DuraMark
DuraMark: Duration-Embedded Watermarking in LLM-based TTS
DuraMark introduces a novel watermarking method for LLM-based text-to-speech by embedding information in the syllable duration rather than the audio signal. This duration-level watermarking offers superior robustness against neural codec and vocoder attacks compared to traditional signal-level techniques.
Demos
These demos demonstrate DuraMark's approach to speech watermarking by embedding watermarks via syllable duration editing in synthesized speech. Evaluate the naturalness of speech and the robustness of watermark extraction against generative attacks, highlighting DuraMark's advantage over signal-level baselines. Architecture images illustrate the duration-controllable TTS and duration extractor modules central to watermark embedding and detection.
Links
Paper & demos
Impact
Abstract
Large language model (LLM)-based text-to-speech (TTS) models have achieved remarkable voice cloning capabilities, raising concerns about potential deepfake misuse. Speech watermarking mitigates this by embedding traceable information into generated speech. Mainstream watermarking methods operate at the signal level (waveform or spectrogram), rendering the watermark vulnerable to generative attacks (e.g., neural codec and vocoder). To address this, we propose DuraMark, a robust information-level watermarking framework. It utilizes syllable duration editing to achieve watermark embedding. Specifically, DuraMark integrates a duration-controllable LLM-based TTS model to edit syllable durations during synthesis, coupled with a duration extractor to extract these durations for detection. Experiments demonstrate DuraMark's superior robustness against generative attacks, significantly outperforming signal-level baselines. Audio samples are available at https://muzw.github.io/duramark_demo/.
Overview
DuraMark targets a specific weakness in contemporary speech watermarking for large language model (LLM)-based text-to-speech (TTS): most existing methods embed watermarks directly in the waveform or spectrogram, so the watermark can be erased or heavily degraded by downstream generative resynthesis such as neural codecs and vocoders. The paper’s core idea is to move watermarking from the signal level to the information level by encoding bits into syllable duration rather than acoustic residues.
The method is built around a duration-controllable LLM-based TTS model and a separate duration extractor. At synthesis time, the model predicts a duration for each syllable, the duration is explicitly edited so that its parity encodes a bit ($0$ for even, $1$ for odd), and the edited duration sequence is then used to synthesize speech. At detection time, the extractor estimates syllable durations from the speech and transcription, maps the estimated durations to a common continuous space, and computes a correlation score against the target watermark sequence. If the score exceeds a threshold, the watermark is declared present.
The paper reports that this design is substantially more robust than signal-level baselines under neural codec and vocoder attacks, while preserving speech naturalness close to unwatermarked synthesis. The evaluation is performed in Mandarin Chinese using the CosyVoice framework.
Method
DuraMark consists of three tightly coupled components:
- a duration-controllable LLM-based TTS model that predicts both syllable durations and speech tokens autoregressively;
- a duration extractor that recovers syllable-level duration estimates from speech and text;
- a watermarking layer that edits predicted durations to force an even/odd state corresponding to bits.
