DeSRPA
DeSRPA: Decoupled Speech Role-Playing Agent via Inference-Time Intervention
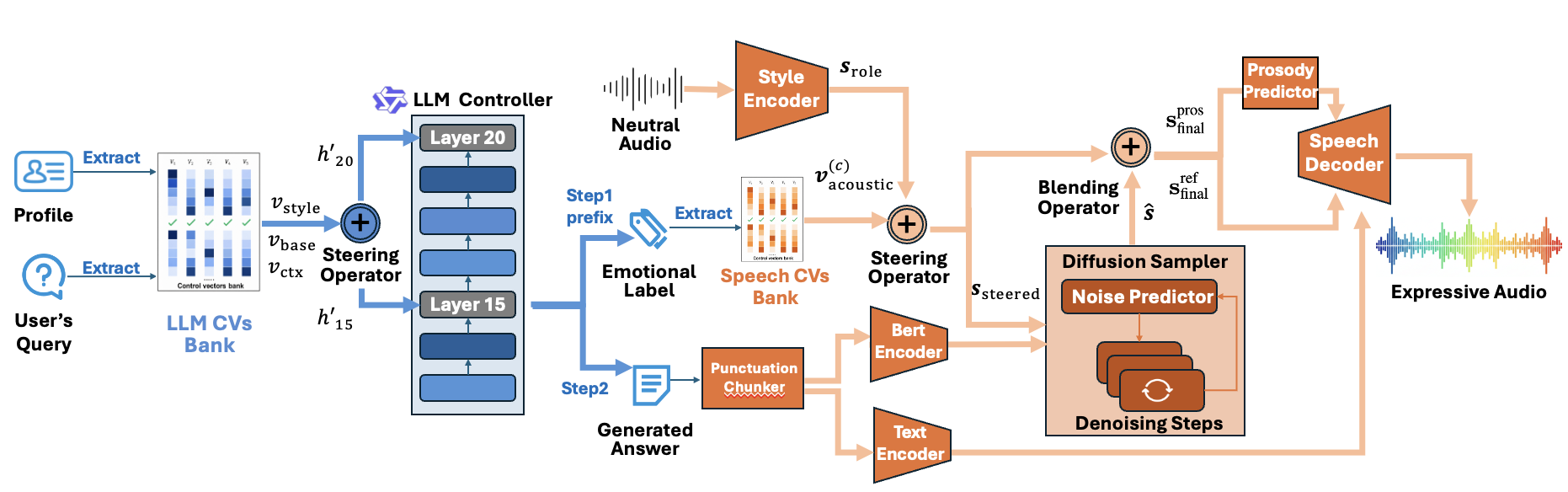
DeSRPA is a speech role-playing agent framework that decouples persona reasoning from speech rendering at inference. It uses frozen LLM and TTS models steered by control vectors, enabling scalable, training-free character adaptation with enhanced personality and emotional consistency.
Links
Paper & demos
Abstract
While Large Language Models (LLMs) have revolutionized text-based role-playing, creating immersive Speech Role-Playing Agents (SRPAs) requires a seamless bridge between cognitive reasoning and paralinguistic nuances. Current SRPAs primarily rely on end-to-end (E2E) fine-tuning. However, this paradigm suffers from poor generalization to unseen characters due to its reliance on role-specific data, while imposing a "modality alignment tax" that degrades intrinsic LLM reasoning capabilities. We propose DeSRPA, an agentic framework for character role play via inference-time intervention on frozen backbones. DeSRPA employs a dual-level control vector mechanism, Internal Cognitive Steering and External Expressive Rendering, to synchronize "mind" and "voice". Experiments on SpeechRole and OmniCharacter benchmarks demonstrate that DeSRPA significantly outperforms E2E baselines in personality and emotional consistency. It achieves high speech naturalness, narrowing the gap with proprietary models like GPT-4o Audio, while remaining a scalable and training-free paradigm.
Introduction
DeSRPA targets a specific gap in speech role-playing agents (SRPAs): how to combine strong persona reasoning with expressive, character-consistent speech without paying the cost of end-to-end (E2E) speech fine-tuning. The paper’s central claim is that current SRPAs are constrained by two related failure modes. First, E2E training on role-specific audio data does not generalize well to unseen characters and scales poorly as the character set grows. Second, tightly coupling text and speech modalities can impose a “modality alignment tax,” where acoustic adaptation degrades the base LLM’s reasoning and persona consistency.
