SiGnature
SiGnature: Explicit Motion Diffusion for Stylized Semantic Gesture
SiGnature generates co-speech gestures that are semantically meaningful and stylistically faithful to the speaker by explicitly modeling motion in joint-rotation space. It injects semantic gestures during inference without retraining, preserving personalized style while smoothly integrating precise semantic motions.
Demos
The OpenTMA demos showcase text-motion alignment across datasets like HumanML3D, Motion-X, and UniMoCap. Evaluate the generated motions for realistic, stylized gestures that semantically match the text input. The demos highlight the integration of text and motion encoders for expressive and well-aligned human motion synthesis.
Links
Paper & demos
Impact
Abstract
While recent advances in co-speech gesture generation have achieved impressive rhythmic synchronization, synthesizing gestures that are both semantically meaningful and faithful to a speaker's unique non-verbal style remains an open challenge. Semantic gestures, such as iconic shapes or deictic pointing, are statistically sparse, making them difficult to learn effectively within standard generative models. We present SiGnature, a framework for Stylized and Semantic Gesture generation that reconciles precise semantic control with high-fidelity style preservation. Unlike prevalent methods that rely on entangled latent representations, SiGnature operates in an explicit joint-rotation space. This design enables our core contribution, Joint Motion Integration (JMI), a training-free inference mechanism capable of injecting any external motion sequence, particularly in-the-wild semantic gestures, directly into the diffusion process. JMI automatically identifies the specific ``active joints'' conveying a semantic action and injects them into the generation, while relying on the diffusion backbone to synthesize the remaining body dynamics, including posture and flow, in accordance with the pre-learned style of the target speaker. This allows for the plug-and-play integration of arbitrary motions, including complex semantic gestures, without retraining or introducing the ``Frankenstein'' artifacts typical of cut-and-paste methods. Extensive experiments and perceptual studies demonstrate that SiGnature offers superior semantic motion control while maintaining smooth and natural co-speech gesture generation and preserving the distinct characteristics of the speaker, thereby outperforming state-of-the-art baselines.
1. Problem Setting and Core Idea
SiGnature addresses a specific but important gap in co-speech gesture generation: modern systems can often produce gestures that are rhythmically aligned with speech, but they still struggle to generate gestures that are both semantically meaningful and faithful to a speaker’s distinctive non-verbal style. The paper argues that this failure is especially severe for long-tailed semantic gestures such as iconic shapes, metaphoric gestures, and deictic pointing, which are sparse in training corpora and therefore poorly represented by standard end-to-end generative models.
