Joycent
Joycent: Diffusion-based Accent TTS without Accented Phone Prediction
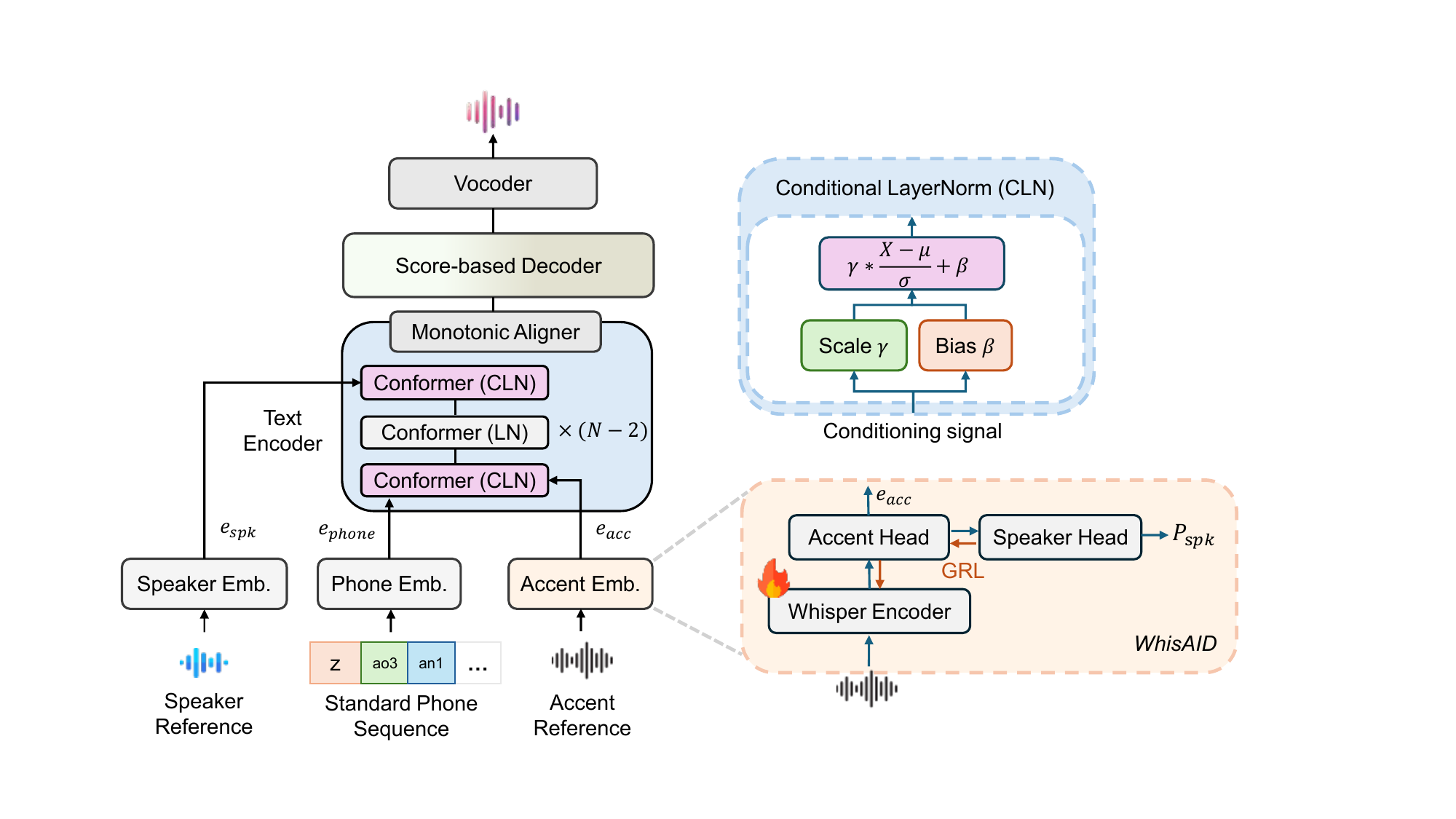
Joycent is a diffusion-based TTS model that synthesizes accented speech from standard phones and speech references, bypassing accented phone prediction. It integrates accent and speaker cues using conditional layer normalization, enhancing accentedness while preserving speaker identity without paired accent data.
