EmoZone-Talker
EmoZone-Talker: Regional Semantic Control of Audio-Driven 3DGS Talking Heads via Facial Action Units
EmoZone-Talker enables fine-grained, anatomically interpretable control of facial expressions in audio-driven 3D Gaussian Splatting talking heads by disentangling spatial and temporal interactions of speech and facial Action Units, improving expression realism, controllability, and lip-sync accuracy.
Links
Paper & demos
Impact
Abstract
3D Gaussian Splatting (3DGS) has shown strong potential for high-fidelity talking head synthesis. However, enabling fine-grained, interpretable, and editable facial expression control remains fundamentally challenging due to intrinsic conflicts between speech-driven facial dynamics and explicit expression signals. Existing methods rely on implicit multimodal fusion, leading to spatial entanglement and temporal instability. We present EmoZone-Talker, a novel framework that reformulates audio-driven facial animation as a structured spatial-temporal coordination problem under cross-modal conflicts. Our approach introduces an explicit spatial disentanglement and temporal dynamics modeling of facial motion. Specifically, we propose Synergy Zones with Prioritized Attention Bias (SZ-PAB) to explicitly decouple modality contributions via region-wise constraints guided by anatomical priors, and a Channel-Independent Temporal AU Encoder (CIT-AE) to model temporally coherent AU dynamics. By integrating these representations into 3D Gaussian deformation, EmoZone-Talker enables precise and interpretable control over facial expressions. Extensive experiments demonstrate that our method improves expression controllability and realism, with notable gains in upper-face accuracy and temporal coherence, while preserving high rendering quality and accurate lip synchronization. Code will be publicly released to facilitate reproducibility and further research.
Overview and Problem Framing
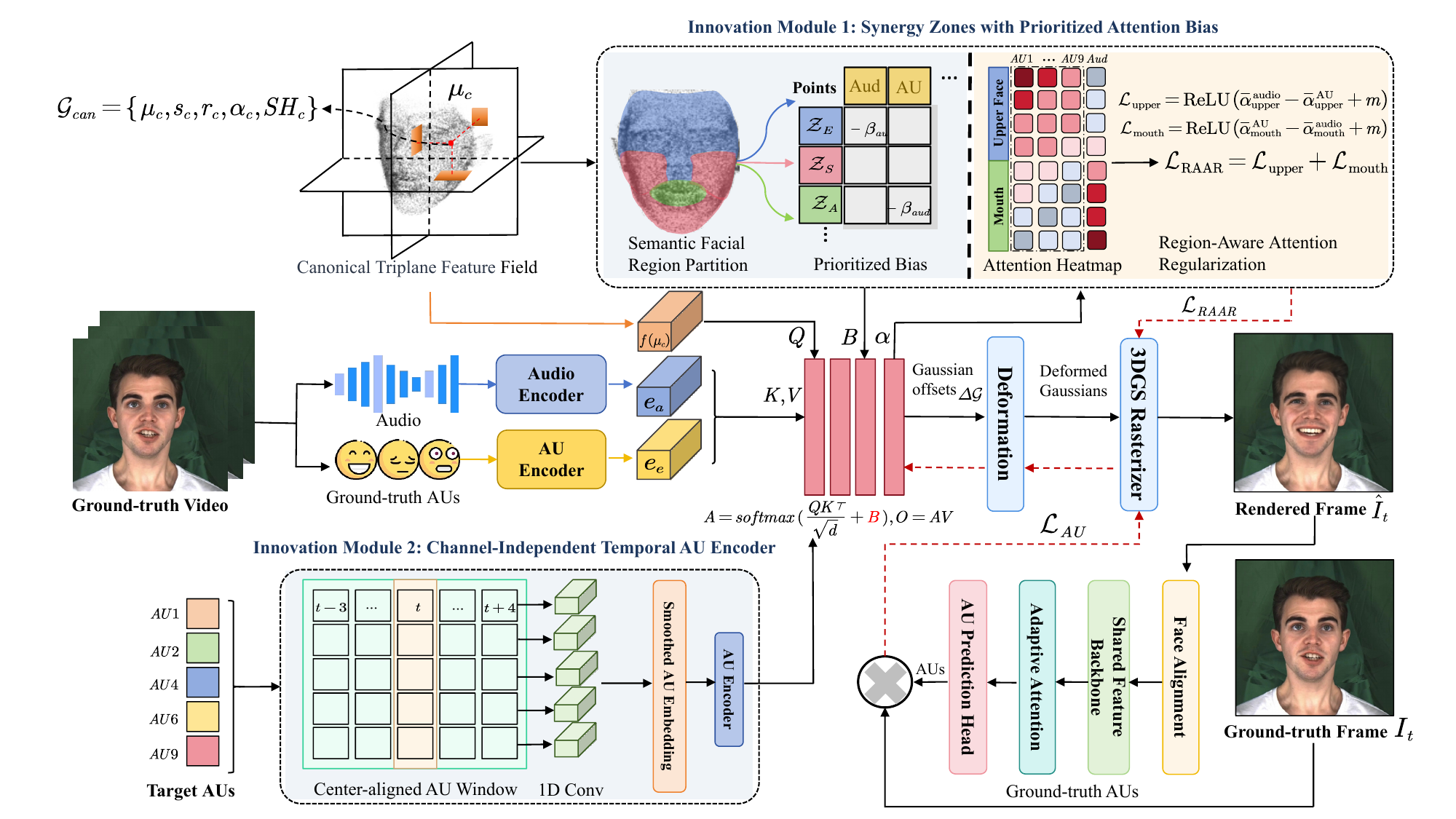
EmoZone-Talker addresses a specific gap in audio-driven 3D Gaussian Splatting (3DGS) talking-head synthesis: the field has largely optimized for photorealism and lip synchronization, but it still lacks an explicit, interpretable mechanism for fine-grained facial expression control. The paper argues that Action Units (AUs) are a better interface than global emotion labels because they are anatomically meaningful and spatially localized, but they also create a harder control problem: speech-driven articulation and AU-driven expression often affect overlapping facial regions, especially around the mouth, cheeks, jaw, eyebrows, eyes, and nose. The core claim is that this is not just a fusion problem, but a cross-modal conflict problem that must be handled with explicit spatial and temporal coordination.
