CraBERT
CraBERT: Efficient Phoneme Encoder Pre-Training via Cascade Fusion of Subword Representations for Text-to-Speech
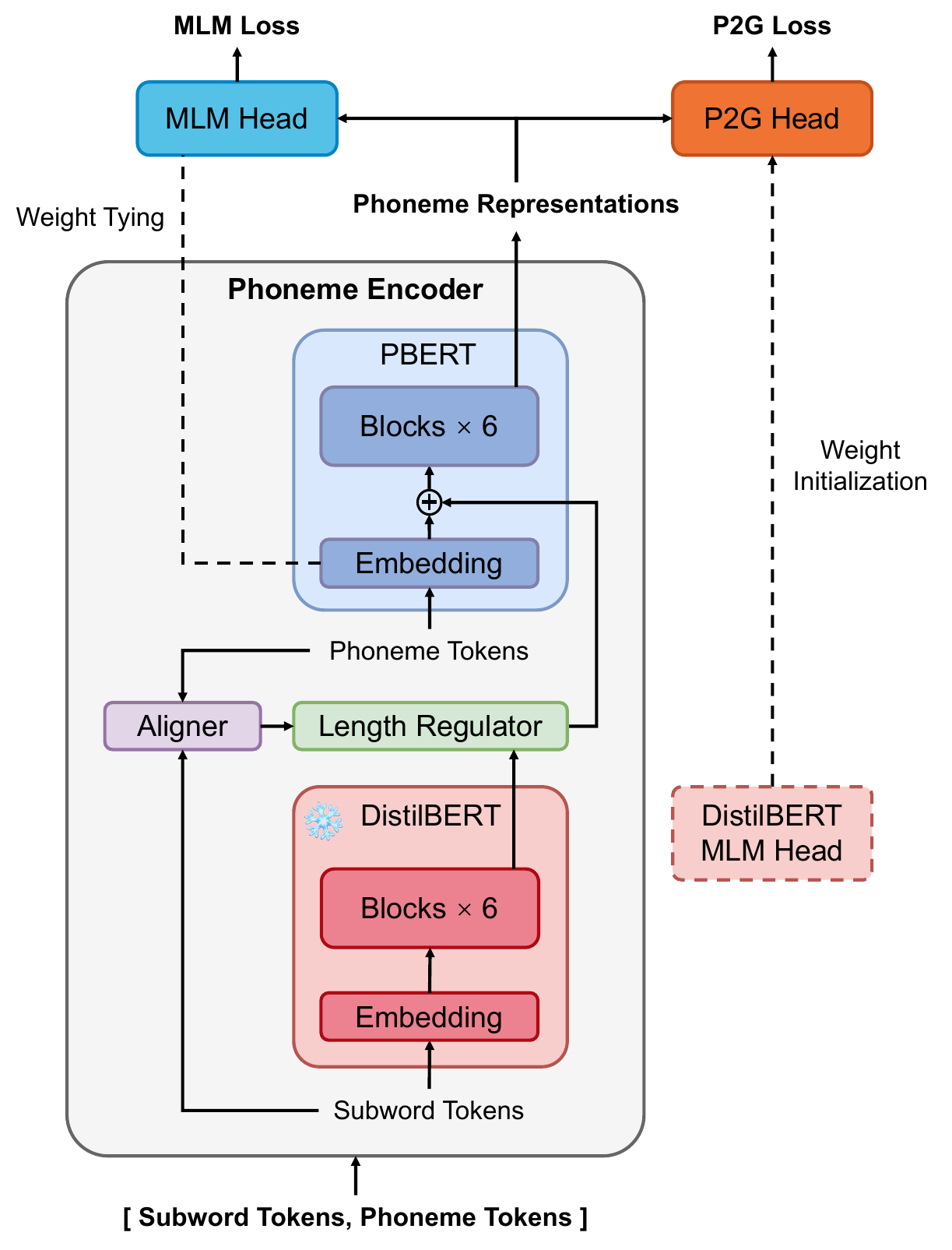
CraBERT is an efficient pre-trained phoneme encoder for text-to-speech that leverages a frozen pre-trained subword BERT to infuse word- and sentence-level context into phoneme-level representations, enabling significantly faster pre-training with comparable perceived speech quality to longer-trained baselines.
