Dynamic Prosody Prediction
Dynamic Prosody Prediction in LLM-based TTS for Improving Speaker Similarity
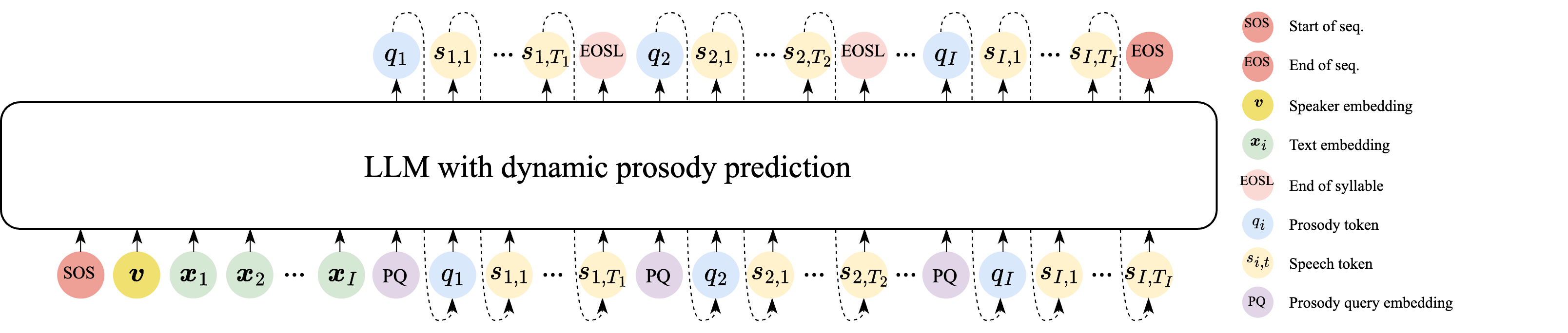
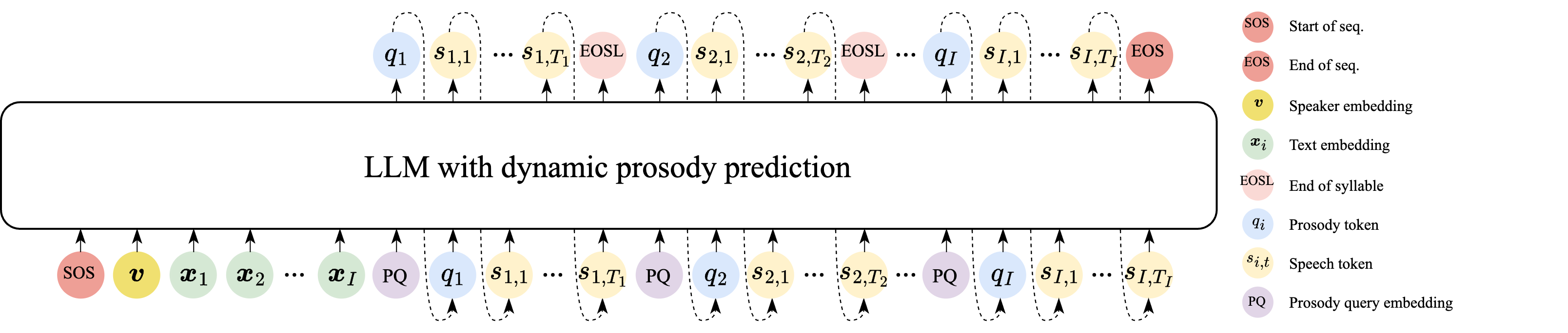
This work proposes dynamic prosody prediction in LLM-based TTS, where prosody for each syllable is predicted conditioned on previously generated speech, improving speaker similarity and style consistency. It differs from prior static or implicit methods by tightly linking prosody with the evolving synthesized speech.
Demos
These demos showcase the dynamic prosody prediction method in an LLM-based TTS system, aimed at improving speaker similarity by modeling prosody at the syllable level. The visuals illustrate the model architecture and inference process, emphasizing how prosody prediction is conditioned on previously generated speech. When evaluating, focus on how this approach enhances style and voice consistency in synthesized speech.