The method is built around two ideas. First, it introduces Synergy Zones with Prioritized Attention Bias (SZ-PAB) to assign different facial regions different modality responsibilities, rather than mixing audio and AU signals implicitly across the whole face. Second, it introduces a Channel-Independent Temporal AU Encoder (CIT-AE) to smooth frame-level AU sequences into temporally coherent latent trajectories, reducing jitter and inconsistent motion. These representations are then injected into the 3DGS deformation pipeline, with an auxiliary AU-consistency branch used only during training.
Method Overview
The paper formulates the task as audio-driven facial animation with explicit AU control. The subject is represented by canonical 3D Gaussians, and a deformation network predicts per-frame Gaussian offsets from multimodal inputs: speech audio, AU features, and camera-related inputs. The method is designed for upper-face control in particular, because upper-face AUs such as AU1, AU2, AU4, AU6, and AU9 are weakly correlated with articulation but highly important for expressive motion.
The conceptual decomposition is:
$$y = f(x_{audio}, x_{AU})$$
where speech drives articulation and AUs explicitly drive expression. Instead of assuming that both signals can be fused uniformly, EmoZone-Talker introduces a region-wise factorization:
$$p(y \mid x_{audio}, x_{AU}) \approx \prod_r p(y_r \mid x_{audio}^{(r)}, x_{AU}^{(r)})$$
This reflects the paper’s main design principle: each facial region should preferentially attend to the modality that should dominate it, while transition regions can remain cooperative.
Synergy Zones with Prioritized Attention Bias (SZ-PAB)
SZ-PAB is the spatial disentanglement module. The face is partitioned into three semantically motivated zones using anatomical priors: an audio-dominant zone $\mathcal{Z}_A$ for the mouth, an expression-dominant zone $\mathcal{Z}_E$ for the upper face, and a synergy zone $\mathcal{Z}_S$ for transition regions. The paper uses these zone assignments to guide cross-attention so that mouth motion stays tied to speech, while AU control is concentrated in the upper face.
The attention rule is modified with a region-dependent bias:
$$\operatorname{Attn}(Q, K, V) = \operatorname{softmax}\left(\frac{QK^\top}{\sqrt{d}} + B\right)V$$
where $B$ encodes region-specific preference. In effect, AU tokens are suppressed in the audio-dominant mouth zone, and audio tokens are suppressed in the expression-dominant upper-face zone, while the synergy zone is left less constrained. The goal is not hard separation everywhere, but explicit responsibility assignment where conflicts are expected.
