NAR-MBR Speech Recognition
Non-Autoregressive Minimum Bayes' Risk Decoding for Fast Speech Recognition
A fast speech recognition decoding method using non-autoregressive models that improves accuracy by minimizing expected word error rate via sampling. It leverages parallelism to keep decoding speed high while recovering quality lost in standard non-autoregressive decoding.
Links
Paper & demos
Abstract
Non-autoregressive (NAR) decoding generates output tokens in parallel, making speech recognition faster than autoregressive decoding, which generates them sequentially from left to right. However, the recognition performance is degraded because NAR decoding cannot resolve uncertainty by conditioning on previously generated tokens. To address this issue, we propose a novel NAR decoding framework based on minimum Bayes' risk (MBR) decoding, termed NAR-MBR decoding, that maximizes the expected utility calculated from samples drawn from the output probability of an NAR model rather than maximizing the output probability. Notably, by leveraging the nature of NAR models, multiple samples are obtained efficiently with a single forward computation. Our experiments across LibriSpeech, Switchboard, AMI, and web presentation corpus demonstrated that our NAR-MBR decoding outperformed previous NAR decoding and ran faster than AR decoding.
Introduction
The paper addresses a central trade-off in automatic speech recognition (ASR): autoregressive (AR) decoding is accurate but slow because it predicts output tokens sequentially, while non-autoregressive (NAR) decoding is fast because it predicts tokens in parallel but often underperforms due to the loss of left-to-right context conditioning. The authors target this performance gap without adding any extra training.
The key idea is to replace NAR maximum-a-posteriori-style selection with minimum Bayes' risk (MBR) decoding. Instead of choosing the single highest-probability output, the decoder chooses the hypothesis that maximizes expected utility under samples drawn from the NAR model. In ASR, the utility is the negative word error rate (WER), so the chosen output is the one that minimizes expected WER over sampled pseudo-references.
The paper's main claim is that NAR MBR decoding can preserve much of the speed advantage of NAR decoding while recovering recognition quality, and in the reported experiments it outperformed prior NAR decoding while remaining faster than AR beam search.
Background: AR decoding, NAR decoding, and MBR
Let $x$ denote the speech input and $y$ the output token sequence. In AR decoding, the output distribution is factorized as
$$p_{ ext{AR}}(y \mid x) = \prod_{t=1}^{|y|} p(y_t \mid x, y_{<t}).$$
This sequential dependence lets the model condition on previously emitted tokens, which helps resolve ambiguity, but it also means that decoding requires one probability computation per output step.
In NAR decoding, the factorization is simplified to
$$p_{ ext{NAR}}(y \mid x) = \prod_{t=1}^{|y|} p(y_t \mid x),$$
so multiple tokens can be generated in parallel. The paper explains that this removes the left-to-right dependency but introduces the well-known multi-modality problem: because the model cannot condition on previously generated tokens, it may struggle to commit to a single coherent output path.
The paper uses Mask-CTC as the NAR model family. Mask-CTC combines a CTC encoder, which predicts framewise token/blank probabilities, with a conditional masked language model (CMLM) decoder that fills in low-confidence tokens. The encoder first produces a CTC alignment path, which is then collapsed to a token sequence. Tokens whose confidence is below a threshold are replaced with a mask token, and the CMLM predicts the masked positions. The number of CMLM refinement stages is denoted by $n_{\text{iter}}$; $n_{\text{iter}}=0$ means the raw CTC output is used directly, without the CMLM.
For decision rules, the paper contrasts MAP decoding with MBR decoding. MAP selects the highest-probability hypothesis from a pruned hypothesis set $\mathcal{H}$:
$$\hat{y}_{\text{MAP}} = \arg\max_{\hat{y} \in \mathcal{H}} p(\hat{y} \mid x).$$
MBR instead selects the hypothesis that maximizes expected utility:
$$\hat{y}_{\text{MBR}} = \arg\max_{\hat{y} \in \mathcal{H}} \mathbb{E}_{y \sim p(\cdot \mid x)}[u(\hat{y}; y)].$$
In the paper, $u(\hat{y}; y)$ is negative WER after detokenization, so the decision rule is equivalent to minimizing expected WER. Since the true expectation is unavailable, it is estimated with Monte Carlo samples (pseudo-references) drawn from the model distribution.
