StressPreserve S2ST
Evaluating and Preserving Lexical Stress in English-to-Chinese Speech-to-Speech Translation
This paper improves English-to-Chinese speech translation by preserving lexical stress, which conveys speaker intent. It introduces a Mandarin stress detector and a new metric to evaluate stress transfer, alongside a stress-aware system that enhances emphasis without compromising naturalness or translation quality.
Links
Paper & demos
Impact
Abstract
Speech-to-speech translation (S2ST) systems have achieved impressive progress in semantic accuracy and speech naturalness. However, the cross-lingual transfer of lexical stress, a vital cue for emphasis and speaker intent, remains heavily underexplored, compounded by a lack of reliable automatic evaluation metrics for tonal languages like Chinese. We investigate English-to-Chinese S2ST stress transfer by constructing a stress-annotated Chinese dataset and an XLS-R-based Mandarin stress detector. Integrating this with the English EmphAssess system, we propose a novel objective metric for cross-lingual stress evaluation. Furthermore, we fine-tune CosyVoice3 to build a stress-aware S2ST system. Experiments demonstrate that our proposed S2ST architecture significantly outperforms existing systems in stress translation capability while maintaining competitive translation quality. Furthermore, our evaluation metric exhibits a strong correlation with human subjective judgments.
Introduction
This paper studies a specific but important gap in speech-to-speech translation (S2ST): whether lexical stress, especially English emphasis that conveys speaker intent and pragmatic meaning, can be preserved when translating into Mandarin Chinese. The motivation is that modern S2ST systems have become strong at semantic fidelity and speech naturalness, but stress transfer is still weakly studied. The problem is harder for Chinese than for stress-accent languages because stress interacts with lexical tone and language-specific prosody, so English-centric emphasis detectors and evaluation tools do not transfer cleanly.
The paper addresses the problem from both the evaluation and generation sides. First, it builds a stress-annotated Mandarin dataset and a Mandarin stress detector. Second, it uses these components to define a cross-lingual stress evaluation pipeline called Cross-lingual Emphasis Transfer Score, or CETS. Third, it fine-tunes a Chinese TTS model to make the S2ST pipeline stress-aware. The central claim is that stress preservation can be substantially improved without sacrificing translation quality or speech naturalness.
The paper’s contributions are threefold: (1) a new Chinese stress speech corpus, (2) a Mandarin detector named Syl-BiLSTM and an objective evaluation metric for English-to-Chinese stress transfer, and (3) a stress-aware cascaded S2ST system built by adapting StressTransfer-style S2T and CosyVoice3-based TTS.
Dataset Construction
Because there was no suitable Chinese dataset for emphasis modeling, the authors constructed a dedicated stress-annotated corpus using material from two existing resources: EmphST-Bench and EmphST-INSTRUCT. They used all 218 Chinese samples from EmphST-Bench and selected 200 samples from EmphST-INSTRUCT, for a total of 418 unique sentences.
Recording was performed by two native Mandarin speakers with standard Mandarin proficiency in a quiet room at a 16 kHz sampling rate. For each sentence, the speaker was shown the target emphasis position and instructed to produce natural prominence on the marked syllable or character while preserving lexical tone category and avoiding exaggerated pitch changes or segmental modifications. Each sentence was recorded 3 to 5 times with the same target emphasis position, varying only the intended stress strength across weak, medium, and strong prompts.
The authors manually filtered the recordings and kept only utterances satisfying five conditions: the intended stressed syllable or character was clearly perceived; no unintended neighboring stress dominated the target; lexical tones and segmental content were correct; the audio had no clipping, noise, or truncation; and forced alignment succeeded at the character level. After filtering, the corpus contained 1,883 samples and 2.74 hours of speech.
| Statistic | Value |
|---|---|
| Number of unique sentences | 418 |
| Number of samples | 1,883 |
| Total hours | 2.74 |
| Language | Chinese |
| Speakers | 2 |
| Average source text length | 9.10 words |
| Average target text length | 13.49 characters |
Cross-Lingual Stress Evaluation Framework
The paper’s evaluation framework is designed around the asymmetry between English stress and Chinese tone. Rather than reusing an English emphasis detector directly, the authors train a dedicated Mandarin stress detector and then align source-side English stress to target-side Chinese stress through word alignment. The resulting metric is intended to measure whether emphasis lands on the semantically corresponding place in the translated speech, not merely whether the output contains any stressed region.