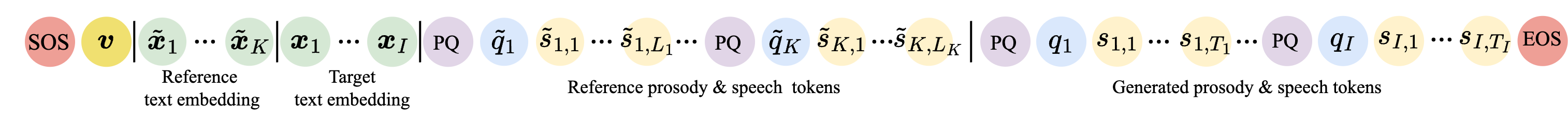
Links
Paper & demos
Code & resources
Impact
Abstract
Personalized text-to-speech (TTS) aims to clone the target speaker in the synthesized speech, imitating both the voice and speaking style. Current large language model (LLM)-based TTS methods ignore the style-specific prosodic patterns in generated speech, resulting in deficient style learning and thus limiting speaker similarity in synthesized speech. To this end, we investigate the prosody learning conditioned on the synthesized speech, and propose to predict the prosody of the current syllable based on previously predicted speech. Experimental results obtained on three datasets demonstrated the efficacy of the proposed dynamic prosody prediction method in enhancing the prosody learning capability, thereby improving the speaker similarity of the generated speech. Audio samples are available at https://muzw.github.io/dynapros/.
1. Problem setting and motivation
Personalized text-to-speech (TTS) aims to synthesize speech that preserves both the target speaker's voice identity and speaking style. This paper focuses on a limitation the authors identify in current large language model (LLM)-based TTS systems: they often model speech attributes such as content, voice, and style only implicitly or as a static conditioning signal, which leaves style-specific prosodic patterns under-modeled. The authors argue that this weak prosody modeling limits speaker similarity, because in their framing speaker similarity depends on both the acoustic voice characteristics and the expressive prosody/style.
The key idea is to make prosody prediction dynamic: instead of predicting all target prosody up front from the prompt and reference speech, the model predicts the prosody of the current syllable conditioned on the speech generated so far. The paper evaluates this idea inside the CosyVoice framework and shows that it improves speaker similarity while maintaining naturalness.
1.1 Background architectures the paper contrasts
The paper contrasts three broad patterns:
- Implicit conditioning, as in CosyVoice, where a speaker embedding is extracted from reference speech and speech tokens for the target utterance are generated without explicit prosody modeling.
- Static explicit prosody prediction, as in CoT-style prompting used by RALL-E and Vevo1.5, where the model predicts prosody tokens for the entire target utterance before speech synthesis.
- Dynamic prosody prediction, the proposed method, where the model alternates between predicting a syllable-level prosody token and the speech tokens for that syllable, using previously generated speech as part of the conditioning context.
2. Core contribution
The paper's main contribution is a dynamic prosody prediction strategy for LLM-based TTS. The method predicts the prosody token of syllable $i$ from the reference speaker embedding, the text, the previously predicted prosody tokens, and the previously generated speech tokens. It then predicts the speech tokens for syllable $i$ conditioned on that predicted prosody token plus the prior speech context. In the authors' view, this causes the model to learn style in a way that is more tightly coupled to the evolving synthetic utterance, rather than treating prosody as a global precomputed attribute.
The paper's stated empirical claims are:
- The method improves speaker similarity relative to both vanilla CosyVoice trained on the same 50k-hour dataset and a CoT-based explicit prosody variant.
- The method does not degrade naturalness or intelligibility.
- It appears to reduce the gap between smaller and larger data regimes, as suggested by preference comparisons against larger open-source baselines.
