Reliable Neural-Codec TTS
Reliable Neural-Codec Text-to-Speech by ASR Self-Verification and Distillation: Near-Zero Catastrophic Failures Across Models and Codecs
Eliminates catastrophic failures in neural-codec text-to-speech by ASR self-verification and distillation, improving single-shot decoding robustness across models and codecs without added inference cost.
Links
Paper & demos
Code & resources
Abstract
Open autoregressive neural-codec text-to-speech (TTS) models sound excellent on typical inputs yet suffer stochastic catastrophic failures: on a meaningful fraction of utterances they emit silence, terminate early, or collapse into repetitive or hallucinated content. We show this failure mode is cheap to remove. Under a single format-robust metric (a catastrophic-failure rate via an ASR round-trip), best-of-N ASR self-verification drives failures to near-zero: no observed failures remain by N=2 on a standard corpus (LibriSpeech) and by N=4 on a hard prompt set. This is not an artifact of one model: the reduction replicates across four open codec-TTS systems and three neural codecs (XCodec2, SNAC, Mimi), reaching the near-zero floor by N=2 on three of the four. We then make the fix free at inference time by distilling the self-verified behaviour into the model, which recovers much of the robustness in single-shot decoding, closing ~52-58% of the failure mass on hard inputs at no test-time cost. The distillation gain concentrates where it is needed (hard inputs); on already-reliable prose there is no headroom and no detectable change. A controlled comparison adds a clean negative: offline direct preference optimization (DPO/IPO) does not beat plain supervised distillation, and an online iterative variant is promising but not statistically separable at our evaluation size. We report honestly the one model that resists (a larger Llasa where scale did not obviously help) and a rare-word capability ceiling that no self-distillation method overcomes
Introduction
This paper addresses a reliability problem in open autoregressive neural-codec text-to-speech (TTS): models often sound strong on ordinary prompts but fail stochastically on a non-trivial fraction of inputs. The failures are deployment-critical rather than cosmetic: the model may emit silence, terminate early, or collapse into repetitive / hallucinated content. The authors treat this as a robustness problem in open codec-TTS systems rather than a one-off bug in a single checkpoint.
The central claim is that the failure mode is inexpensive to remove. A simple best-of-$N$ test-time verification scheme, using ASR to score candidates, can drive catastrophic failures close to zero across multiple models and multiple codecs. Then, by distilling the self-verified behavior back into the model, much of the robustness can be recovered in single-shot decoding with no inference-time sampling overhead.
Two broader points make the paper notable. First, the improvement is shown to generalize beyond one architecture or codec family: the same procedure is evaluated across four open codec-TTS systems and three neural codecs. Second, the paper explicitly distinguishes oracle-style verification from deployable robustness, and argues that the deployable number is the distilled single-shot model, not the best-of-$N$ verifier itself.
Problem statement and reliability metric
The paper works with autoregressive language models over discrete acoustic tokens decoded by a neural codec. The failure mode of interest is not ordinary transcription error but a catastrophic generation failure. A generation is counted as catastrophic if it is a dropout or a content failure:
$$ \phi(g)=\mathbf{1}\Big[\,n(g)<25 \;\lor\; |h(g)|\le 1 \;\lor\; \mathrm{WER}(h(g),x)>0.5\Big], $$
where $n(g)$ is the decoded speech-token count, $h(g)$ is the ASR transcript of the generated audio, $|h(g)|$ is transcript word count, and $x$ is the reference text. In words, the paper uses a single format-robust failure metric that flags outputs that are too short to be viable, or whose ASR transcript is too far from the prompt.
For a prompt set $\mathcal{P}$ and $N$ sampled candidates per prompt, the best-of-$N$ catastrophic-failure rate is defined as:
$$ \mathrm{CFR}_N = \frac{1}{|\mathcal{P}|} \sum_{p\in\mathcal{P}} \prod_{k=1}^{N} \phi(g_{p,k}). $$
This quantity is monotone non-increasing in $N$: a prompt only counts as failed if all $N$ samples are catastrophic. The paper emphasizes that this is a reference-aware oracle selection metric: the verifier uses the target transcript to choose among candidates, so best-of-$N$ upper-bounds what self-verification can achieve in deployment.
