SpatialAvatar-0
SpatialAvatar-0: High-Quality 4D Head Avatar with Multi-Stage Reconstruction
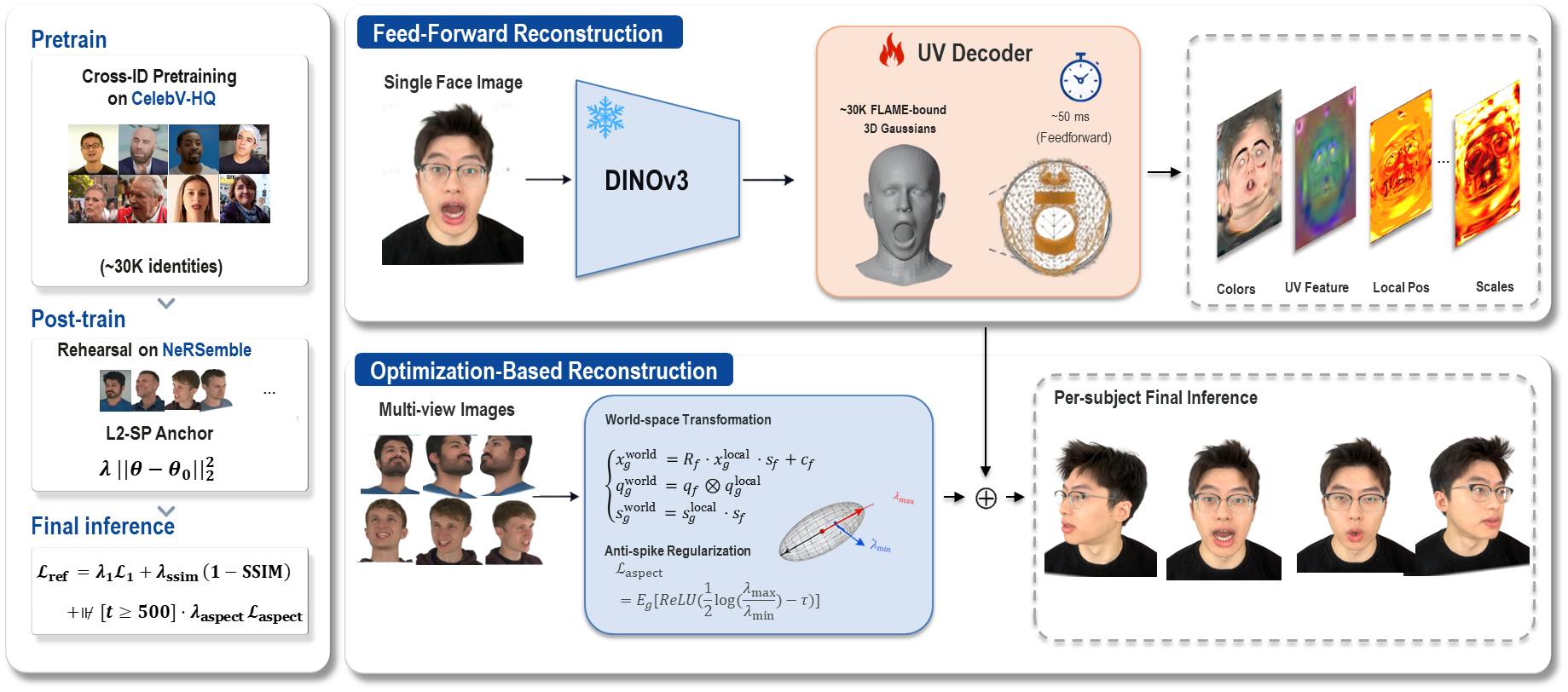
SpatialAvatar-0 creates high-quality 4D head avatars from few portraits by unifying feed-forward prediction and per-subject refinement on a shared Gaussian-splat FLAME-mesh representation. It enables strong zero-shot generalization and faster refinement by preserving spatial layout and Gaussian count throughout.