Links
Paper & demos
Impact
Abstract
This paper introduces CraBERT, a pre-trained phoneme encoder (PPEnc) designed for efficient pre-training in text-to-speech (TTS). CraBERT employs a cascade-fusion architecture and a subword-phoneme alignment algorithm to integrate representations from a pre-trained subword-level BERT into a phoneme-level BERT. This design provides prior word- and sentence-level information, reducing the amount of pre-training required by the phoneme encoder. Subjective listening evaluations show that CraBERT achieves MOS values comparable to existing PPEncs after approximately one epoch of pre-training, whereas the baselines in our comparison are pre-trained for approximately ten epochs. These results demonstrate that CraBERT can efficiently learn representations suitable for improving the perceived naturalness and prosody of synthesized speech.
Introduction and problem setting
CraBERT targets a practical bottleneck in text-to-speech (TTS) pre-training: how to obtain a strong phoneme encoder without paying the large optimization cost typically associated with phoneme-level language modeling. In modern TTS systems, the phoneme encoder is an important component because it converts phoneme tokens into contextual representations that help improve synthesized speech naturalness and prosody. The paper positions CraBERT as a pre-trained phoneme encoder (PPEnc) that is specifically designed to be efficient in pre-training, rather than merely being a better downstream encoder after a long training schedule.
The key observation motivating the work is that phoneme-only PPEncs face several structural disadvantages compared with subword language models. First, phoneme sequences are longer than the corresponding word sequences, which makes word- and sentence-level semantic learning inefficient. Second, phoneme vocabularies are small, which can reduce representation capacity and make masked prediction too easy. Third, support for multiple phonetic notations can multiply training costs. The paper argues that a phoneme encoder should therefore borrow linguistic context from a stronger subword model rather than relearn all higher-level information from phonemes alone.
CraBERT addresses this by combining a frozen pre-trained subword BERT with a phoneme-level BERT through an alignment-and-fusion pipeline. The model is intended to inject prior word- and sentence-level knowledge into phoneme-level pre-training so that the phoneme encoder can focus on TTS-relevant features. In the reported subjective evaluations, this design allows CraBERT to reach MOS levels comparable to existing PPEncs after about one epoch of pre-training, while the main baselines are trained for about ten epochs.
Main idea and claimed contributions
The paper's central idea is called cascade fusion: subword representations from a pre-trained BERT are first produced, then aligned to phoneme tokens, upsampled to the phoneme sequence length, and fused with the phoneme embeddings by element-wise addition before being processed by the phoneme BERT blocks. This is not the same as simply concatenating phoneme and grapheme inputs or adding subword representations only at the output of a TTS encoder. Instead, the subword model acts as a fixed prior that conditions phoneme-level pre-training from the start.
The paper explicitly claims three main contributions:
- CraBERT uses a pre-trained subword-level BERT to provide prior word- and sentence-level information, enabling efficient pre-training of a phoneme-level BERT.
- CraBERT achieves MOS comparable to existing PPEncs with about one-tenth the pre-training steps used by the main baselines in the paper.
- The paper introduces a data-driven subword-phoneme alignment algorithm based on dynamic time warping (DTW) to support the fusion mechanism.