The main design choice is to abandon compressed latent motion spaces for generation and editing, and instead model motion directly in an explicit joint-rotation representation. This enables joint-level controllability and makes it possible to inject external semantic motion clips without retraining the generator. The resulting framework has two parts: a multimodal diffusion backbone for co-speech generation, and a training-free inference-time editor called Joint Motion Integration (JMI) for semantic motion injection.
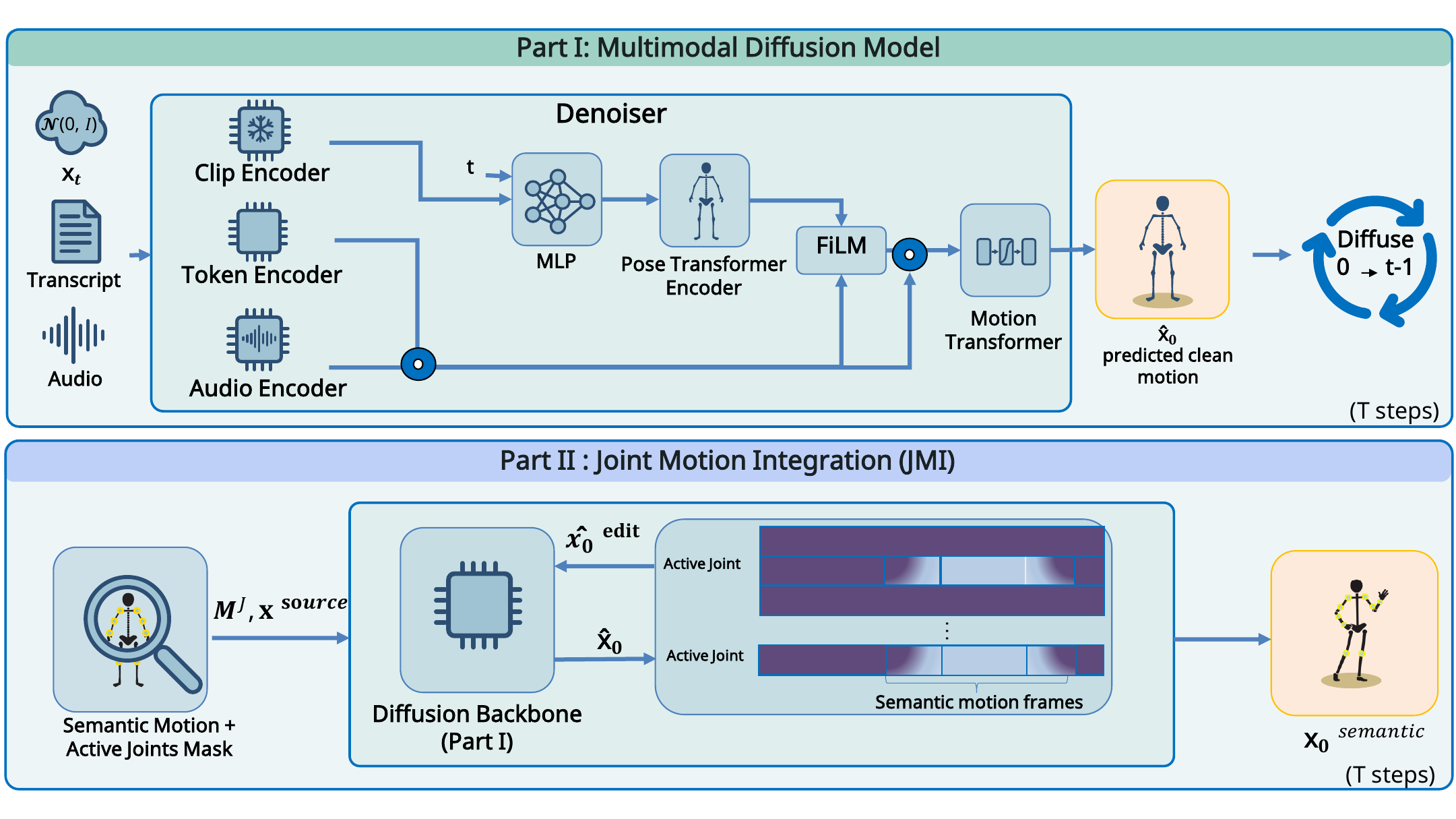
2. Representation and Diffusion Backbone
The backbone operates on full-body motion represented in SMPL-X rotation space. For each frame $n$, the paper defines local joint rotations $\mathbf{r}_n \in \mathbb{R}^{J \times 6}$ using the 6D continuous rotation representation, the root translation $\mathbf{p}_n \in \mathbb{R}^3$, and binary foot-contact flags $\mathbf{f}_n \in \{0,1\}^4$. These are concatenated into a per-frame vector
$$ \mathbf{x}_n = [\operatorname{vec}(\mathbf{r}_n),\ \mathbf{p}_n,\ \mathbf{f}_n] \in \mathbb{R}^{C}, $$ where $C = 6J + 3 + 4$, and a sequence is formed as $\mathbf{x} \in \mathbb{R}^{N \times C}$.
Co-speech conditioning uses three streams: frame-level transcript tokens $\mathbf{s}_{1:N}$, raw audio $\mathbf{a}_{1:N_a}$, and a global sentence embedding $\mathbf{g}$ extracted from a frozen CLIP text encoder. The model explicitly separates global semantic intent from local prosody.
The denoising process follows standard Gaussian diffusion:
$$ q(x_t \mid x_{t-1}) = \mathcal{N}\!\bigl(\sqrt{1-\beta_t}\,x_{t-1},\ \beta_t \mathbf{I}\bigr), \quad t=1,\dots,T. $$
A transformer denoiser predicts the clean motion directly:
$$ \hat{x}_0 = f_\theta(x_t, t, \mathbf{a}_{1:N_a}, \mathbf{s}_{1:N}, \mathbf{g}). $$
The training objective combines three terms in rotation space:
$$ \mathcal{L} = \mathcal{L}_{\text{rec}} + \lambda_{\text{vel}}\mathcal{L}_{\text{vel}} + \lambda_{\text{fc}}\mathcal{L}_{\text{foot}}. $$
Here $\mathcal{L}_{\text{rec}}$ reconstructs rotations with an $\ell_2$ loss, $\mathcal{L}_{\text{vel}}$ matches rotation velocities $v_k = r_k - r_{k-1}$, and $\mathcal{L}_{\text{foot}}$ penalizes foot sliding when contact is active. The implementation uses $\lambda_{\text{vel}} = 100$ and $\lambda_{\text{fc}} = 50$.
2.1 Conditioning design
The model uses a dual-stream conditioning scheme. The global CLIP sentence embedding is projected and added to the diffusion timestep embedding, then appended as a global context token. This biases the full denoising trajectory toward sentence-level meaning. In parallel, audio and transcript tokens are encoded with lightweight modules and concatenated into a local condition vector $\mathbf{c}$. That local stream drives a FiLM module that predicts time-varying scale and shift parameters, and the conditioned hidden state is updated as
$$ \mathbf{h}'_t = \mathbf{h}_t \odot (1 + \Gamma_t) + B_t. $$
The modulated hidden features are then concatenated with the local condition features before later self-attention layers. This is intended to couple amplitude, emphasis, and timing from audio/text with the motion synthesis process while preserving explicit joint-level generation.
