Context-Aware Decoding (CAD)
From Awareness to Adherence: Bridging the Context Gap in Spoken Dialogue Systems via Context-Aware Decoding
Introduces an inference-only method that boosts multi-round spoken dialogue systems by amplifying relevant context during response generation. It bridges the gap between internal context awareness and active adherence, improving context fidelity without retraining or extra modules.
Links
Paper & demos
Code & resources
Impact
Abstract
Despite the success of end-to-end (E2E) spoken dialogue systems, maintaining strict context adherence in multi-round conversations remains a challenge. While prior works attribute these failures to models forgetting dialogue history, we highlight an equally critical but overlooked bottleneck: a gap between latent context awareness and active adherence. Although models internally recognize relevant past utterances, strong parametric priors often overshadow these signals during decoding. To bridge this gap, we propose an audio-adapted Context-Aware Decoding (CAD) approach. By leveraging internal attention mechanisms to isolate key historical rounds, our approach contrasts output distributions with and without this key context during inference, directly amplifying multimodal contextual signals. Evaluations on the Audio MultiChallenge benchmark demonstrate significant improvements in Semantic Memory and Self Coherence subtasks, successfully enforcing strict, context-faithful adherence.
Introduction
This paper addresses a specific failure mode in end-to-end spoken dialogue systems: in multi-round conversations, models often appear to recognize relevant past information internally, yet still fail to express that information in the final response. The authors argue that this is not only a memory problem, but also a generation-time adherence problem. They frame the issue as a gap between latent context awareness and active adherence.
In the paper's terminology, latent awareness is the model's internal ability to attend to or recognize useful historical utterances, while active adherence is the successful manifestation of that context in the generated output. The key observation is that strong parametric priors can dominate the decoding process even when the model has internally identified the correct historical evidence. Rather than treating the system as if it had completely forgotten the dialogue, the paper argues that the bottleneck often lies in the decoding stage.