The proposed solution is a decoupled framework, DeSRPA, that performs character adaptation at inference time on frozen backbones. Instead of updating model weights, DeSRPA steers a frozen LLM and a frozen TTS system using control vectors. The design separates the agent into an internal cognitive layer that shapes what the model thinks and says, and an external expressive layer that shapes how the speech is rendered. This lets the system preserve the reasoning strengths of the LLM while still injecting role-specific linguistic style and emotional expression.
The paper positions DeSRPA against both cascaded LLM-TTS pipelines and E2E speech models. Cascaded systems preserve language reasoning but often suffer semantic-acoustic misalignment, because the intermediate text bottleneck can lose emotional nuance. E2E systems remove that bottleneck, but they typically require heavy supervision and can blur the distinction between persona control and speech control. DeSRPA aims to keep the benefits of both worlds while avoiding their most important drawbacks.
Framework Overview
The architecture uses two frozen modules: a frozen LLM controller and a frozen StyleTTS~2 backbone. The LLM side is instantiated with Qwen3-4B and is responsible for cognitive steering. The TTS side renders the final audio. The connection between them is not gradient-based training, but inference-time intervention through explicit control vectors.
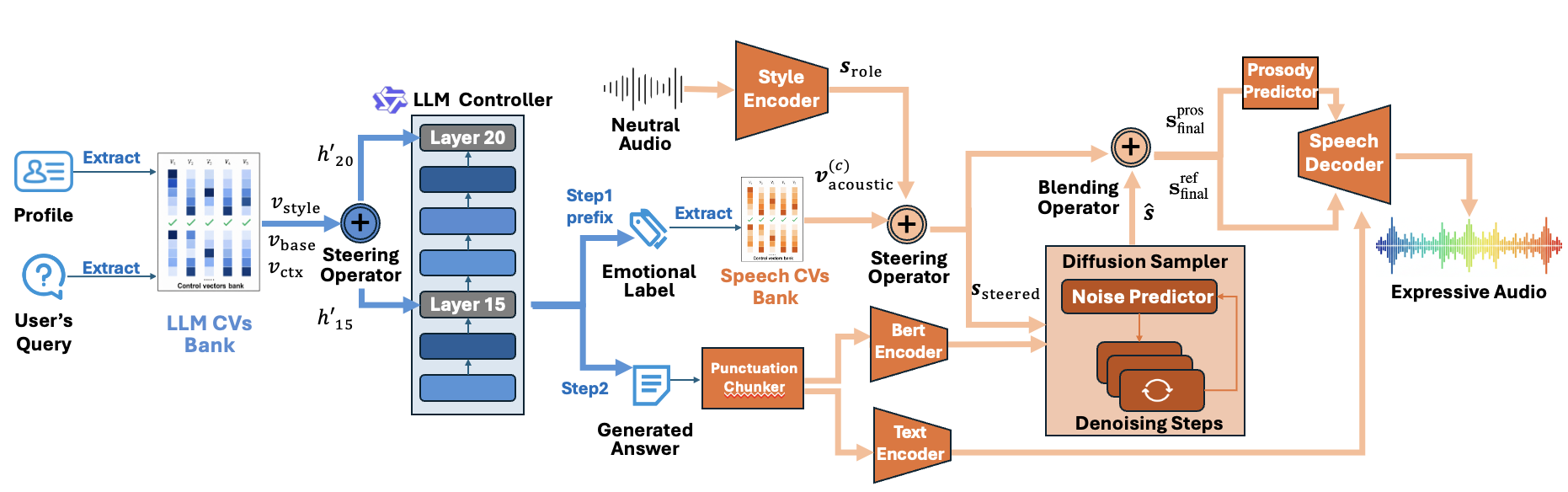
Conceptually, DeSRPA introduces a dual-level control mechanism:
- Internal Cognitive Steering: persona-, context-, and style-related control vectors are injected into the LLM residual stream to shape character-consistent reasoning and response formulation.