2.2 Long-form generation with overlapping windows
To generate sequences of arbitrary length, SiGnature uses overlapping windows of length $W$ with overlap $H$. The paper follows the Double-Take strategy: windows are processed together in a shared batch, and after each denoising step the overlapping region is linearly blended with a handshake operation to avoid temporal drift and discontinuities. In the implementation, $W=196$ and $H=30$.
The paper reports that this explicit-space backbone can be sampled with different DDIM step counts, trading speed for quality: 1,000 steps, 100 steps, and 20 steps are all evaluated.
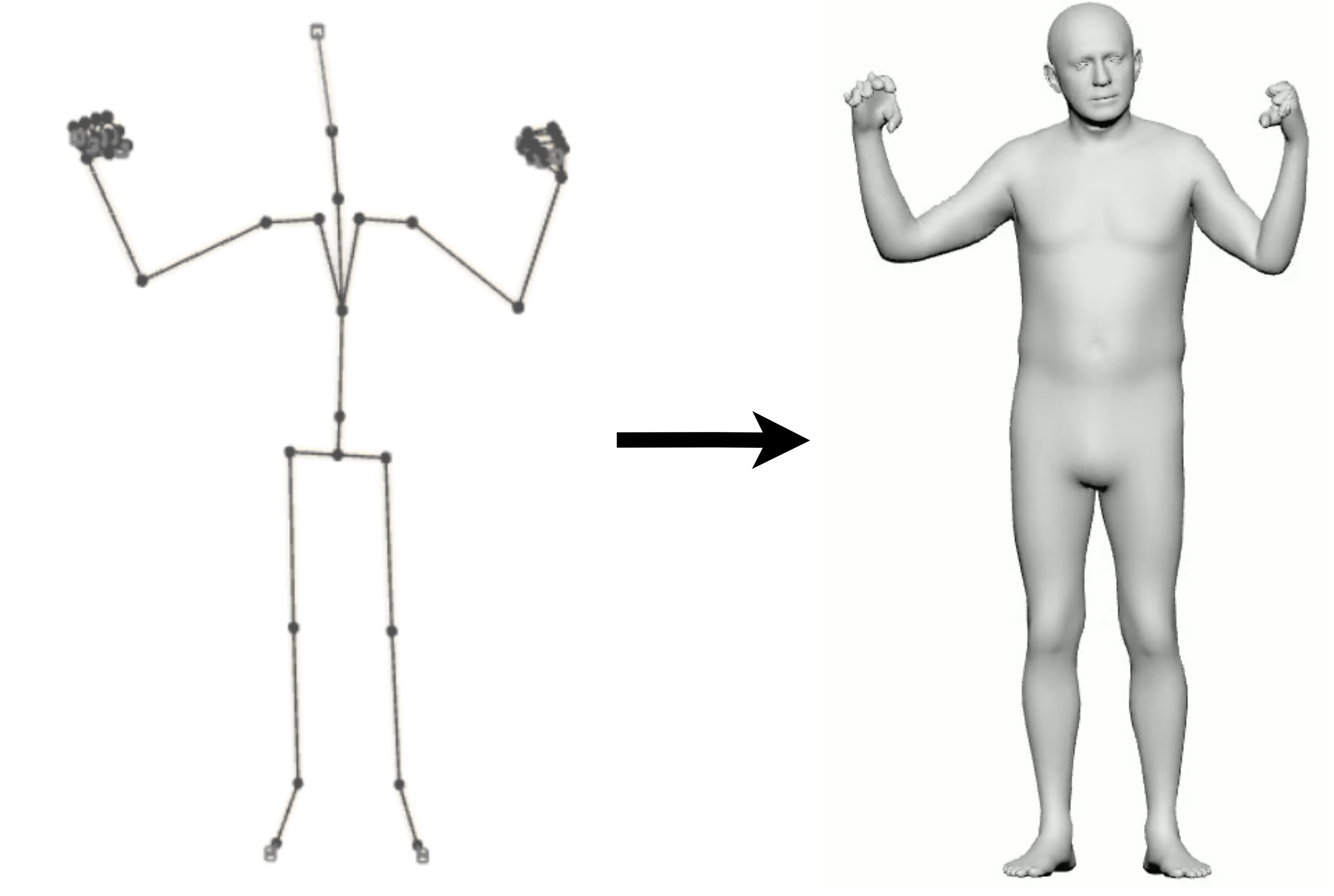
3. Joint Motion Integration (JMI)
JMI is the paper’s main semantic-editing contribution. It is explicitly training-free: at inference time, the diffusion backbone is augmented with an external semantic gesture clip, but only the joints that actually carry the semantic action are injected. The core motivation is that semantic meaning is usually conveyed by a localized subset of joints, while the rest of the body should remain under the control of the personalized diffusion prior so that the speaker’s style is preserved.
