | 2.943 | 27.45 | 16.67 | 0.601 | 3.053 | 6.42 | |
| 90 | 27.28 | 0.595 | 2.993 | 13.47 | 12.66 | 0.596 | 3.008 | 4.84 | |
| 110 | 20.45 | 0.590 | 2.994 | 9.94 | 10.83 | 0.589 | 2.984 | 4.20 | |
| 130 | 18.13 | 0.581 | 2.982 | 8.81 | 10.02 | 0.581 | 2.965 | 3.95 | |
| 150 | 17.22 | 0.571 | 2.983 | 8.54 | 9.85 | 0.571 | 2.952 | 4.00 | |
| DE-50h | 10 | 125.13 | 0.360 | 2.355 | 88.74 | 60.85 | 0.513 | 3.273 | 24.85 |
| 30 | 114.07 | 0.478 | 2.515 | 82.40 | 38.81 | 0.583 | 3.215 | 15.47 | |
| 50 | 97.52 | 0.561 | 2.744 | 63.02 | 23.96 | 0.605 | 3.114 | 9.62 | |
| 70 | 44.46 | 0.602 | 2.943 | 23.54 | 16.76 | 0.609 | 3.032 | 6.70 | |
| 90 | 23.17 | 0.609 | 2.976 | 11.25 | 12.70 | 0.610 | 2.990 | 5.05 | |
| 110 | 16.92 | 0.610 | 2.972 | 8.00 | 10.88 | 0.609 | 2.955 | 4.26 | |
| 130 | 14.40 | 0.610 | 2.963 | 6.82 | 9.79 | 0.608 | 2.933 | 3.86 | |
| 150 | 12.87 | 0.609 | 2.966 | 5.99 | 9.42 | 0.606 | 2.920 | 3.62 | |
The table shows a large gap early in fine-tuning. At $10$k updates on DE-10h, Text-TTS has WER $125.00$ and CER $88.70$, while Pixel-TTS already reaches WER $61.02$ and CER $24.87$. By $150$k updates the gap narrows, but Pixel-TTS still remains better on both WER and CER for both data regimes. The paper's conclusion is that pixel-level input reduces the cost of adapting to new orthography and accelerates convergence in low-resource settings.
Robustness to orthographic noise
The paper evaluates robustness on LibriSpeech-PC under two character-level perturbation types: Unicode homoglyph substitutions and l33tspeak transformations. Corruption probabilities range from $0.1$ to $1.0$. The results are summarized visually in the paper's figures and numerically in the text. The main message is that Pixel-TTS degrades more gracefully than Text-TTS because it reasons over rendered glyph shape rather than a fixed symbol inventory.

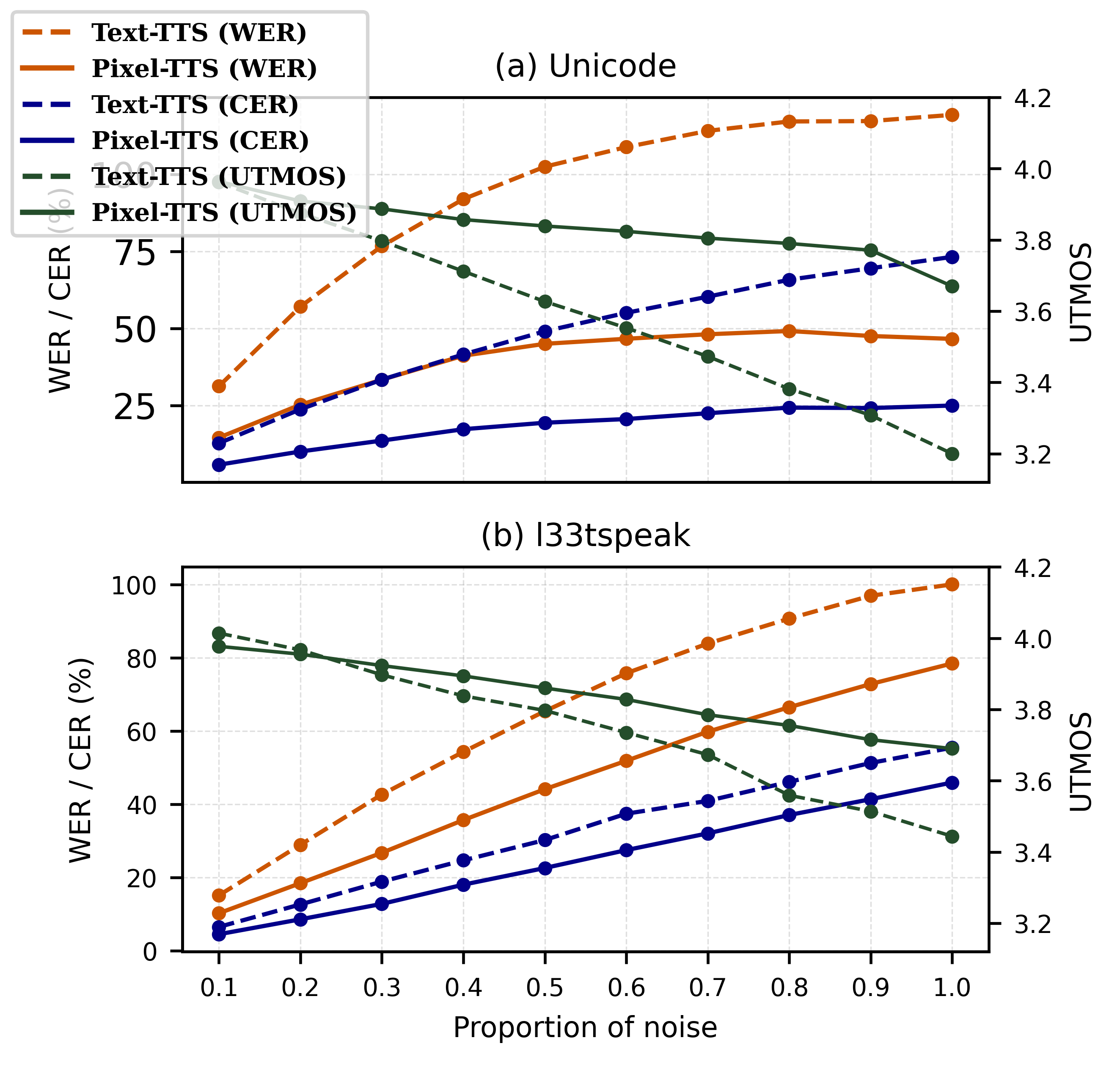
For Unicode homoglyph noise, Text-TTS degrades sharply from WER $31.21$ to $119.25$ and UTMOS from $3.962$ to $3.20$, while Pixel-TTS changes from WER $14.55$ to $46.57$ and UTMOS from $3.964$ to $3.670$. For l33tspeak noise, Text-TTS ranges from WER $15.1$ to $100.04$ and UTMOS from $4.014$ to $3.444$, whereas Pixel-TTS ranges from WER $10.21$ to $78.44$ and UTMOS from $3.977$ to $3.690$. These results support the claim that visual grounding makes the front-end more tolerant of character-level corruption.