To address this, the paper introduces an audio-adapted Context-Aware Decoding (CAD) method. The method is inference-only, does not require extra training, and does not add an external retrieval module. Instead, it amplifies the impact of selected historical context by contrasting output distributions computed with and without that context. The approach is designed for spoken dialogue systems and is presented as model-agnostic across different end-to-end architectures.
The authors summarize their main contributions as follows: (1) they explicitly formalize context failures in multi-round spoken dialogue as a gap between latent awareness and active adherence; (2) they propose an audio-adapted CAD mechanism that strengthens contextual signals during decoding; and (3) they show consistent gains on the Audio MultiChallenge benchmark, especially on strict context-adherence tasks such as Semantic Memory and Self Coherence.
Method
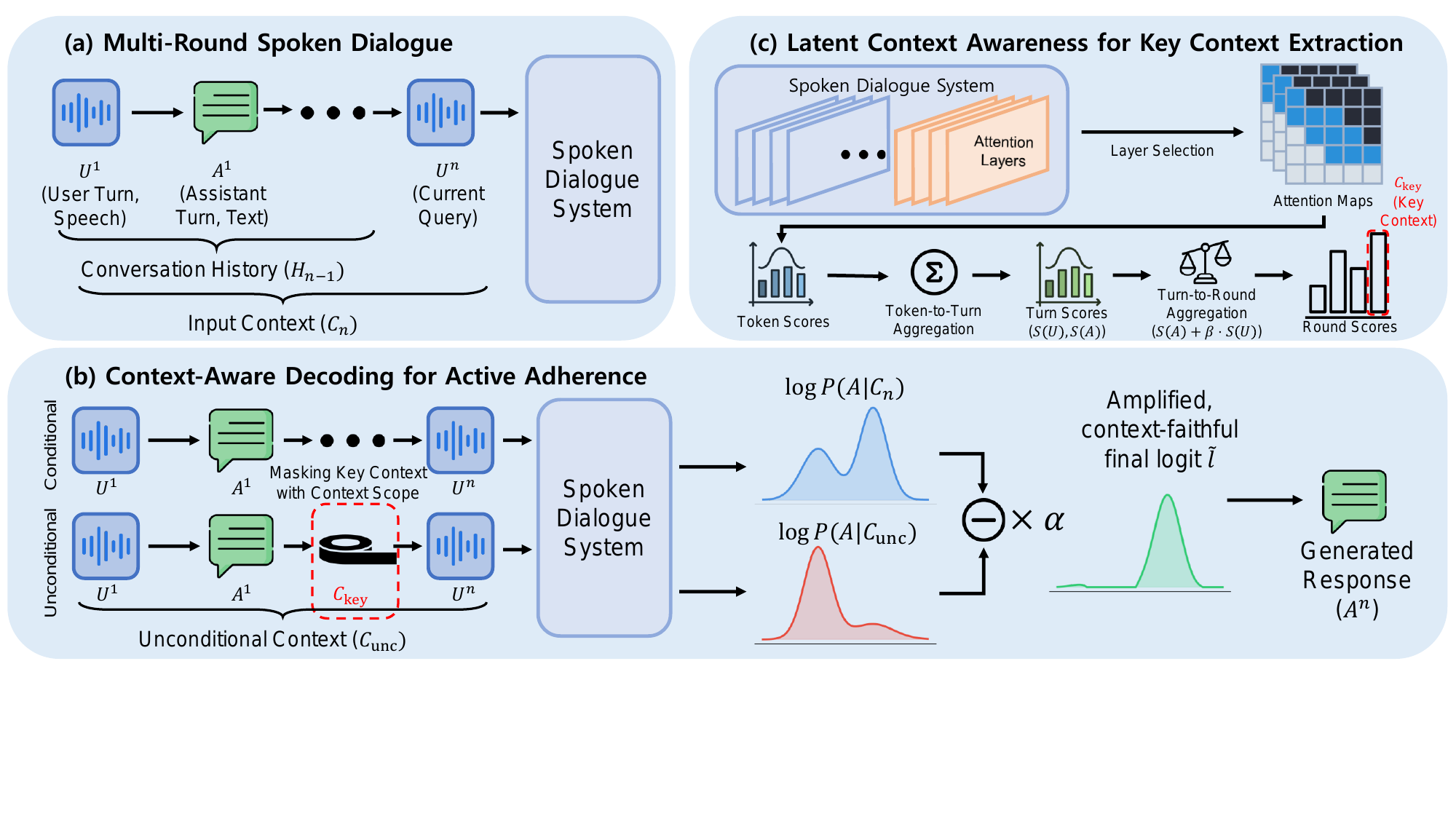
Problem formulation: multi-round spoken dialogue
The paper defines a conversation as a sequence of rounds, where each round consists of a user turn followed by an assistant turn. For a single-round setting, a user utterance $U = [u_1, u_2, \dots, u_i]$ is mapped to an assistant response $A = [a_1, a_2, \dots, a_k]$ autoregressively:
$$
P_{\phi}(A \mid U) = \prod_{j=1}^{k} P_{\phi}(a_j \mid U, a_{
In the multi-round case, the model receives the prior dialogue history $H_{n-1} = [U^1, A^1, \dots, U^{n-1}, A^{n-1}]$ and the current user utterance $U^n$. The full input context is $C_n = [H_{n-1}, U^n]$, and the assistant generates $A^n$ conditioned on that context:
$$
P_{\phi}(A^n \mid C_n) = \prod_{j=1}^{|A^n|} P_{\phi}(a^n_j \mid C_n, a^n_{
The paper focuses on a speech-to-text setting, where the user input is composed of speech tokens and the response is generated as text. The authors note, however, that the decoding strategy is modality-agnostic and can be extended to speech-to-speech generation as well.