To further stabilize this behavior, the paper adds Region-Aware Attention Regularization (RAAR). Let $\alpha_{i,j}$ be the attention weight from Gaussian $i$ to token $j$. RAAR compares average attention response over the upper face and mouth regions, and imposes margin-based hinge losses so that upper-face regions prefer AU tokens over audio tokens, while mouth regions prefer audio tokens over AU tokens. The overall regularizer is written as:
$$\mathcal{L}_{RAAR} = \mathcal{L}_{upper} + \mathcal{L}_{mouth}$$
Channel-Independent Temporal AU Encoder (CIT-AE)
CIT-AE addresses temporal conflict. The paper observes that frame-level AU estimates are noisy and fluctuate over time, which can produce jittery facial motion if injected directly into the deformation model. It models each AU vector as a noisy observation:
$$\mathbf{a}_t = \mathbf{s}_t + \boldsymbol{\epsilon}_t$$
where $\mathbf{s}_t$ is the smooth underlying expression trajectory and $\boldsymbol{\epsilon}_t$ is high-frequency noise. Instead of using $\mathbf{a}_t$ directly, CIT-AE builds a center-aligned temporal window:
$$\mathbf{A}_t = [\mathbf{a}_{t-h}, \dots, \mathbf{a}_t, \dots, \mathbf{a}_{t+h-1}] \in \mathbb{R}^{T \times K}$$
and produces a refined center-frame embedding $\tilde{\mathbf{a}}_t \in \mathbb{R}^K$. The key design choice is that the channels are modeled independently, which reduces cross-channel interference while still leveraging local temporal context. The intended effect is a learnable temporal filter that suppresses high-frequency jitter and keeps expression transitions coherent.
AU Consistency Supervision
The architecture includes a training-only AU-consistency branch to ensure that the generated frames actually reflect the requested expression semantics. Ground-truth AU labels $\mathbf{a}^{gt}_t$ are extracted with a pretrained AU detector, and the rendered frame $\hat{I}_t$ is evaluated by a pretrained JAA network to obtain predicted AU responses:
$$\hat{\mathbf{a}}_t = \Psi_{JAA}(\hat{I}_t)$$
The AU loss is then:
$$\mathcal{L}_{AU} = \|\hat{\mathbf{a}}_t - \mathbf{a}^{gt}_t\|_1$$
This branch does not add inference cost; it acts as an external semantic constraint during training so that the deformation network cannot ignore AU inputs or collapse them into the speech branch.
Training Objective
The total objective combines reconstruction fidelity, lip synchronization, AU consistency, and region-aware regularization:
$$\mathcal{L}_{total} = \mathcal{L}_{rec} + \lambda_{sync}\mathcal{L}_{sync} + \lambda_{AU}\mathcal{L}_{AU} + \lambda_{RAAR}\mathcal{L}_{RAAR}$$
The paper states that $\mathcal{L}_{rec}$ enforces photometric and perceptual consistency, $\mathcal{L}_{sync}$ uses SyncNet for speech-lip alignment, $\mathcal{L}_{AU}$ enforces AU semantics, and $\mathcal{L}_{RAAR}$ regularizes region-wise attention. The reported weights are $\lambda_{sync}=0.1$, $\lambda_{AU}=0.05$, and $\lambda_{RAAR}=0.01$.
Experimental Setup
The experiments are conducted on two datasets. For self-reconstruction, the paper follows the TalkingGaussian protocol and uses the neutral subset containing Obama, May, Lieu, and Macron. For emotion-conditioned generation, it uses MEAD, which is a large-scale multi-view emotional talking-head dataset with 60 speakers, 8 emotion categories, and 3 intensity levels. Videos are resized to $256\times256$ at 25 FPS, and audio is sampled at 16 kHz.
For AU annotations, the paper uses JAANet during training and OpenFace for evaluation, with the latter chosen to align with prior work and maintain unbiased comparisons.
Implementation details are brief but concrete: the model is implemented in PyTorch, optimized with Adam, trained in a coarse stage followed by a fine stage for lip and depth refinement, and the learning rate decays exponentially from $10^{-4}$ to $10^{-5}$. Gaussian densification is performed every 100 iterations between 1k and 7k steps.