Demos
The demos showcase SpatialAvatar-0's high-fidelity 4D head avatars, highlighting superior visual quality and temporal consistency in both same-identity and cross-identity driving scenarios. Viewers should note preservation of identity details, natural expression tracking, and robust performance compared to leading baselines, achieved with significantly shorter refinement times.
Links
Paper & demos
Impact
Abstract
High-quality 4D head avatars from one or a few source portraits are central to telepresence, AR/VR, and digital-human interaction. 3D Gaussian Splatting (3DGS) has emerged as the dominant representation, with two complementary regimes (generalizable feed-forward predictors and per-subject refiners) maturing in parallel. However, existing feed-forward predictors are trained on a single dataset family with a hard-coded source count, inheriting the corresponding domain bias. Per-subject refiners require 300K--600K iterations and rely on adaptive densification that destroys upstream Gaussian layouts, preventing the two regimes from sharing a representation end-to-end. To bridge both regimes we propose SpatialAvatar-0 on a shared FLAME-mesh-bound Gaussian representation: a feed-forward generator with a parameter-free K-source mean-pool and a monocular-temporal to multi-view-spatial two-phase schedule that anchors against identity-prior collapse onto the smaller multi-view set. We further introduce a 10K-iter layout-preserving per-subject refinement loop that freezes the FLAME-binding and Gaussian count and replaces densification with a three-component anti-spike regularization. On VFHQ/HDTF cross-domain zero-shot we surpass the in-domain leader GAGAvatar by +1.5 dB PSNR despite never training on either test domain, and on the SplattingAvatar monocular benchmark we lead every reported metric, surpassing the 300K-iter GeoAvatar by +1.3 dB PSNR at up to 60x shorter per-subject schedule than common SOTA baselines. Website: https://spatialwalk.github.io/SpatialAvatar-0.
1. Problem setting and core idea
SpatialAvatar-0 targets the problem of producing high-quality 4D head avatars from one or a few source portraits. The paper frames the field as having two complementary 3D Gaussian Splatting (3DGS) regimes: generalizable feed-forward predictors, which generate an animatable head model in a single pass, and per-subject refiners, which optimize a model for one identity to recover subject-specific detail. The central claim is that these two regimes should not be treated as separate systems: they can share a common FLAME-mesh-bound Gaussian representation end-to-end.