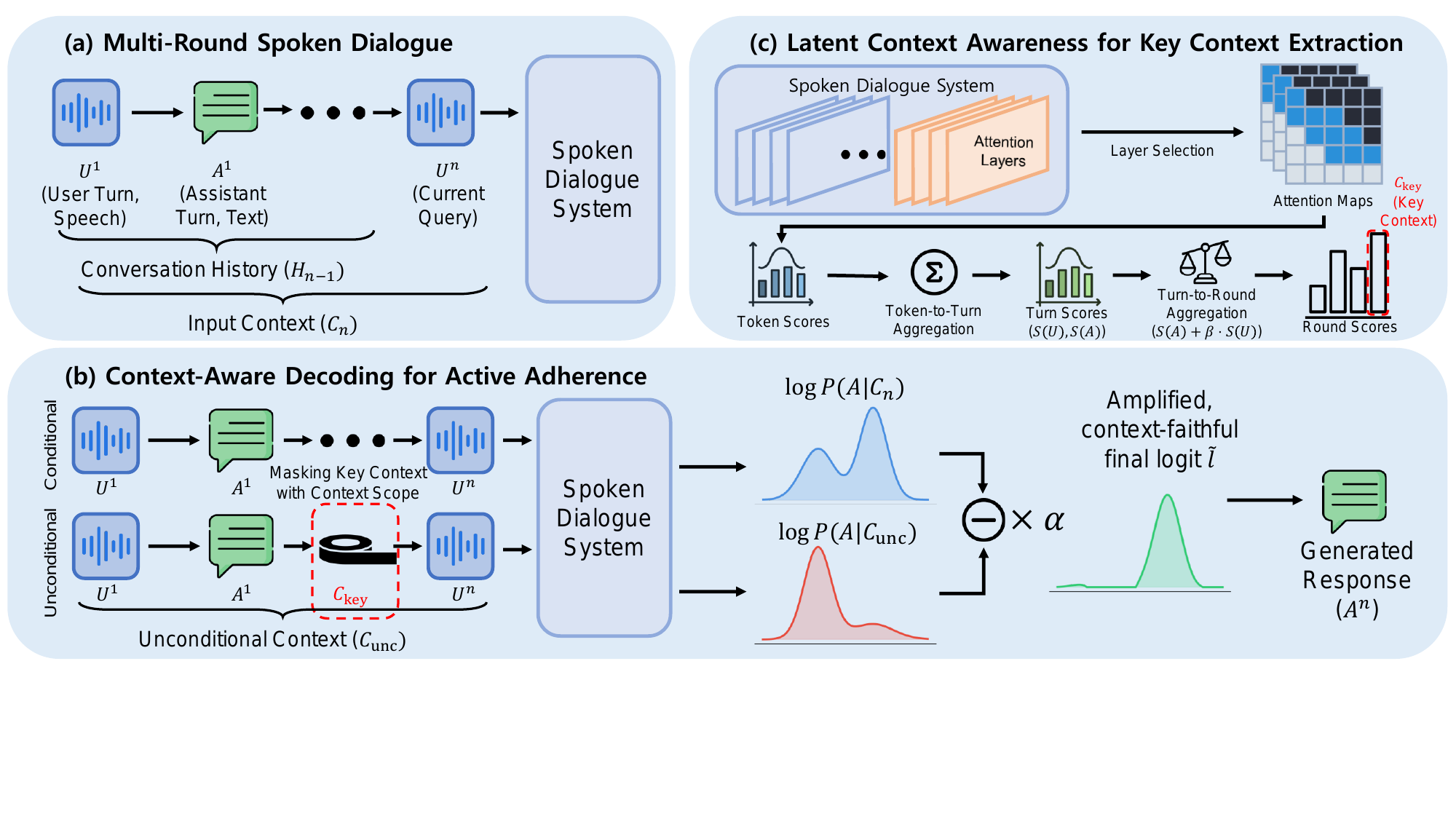
Standard CAD contrasts the model's output distribution under the full context with an unconditional version computed after removing the history. This paper adapts that idea for spoken dialogue by defining a key context $C_{\mathrm{key}} \subset H_{n-1}$ rather than masking the entire history. The unconditional context is then defined as $C_{\mathrm{unc}} = C_n \setminus C_{\mathrm{key}}$.
The intuition is that the difference between the full-context and key-context-removed predictions reflects how much the selected historical evidence should influence the next token. The modified logit for token $a^n_j$ is:
$$
\tilde{l}_j = \log P_{\phi}(a^n_j \mid C_{\mathrm{unc}}, a^n_{
Here, $\alpha$ is a penalty weight that controls how strongly the key context is amplified relative to the model's prior. The paper explores $\alpha \in [1.0, 3.0]$ with a step size of $0.5$.