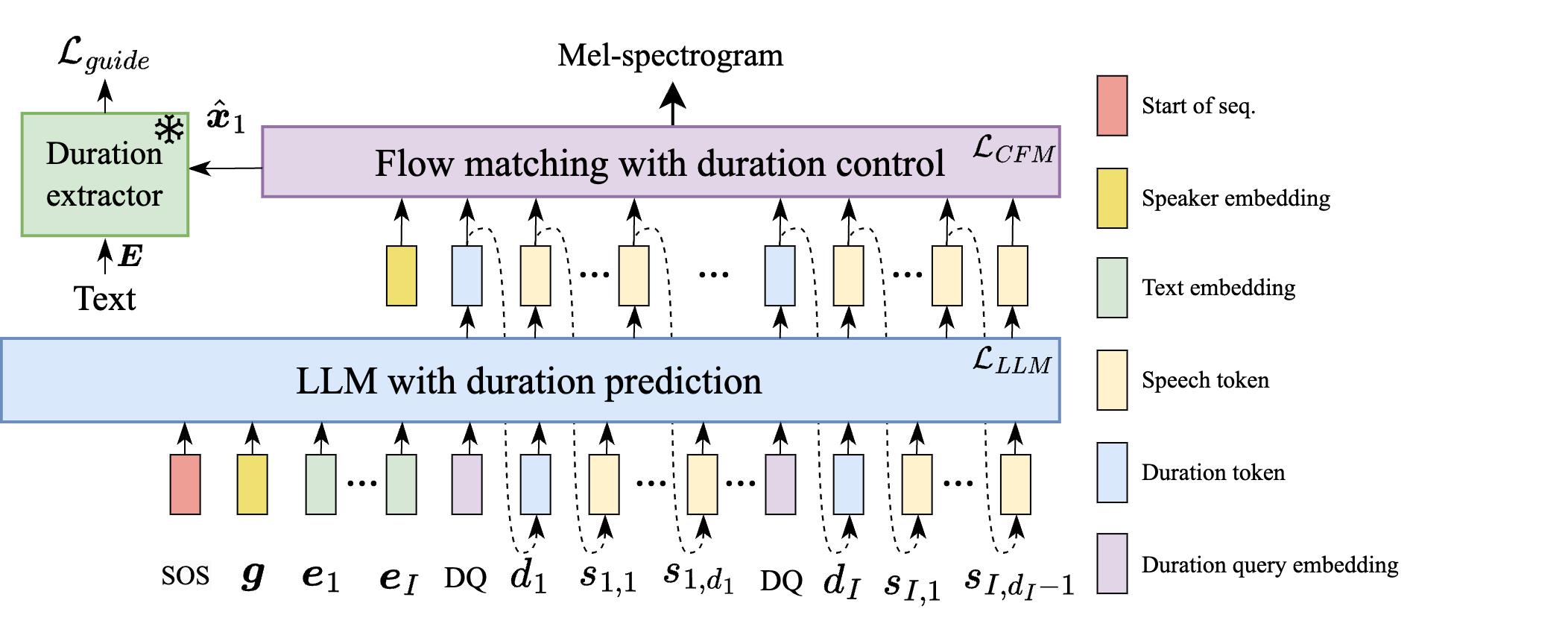
The paper’s overall architecture is shown below.


Duration-controllable LLM-based TTS
Unlike conventional LLM-based TTS that models duration implicitly, DuraMark introduces explicit duration control. Given a syllable-level text embedding sequence $\mathbf{E} = \{\mathbf{e}_1, \dots, \mathbf{e}_I\}$, where $I$ is the number of syllables, the LLM autoregressively predicts a duration token sequence $\mathbf{d} = \{d_1, \dots, d_I\}$ and corresponding speech tokens $\mathbf{S} = \{\mathbf{s}_1, \dots, \mathbf{s}_I\}$. Here, each syllable $i$ has duration $d_i$, and $\mathbf{s}_i$ contains the frame-level tokens for that syllable.
The decoder is a flow-matching model conditioned on speaker embedding $\mathbf{g}$, speech tokens, and duration tokens. During training, the LLM and flow-matching decoder are optimized separately, and the decoder is additionally guided by a frozen duration extractor so that the synthesized speech adheres to the requested durations.
For the LLM, the duration for syllable $i$ is predicted with a duration query token, and speech tokens are generated conditioned on the predicted duration and previously generated history. The paper writes the duration distribution as
$$p\big(\mathcal{C}^{\rm d} \mid \mathbf{g}, \mathbf{E}, d_{1:i-1}, \mathbf{s}_{1:i-1}\big),$$
and the speech-token distribution within syllable $i$ as
$$p\big(\mathcal{C}^{\rm s} \mid \mathbf{g}, \mathbf{E}, d_{1:i}, \mathbf{s}_{1:i-1}, s_{i,1:t-1}\big).$$
The LLM objective is a weighted cross-entropy over duration tokens and speech tokens:
$$\mathcal{L}_{\text{llm}} = -w_{\text{llm}}\frac{1}{I}\sum_{i=1}^{I}\tilde{\mathbf{y}}_i\log \mathbf{y}_i - (1-w_{\text{llm}})\frac{1}{\sum_{i=1}^{I} d_i}\sum_{i=1}^{I}\sum_{t=1}^{d_i}\tilde{\mathbf{z}}_{i,t}\log \mathbf{z}_{i,t},$$
where $w_{\text{llm}} \in [0,1]$ balances the two terms, $\mathbf{y}_i$ is the duration distribution, and $\mathbf{z}_{i,t}$ is the speech-token distribution.
