MagpieTTS-LF
MagpieTTS-LF: Inference-Time Long-Form Speech Generation Without Training on Long-Form data
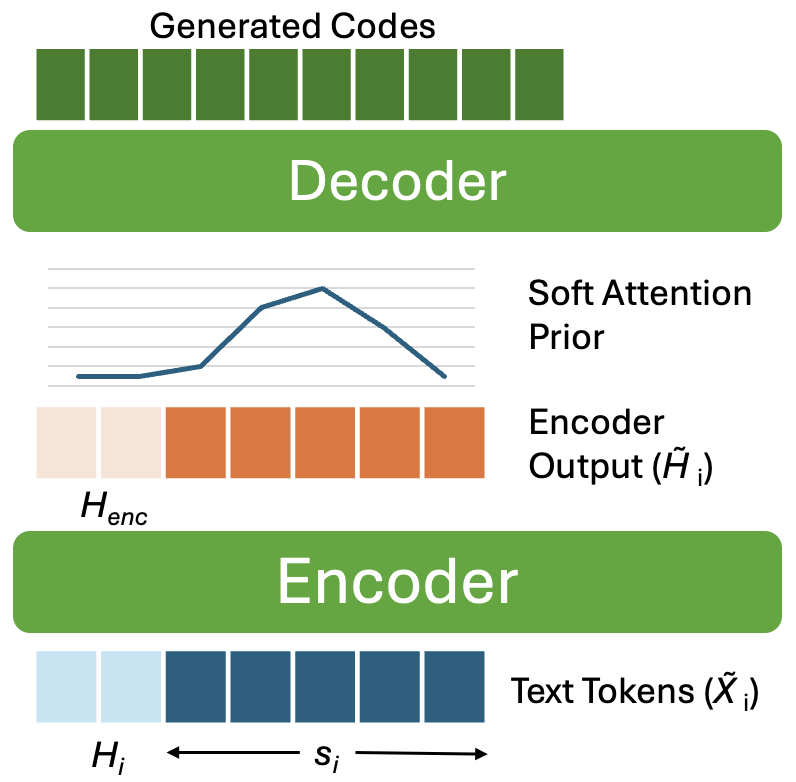
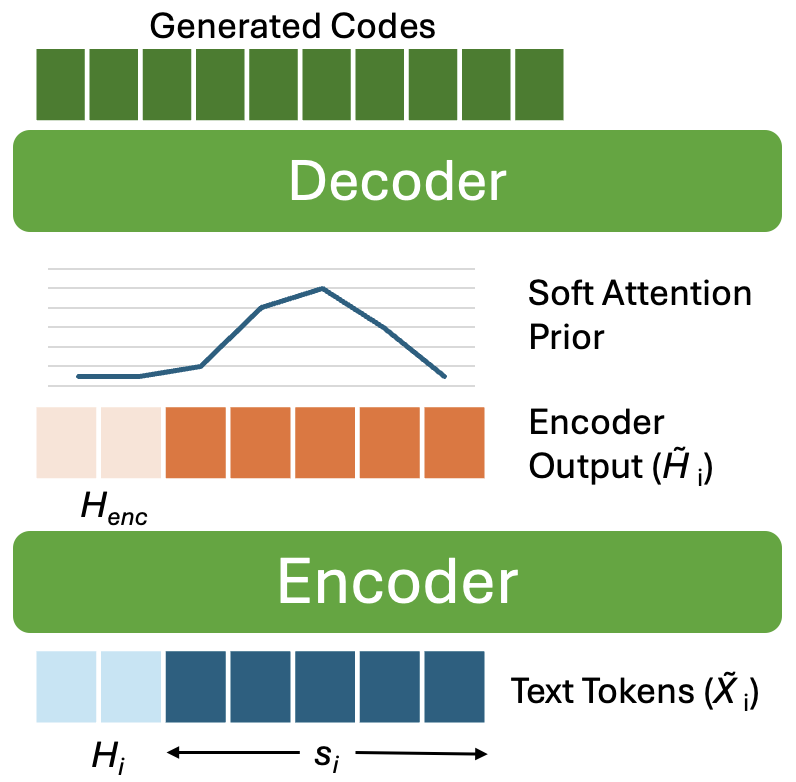
MagpieTTS-LF improves long-form speech synthesis without retraining by maintaining context and guiding attention across sentence chunks. It combines stateful chunk generation, soft attention priors, and history-aware text encoding to enhance prosodic continuity, speaker consistency, and boundary smoothness.
