DASH
DASH: Dual-View Self-Distillation with Multi-Layer Hidden Representations for Robust Speech Recognition

DASH is a self-distillation framework for robust speech recognition that aligns prototype assignment distributions from multiple encoder layers between clean and noisy views. This approach stabilizes training and learns noise-invariant representations, improving robustness without sacrificing clean accuracy.
Links
Paper & demos
Abstract
Automatic Speech Recognition (ASR) often degrades in real-world noisy environments, making noise robustness essential for deployment. Supervised noise-augmented fine-tuning is a common remedy, but it can introduce a robustness-clean trade-off and overfit to specific corruptions, degrading recognition in clean conditions. We propose DASH, a self-distillation framework that improves robustness by learning clean--noisy consistency from paired views. DASH distills hidden representations from multiple encoder layers to capture features from low-level acoustics to high-level semantics, and stabilizes training by minimizing KL divergence between prototype assignment distributions of clean and noisy views. Experiments on LibriSpeech show that DASH consistently improves recognition under diverse noisy conditions while preserving clean accuracy, achieved by a label-free pre-training stage with minimal additional overhead (about 4% of fine-tuning time) beyond standard fine-tuning.
1. Problem, motivation, and core idea
The paper addresses a common failure mode of automatic speech recognition (ASR): systems that perform well on clean speech can degrade sharply under real-world noise. A straightforward remedy is supervised noise augmentation during fine-tuning, but the authors argue that this often creates a robustness-clean trade-off and can overfit the model to specific corruptions, hurting clean recognition. DASH is proposed as a self-distillation framework that instead learns clean-noisy consistency from paired views of the same utterance, with the goal of improving robustness while preserving clean accuracy.
The central design choice is to distill not only final-layer predictions, but hidden representations from multiple encoder layers. The method uses a clean teacher branch and a noisy student branch, with the teacher updated by exponential moving average (EMA). To make the distillation stable and avoid shortcut solutions, DASH maps encoder features to prototype assignments and minimizes the KL divergence between the clean and noisy assignment distributions. The paper’s empirical claim is that this produces more noise-invariant speech representations spanning both low-level acoustics and high-level semantics, while adding only a small amount of extra computation beyond standard fine-tuning.
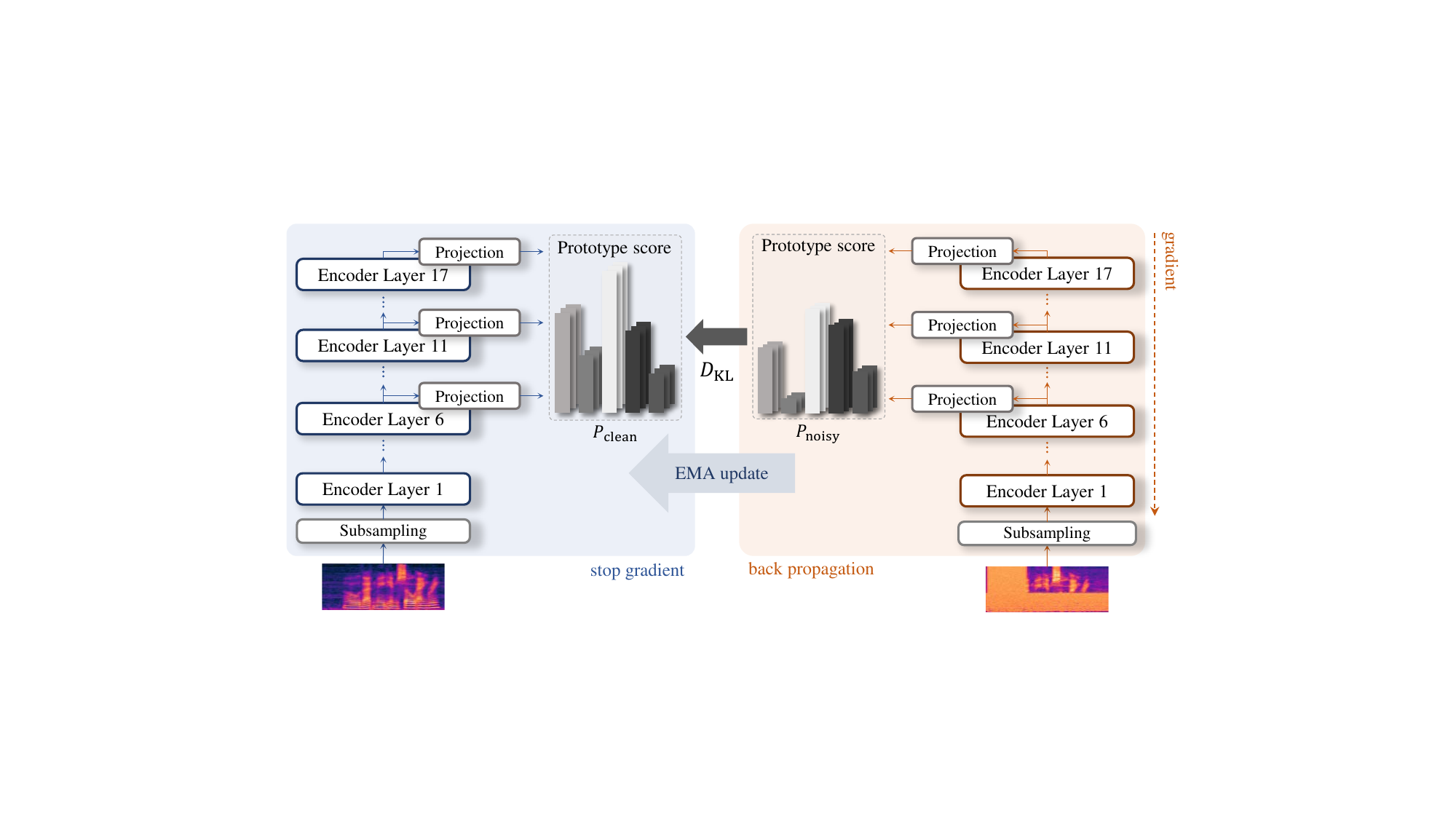
2. Method: dual-view self-distillation with prototype-based alignment
2.1 Dual clean/noisy encoder branches