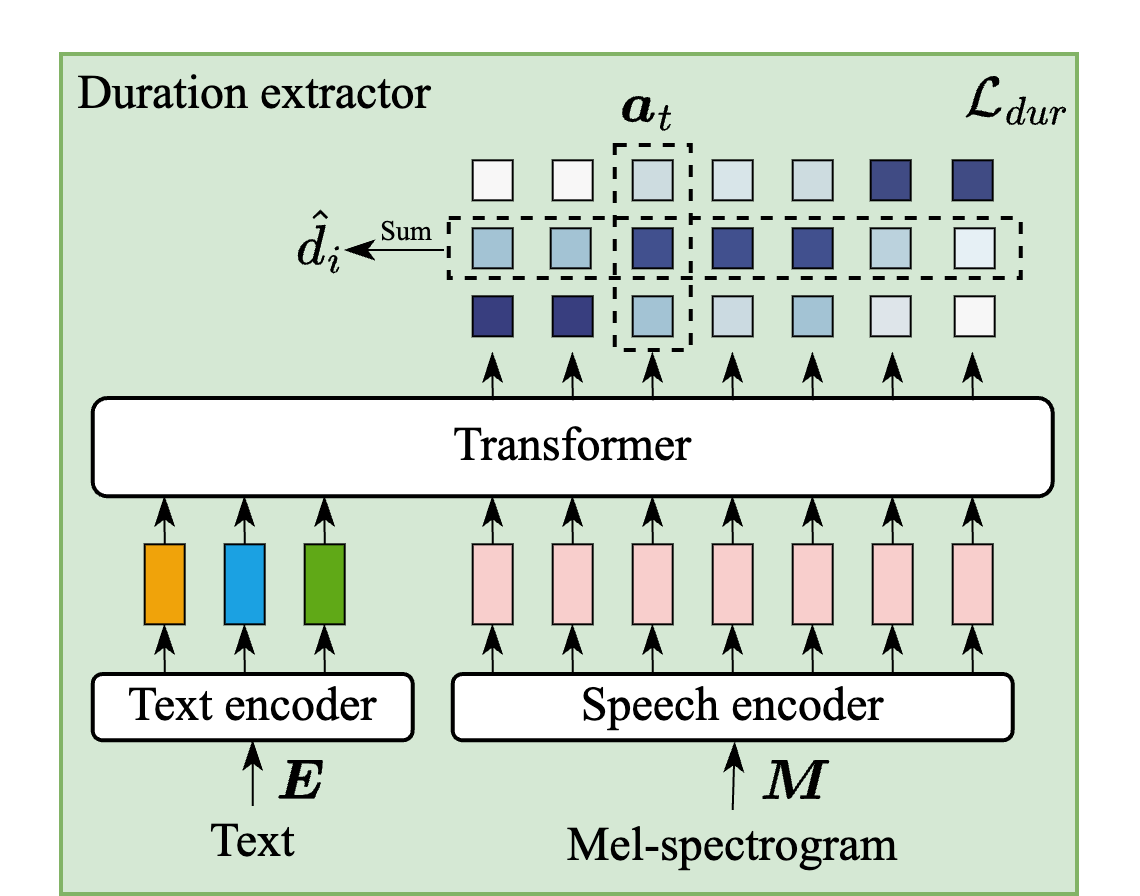
Duration extractor
The duration extractor takes the syllable sequence $\mathbf{E}$ and a Mel-spectrogram $\mathbf{M} = \{\mathbf{m}_1, \dots, \mathbf{m}_T\}$ as input. It concatenates encoded text and Mel features and feeds them through a transformer. For each frame $t$, it outputs a distribution over the input syllables, $\mathbf{a}_t = \{a_{1,t}, \dots, a_{I,t}\}$, where $a_{i,t}$ is the probability that frame $t$ belongs to syllable $i$.
The extractor is trained with frame-level cross-entropy:
$$\mathcal{L}_{\text{dur}}(\tilde{\mathbf{a}}_t, \mathbf{a}_t) = -\frac{1}{T}\sum_{t=1}^{T} \tilde{\mathbf{a}}_t \log \mathbf{a}_t.$$
At inference, the duration estimate for syllable $i$ is the sum of its frame probabilities:
$$\hat{d}_i = \sum_{t=1}^{T} a_{i,t}.$$
This makes the detector operate on extracted syllable-duration counts rather than on raw waveform or spectrogram perturbations.