Proposed method: NAR-MBR decoding
The proposed framework has two stages: (1) efficient unbiased sampling from a Mask-CTC model, and (2) MBR selection using an efficient edit-distance-based expected utility estimate. The novelty is not just applying MBR to ASR, but doing so in a way that exploits NAR structure so that many samples can be obtained from a single forward pass.
Overview
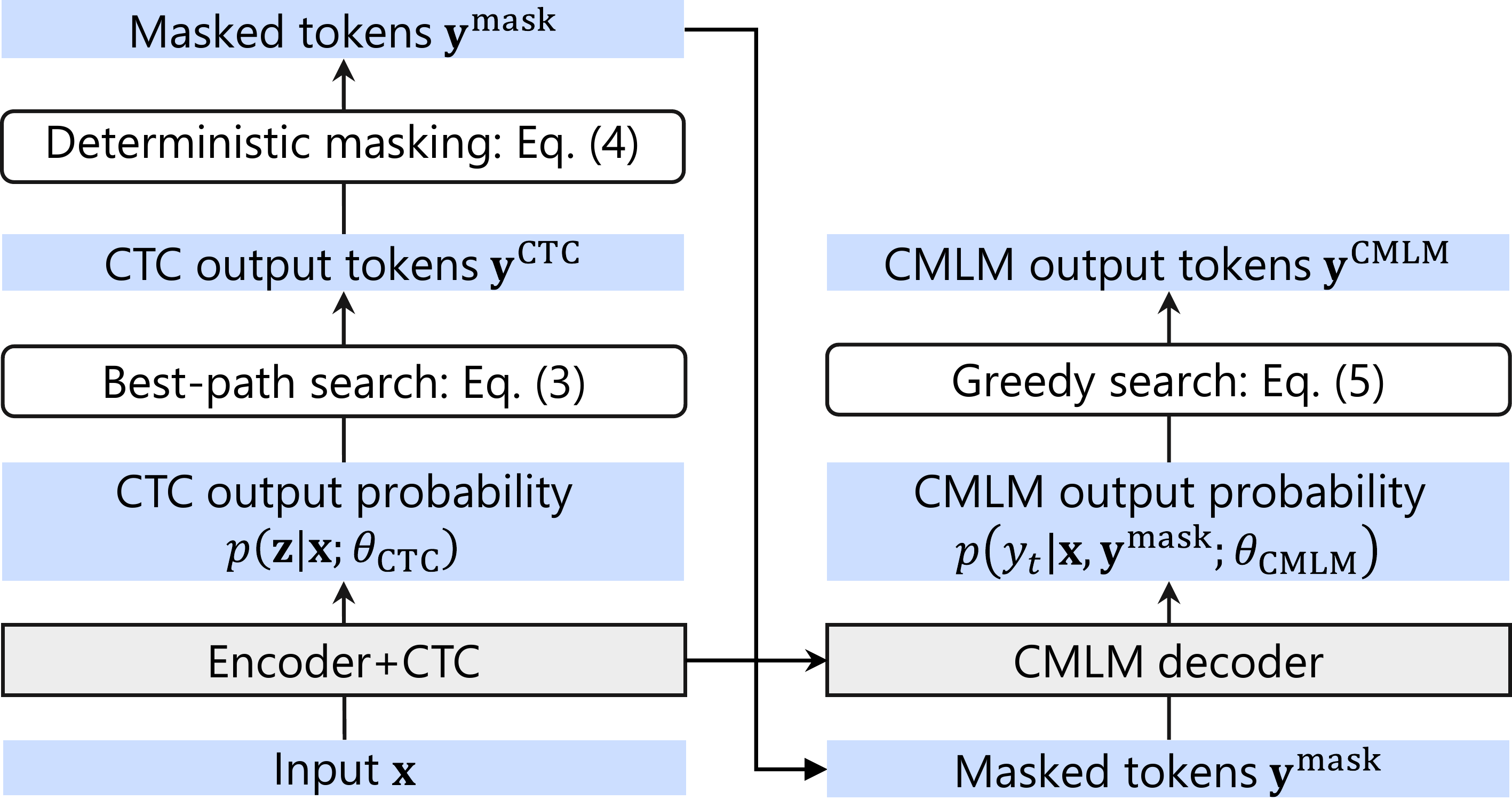
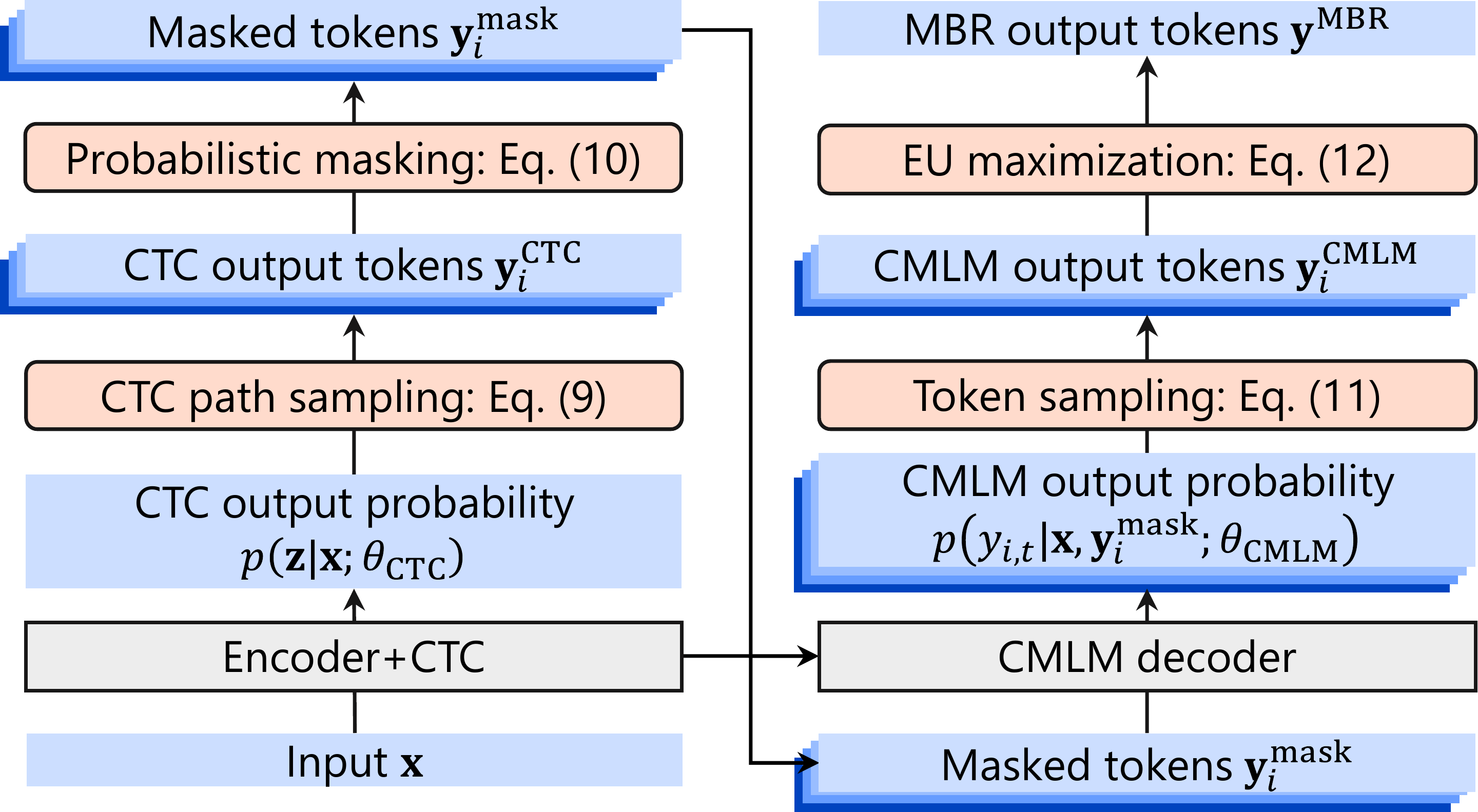
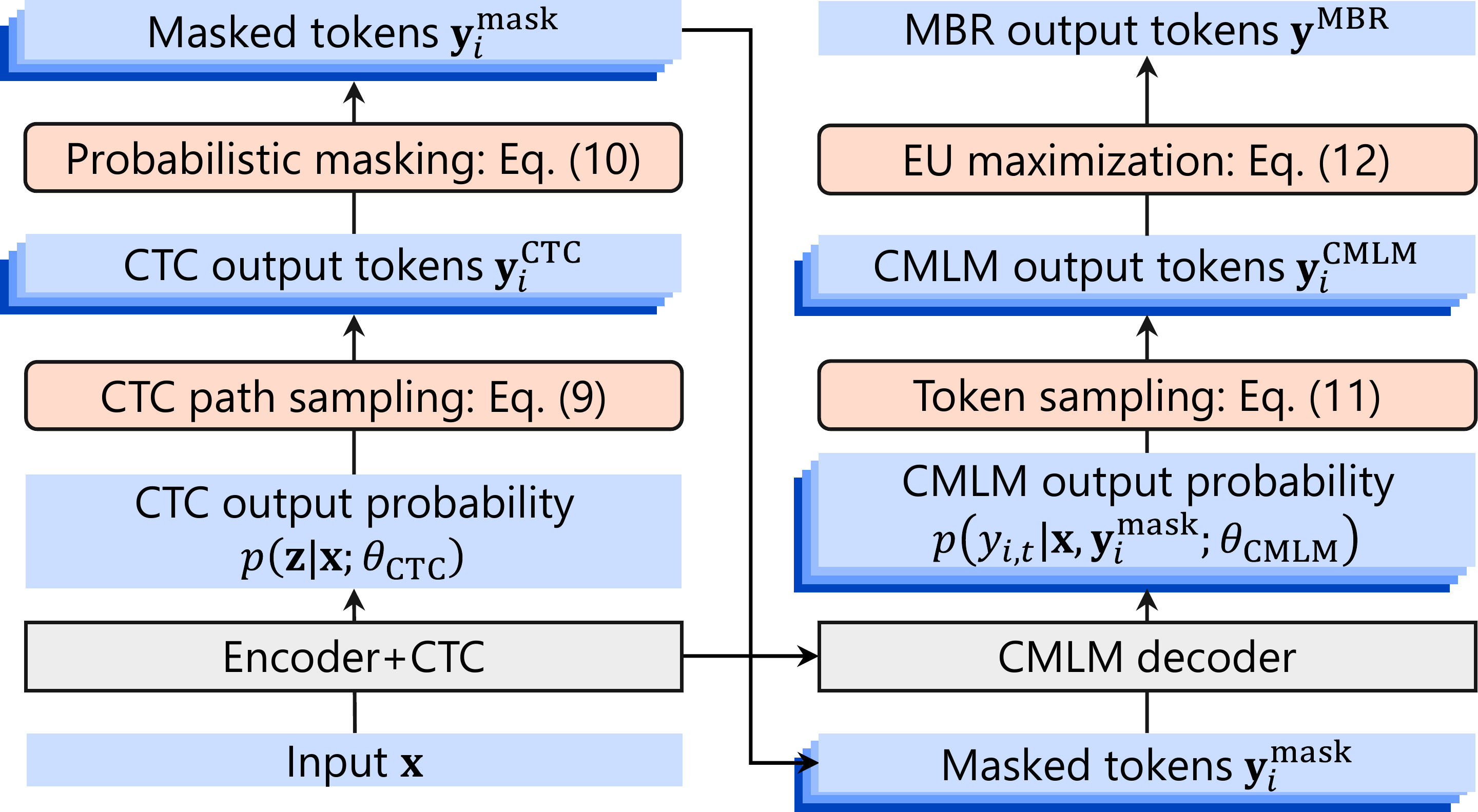
These overview figures illustrate the difference between standard Mask-CTC decoding and the proposed NAR-MBR decoding. The main change is in how candidate outputs are generated and selected: instead of deterministic greedy-style output selection, the method samples multiple outputs and evaluates them under an MBR objective.