3. Method
3.1 Overall generation process
The paper works in the CosyVoice LLM-based TTS framework. Let the input text be tokenized at the syllable level into a sequence $\mathbf{X} = \{\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_I\}$, where $I$ is the number of syllables. A reference speech utterance provides a speaker embedding $\mathbf{v}$. The model alternates between predicting:
- a syllable-level prosody token $q_i$ for syllable $i$; and
- a sequence of speech tokens $S_i = \{s_{i,1}, s_{i,2}, \ldots, s_{i,T_i}\}$ for that syllable.
For prosody prediction, the model estimates a distribution over a prosody token vocabulary $\mathcal{C}^{\mathrm{p}}$:
$$ \mathbf{y}_i = p\big(\mathcal{C}^{\mathrm{p}} \mid \mathbf{v}, \mathbf{X}, q_{1:i-1}, S_{1:i-1}\big), $$
where $q_{1:i-1}$ and $S_{1:i-1}$ are the previously predicted prosody and speech tokens. The first syllable is a special case: no previous prosody or speech tokens are available for its prediction.
After choosing the prosody token for syllable $i$, the model predicts the speech token sequence for that syllable, one frame at a time:
$$ \mathbf{z}_{i,t} = p\big(\mathcal{C}^{\mathrm{s}} \mid \mathbf{v}, \mathbf{X}, q_{1:i-1}, S_{1:i-1}, q_i, s_{i,1:t-1}\big), $$
where $\mathcal{C}^{\mathrm{s}}$ is the speech-token vocabulary. The model uses special tokens to mark boundaries: EOSL indicates the end of a syllable and EOS indicates the end of the full utterance.
