Edit3DGS
Edit3DGS: Unified Framework for Dynamic Head Editing via 2D Instruction-Guided Diffusion and 3D Gaussian Splatting
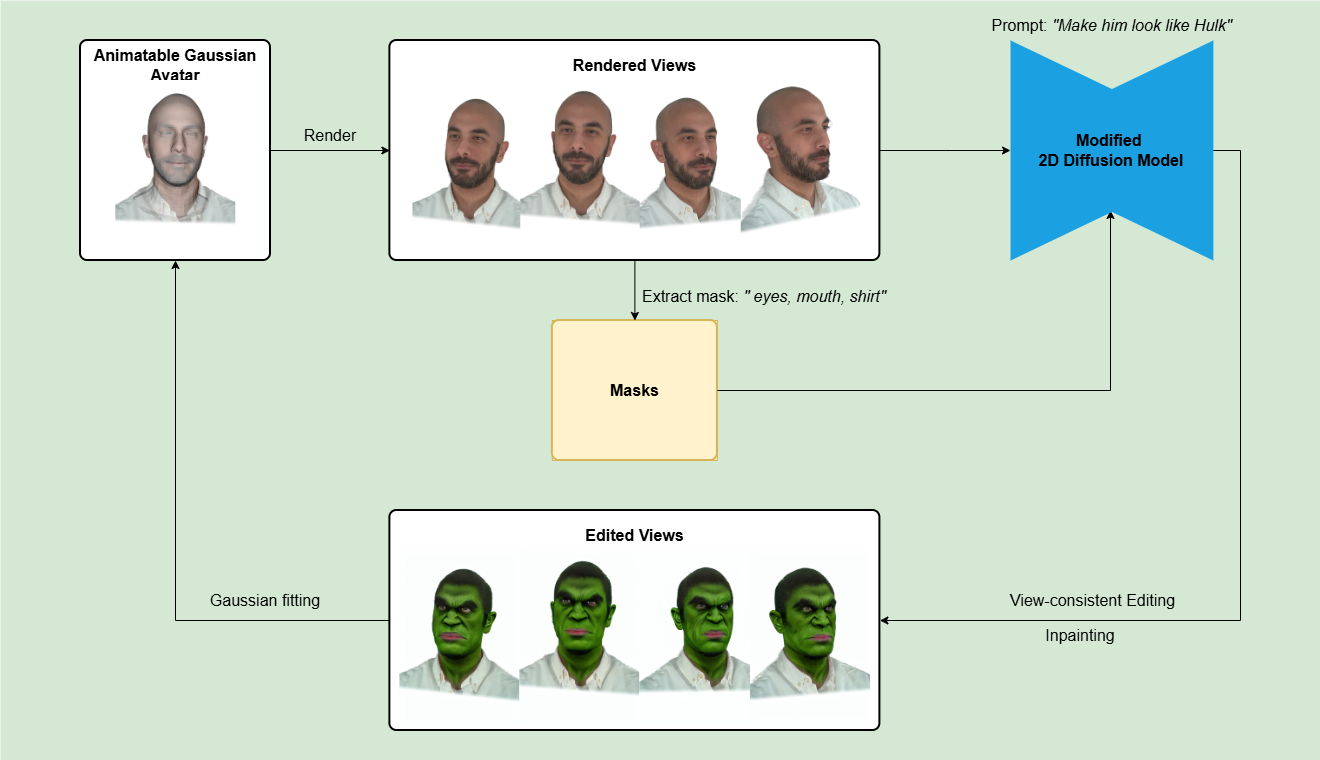
Edit3DGS unifies 2D instruction-guided diffusion with 3D Gaussian splatting for dynamic 3D head editing, ensuring semantic control and temporal consistency. It uses multi-view batch editing and expression-preserving inpainting to create coherent, photorealistic avatars suitable for reenactment and novel view synthesis.
