Dixtral
Grounding Spoken LLMs in Multi-Speaker Audio via Diarization Conditioning
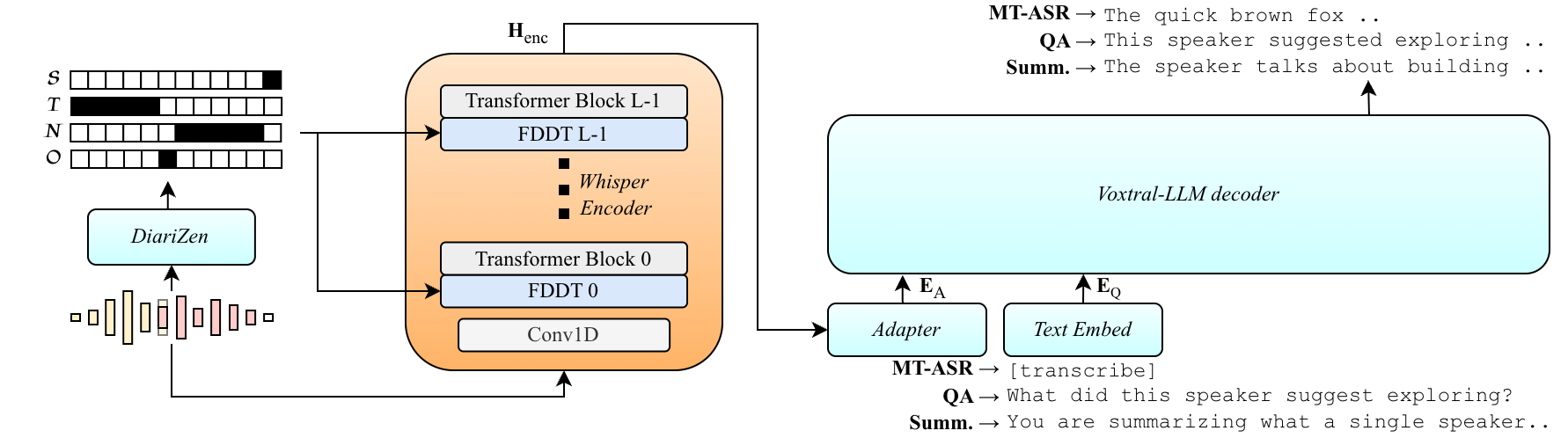
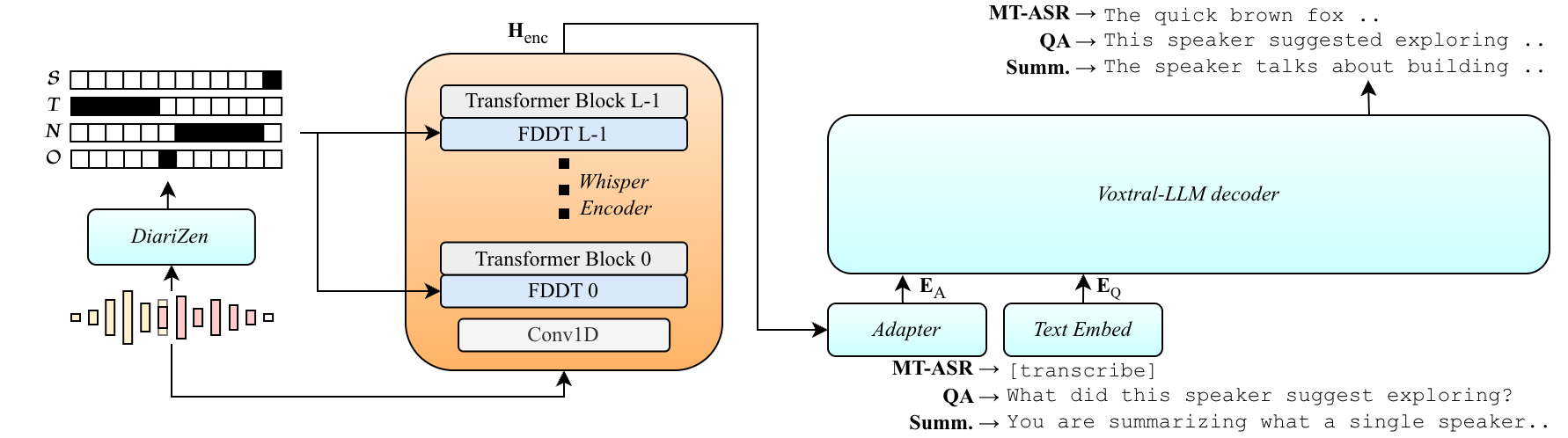
Dixtral improves multi-speaker transcription by conditioning the acoustic encoder on diarization masks to isolate speakers, while keeping the language model decoder fixed. This preserves language reasoning and supports zero-shot multi-speaker QA without altering the decoder or output format.