1) Probabilistic unbiased sampling from Mask-CTC
The first stage samples CTC alignment paths independently across frames. Because Mask-CTC is non-autoregressive, all framewise probabilities are available after a single forward computation, so generating multiple samples does not require repeating the forward pass the way it would in an AR model.
The paper samples each frame from a categorical distribution:
$$z_{i,t} \sim \mathrm{Cat}(p(z_t \mid x; \theta_{\mathrm{ctc}})),$$ where $z_{i,t}$ is the sampled CTC symbol for sample $i$ at frame $t$.
After collapsing the CTC path to a token sequence, masking is applied according to token confidence. For each token position, the mask indicator is sampled as
$$m_{i,t} \sim \mathrm{Bernoulli}(1 - p(y^{\mathrm{ctc}}_{i,t} \mid x; \theta_{\mathrm{ctc}})).$$
Unconfident tokens are replaced by a mask, and the CMLM decoder fills those positions by sampling from its output distribution. The paper notes that the Gumbel-max trick is used to probabilistically fix higher-confidence tokens instead of using a deterministic top-$k$ style rule. As in standard Mask-CTC, the process can be repeated for multiple refinement stages $n_{\text{iter}}$, and $n_{\text{iter}}=0$ bypasses the CMLM decoder entirely.
For MBR, the same sampled set is used both as hypotheses and pseudo-references, following standard practice. This is important because the expected utility estimate needs a representative set drawn from the model distribution rather than a beam-pruned or otherwise biased set.
2) Efficient expected-utility maximization
With the sampled hypotheses and pseudo-references, the decoder chooses the hypothesis with the largest empirical expected utility:
$$\hat{y}_{\text{NAR-MBR}} \approx \arg\max_{\hat{y} \in \mathcal{H}} -\frac{1}{|\mathcal{P}|} \sum_{y \in \mathcal{P}} \mathrm{WER}(\sigma(\hat{y}), \sigma(y)), $$
where $\sigma(\cdot)$ denotes detokenization and $\mathcal{P}$ is the multiset of pseudo-references.
Because naive pairwise scoring is quadratic in the number of samples, the paper introduces several practical speedups:
- Longest common prefix/suffix removal: before edit-distance calculation, shared prefixes and suffixes are removed because they do not affect the edit distance.
- Memoization: duplicate sample pairs are detected, unique hypothesis/pseudo-reference pairs are scored once, and cached results are reused.
- Parallelization: edit-distance computations for unique pairs are distributed across multiple CPUs.
- Rust-based WER implementation: the paper implements WER, including text normalization, in Rust and converts words to $u32$ IDs to avoid expensive string comparisons.
These engineering choices are central to the paper's contribution because they let MBR decoding remain practical even after adding the utility-based reranking step.
Experimental setup
The paper evaluates recognition quality and decoding speed on four datasets: LibriSpeech, Switchboard (SWBD), AMI, and a web presentation corpus (Web). The Web corpus is described in the paper as having 346 hours of training data from 1,938 speakers and 3.7 hours each for development and test, from 16 speakers.
For model comparison, the AR baseline is Conformer, and both NAR and NAR-MBR use Mask-CTC. The paper states that all models are trained with the default hyperparameters for each dataset as defined in ESPNet, and that the models share the same number of parameters and other hyperparameters; the main differences are architecture and loss function.
The decoding settings are:
- AR decoding: joint decoding with CTC, using CTC weight $0.3$; beam widths of $1$ (greedy) and $10$ are reported.
- NAR decoding: masking threshold $\alpha = 0.999$; refinement iterations $n_{\text{iter}} \in \{0, 1, 10\}$.