In words, the decoding rule increases the influence of tokens whose probabilities change meaningfully when the key context is present. This is the paper's main mechanism for converting internal awareness into explicit adherence at generation time.
A central novelty of the paper is that it does not use the whole history as the key context. Instead, it tries to identify the rounds that the model already attends to most strongly, using the model's own attention patterns as a proxy for latent awareness. The pipeline is:
The paper studies four design axes.
$$
S_{\mathrm{round}}(R^m) = S_{\mathrm{turn}}(A^m) + \beta \cdot S_{\mathrm{turn}}(U^m).
$$
This design is explicitly meant to avoid the noise introduced by naive whole-history conditioning. The authors argue that selecting too much history can dilute the relevant signal and even hurt decoding.
The paper evaluates on the Audio MultiChallenge benchmark, which is designed for multi-round, end-to-end spoken dialogue under realistic conditions. The benchmark includes unscripted speech, disfluencies, and ambient noise, and conversations span roughly 3 to 8 continuous rounds. This makes it a good stress test for long-horizon state tracking.
The paper focuses on two benchmark subsets that require strict adherence to context:
Evaluation is done with a strict rubric-based binary judge on the assistant's final utterance. A response passes only if it satisfies all instance-specific rubrics. The paper reports Average Pass Ratio (APR), averaged over 5 independent generation runs. The authors use
The experiments compare CAD against three state-of-the-art spoken dialogue systems: MiMo-Audio-7B-Instruct with its thinking mode enabled, Qwen3-Omni-30B-A3B-Instruct, and Kimi-Audio-7B-Instruct. All models are run with their default generation settings, such as the official temperature and top-p parameters, to isolate the effect of the decoding method itself.
For the main table, the paper uses the empirically chosen CAD configuration
The main finding is that CAD improves every evaluated model on both subtasks and on the average APR. The strongest gain is observed for Qwen3-Omni-30B-A3B-Instruct, where the average APR increases from 25.78 to 39.08, an absolute gain of 13.30 points. MiMo-Audio improves from 26.01 to 34.11, and Kimi-Audio improves from 16.19 to 22.89.
The paper interprets these gains as evidence that the models were not simply unable to remember the context; rather, the relevant context was present internally but underused at decoding time. CAD makes the models actively rely on the selected history instead of following stronger parametric priors.
The ablation studies are performed with MiMo-Audio as the base model. They probe the design choices behind key-context extraction and the effect of the CAD hyperparameters.
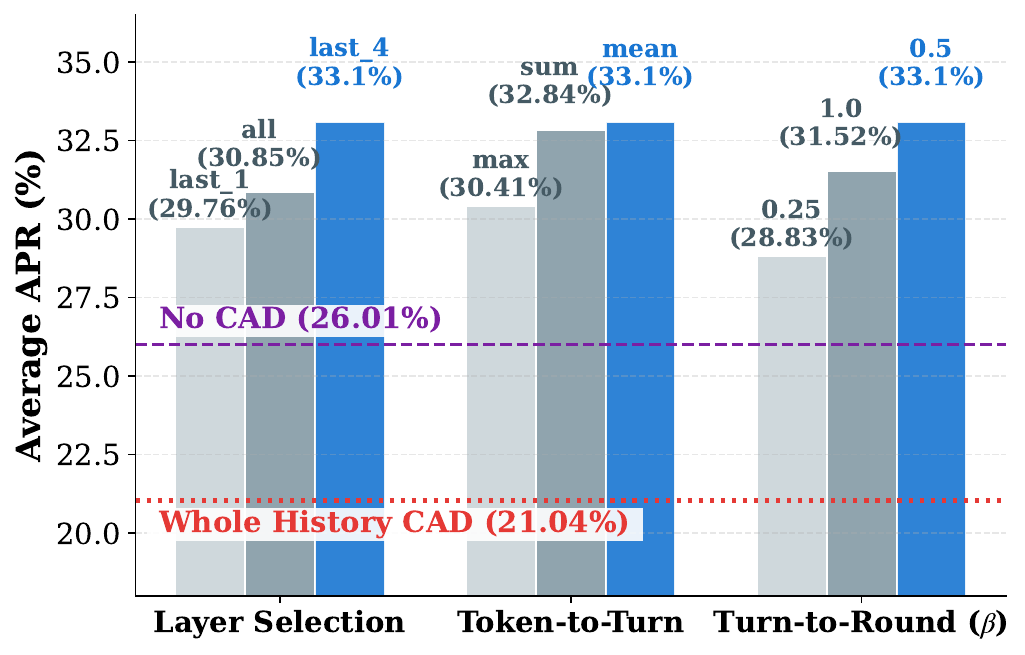
One of the most important ablations is the comparison between selective key-context CAD and a naive variant that uses the entire history as $C_{\mathrm{key}}$. The paper reports that this Whole History CAD setting drops to 21.04 compared with the No CAD baseline of 26.01. In contrast, using carefully isolated key context raises performance to 33.10.