Mandarin Stress Detection: Syl-BiLSTM
The detector, Syl-BiLSTM, operates strictly at the syllable or character level. It begins with all 25 layers of a pretrained XLS-R model, because different layers encode complementary acoustic, prosodic, and semantic information. Using forced-alignment timestamps, the hidden states are segmented into character-specific tensors with shape $[T, 25, 1024]$, where $T$ is the number of frames for a character. Mean pooling over the time dimension produces a fixed-size representation of shape $[25, 1024]$ for each character.
The character-level vectors are stacked into an utterance sequence. A learned softmax-normalized layer fusion combines the 25 XLS-R layers into a single feature sequence:
$$H_{\text{fused}} = \sum_{i=1}^{25} \operatorname{softmax}(w_i) \cdot h_i$$
where the weights are learned and normalized across layers. The fused sequence is then processed by a bidirectional LSTM, and a linear prediction head outputs a binary label for each character: $0$ for unstressed and $1$ for stressed.
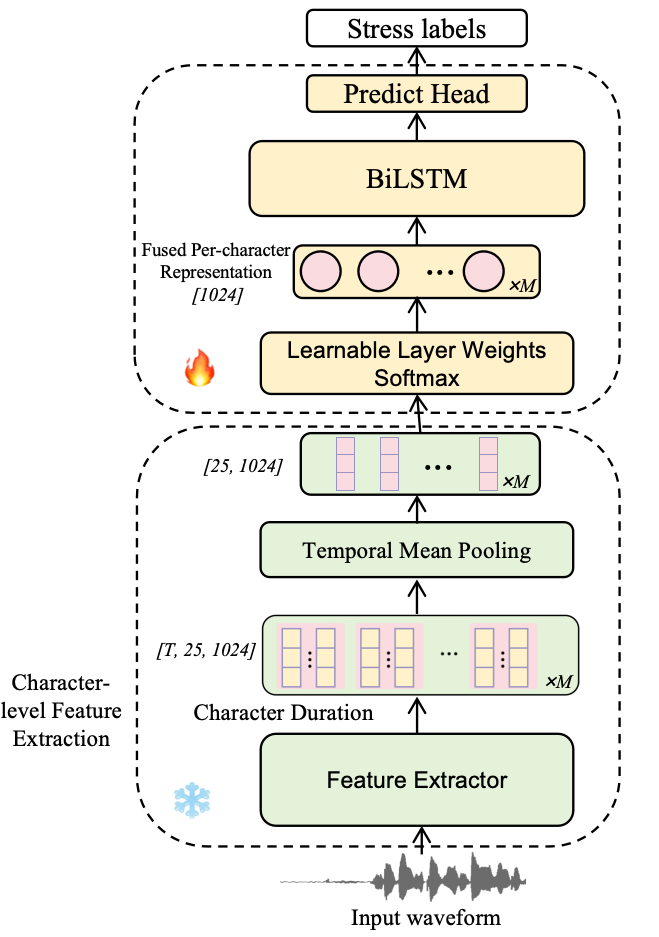
The key design choices are therefore: syllable-level pooling rather than frame-level voting, fusion across all XLS-R layers rather than only the top layer, and contextual sequence modeling with a BiLSTM. The authors argue that these choices are important because Mandarin stress is tightly linked to local syllabic realization and surrounding context.
Cross-Lingual Emphasis Transfer Score (CETS)
To evaluate stress transfer, the authors define CETS as a cross-lingual pipeline that maps stressed English source words to stressed Chinese target characters. On the source side, they use EmphaClass to detect emphasis in the English audio; a source word is treated as stressed if more than half of its frames are predicted as emphasized. On the target side, the synthesized Chinese speech is transcribed with Whisper Large, aligned with the fa-zh forced aligner to obtain character timestamps, and then passed through Syl-BiLSTM to predict stressed characters.