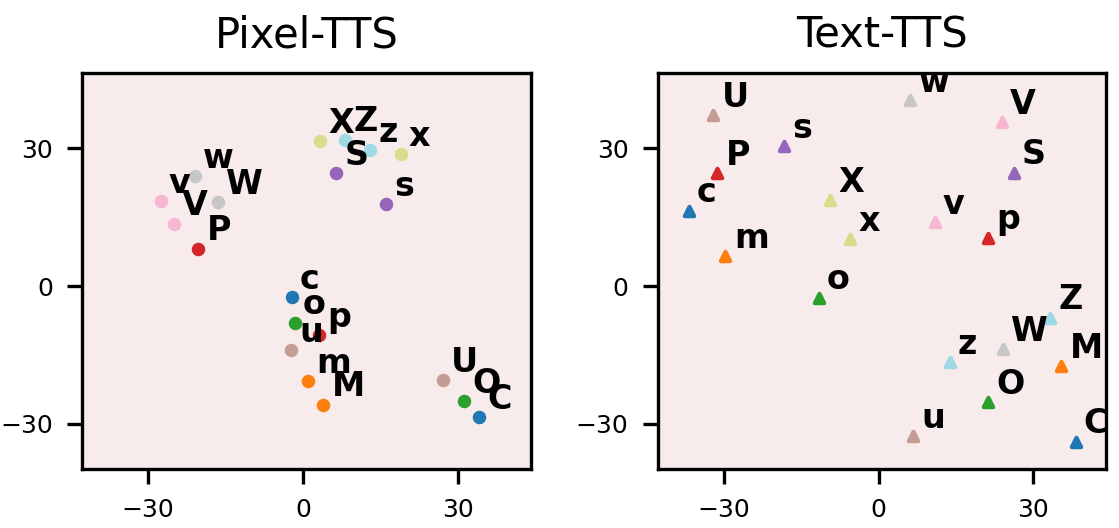
Visual evidence from embedding space
The authors also inspect character embeddings with t-SNE at the $60$k-update checkpoint. The resulting visualization shows tighter clusters for visually similar characters in Pixel-TTS than in Text-TTS. Examples cited in the paper include pairs and groups such as $c/C$, $m/M$, $o/O$, $p/P$, $s/S$, $u/U$, $v/V$, $w/W$, $x/X$, and $z/Z$. The interpretation is that pixel-level projection naturally encodes glyph structure, which in turn helps the model share statistical strength across related characters.
What is novel in this paper
- Visual text grounding for TTS: the model renders text as images and learns embeddings from pixels rather than from a learned token table.
- Compatibility with a strong TTS backbone: the method is not a new vocoder or a new generative paradigm; it keeps the ADMA-style backbone and replaces the front-end representation.
- No embedding expansion during adaptation: cross-lingual and low-resource fine-tuning do not require extending the text vocabulary, unlike the text-based baseline.
- Robustness to unseen characters and noise: the approach is explicitly tested on zero-shot Latin-script languages and synthetic orthographic corruption.
- Faster convergence: the paper reports that Pixel-TTS catches up earlier during training and adapts more quickly in German fine-tuning.
Limitations and future work
The paper does not include a separate limitations section, but its own discussion implies several scope boundaries. The evaluation is centered on English training data, zero-shot transfer to three Latin-script languages, and German fine-tuning, so broader multilingual coverage remains untested. The model also relies on rendering each character into a fixed $16 \times 16$ patch and stacking patches to match acoustic frame timing, which ties the representation to a specific visual encoding and alignment strategy. The concluding future-work statement is to extend Pixel-TTS toward fully multilingual speech synthesis.
Conclusion
Pixel-TTS demonstrates that pixel-level text representation is a viable front-end for text-to-speech. By rendering characters as images and learning embeddings with a 2D convolution, the model can exploit visual similarity between glyphs, avoid embedding expansion, and improve robustness to unseen characters and orthographic perturbations. On LibriSpeech-PC it matches or exceeds the text-based baseline in intelligibility after sufficient training; in zero-shot cross-lingual tests it reduces WER and CER across German, French, and Dutch; and in German low-resource fine-tuning it adapts faster and more reliably than the baseline. The paper's central contribution is therefore not a wholesale redesign of TTS, but a carefully targeted shift in how text enters the system.