The authors deliberately avoid using WER to measure number/date robustness, because digit-versus-word formatting noise dominates the score and obscures the phenomenon they care about. They report that raw-versus-normalized number/date WER is essentially unchanged at about $0.155$ versus $0.143$, with canonicalization artifacts around $0.14$ swamping the signal. As a result, numbers and dates are treated as a qualitative limitation rather than the main evaluation target.
Models, codecs, and evaluation setup
The primary model is Llasa-1B, a LLaMA-style language model over XCodec2 speech tokens, adapted with LoRA from the released checkpoint. The broader test-time generalization study includes three additional open systems spanning three codecs:
- Orpheus-3B over the SNAC codec,
- CSM-1B over the Mimi RVQ codec,
- Llasa-3B over XCodec2 as a scale point.
The paper notes that XTTS-v2 was initially targeted but could not be fine-tuned in the authors' environment.
Two held-out evaluation sets are used throughout, both text-disjoint from training:
- Hard set: 26 hand-written prompts covering normal, long, and tongue-twister inputs, evaluated with 6 generations each for a total of 156 generations. Rare-word and number/date buckets are analyzed separately because they expose different failure modes.
- Standard corpus: 120 held-out LibriSpeech test-clean transcripts evaluated with 3 generations each for a total of 360 generations. Training prompts are drawn from the disjoint dev-clean split.
For clarity, the paper distinguishes several base rates: a broad-eval rate of about $0.36$ that includes rare-word and number/date prompts, a hard-set single-shot rate of about $0.269$, and a larger 156-generation hard-set rate of $0.199$ used as the anchor for the distillation comparisons. The distinction matters because the rare-word bucket is a capability ceiling, while the rest of the hard set is a robustness problem.
Statistically, the authors report Wilson 95% confidence intervals for non-zero proportions and a rule-of-three upper bound $3/n$ when no failures are observed. They also explicitly avoid ranking methods whose intervals overlap, since every reported condition is a single training run.
Method
Best-of-$N$ ASR self-verification at test time
The test-time algorithm is simple: for a prompt, sample $N$ candidates, transcribe each with ASR, and select the lowest-WER candidate that is not a dropout. A prompt is considered failed at best-of-$k$ only if every one of its $k$ candidates is catastrophic. The smallest $N$ at which a prompt stops failing is interpreted as a prompt-level difficulty signal.
The important implementation detail is that the verifier is reference-aware. It uses ASR round-tripping against the target text, so it is not a pure black-box deployment metric. The paper is explicit that this makes best-of-$N$ an oracle upper bound on what a deployable system can do, but it is still useful because it directly reveals whether the model can produce a good sample at all.
Distilling verified behavior into single-shot decoding
To avoid the $N\times$ inference cost, the authors fine-tune the model on the best self-verified sample for each training prompt. In other words, they use self-verification to choose the target output, then train the model to imitate that verified output so that ordinary single-shot decoding inherits the same behavior.
The main distillation path is supervised fine-tuning (SFT) on the chosen sample. The paper also compares preference-style objectives that incorporate a rejected sample. A generic form of the DPO loss is given as:
$$ \mathcal{L}_{\mathrm{DPO}} = -\log \sigma\!\Big(\beta\big[(\log p_\theta - \log p_{\mathrm{ref}})_c - (\log p_\theta - \log p_{\mathrm{ref}})_r\big]\Big), $$
where $c$ is the chosen sample, $r$ is the rejected sample, and $p_{\mathrm{ref}}$ is the LoRA-disabled base model. The paper additionally tests IPO, a failure-targeted pairing variant (FTPO), and an online iterative variant in which the model is repeatedly re-sampled on-policy, re-scored by ASR, and retrained over three rounds.
The authors are careful to separate two ideas:
- Robustness recovery: whether the training objective reduces catastrophic failures.