Links
Paper & demos
Code & resources
Impact
Abstract
Accent text-to-speech (TTS) aims to synthesize speech with target accents. Existing accent TTS systems typically rely on a two-stage pipeline that first converts standard phone sequences into accented phone sequences and then synthesizes accented speech. However, such approaches suffer from error accumulation and require paired standard-accented phone sequence data, which is often limited in practice. Moreover, text-based accented phone representations are insufficient to model acoustic accent characteristics such as prosody and rhythm. In this work, we propose Joycent, a diffusion-based accent TTS model that synthesizes accented speech directly from standard phone sequences and speech references without accented phone prediction. Joycent integrates accent and speaker representations through conditional layer normalization (CLN) in the text encoder. We introduce WhisAID, a Mandarin accent identification model trained on accented Mandarin speech to extract accent representations. Experimental results show that Joycent improves accentedness while preserving speaker identity compared with baseline systems. We release our code and demos at: https://github.com/oshindow/Joycent-code.
Introduction
Joycent addresses accent text-to-speech (TTS), the task of synthesizing speech with a target accent rather than a neutral or standard pronunciation. The paper focuses on a practical limitation of prior accent TTS pipelines: they commonly convert standard phones into accented phones in a first stage, then synthesize speech in a second stage. The authors argue that this design has two major weaknesses: it introduces error accumulation across stages, and it depends on paired standard/accented phone supervision, which is scarce. They also note that text-level accented-phone representations miss acoustic aspects of accent such as prosody and rhythm.
The core idea of Joycent is to avoid explicit accented phone prediction altogether. Instead, the model synthesizes accented speech directly from standard phone sequences, a speaker reference, and an accent reference. In other words, linguistic content is represented by standard phones, while accent and speaker identity are provided through learned embeddings extracted from reference speech. The resulting system is built on a diffusion TTS backbone and is designed to improve accentedness while preserving speaker identity, especially in Mandarin accent synthesis.