Flow matching decoder with duration control
The synthesis decoder uses Optimal Transport Conditional Flow Matching (OT-CFM). The paper defines a linear probability flow $\psi_t(\mathbf{x}_0) = (1-t)\mathbf{x}_0 + t\mathbf{x}_1$ that moves from Gaussian noise $\mathbf{x}_0$ to the target Mel-spectrogram $\mathbf{x}_1$, with target vector field $\mathbf{u}_t = \mathbf{x}_1 - \mathbf{x}_0$. A neural vector field $\mathbf{v}_t$ is trained to regress this field conditioned on $\mathbf{c} = \{\mathbf{g}, \mathbf{S}, \mathbf{d}\}$:
$$\mathcal{L}_{\text{CFM}} = \mathbb{E}_{t,\mathbf{x}_0,\mathbf{x}_1}\left[\lVert \mathbf{v}_t(\psi_t(\mathbf{x}_0), t, \mathbf{c}) - (\mathbf{x}_1 - \mathbf{x}_0) \rVert^2\right].$$
To make the decoder obey the requested durations, the paper introduces a duration-guidance loss. A single-step estimate of the output Mel-spectrogram is constructed as
$$\hat{\mathbf{x}}_1 = \psi_t(\mathbf{x}_0) + (1-t)\,\mathbf{v}_t(\psi_t(\mathbf{x}_0), t, \mathbf{c}),$$
which is passed through the frozen duration extractor to obtain predicted duration probabilities. The guidance loss compares those predictions with ground-truth alignments:
$$\mathcal{L}_{\text{guide}} = \mathcal{L}_{\text{dur}}(\tilde{\mathbf{a}}_t, \hat{\mathbf{a}}_t).$$
The final flow objective is a weighted sum:
$$\mathcal{L}_{\text{flow}} = w_{\text{flow}}\mathcal{L}_{\text{CFM}} + (1-w_{\text{flow}})\mathcal{L}_{\text{guide}},$$
where $w_{\text{flow}} \in [0,1]$ balances fidelity to the flow-matching target and adherence to explicit duration control.
Watermark embedding and detection
DuraMark embeds a binary watermark sequence $\mathbf{w} = \{w_1, \dots, w_I\}$ aligned with the syllable sequence. The key encoding rule is simple: each syllable duration is forced into an even state to represent bit $0$ or an odd state to represent bit $1$. The watermark is therefore embedded in the parity pattern of the duration sequence.
In embedding, the model first predicts an initial duration $d_i$ from the LLM distribution for syllable $i$. If the sampled duration already matches the target parity, it is left unchanged. Otherwise, it is edited to $d_i+1$ or $d_i-1$, whichever has higher probability under the duration distribution. The edited duration $d_i^*$ then conditions speech-token generation and final synthesis. This means the watermark is not injected after generation; it is woven into the synthesis process itself.
The detection pipeline first extracts estimated durations $\hat{\mathbf{d}} = \{\hat{d}_1, \dots, \hat{d}_I\}$ from the received speech and its transcription. Because the watermark bits and extracted durations live in different spaces, DuraMark maps both to $[-1,1]$. The watermark bits are mapped as
$$w'_i = 2w_i - 1,$$
and the estimated durations are mapped as
$$d'_i = -\cos(\pi \hat{d}_i).$$
The similarity score is the mean correlation
$$\mathcal{T} = \frac{1}{I}\sum_{i=1}^{I} d'_i w'_i,$$
and watermark presence is decided by thresholding $\mathcal{T}$ against a preset threshold $\tau$.
This design is central to the paper’s argument: because the watermark is represented at the duration level, generative post-processing that reconstructs speech from higher-level representations is less likely to erase it than if the watermark had been encoded in small signal perturbations.
Training and implementation details
The experiments are conducted on Mandarin Chinese, where a character corresponds to a syllable. Training data is derived from WenetSpeech, a 10,000-hour speech corpus. Syllable boundaries are obtained using the Montreal Forced Aligner. Evaluation uses the test set of AISHELL-3, which contains recordings from 214 speakers.