- External Expressive Rendering: the LLM’s predicted emotion tags are mapped to acoustic control vectors that steer the TTS model toward the target emotional realization.
The overall goal is synchronization between “mind” and “voice”: the text emitted by the LLM should reflect the character’s identity and current stance, and the synthesized speech should express that intent with aligned prosody, timbre, and emotional intensity.
Methodology
Internal Cognitive Steering
On the language side, DeSRPA avoids parameter updates and instead intervenes in selected LLM layers using sparse control vectors learned with Sparse Autoencoders (SAEs). The paper describes a steering loss that moves latent states toward a target centroid while pushing them away from an opposing centroid, while also preserving language-model quality and enforcing sparsity:
$$\mathcal{L}_{\mathbf{steer}} = \lVert \mathbf{z}' - \boldsymbol{\mu}^{+} \rVert_{2}^{2} - \lVert \mathbf{z}' - \boldsymbol{\mu}^{-} \rVert_{2}^{2} + \mathcal{L}_{\mathbf{LM}} + \lambda \lVert \mathbf{v} \rVert_{1}$$
where $\mathbf{z}' = \mathbf{z} + \mathbf{v}$ is the steered latent representation, $\mathcal{L}_{\mathbf{LM}}$ preserves generation quality, and the $\ell_1$ penalty encourages a sparse vector. The paper uses layer-specific control vectors because different depths capture different kinds of information: mid-layers are treated as more responsible for core semantics, while deeper layers are treated as more responsible for surface style.
The paper organizes the LLM control into three functions:
- Personality Base vector $\mathbf{v}_{\text{base}}$ at Layer 15, to shape core identity.
- Contextual Activation vector $\mathbf{v}_{\text{ctx}}$ at Layer 15, to activate trait expression in the current situation.
- Linguistic Style vector $\mathbf{v}_{\text{style}}$ at Layer 20, to modulate phrasing and idiolect.
The paper states that these vectors are trained across 30 fine-grained personality facets, extending beyond standard Big Five personality modeling, and that the training data come from a 15k dataset for facet-level persona control. During inference, the hidden states are modified as:
$$\mathbf{h}_{15}' = \mathbf{h}_{15} + w_{b} \mathbf{v}_{\text{base}} + w_{c} \mathbf{v}_{\text{ctx}}, \quad \mathbf{h}_{20}' = \mathbf{h}_{20} + w_{s} \mathbf{v}_{\text{style}}$$
The scaling coefficients $w_{b}$, $w_{c}$, and $w_{s}$ are grounded in objective personality metrics from PDB and further refined with Human-LLM collaborative annotation. The authors report a strong inter-rater agreement of Pearson’s $r = 0.82$. The contextual control vector $\mathbf{v}_{\text{ctx}}$ is activated dynamically according to Trait Activation Theory, so that character traits appear when the conversation context calls for them rather than being applied uniformly.
External Expressive Rendering
On the speech side, DeSRPA uses a frozen StyleTTS~2 model. The key idea is to convert the LLM’s semantic emotion decision into a latent acoustic steering signal that can be injected into StyleTTS~2 without fine-tuning.
To build acoustic control vectors, the paper uses two multi-speaker emotional speech datasets: the Emotional Speech Database (ESD) and CREMA-D. Samples are filtered to ensure emotion purity and audio stability. For each target emotion $c \in \{\text{neutral}, \text{angry}, \text{happy}, \text{sad}, \text{surprise}, \text{disgust}, \text{fear}\}$, the paper keeps samples with Emo2Vec scores above $0.90$ and silence rate below $20\%$, then selects the best $N = 300$ examples per emotion.
StyleTTS~2 produces a unified style representation $S(x) = [\mathbf{r}_s; \mathbf{r}_p] \in \mathbb{R}^{256}$, with a 128-dimensional reference component and a 128-dimensional prosody component. To avoid entangling emotion with speaker identity, the paper computes a difference vector between the mean emotional embedding and the mean neutral embedding:
$$\mathbf{v}_{\text{acoustic}}^{(c)} = \frac{1}{N} \sum_{i=1}^{N} S(x_{i}^{(c)}) - \frac{1}{N} \sum_{i=1}^{N} S(x_{i}^{(n)})$$
This style-subtraction construction is intended to capture the direction of emotional change in latent space, rather than memorizing a specific emotional voice. The paper reports that this helps preserve speaker similarity while still enabling expressive variation.