The evaluation suite is designed to cover multiple axes of quality:
- Rendering fidelity: SSIM, PSNR, and LPIPS.
- Synchronization and geometry: SyncNet confidence (Sync) and landmark distance (LMD).
- Expression controllability: AUE-U and AUE-L for AU reconstruction in upper and lower regions.
- Temporal stability: AU-Jerk, defined as the average second-order derivative of AU trajectories.
- Emotion-conditioned generation: E-Score from a pretrained emotion classifier.
- Identity preservation: cosine similarity (CSIM).
Baselines
For self-reconstruction, the paper compares against ER-NeRF, GaussianTalker, and TalkingGaussian. For emotion-conditioned generation, it compares against StyleTalk, EAT, DreamTalk, and DICE-Talk. The comparison set intentionally spans both reconstruction-oriented methods and emotion-aware methods so that the paper can test whether AU-level control helps without sacrificing lip synchronization or fidelity.
Quantitative Results
Self-Reconstruction
On the neutral subset and on MEAD, EmoZone-Talker reports the best overall performance on most metrics, especially the AU-specific measures. The paper emphasizes that the main gain is not only higher image quality, but a much better balance between upper-face expression control and speech synchronization.
| Method | PSNR | SSIM | LPIPS | LMD | Sync | CSIM | AUE-U / AUE-L | PSNR | SSIM | LPIPS | LMD | Sync | CSIM | AUE-U / AUE-L |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ER-NeRF | 33.059 | 0.935 | 0.027 | 2.269 | 5.554 | 0.930 | 0.271 / 0.228 | 31.156 | 0.931 | 0.033 | 2.649 | 4.492 | 0.864 | 0.355 / 0.376 |
| GaussianTalker | 33.023 | 0.939 | 0.033 | 2.306 | 5.741 | 0.946 | 0.256 / 0.228 | 31.952 | 0.946 | 0.047 | 2.410 | 4.823 | 0.913 | 0.338 / 0.330 |
| TalkingGaussian | 33.637 | 0.940 | 0.026 | 2.013 | 5.919 | 0.945 | 0.206 / 0.223 | 32.769 | 0.942 | 0.029 | 2.074 | 4.794 | 0.914 | 0.163 / 0.314 |
| EmoZone-Talker | 34.732 | 0.952 | 0.030 | 1.951 | 5.849 | 0.956 | 0.156 / 0.199 | 33.940 | 0.957 | 0.038 | 1.852 | 5.228 | 0.944 | 0.145 / 0.258 |
The paper’s main interpretation is that explicit region-aware disentanglement substantially improves upper-face accuracy. On the neutral dataset, EmoZone-Talker reaches AUE-U/AUE-L of $0.156/0.199$, compared with TalkingGaussian’s $0.206/0.223$. On MEAD, it achieves $0.145/0.258$, again better than the baselines. The paper also reports real-time performance at 110.5 FPS, comparable to GaussianTalker and TalkingGaussian, while remaining much faster than ER-NeRF.
One notable nuance is that the method does not maximize every single rendering metric: for example, TalkingGaussian is slightly better on LPIPS in some settings, and it remains competitive on lip synchronization. The advantage of EmoZone-Talker is therefore best understood as a better overall balance, especially on controllability, upper-face reconstruction, and identity preservation.
Emotion-Conditioned Generation
On the emotion subset of MEAD, the AU-conditioned design outperforms emotion-label-based or global emotion methods by a clear margin. The paper attributes this to the fact that AUs correspond to specific muscle activations, while global emotion categories only approximate a facial state distribution.
| Method | E-Score | Neutral | Non-neutral | CSIM |
|---|---|---|---|---|
| StyleTalk | 0.383 | 0.392 | 0.378 | 0.632 |
| EAT | 0.552 | 0.368 | 0.613 | 0.616 |
| DreamTalk | 0.526 | 0.585 | 0.501 | 0.606 |
| DICE-Talk | 0.311 | 0.329 | 0.305 | 0.651 |
| EmoZone-Talker | 0.653 | 0.601 | 0.685 | 0.841 |
The strongest result here is the identity score: EmoZone-Talker’s CSIM of $0.841$ is far above the baselines, indicating that AU-level control can preserve identity more effectively than holistic emotion conditioning. Its E-Score is also the best overall, with strong performance on both neutral and non-neutral cases. The paper interprets this as evidence that fine-grained muscle-level control better captures real emotional expression than categorical emotion embeddings.