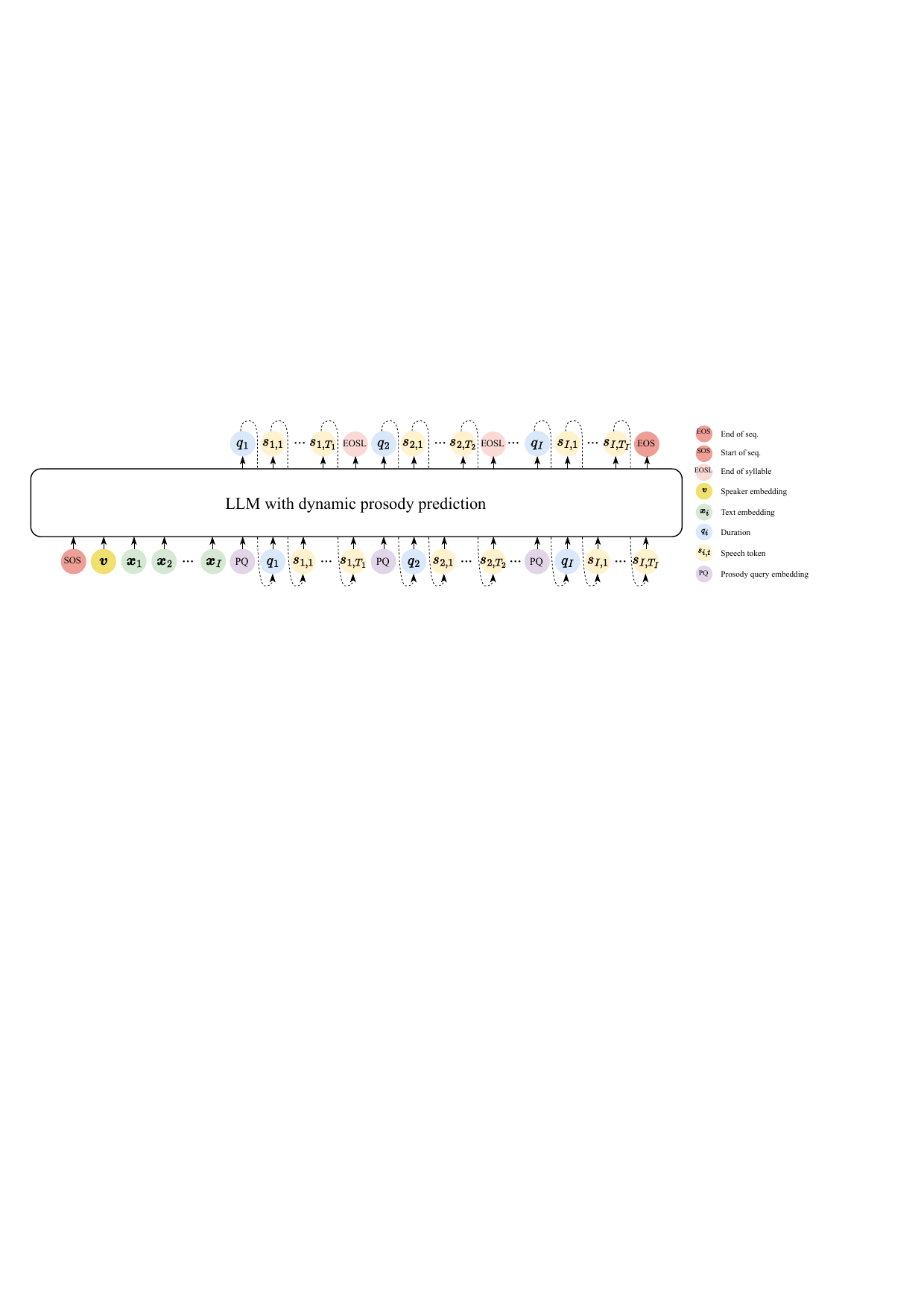

3.2 Prosody token construction
Prosody is represented at the syllable level using four features extracted from each syllable: duration $d_i$, mean energy $e_i$, mean pitch $h_i$, and pitch range $r_i$. The syllable-level prosody vector is
$$ \mathbf{g}_i = [d_i, e_i, h_i, r_i]. $$
The paper computes $e_i$ and $h_i$ as within-syllable means, and computes $r_i$ as the difference between the maximum and minimum pitch values in the syllable. These vectors are quantized with k-means clustering. The prosody token for syllable $i$ is the index of the nearest cluster centroid:
$$ q_i = \arg\min_j \lVert \mathbf{g}_i - \boldsymbol{\mu}_j \rVert^2, $$
where $\boldsymbol{\mu}_j$ is the centroid of cluster $j$. The cluster size used in experiments is 512.
3.3 Training objective
The model is trained with a weighted sum of cross-entropy losses over prosody tokens and speech tokens. If $\hat{\mathbf{y}}_i$ denotes the ground-truth prosody token for syllable $i$ and $\hat{\mathbf{z}}_{i,t}$ denotes the ground-truth speech token for frame $t$ in syllable $i$, the loss is
$$ \mathcal{L} = -\alpha \frac{1}{I} \sum_{i=1}^{I} \hat{\mathbf{y}}_i \log \mathbf{y}_i - (1-\alpha) \frac{1}{\sum_{i=1}^{I}(T_i+1)} \sum_{i=1}^{I} \sum_{t=1}^{T_i+1} \hat{\mathbf{z}}_{i,t} \log \mathbf{z}_{i,t}, $$
with $0 \leq \alpha \leq 1$. In the reported experiments, the authors set $\alpha = 0.5$.