At inference time, DeSRPA uses a dual-path fusion strategy. First, it extracts a role-specific neutral reference style $\mathbf{s}_{\text{role}}$. Then it steers this style with the acoustic control vector:
$$\mathbf{s}_{\text{steered}} = \mathbf{s}_{\text{role}} + \tau \mathbf{v}_{\text{acoustic}}^{(c)}$$
where the emotion intensity scalar $\tau \in [0.5, 2.5]$ is determined by the product of the LLM-inferred emotion label weight and an annotated intensity score. The paper notes that $\tau = 0.5$ corresponds to subtle emotional onset, while $\tau = 2.5$ corresponds to peak expressiveness.
The steered style is then passed through the diffusion-based Style Predictor to produce a text-coherent predicted style $\hat{\mathbf{s}}$. Finally, the system interpolates between the predicted and steered styles:
$$\mathbf{s}^{\text{ref}}_{\text{final}} = (1 - \rho) \hat{\mathbf{s}}^{\text{ref}} + \rho \mathbf{s}^{\text{ref}}_{\text{steered}}$$
$$\mathbf{s}^{\text{pros}}_{\text{final}} = (1 - \eta) \hat{\mathbf{s}}^{\text{pros}} + \eta \mathbf{s}^{\text{pros}}_{\text{steered}}$$
The authors set $\rho = 0.8$ to keep speaker similarity above the verification threshold, and they observed that $\eta > 0.5$ yields diminishing returns for emotion execution accuracy. This is an explicit engineering compromise between emotional intensity and natural prosody.
What is novel in the method
- It is training-free at adaptation time: no role-specific SFT is required for new characters.
- It uses a dual-level control scheme to tie together internal persona reasoning and external expressive rendering.
- It leverages layer-specific LLM steering rather than end-to-end parameter updates, keeping the backbone frozen.
- It constructs emotion direction vectors by subtracting neutral style embeddings from emotional embeddings, reducing speaker-identity leakage.
Experimental Setup
The evaluation is designed to cover both plot-anchored character imitation and open-domain role-play. The paper uses two benchmarks.
- SpeechRole-Data test split: the main benchmark for plot-based evaluation. The authors curate 72 English characters from movies and TV series, with an average of 10 dialogue turns each, yielding 372 evaluated responses.
- OmniCharacter-10K test split: an open-domain benchmark with 10 characters from the RPG Genshin Impact, where prompts go beyond source narrative and require extrapolation to novel topics.
On SpeechRole, the paper combines automated and multimodal-judge evaluation. Gemini 2.5 Pro is used as a multimodal judge to score pairwise responses against the ground truth on eight dimensions: instruction adherence, fluency, coherence, naturalness, prosody, emotion, personality, and knowledge.
The paper also reports objective metrics that directly target speech quality and role fidelity:
- TTFA ($\downarrow$): time-to-first-audio, measuring streaming latency from user input to the first audio chunk.
- SIM ($\uparrow$): speaker similarity using cosine similarity of WaveLM speaker embeddings against reference audio.
- EEA ($\uparrow$): emotion execution accuracy, using emotion2vec to compare predicted and rendered emotion.
- WER ($\downarrow$): word error rate from ASR transcriptions, measuring intelligibility.
For OmniCharacter-10K, the paper additionally performs human evaluation with six experts on a 10-point Likert scale across fluency, consistency, emotional expression, clarity, appropriateness, and immersion.
The baseline set includes open-source E2E and role-playing models such as Qwen2.5-Omni, LLaMA-Omni, SpeechRole, and OmniCharacter, plus proprietary systems including GPT-4o Audio and the AliCloud pipeline using qwen-plus-character with CosyVoice3. The ablations remove either both control-vector components, only the LLM-side vectors, or only the speech-side vectors.
