Latent-Conditioned Emotional TTS
An Empirical Study on Learning Latent Representations for Emotional Speech Synthesis
This work presents a system for emotional speech synthesis in Vietnamese, extending FastSpeech 2 with latent emotion and speaker embeddings plus a prosody bottleneck. It emphasizes emotional control and speaker adaptation on limited, noisy datasets through careful preprocessing.
Links
Paper & demos
Impact
Abstract
For the last couple of years, the field of speech synthesis has improved dramatically thanks to deep learning. There are more and more deep learning-based TTS systems developed to make it possible to produce voices with high intelligibility and naturalness. Meanwhile, controlling the expressiveness is yet a big deal, generating speech in different styles or manners has received a lot of attention from community recently. This paper aims to give our solutions to deal with the task emotional speech synthesis (ESS) at VLSP 2022 which allows to generate humanlike natural-sounding voice from a given input text with desired emotional expression. By integrating speaker embedding, prosody bottleneck into FastSpeech 2, our systems can promisingly generate emotional speech of a single speaker (Sub-task 1), transfer speaking styles from another speaker to the target speaker with neutral non-expressive data while retaining the target speaker's identity (Sub-task 2).
Introduction and paper scope
This paper reports a system description and empirical study for the VLSP 2022 emotional speech synthesis (ESS) task. The goal is to generate natural-sounding Vietnamese speech with a desired emotional expression, using only the datasets provided by the organizers. The authors position ESS as a controllability problem in modern text-to-speech (TTS): while deep learning has improved intelligibility and naturalness, controlling expressiveness remains difficult because emotional and stylistic variation is entangled with content, speaker identity, and prosody.
The paper addresses two related sub-tasks:
- Sub-task 1: synthesize emotional speech for a single speaker given emotional training data.
- Sub-task 2: transfer emotional style to a target speaker whose own training data are neutral/non-expressive, while preserving that speaker’s identity.
The core modeling choice is to extend FastSpeech 2 with explicit latent embeddings for emotion, and for speaker adaptation also with speaker embeddings and a prosody bottleneck inspired by prior work on cross-speaker prosody transfer. The paper’s stated emphasis is empirical: it evaluates a straightforward, self-contained system built from standard components rather than proposing a new TTS backbone or a new training objective.
Problem formulation and system overview
The system takes a phone sequence as input and produces a log-mel spectrogram, which is then converted to waveform by a neural vocoder. Like standard FastSpeech 2 pipelines, the model relies on phoneme duration supervision extracted by forced alignment. The paper does not introduce a new objective function; instead, it modifies the conditioning signals injected into the FastSpeech 2 encoder-side representations.
The overall design is intentionally simple:
- Use FastSpeech 2 as the acoustic model because it is non-autoregressive, fast, and supports controllable pitch, energy, and duration.
- Represent emotion with a learned lookup-table embedding.
- For speaker adaptation, combine speaker identity and emotion information before decoding.
- Use a pre-trained HiFi-GAN vocoder to synthesize the final waveform from the predicted mel-spectrogram.
The paper’s novelty is therefore not a novel architecture family, but a targeted adaptation of latent representation learning ideas to a low-resource Vietnamese ESS benchmark, together with a concrete preprocessing pipeline for noisy, partially mislabeled data.
Data preprocessing
A notable part of the paper is the preprocessing of the provided datasets, especially VLSP-EMO. The authors report that the raw emotional data were collected from films and interviews and contained substantial quality issues: background noise, background music, room reverberation, overlapping speech from other people, and even inconsistent voices for the same speaker due to recording conditions.
To improve signal quality, they applied Facebook Denoiser, described as an encoder-decoder architecture with skip connections that removes background noise and reverberation. They also cleaned the transcripts in several ways:
- Fixed typos in the provided text.
- Split English words into Vietnamese-like syllabic pronunciations when appropriate, for example converting “me too” to “mi tu” and “resort” to “ri sọt”.
- Used an ASR system to re-transcribe audio, compared ASR output with the ground-truth transcript using character error rate (CER), and filtered or corrected labels with high CER.
- Resampled all audio to 22,050 Hz.
- Removed utterances considered unintelligible.
This preprocessing stage is important because the reported results are based on the cleaned data, not the raw release. In effect, the paper frames data cleansing as a prerequisite for making latent-emotion modeling work on a noisy task set.