Architecture overview
The architecture uses two BERT-style components: a frozen DistilBERT for subword tokens and a trainable vanilla BERT backbone for phoneme tokens, referred to in the paper as PBERT. The subword encoder is pre-trained and frozen during CraBERT pre-training, which reduces training cost and stabilizes optimization. The phoneme-side model is configured with 6 BERT
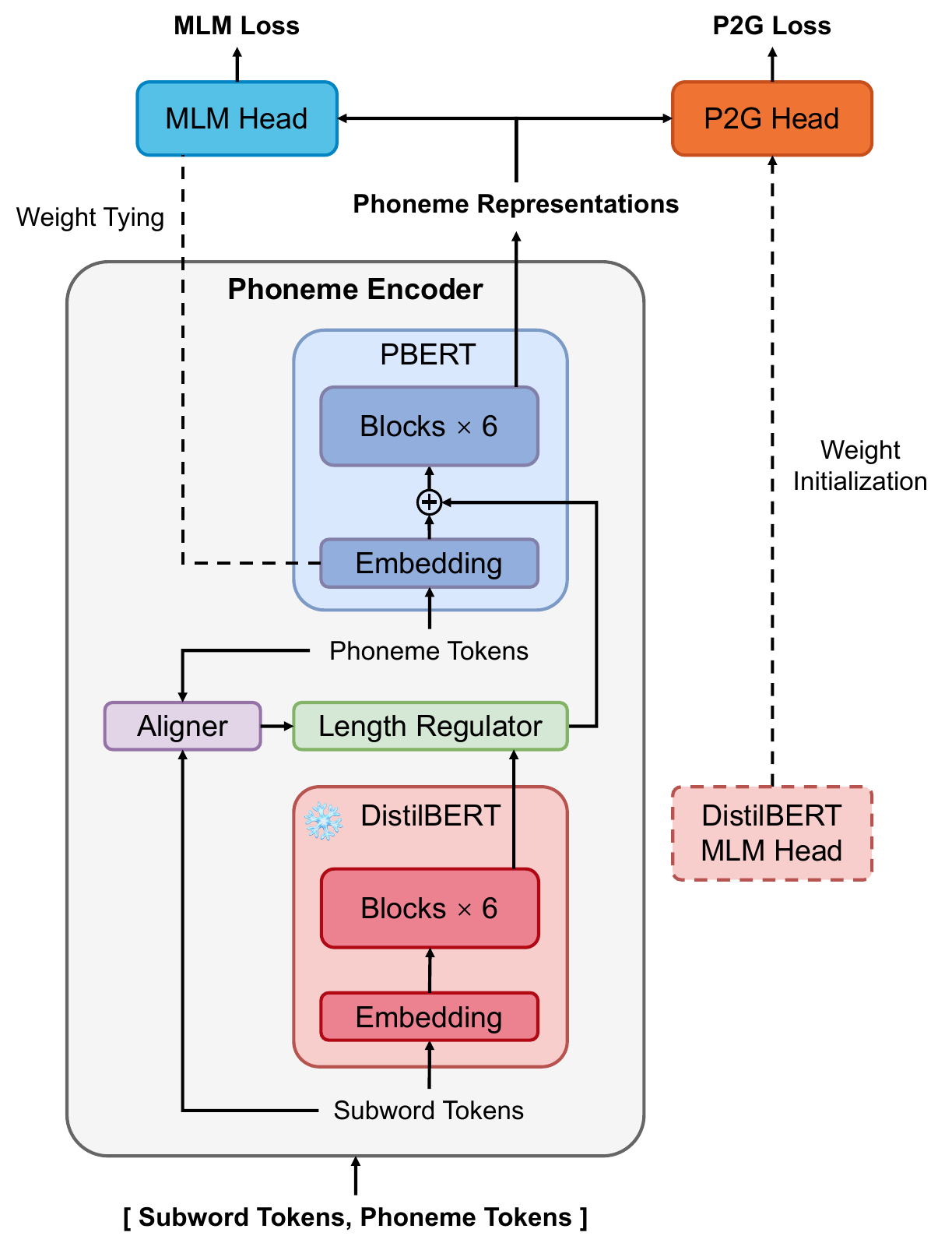
The processing flow is as follows. Input text is converted into both subword tokens and phoneme tokens. The aligner determines how phoneme tokens correspond to subword spans. DistilBERT then produces subword representations, which are expanded to the phoneme timeline using a length-regulator-style upsampling module similar to the one in FastSpeech 2. These aligned subword features are added element-wise to the phoneme embeddings, and the fused sequence is passed through the phoneme BERT layers.
This design is called cascade fusion because the stronger subword model is not used as a parallel side branch at the end of the network; instead, it provides representation priors that are cascaded into the phoneme encoder before the main phoneme-level contextual modeling happens.
Pre-training objectives and losses
CraBERT is trained with two objectives: masked language modeling on phoneme tokens and phoneme-to-grapheme prediction, but both are adapted to exploit the fused subword features. The paper denotes the phoneme input sequence by $\mathbf{p}$, the subword sequence by $\mathbf{g}$, and the masked index set by $M$.