The paper’s main claims are:
- accented speech can be synthesized directly without a phone-level accent conversion stage;
- accent and speaker cues can be disentangled by using dedicated pretrained encoders and adversarial training;
- conditioning the text encoder with accent and speaker embeddings via conditional layer normalization (CLN) yields stronger accent rendering than injecting text-based accent information alone.
Overall architecture
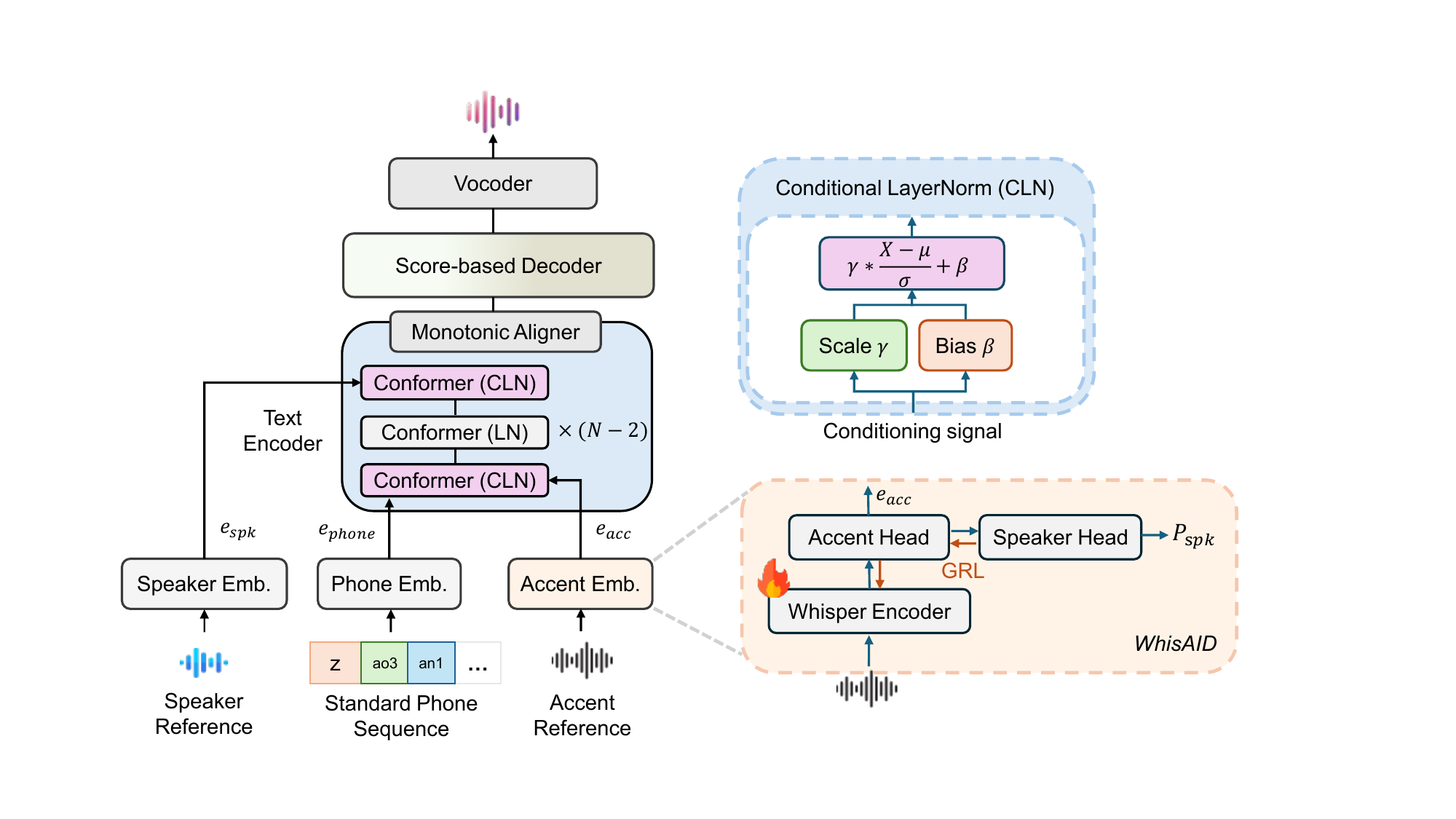
The system consists of two tightly connected components. First, WhisAID extracts accent embeddings from accented speech and is trained to reduce speaker leakage in those embeddings. Second, the accent TTS model uses those accent embeddings together with speaker embeddings and standard phone sequences to generate mel-spectrograms with a diffusion decoder. A vocoder then converts the spectrograms into waveforms.
The paper uses Grad-TTS as the backbone for accent synthesis, but modifies the text encoder: the Transformer blocks are replaced with Conformer blocks so that both local and global context can be modeled more effectively. The accent embedding and speaker embedding are injected into the text encoder via CLN rather than concatenated directly to phone features. The score-based decoder remains Grad-TTS-like, with a U-Net-based score estimator and diffusion sampling at inference.
Method
WhisAID: accent embedding extraction with speaker disentanglement
WhisAID is the paper’s accent identification model and also the mechanism used to extract accent embeddings. It is built by fine-tuning a pretrained Whisper encoder with two classification heads: an accent head and a speaker head. A gradient reversal layer (GRL) is inserted before the speaker head so that the accent embedding is encouraged to be informative for accent classification while suppressing speaker-specific information.
The training objective is:
$$ \mathcal{L}_{\mathrm{WhisAID}} = \mathcal{L}_{\mathrm{acc}} + \lambda \, \mathcal{L}_{\mathrm{spk}}, $$
where $\mathcal{L}_{\mathrm{acc}}$ is the accent classification loss, $\mathcal{L}_{\mathrm{spk}}$ is the speaker classification loss, and $\lambda$ controls the speaker-loss weight. The paper reports that $\lambda = 0.05$ gives the best English validation performance and is used in the Mandarin experiments.