3.4 Inference procedure
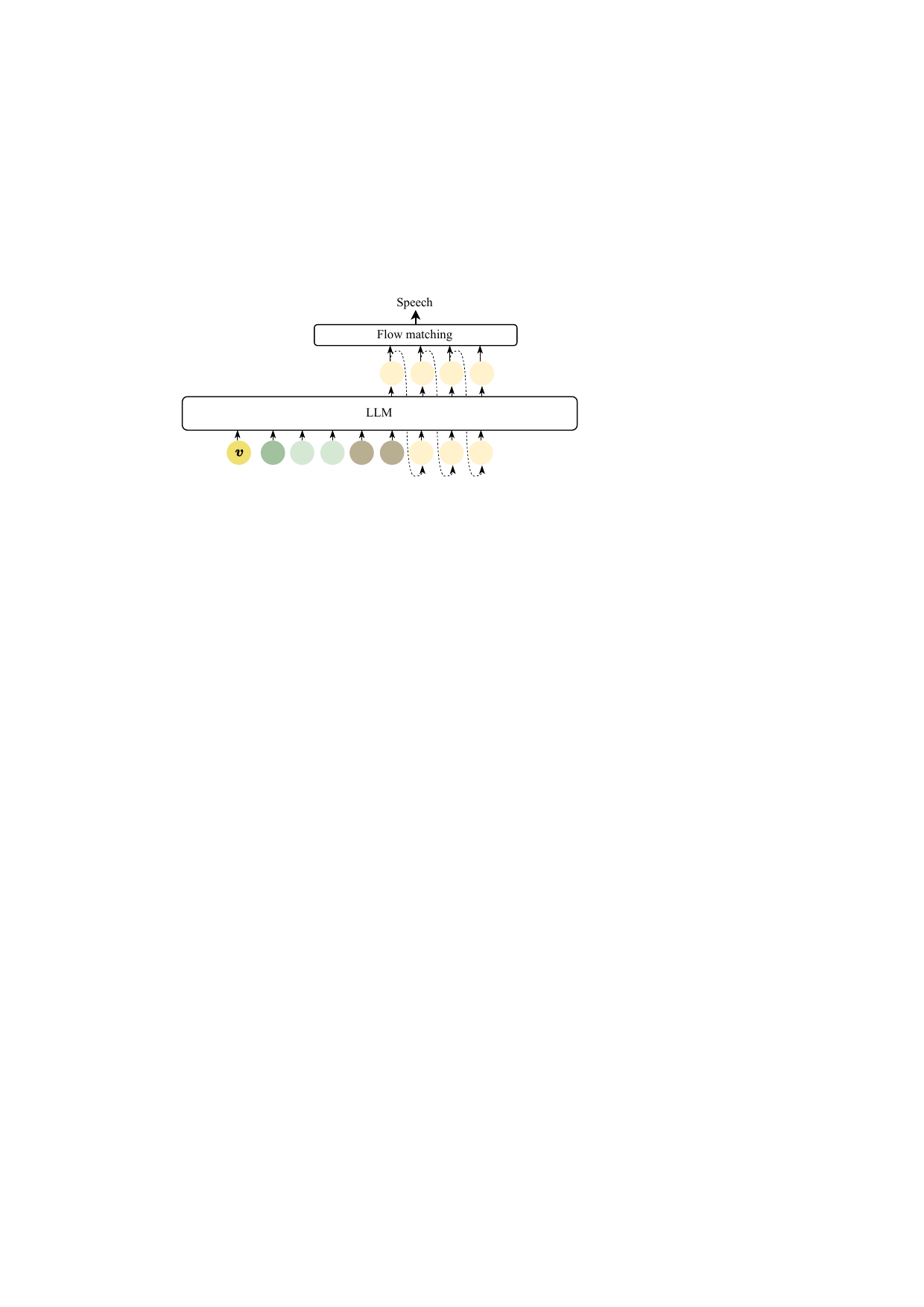
At inference time, the model takes the reference speech and its transcription, extracts reference prosody tokens and reference speech tokens, and combines them with the reference speaker embedding and the syllable-level text embeddings for both reference and target text. The LLM then generates prosody and speech tokens alternately. The paper samples token indices using top-$p$ and top-$k$ sampling: top-$p = 0.8$, with top-$k = 15$ for prosody tokens and top-$k = 25$ for speech tokens. Finally, the generated speech tokens are passed to the flow-matching vocoder/module to synthesize waveform audio.
4. Experimental setup
4.1 Training data
The experiments are conducted on Mandarin Chinese, where a character corresponds to a single syllable. Training data comes from two sources:
- WenetSpeech: 10k hours of speech.