Cross-lingual correspondence is established with SimAlign, which aligns English source words to Chinese target characters. A transfer is counted as successful only when an English stressed word is aligned to a Chinese character that the detector also marks as stressed. This strict definition is meant to avoid crediting arbitrary stress placement that is not aligned with the translated meaning.
The paper reports two variants of the metric:
- CETS-W: word-level strict transfer rate, defined as the ratio of successfully transferred stressed words to the total number of stressed words in the source.
- CETS-S: sentence-level full transfer rate, where a sentence is successful only if all source stressed words are transferred correctly.
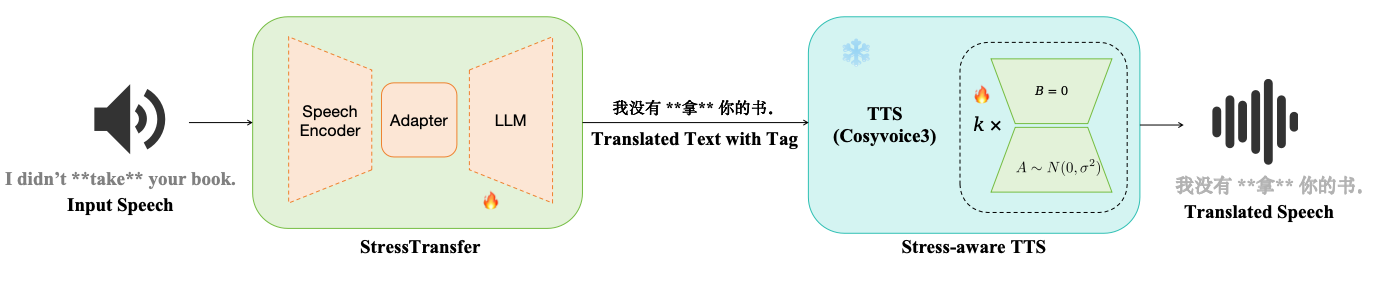
Stress-Aware S2ST Architecture
The proposed S2ST system is a cascade: a stress-aware speech-to-text translation module generates Chinese text with explicit stress tags, and a stress-controllable TTS module synthesizes the final speech. The overall architecture is illustrated below.
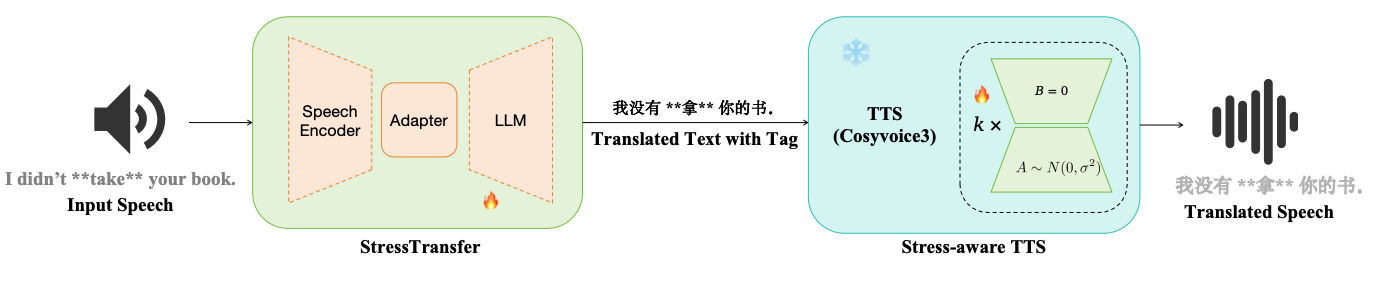
Emphasis-Aware Speech Translation
For translation, the paper adopts the StressTransfer S2TT backbone. The speech encoder is Whisper-Large-v3 and the LLM is Qwen2.5-3B. The model is fine-tuned to jointly perform translation and emphasis prediction, producing translated Chinese text with explicit stress tags. The authors use LoRA on both the speech encoder and the LLM backbone, while fully fine-tuning the adapter module, to preserve general translation ability while adapting to the emphasis prediction task.