The authors interpret this as evidence that indiscriminately amplifying all prior rounds introduces substantial noise. In other words, more history is not always better; context selection must be precise for decoding-time contrastive amplification to help.
The ablation on layer selection shows that relying on only the final layer does not capture enough contextual nuance, while averaging all layers introduces too much low-level noise from shallow representations. The best trade-off comes from averaging the last four layers, which the paper selects as the default.
For token-to-turn aggregation,
For turn-to-round aggregation, the paper argues that user speech turns contain many more tokens than assistant text turns, so a moderate down-weighting of the user side is helpful. Among the tested values, $\beta = 0.5$ performs best, outperforming both the uncompensated case ($\beta = 1.0$) and the stronger compensation setting ($\beta = 0.25$).
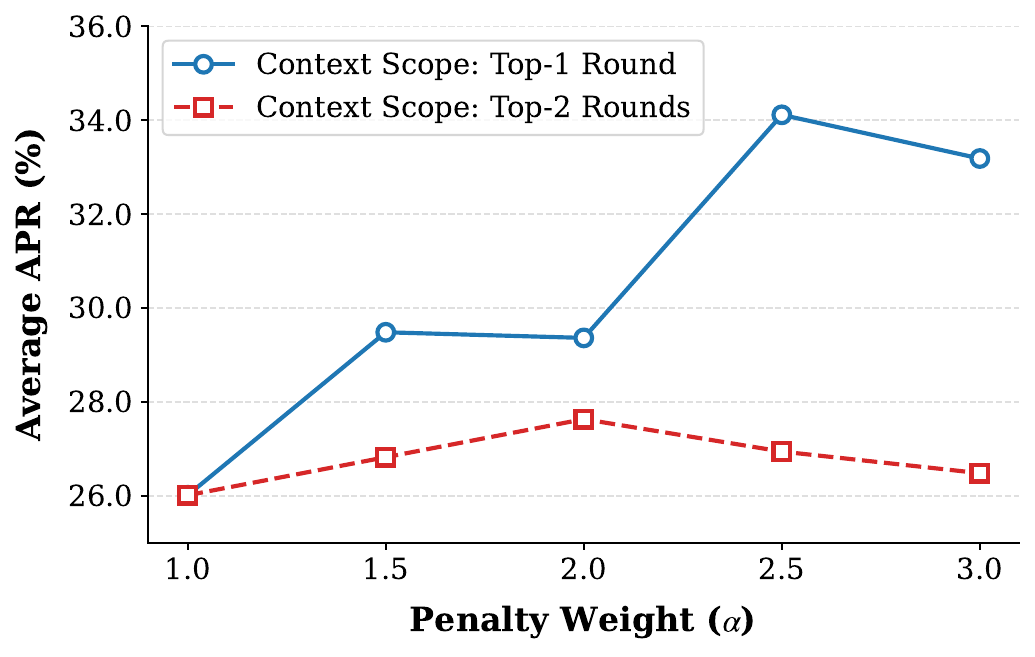
The paper also studies the penalty weight $\alpha$ and the number of selected rounds $K$. For $K = 1$, increasing $\alpha$ steadily improves APR until the performance saturates, and the paper chooses $\alpha = 2.5$ as the best setting in that regime. The searched range is $\alpha \in \{1.0, 1.5, 2.0, 2.5, 3.0\}$.