The paper identifies two practical gaps. First, prior feed-forward predictors are typically trained on a single dataset family and often hard-code the number of source images, which creates domain bias and prevents flexible deployment. Second, per-subject refiners usually need 300K--600K iterations and rely on adaptive densification, which destroys the upstream Gaussian layout and prevents a clean handoff from the feed-forward stage. SpatialAvatar-0 addresses both issues with a two-stage design: a variable-source feed-forward generator trained in two phases, followed by a layout-preserving per-subject refinement loop that keeps the Gaussian count and FLAME binding fixed.
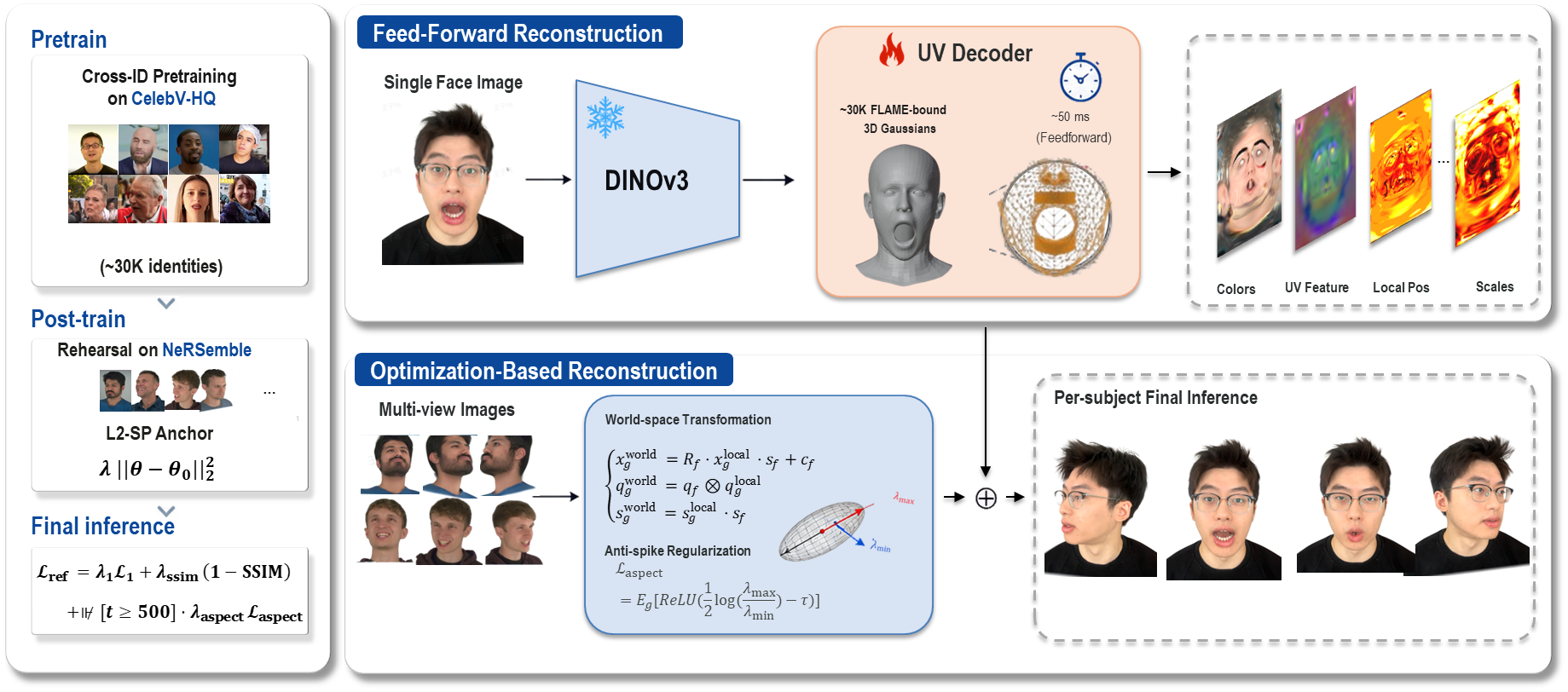
- Shared representation: one Gaussian per valid pixel of a FLAME UV grid, rigidly bound to the corresponding mesh triangle.
- Feed-forward stage: a single network consumes $K \in \{1,2,3,4\}$ source portraits and emits face-bound Gaussians in one forward pass.
- Training strategy: monocular-temporal pretraining on CelebV-HQ, then multi-view-spatial post-training on NeRSemble with an anchor against forgetting.
- Per-subject stage: 10K iterations, no densification, and an anti-spike regularizer to prevent 3DGS anisotropy failures.
2. Method
2.1 Shared FLAME-bound Gaussian representation
The representation is built on a FLAME UV unwrap with one Gaussian per valid UV pixel, giving about 58K Gaussians per identity. Each Gaussian is rigidly bound to its parent triangle, so its world-space parameters are obtained by deforming the FLAME mesh and applying the local triangle frame. For a Gaussian $g$ bound to triangle $f(g)$, the paper writes the world transform as
$$ \mathbf{x}^{\text{world}}_g = \mathbf{R}_{f(g)} \mathbf{x}^{\text{local}}_g \, s_{f(g)} + \mathbf{c}_{f(g)}, \qquad \mathbf{q}^{\text{world}}_g = \mathbf{q}_{f(g)} \otimes \mathbf{q}^{\text{local}}_g, \qquad \mathbf{s}^{\text{world}}_g = \mathbf{s}^{\text{local}}_g \, s_{f(g)}. $$
Here $\mathbf{c}_{f(g)}$ is the triangle centroid, $\mathbf{R}_{f(g)}$ is the triangle-local rotation, and $s_{f(g)}$ is the triangle scale. The paper emphasizes that this binding is the infrastructure layer that makes feed-forward prediction and per-subject refinement compatible: in refinement, the binding and Gaussian count are frozen rather than being rewritten by densification.