First, DistilBERT encodes the subword sequence to produce subword representations:
$$\mathbf{r}_{\mathbf{g}} = \theta_{\text{DistilBERT}}(\mathbf{g}).$$
Then the phoneme-side MLM loss predicts masked phoneme tokens conditioned on both the phoneme sequence and the fused subword representations:
$$L_{\text{MLM}} = -\mathbb{E}\left[\sum_{m \in M} \log P\big(p_m \mid \mathbf{p}, \mathbf{r}_{\mathbf{g}}; \theta_{\text{PBERT}}, \theta_{\text{MLM}}\big)\right].$$
The auxiliary P2G objective predicts the subword tokens corresponding only to the masked phoneme positions:
$$L_{\text{P2G}} = -\mathbb{E}\left[\sum_{m \in M} \log P\big(g_m \mid \mathbf{p}, \mathbf{r}_{\mathbf{g}}; \theta_{\text{PBERT}}, \theta_{\text{P2G}}\big)\right].$$
The paper emphasizes two implementation details. One is weight tying: the embedding layer of PBERT and the output layer of the MLM head are tied, as is common in BERT-like models. The other is initialization of the P2G head using the pre-trained MLM head of DistilBERT, which the authors report helps convergence of the P2G objective.
Importantly, the paper does not apply P2G prediction to all phoneme tokens. Instead, it restricts P2G to the masked phoneme positions. The authors state that predicting all phoneme tokens, as in PL BERT, hurt MLM training efficiency in their setting.
Subword-phoneme alignment algorithm
A major technical component of the paper is the alignment algorithm that links phonemes to subwords. The authors argue that many prior approaches are either lossy or cumbersome: averaging subword representations discards positional and semantic detail, while heuristic rule-based alignment can be complex and opaque. Their solution is a data-driven aligner based on dynamic time warping.
The aligner is built in two stages. First, the paper trains a character-phoneme distance matrix from large text-derived word pairs. Second, the trained matrix is used to align characters and phonemes for each word via DTW-style dynamic programming. Finally, subword-phoneme alignment is obtained through a mapping chain from phoneme to character to subword, since letter-subword alignment is directly obtainable.
In training the distance matrix, the paper iterates over words with character sequence length $I$ and phoneme sequence length $J$ and accumulates a co-occurrence score for each character-phoneme pair according to relative position distance. The contribution decays with squared distance using
$$\delta(d) = e^{-\alpha d^2}, \quad \alpha = 50.$$
After accumulation, each row of the matrix is normalized by its maximum value, and the final distance matrix is formed as $\mathbf{D} = \mathbf{J} - \widetilde{\mathbf{D}}$ in the paper's notation, where $\mathbf{J}$ is an all-ones matrix. This distance matrix becomes the cost table used during DTW alignment.
During forward alignment, the algorithm constructs a cumulative cost matrix $\mathbf{L}$ and a track matrix $\mathbf{T}$ that stores the locally optimal predecessor for each cell. Boundary cases are initialized along the first row and first column, and each interior cell chooses the minimum-cost predecessor among the up, left, and diagonal transitions. In the backward pass, the track matrix is used to recover the optimal warping path. The paper frames this as a concise and general aligner that can be applied across different subword segmentation algorithms.
Phoneme tokenization and text preprocessing
The phoneme tokenizer is built using a grapheme-to-phoneme module from the cited work. The paper converts text to ARPAbet phoneme sequences. Instead of using explicit separators between adjacent words, it borrows the WordPiece-style continuation prefix and appends ## to subsequent phoneme tokens within a word and to consecutive punctuation marks after the first token. The example given is hello?!, tokenized as hh ##ah ##l ##ow ? ##!.
This design is intended to make phoneme segmentation more compatible with the subword alignment stage and with the TTS pipeline.
Baseline systems and unified experimental setup
The paper compares CraBERT against a small number of PPEnc baselines that are reimplemented in a unified framework for fairness. The baseline set consists of MP BERT and PL BERT, which the authors treat as representative recent phoneme encoder pre-training methods. XPhoneBERT is not included because the paper describes it as focusing on multilingual capability rather than architectural innovation.