Architecturally, each head uses a linear layer, GELU activation, Layer Normalization, and a projection layer to predict class logits. At inference, the projection layer is removed, and the accent embedding is taken from the layer-normalized features of the accent head. The Whisper encoder remains trainable rather than frozen, so the full accent extractor is jointly optimized.
The authors emphasize that the GRL is important because accent and speaker are entangled in speech data: the same accent can occur across many speakers, but each individual speaker usually exhibits only one accent. By pushing speaker information out of the accent representation, the model should generalize better to unseen speakers.
Phone-level accent conditioning with conditional layer normalization
Joycent conditions linguistic representations with accent and speaker information using CLN in the text encoder. Let $X$ be the hidden feature from a Conformer block, with mean $\mu$ and standard deviation $\sigma$. CLN produces
$$ \hat{X} = \gamma \cdot \frac{X - \mu}{\sigma} + \beta, $$
where $\gamma$ and $\beta$ are learned from a conditioning embedding through linear layers. Rather than appending accent embeddings to the phone embeddings, the paper replaces the last normalization in the first Conformer block with CLN conditioned on the accent embedding. It replaces the final normalization in the last Conformer block with CLN conditioned on the speaker embedding.
This placement is central to the method: accent information is injected early so it can influence the progression of linguistic encoding, while speaker information is injected late to preserve identity without overpowering accent conditioning.
Diffusion-based score decoder
The decoder follows the Grad-TTS formulation. From the text encoder output, the model first predicts a prior mean $\boldsymbol{\mu}_x$ as a coarse acoustic representation. During training, the ground-truth mel-spectrogram $\mathbf{y}_0$ is perturbed to $\mathbf{y}_t$ using a Gaussian diffusion process centered around $\boldsymbol{\mu}_x$. The score network is trained to estimate the denoising direction:
$$ s_\theta(\mathbf{y}_t, t, \boldsymbol{\mu}_x) \approx \nabla_{\mathbf{y}_t} \log p_t(\mathbf{y}_t \mid \boldsymbol{\mu}_x). $$
In implementation, $\mathbf{y}_t$ and $\boldsymbol{\mu}_x$ are concatenated and fed to the score estimator, and the diffusion time $t$ is embedded with sinusoidal positional embeddings. The score estimator is U-Net-based.
At inference, the initial latent is sampled as
$$ \mathbf{y}_T = \boldsymbol{\mu}_x + \frac{\boldsymbol{\epsilon}}{\tau}, \qquad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), $$
where $\tau$ is the temperature controlling the scale of the initial noise. The paper uses deterministic reverse diffusion by solving the associated ODE rather than a stochastic SDE sampler:
$$ d\mathbf{y}_t = \frac{1}{2}\left(\boldsymbol{\mu}_x - \mathbf{y}_t - s_\theta(\mathbf{y}_t, t, \boldsymbol{\mu}_x)\right) \beta_t \, dt. $$
The reverse trajectory is discretized into $M$ steps; the paper states $M = 50$ for generation. The generated mel-spectrogram is then converted to waveform with a Parallel WaveGAN vocoder.
Data, training setup, and evaluation protocol
WhisAID datasets
WhisAID is trained on three open-source Mandarin speech corpora: the Magichub Multi-Accents corpus, the Magichub-SG corpus, and AISHELL-3. The Multi-Accents corpus contributes nine regional Mandarin accents totaling 76.02 hours. Magichub-SG adds about 4 hours of Singaporean Mandarin speech from 4 speakers. AISHELL-3 is included after excluding the “Others” category. Together these corpora yield 12 accent labels.
The paper reports both seen-speaker and unseen-speaker evaluation splits for accent identification. For WhisAID, the unseen-speaker set contains 1,160 samples; the seen-speaker set contains 3,050 samples. The authors note that some AISHELL-3 regional labels overlap partially with the Multi-Accents categories, but adding AISHELL-3 still substantially increases the training data and improves accuracy.