Links
Paper & demos
Code & resources
Abstract
Neural Text-to-Speech (TTS) systems achieve remarkable quality on short utterances but long-form speech generation shows prosodic drift, speaker inconsistencies and sentence boundary artifacts. Existing approaches either compress sequences, increase context length or naively concatenate independently synthesized chunks. We present an inference-time approach called MagpieTTS-LF that enables MagpieTTS to produce coherent long-form speech without model retraining. Our method introduces three key innovations: (1) soft attention priors to guide monotonic alignment while preserving past and future context; (2) a stateful inference algorithm that maintains context across sentence chunks, ensuring prosodic continuity; (3) history-aware text encoding that uses past text for discourse-level prosodic planning. Experiments on long texts show significant improvements in long-range intelligibility, prosodic coherence, speaker consistency, and boundary naturalness compared to other baselines.
Introduction
The paper addresses a common failure mode of strong neural text-to-speech systems: they sound excellent on short utterances, but become unstable over paragraph-length or multi-minute generation. The authors identify three recurring long-form artifacts: prosodic drift, speaker inconsistency, and boundary discontinuities when speech is synthesized in independent chunks and concatenated afterward. Their core claim is that these issues can be mitigated at inference time without retraining the underlying model.
The proposed system, MagpieTTS-LF, extends MagpieTTS to long-form synthesis through three mechanisms: soft attention priors that preserve monotonic alignment while keeping distant context available, a stateful chunked decoding procedure that carries information across sentence boundaries, and history-aware text encoding that reuses past text for discourse-level prosodic planning. The method is presented as a general inference-time recipe for chunk-based encoder-decoder TTS systems, not as a new training regime.
The paper positions this approach against three broad strategies in the literature: sequence compression, increasing context length or streaming through architectural changes, and naive sentence-level concatenation. The authors argue that existing long-context solutions often require retraining or impose hard information cutoffs, while MagpieTTS-LF attempts to retain the strengths of the base model and add continuity only where needed.
- Main problem: short-form TTS quality does not automatically translate to coherent long-form speech.
- Main constraint: no retraining or architectural modification of the base MagpieTTS model.
- Main thesis: continuous long-form speech can be improved by state carried across chunks plus a soft alignment prior.
Base Model and Training Context
MagpieTTS is described as an encoder-decoder transformer operating on discrete audio tokens produced by a neural audio codec. The encoder processes text through self-attention layers to produce contextual representations, and the decoder autoregressively emits discrete audio tokens while attending to both the text encoder output and any audio context used for voice cloning. During the original MagpieTTS training, the model uses Connectionist Temporal Classification (CTC) loss and learned attention priors to encourage monotonic cross-attention, reducing hallucinations such as repetition, skipping, and misalignment.
The paper emphasizes that the standard MagpieTTS setup is intended for single utterances, with typical generation length around 2 to 20 seconds. Long texts therefore require chunking, which is precisely where continuity breaks down. MagpieTTS-LF does not change the trained weights; instead, it changes how attention and state are managed during inference.
Method Overview
The long-form algorithm is built around sentence-level chunk generation. Given a long text, the system splits it into punctuation-aware sentence chunks $S = \{s_0, s_1, \ldots, s_M\}$. For each sentence, the method prepends a short textual history window, reuses cached encoder state, and initializes attention with the state from the previous chunk. This makes each new chunk aware of what came before without requiring the entire paragraph to fit in a single forward pass.
The state passed from one chunk to the next has three components:
- History text tokens $H_{\text{text}} \in \mathbb{R}^{B \times K}$: the final $K$ text tokens from the previous chunk, prepended to the current sentence.
- History encoder context $H_{\text{enc}} \in \mathbb{R}^{B \times K \times d}$: the corresponding encoder hidden states, concatenated with the current chunk's encoder output.
- Attention tracking: the most recent attended text position(s), stored as the prior state $\tau$ and used to initialize the next chunk.
The stated goal is not to make the model attend everywhere equally, but to avoid the hard information cutoff of binary masking. The method keeps useful distant context available while still biasing decoding toward the current local span.