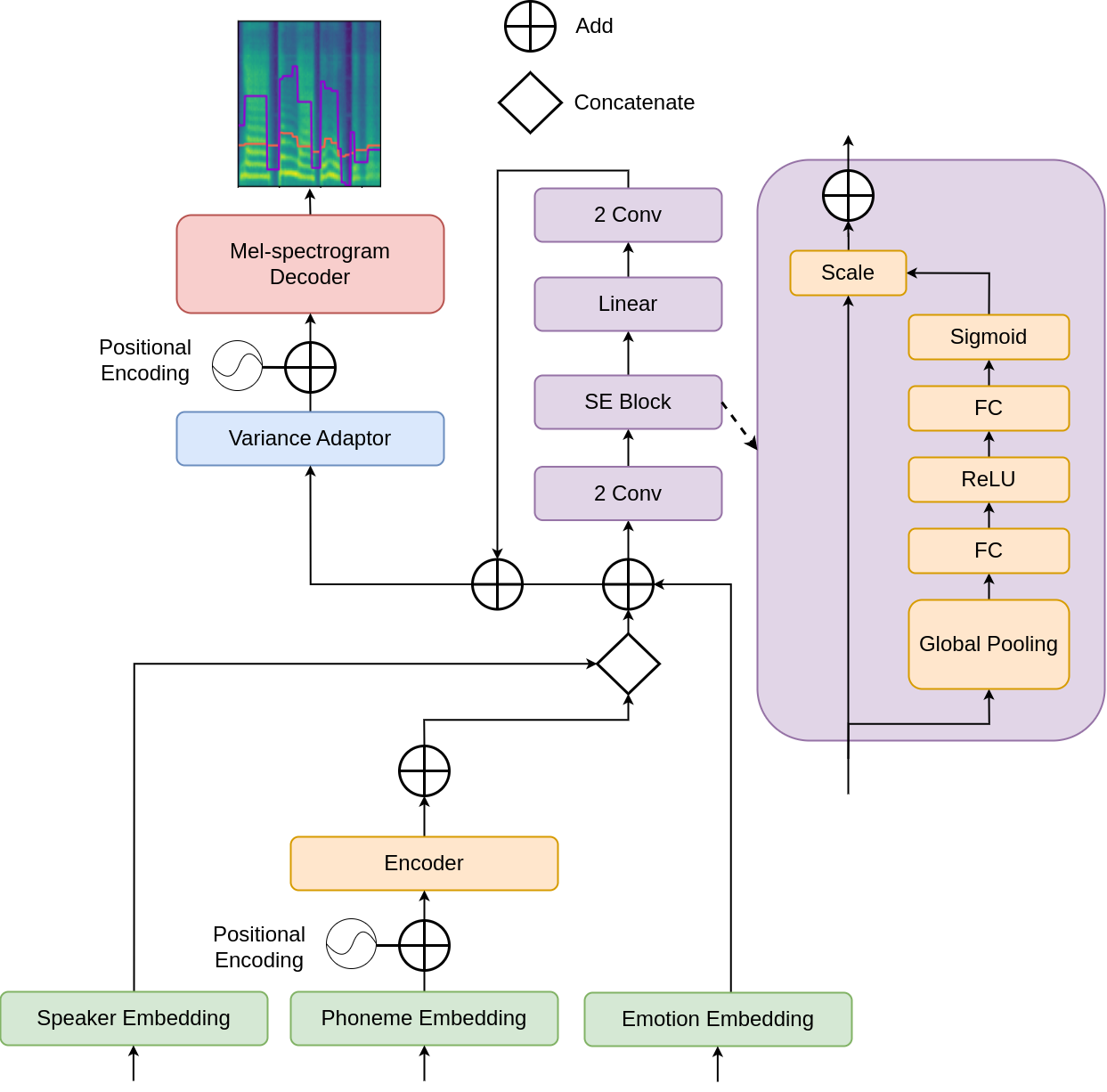
Model architecture
Both sub-tasks use a modified FastSpeech 2 backbone. The model maps an input sequence of phones to a mel-spectrogram in the log-mel scale. The authors use Montreal Forced Aligner to obtain phoneme durations for training, following the standard FastSpeech 2 training recipe. For waveform generation, they use a pre-trained HiFi-GAN V1 vocoder.