Statistics of the nine-accent Multi-Accents corpus are:
| Accent | Speakers | Hours |
|---|---|---|
| Sichuan | 39 | 21.06 |
| Guangdong | 45 | 19.68 |
| Henan | 20 | 13.25 |
| Shanghai | 20 | 8.15 |
| Wuhan | 10 | 5.13 |
| Tianjin | 7 | 4.17 |
| Changsha | 2 | 1.96 |
| Nanchang | 2 | 1.46 |
| Shanxi | 1 | 1.11 |
| Total | 146 | 76.02 |
Accent TTS datasets and evaluation setup
For accent TTS, the target accent corpus is Magichub-SG, and AISHELL-3 training data are added to increase the amount of speech available for synthesis training. At inference, Joycent requires three inputs: a standard phone sequence, a speaker reference, and an accent reference. The paper evaluates both seen-speaker and unseen-speaker scenarios. The unseen-speaker set contains 10 speakers; the seen-speaker set also contains 10 speakers. Standard phone inputs are sampled from 100 utterances in total, 50 from AISHELL-3 and 50 from Magichub-SG. For evaluation, the accent reference is fixed to a Magichub-SG sample to keep accent conditioning consistent.
Each setting uses 1,000 synthesized samples for objective evaluation, with 100 utterances per speaker. Subjective evaluation uses 20 utterances per setting, sampled as 2 utterances per speaker. Twenty native Chinese speakers in Singapore, familiar with Singaporean-accented Mandarin, provide MOS and SMOS ratings.
Training details
For WhisAID, the paper follows Whisper’s input conventions: 80-dimensional log-mel spectrograms are extracted for Whisper-small and Whisper-medium, while 128-dimensional log-mel spectrograms are used for Whisper-large-v3-turbo. Audio segments are zero-padded to 30 seconds. The accent head uses a 768-dimensional input, a 256-dimensional hidden/output projection, GELU, and LayerNorm. WhisAID is fine-tuned for 10 epochs with AdamW, a cosine learning rate schedule, peak learning rate $1 \times 10^{-5}$, weight decay 0.01, and 1,000 warm-up steps.
For the accent TTS model, the text encoder has six Conformer blocks with hidden size 384, two attention heads, a convolution module with 768 channels and kernel size 31, and dropout 0.1. The vocabulary contains 199 phonemes, including a silence token. The model is trained for 900k steps with batch size 16 using Adam and a constant learning rate of $1 \times 10^{-4}$. The diffusion temperature is set to $\tau = 1.5$. Speaker embeddings are extracted with the pretrained FACodec model from Amphion. The vocoder is a Parallel WaveGAN trained on AISHELL-3, CSMSC, and Magichub-SG for 400k steps with batch size 6.
Experimental results
Accent identification results for WhisAID
The paper first validates WhisAID against GenAID on an English benchmark using the same split as the baseline. WhisAID uses Whisper-medium in that comparison so the backbone depth matches GenAID. The main finding is that WhisAID improves generalization to unseen speakers and produces lower speaker leakage in the accent embedding, as measured by the Silhouette Coefficient for Speaker Clusters (SCSC).