- Mandarin subset of Emilia: 50k hours of speech.
Syllable boundaries are obtained with the Montreal Forced Aligner (MFA). After removing MFA failures and language-misclassified utterances, the training set contains approximately 50k hours of data.
4.2 Evaluation datasets
The paper evaluates on three test sets that cover different speaking-style conditions:
- ESD: 350 utterances from 10 speakers expressing 5 emotions: neutral, happy, angry, sad, and surprised. This is the most stylistically rich evaluation set.
- Internal: 230 unlabeled utterances with diverse speaking styles, provided by iFLYTEK.
- AISHELL-3: the test split of AISHELL-3, containing prosodically neutral recordings from 214 speakers.
For inference, target text selection differs by dataset: in ESD, the target text is the transcription of another utterance by the same speaker and same emotion; in AISHELL-3, the target text is the transcription of another utterance by the same speaker; in the internal test set, the target text is randomly selected from a different utterance than the reference speech.
4.3 Compared systems
All main comparisons are run within the CosyVoice implementation and with the same speech tokenizer/configuration. Speaker embeddings are extracted using a pre-trained CAM++ speaker encoder. The three primary systems are:
- CosyVoice(50k): CosyVoice LLM trained from scratch on the 50k-hour training set, without explicit prosody modeling.
- CoT: CosyVoice augmented with chain-of-thought-style syllable-level prosody prediction for the full utterance before synthesis.
- Proposed: CosyVoice with dynamic prosody prediction; $\alpha = 0.5$.
The paper also compares against three open-source TTS models in preference tests:
- Vevo1.5: explicit prosody modeling with CoT prompting, trained on 100k hours of Emilia (50k Chinese + 50k English).
- F5-TTS: trained on the same 100k-hour Emilia corpus.
- CosyVoice: a larger model trained on a multilingual 170k-hour corpus, including 130k hours of Chinese.
4.4 Optimization and model size
The LLM is a decoder-only Transformer with 14 layers, 16 attention heads, 1024 embedding dimensions, and 4096 feed-forward dimensions. All models are trained for 800,000 steps on eight MLU 580 GPUs, using learning rate $10^{-4}$ and 10,000 warmup steps.
5. Evaluation protocol
5.1 Subjective tests
The paper conducts two subjective evaluations with 11 native speakers:
- MOS for naturalness.
- Preference tests for speaker similarity / consistency.
For each test set, 20 sentences are sampled. In the preference task, the synthesized utterance is concatenated with the reference recording, and listeners choose which concatenated sequence sounds more internally consistent across voice and style. The authors report that higher preference indicates greater speaker similarity; for ESD, style similarity includes emotion consistency.
5.2 Objective tests
Objective evaluation is designed to probe three aspects: intelligibility, emotion/style transfer, and prosody matching.
- Intelligibility: character error rate (CER) from a Whisper ASR system.
- Emotion/style: emotion embedding cosine similarity (SIM) and emotion recognition accuracy (ACC) using emotion2vec+.
- Prosody matching: correlation (Corr) and root mean square error (RMSE) for pitch and energy relative to the recording.
For each test set, 1000 utterances are generated. AISHELL-3 is excluded from emotion evaluation because it is prosodically neutral. The internal test set is not evaluated on pitch/energy metrics because speaker labels are unavailable.
6. Results
6.1 Subjective naturalness and speaker similarity
The MOS results show that the proposed method preserves naturalness and is broadly comparable to the baselines. On ESD, the proposed method achieves the highest MOS among the three trained-from-scratch systems. On Internal and AISHELL-3, it is essentially on par with the best baseline.