The result of this stage is stress-tagged Chinese text, which is then passed to the synthesizer. The paper does not describe a separate decoding objective beyond the stress-aware translation behavior, but its role is to surface emphasis information in a text form that can be consumed by TTS.
Stress-Controllable Speech Synthesis
For synthesis, the authors start from CosyVoice3 and fine-tune it on the newly collected stress-annotated Chinese corpus. Because the available data are limited, they freeze the text and speech tokenizers and apply LoRA to the attention and projection layers of the transformer blocks, specifically q_proj, k_proj, v_proj, and o_proj. The input text uses a <strong> tag to mark emphasized content.
The training objective is standard token-level cross-entropy over speech tokens:
$$\mathcal{L} = -\sum_t \log P\bigl(s_t \mid s_{
Here, $s_t$ denotes the target speech token at time step $t$, conditioned on the prompt, the text input, and the stress tag. The paper’s stated intent is that this fine-tuning makes the TTS model reliably interpret stress tags and render more natural Mandarin emphasis.
A useful implementation detail is that, during S2ST inference, the TTS module synthesizes from stress-tagged Mandarin text using a fixed default voice rather than corpus-speaker prompts. The two-speaker stress corpus is not used to train the StressTransfer-based S2TT module, and held-out test sentences are excluded from both TTS fine-tuning and Syl-BiLSTM training.
The experimental protocol uses the authors’ Chinese stress-annotated corpus. For each evaluation run, they randomly sample 35 unique sentences from EmphST-Bench to form a test set, which corresponds to roughly 170 emphasized speech samples, or about 10% of the full dataset. This random sentence sampling is repeated 5 times, and objective metrics are reported as mean and standard deviation across the five splits.
Translation quality is measured with ASR-BLEU computed by transcribing generated audio using Whisper Large. Naturalness and audio quality are measured using UTMOS. Stress preservation is measured using CETS-W and CETS-S. The subjective evaluation is separate and uses a 20-sample subset from one test split.
The detector is evaluated against two baselines derived from EmphaClass, the English emphasis detector. Frame-Linear follows the original EmphaClass style: final-layer XLS-R frame classification followed by majority voting over character boundaries. Frame-BiLSTM adds a BiLSTM after the final XLS-R layer while keeping frame-level classification and majority voting.
The result is a large jump in recall and F1 for the proposed syllable-level model. The paper emphasizes that the final architecture is not merely an English detector transferred to Chinese: the syllable-level representation, multi-layer feature fusion, and contextual BiLSTM are all needed to match the prosodic behavior of Mandarin. In the reported comparison, Syl-BiLSTM reaches $0.91$ F1, compared with $0.66$ for Frame-BiLSTM and $0.29$ for Frame-Linear.
The complete S2ST system is benchmarked against four strong baselines: Qwen2.5-Omni, GPT-4o-audio-preview, Gemini 2.5 Pro + CosyVoice3 Base, and StressTransfer + CosyVoice3 Base. These baselines cover both direct end-to-end multimodal models and cascaded systems without the proposed TTS adaptation.
The most important result is the large gain in stress transfer. Under the stricter sentence-level metric, the proposed system reaches 58.30%, while the baselines stay in roughly the 16% to 22% range. Word-level CETS shows the same pattern, with the proposed method at 60.80% versus about 15% to 26% for the baselines. This indicates that the system is not just occasionally producing stress, but is doing so at the semantically corresponding location much more reliably.
Translation quality remains competitive. The large multimodal LLM baselines achieve somewhat higher BLEU, with Gemini + Base reaching the highest BLEU at 54.26, but they perform much worse on stress transfer. The proposed system obtains slightly lower BLEU than Gemini + Base, but it improves over the StressTransfer + Base baseline while also achieving the best UTMOS score at 3.68. The paper interprets this as evidence that the fine-tuned CosyVoice3 improves emphasis control without degrading naturalness.