- Inference cost: whether the final model needs test-time best-of-$N$ sampling.
The deployable outcome is the distilled single-shot model, not the verifier itself.
Self-verification results across models and codecs
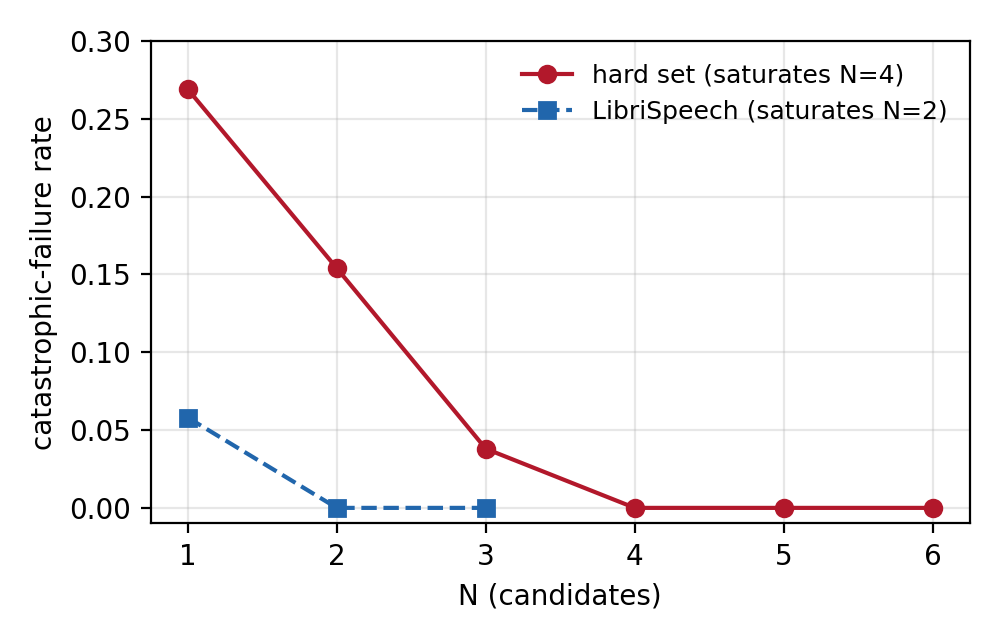
The headline result is that best-of-$N$ self-verification drives catastrophic failures to a near-zero floor across the models and codecs tested. On the primary Llasa-1B model, the hard-set failure rate falls from $0.269$ at $N=1$ to $0.154$ at $N=2$, $0.038$ at $N=3$, and no observed failures at $N\ge 4$. On LibriSpeech, the rate falls from $0.058$ to no observed failures already at $N=2$.
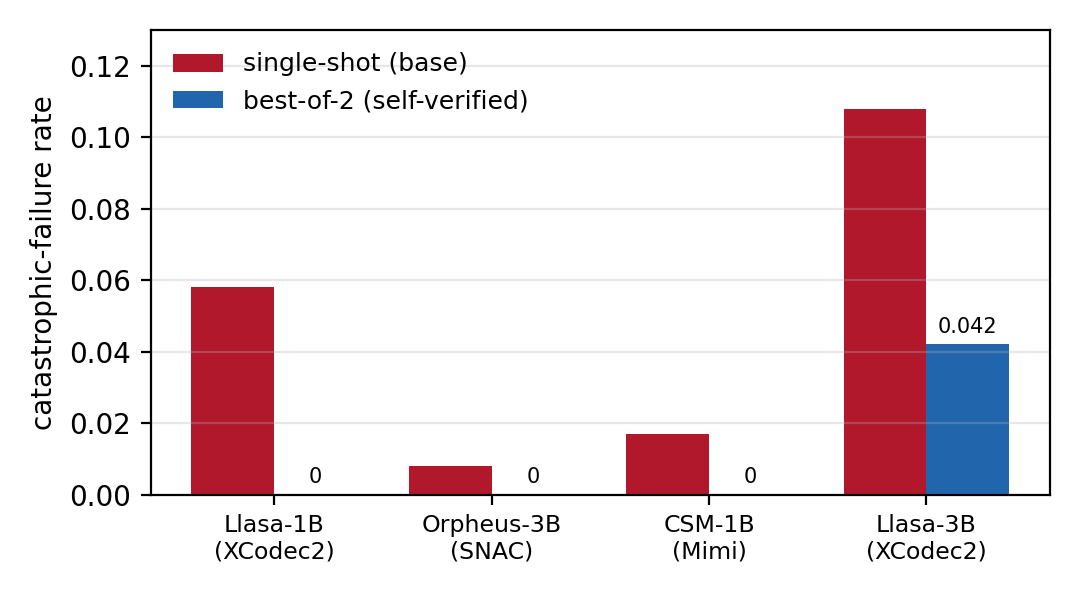
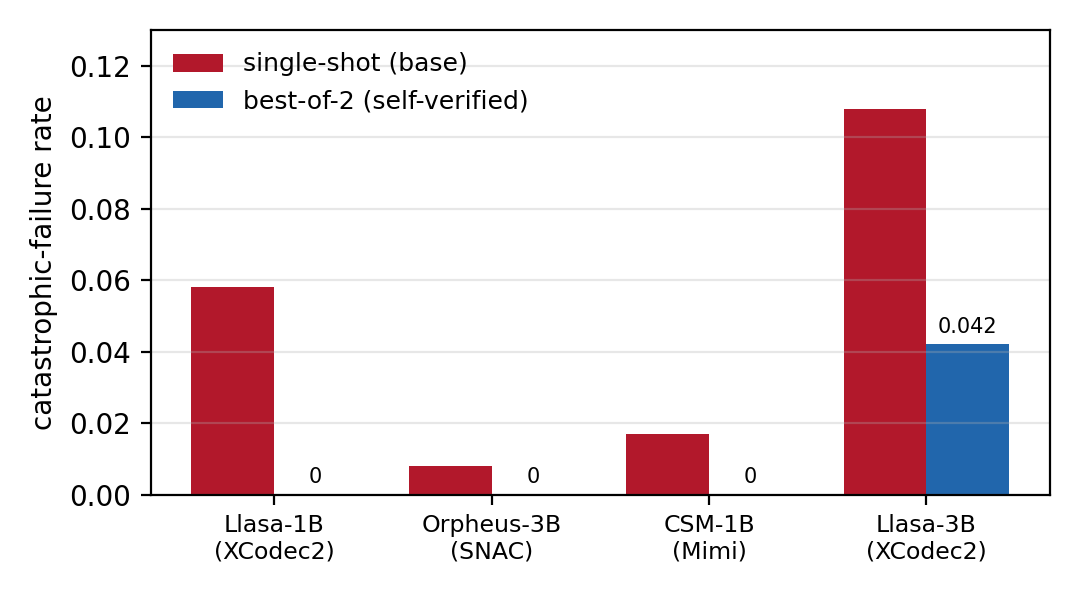
On the standard LibriSpeech set, the authors report no observed failures at $N=2$ for three of the four models, and substantial reduction for the fourth. The same verifier works on all tested codec families: XCodec2, SNAC, and Mimi. The key claim is not merely that one model improves, but that the same simple selection rule generalizes across model families and codec representations.
| model | codec | base | best-of-2 | best-of-3 | distilled |
|---|---|---|---|---|---|
| Llasa-1B | XCodec2 | 0.058 | 0.000 | 0.000 | 0.058 |
| Orpheus-3B | SNAC | 0.008 | 0.000 | 0.000 | 0.033 |
| CSM-1B | Mimi | 0.017 | 0.000 | 0.000 | not run |
| Llasa-3B | XCodec2 | 0.108 | 0.042 | 0.033 | 0.142 |
The authors include two important qualifications. First, the verifier is reference-aware, so the best-of-$N$ numbers are oracle upper bounds rather than direct deployment figures. Second, Llasa-3B is the one model that does not reach the floor: scaling from 1B to 3B did not visibly improve robustness in their run, and the 3B evaluation used a tighter generation budget ($\texttt{max\_new\_tokens}=1024$) to bound a suspected hang. That budget change can truncate long generations into apparent failures, so the paper does not read the 1B-versus-3B gap as a clean scale effect.