Sub-task 1: single-speaker emotional speech synthesis
For the single-speaker setting, the modification to FastSpeech 2 is minimal: the model adds an emotion embedding implemented as a learned lookup table mapping an emotion ID to a fixed-length vector. This vector is broadcast-added to the encoder output. The resulting emotion-conditioned representation is then passed through the rest of the FastSpeech 2 stack to predict the emotional mel-spectrogram.
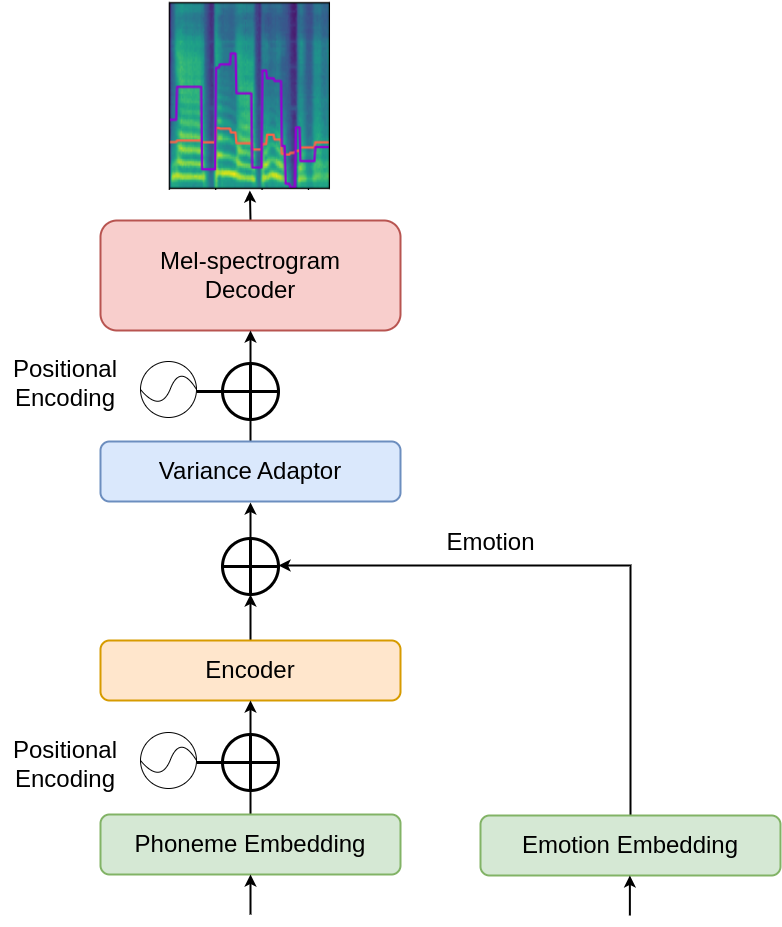
Conceptually, this is a direct conditioning approach: rather than altering the duration, pitch, or energy predictors separately, emotion information is injected into the encoder representation so that downstream modules can learn to render the style in all acoustic outputs jointly.
Sub-task 2: emotional speech synthesis with speaker adaptation
The second setting is more complex because the target speaker has only neutral, non-expressive data. The authors therefore augment FastSpeech 2 with both speaker embeddings and emotion embeddings, and they add a prosody bottleneck to encourage style transfer while preserving speaker identity.
The described computation proceeds as follows:
- The speaker embedding is broadcast-concatenated with the encoder output.
- The concatenated representation is projected back to the original hidden dimension.
- The emotion embedding is passed through a linear layer with $ \tanh$ activation so that it matches the encoder dimensionality.
- The transformed emotion vector is added to the speaker-conditioned encoder output.
- This combined representation, called the speaker-emotion-combined encoder output in the paper, is passed through a prosody bottleneck.
- The bottleneck output is added back to the combined encoder output through a residual connection.
- The resulting representation is fed into the variance adaptor and then the decoder to produce the target mel-spectrogram.