The implementation uses the open-source CosyVoice framework. Models are trained with Adam at learning rate $10^{-5}$ on eight MLU 580 GPUs. The paper states the loss-balancing weights as $\lambda_{\text{llm}} = 1$ and $\lambda_{\text{flow}} = 4$. During inference, speech tokens are sampled with top-$p$ sampling ($p=0.8$) and top-$k$ sampling ($k=25$), while duration tokens are sampled greedily.
For the watermark itself, embedded sequences are randomly generated. The paper evaluates two detection settings:
- DuraMark-Info: informed detection using ground-truth text;
- DuraMark-Blind: blind detection using text transcribed by ASR.
Experimental results
Impact of speech length
The paper first studies how utterance length affects detection. Test samples are grouped by syllable count into $17$--$32$, $33$--$64$, and $65$--$100$ syllables. For each configuration, 1,000 pairs of watermarked and unwatermarked utterances are generated. Performance is measured by TPR at $1.0\%$ FPR. Longer utterances help because they carry a longer watermark sequence and thus more evidence for the correlation test. The authors therefore use the $33$--$64$ syllable regime in later experiments.
| Length (syllables) | DuraMark-Info | DuraMark-Blind |
|---|---|---|
| 17--32 | 0.981 | 0.942 |
| 33--64 | 0.998 | 0.987 |
| 65--100 | 0.998 | 0.992 |
Robustness against attacks
The central empirical claim of the paper is that DuraMark is far more robust than signal-level watermarking under generative attacks. The compared baselines are AudioSeal, Timbre, and WavMark. DuraMark is evaluated in both informed and blind settings. The test suite covers neural codecs, neural vocoders, speech enhancement, lossy compression, and signal processing perturbations.
The paper’s conclusion from the robustness table is consistent across attack families: classical signal processing, compression, and enhancement generally leave all methods relatively stable, but neural codec and vocoder attacks strongly damage the signal-level baselines. DuraMark remains consistently high, with average TPR $0.993$ in informed detection and $0.978$ in blind detection.
| Attack category | Perturbation | Param | AudioSeal | Timbre | WavMark | DuraMark-Info | DuraMark-Blind |
|---|---|---|---|---|---|---|---|
| None | Original | - | 1.000 | 1.000 | 1.000 | 0.998 | 0.987 |
| Neural codecs | EnCodec | 6.0k | 0.773 | 0.124 | 0.015 | 0.991 | 0.968 |
| Neural codecs | EnCodec | 12.0k | 1.000 | 0.551 | 0.010 | 0.994 | 0.970 |
| Neural codecs | DAC | 3.0k | 0.096 | 0.414 | 0.007 | 0.994 | 0.980 |
| Neural codecs | DAC | 4.5k | 0.512 | 0.832 | 0.002 | 0.996 | 0.979 |
| Neural codecs | SpeechTokenizer | 4.0k | 0.004 | 0.047 | 0.017 | 0.984 | 0.966 |
| Neural codecs | FACodec | 2.4k | 0.013 | 0.036 | 0.010 | 0.994 | 0.977 |
| Neural vocoders | BigVGAN | - | 0.908 | 1.000 | 0.012 | 0.997 | 0.987 |
| Neural vocoders | Vocos | - | 0.005 | 1.000 | 0.010 | 0.997 | 0.979 |
| Neural vocoders | HiFiGAN | - | 0.013 | 1.000 | 0.007 | 0.994 | 0.985 |
| Speech enhancement | FRCRN | - | 1.000 | 1.000 | 1.000 | 0.999 | 0.989 |
| Speech enhancement | Demucs | - | 1.000 | 1.000 | 1.000 | 0.998 | 0.983 |
| Lossy compression | MP3 | 32k | 1.000 | 1.000 | 1.000 | 0.998 | 0.983 |
| Lossy compression | Opus | 16k | 0.986 | 1.000 | 0.665 | 0.994 | 0.983 |
| Lossy compression | Quantization | $2^6$ | 1.000 | 1.000 | 0.010 | 0.995 | 0.982 |
| Signal processing | Gaussian noise | 20 dB | 1.000 | 0.999 | 0.050 | 0.994 | 0.979 |
| Signal processing | Background noise | 20 dB | 1.000 | 1.000 | 0.905 | 0.987 | 0.965 |
| Signal processing | Low-pass | 4.8 kHz | 1.000 | 1.000 | 1.000 | 0.973 | 0.961 |
| Signal processing | Smoothing | 18 | 1.000 | 1.000 | 0.945 | 0.995 | 0.978 |
| Average | 0.701 | 0.790 | 0.403 | 0.993 | 0.978 |
The most informative pattern in this table is the gap between generative and non-generative perturbations. Under codec and vocoder attacks, WavMark in particular collapses in many settings, and AudioSeal/Timbre are unstable. By contrast, DuraMark retains high TPR across almost all rows, including the most destructive codec settings such as SpeechTokenizer and FACodec. The blind setting is slightly lower than informed detection, but still remains very strong.