Links
Paper & demos
Code & resources
Abstract
We propose diarization-conditioned spoken language models (SLMs), a strategy for extending SLMs to far-field multi-talker audio. Rather than adapting the decoder via Serialized Output Training, which risks catastrophic forgetting, we condition the acoustic encoder on diarization masks to extract target-speaker representations, keeping the decoder frozen. We instantiate this as Dixtral, integrating a Diarization Conditioned Whisper (DiCoW) encoder into the Voxtral SLM. On AMI, NOTSOFAR-1, LibriSpeechMix, and Mixer6, Dixtral outperforms Gemini 3.0 Flash, VibeVoice, and Voxtral Mini Transcribe V2 on speaker-attributed transcription by 29.0%, 19.8%, and 16.0% absolute cpWER respectively. On a novel long-form multi-speaker QA benchmark, zero-shot Dixtral matches Gemini on far-field content understanding, and when fine-tuned surpasses both Gemini and Voxtral operating on close-talk across all tasks.
Introduction and problem statement
This paper addresses a central limitation of current spoken language models (SLMs): they are increasingly capable of multi-talker speech processing, but strong speaker-attributed transcription for far-field overlapping audio still lags behind specialized modular pipelines. The authors focus on the mismatch between multi-speaker transcription and instruction-tuned LLM decoders. Most LLM-based multi-speaker systems rely on Serialized Output Training (SOT), which concatenates transcripts from multiple speakers into one token stream ordered by speech onset. In an LLM setting, this creates two problems: the decoder vocabulary and output format must be adapted to handle special speaker-change tokens, and the resulting interleaved token distribution differs strongly from the single-speaker, instruction-following formats that LLMs are pretrained to generate. The paper argues that this often forces decoder fine-tuning on large multi-speaker corpora and can cause catastrophic forgetting of reasoning, summarization, and question-answering abilities.
The proposed alternative is target-speaker extraction driven by diarization conditioning. Rather than teaching the decoder to represent multiple speakers explicitly, the acoustic encoder is conditioned on frame-level diarization masks to isolate the acoustic representation of a chosen speaker. The decoder remains frozen, preserving its general-purpose language capabilities by design. This makes the model compatible with zero-shot multi-speaker QA and summarization, while also avoiding vocabulary expansion and special serialization tokens.
The paper instantiates this idea as Dixtral, a diarization-conditioned extension of Voxtral built by integrating a Diarization Conditioned Whisper (DiCoW) encoder into the Voxtral SLM. The key message is that multi-speaker grounding can happen at the acoustic level, while the LLM decoder stays untouched.
Core method: diarization-conditioned target-speaker extraction
Dixtral combines two pretrained systems that share Whisper-style acoustic architecture: Voxtral, which pairs a Whisper encoder with a Ministral decoder, and DiCoW, a target-speaker ASR system that conditions its encoder on diarization outputs. The compatibility of these backbones is crucial: it allows the authors to reuse pretrained weights and align the acoustic front-end with the frozen LLM decoder without architectural surgery.