Qualitative Results

In self-reconstruction, the paper shows that prior methods often produce visible lip articulation errors, particularly at phonetic moments where the mouth should open more clearly. ER-NeRF is described as exhibiting clear lip deformation in some phonemes, while GaussianTalker and TalkingGaussian can produce mismatched lip motion in the highlighted mouth regions. EmoZone-Talker is qualitatively better at maintaining both speech alignment and facial detail, supporting the quantitative Sync and LMD gains.

In emotion-controlled generation, the paper highlights that some baselines can create emotional faces but often fail to coordinate local action units with the target affect. StyleTalk and DreamTalk produce generic emotions, EAT improves global emotional conveyance but still lacks local coordination, and DICE-Talk can become over-smoothed or overly exaggerated in the mouth region. EmoZone-Talker better preserves lip articulation while rendering clearer emotion cues.
Ablation Studies
The ablation section is important because it isolates the paper’s central claims: AU conditioning alone is not enough, and both spatial decoupling and temporal modeling are necessary. The authors evaluate four configurations: an audio-only baseline, audio plus AU conditioning, AU conditioning with SZ-PAB, and AU conditioning with CIT-AE. The full model combines all three.
| Config | AU Cond | SZ-PAB | CIT-AE | PSNR | LPIPS | Sync | AUE-U | AUE-L | AU-Jerk |
|---|---|---|---|---|---|---|---|---|---|
| (A) | - | - | - | 32.879 | 0.042 | 5.741 | 0.309 | 0.314 | 0.137 |
| (B) | ✓ | - | - | 31.795 | 0.046 | 5.378 | 0.324 | 0.358 | 0.153 |
| (C) | ✓ | ✓ | - | 33.947 | 0.037 | 5.569 | 0.152 | 0.235 | 0.126 |
| (D) | ✓ | - | ✓ | 33.921 | 0.039 | 5.571 | 0.305 | 0.276 | 0.098 |
| EmoZone-Talker | ✓ | ✓ | ✓ | 33.960 | 0.034 | 5.712 | 0.143 | 0.231 | 0.095 |
The ablation results make two points very clear. First, simply adding AU conditioning without region decoupling hurts performance: configuration (B) has worse PSNR than the audio-only baseline and substantially worse AU errors, which the paper interprets as cross-modal interference. Second, each proposed module fixes a different failure mode. SZ-PAB sharply lowers upper-face error by separating speech and AU responsibilities, while CIT-AE reduces AU-Jerk by smoothing temporal fluctuations. The full model is best overall because the two modules are complementary rather than redundant.

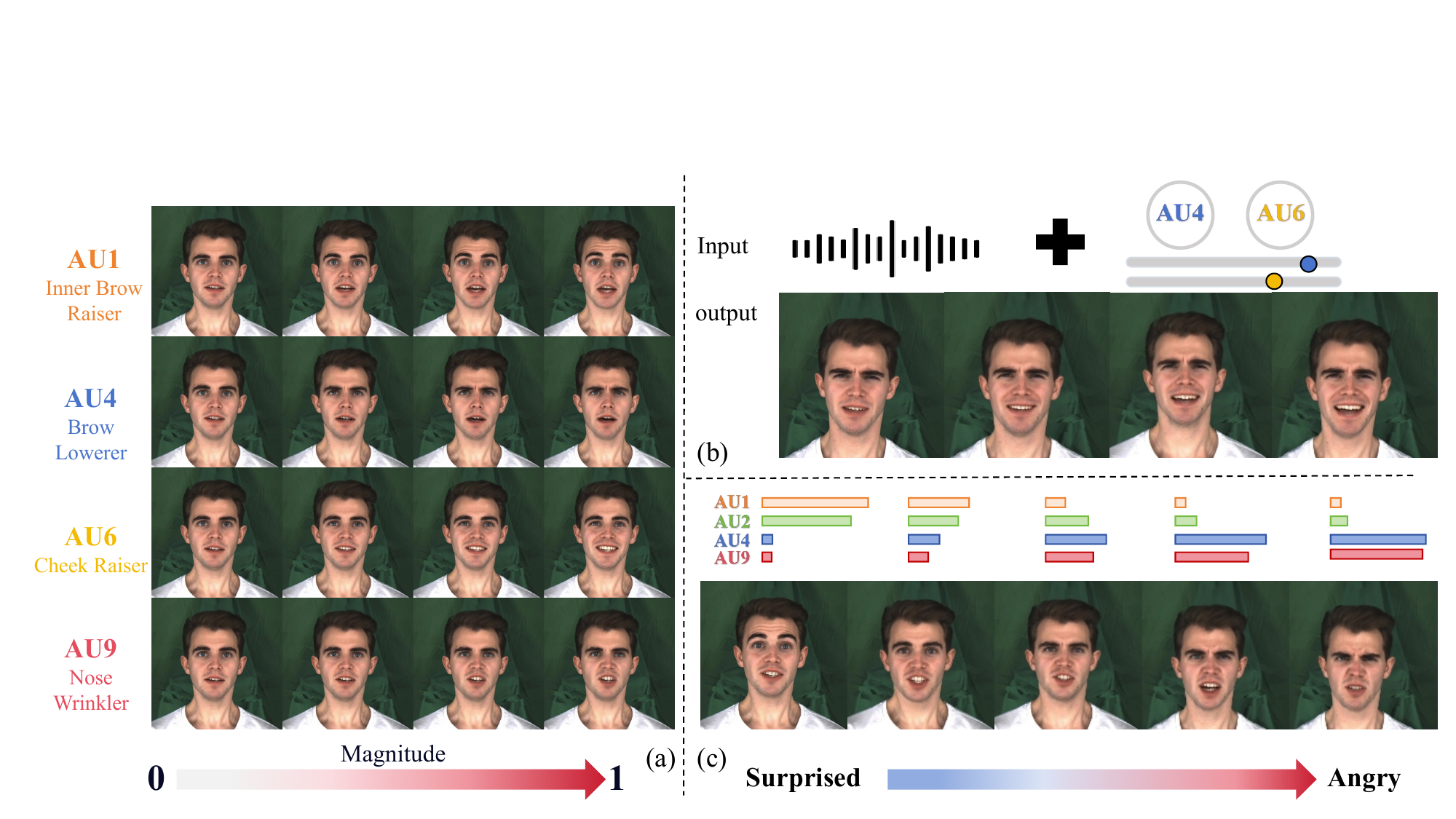
Figure 5 visualizes the effect of removing SZ-PAB across several AUs. With the full model, AU1 and AU2 produce visible brow elevation, AU4 generates brow lowering with wrinkles, AU6 raises the cheeks, and AU9 activates nose wrinkling. Without SZ-PAB, these upper-face activations largely disappear, which supports the paper’s claim that AU conditioning becomes suppressed when the model is forced to learn everything implicitly.