Inference-Time Soft Attention Priors
The first major innovation is a soft attention prior that nudges cross-attention toward a monotonic progression through the text. At decoding step $t$, the algorithm identifies the text position $T_t$ with the highest cross-attention score at the previous step, then constructs a prior distribution $P_t$ over encoder positions. The prior assigns a high-weight window near the current location and a small nonzero value elsewhere:
$$ P_t[i] = \begin{cases} w_j & \text{if } i \in \{T_t-1, T_t, T_t+1, T_t+2, T_t+3\} \\ \epsilon & \text{otherwise} \end{cases} $$
where the fixed window weights are $w = (0.2, 0.8, 1.0, 0.8, 0.2)$ in the reported experiments and $\epsilon$ is a small positive value for distant positions. The modified attention is then computed as:
$$ \tilde{A}_t = \operatorname{softmax}\left(\frac{Q_t K^\top}{\sqrt{d}} + \lambda \log P_t\right) $$
Here $Q_t$ and $K$ are the query and key matrices, $d$ is the attention dimension, and $\lambda$ controls the strength of the prior. The key design choice is that all positions remain reachable: the model is guided toward monotonic alignment, but distant context is not eliminated. In the authors' framing, this creates a smoother decay of information than a binary mask and is especially useful for long-range prosodic dependencies.
In the reported evaluation, the soft-prior hyperparameters are fixed to $\epsilon = 0.1$, $\lambda = 1.0$, temperature $0.7$, and classifier-free guidance scale $2.5$.
Stateful Chunk Generation
The second major innovation is a stateful inference algorithm that preserves continuity across sentence boundaries. For a current sentence $s_i$, the system forms the encoder input $\tilde{X}_i = [H_{\text{text}}; s_i]$ and then concatenates the new encoder output with the cached encoder history to form $\tilde{H}_i = [H_{\text{enc}}; \operatorname{Encoder}(s_i)]$. In other words, the new chunk is never generated in isolation; it is always contextualized by a short memory of the previous chunk.
The stateful process works as follows:
- Split the input into sentences using punctuation-aware segmentation.
- Initialize an empty state and process each sentence iteratively.
- Prepend the last $K$ text tokens from the previous chunk to the current sentence.
- Carry the corresponding encoder states forward, so the decoder sees continuous representations across the boundary.
- Initialize the soft prior from the previous chunk's final attention state $\tau$ and update it autoregressively as audio tokens are produced.
- When the end-of-speech token is detected for the sentence, save the generated codes and continue with the next chunk.
The paper's claim is that this state propagation reduces the typical sentence-boundary artifacts of chunked TTS, such as abrupt changes in gain, speaking rate, intonation, and speaker identity. This stateful mechanism is the central difference from naive segmentation plus concatenation.
Long-Form HiFiTTS Benchmark
To evaluate long-form synthesis, the authors introduce a benchmark called Long-Form HiFiTTS. It is constructed by concatenating paragraphs from Multilingual LibriSpeech (MLS) into 20 passages of approximately 3 to 4 minutes each, with duration estimated using an English speech rate of 135 words per minute. The text is normalized and cleaned, including acronym expansion and normalization of numerical values.
The evaluation section also refers to a curated dataset of 20 long English texts and a long-form HiFiTTS 1-hour subset for the intelligibility measurements. Taken together, the paper's evaluation is centered on extended English synthesis and is designed to test continuity over several minutes rather than isolated utterances.
Experimental Setup
All experiments are run on a single A6000 GPU. The paper compares MagpieTTS-LF against three baselines: XTTS, Qwen3-TTS, and VibeVoice. The authors use Whisper-Large to transcribe generated audio for intelligibility evaluation. Speaker similarity is computed with embeddings from Titanet and WavLM, using cosine similarity against reference speaker audio. Naturalness is measured with UTMOSv2 on 10-second windows.
For the baselines, the authors test two common generation strategies: sentence-wise segmentation followed by concatenation, and unsegmented generation up to the model's maximum input length. They report whichever configuration performs better for each baseline, which is an important implementation detail because the comparison is not restricted to a single weak chunking policy.
The reported MagpieTTS-LF inference settings are $\epsilon = 0.1$, $w = (0.2, 0.8, 1.0, 0.8, 0.2)$, temperature $0.7$, $\lambda = 1.0$, and CFG scale $2.5$.