DASH instantiates a dual-branch encoder setup. The teacher branch processes the clean view $x_{\text{clean}}$, while the student branch processes an augmented noisy view $x_{\text{noisy}}$. The teacher is not updated by ordinary backpropagation; instead, its parameters are updated with EMA from the student parameters:
$$\theta_{\text{teacher}}^{(t+1)} = \alpha \theta_{\text{teacher}}^{(t)} + (1-\alpha)\theta_{\text{student}}^{(t)}$$
where $\alpha$ is the EMA decay. The teacher branch is stop-gradient, so gradients flow only through the noisy student path. This produces a stable target that evolves smoothly over training and avoids the instability of a fully jointly optimized teacher-student pair.
The motivating representation-level goal is consistency under noise transformations $t \in \mathcal{T}$:
$$f(t(x)) \approx f(x), \quad x \in \mathcal{X},\ t \in \mathcal{T}.$$
2.2 Why the paper uses prototypes instead of direct continuous regression
The authors explicitly identify the shortcut problem: in predictive ASR models, directly matching continuous teacher and student activations can encourage trivial solutions that track low-level correlations or specific noise patterns rather than robust phonetic structure. To reduce this risk, DASH adds a projection head and then clusters projected encoder vectors using k-means, converting the continuous embedding space into a discrete prototype space. These prototypes function as structured acoustic units that are intended to be harder to game than raw continuous logits.
Concretely, if $f_{\theta}$ is the encoder and $h_{\theta}$ is the projection head, then for an input sequence $\mathbf{x} \in \mathbb{R}^{T \times D_{\text{in}}}$ the projected representation is
$$\mathbf{z} = h_{\theta}(f_{\theta}(\mathbf{x})) \in \mathbb{R}^{T \times D_K}.$$
Each frame embedding is compared with a prototype set $\mathbf{C} \in \mathbb{R}^{K \times D_K}$, where the paper uses $K=512$ prototypes. Similarity scores are temperature-scaled and normalized into clean and noisy distributions over prototypes:
$$P_{\text{clean}}(k) = \frac{\exp\bigl(\mathbf{z}_{\text{clean}}^{\top} \mathbf{c}_k / \tau_{\text{temp}}\bigr)}{\sum_{j=1}^{K} \exp\bigl(\mathbf{z}_{\text{clean}}^{\top} \mathbf{c}_j / \tau_{\text{temp}}\bigr)}, \quad P_{\text{noisy}}(k) = \frac{\exp\bigl(\mathbf{z}_{\text{noisy}}^{\top} \mathbf{c}_k / \tau_{\text{temp}}\bigr)}{\sum_{j=1}^{K} \exp\bigl(\mathbf{z}_{\text{noisy}}^{\top} \mathbf{c}_j / \tau_{\text{temp}}\bigr)}.$$
2.3 Multi-layer hidden representation distillation
A key novelty is that DASH does not restrict alignment to the final encoder layer. Instead, it extracts hidden states from multiple intermediate layers of the encoder, with the paper illustrating layers 6, 11, and 17 as examples. Each layer’s output is independently passed through the projection head and matched across clean and noisy views. The authors’ intuition is that this captures a spectrum of information: earlier layers encode more local acoustics, while later layers carry more semantic structure. Distilling across multiple depths is meant to align both kinds of information under noise.