The diarization signal is provided as frame-level speaker activity probabilities $d(s,t)$ for $S$ speakers, where $s$ indexes speakers and $t$ indexes time frames. For a target speaker $s_k$, the paper derives four STNO categories—Silence $\mathcal{S}$, Target $\mathcal{T}$, Non-target $\mathcal{N}$, and Overlap $\mathcal{O}$—with probabilities:
$$ p_{\mathcal{S}}^t = \prod_{s=1}^S (1 - d(s,t)),\quad p_{\mathcal{T}}^t = d(s_k,t)\prod_{\substack{s=1\\s\neq s_k}}^S (1 - d(s,t)), $$
$$ p_{\mathcal{N}}^t = (1 - p_{\mathcal{S}}^t) - d(s_k,t),\quad p_{\mathcal{O}}^t = d(s_k,t) - p_{\mathcal{T}}^t. $$
Instead of masking the input waveform directly, Dixtral injects these probabilities through Frame-Level Diarization-Dependent Transformations (FDDT) inside each Transformer encoder layer. Each layer has four learnable diagonal affine transforms $$(\mathbf{W}_i^l, \mathbf{b}_i^l)$$ for $i \in \{\mathcal{S},\mathcal{T},\mathcal{N},\mathcal{O}\}$, and the hidden state at layer $l$ and frame $t$ is updated as a probabilistic mixture:
$$ \hat{\mathbf{z}}_t^l = \sum_{i \in \{\mathcal{S},\mathcal{T},\mathcal{N},\mathcal{O}\}} (\mathbf{W}_i^l\mathbf{z}_t^l + \mathbf{b}_i^l)p_i^t. $$
This is an important design choice: the conditioning is not a one-time input preprocessing step, but a layer-wise modulation mechanism that shapes internal representations throughout the acoustic stack. The final encoder output is written as $\mathbf{H}_{\text{enc}} = \text{Encoder}_{\theta_{\text{enc}}}(\mathbf{X}, \mathbf{STNO}_{s_k})$, producing a target-speaker acoustic embedding sequence.
The authors note that the same mechanism can support different operating modes. If the task is to extract a specific speaker, STNO probabilities are derived from diarization. If the goal is global reasoning over the whole recording, or if the input is single-speaker audio, they set $p_{\mathcal{T}}^t = 1$ and all other probabilities to $0$ for every frame, effectively telling the encoder to process the entire acoustic context.
Reasoning framework and training objective
After the acoustic encoder produces target-speaker representations, they are passed through a small modality adapter: a two-layer MLP with a GELU nonlinearity that projects the encoder embedding space into the LLM embedding space. The projected audio prefix $E_A$ is concatenated with textual prompt embeddings $E_Q$ to form the full prefix $\mathbf{U} = [E_A; E_Q]$. The decoder then autoregressively generates the target output sequence $Y = (y_1,\dots,y_N)$ conditioned on this prefix and previous tokens.
The training loss is standard token-level cross entropy applied only to the target text following the prompt:
$$
\mathcal{L}_{CE} = -\sum_{i=1}^{N} \log p(y_i \mid \mathbf{U}, Y_{
A major conceptual claim of the paper is that the decoder can remain fully frozen. In the experimental setup, both the LLM and the modality adapter are frozen, and only the acoustic encoder layers and FDDT modules are updated. This is the mechanism the authors use to avoid catastrophic forgetting while still adapting the speech front-end to multi-speaker, far-field conditions.
The paper also emphasizes a computational argument. Joint multi-speaker decoding with sequence length $SN$ scales as $\mathcal{O}((SN)^2)$ in the autoregressive decoder, while extracting each of $S$ speakers separately costs $\mathcal{O}(S \cdot N^2)$. Since the decoder dominates compute at large model sizes, target-speaker extraction can be more favorable than constructing one long interleaved transcript.