Results: Intelligibility and Speaker Similarity
The first evaluation axis is alignment robustness over time, measured with word error rate (WER) and character error rate (CER) on Whisper-Large transcriptions. The second axis is speaker similarity, computed as cosine similarity between reference and generated embeddings from Titanet and WavLM. Lower WER/CER is better, and higher similarity is better.
| Model | WER $\downarrow$ | CER $\downarrow$ | SSIM (TitaNet) $\uparrow$ | SSIM (WavLM) $\uparrow$ |
|---|---|---|---|---|
| MagpieTTS-LF | 0.025 | 0.012 | 0.79 $\pm$ 0.02 | 0.979 $\pm$ 0.002 |
| XTTS | 0.051 | 0.035 | 0.69 $\pm$ 0.06 | 0.929 $\pm$ 0.042 |
| Qwen3-TTS | 0.045 | 0.028 | 0.80 $\pm$ 0.09 | 0.958 $\pm$ 0.025 |
| VibeVoice | 0.115 | 0.105 | 0.53 $\pm$ 0.15 | 0.848 $\pm$ 0.162 |
MagpieTTS-LF achieves the best WER and CER by a clear margin, indicating the strongest long-range intelligibility among the evaluated systems. The paper interprets the gains as evidence that the stateful inference procedure prevents error accumulation at chunk boundaries. XTTS and Qwen3-TTS degrade more than MagpieTTS-LF, which the authors attribute to boundary effects and the absence of cross-chunk history. VibeVoice performs worst in intelligibility, consistent with the authors' hypothesis that aggressive token compression can harm fine-grained linguistic fidelity over long spans.
For speaker similarity, MagpieTTS-LF obtains the best WavLM score and remains highly competitive on TitaNet. The paper notes that Qwen3-TTS slightly exceeds MagpieTTS-LF on TitaNet, but the margin is not statistically significant. The key finding is not a single point estimate, but the stability of similarity over time, which is treated more fully in the position-dependent plots below.
Results: Prosodic Boundary Discontinuity
To quantify sentence-boundary artifacts, the paper extracts $F_0$ and energy in $\pm 1000$ ms windows around each sentence boundary and computes two discontinuity measures: the absolute jump in mean $F_0$ before and after the boundary, and the energy difference in dB. These are aggregated across boundaries, min-max normalized, and combined into a composite measure. Lower values indicate smoother transitions.
| Model | $\Delta F_0$ (Hz) $\downarrow$ | $\Delta$ Energy (dB) $\downarrow$ | Composite $\downarrow$ |
|---|---|---|---|
| MagpieTTS-LF | 69.19 | 14.04 | 0.4646 |
| XTTS | 67.13 | 30.62 | 0.734 |
| Qwen3-TTS | 65.54 | 17.91 | 0.5169 |
| VibeVoice | 69.08 | 28.90 | 0.712 |
The authors highlight that the energy discontinuity is the clearest separator: MagpieTTS-LF has the lowest boundary energy jump, roughly half the magnitude of the weakest baselines. The $F_0$ differences are closer across systems, suggesting that loudness consistency is the dominant perceptual contributor to boundary naturalness in this benchmark. XTTS is described as having relatively smooth pitch transitions but severe loudness inconsistency. Qwen3-TTS performs well overall, but still trails MagpieTTS-LF on the composite boundary score. VibeVoice again shows strong degradation at boundaries.
Results: Speaker Consistency and Naturalness Over Sequence Length
The paper further analyzes long-form stability by slicing generated audio into non-overlapping 10-second windows and tracking speaker similarity and perceived quality as a function of relative position in the utterance. The speaker similarity plots use Titanet and WavLM embeddings, while naturalness uses UTMOSv2. The main objective here is to determine whether a model drifts as the generated passage gets longer.