Links
Paper & demos
Abstract
We present Edit3DGS, a unified framework for dynamic 3D head editing that integrates 2D instruction-guided diffusion with 3D Gaussian splatting. Unlike prior approaches that separately address frame-based edits or static 3D reconstruction, our method couples semantic controllability in the image domain with photorealistic, temporally consistent 3D representations. Given an input video, editable facial regions are masked and modified using a text-conditioned diffusion model to support fine-grained operations such as expression transformation, attribute modification, and appearance refinement. The edited frames are then aggregated through 3D Gaussian splatting to produce a coherent, high-fidelity avatar that preserves both identity and motion dynamics. To enforce consistency, Edit3DGS incorporates multi-view batch editing and lightweight inpainting strategies that recover lost expressions across timesteps. Experimental results demonstrate that our framework enables controllable, artifact-free head editing with smooth temporal transitions, offering practical applications in virtual avatars, immersive communication, film production, and interactive media.
Introduction and problem setting
Edit3DGS addresses dynamic 3D head editing: given a reconstructed 3D head avatar and a text instruction, the goal is to edit facial appearance or expression while preserving identity, motion dynamics, and multi-view coherence. The paper positions this as a gap between two mature but previously disconnected lines of work: (1) 2D instruction-guided diffusion editing, which is semantically expressive but view-by-view and therefore prone to inconsistency when applied independently across frames or cameras, and (2) 3D Gaussian Splatting (3DGS), which gives photorealistic and efficient rendering for head avatars but is not itself an editing mechanism.
The core difficulty is consistency. If each rendered view or frame is edited independently, the results tend to drift across cameras and timesteps, causing blur, identity leakage, and broken facial motion when the edited images are re-fit into a 3D model. Edit3DGS’s main claim is that 2D semantic control and 3D structural fidelity can be coupled by editing rendered views in a coordinated way and then re-optimizing the Gaussian avatar from the edited images.
The method is built on a Gaussian head avatar produced by the GaussianAvatars pipeline and uses a render-edit-aggregate loop: render selected views, edit them with a text-conditioned diffusion model, fit the 3D Gaussian model to the edited images, and repeat so that changes propagate to unseen timesteps and views.
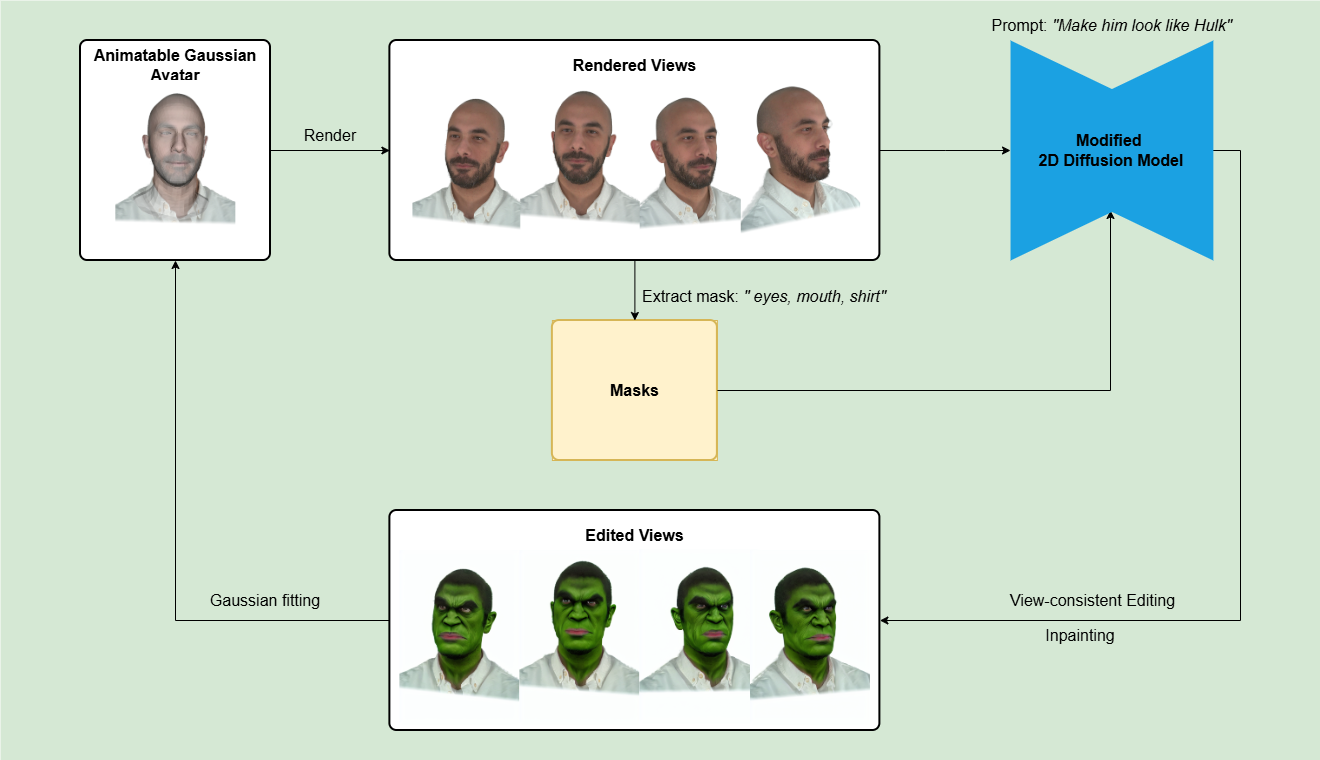
Method overview