Dixtral is initialized by leveraging the shared Whisper-style pretraining of Voxtral and DiCoW. The paper states that one can either replace the full acoustic encoder with DiCoW’s pretrained weights or selectively inject the pretrained FDDT parameters into Voxtral’s encoder. The practical experiments build on Voxtral Mini 3B, which uses a Ministral 3B backbone and a Whisper large-v3 acoustic encoder.
Training is deliberately done under modest academic compute: eight 24GB A5000 GPUs, 20k steps, peak learning rate $6\times10^{-5}$, 5k warmup steps, cosine decay to zero, gradient checkpointing, bfloat16 precision, and 4 gradient accumulation steps for an effective global batch size of 32. The authors mention two engineering exceptions caused by memory limits: AMI decoding is chunked into about 5-minute segments split at diarization-derived pauses, and the long-form QA/summarization fine-tuning requires H100 GPUs because it does not fit on the A5000 setup.
The diarization backbone is DiariZen, used for both DiCoW and Dixtral. The paper treats it as a strong baseline and notes that sensitivity to this diarization system had already been studied in the DiCoW line of work.
The evaluation spans four multi-talker ASR datasets: NOTSOFAR-1 (NSF-1), AMI, LibriSpeechMix, and Mixer6. Transcription is measured with concatenated minimum-permutation word error rate (cpWER). Mixer6 CH4 is explicitly used as out-of-domain generalization, while the other datasets cover in-domain or less shifted conversational settings.
The paper’s second benchmark is NSF-QA, a new long-form target-speaker question-answering and summarization benchmark built on NOTSOFAR-1. It contains two families of questions. Content QA includes entity, topic, yes/no, and detail questions that are answerable from text alone. These are designed to compare end-to-end methods against cascaded ASR+LLM systems. Paralinguistic QA includes emotion and speaker gender questions that require audio understanding and cannot be answered once the signal is reduced to text.
The benchmark construction is carefully described. Content questions and references are generated with Gemini 2.5 Flash from the target speaker’s ground-truth transcript. Emotion questions are generated by combining transcript text with utterance-level emotion labels from emotion2vec, using close-talk recordings and ground-truth segmentation to anchor questions to specific moments. Gender labels come from session metadata. Questions do not reference timestamps or segment boundaries, so the system must search and reason over the full meeting.
QA outputs are judged by Gemini 2.5 Flash in a binary correct/incorrect fashion, and the paper reports accuracy. For summarization, the system must generate a concise summary of under 50 words for what the target speaker said; five reference summaries per speaker are generated with Gemini 2.5 Flash from the ground-truth transcript, and evaluation uses ROUGE-L with the maximum over references. The authors explicitly acknowledge a potential circularity in using the same LLM family to generate references and to judge QA, which could favor Gemini-based outputs; they argue this would make Dixtral’s gains conservative.
The NSF-QA split statistics reported in the paper are:
The headline transcription table compares Dixtral against task-specific multi-talker ASR systems and general-purpose spoken LMs. The most important result is that Dixtral dramatically improves over prior spoken LLM baselines while preserving the ability to reason on top of audio, although it does not beat the dedicated DiCoW ASR model, which is expected because DiCoW is specialized for transcription only.
The abstract-level comparison is reflected here in the macro average cpWER: Dixtral achieves 15.4% versus 44.4% for Gemini 3.0 Flash, 35.2% for VibeVoice, and 31.4% for Voxtral Mini Transcribe V2. The paper summarizes this as absolute improvements of 29.0, 19.8, and 16.0 cpWER points respectively. On individual datasets, Dixtral is especially strong on AMI (19.8%) and also generalizes to Mixer6 CH4 with 14.4% cpWER, where it outperforms all other LLM-based systems.