- NAR-MBR decoding: sample sizes $|\mathcal{P}| \in \{64, 256\}$ and refinement iterations $n_{\text{iter}} \in \{0, 1, 10\}$.
Recognition quality is measured by WER. The paper also reports statistical significance via paired bootstrap resampling with 1,000 resamples, comparing NAR-MBR against baseline NAR decoding. For speed, wall-clock time includes encoder and decoder forward computation as well as utility calculation for NAR-MBR, but excludes model loading and data loading. GPU memory usage is reported relative to AR beam decoding.
The experiments were run on 8 CPU cores of an Intel Xeon Gold 6346 and an NVIDIA RTX 6000 Ada GPU.
Results
Word error rate
The main WER results show that NAR-MBR consistently improves over plain NAR decoding, and that the best NAR-MBR setting is usually achieved with only one refinement iteration. The paper emphasizes that the MBR step itself appears to resolve uncertainty, so iterative refinement beyond $n_{\text{iter}}=1$ does not help much.
| Decoding | LibriSpeech Clean | LibriSpeech Other | SWBD Swbd | SWBD Callhm | AMI | Web |
|---|---|---|---|---|---|---|
| AR | ||||||
| Greedy | 3.0 | 6.0 | 6.9 | 13.9 | 17.8 | 8.2 |
| Beam | 2.4 | 5.5 | 6.6 | 13.5 | 17.0 | 7.3 |
| NAR | ||||||
| $n_{\text{iter}}=0$ | 3.3 | 7.4 | 7.9 | 15.7 | 18.9 | 7.7 |
| $n_{\text{iter}}=1$ | 3.4 | 7.7 | 7.8 | 15.6 | 18.8 | 8.9 |
| $n_{\text{iter}}=10$ | 3.3 | 7.5 | 7.6 | 15.2 | 18.4 | 8.5 |
| NAR-MBR, $|\mathcal{P}|=64$ | ||||||
| $n_{\text{iter}}=0$ | 3.3 | 7.4 | 7.8 | 15.6 | 18.7 | 7.6 |
| $n_{\text{iter}}=1$ | 3.1 | 7.1 | 7.3 | 14.9 | 18.1 | 7.4 |
| $n_{\text{iter}}=10$ | 3.1 | 7.1 | 7.4 | 14.9 | 18.1 | 7.4 |
| NAR-MBR, $|\mathcal{P}|=256$ | ||||||
| $n_{\text{iter}}=0$ | 3.2 | 7.4 | 7.7 | 15.5 | 18.6 | 7.5 |
| $n_{\text{iter}}=1$ | 3.1 | 7.0 | 7.3 | 14.9 | 18.1 | 7.3 |
| $n_{\text{iter}}=10$ | 3.1 | 7.0 | 7.3 | 14.9 | 18.1 | 7.3 |
Several patterns are emphasized by the authors:
- NAR-MBR improves WER over NAR for both sample sizes and for $n_{\text{iter}} \in \{1, 10\}$ on all datasets, with statistically significant gains in the reported cases.
- Increasing the number of samples from $64$ to $256$ slightly improves WER, consistent with more stable Monte Carlo estimation of expected utility.
- Increasing $n_{\text{iter}}$ beyond $1$ does not meaningfully improve NAR-MBR; performance effectively saturates at $n_{\text{iter}}=1$.
- On Web, NAR-MBR with $|\mathcal{P}|=256$ and $n_{\text{iter}}=1$ matches beam search WER exactly at $7.3$.