2.2 Feed-forward architecture
The feed-forward model uses a frozen DINOv3 ViT-B/16 backbone with a trainable DPT head to produce dense features and a global CLS token. The dense feature is barycentrically warped into UV space and then processed by a StyleUNet UV generator based on StyleGAN2. The UV generator outputs 32-channel feature maps, which are concatenated with a 27-dimensional harmonic embedding of the target camera direction and decoded by five parallel heads for local position, rotation, scale, color, and opacity.
For multiple source images, the per-source UV features and CLS tokens are aggregated by parameter-free mean pooling. This pooling is order-invariant, reduces to the identity for $K=1$, and avoids the need for an attention module or a source-count-specific architecture. The paper also tests attention pooling as an ablation, but mean pooling is the default because it gives the best overall tradeoff.
The camera-direction encoding is the standard harmonic embedding:
$$ \gamma(\mathbf{d}) = \big[\mathbf{d},\, \sin(2^k \pi \mathbf{d}),\, \cos(2^k \pi \mathbf{d})\big]_{k=0..3} \in \mathbb{R}^{27}. $$
On top of the main decoder, the method adds a FLAME-conditioned residual head. It is modulated by a 112-dimensional conditioning vector made from expression, pose, and eye codes, and it predicts per-attribute residuals for position, rotation, scale, and color. Shape is intentionally excluded from this conditioning path, because the paper treats FLAME shape as the load-bearing identity prior that should come from the mesh geometry rather than be learned as a free residual. Opacity is also excluded from the residual head because the authors report alpha-pumping artifacts during early experiments.
2.3 Training objective for the feed-forward stage
The feed-forward stage is supervised with a weighted sum of photometric, face-region, smoothness, and architectural regularizers:
$$ \mathcal{L} = \lambda_1 \mathcal{L}_1 + \lambda_{\text{ms}} \mathcal{L}_{\text{ms}} + \lambda_{\text{lp}} \mathcal{L}_{\text{lp}} + \lambda_{\text{box}} \mathcal{L}_{\text{box}} + \lambda_{\text{ps}} \mathcal{L}_{\text{ps}} + \lambda_{\text{ss}} \mathcal{L}_{\text{ss}} + \lambda_{\text{jac}} \mathcal{L}_{\text{jac}} + \lambda_{\delta} \mathcal{L}_{\delta}. $$
The photometric terms are $L_1$, multi-scale SSIM, and LPIPS; the face-box term adds supervision inside the detected face bounding box. The smoothness terms are UV-domain total-variation penalties on local position and log-scale. The residual shrinkage term $\mathcal{L}_{\delta}$ discourages large residual-head outputs, and the Jacobian penalty discourages view-direction leakage into geometry.
The Jacobian regularizer is estimated with a Hutchinson-style projection so that a single backward pass against the harmonic view encoding can approximate the per-pixel Frobenius norm of the geometric Jacobian. The paper applies this penalty to position and scale only, not to color or opacity. In the authors' framing, this keeps geometry as an intrinsic property of the scene while allowing appearance to remain view-dependent.
The body loss is written as
$$ \mathcal{L}_{\text{jac}} = \log\big(1 + \|\nabla_\gamma g_{\mathbf{x}}\|_2^2 + \|\nabla_\gamma g_{\mathbf{s}}\|_2^2\big), $$
where $g_{\mathbf{x}}$ and $g_{\mathbf{s}}$ are the Hutchinson scalars for the local position and local scale heads.
2.4 Two-phase feed-forward training
Training is split into two phases with the same architecture. Phase 1 is monocular-temporal pretraining on CelebV-HQ: each clip contributes $K \sim \text{Uniform}\{1,2,3,4\}$ source frames and a held-out target frame. This phase exposes the network to a wide identity manifold but does not provide multi-view ground-truth geometry. Phase 2 continues from the Phase-1 checkpoint on NeRSemble multi-view data and mixes same-time cross-camera supervision with cross-time supervision.