Edit3DGS starts from a 3D head avatar already trained with GaussianAvatars. For editing, the method renders a batch of images from selected cameras and timesteps, applies text-guided diffusion-based modification to those images, and then refits the Gaussian avatar using the edited results. The authors emphasize that this is not just one-shot image editing: the edited images are fed back into the 3D pipeline so the underlying avatar changes in a coherent way rather than merely producing edited frames.
The paper highlights two consistency mechanisms:
- Spatial consistency across views through multi-view batch editing.
- Temporal consistency across frames through a lightweight inpainting strategy that restores facial expression cues lost during diffusion edits.
The method is designed for dynamic heads, so the editing process must support changes in expression, pose, and appearance while keeping the avatar animatable. The reported target use cases are novel view rendering, self-reenactment, and cross-identity reenactment.
Base 3D representation: GaussianAvatars
The paper uses GaussianAvatars as the reconstruction backbone. GaussianAvatars binds Gaussian primitives to a parametric head model, specifically FLAME, to provide controllable deformation under pose and expression changes. The authors choose this as the base because it already supports photorealistic rendering and controllable animation, making it a practical foundation for editing. Edit3DGS does not propose a new 3D avatar representation; instead, it edits and refits an existing Gaussian avatar to achieve controllable change.
Editing through Gaussian fitting
The central idea is that if the system can produce a set of multi-view consistent edited images, then the 3D Gaussian model can be updated directly by fitting to those edited images. This is efficient because 3DGS optimizes and renders quickly. The paper notes that a naïve per-view application of an image editor such as Instruct-Pix2Pix yields inconsistent outputs across views and timesteps, which degrades the eventual 3D reconstruction. Edit3DGS therefore augments the 2D editing stage so that the edited image set is suitable for 3D refitting.
Spatially consistent editing via multi-view batching
To enforce consistency among views rendered at the same timestep, the paper adapts a multi-view editing strategy inspired by DGE. A set of rendered views $V$ is passed as a batch to a Stable Diffusion-based editor extended with spatial-temporal attention blocks. The editing process is split into two stages:
- Key-view editing: during each denoising step, a subset of views is randomly selected as key views and edited jointly. The spatial-temporal attention lets the views exchange context so the editor can condition on multiple camera observations at once.