Main Results on SpeechRole
The main table below summarizes the paper’s SpeechRole results. The headline result is that DeSRPA achieves the best mean automated score among open-source systems, while also outperforming the other open-source baselines on the key role-consistency and emotion-rendering metrics that matter most for SRPAs.
| Metric | Qwen2.5 | LLaMA | SpeechRole | DeSRPA | w/o Both | w/o LLM | w/o Speech | GPT-4o | AliCloud |
|---|---|---|---|---|---|---|---|---|---|
| TTFA (ms) | 274 | 226 | 389 | 577 | 561 | 573 | 569 | 320 | 872 |
| SIM | < 0.80 | < 0.80 | < 0.80 | 0.886 | 0.919 | 0.905 | 0.892 | < 0.80 | 0.859 |
| EEA | 0.453 | 0.397 | 0.433 | 0.701 | 0.537 | 0.677 | 0.549 | 0.501 | 0.694 |
| WER (%) | 0.98 | 2.21 | 5.31 | 2.63 | 2.49 | 2.64 | 2.52 | 2.03 | 1.74 |
| Instruction Adherence | 0.5127 | 0.7808 | 0.8203 | 0.8790 | 0.8745 | 0.8810 | 0.8799 | 0.9137 | 0.8986 |
| Speech Fluency | 0.6714 | 0.8795 | 0.8745 | 0.8741 | 0.8922 | 0.8891 | 0.8846 | 0.9329 | 0.8706 |
| Conversation Coherence | 0.6326 | 0.8607 | 0.9316 | 0.9506 | 0.9548 | 0.9245 | 0.9351 | 0.9983 | 0.9563 |
| Speech Naturalness | 0.6474 | 0.7864 | 0.7838 | 0.8147 | 0.8155 | 0.8152 | 0.8149 | 0.9079 | 0.8177 |
| Prosodic Consistency | 0.4763 | 0.6620 | 0.6505 | 0.7958 | 0.6936 | 0.7412 | 0.7186 | 0.8046 | 0.7743 |
| Emotion Appropriateness | 0.4793 | 0.6427 | 0.6913 | 0.8160 | 0.6874 | 0.7568 | 0.7245 | 0.8341 | 0.7872 |
| Personality Consistency | 0.3931 | 0.6415 | 0.6122 | 0.7615 | 0.7167 | 0.7235 | 0.7592 | 0.8018 | 0.7402 |
| Knowledge Consistency | 0.5907 | 0.7077 | 0.8334 | 0.8116 | 0.7828 | 0.7743 | 0.8074 | 0.8910 | 0.8405 |
| Mean (Automated Eval) | 0.5504 | 0.7452 | 0.7747 | 0.8379 | 0.8022 | 0.8120 | 0.8168 | 0.8862 | 0.8356 |
The paper’s interpretation of these results is straightforward: among open-source methods, DeSRPA is best overall on the mean automated score, and it is especially strong on personality consistency, emotion appropriateness, and prosodic consistency. It also achieves the best EEA at $0.701$, showing that the emotional label predicted by the LLM is being realized effectively in the speech module. Compared with the AliCloud pipeline, DeSRPA shows stronger paralinguistic control, especially in prosody and emotion.
DeSRPA is not the fastest system in the table. Its TTFA is $577$ ms, which is slower than fully E2E models such as LLaMA-Omni at $226$ ms and GPT-4o Audio at $320$ ms. The paper frames this as an expected latency trade-off for a decoupled and controllable architecture, while still noting that DeSRPA is much lighter than the AliCloud pipeline at $872$ ms.
Ablation Analysis
The ablations are important because they separate the contributions of the two control levels. Removing both control-vector modules gives a strong general-purpose baseline, but it loses character alignment. Removing only the LLM-side vectors mainly harms the internal role signal, while removing only the speech-side vectors mainly harms emotional and prosodic realization.