The main purpose of Phase 2 is to add multi-view geometry without collapsing the identity prior learned from CelebV-HQ. To do that, the paper uses two controls together: an L2-SP anchor back to the Phase-1 weights and a 25% cross-time mixture in the NeRSemble batches. The rest of each batch is dominated by cross-camera pairs, so the model still gets the geometric benefit of synchronized multi-view supervision.
The source-frame sampler is also deliberately nontrivial: it biases the first source toward frames that are dissimilar to the target in camera direction and expression, rather than always choosing easy near-identity pairs. This is intended to make the feed-forward model robust to a wider range of reenactment conditions.
The paper reports that the full schedule uses a frozen DINOv3-B encoder, and that training runs on a single H100 NVL GPU for 14 days. In the appendix, the authors further specify the optimizer and batch settings for the two phases, but the main architectural takeaway is that Phase 2 is a continuation of Phase 1 rather than a separate model.
2.5 Per-subject refinement without densification
The refinement stage starts from the feed-forward prediction at a chosen reference frame and then optimizes the avatar for 10K iterations on the target video. Crucially, the FLAME mesh and triangle bindings are frozen, so the Gaussian count and layout remain fixed throughout optimization. This is the opposite of the common densification strategy used in many 3DGS refiners; the paper argues that densification would destroy the upstream spatial inductive bias learned by the feed-forward stage.
The refinement objective uses photometric loss and SSIM, plus a screen-space anti-anisotropy penalty after iteration 500:
$$ \mathcal{L}_{\text{ref}} = \lambda_1 \mathcal{L}_1 + \lambda_{\text{ssim}} (1 - \text{SSIM}) + \mathbb{1}[t \geq 500] \cdot \lambda_{\text{aspect}} \mathcal{L}_{\text{aspect}}. $$
The anti-spike term is defined on the projected 2D covariance of each Gaussian:
$$ \mathcal{L}_{\text{aspect}} = \mathbb{E}_g\left[\operatorname{ReLU}\left(\tfrac{1}{2}\log\frac{\lambda_{\max}(\Sigma_g^{2D})}{\lambda_{\min}(\Sigma_g^{2D})} - \tau\right)\right]. $$
The authors combine this soft penalty with two additional safeguards: a scale-freeze warmup for the first 500 iterations, and a hard log-scale clamp once scale is unfrozen. Their argument is that these three mechanisms are complementary rather than redundant: the warmup prevents early blow-ups, the clamp gives an absolute bound, and the screen-space penalty discourages thin streaks in the rendered image.
The refinement stage also uses shared random background compositing on both the rendered image and the target image, so silhouette-boundary gradients remain symmetric. This is intended to pull the learned splatting alpha toward the matte without needing an explicit silhouette loss. The paper omits LPIPS from this stage because, at the small 10K-step budget, LPIPS gradients were found to introduce speckle-like artifacts before convergence.
Reference-frame selection is heuristic: the system picks the frame with minimum jaw-pose magnitude, with a fallback for videos where the jaw motion is essentially zero or the jaw is occluded. In other words, the initialization is designed to be stable, but it is not a full canonical-pose solver.
3. Datasets, supervision, and implementation
The paper trains the feed-forward pipeline on CelebV-HQ in Phase 1 and NeRSemble v2 in Phase 2. For zero-shot evaluation, it uses VFHQ and HDTF, explicitly noting that these test domains do not appear in either supervised training stage. For per-subject evaluation, it uses the SplattingAvatar dataset and reserves the last 350 frames of each video as the test set. All ablations are evaluated on a held-out CelebV-HQ slice.
The paper reports standard image-quality metrics PSNR, SSIM, and LPIPS for both evaluation lanes. For the feed-forward lane, it additionally reports ArcFace identity similarity (CSIM), average expression distance (AED), average pose distance (APD), and average keypoint distance (AKD). The evaluation separates self-reenactment, where the source is the first frame of the same video, from cross-reenactment, where a different-identity driver is used and only identity/expression/pose metrics are reported.
The FLAME parameters are recovered using the GAGAvatar tracker stack, which the appendix describes as an EMICA-style monocular tracker with a detector, matting, and optimization components. The tracked outputs include shape, expression, pose, eye pose, a camera transform, and a face bounding box. The paper also states that the FLAME 2020 mesh is patched to include teeth and unwrapped onto a 256 x 256 UV grid, yielding the approximately 58K valid UV pixels used as Gaussian slots.