3.1 Active-joint masking
For each semantic source clip, the method precomputes an active-joint mask by thresholding kinematic variance. Joints with substantial motion, along with their kinematic parents, are marked active; low-variance joints are left unmodified. The authors note that manual masks can be used as a fallback for near-static clips or other edge cases.
This design is crucial because naive injection of a full-body clip would overwrite the target speaker’s posture and style and create cut-and-paste artifacts. The paper’s terminology for those failures is the kind of “Frankenstein” motion produced by unmasked compositing.
3.2 Semantic gesture selection and timing
The pipeline aligns speech and transcript with word-level timestamps, producing tuples $\{(w_i, s_i, e_i)\}_{i=1}^M$ where $w_i$ is a word and $s_i, e_i$ are its start and end times. Candidate semantic gestures can be selected manually or automatically. In the reported pipeline, the authors use a zero-shot LLM call to annotate the transcript with gesture tags, using a gesture dictionary that contains names, textual descriptions, contextual meaning, and examples. The appendix gives a prompt adapted from Semantic Gesticulator and shows example annotations.
For each tagged word, the corresponding gesture clip $G^m$ of length $L_m$ is centered at the midpoint of the annotated word, giving an injection interval
$$ \left[\frac{s_k+e_k}{2} - \frac{L_m}{2},\ \frac{s_k+e_k}{2} + \frac{L_m}{2}\right]. $$
Each edit specification includes the active-joint mask, the timing interval, the source gesture, the injection strength $\lambda_{\mathrm{inj}} \in [0,1]$, and the blending window $B_{\mathrm{blend}}$.
3.3 Per-step joint-space intervention
During sampling, at each diffusion step the denoiser predicts a clean motion $\hat{x}_0$. For each tagged gesture intersecting the current temporal window, the source clip is cropped and blended into the prediction using a spatiotemporal mixing matrix
$$ \Phi = \lambda_{\mathrm{inj}} (M^m \otimes \tau) \in [0,1]^{6J \times L}, $$
where $M^m$ is the active-joint mask and $\tau$ is a trapezoidal temporal profile with linear ramps of length $B_{\mathrm{blend}}$ at the boundaries. The edited motion is computed as
$$ \hat{x}_0^{\text{edit}}[:6J, s_k^w:e_k^w] \leftarrow (1-\Phi) \odot \hat{x}_0[:6J, s_k^w:e_k^w] + \Phi \odot G^m_{\mathrm{crop}}. $$
The modified prediction then replaces the original one in the DDIM posterior update. The key point is that only the active joints and the relevant frames are pulled toward the source gesture, while the rest of the body continues to be synthesized by the personalized diffusion prior. The paper emphasizes that this per-step harmonization is important: a single posthoc injection is noticeably worse than stepwise editing.
3.4 Generalization and composition
JMI is source-agnostic: any SMPL-X motion sequence can be injected if timing annotations are available. The joint-wise mask also supports composition of multiple non-conflicting gestures, such as simultaneously injecting an upper-body wave and a lower-body jump. This is presented as an advantage over latent-space blending, which is more likely to leak style or distort motion statistics.

4. Implementation Details
The motion representation uses a 55-joint SMPL-X rig at 30 FPS. Training uses temporal windows of size $W=196$. The backbone is an 8-layer Transformer with hidden size 512. It is pretrained on AMASS and then fine-tuned separately for each target identity on BEAT2. Optimization uses AdamW with learning rate $10^{-4}$. Training runs on a single NVIDIA RTX 3090 GPU; the paper reports roughly 24 hours for base pretraining and about 90 minutes of fine-tuning per subject.
At inference, the authors use DDIM sampling with $T=1000$ steps, handshake overlap $H=30$, default injection strength $\lambda_{\mathrm{inj}}=0.65$, and blend window $B_{\mathrm{blend}}=10$. They also report results at 100 and 20 steps to illustrate the speed-quality tradeoff.
5. Datasets and Preprocessing
AMASS is used for motion prior pretraining. The paper describes it as a large archive with more than 40 hours of motion capture from over 300 subjects and about 11,000 sequences. Although AMASS contains no speech, it gives the diffusion backbone a robust kinematic prior and improves physical plausibility.
BEAT2 is used for co-speech fine-tuning. The paper fine-tunes a separate personalized model for each of five selected speakers: Scott, Ayana, Wayne, Lawrence, and Sophie. Approximately 90 minutes of training data per subject are used. The authors also re-transcribe the selected BEAT2 subsets with Whisper ASR to obtain better transcript alignment.