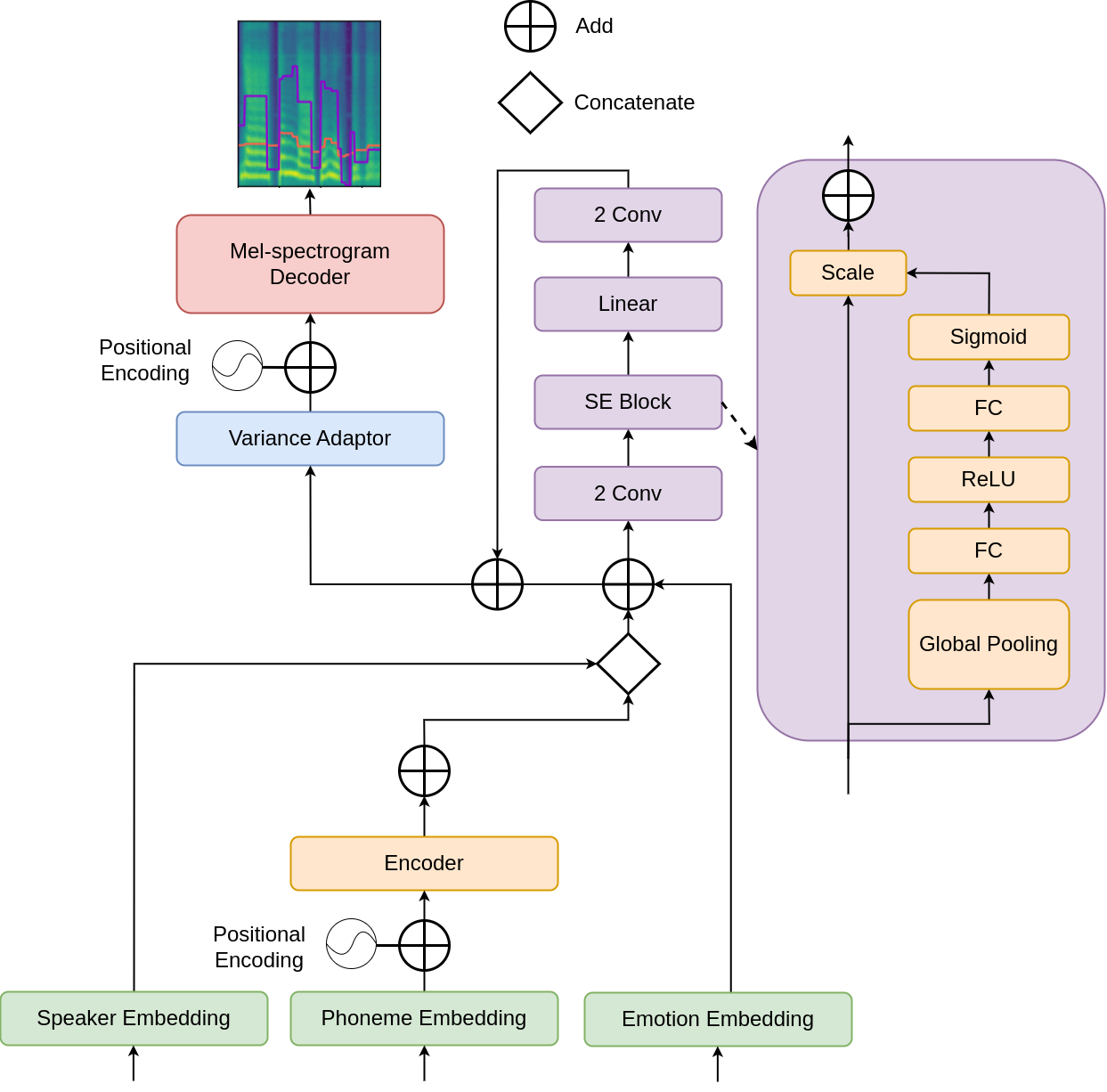
The authors’ stated rationale for the prosody bottleneck is that it should retain emotional information useful for transferring style from a source speaker to the target speaker without losing the target speaker’s timbre. In other words, speaker identity and expressive prosody are meant to be partially disentangled, but not at the cost of eliminating the desired emotion.
Training setup
The paper reports a single shared training configuration for both sub-tasks. The modified FastSpeech 2 model is trained from scratch for 40,000 steps with a batch size of 16. Optimization uses Adam with parameters $\beta_1 = 0.9$, $\beta_2 = 0.98$, and $\epsilon = 10^{-9}$.