| Method | ESD | Internal | AISHELL-3 |
|---|---|---|---|
| Recording | 4.21 ± 0.09 | 4.16 ± 0.07 | 4.18 ± 0.08 |
| CosyVoice(50k) | 4.01 ± 0.07 | 3.97 ± 0.07 | 4.06 ± 0.06 |
| CoT | 4.00 ± 0.09 | 3.98 ± 0.08 | 4.03 ± 0.10 |
| Proposed | 4.07 ± 0.06 | 3.99 ± 0.07 | 4.06 ± 0.07 |
Preference tests consistently favor the proposed method over CosyVoice(50k) and CoT. The paper reports statistical significance at $p < 0.01$ for these comparisons. The preference margins are strongest on the style-rich ESD and Internal sets, which aligns with the paper's claim that dynamic prosody is especially helpful when expressive style matters.
| Dataset | Method A | Prefer A (%) | N/P (%) | Prefer B (%) |
|---|---|---|---|---|
| ESD | CosyVoice(50k) | 28.8 | 19.7 | 51.5 |
| ESD | CoT | 28.8 | 21.4 | 50.9 |
| Internal | CosyVoice(50k) | 33.2 | 18.6 | 48.2 |
| Internal | CoT | 30.9 | 21.4 | 47.7 |
| AISHELL-3 | CosyVoice(50k) | 20.4 | 45.9 | 33.6 |
| AISHELL-3 | CoT | 25.9 | 40.5 | 33.6 |
6.2 Objective metrics: intelligibility, emotion, and prosody
The objective results support the subjective findings. The proposed method improves CER on all three datasets, suggesting that explicit dynamic prosody conditioning does not hurt linguistic fidelity and may even help generation robustness.
On ESD, the proposed model is best on all reported metrics: lowest CER, highest emotion similarity, highest emotion accuracy, highest pitch and energy correlations, and lowest pitch and energy RMSE. On the Internal set, it achieves the best CER and emotion similarity, while emotion accuracy is slightly below CosyVoice(50k) but still competitive. On AISHELL-3, the proposed method again achieves the best CER and the best prosody metrics.
| Dataset | Model | CER | Emotion SIM | Emotion ACC (%) | Pitch Corr (%) | Pitch RMSE | Energy Corr (%) | Energy RMSE |
|---|---|---|---|---|---|---|---|---|
| ESD | CosyVoice(50k) | 6.38 | 0.875 | 84.32 | 79.52 | 83.61 | 94.08 | 6.42 |
| CoT | 6.14 | 0.876 | 84.52 | 79.31 | 82.82 | 94.03 | 6.39 | |
| Proposed | 5.66 | 0.884 | 86.56 | 80.32 | 80.81 | 94.91 | 5.93 | |
| Internal | CosyVoice(50k) | 13.69 | 0.802 | 52.31 | — | — | — | — |
| CoT | 13.60 | 0.799 | 50.23 | — | — | — | — | |
| Proposed | 10.44 | 0.821 | 51.63 | — | — | — | — | |
| AISHELL-3 | CosyVoice(50k) | 11.59 | — | — | 80.41 | 69.92 | 90.59 | 6.66 |
| CoT | 11.61 | — | — | 80.61 | 69.90 | 90.51 | 6.52 | |
| Proposed | 10.19 | — | — | 82.58 | 66.08 | 92.66 | 5.91 |
Several trends are worth emphasizing:
- Comparing against CosyVoice(50k): dynamic prosody prediction consistently improves style-sensitive metrics, especially on ESD and Internal, which are rich in emotion and speaking-style variation.
- Comparing against CoT: the proposed method outperforms static utterance-level prosody prediction, indicating that conditioning on previously generated speech is beneficial beyond simply adding explicit prosody tokens.
- Generalization to neutral speech: improvements remain visible on AISHELL-3, suggesting that the method is not limited to expressive/emotional speech.