4. Main empirical results
4.1 Feed-forward zero-shot results on VFHQ and HDTF
The most important feed-forward result is that SpatialAvatar-0 is evaluated out of domain: it is trained on CelebV-HQ and NeRSemble, but tested on VFHQ and HDTF. The paper compares against eleven generalizable head-avatar baselines and reports that Ours-FF leads every column on both datasets. In particular, it beats the in-domain leader GAGAvatar by $+1.5$ dB PSNR on both VFHQ and HDTF, while also improving identity similarity, expression/pose alignment, and perceptual quality.


| Dataset | Method | Self PSNR | Self SSIM | Self LPIPS | Cross CSIM | Cross AED | Cross APD | Cross AKD |
|---|---|---|---|---|---|---|---|---|
| VFHQ | GAGAvatar | 21.83 | 0.818 | 0.122 | 0.633 | 0.253 | 0.247 | 3.349 |
| VFHQ | Ours-FF | 23.34 | 0.875 | 0.077 | 0.675 | 0.245 | 0.210 | 2.181 |
| HDTF | GAGAvatar | 23.13 | 0.863 | 0.103 | 0.851 | 0.231 | 0.181 | 2.985 |
| HDTF | Ours-FF | 24.67 | 0.916 | 0.076 | 0.905 | 0.224 | 0.147 | 2.326 |
Qualitatively, the paper argues that Ours-FF preserves high-frequency identity cues such as forehead wrinkles, beard texture, nasolabial folds, malar contour, and hair-edge silhouette. It also shows cross-identity examples in which the source identity is retargeted under a different driver's expression and pose while keeping the source face geometry consistent.


4.2 Per-subject monocular benchmark on SplattingAvatar
On the per-subject SplattingAvatar benchmark, the paper compares against per-subject baselines and includes GAGAvatar's one-shot feed-forward result as a reference point. Ours+S3 leads every reported metric: it achieves the best MSE, the highest PSNR and SSIM, and the lowest LPIPS. The headline comparison is that Ours+S3 surpasses GeoAvatar by about $+1.3$ dB PSNR while using only 10K iterations instead of 300K.
| Method | MSE $\times 10^{-3}$ | PSNR | SSIM | LPIPS $\times 10^{-1}$ |
|---|---|---|---|---|
| GAGAvatar* | 4.425 | 23.541 | 0.875 | 1.121 |
| GeoAvatar | 0.545 | 32.635 | 0.965 | 0.367 |
| Ours+S3 | 0.402 | 33.960 | 0.971 | 0.355 |

The qualitative result the paper stresses is that the 10K-step refinement keeps high-frequency content sharp at rendered scale, including wrinkles, beard or mustache texture, eye specularities, and hair-edge silhouettes. This is used as evidence that the layout-preserving refinement can recover subject-specific details without needing the very long optimization schedules common in prior Gaussian refiners.
4.3 Training cost and runtime
The per-subject efficiency story is a major part of the paper's contribution. On a single RTX 3090, the reported refinement finishes in about 2 minutes per subject, while prior per-subject methods take hours. The feed-forward stage produces a complete avatar in about 50 ms on the same GPU. Inference remains real-time even after refinement, with 265.60 FPS at $512^2$ resolution using the 3-channel diff_gaussian_rasterization backend.
| Method | Iterations | Train time | Latency (ms) | FPS |
|---|---|---|---|---|
| FlashAvatar | 150K | ~1.66 h | -- | 291.20 |
| GaussianAvatars | 600K | ~9.25 h | -- | 19.11 |
| GeoAvatar | 300K | ~4.90 h | -- | 71.52 |
| Ours+S3 | 10K | ~2.0 min | 3.77 | 265.60 |
5. Ablations and design analysis
The ablation story is unusually clean in this paper: each component is shown to support a distinct failure mode. The authors first build the pipeline cumulatively and then remove architecture pieces one at a time from the full model. The main lesson is that Phase 2, the L2-SP anchor, the cross-time mixture, the residual head, the Jacobian penalty, and the mean-pooling choice all matter for different reasons.