Decoding speed and memory
The speed table shows that NAR-MBR remains substantially faster than AR beam decoding, even after the MBR reranking overhead is included.
| Decoding | LS Clean Speed | LS Clean Mem | LS Other Speed | LS Other Mem | Web Speed | Web Mem |
|---|---|---|---|---|---|---|
| AR | ||||||
| Greedy | 5.3× | 1.0× | 5.2× | 1.0× | 5.0× | 1.0× |
| Beam | 1.0× | 1.0× | 1.0× | 1.0× | 1.0× | 1.0× |
| NAR | ||||||
| $n_{\text{iter}}=0$ | 61.3× | 1.0× | 50.1× | 1.0× | 90.3× | 1.0× |
| $n_{\text{iter}}=1$ | 44.2× | 1.0× | 34.7× | 1.0× | 71.3× | 1.0× |
| $n_{\text{iter}}=10$ | 21.3× | 1.0× | 15.2× | 1.0× | 26.7× | 1.0× |
| NAR-MBR, $|\mathcal{P}|=64$ | ||||||
| $n_{\text{iter}}=0$ | 38.7× | 1.0× | 32.1× | 1.0× | 75.2× | 1.0× |
| $n_{\text{iter}}=1$ | 27.4× | 1.3× | 22.4× | 1.3× | 43.1× | 1.8× |
| NAR-MBR, $|\mathcal{P}|=256$ | ||||||
| $n_{\text{iter}}=0$ | 30.9× | 1.0× | 22.1× | 1.0× | 41.1× | 1.0× |
| $n_{\text{iter}}=1$ | 11.8× | 2.7× | 9.7× | 2.4× | 20.7× | 5.0× |
The paper highlights that NAR-MBR with $n_{\text{iter}}=1$ is still faster than AR decoding, including greedy AR, while giving better WER than plain NAR. The memory footprint is modest at $n_{\text{iter}}=0$ but grows at $n_{\text{iter}}=1$, especially for larger sample sizes, because the CMLM decoder adds cost. This is the main practical limitation discussed in the paper.
Effect of the number of samples
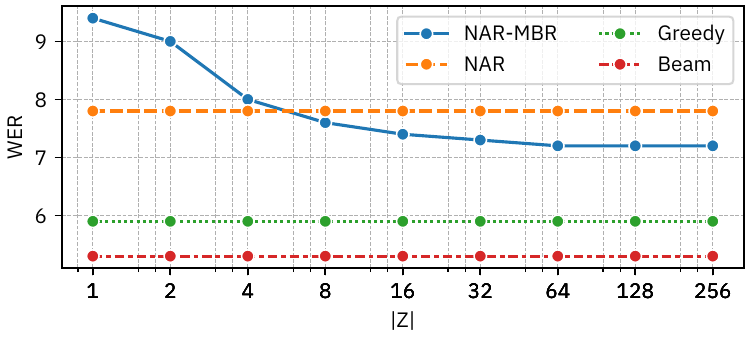
The sample-size study on LibriSpeech Other shows a monotonic improvement in WER as the number of samples increases, with the gain saturating around $|\mathcal{P}| \geq 64$. The paper explicitly connects this behavior to Monte Carlo convergence and notes that the trend is similar to theoretical analyses of AR MBR convergence rate cited in the paper.
Interpretation and limitations
The paper's main technical conclusion is that much of the quality gap between AR and NAR decoding can be recovered by changing the decision rule rather than the training objective. In other words, the NAR model is not merely a faster approximation to AR; with the right sampling-based decision rule, it can support high-quality output selection while preserving most of the speed advantage.
The authors' own discussion also makes the limitations clear. First, NAR-MBR does introduce additional computation relative to plain NAR because the expected-utility calculation has to score sample pairs. Second, memory usage increases at $n_{\text{iter}}=1$, particularly with more samples. Third, the method is evaluated on Mask-CTC rather than on a broader set of NAR architectures, so the generality beyond this family is left for future work. Finally, the authors state that more memory-efficient sampling and extension to other models and tasks are natural next steps.
Conclusion
NAR-MBR decoding is a sampling-based decision rule for Mask-CTC ASR that uses unbiased NAR samples and MBR reranking with negative WER as utility. The method requires no additional training, improves recognition over baseline NAR decoding across LibriSpeech, Switchboard, AMI, and the web presentation corpus, and remains substantially faster than AR beam search. The best trade-off in the reported experiments is achieved with $n_{\text{iter}}=1$, and the method is especially strong when the sample count is at least $64$.