The learning-rate schedule uses 3,000 warm-up steps, followed by annealing at milestone steps 5,000, 9,000, and 17,000 with a decay rate of 0.3. The authors report that the usable models were obtained in roughly one hour for sub-task 1 and more than three hours for sub-task 2 on a single NVIDIA GeForce RTX 2080 Ti GPU.
No explicit loss decomposition, auxiliary regularizers, or architectural ablations are reported in the paper. The text also does not describe any external data usage; the systems are trained only on the provided VLSP datasets.
Datasets and experimental protocol
The experiments use only the two organizer-provided datasets, as required by the task rules:
- VLSP-EMO: emotional speech data.
- VLSP-NEU: neutral speech data.
After preprocessing, the authors report 3.8 hours of speech audio for VLSP-EMO and 11.89 hours for VLSP-NEU. The training data composition differs by sub-task:
- Sub-task 1: all VLSP-EMO data are used for training.
- Sub-task 2: VLSP-EMO and VLSP-NEU are combined into one larger dataset for training.
The paper does not report a validation split, test split construction, or a held-out ablation protocol in the body text. The reported numbers are the organizers’ announced evaluation results.
Results
The paper reports the following evaluation metrics from the VLSP 2022 organizers. For naturalness, the task uses MOS on a 5-point scale. For intelligibility, it reports syllable error rate (SUS). For sub-task 2, it also reports a speaker similarity score on a 4-point scale.
| Sub-task | Naturalness (MOS, /5) | Intelligibility (Syllable Error Rate) | Speaker Similarity |
|---|---|---|---|
| Sub-task 1 | 2.719 | 72.40% | Not reported |
| Sub-task 2 | 1.622 | 64.80% | 1.543 / 4 |
These results suggest that the simpler single-speaker emotional setup performed better on naturalness than the speaker-adaptation setup, while sub-task 2 achieved somewhat better syllable accuracy and a non-trivial speaker-similarity score. The paper does not provide a comparison against external baselines, so the results should be interpreted as absolute task scores rather than relative improvements.
What the paper contributes
The paper’s contribution is best understood as a practical system report rather than a new theoretical method. Its main contributions are:
- A FastSpeech 2-based ESS system for Vietnamese emotional speech generation.
- A simple emotion-conditioning strategy using learned lookup embeddings for the single-speaker task.
- A speaker-adaptive extension that combines speaker embedding, emotion embedding, and a prosody bottleneck for style transfer.
- A detailed preprocessing pipeline for noisy emotional speech data, including denoising, transcript cleanup, ASR-based filtering, and resampling.
- Empirical results on the VLSP 2022 benchmark under the organizer’s evaluation protocol.
The framing of the paper is aligned with latent representation learning for expressive speech: emotion and speaker factors are injected as discrete embeddings, and the prosody bottleneck is used to encourage a more disentangled representation of style-related information.
Limitations and caveats
Several limitations are implicit in the paper text and should be kept in mind when reusing the approach:
- No ablation studies are reported. The paper does not isolate the effect of denoising, transcript correction, emotion embeddings, speaker embeddings, or the prosody bottleneck.
- No baseline comparison table is provided. The reported metrics are organizer-announced scores, not paired comparisons to other systems in the paper body.
- Limited training data. Even after preprocessing, the emotional dataset is only 3.8 hours, which is small for expressive TTS.
- Data quality issues. The authors explicitly note noise, music, overlapping speech, mislabeled utterances, and inconsistent voice conditions in the raw emotional corpus.
- Task-specific supervision. The approach depends on emotion IDs and speaker IDs, so it is not a fully unsupervised style-discovery method.
- Evaluation detail is sparse. The paper does not discuss listening-test procedures beyond the organizer-reported MOS, SUS, and similarity scores.
In short, the paper demonstrates that a relatively standard FastSpeech 2 pipeline can be adapted to Vietnamese ESS with explicit latent conditioning, but the reported evidence is limited to one benchmark and does not establish broader generalization.
Conclusion
The paper concludes that latent embedding spaces are a promising way to control emotional expressiveness in TTS. By combining emotion embeddings, speaker embeddings, and a prosody bottleneck within FastSpeech 2, the authors obtain systems that can generate emotional speech for a single speaker and transfer style to a target speaker with neutral data. Their final takeaway is that the approach is straightforward to adapt to other languages without external sources, and they propose extending the same latent-representation idea to multilingual and adaptive speech synthesis in future work.