| Exp. | Setting | PSNR | SSIM | LPIPS | CSIM | AED | APD | AKD |
|---|---|---|---|---|---|---|---|---|
| A | Phase 1 only | 24.84 | 0.879 | 0.073 | 0.923 | 0.086 | 0.053 | 2.102 |
| B | A + Phase 2, no anchor, no cross-time mix | 22.73 | 0.799 | 0.135 | 0.814 | 0.117 | 0.112 | 3.244 |
| C | B + L2-SP anchor + 25% cross-time mix | 24.94 | 0.881 | 0.070 | 0.935 | 0.084 | 0.054 | 2.032 |
| D | C + per-subject refinement (10K iters, Full) | 29.95 | 0.947 | 0.045 | 0.959 | 0.057 | 0.039 | 1.365 |
| E | D without residual head | 28.36 | 0.933 | 0.060 | 0.931 | 0.081 | 0.041 | 1.412 |
| F | D without Jacobian penalty | 28.72 | 0.937 | 0.040 | 0.952 | 0.061 | 0.042 | 1.874 |
| G | D with attention pooling instead of mean pooling | 29.46 | 0.948 | 0.047 | 0.907 | 0.062 | 0.036 | 1.374 |
The interpretation given in the paper is:
- Phase 2 without controls catastrophically forgets the CelebV-HQ distribution.
- Anchor + cross-time mix are jointly sufficient to recover the wide-identity prior while still learning multi-view geometry.
- Per-subject refinement produces the largest single jump in quality.
- Residual head removal hurts across all major metrics, showing it is load-bearing.
- Jacobian penalty removal substantially worsens AKD, confirming that view-direction leakage into geometry is a real issue.
- Attention pooling is competitive on a subset of metrics, but mean pooling is better overall and simpler.
The appendix also studies several training and scaling knobs. The best backbone is DINOv3-B as the knee of the quality/compute curve, with DINOv3-L giving only modest extra gains. The source-count study shows the largest jump from $K=1$ to $K=2$ and diminishing returns afterward. For training hyperparameters, the paper reports that the Phase-1 linear learning-rate schedule performs best, the Phase-1 base learning rate peaks around $2.5 \times 10^{-4}$, the Phase-2 encoder layer-wise decay performs best around $\gamma_{\text{LR}}=0.65$, and the Jacobian weight peaks sharply at $\lambda_{\text{jac}}=10^{-1}$.
The Phase-2 protection mechanisms are also isolated in a factorial ablation: the L2-SP anchor and the 25% cross-time mix each help on their own, but the combination is best. On the per-subject side, the anti-spike components are likewise complementary: removing scale freeze, removing the hard log-scale clamp, or removing the screen-space aspect penalty each causes a different type of anisotropy failure.
6. Limitations and future work
The paper is explicit about two main limitations inherited from the FLAME-mesh foundation. First, large accessories such as glasses and hats are not modeled explicitly and may be absorbed into the head texture. Second, the upstream tracker assumes that at least one source frame supports a successful frontal face detection. A third limitation is practical: even though the per-subject refinement is vastly faster than prior work, it still takes about 2 minutes, so true real-time avatar creation is limited to the feed-forward stage.
The stated future directions are to couple the system with audio and motion control for a fuller digital-human stack, and to extend the FLAME-bound Gaussian representation with body and hand sub-meshes for full-body avatars.
7. Bottom line
SpatialAvatar-0 is best understood as a unification paper: it shows that a single FLAME-mesh-bound Gaussian representation can support both zero-shot feed-forward avatar generation and short-horizon per-subject refinement. The feed-forward model is trained to generalize across source-count and domain shift; the refinement model is constrained to preserve the spatial layout and recover extra detail without expensive densification. Empirically, the result is strong cross-domain zero-shot performance on VFHQ/HDTF and state-of-the-art per-subject quality on SplattingAvatar, with major gains in efficiency.