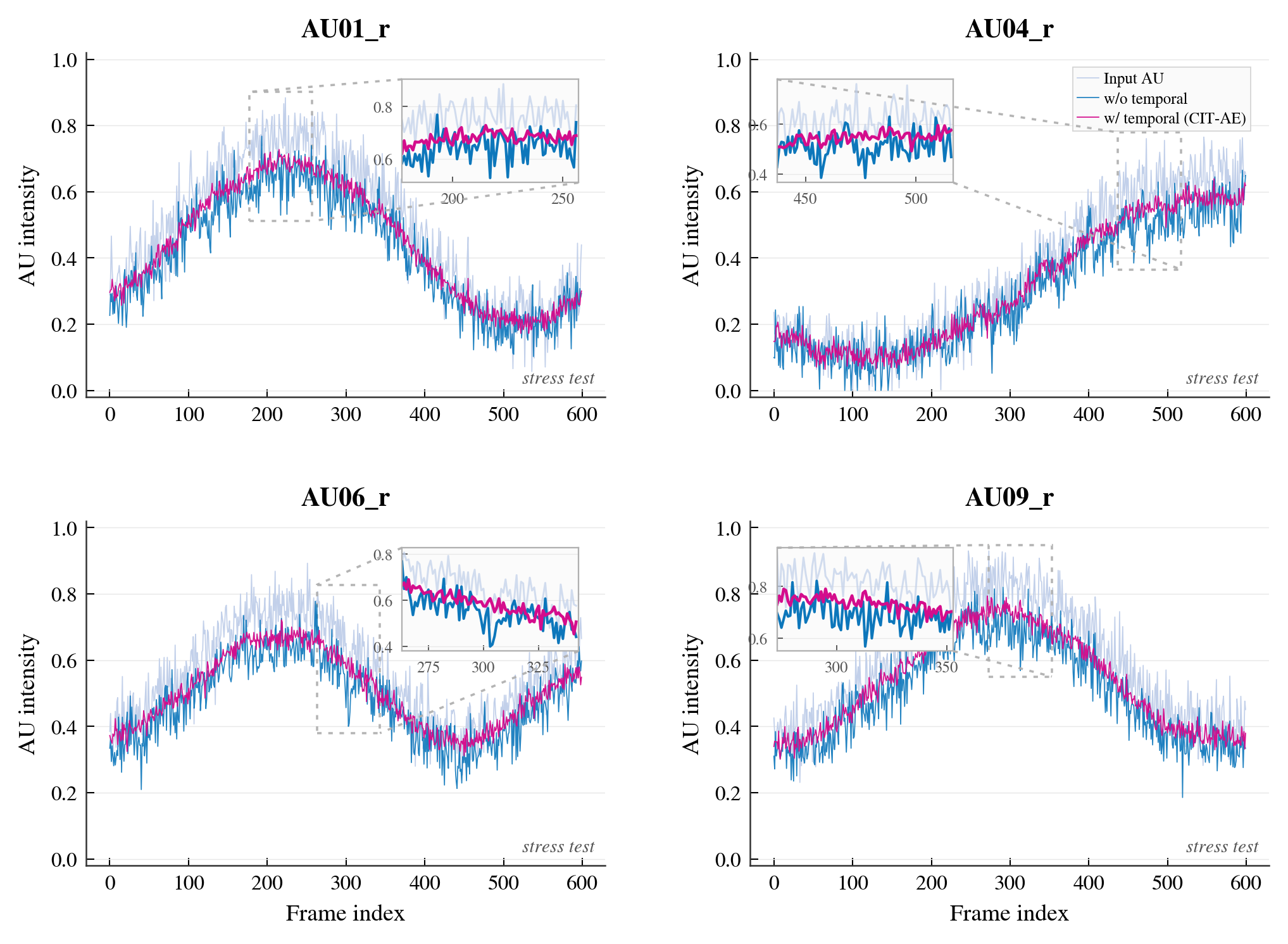
Figure 6 stress-tests the model with noisy AU inputs. The paper shows that the output without temporal modeling follows the noisy input too closely and remains jittery, while CIT-AE produces much smoother trajectories that preserve the underlying intensity trends. This is important because real AU detectors are not perfectly stable frame to frame.
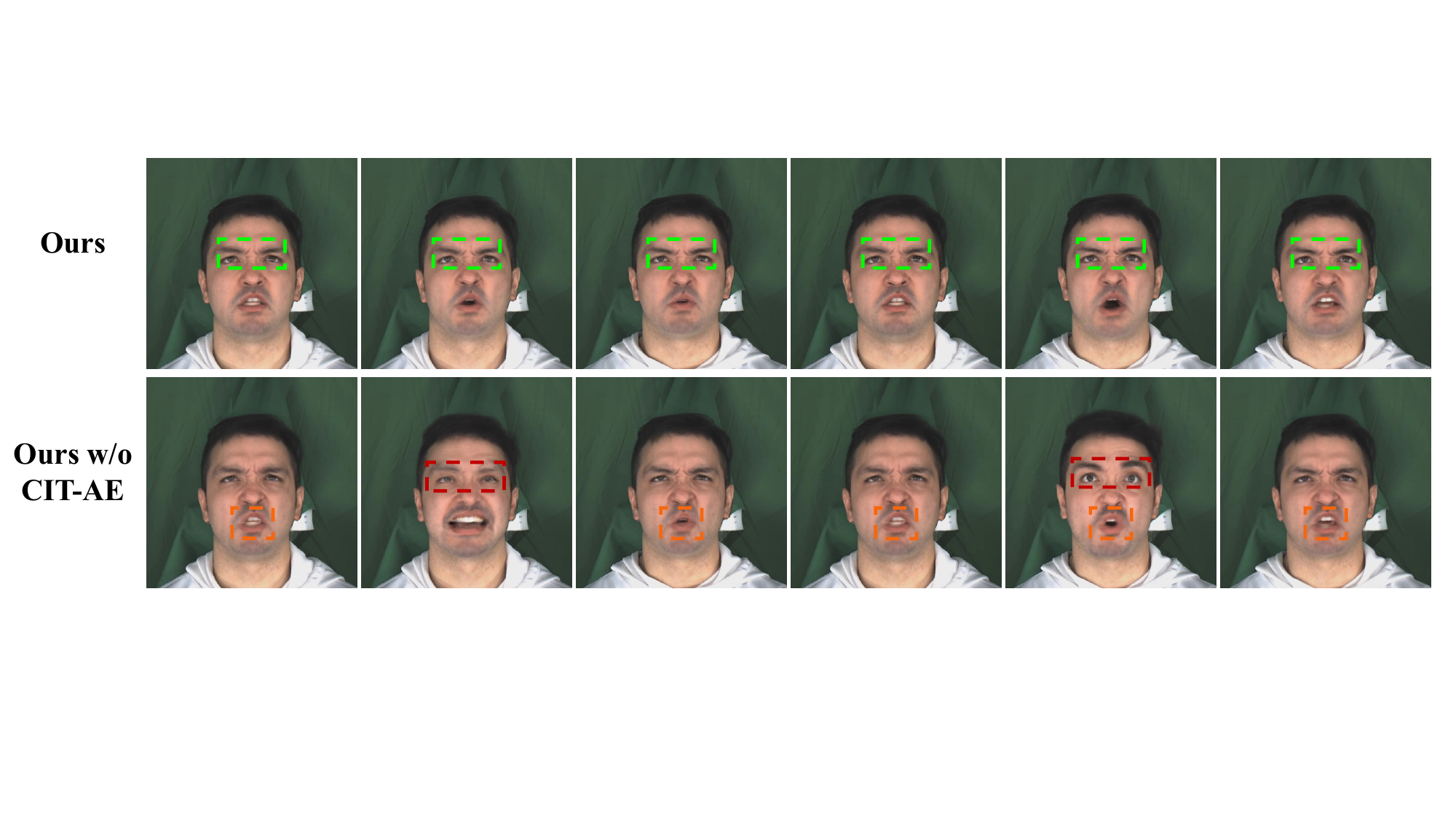
Figure 7 further demonstrates the importance of CIT-AE. Without it, the upper-face activations become erratic and temporal blur appears, especially under noisy AU control. The full model remains stable and preserves sharper facial motion over time.
User Study
The paper also reports a user study with 20 participants, evenly split by gender, who rated videos on a 5-point Likert scale across five dimensions: quality, emotion, lip synchronization, identity, and naturalness. EmoZone-Talker received the best score in every category.
| Method | Quality | Emotion | Lip Sync | Identity | Naturalness |
|---|---|---|---|---|---|
| StyleTalk | 3.38 | 2.68 | 3.65 | 2.34 | 2.98 |
| EAT | 3.62 | 3.24 | 3.62 | 3.53 | 3.19 |
| DreamTalk | 3.45 | 3.19 | 3.65 | 3.65 | 3.47 |
| DICE-Talk | 3.12 | 2.82 | 3.45 | 2.47 | 3.21 |
| EmoZone-Talker | 4.33 | 3.89 | 3.67 | 4.67 | 4.28 |
The strongest human-rated gains are in identity and naturalness, which is consistent with the method’s explicit decoupling of expression control from speech-driven articulation. The paper uses this to reinforce the idea that AU-level control is not just more interpretable, but also perceptually more natural when done with region awareness and temporal smoothing.
Limitations
The paper explicitly notes one limitation: facial actions are not strictly independent in practice. Some expression-related AUs, such as AU6, can naturally influence the mouth region because of shared muscle structures. As a result, strong expressions may still produce minor artifacts. The authors frame handling such anatomically coupled effects as an important direction for future work.
Takeaway
EmoZone-Talker’s main contribution is a structured way to think about emotional talking-head generation under conflict: instead of mixing speech and expression signals implicitly, it separates where each signal should act and how expression should evolve over time. In practice, this yields better AU controllability, better temporal stability, strong lip synchronization, and improved identity preservation, while staying efficient enough for real-time rendering.