| System | Seen F1 | Seen Acc. | Unseen Prec. | Unseen Rec. | Unseen F1 | Unseen Acc. | Gap F1 | Gap Acc. | SCSC |
|---|---|---|---|---|---|---|---|---|---|
| GenAID | 0.78 | 0.62 | 0.63 | 0.56 | 0.55 | 0.56 | 0.23 | 0.06 | 0.079 |
| WhisAID, $\lambda = 0.1$ | 0.63 | 0.79 | 0.70 | 0.55 | 0.54 | 0.55 | 0.09 | 0.24 | 0.063 |
| WhisAID, $\lambda = 0.05$ | 0.68 | 0.80 | 0.70 | 0.59 | 0.58 | 0.58 | 0.10 | 0.22 | 0.059 |
| WhisAID, $\lambda = 0.01$ | 0.64 | 0.79 | 0.69 | 0.56 | 0.55 | 0.56 | 0.09 | 0.23 | 0.066 |
| WhisAID, w/o GRL | 0.71 | 0.81 | 0.70 | 0.58 | 0.58 | 0.58 | 0.13 | 0.23 | 0.075 |
For Mandarin accent identification, the paper compares different Whisper sizes and finds that Whisper-medium is the best trade-off for classification quality. The reported Mandarin results are:
| Model | Seen F1 | Seen Acc. | Unseen Prec. | Unseen Rec. | Unseen F1 | Unseen Acc. | Gap F1 | Gap Acc. | SCSC |
|---|---|---|---|---|---|---|---|---|---|
| WhisAID Small | 0.91 | 0.91 | 0.58 | 0.50 | 0.50 | 0.61 | 0.41 | 0.30 | 0.181 |
| WhisAID Medium | 0.93 | 0.93 | 0.60 | 0.58 | 0.57 | 0.64 | 0.36 | 0.29 | 0.158 |
| WhisAID Large-v3-turbo | 0.87 | 0.90 | 0.56 | 0.48 | 0.49 | 0.59 | 0.38 | 0.31 | 0.102 |
| WhisAID w/o GRL | 0.92 | 0.92 | 0.60 | 0.55 | 0.54 | 0.61 | 0.38 | 0.31 | 0.221 |
Two patterns stand out. First, the GRL helps suppress residual speaker information in the accent embedding, which is reflected in lower SCSC values. Second, larger Whisper models do not automatically give the best accent-classification accuracy; the medium model performs best in the paper’s Mandarin setting, while the large-v3-turbo model yields the lowest SCSC, indicating stronger speaker disentanglement but weaker classification performance.
Accent TTS results
The paper compares Joycent with two baselines: MacST, a text-based accent conversion pipeline, and CosyVoice3, fine-tuned in instruction mode on Magichub-SG. MacST uses ChatGPT-5 to generate Chinese character sequences that mimic Singaporean-accented Mandarin, then synthesizes them using ElevenLabs Multilingual v2 with voice cloning. CosyVoice3 is fine-tuned for 27 epochs on Magichub-SG. The main message is that both baselines achieve strong naturalness but substantially weaker accentedness, whereas Joycent substantially improves accent realization while staying competitive on speaker similarity and inference speed.
| Model | Speaker split | MOS | Acc. (w/o GRL / WhisAID) | Accent Sim. (w/o GRL / WhisAID) | SMOS | Speaker Sim. | RTF |
|---|---|---|---|---|---|---|---|
| Ground-truth (1,000 samples) | Seen | 3.96 | 0.93 / 0.95 | 0.83 / 0.84 | 3.50 | 0.7166 | - |
| CosyVoice3 (fine-tuned) | Seen | 3.66 | 0.05 / 0.11 | 0.52 / 0.52 | 2.95 | 0.5883 | 0.642 |
| MacST | Unseen | 3.57 | 0.00 / 0.15 | 0.04 / 0.09 | 2.10 | - | - |
| Joycent | Seen | 3.54 | 0.28 / 0.44 | 0.61 / 0.64 | 3.00 | 0.5871 | 0.069 |
| Joycent | Unseen | 3.42 | 0.26 / 0.38 | 0.58 / 0.61 | 2.90 | 0.5750 |
These results support the paper’s central claim: acoustic accent representations are substantially more effective than text-level accent substitution for modeling Singaporean Mandarin. The paper argues that the accent differences in this dataset are primarily realized through pronunciation patterns, retroflex versus non-retroflex initials, front-back nasal distinctions, stress, and prosodic variation, rather than through lexical or tone substitution. That makes purely text-based accent conversion a weak proxy for the acoustic phenomena that matter.