SeG provides the semantic gesture bank used by JMI. It is a curated subset of Semantic Gesticulator with over 200 distinct semantic gestures spanning iconic, metaphoric, and deictic motions. The source motions are in BVH format, so the paper builds a custom BVH-to-SMPL-X retargeting pipeline.
The appendix describes the retargeting process in detail: BVH parsing and joint mapping to SMPL-X, scale and root alignment, 30 FPS resampling, optional IK cleanup and temporal smoothing, and final export into the SMPL-X 6D rotation format. This retargeting is shape-agnostic and designed to produce a unified $T \times 55 \times 6$ representation.
6. Experimental Setup
The evaluation is split into two roles: the backbone as a general co-speech generator, and JMI as a semantic injection mechanism. The paper uses both quantitative metrics and perceptual studies.
The reported metrics are:
- FGD for feature-space realism.
- Diversity for variability in generated gestures.
- Beat Consistency (BC) for audio-motion synchronization.
- Mean absolute jerk and mean absolute acceleration for kinematic smoothness.
- Mean Joint Position Error (MPJPE) for semantic reconstruction fidelity.
- Cross-identity FGD for style preservation under semantic injection.
The backbone is compared against EMAGE, SynTalker, and GestureLSM. For semantic injection, JMI is compared against Semantic Gesticulator, naive in-betweening that forces the source motion onto all joints, and a single-step JMI variant that only injects at the final step. The paper also uses a SynTalker VQ-VAE reconstruction baseline to quantify the loss introduced by latent codebooks on out-of-distribution semantic gestures.
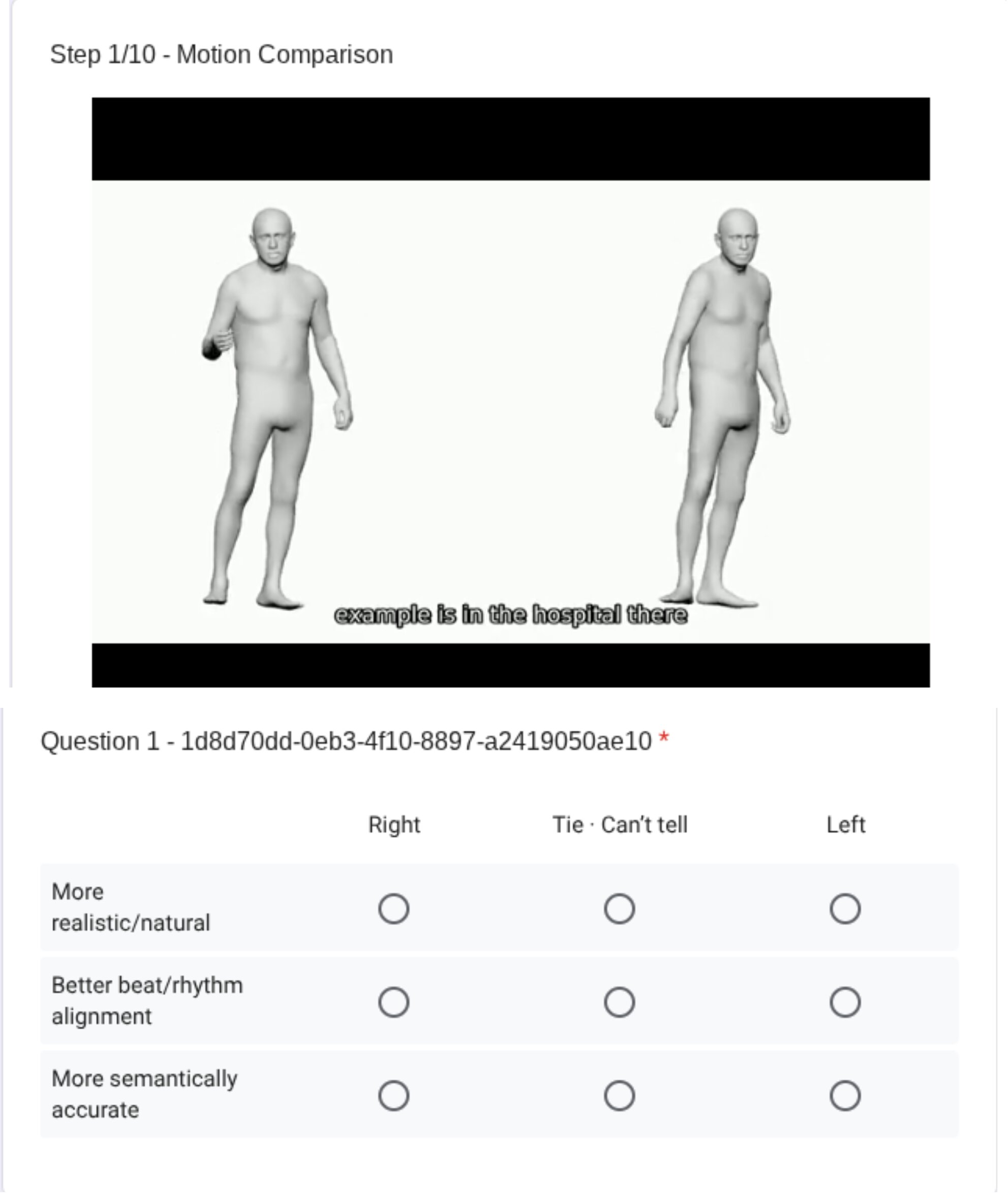
6.1 Perceptual studies
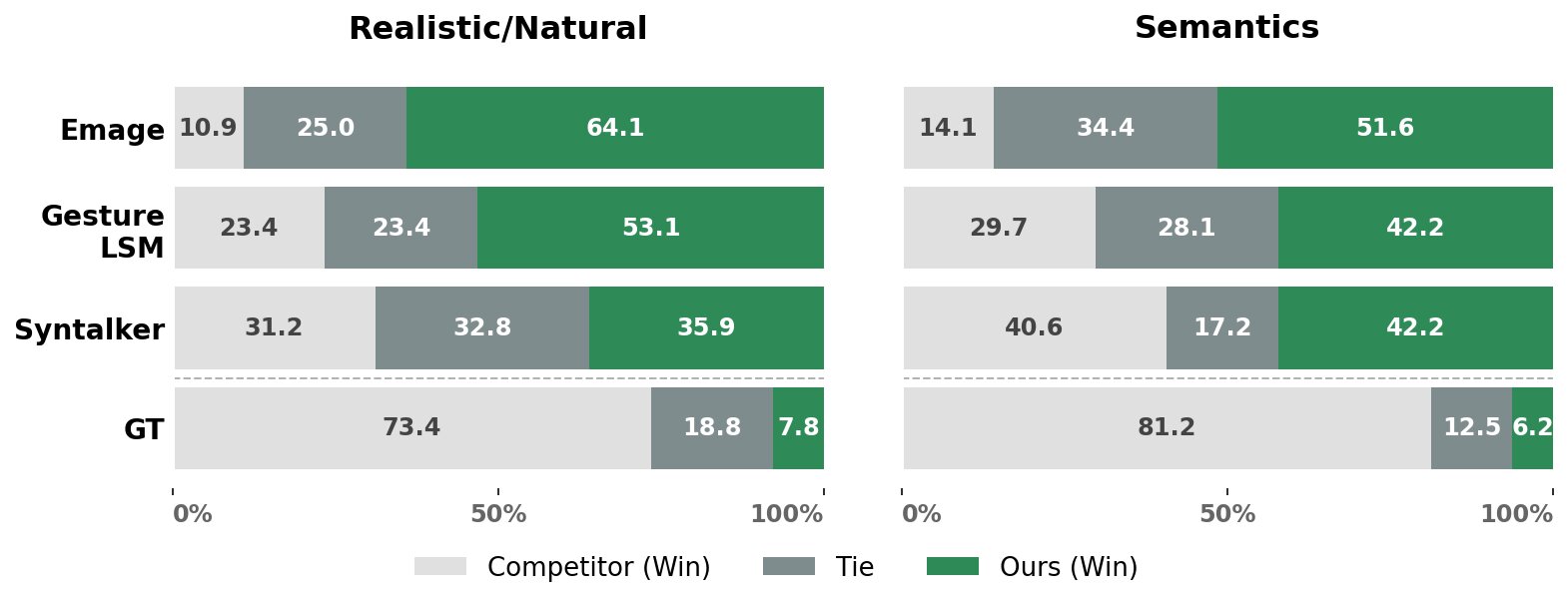
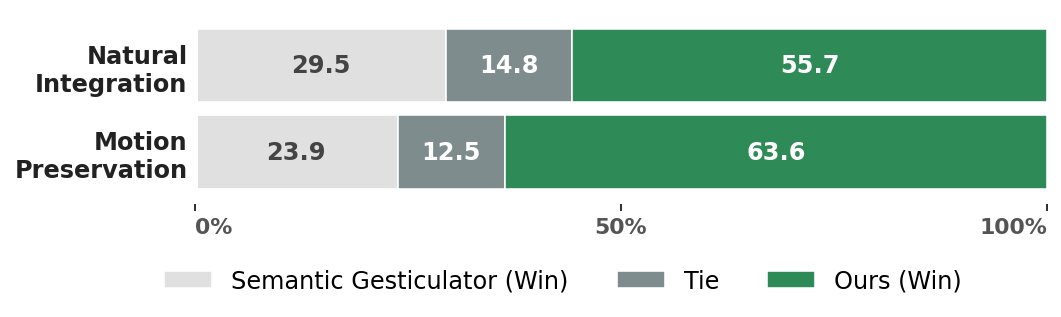
The paper reports three user studies. Study I uses 32 participants and evaluates the backbone against EMAGE, GestureLSM, SynTalker, and ground truth on realism, audio-motion alignment, and semantic accuracy. Study II uses 22 participants and 88 evaluations to compare JMI against Semantic Gesticulator on motion preservation and natural integration. Study III reuses 32 participants to compare the full model with JMI against the backbone alone, focusing on whether semantic injection improves perceived quality.