The result set reveals a useful nuance: the strongest transcription model overall is still the specialized DiCoW v3.3 ASR system at 14.0% average cpWER. Dixtral is slightly worse in transcription-only terms, but it is designed to retain the frozen decoder’s reasoning behavior and support downstream QA and summarization, which DiCoW does not address.
The paper includes an ablation study under oracle diarization to isolate the value of encoder swapping, FDDT injection, and decoder adaptation. The main takeaways are that the initialization strategy affects convergence speed and final performance, and that preserving the original Voxtral encoder weights can stabilize cross-modal alignment.
The authors report that under strict compute budgets a full encoder swap converges fastest early in training, but over longer runs either random initialization without swapping or hot-swapping only FDDT parameters becomes better. The explanation offered is that retaining Voxtral’s original encoder weights prevents embedding shifts that might otherwise disturb cross-modal alignment. Adding LoRA to the decoder gives the best overall ASR numbers in this ablation table, with 21.3% on NSF-1 and 16.4% on AMI, suggesting that a small amount of decoder flexibility can absorb language-shift effects. However, that extra flexibility comes with a trade-off discussed in the QA section: it can surface speaker attributes better, but it can also distort the instruction-following behavior needed for summarization.
The final row of the ablation table is particularly revealing. After explicit QA+summarization fine-tuning, transcription degrades, most visibly on Mixer6 CH4 where cpWER worsens from 14.5% to 26.1%. The paper interprets this as the encoder adapting to optimize reasoning at the expense of verbatim transcription fidelity. Joint ASR and QA/summarization training is suggested as a possible remedy, but it is left for future work.
The NSF-QA results are the paper’s strongest evidence that diarization conditioning preserves and extends the decoder’s general-purpose reasoning. The main comparison is between zero-shot Dixtral on far-field multi-speaker mixtures and two reference points: Voxtral Mv1 on close-talk per-speaker audio, and Gemini 3.0 Flash. The far-field setup is intentionally challenging because the system must understand a target speaker in a meeting-like mixture rather than on isolated close-talk audio.
In zero-shot far-field mode, Dixtral roughly matches Gemini on content QA (54.6% vs. 55.1%) and closely tracks Voxtral on emotion QA and summarization, which the authors use as evidence that the frozen decoder retains its prior abilities. Gender QA is notably lower than Gemini in the zero-shot setting, showing that paralinguistic inference is not fully solved by the pretrained model alone.
Adding LoRA to the decoder has a mixed effect: gender QA jumps to 73.3%, roughly matching Gemini, but summarization collapses to 15.4 ROUGE-L because the model sometimes produces verbatim transcriptions instead of concise summaries. This is an important qualitative finding about decoder adaptation: small language-side updates can unlock speaker-level attributes but can also damage instruction adherence.
The fine-tuned Dixtral model is the strongest system on the benchmark. On far-field audio it surpasses both Gemini and Voxtral close-talk performance across all four metrics: 73.0% content accuracy, 47.6% emotion accuracy, 95.5% gender accuracy, and 41.4 ROUGE-L. The paper interprets this as evidence that diarization conditioning is not only useful for transcription, but also a viable way to ground a spoken LLM in multi-speaker audio for higher-level reasoning tasks.
The paper’s main contribution is architectural rather than algorithmic in the narrow sense: it shows that a frozen spoken LLM can be extended to far-field multi-talker audio by moving the adaptation burden from the decoder to the acoustic encoder. This avoids the vocabulary expansion and multi-speaker output formatting required by SOT-style training, and it aims to preserve the LLM’s reasoning and instruction-following abilities. The design is also modular: the authors present it as a general strategy for SLMs, not only for Voxtral.
The empirical contribution is twofold. First, Dixtral substantially improves speaker-attributed transcription relative to other spoken LMs on AMI, NOTSOFAR-1, LibriSpeechMix, and Mixer6. Second, it enables audio-grounded QA and summarization that are unavailable to purely cascaded ASR+LLM systems, particularly for paralinguistic questions such as emotion and gender. The fine-tuned version demonstrates that the same architecture can support stronger downstream reasoning once task-specific data is available.