Expanding the scope to $K = 2$ generally hurts performance, and high values of $\alpha$ are especially harmful in that setting. The paper's interpretation is that a broader context window is more likely to include irrelevant rounds, and aggressively amplifying such noisy context degrades decoding quality.
The paper's key takeaway is that strict context adherence in spoken dialogue can be improved without retraining the base model. By using the model's own attention as a proxy for latent awareness and then applying contrastive decoding against a context-masked variant, the method turns internal recognition into visible output adherence.
The stated evidence is strong but also scoped: the experiments are limited to the Audio MultiChallenge benchmark, to two benchmark subsets for detailed reporting, and to three end-to-end spoken dialogue systems. The provided LaTeX does not include a separate limitations section, so this summary cannot claim limitations beyond the experimental scope reported by the authors. The paper also does not present training of a new model; it is a decoding-time intervention evaluated under default generation settings.
The paper concludes that audio-adapted CAD is a robust, model-agnostic way to reduce context failures in multi-round spoken dialogue systems. The method consistently improves strict adherence metrics across models, especially on Semantic Memory and Self Coherence, and the ablations support the central claim that precise key-context isolation is essential. Overall, the work argues that many dialogue failures are not pure memory failures, but failures to convert latent contextual understanding into active adherence during decoding.
This repository provides the official implementation of the paper's audio-adapted Context-Aware Decoding (CAD) method for spoken dialogue systems. It implements CAD as a training-free, inference-time procedure that modifies the generation loop of existing state-of-the-art models to enforce context adherence by contrasting output distributions with and without key dialogue context. The repo is organized around three separate model implementations— These inference scripts handle dataset loading, caching of audio files, building conversations from dialog turns, and invoking the respective model's generation call with CAD-specific hyperparameters that include aggregation methods ( The Overall, the repository provides full reproducibility of the paper's experiments and a clear separation of the CAD logic intertwined with each upstream model's inference pipeline, making it straightforward to adapt the CAD decoding procedure to new models that support token-level attention inspection.Context-Aware Decoding for active adherence
Latent context awareness and key-context extraction
last_1), the average of the last four layers (last_4), or all layers.
mean, max, or sum.
Experiments
Benchmark and evaluation protocol
gpt-5-nano as the judge instead of the benchmark's default o4-mini, while otherwise following the official pipeline.
Baselines and setup
last_4, mean, and $\beta = 0.5$ across all baselines.
Main results
Model
Semantic Memory
Self Coherence
Average
MiMo-Audio-7B-Instruct
26.00
26.02
26.01
+ CAD
32.00
36.39
34.11
Qwen3-Omni-30B-A3B-Instruct
22.67
29.16
25.78
+ CAD
39.33
38.80
39.08
Kimi-Audio-7B-Instruct
13.56
19.04
16.19
+ CAD
23.11
22.65
22.89
Ablation Studies
last_4, mean, and $\beta=0.5$.Why whole-history CAD fails
Layer selection and aggregation behavior
max is too sensitive to isolated outlier tokens and sum is biased toward longer turns. The paper finds mean to be the most stable and representative turn-level aggregation strategy.
Penalty weight and context scope
Discussion and limitations
Conclusion
Code & Implementation
Kimi-Audio-7B-Instruct, MiMo-Audio-7B-Instruct (with Thinking mode), and Qwen3-Omni-30B-A3B-Instruct—each in their own subdirectory (kimi/, mimo/, and qwen/ respectively). Each model folder contains a dedicated inference.py script that shows how the CAD method is applied at inference time on the Audio MultiChallenge benchmark dataset.intra, inter), layer selection (layer_from), the number of key context rounds (num_rounds), and the guidance scale (guidance_scale) that controls the CAD penalty strength.eval/ directory contains evaluation scripts such as evaluate_openai.py which uses GPT-based LLMs as judges to assess the quality of generated dialogues. The repo also includes shell scripts in each model folder's bash_scripts/ to reproduce key experiment tables and ablations reported in the paper.