The subjective study uses 20 samples from one test split and 6 proficient bilingual speakers. The evaluators read the source English sentence with stress highlighted, listened to the source audio, and then listened to the translated Chinese audio. They issued a binary Success/Fail judgment based only on whether the emphasis was transferred to the correct semantic position, ignoring overall translation quality and audio quality.
The subjective ranking mirrors the objective CETS results. The paper reports a Pearson correlation of $r = 0.52$ with $p < 10^{-6}$ between automatic evaluation and human judgments over 100 system outputs, along with an absolute agreement rate of 79%. This is presented as evidence that CETS is a useful proxy for human perception of cross-lingual stress transfer.
Taken together, the experiments support two main conclusions. First, Chinese stress is not well handled by English-centric emphasis detectors or by frame-level transfer methods; a Mandarin-specific syllable-level detector is needed for reliable evaluation. Second, explicit stress-aware synthesis matters: adapting CosyVoice3 on stress-annotated data substantially improves the actual transfer of emphasis in translated speech.
A subtle but important point is that the paper separates semantic translation quality from prosodic correctness. High BLEU alone does not imply stress preservation, as shown by the large LLM baselines. Conversely, the proposed system trades a small amount of BLEU relative to the strongest BLEU baseline for a very large gain in emphasis transfer and a top UTMOS score. That makes the work especially relevant to conversational AI systems where emphasis can change the pragmatic interpretation of otherwise correct content.
The paper is careful to note the scope of its current evidence. The Mandarin corpus is relatively small and contains only 2 speakers, so the stress detector and synthesis adaptation are trained on a limited set of voices and speaking styles. The evaluation also focuses on a specific English-to-Chinese setting and uses a bespoke benchmark subset sampled from EmphST-Bench. In addition, the paper uses a fixed default voice at inference rather than speaker prompts from the corpus.
The stated future work is to extend the evaluation and generation framework to broader speakers and to other tonal-language settings. Within the reported scope, however, the method demonstrates that both automatic evaluation and controllable synthesis for lexical stress are feasible when the detector and the synthesis model are adapted to Mandarin-specific prosodic structure.
The paper presents a full English-to-Chinese stress-preservation pipeline for S2ST: a newly collected Mandarin stress corpus, a high-performing Syl-BiLSTM detector built on XLS-R, the CETS metric for cross-lingual emphasis transfer, and a CosyVoice3-based stress-aware S2ST system. The principal outcome is a large improvement in stress transfer accuracy, validated both automatically and by human listeners, while keeping translation quality and speech naturalness competitive.
Experiments
Mandarin Stress Detection Results
Architecture
Precision
Recall
F1-score
Frame-Linear 0.78 ± 0.02 0.18 ± 0.04 0.29 ± 0.05 Frame-BiLSTM 0.77 ± 0.02 0.58 ± 0.02 0.66 ± 0.01 Syl-BiLSTM 0.94 ± 0.01 0.89 ± 0.03 0.91 ± 0.01 S2ST Objective Results
System
BLEU
UTMOS
CETS-W (%)
CETS-S (%)
Qwen2.5-Omni 51.35 ± 3.08 3.53 ± 0.03 25.70 ± 6.00 21.10 ± 6.70 GPT-4o-audio 50.63 ± 1.72 3.46 ± 0.04 25.20 ± 6.60 19.40 ± 7.10 Gemini + Base 54.26 ± 2.91 3.60 ± 0.03 15.70 ± 4.60 16.60 ± 3.80 StressTransfer + Base 46.34 ± 1.92 3.54 ± 0.05 24.60 ± 5.80 22.30 ± 5.50 Proposed 47.35 ± 1.52 3.68 ± 0.02 60.80 ± 7.70 58.30 ± 6.90 Subjective Evaluation and Metric Validation
System
Success Rate (%)
Qwen2.5-Omni 11.67 ± 11.55 GPT-4o-audio 25.00 ± 0.00 Gemini + Base 16.67 ± 20.82 StressTransfer + Base 16.67 ± 20.21 Proposed 78.33 ± 2.89 What the Reported Results Show
Limitations and Scope
Conclusion