- Feature injection: after key views are edited, their features are propagated to the remaining views to enforce batch-wide coherence. The paper says correspondences are established with epipolar constraints, and matching visual features from different denoising layers are transferred from key to non-key views.
This design is intended to reduce the usual multi-view drift of 2D editing. Rather than making each camera independently satisfy the prompt, the batch is edited jointly so the resulting images are more consistent when refit into 3D.
Temporal consistency via lightweight inpainting
The temporal issue is different: at the same viewpoint, frames from different timesteps often differ mainly in expression and pose, but 2D editors can collapse those dynamics and produce nearly identical faces across time. The paper specifically observes that eyes and mouth are the most common failure points, where emotional detail is lost. To address this, Edit3DGS adds a lightweight inpainting mechanism using a latent diffusion model.
The described procedure is:
- The input images are mapped into latent space at different noise levels.
- Masks isolate the latent regions corresponding to the eyes and mouth of the original faces.
- These masked latent vectors are re-injected later in the denoising process so the original expression cues reappear in the final edit.
The paper frames this as both an expression-preservation mechanism and a way to support local facial editing. In practice, the masks are generated automatically using SAM 2 and Grounding DINO.
Implementation details
The implementation uses a Gaussian head avatar trained with the GaussianAvatars pipeline on a multi-view dataset. For the text-driven image editor, the authors use Instruct-Pix2Pix, explicitly noting that this choice helps comparison with existing work. For inpainting, they combine SAM 2 and Grounding DINO to extract masks covering only the eyes and mouth regions in rendered images.
Training uses the Adam optimizer with learning rate $1 \times 10^{-2}$. For each editing episode, the model runs for $10 \times n$ iterations, where $n$ is the number of timesteps or batches in the considered dataset. At inference time, the avatar can be rendered under novel poses, expressions, and viewpoints guided by FLAME parameters.
The paper does not present a separate analytical loss derivation or a new objective function beyond the Gaussian fitting / diffusion-driven editing loop. The novelty is in the system design that coordinates 2D editing and 3D refitting with consistency constraints.
Dataset and evaluation protocol
Experiments are conducted on NeRSemble, a multi-view video dataset. The paper states that the dataset contains 11 video sequences per subject, with each sequence containing approximately 150 frames showing different expressions and movements. The data are downscaled to 802 × 550. Following the original GaussianAvatars setup, the authors leave one video sequence and one camera view out for quantitative evaluation.
Three evaluation settings are used:
- Novel view rendering
- Self-reenactment
- Cross-identity reenactment
For quantitative comparison, the paper reports the CLIP-based metrics CLIP-S and CLIP-C across those three settings. The baseline is GaussianAvatars-Editor, which the paper describes as the only prior work it is aware of that directly addresses editable 3DGS-based dynamic head models.
Qualitative results
The paper’s qualitative evidence is organized around the three target tasks. In all cases, the claim is that Edit3DGS preserves identity and structural fidelity while applying the requested semantic changes with smoother temporal transitions than independent 2D editing would produce.

Novel view rendering
For novel view rendering, the example prompt is “Make him look older”. The paper reports that Edit3DGS produces coherent edits across viewpoints, with age-related changes visible in skin texture and facial appearance while keeping facial structure stable. The key point is that the edited appearance remains consistent from different camera angles, which suggests that the 2D diffusion edits were successfully integrated into the 3D model rather than remaining view-specific artifacts.

Self-reenactment
In self-reenactment, the edited avatar is driven by unseen expressions and poses from the same actor. The paper reports smooth, temporally coherent results that retain subtle wrinkles, eye gaze, and lip motion. This is the setting most directly connected to the inpainting contribution: because expressions vary over time, preserving mouth and eye detail is essential to avoid flattened or over-smoothed motion.