To standardize the comparison, the authors use a 12-layer vanilla BERT
The paper also defines two non-pre-trained comparison points:
- Baseline VITS: VITS with an untrained 12-layer PBERT replacing the original phoneme encoder.
- CraBERTpara-0e: a parallel-fusion variant inspired by prior work, implemented by adding DistilBERT outputs and untrained PBERT outputs without the new pre-training strategy.
Training configuration
The pre-training corpus is BookCorpus plus English Wikipedia. This choice is explicitly made so that CraBERT and the compared language models share a corpus compatible with DistilBERT-style pre-training. The maximum phoneme sequence length is capped at $1024$ tokens. The authors use AdamW with $\beta_1 = 0.9$, $\beta_2 = 0.98$, $\epsilon = 10^{-6}$, and weight decay $0.01$. The learning rate follows a linear schedule from $0$ to $5 \times 10^{-4}$ over the first $10\%$ of warmup steps and then decays linearly to zero.
Training is done with a large effective mini-batch size of 2,000 sequences through gradient accumulation, using mixed precision on 8 NVIDIA A100 40GB GPUs. The paper reports that MP BERT, PL BERT, and CraBERT-10e are trained for 90,000 steps, which the authors describe as about ten epochs, while CraBERT-1e is trained for 9,000 steps, or about one epoch.
The paper also notes a wall-clock speed advantage from freezing DistilBERT. On 8 A100 GPUs, one epoch takes about 19 hours for CraBERT, compared with about 27 hours for MP BERT and 29 hours for PL BERT.
Downstream TTS evaluation setup
The downstream evaluation is performed on a multi-speaker TTS task using VITS as the backbone. The dataset is derived from the train-clean-360 subset of LibriTTS-R and is annotated with respiratory pauses and breath sounds. The paper's focus is not on building a new TTS model; rather, it uses VITS to test how different phoneme encoders affect synthesized speech naturalness and prosody.
All TTS systems are trained for 250 epochs with mini-batch size 80 on a single A100 GPU. The optimizer is AdamW with PyTorch default hyper-parameters, and the learning-rate schedule is the same linear warmup/decay schedule used during pre-training. The peak learning rate is $3 \times 10^{-4}$. For subjective testing, 50 speaker-text pairs are randomly sampled from the test set for synthesis.
Subjective evaluation protocol
The paper relies on mean opinion score (MOS) tests because the authors judge that naturalness and prosody are not fully captured by objective metrics. Native English listeners on Prolific rate each sample on a five-point scale from 1 to 5, corresponding to bad, poor, fair, good, and excellent. The paper performs separate listening tests for the masking-rate study and the model-comparison study, and it explicitly warns that MOS values should only be compared within each table, not across tables.
This is an important methodological point: the reported MOS values are not intended as a single global ranking across all experiments, but as evidence within two separate evaluation settings.
Masking-rate ablation
One of the paper's most important ablations studies the masking rate used in pre-training. The authors hypothesize that the standard BERT masking rate of 15% may be too low for CraBERT because DistilBERT already supplies rich contextual priors, making the masked prediction task easier than in a standard masked LM. They therefore test masking rates from 15% to 90% in 15-point increments, holding the number of pre-training steps fixed at 9,000 and then fine-tuning on VITS for MOS evaluation.
| Masking rate | MOS $\uparrow \pm$ CI |
|---|---|
| 15% | 3.10 $\pm$ 0.16 |
| 30% | 3.23 $\pm$ 0.18 |
| 45% | 3.25 $\pm$ 0.17 |
| 60% | 3.25 $\pm$ 0.17 |
| 75% | 3.29 $\pm$ 0.17 |
| 90% | 3.15 $\pm$ 0.19 |
The reported trend is that MOS increases as the masking rate rises, peaks at 75%, and then drops at 90%. The authors interpret this as evidence that CraBERT benefits from a higher-than-usual masking rate and choose 75% for the later comparisons. This is one of the clearest experimental findings in the paper because it directly changes the pre-training recipe.