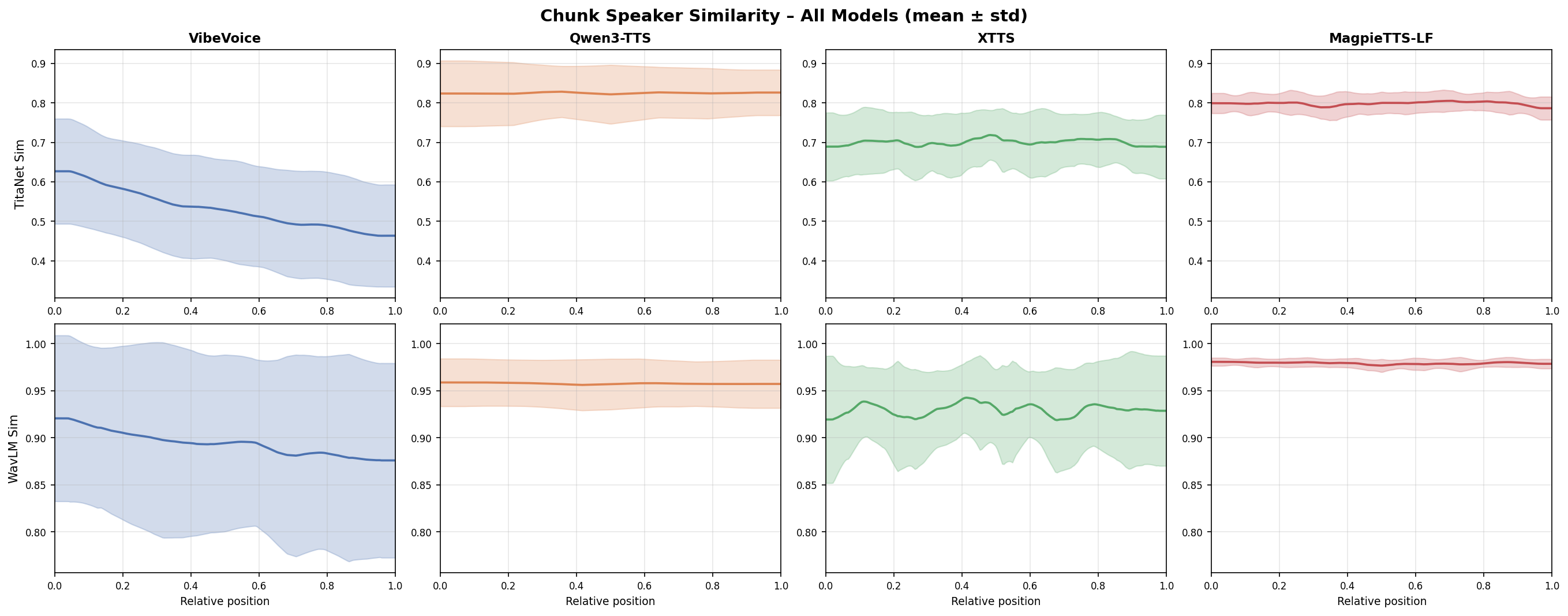
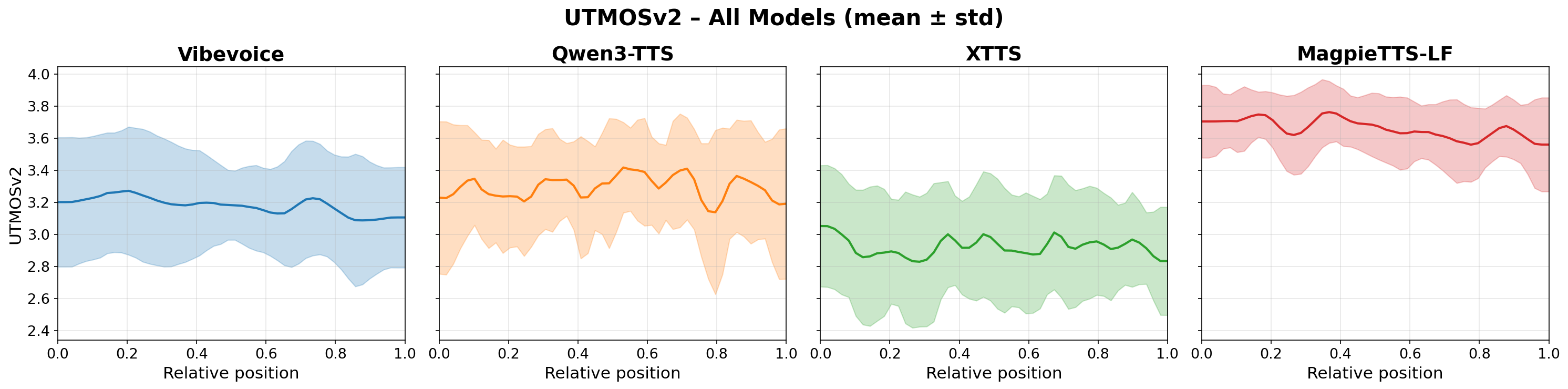
According to the paper, MagpieTTS-LF maintains the highest and most stable speaker similarity throughout generation for both Titanet and WavLM, with minimal variance and no visible start-to-end drift. The competing systems show larger variance or downward trends, indicating that speaker identity is less stable over long distances. The same pattern appears in UTMOSv2: MagpieTTS-LF has the highest score and the most consistent quality curve, while VibeVoice degrades the most and XTTS is described as the least natural-sounding among the baselines.