| Variant | SIM | EEA | Prosodic Consistency | Emotion Appropriateness | Personality Consistency | Knowledge Consistency |
|---|---|---|---|---|---|---|
| DeSRPA | 0.886 | 0.701 | 0.7958 | 0.8160 | 0.7615 | 0.8116 |
| w/o Both CVs | 0.919 | 0.537 | 0.6936 | 0.6874 | 0.7167 | 0.7828 |
| w/o LLM CVs | 0.905 | 0.677 | 0.7412 | 0.7568 | 0.7235 | 0.7743 |
| w/o Speech CVs | 0.892 | 0.549 | 0.7186 | 0.7245 | 0.7592 | 0.8074 |
The paper highlights a few specific trends. First, removing the LLM control vectors degrades Personality Consistency from $0.7615$ to $0.7235$ and Knowledge Consistency from $0.8116$ to $0.7743$, showing that the internal steering affects what the model believes and says about the character. Second, removing the speech control vectors degrades Prosodic Consistency from $0.7958$ to $0.7186$ and Emotion Appropriateness from $0.8160$ to $0.7245$, and it drops EEA from $0.701$ to $0.549$, confirming that acoustic steering is crucial for emotional execution.
The authors also note an inherent trade-off: injecting control vectors perturbs the unguided baseline somewhat, causing small regressions in fluency, naturalness, and some low-level objective measures such as WER and SIM relative to the unsteered variants. Nevertheless, the combined system produces the best overall role-playing fidelity.
Human Evaluation on OmniCharacter-10K
On the open-domain OmniCharacter-10K test split, the paper reports human ratings from six experts on a 10-point Likert scale. The most important takeaway is that DeSRPA is strong in acoustic quality and emotional expression, but it does not dominate every open-domain human dimension.
| Model | Fluency | Consistency | Emotional Expression | Clarity | Appropriateness | Immersion |
|---|---|---|---|---|---|---|
| LLaMA-Omni | 6.88 | 4.27 | 3.44 | 6.69 | 4.78 | 4.68 |
| OmniCharacter | 7.97 | 6.84 | 6.23 | 7.88 | 5.63 | 8.52 |
| DeSRPA | 8.70 | 6.07 | 7.41 | 9.11 | 5.54 | 7.44 |
DeSRPA receives the best scores in Fluency ($8.70$), Emotional Expression ($7.41$), and Clarity ($9.11$). The authors interpret this as evidence that the decoupled design preserves speech quality while still allowing emotionally rich speech synthesis. OmniCharacter, however, scores higher on Consistency and Immersion. The paper attributes this to the benchmark’s highly stylized anime personae and exaggerated prosody, which are out of distribution for a TTS stack optimized for natural human speech.
Discussion and Limitations
The paper’s discussion identifies several practical limitations and trade-offs, even though the overall method is positioned as scalable and training-free.
- Latency trade-off: DeSRPA’s decoupled pipeline is slower than the fastest E2E baselines, with TTFA at $577$ ms versus $226$ ms for LLaMA-Omni.
- Small quality trade-offs from control injection: compared with the unsteered baseline, adding control vectors slightly worsens some metrics such as WER and SIM, reflecting the cost of steering the latent space.
- Open-domain mismatch: on stylized character settings like OmniCharacter-10K, human consistency and immersion remain below OmniCharacter, which the authors attribute to the benchmark’s highly stylized persona distributions and exaggerated prosody.
- Speech-naturalness ceiling: while the system narrows the gap to proprietary models such as GPT-4o Audio, the paper still reports that GPT-4o remains ahead on the overall automated mean score.
These limitations are consistent with the paper’s own framing: DeSRPA is meant to be a training-free, controllable alternative to fully joint speech modeling, not a universal replacement for all high-end proprietary speech systems. Its main value is that it gives a practical path toward character-adaptive speech without character-specific fine-tuning and without collapsing persona control into opaque end-to-end adaptation.
Conclusion
DeSRPA proposes a decoupled, inference-time intervention framework for speech role playing. Its core idea is to separate internal persona reasoning from external speech rendering while keeping both backbones frozen. The LLM side uses sparse control vectors for personality, context, and style; the TTS side uses emotion direction vectors derived from parallel emotional speech corpora and a dual-path fusion mechanism to balance identity preservation with expressive speech.
In the reported experiments, DeSRPA is the strongest open-source system on the SpeechRole benchmark’s automated mean score and achieves the best EEA, while also delivering strong human-rated fluency, clarity, and emotional expression on OmniCharacter-10K. The work’s main contribution is therefore not just a specific architecture, but a general training-free strategy for aligning character cognition and character voice through inference-time control vectors.