Cross-identity reenactment
In cross-identity reenactment, expressions and poses from another actor drive the edited avatar. This is the harder task because the system must simultaneously preserve the target identity and accurately transfer the source motion. The paper states that Edit3DGS succeeds in maintaining the edited subject’s identity while conveying complex expressions such as smiles, raised eyebrows, and mouth openings.
Quantitative results
The paper reports the following CLIP-based scores for the three tasks. The authors characterize the gap between Edit3DGS and GaussianAvatars-Editor as small overall, with both methods performing competitively.
| Method | Novel view CLIP-S | Novel view CLIP-C | Self-reenact. CLIP-S | Self-reenact. CLIP-C | Cross-reenact. CLIP-S | Cross-reenact. CLIP-C |
|---|---|---|---|---|---|---|
| GA-Editor | 0.258 | 0.978 | 0.076 | 0.954 | 0.072 | 0.965 |
| Edit3DGS (Ours) | 0.269 | 0.969 | 0.071 | 0.957 | 0.074 | 0.945 |
Interpreting these numbers as reported in the paper, Edit3DGS is slightly better on CLIP-S for novel view rendering and cross-identity reenactment, while GaussianAvatars-Editor is slightly better on some CLIP-C scores. The authors emphasize that these differences are modest and not likely to correspond to large perceptual differences. Their qualitative results are used to argue that Edit3DGS provides a favorable balance of semantic alignment, temporal stability, and visual coherence.
Ablation study
The only ablation explicitly described in the paper disables the inpainting module. The figure shows that without inpainting, edited views lose the original facial expression, especially around the eyes and mouth. The authors argue that this degradation would hurt animation quality because the avatar no longer preserves the fine-grained expression dynamics needed for convincing reenactment.

Although the paper does not provide a numerical ablation table, the qualitative takeaway is clear: masked latent inpainting is essential for maintaining expression detail and temporal plausibility in the edited head avatar.
Contributions and novelty
The paper’s stated contributions are:
- An integrated framework for editing dynamic 3DGS-based head avatars using instruction-guided diffusion and Gaussian fitting.
- Multi-view batch editing plus an auto-generated inpainting mask to preserve expression and improve temporal consistency.
- Demonstration of high-quality edits across novel view rendering, self-reenactment, and cross-identity reenactment.
In the paper’s framing, the novelty is primarily system-level: it combines a 2D diffusion editor, multi-view coordination, and 3D Gaussian refitting into a single pipeline for dynamic head editing. The authors explicitly claim that, to their knowledge, this is the first method to achieve editable 3DGS-based head avatars while preserving structural integrity and rendering quality.
Limitations
The conclusion is candid about two limitations. First, Edit3DGS inherits the constraints of the FLAME model, which cannot perfectly capture fine details such as teeth and hair. Second, performance depends on the choice of 2D diffusion editor, so speed and stability can vary with the underlying image-editing model.
The authors suggest several directions for future work: integrating stronger 3D priors, improving expression modeling, and designing more robust domain-adaptive 2D–3D editing pipelines. These points indicate that while Edit3DGS is effective for controlled head edits, its fidelity is still bounded by the representation and editing priors used underneath.
Conclusion
Edit3DGS presents a practical framework for dynamic head editing that bridges semantic control in 2D with photorealistic 3D Gaussian head avatars. Its key technical ingredients are multi-view batch editing, feature injection for view coherence, and latent inpainting for expression preservation. On NeRSemble, the method produces visually coherent edits for novel views and reenactment scenarios and reports CLIP-based performance that is competitive with the best prior editable 3DGS head method the authors identify.
From a conversational-AI / talking-head perspective, the paper’s main value is that it moves toward editable digital humans whose appearance can be modified through natural language while remaining animatable, view-consistent, and temporally stable. The paper is strongest as a system paper: it does not introduce a new 3D representation or a new diffusion model, but rather a carefully designed editing-and-refitting pipeline that makes existing components work together for dynamic head avatars.