What the Paper Claims as Contributions
- An inference-time soft attention prior that encourages monotonic text-audio alignment without hard masking.
- A stateful chunk-generation algorithm that carries text, encoder context, and attention state across sentence boundaries.
- An evaluation showing improved long-range intelligibility, speaker consistency, boundary naturalness, and perceived quality.
- A long-form benchmark constructed from MLS paragraphs for evaluating paragraph-length synthesis.
- A comparison against representative long-form TTS strategies including chunked XTTS, Qwen3-TTS, and VibeVoice.
Limitations and Scope, as Supported by the Paper
The provided LaTeX source does not include a dedicated limitations section, so the most defensible limitations are those that follow directly from the method and evaluation setup. First, the procedure relies on sentence-level chunking and punctuation-aware segmentation, so it still assumes a text partitioning step rather than fully global decoding. Second, the history mechanism uses a fixed number $K$ of past tokens and cached encoder states, which means the amount of retained context is bounded. Third, the reported evaluation is limited to 20 English long texts and a long-form HiFiTTS subset derived from MLS, so the evidence in the paper is centered on English paragraph-length synthesis rather than multilingual or unrestricted document-length speech.
Another practical constraint is that the soft-prior parameters are experimentally set rather than learned within the inference procedure. The method is therefore simple to deploy, but it also means performance depends on these hand-tuned settings. Finally, the paper demonstrates that the approach works on a chunk-based encoder-decoder TTS model, but it does not provide proof that every possible speech generator would benefit equally without adaptation.
The source provided here also does not report a separate ablation table, so the relative importance of the soft prior, the cached encoder state, and the text-history component is described qualitatively rather than through isolated ablation numbers in the LaTeX body.
Conclusion
MagpieTTS-LF is presented as a practical inference-time extension for long-form speech generation that avoids retraining while substantially improving continuity. Its core technical idea is to preserve local monotonic alignment while keeping long-range context alive through soft attention priors and cross-chunk state propagation. Across the reported metrics, the method delivers the lowest WER and CER, the best boundary energy continuity, strong and stable speaker similarity, and the highest naturalness consistency over long passages. The paper's broader takeaway is that long-form coherence can be recovered from a strong short-form TTS model by making inference stateful and context-aware rather than by rebuilding the model from scratch.
Code & Implementation
This repository provides the NeMo Speech toolkit, encompassing a broad suite of speech AI tools including Text-to-Speech (TTS) models. Within it, the long-form speech generation approach MagpieTTS-LF is implemented primarily under the nemo/collections/tts/models/ directory, where the magpietts.py and easy_magpietts_inference.py source files offer the core model and inference logic.
The magpietts.py file contains the main MagpieTTS model implementation with utilities for autoregressive, chunked speech generation and management of monotonic alignments, guided attention priors, and context maintenance across sentence chunks as described in the paper. The easy_magpietts_inference.py file complements it with higher-level inference classes to facilitate streaming and batching inference while maintaining prosodic continuity and history-aware text encoding.
The repository is structured to integrate these models with PyTorch Lightning for flexible training and inference workflows, and the codebase contains support for data loading, alignment losses, and codec-based audio generation. Extensive configuration and streaming state management enables the inference-time innovations of MagpieTTS-LF without retraining on long-form data.
For detailed usage and model documentation, users should refer to the nemo/collections/tts/README.md and the official NeMo Speech documentation linked from the repository.