For CSM-1B, the paper reports only base and best-of-$N$ results because its two-transformer architecture does not expose the single token stream used by the authors' distillation path. Distillation on CSM is explicitly left as future work.
| $N$ | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| hard set | 0.269 | 0.154 | 0.038 | 0.000 | 0.000 | 0.000 |
| LibriSpeech | 0.058 | 0.000 | 0.000 | not sampled | not sampled | not sampled |
Distillation results: making the fix free at inference
The main deployable result is that a single distillation pass on self-verified samples transfers much of the robustness into single-shot decoding. The effect is concentrated on the hard inputs that dominate the failure budget. On the hard set, the single-shot catastrophic-failure rate drops from $0.199$ to $0.083$ with DPO and to $0.096$ with SFT, corresponding to roughly $58\%$ and $52\%$ of the failure mass removed, respectively. The remaining residual is not negligible, but the reduction is large enough to matter operationally.
On easier LibriSpeech prose, there is no headroom to recover. The base is already at $0.058$, best-of-$N$ saturates by $N=2$, and distillation produces no detectable change. In a few already-near-floor cases the paper even observes slight regressions after distillation, consistent with the idea that there is little signal to learn when the model is already reliable.
| inputs | base single-shot | saturation $N$ | distilled single-shot |
|---|---|---|---|
| hard set | 0.199 $[0.143, 0.270]$ | $N=4$ | 0.083 $[0.049, 0.137]$ / 0.096 $[0.059, 0.152]$ |
| LibriSpeech | 0.058 $[0.038, 0.087]$ | $N=2$ | 0.058 (no detectable change) |
The paper interprets the saturation point $N^*$ as a proxy for distillation headroom: when a prompt is already easy, the verifier finds a good sample quickly and there is little for distillation to improve; when a prompt is hard but still sampleable, the verified sample reveals a good mode that single-shot decoding has trouble reaching directly.
Preference optimization comparison
The authors explicitly compare supervised distillation against preference-style optimization, and the main takeaway is negative: offline preference optimization does not beat plain SFT. In an offline sweep on the hard set, DPO and FTPO both report $0.292$, IPO reports $0.319$, and these do not improve on SFT-on-best at $0.264$. The intervals overlap heavily, so the paper reads this as “no method beat SFT” rather than a strict ordering.
In the matched distillation comparison, SFT reaches $0.096$ and DPO reaches $0.083$ on the 156 shared-prompt generations, a difference of $0.013$ that is well inside the reported standard error of about $0.032$. The authors therefore treat the two as a tie.
The most optimistic result is the online iterative variant: after three rounds of on-policy resampling and retraining, the paper observes $0.013$ for DPO and $0.026$ for SFT on a smaller evaluation of 78 generations. The authors do not claim this as a definitive win, because the intervals overlap the single-pass results and the values are post-hoc minima across multiple conditions.
| setting | reported failure rate | interpretation |
|---|---|---|
| offline SFT-on-best | 0.264 | baseline for the preference sweep |
| offline DPO | 0.292 | no improvement over SFT |
| offline FTPO | 0.292 | no improvement over SFT |
| offline IPO | 0.319 | no improvement over SFT |
| matched distillation SFT | 0.096 | single-shot, hard set |
| matched distillation DPO | 0.083 | single-shot, hard set |
| online iterative DPO | 0.013 | promising but not statistically separated |
| online iterative SFT | 0.026 | promising but not statistically separated |
Analysis and interpretation
The paper offers a straightforward mechanism for why distillation helps mostly on hard inputs. Self-verification exposes a good mode of the model distribution when such a mode exists, and distillation teaches the model to land on that mode directly in one shot. If the base model already sits near the good modes, as with easy prose, there is little to move. If the model often misses but still has a reachable good mode, as with hard prompts, then imitating the verified sample can recover a substantial fraction of the failure mass.