Comparison with baseline phoneme encoders
The main comparison evaluates several encoder variants after TTS fine-tuning. The table below reproduces the reported MOS results and highlights the paper's central claim: CraBERT can reach baseline-level perceptual quality with about one-tenth the pre-training steps.
| Encoder | Pre-training steps | MOS $\uparrow \pm$ CI |
|---|---|---|
| Ground Truth | -- | 3.60 $\pm$ 0.18 |
| Baseline | 0 | 2.83 $\pm$ 0.18 |
| MP BERT | 90,000 | 3.14 $\pm$ 0.17 |
| PL BERT | 90,000 | 3.13 $\pm$ 0.19 |
| CraBERTpara-0e | 0 | 2.90 $\pm$ 0.18 |
| CraBERT-0e | 0 | 3.09 $\pm$ 0.17 |
| CraBERT-1e | 9,000 | 3.21 $\pm$ 0.18 |
| CraBERT-10e | 90,000 | 3.15 $\pm$ 0.19 |
The results support several conclusions. First, any phoneme encoder with pre-trained or partially pre-trained parameters improves upon the untrained baseline VITS encoder. Second, CraBERT-1e, trained for 9,000 steps, reaches MOS comparable to MP BERT and PL BERT trained for 90,000 steps. Third, extending CraBERT pre-training from 1 epoch to 10 epochs does not improve MOS further, suggesting that the useful representation quality is reached relatively quickly in this TTS setting.
The comparison between fusion strategies is also important. CraBERT-0e, which uses cascade fusion, outperforms CraBERTpara-0e, which uses a parallel addition-style fusion without the proposed pre-training strategy. The paper interprets this as evidence that the cascade design is more effective than simply adding frozen subword representations to phoneme features at the output or side-branch level.
Efficiency analysis
Beyond MOS, the paper reports pre-training time to quantify efficiency. With 8 A100 GPUs, the per-epoch times are approximately 19 hours for CraBERT, 27 hours for MP BERT, and 29 hours for PL BERT. Since CraBERT-1e reaches the target MOS after roughly 19 hours, whereas 10-epoch baselines require about 270 and 290 hours, the estimated training speedups are about $14\times$ over MP BERT and $15\times$ over PL BERT.
The paper notes that inference speed is comparable on a single A100 GPU, so the main gain is in pre-training cost rather than runtime synthesis speed.
Interpretation and discussion
The discussion centers on why CraBERT can learn useful phoneme representations so quickly. The authors argue that DistilBERT already injects word- and sentence-level information, allowing PBERT to concentrate on phoneme-level features that matter for TTS. In their interpretation, this reduces the burden on phoneme-level masked prediction, especially because the subword prior makes the task easier than in a stand-alone phoneme LM.
They also point to a potential mismatch between the phoneme-level contextual features optimized by language modeling and those actually needed in TTS. This is offered as one reason why additional pre-training beyond the one-epoch regime does not translate into better MOS. The paper explicitly leaves a more detailed analysis of this discrepancy to future work.
Limitations and scope
The paper is careful in scope: it evaluates CraBERT in English TTS, with a single downstream backbone (VITS) and subjective MOS as the primary metric. The reported study does not present objective acoustic metrics, multilingual experiments, or evaluations on alternative TTS architectures. Those absences are not framed as failures, but they do define the limits of the evidence presented.
Another practical limitation is that the method depends on a subword-level pretrained encoder and on a separate alignment stage. Although the paper argues that its DTW-based aligner is concise and broadly applicable, the quality of the approach still relies on accurate alignment between subwords, letters, and phonemes. The authors also note that future work should determine the optimal amount of pre-training and further study the difference between phoneme features learned for language modeling versus those useful for speech synthesis.
Bottom line
CraBERT is a phoneme encoder pre-training method that reduces training cost by using a frozen subword BERT as a representation prior, a DTW-based alignment mechanism to map subwords to phonemes, and a cascade-fusion architecture that injects subword context before phoneme-level contextualization. Under the paper's evaluation protocol, the method achieves the key practical result it aims for: MOS comparable to strong PPEnc baselines after about one epoch instead of about ten, with substantially lower pre-training time.