7. Quantitative Results
The main quantitative takeaway is that explicit-space diffusion substantially improves kinematic smoothness while retaining competitive distributional quality. The authors call the resulting behavior active smoothness: gestures remain fluid and low-jerk, yet preserve expressive diversity.
7.1 Backbone comparison
| Method | FGD ↓ | Diversity ↑ | BC ↑ | Jerk ↓ | Accel ↓ | FPS ↑ |
|---|---|---|---|---|---|---|
| EMAGE | 5.54 | 13.08 | 7.70 | 66.76 | 4.16 | 925 |
| SynTalker | 4.66 | 12.30 | 7.37 | 55.40 | 3.40 | 18 |
| gLSM-D | 4.10 | 12.56 | 7.35 | 57.73 | 3.47 | 399 |
| gLSM-MF | 4.04 | 12.46 | 7.45 | 61.16 | 3.69 | 1890 |
| GT | 0.00 | 13.09 | 6.83 | 42.13 | 3.03 | — |
| Ours (1k steps) | 4.72 | 13.66 | 6.81 | 34.91 | 2.60 | 55 |
| Ours (100 steps) | 5.49 | 13.52 | 6.81 | 33.92 | 2.57 | 547 |
| Ours (20 steps) | 5.48 | 13.29 | 6.84 | 33.99 | 2.59 | 2802 |
| Ours w/o CLIP&FiLM | 7.28 | 13.08 | 6.86 | 34.93 | 2.67 | — |
| Ours w/o AMASS | 7.34 | 10.07 | 7.46 | 69.65 | 3.88 | — |
Relative to latent baselines, the explicit-space backbone has a slightly worse FGD than the best latent model in the table, but it dramatically improves kinematic quality. For example, Jerk drops from 55.40 for SynTalker and 57.73 for gLSM-D to 34.91 for SiGnature at 1,000 steps, and Accel drops to 2.60. Diversity also exceeds ground truth, which the paper interprets as a sign of expressive range rather than mere smoothing.
The 20-step version retains similar smoothness with much higher throughput. The paper reports 2,802 FPS for 20 steps, compared with 55 FPS at 1,000 steps and 547 FPS at 100 steps.
7.2 Semantic injection and masking
| Method | FGD ↓ | Diversity ↑ | BC ↑ | Jerk ↓ | Accel ↓ |
|---|---|---|---|---|---|
| Ours w/ IB | 22.54 | 14.58 | 7.49 | 43.23 | 3.24 |
| Ours w/ JMI Post Integration | 16.28 | 14.66 | 7.76 | 44.83 | 3.34 |
| Ours w/ JMI | 11.88 | 14.10 | 7.74 | 40.31 | 3.03 |
This table isolates the impact of active-joint masking and per-step intervention. Naive in-betweening on all joints severely degrades realism, with FGD rising to 22.54. A single final-step injection is better than naive in-betweening but still worse than full JMI. The full stepwise JMI gives the best overall tradeoff and restores the strongest semantic fidelity while keeping kinematics smooth.
7.3 Reconstruction limits of latent-space semantic editing
| Evaluation set | Region | MPJPE (cm) ↓ |
|---|---|---|
| BEAT2 | Full body | 5.34 ± 0.85 |
| SeG | Full body | 16.32 ± 3.37 |
| SeG | Active joints | 21.64 ± 5.64 |
The VQ-VAE reconstruction baseline works reasonably on in-distribution co-speech motion from BEAT2, but semantic gestures from SeG are much harder: the error roughly triples on the full body and is especially high on active joints. The paper uses this as evidence that latent codebooks struggle with long-tailed, high-frequency semantic gestures and tend to erase fine-grained details.
7.4 Spatial precision of JMI
| Identity | Active joints to target | Active joints to base | Non-active joints to target | Non-active joints to base |
|---|---|---|---|---|
| Scott | 12.9 | 28.6 | 17.5 | 7.3 |
| Wayne | 14.5 | 28.1 | 20.7 | 6.0 |
| Ayana | 12.6 | 33.0 | 21.2 | 11.0 |
| Sophie | 15.8 | 29.7 | 14.4 | 3.1 |
| Lawrence | 11.8 | 26.7 | 18.4 | 7.3 |
The active joints are substantially closer to the target semantic gesture than to the base motion, while the non-active joints remain much closer to the base motion. This is the paper’s main quantitative evidence that JMI selectively edits the intended semantic region while preserving posture and style elsewhere.