Naturalness
To check whether duration-based watermarking harms speech quality, the paper reports both intelligibility and subjective naturalness. Intelligibility is measured with Whisper character error rate (CER), and naturalness is evaluated using mean opinion score (MOS). Eleven native speakers rate 20 randomly selected sentences.
The key result is that DuraMark is close to the unwatermarked baseline and competitive with the signal-level methods, indicating that embedding watermark bits through duration editing does not produce a large perceptual penalty in the tested setup.
| Method | CER (%) | MOS |
|---|---|---|
| Ground truth | 5.44 | 4.35 ± 0.11 |
| Unwatermarked | 8.73 | 4.05 ± 0.09 |
| AudioSeal | 8.15 | 4.07 ± 0.08 |
| Timbre | 8.56 | 4.03 ± 0.07 |
| WavMark | 9.25 | 3.97 ± 0.08 |
| DuraMark | 8.54 | 4.04 ± 0.07 |
Ablation study
The ablation study isolates the contributions of explicit duration conditioning and duration-guidance training. Two variants are tested: removing duration tokens from the decoder input, and removing the guidance loss $\mathcal{L}_{\text{guide}}$.
Both are crucial. Without duration input, detection performance drops sharply, and removing the guidance loss causes an even larger degradation. This supports the paper’s claim that the decoder must be forced to respect the edited duration sequence; otherwise the intended watermark is weakened or lost.
| Method | Informed | Blind |
|---|---|---|
| DuraMark | 0.998 | 0.987 |
| w/o duration input | 0.455 | 0.473 |
| w/o $\mathcal{L}_{\text{guide}}$ | 0.327 | 0.342 |
Key takeaways
- Information-level watermarking: DuraMark encodes bits in syllable-duration parity rather than in waveform or spectrogram artifacts.
- Robust against generative attacks: The method is designed specifically to withstand neural codec and vocoder resynthesis, where signal-level watermarks often fail.
- Explicit duration control matters: The LLM-based TTS is modified to predict and then obey editable durations, and the extractor-guided loss is essential for reliable embedding.
- Blind detection is practical: Even with ASR-derived transcription, DuraMark maintains high detection rates, though informed detection is stronger.
- Naturalness is preserved: The reported CER and MOS remain close to the unwatermarked system.
Limitations and scope
The paper does not include a dedicated limitations section, but its reported setup makes the scope clear. Evaluation is conducted on Mandarin Chinese, where characters correspond to syllables, so the method is demonstrated in a setting that is naturally compatible with syllable-level control. The implementation is also tied to the CosyVoice framework. As a result, the paper does not directly establish how well the approach transfers to other languages, different phonological units, or non-CosyVoice TTS stacks.
Detection also depends on a syllable sequence derived from transcription. In the blind setting, this sequence comes from ASR, so transcription quality can affect the detector. Finally, the watermarking scheme uses parity-based duration editing, which is elegant and simple, but the paper does not explore alternative bit encodings or capacity beyond the tested syllable-length ranges.
Conclusion
DuraMark reframes speech watermarking for LLM-based TTS as a duration-editing problem rather than a signal perturbation problem. By integrating a duration-controllable TTS model, a duration extractor, and a parity-based embedding rule, the method produces watermarked speech that is much harder to remove through generative resynthesis than signal-level watermarks. The experiments support three main claims: strong robustness under codec/vocoder attacks, competitive naturalness, and the necessity of explicit duration control plus duration-guidance training.