Ablation study
The ablation study isolates where accent and speaker information should enter the model. The tested variants compare CLN placement in different Conformer blocks and optionally inject accent/speaker embeddings into the decoder. Results are averaged over seen-speaker and unseen-speaker evaluation settings.
| System | Accent CLN | Speaker CLN | Decoder accent emb. | Decoder speaker emb. | Acc. | Accent Sim. |
|---|---|---|---|---|---|---|
| E1 (Ours) | Block 1 | Block 6 | × | × | 0.44 | 0.64 |
| E2 | Block 3 | Block 6 | × | × | 0.33 | 0.53 |
| E3 | Block 1 | Block 6 | ✓ | ✓ | 0.33 | 0.62 |
| E4 | Block 3 | Block 6 | ✓ | ✓ | 0.20 | 0.57 |
| E5 | × | × | ✓ | ✓ | 0.02 | 0.09 |
The ablation shows three clear conclusions. First, placing accent CLN in the first Conformer block is better than placing it later in the encoder. Second, adding accent and speaker embeddings directly into the decoder does not help and can hurt, presumably because it interferes with the decoder’s acoustic latent refinement. Third, removing encoder-side CLN causes performance to collapse, confirming that the text encoder is the right place for accent conditioning in this architecture.
Interpretation and scope
The paper’s interpretation is that accent synthesis works best when accent is modeled as an acoustic conditioning signal rather than as a text rewrite problem. This is especially relevant for Singaporean Mandarin, where accent distinctions are largely prosodic and phonetic rather than lexical. Joycent therefore combines a learned accent representation, a separate speaker representation, and diffusion-based acoustic generation to better capture those characteristics.
From the experimental design, the practical scope is still fairly focused. The strongest evidence is for Mandarin accent synthesis, with the accent TTS evaluation centered on Singaporean-accented Mandarin and the accent extractor trained on Mandarin accent data. The paper also relies on pretrained encoders for both accent and speaker representations, specifically Whisper for accent and FACodec for speaker identity. The system is evaluated with reference speech for both accent and speaker control, so the quality of those references matters at inference time.
The paper does not include a separate formal limitations section, but the reported experiments suggest several boundaries: the method is demonstrated on Mandarin accents rather than a broad multilingual benchmark; it depends on reference audio to supply accent and speaker cues; and the gains come from a carefully tuned CLN placement and diffusion setup rather than from a simple plug-in module. These are not stated as failures, but they define the evaluated operating regime.
Conclusion
Joycent is a diffusion-based accent TTS system that removes the need for accented phone prediction. Its main contribution is to condition standard-phone TTS on disentangled acoustic accent and speaker embeddings, extracted by WhisAID and FACodec respectively, and injected through CLN into a Conformer text encoder. The paper’s experiments show that this design improves accent realization relative to text-based accent conversion approaches while maintaining competitive naturalness and speaker similarity. The ablation study supports the architectural choice of early accent conditioning in the encoder, and the WhisAID results indicate that GRL-based disentanglement improves robustness to speaker variation.
Code & Implementation
This repository provides the official implementation of Joycent, a Mandarin accent text-to-speech (TTS) system as described in the paper. It includes the diffusion-based accent TTS model, an accent identification model called WhisAID, and a ParallelWaveGAN vocoder for waveform synthesis.
The core Joycent model integrates accent and speaker representations into a neural TTS architecture based on a GradTTS Conformer framework with conditional layer normalization (CLN), as implemented in the joycent/model/tts_conformer_gstloss_whisper3_qwen2_facodec3_acc_rmllm.py module. Training is managed through joycent/train_joycent.py, which utilizes distributed training with multi-GPU support and processes data including phoneme sequences, speaker, and accent embeddings.
Inference is supported by joycent/inference_joycent.py, which loads pretrained acoustic and vocoder models (including the FACodec codec) and synthesizes accented speech from standard phoneme input and speech references. The repository also provides data processing and feature extraction scripts to prepare speaker and accent embeddings.
Pretrained model weights for Joycent, WhisAID, and the vocoder are available, enabling reproduction of the paper1s results without needing to retrain from scratch. The README offers detailed instructions for setup, training, inference, and evaluation.