The authors use the best-of-$N$ saturation point as a proxy for prompt difficulty and, by extension, a proxy for how much room distillation has to improve. This is an interpretation, not a proven causal relationship, but the reported pattern is consistent with it: hard prompts need more samples before a successful candidate appears, and they are the prompts on which distillation buys the most.
The paper also gives a practical taxonomy of observed failure modes:
- silence or dropout,
- repetitive collapse, such as a looped syllable,
- content hallucination, where the model emits unrelated short phrases,
- rare-word mispronunciation.
The dropout class is reported to account for about $4.6\%$ of base generations. The rare-word bucket is especially important because it exposes a capability ceiling rather than a sampling problem: for examples like otorhinolaryngologist, only 2 of 10 prompts ever produce a faithful sample within $N=3$. Since best-of-$N$ and self-distillation can only recover prompts for which a correct sample exists, neither approach solves this bucket.
Limitations and threats to validity
The paper is unusually explicit about its limitations. The most important internal threat is that the distillation gain is compared across two different regimes: the hard hand-authored set and LibriSpeech prose. These differ not only in difficulty but also in corpus source, length, word-frequency distribution, and prompt style. The authors say the right control would be a within-corpus difficulty sweep: stratify one corpus by prompt-level saturation $N^*$ and test whether the distillation gain grows with $N^*$ while holding source fixed. They did not run that experiment.
External validity is also bounded. The best-of-$N$ test-time result spans four models and three codecs, but the distillation analysis is shown on fewer systems. The evaluation is English-only and uses two corpora, so the null result on easy prose may not transfer to noisier real-world text. The Llasa-3B result also carries a generation-budget caveat because a tighter token limit may inflate apparent failures.
There are construct-level caveats as well. The ASR round-trip metric inherits the ASR system's own errors, and the authors did not measure the false-positive floor on ground-truth audio. Best-of-$N$ uses the reference transcript and therefore upper-bounds deployable robustness rather than measuring it directly. Finally, all reported distilled numbers come from a single training run, so the paper does not overinterpret small differences when confidence intervals overlap.
The paper reports total compute of about 45 GPU-hours.
Conclusion
The main conclusion is that catastrophic failures in neural-codec TTS are not an inherent cost of the paradigm. A simple ASR-based best-of-$N$ verification step drives failures to near-zero on three of four models and substantially reduces them on the fourth, across four models and three codecs. A single distillation pass then recovers much of that robustness in single-shot decoding, especially on hard inputs where the failure budget is concentrated.
The negative result is equally important: offline DPO/IPO does not clearly beat plain supervised distillation, while the online iterative direction looks promising but remains unproven at the paper's evaluation scale. The remaining open issues are also clearly delineated: rare-word capability is not solved, number/date robustness is not well measured by WER, and a within-corpus difficulty-control experiment remains the key next step for establishing the causal story behind the distillation gains.
Code & Implementation
This repository implements the Orpheus TTS system, an advanced text-to-speech model based on the Llama-3b backbone, designed to achieve human-like speech synthesis with zero-shot voice cloning and guided emotion control.
The core model training is located in the finetune/train.py script, which utilizes the HuggingFace Transformers library and Trainer API to fine-tune an autoregressive language model on a large speech-text dataset. Configuration settings such as dataset, model name, training parameters, and logging are managed via a YAML config file.
The main inference interface is provided by the OrpheusModel class within orpheus_tts_pypi/orpheus_tts/engine_class.py. This class wraps model loading and asynchronous generation of speech tokens through the vLLM engine. It supports voice selection, prompt formatting, and streaming token decoding.
The repository supports streaming inference with real-time token and audio chunk output, enabling low-latency speech generation. Additional inference options, such as watermarking or no-GPU modes, are provided as independent example directories.
Overall, the codebase maps directly to the paper's contributions by enabling research-scale training and robust inference of neural-codec TTS models with strong control over voice and expressivity, facilitating the near-zero failure rates and distilled robustness described.