The paper is also careful about trade-offs and practical limits. The frozen-decoder approach preserves reasoning better than decoder-heavy fine-tuning, but there is still a tension between improving QA/summarization and maintaining transcription fidelity. Performance depends on an external diarization backbone, and the authors do not claim end-to-end joint diarization training. The NSF-QA benchmark is synthetic in part, with Gemini used to generate questions/references and to judge answers, which the authors acknowledge as a potential source of bias. Finally, the need to chunk AMI for decoding and to use H100s for long-form QA fine-tuning underscores that some operating modes remain compute-intensive.
The stated future directions are consistent with these limitations: end-to-end joint training with diarization, multilingual evaluation, and scaling the method in task diversity, model size, and training data.
The Dixtral repository implements the diarization-conditioned spoken language model proposed in the paper, extending the DiCoW target-speaker ASR with an LLM decoder to enable per-speaker automatic speech recognition (ASR), question answering (QA), and summarization directly from multi-speaker meeting audio. The codebase integrates two main components: The repository uses Core training and decoding scripts are located under For usage, the README highlights a live demo with a Gradio interface in the Model initialization and training setup
Datasets, tasks, and evaluation metrics
Split
Content QA: Entity
Topic
Y/N
Detail
Emotion QA
Summ.
Train 1,111 1,139 1,557 775 1,196 390 Dev 579 593 807 402 579 201 Eval 1,092 1,114 1,515 753 1,145 379 Main transcription results
System
NSF-1 Small
AMI SDM
LSMix 1
LSMix 2
LSMix 3
MX-6 CH4
Avg.
Voxtral MTv2 54.4 42.3 2.0 28.2 42.3 19.4 31.4 VibeVoice 35.8 33.7 2.1 50.8 72.8 16.0 35.2 DiCoW v3.3 26.6 18.6 1.8 3.1 21.7 11.9 14.0 Gemini 3.0 Flash 39.1 56.3 4.5 23.3 84.7 58.3 44.4 Dixtral 29.1 19.8 2.1 3.6 23.5 14.4 15.4 Ablations on initialization and adaptation strategy
Variant
NSF-1 Small
AMI SDM
LSMix 1
LSMix 2
LSMix 3
MX6 CH4
Dixtral wo/ swap 26.3 19.8 1.9 2.3 3.6 12.6 w/ enc. swap 26.4 21.0 1.9 2.4 4.6 20.4 w/ FDDT swap 26.3 17.1 1.8 2.2 3.5 16.2 w/ LORA 21.3 16.4 2.0 2.6 4.8 14.5 QA+Summ ft 24.3 19.4 2.2 3.1 5.6 26.1 Question answering and summarization results
System
Content
Emotion
Gender
ROUGE-L
Dixtral (zero-shot, far-field) 54.6 25.4 43.2 24.4 Dixtral (+LoRA, zero-shot, far-field) 56.9 22.2 73.3 15.4 Dixtral (finetuned, far-field) 73.0 47.6 95.5 41.4 Gemini 3.0 Flash (far-field) 55.1 29.3 74.1 23.7 Voxtral Mv1 (close-talk) 68.3 25.5 49.7 24.1 Gemini 3.0 Flash (close-talk) 68.1 34.1 75.0 26.4 Interpretation, contributions, and limitations
Code & Implementation
Hydra for configuration management, with separate configs for ASR training, QA fine-tuning, and decoding. It includes training scripts configured for SLURM-based clusters and utilities for data preparation, including population of question-answer annotations and long-form audio chunking.src/train.py and src/main.py, where the training modes correspond to the paper's target-speaker ASR and QA fine-tuning strategies. The diarization conditioning is implemented in the encoder's architecture, loaded from pretrained DiCoW checkpoints.demo/ directory, showcasing the model's capability for interactive per-speaker ASR and QA.