6.3 Comparison with larger open-source systems
The paper further evaluates the proposed 50k-hour model against Vevo1.5, F5-TTS, and a much larger CosyVoice model trained on 170k hours. The comparison is subjective preference only. The proposed model wins against Vevo1.5 and F5-TTS on all three datasets, and it also beats the larger CosyVoice model on the style-rich ESD and Internal sets. Against the larger CosyVoice model on AISHELL-3, the proposed method does not show a significant preference advantage, but it remains competitive.
| Dataset | Model A | Prefer A (%) | N/P (%) | Prefer B (%) | p |
|---|---|---|---|---|---|
| ESD | Vevo1.5 | 27.8 | 19.4 | 52.8 | < 0.01 |
| F5-TTS | 22.7 | 26.4 | 50.9 | < 0.01 | |
| CosyVoice | 32.7 | 22.4 | 44.8 | < 0.01 | |
| Internal | Vevo1.5 | 36.4 | 16.6 | 47.0 | < 0.01 |
| F5-TTS | 24.1 | 15.5 | 60.4 | < 0.01 | |
| CosyVoice | 35.4 | 26.4 | 38.2 | 0.10 | |
| AISHELL-3 | Vevo1.5 | 23.2 | 41.2 | 35.6 | < 0.01 |
| F5-TTS | 21.4 | 50.0 | 28.6 | < 0.01 | |
| CosyVoice | 29.1 | 43.2 | 27.7 | 0.65 |
7. Interpretation
The paper's central interpretation is that style is not a fixed utterance-level attribute that can always be solved by a single upfront prompt. Instead, style emerges over time as the utterance is generated. By feeding already generated speech back into the prosody prediction path, the model can better align future syllables with the style trajectory established so far. This appears to help most on expressive datasets, where emotion and rhythmic shaping matter more than on neutral speech.
Another important interpretation is that dynamic prosody prediction may be especially useful when training data is limited. The authors explicitly suggest that the mechanism can compensate for a prosody-learning deficit and narrow the performance gap between smaller and larger training regimes. This claim is supported by preference wins over a much larger CosyVoice model on the expressive test sets.
8. Stated limitations and scope
The paper does not include a dedicated limitations section, but several constraints are clear from the reported setup:
- The method is evaluated only on Mandarin Chinese, where the syllable structure aligns naturally with the modeling choice.
- The prosody tokenization is based on a hand-designed four-feature syllable representation $[d_i, e_i, h_i, r_i]$ followed by k-means clustering, so the approach depends on external pitch/energy extraction and forced alignment.
- The internal test set lacks speaker labels, which prevents some objective prosody metrics from being computed there.
- The paper's broader claim about improved speaker similarity is supported by three datasets and subjective/objective metrics, but the work does not report an ablation table isolating each component beyond the main comparison to CosyVoice and CoT.
The conclusion explicitly notes that the method's ability to reduce the prosody-learning gap between small- and large-scale data regimes is promising and merits future investigation.
9. Bottom line
This paper proposes a straightforward but effective idea: make prosody prediction online rather than static by conditioning the current syllable's prosody on the speech already generated. Within a CosyVoice-style LLM-based TTS system, this dynamic conditioning improves expressive style transfer, speaker similarity, and prosody fidelity, while preserving naturalness and intelligibility. The strongest gains appear on emotionally rich or style-diverse data, and the method also competes favorably with larger open-source systems trained on more data.
Code & Implementation
The CosyVoice repository implements an advanced text-to-speech (TTS) system based on large language models (LLM), directly corresponding to the paper's dynamic prosody prediction method to enhance prosody learning and speaker similarity.
The core implementation is found under cosyvoice/cli/cosyvoice.py, which defines the CosyVoice class encapsulating model loading, various inference modes (e.g., zero-shot, cross-lingual, speaker fine-tuning), and speech synthesis streaming. The example usage script example.py demonstrates key functionalities including zero-shot voice cloning, cross-lingual synthesis, instruction-guided synthesis, and voice conversion.
The repository contains pretrained models referenced in the paper, loaded via the AutoModel interface, supporting multiple versions of CosyVoice (1.0, 2.0, 3.0) with rich control over prosodic and speaker characteristics.
Overall, this repo provides a comprehensive implementation of the paper's method centered around dynamic prosody prediction in an LLM-based TTS framework, enabling high-quality, personalized multi-lingual speech synthesis.