7.5 Cross-identity style preservation
| Generated motion | Scott GT | Wayne GT | Ayana GT | Sophie GT | Lawrence GT |
|---|---|---|---|---|---|
| Scott (Gen.) | 1.00 | 3.07 | 3.66 | 3.55 | 2.92 |
| Wayne (Gen.) | 1.81 | 1.28 | 3.35 | 2.84 | 2.77 |
| Ayana (Gen.) | 2.72 | 3.06 | 1.84 | 3.40 | 3.41 |
| Sophie (Gen.) | 3.04 | 3.88 | 4.09 | 1.87 | 4.24 |
| Lawrence (Gen.) | 1.36 | 2.41 | 3.11 | 3.07 | 1.18 |
| Source (SeG) | 3.68 | 4.36 | 4.57 | 5.19 | 3.22 |
The diagonal entries are low, which indicates that the personalized diffusion models match the target speaker styles well. Off-diagonal values stay relatively higher, suggesting that the method does not collapse all outputs into an average speaker style. The source SeG row is farther from the target identities, which the paper uses to show that JMI successfully pulls injected gestures into the target speaker’s stylistic manifold rather than simply pasting the source style.
8. Perceptual Findings
Study I shows that participants preferred SiGnature’s backbone over EMAGE and GestureLSM on realism and semantic correctness; the differences are statistically significant against EMAGE on both metrics and against GestureLSM on realism. The paper notes that this happens even though FGD is not the best among all baselines, underscoring a mismatch between feature-space metrics and human judgments.
Study II shows that JMI is rated better than Semantic Gesticulator on motion preservation and natural integration. The main interpretation is that explicit joint-space editing preserves fine-grained semantic detail better than latent blending while avoiding discontinuities at the insertion boundaries.
Study III compares the full model against the backbone without semantic injection. Participants prefer the full model for both naturalness and semantic accuracy, indicating that JMI does not merely add rare gestures; it improves perceived liveliness and communicative quality.
9. Ablations and Diagnostic Insights
The main ablation questions are whether the dual-stream conditioning matters and whether a strong motion prior matters. Removing CLIP and FiLM together increases FGD from 4.72 to 7.28, while leaving smoothness almost unchanged. The authors interpret this as evidence that the global sentence prior specifically improves distributional matching, rather than kinematic regularity.
Removing AMASS pretraining hurts much more: FGD rises to 7.34, Diversity falls sharply to 10.07, Jerk jumps to 69.65, and Accel rises to 3.88. This supports the claim that a large motion prior is essential for smooth and stable generation.
The appendix further studies the global CLIP prior and finds that the transcript prompt matters: using the actual transcript gives the best FGD, dropping the text hurts, and a mismatched prompt is actively harmful. A CLIP-only variant performs very poorly, confirming that the global prior is only supplementary and cannot replace local audio/transcript conditioning.
10. Claimed Contributions and Takeaways
- Explicit-space co-speech diffusion: generation directly in SMPL-X rotation space, not a compressed latent, giving more reliable joint-level control and better kinematic smoothness.
- Training-free semantic editing: JMI injects arbitrary semantic gesture clips at inference time without retraining the backbone.
- Active-joint masking: only the motion-bearing joints are replaced, which reduces style leakage and prevents cut-and-paste artifacts.
- Dual-stream conditioning: a global CLIP prior plus local audio/transcript FiLM modulation help balance semantics, rhythm, and style.
- Personalized style preservation: the model is fine-tuned per speaker and then edited in a way that preserves the target speaker’s signature dynamics.
Overall, the paper’s central claim is that compressed latent spaces are a poor fit for rare semantic gestures, while explicit joint-space diffusion plus sparse, per-joint intervention provides a better substrate for controllable, stylized co-speech gesture generation.
11. Limitations and Future Work
The authors acknowledge several limitations. First, the system focuses on body and hand motion and does not natively model facial expression. Second, because it relies on overlapping windows and multi-step diffusion sampling, it is not strictly real-time; latency depends on window size and the number of denoising steps. Third, the active-joint heuristic is based on spatial variance and may miss subtle or low-amplitude semantic gestures, especially in complex or noisy clips. The paper also notes that word-level timestamps are only a coarse alignment signal and may not capture fine sub-word timing for very short gestures.
Proposed future directions include learning a semantic-aware joint-selection module, integrating JMI into more fully automated speech-to-gesture systems, and extending the architecture to multi-speaker or environment-aware generation. The authors also mention that finer-grained alignment and stronger semantic retrieval would further improve the system.
12. Bottom Line
SiGnature’s main technical contribution is the combination of a strong explicit-space diffusion backbone with a sparse, training-free editing mechanism that can import arbitrary semantic gestures while preserving personalized style. The experimental evidence consistently supports the paper’s thesis: latent compression is good for broad motion statistics but brittle for long-tailed semantic gestures, whereas explicit rotation-space modeling with active-joint intervention yields better controllability, smoother motion, and stronger human preference.