The self-distillation objective is the average KL divergence over time between the stop-gradient clean distribution and the noisy distribution:
$$\mathcal{L}_{\text{DASH}} = \frac{1}{T} \sum_{t=1}^{T} D_{\mathrm{KL}}\Bigl(\mathrm{sg}(P_{\text{clean}}) \parallel P_{\text{noisy}}\Bigr).$$
Because the teacher distribution is detached, the student branch is explicitly trained to produce prototype assignments that remain consistent with the clean branch while being robust to acoustic perturbations. In the paper’s framing, this stabilizes training and encourages noise-invariant representations without requiring text labels during the pre-training stage.
2.4 Decoupled two-stage training
DASH uses a decoupled pipeline rather than a single joint optimization objective. Stage 1 is label-free encoder-only self-distillation on unlabeled speech. Stage 2 is standard supervised ASR fine-tuning. The authors emphasize that this separation avoids gradient interference and delayed convergence that can arise when distillation and ASR loss are optimized together. It also lets the method exploit unlabeled data, which is important because the distillation stage does not need transcripts.
In the reported implementation, only the encoder is updated during self-distillation; the prediction and joint networks are frozen. This means the extra stage is deliberately lightweight and intended to serve as a representation-shaping warm start before task-specific fine-tuning.
3. Experimental setup
3.1 Data, noisy views, and evaluation protocol
The supervised ASR fine-tuning set is LibriSpeech train-960. The encoder-only self-distillation stage uses LibriLight Medium, which the paper equates to about $3{,}230$ hours of unlabeled speech. Prototype construction uses encoder representations from $100{,}000$ randomly sampled utterances from this unlabeled set.
Evaluation is performed on LibriSpeech test-clean and test-other, and the paper also reports noisy-condition results by mixing test-clean with noise from NOISEX-92. The evaluated noises are white, pink, and babble, each at $0$ dB, $5$ dB, and $10$ dB SNR. Greedy decoding is used, with no external language model.
During self-distillation, the clean view is left unaugmented. The noisy view is built from three augmentation families: SpecAugment, additive noise from MUSAN, and reverberation via room impulse responses from the DNS Challenge 2021 dataset. The paper compares different combinations and uses the best trade-off as its default noisy-view construction.
3.2 Baseline model and optimization details
The baseline is nvidia/parakeet-tdt_ctc-110m, a hybrid ASR model combining Token-and-Duration Transducer (TDT) and CTC. The encoder has 17 FastConformer layers with 512-dimensional hidden states. The supervised loss is
$$\mathcal{L}_{\text{ASR}} = 0.7\,\mathcal{L}_{\text{TDT}} + 0.3\,\mathcal{L}_{\text{CTC}}.$$
The paper reports dropout $0.1$, AdamW optimization with learning rate $5 \times 10^{-5}$, weight decay $10^{-4}$, and $\beta=(0.9, 0.999)$. Training uses gradient clipping with $L_1$ norm $1$ and Lhotse dynamic bucketing with batch duration up to $500$ seconds. The teacher EMA decay is $\alpha = 0.999$, the prototype temperature is $\tau_{\text{temp}} = 3.5$, and the prototype count is $K=512$.
The self-distillation stage runs for $5{,}000$ steps, and the supervised fine-tuning stage runs for $100{,}000$ steps. The authors note that the self-distillation stage adds only about $4\%$ of fine-tuning time: roughly half an hour versus about 12 hours for fine-tuning on a single RTX 3090. All experiments were run on two NVIDIA GeForce RTX 3090 GPUs.
4. Main results
4.1 Overall WER on clean and noisy conditions
The paper’s central result is that DASH improves robustness under a wide range of noisy conditions while largely preserving clean performance. The table below summarizes the main WER results reported in the paper.
| Method | Phase 1 | Phase 2 | test-clean | test-other | white 0 dB | white 5 dB | white 10 dB | pink 0 dB | pink 5 dB | pink 10 dB | babble 0 dB | babble 5 dB | babble 10 dB |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | - | - | 2.58 | 5.41 | 19.04 | 8.47 | 4.65 | 19.79 | 7.11 | 4.01 | 19.80 | 6.73 | 3.90 |
| Fine-tuning only | - | Clean | 2.00 | 4.45 | 15.49 | 6.68 | 3.55 | 16.73 | 5.77 | 3.12 | 19.11 | 5.79 | 2.92 |
| Fine-tuning only | - | Noisy (0 to 15 dB) | 2.07 | 4.35 | 10.89 | 5.22 | 3.18 | 11.82 | 4.70 | 2.90 | 13.78 | 4.77 | 2.78 |
| Fine-tuning only | - | Noisy (-5 to 10 dB) | 2.14 | 4.40 | 10.34 | 5.02 | 3.14 | 11.12 | 4.50 | 2.83 | 13.06 | 4.50 | 2.71 |
| DASH | Noisy (0 to 15 dB) | Clean | 1.99 | 4.10 | 11.89 | 5.33 | 3.14 | 12.78 | 4.61 | 2.75 | 16.48 | 5.07 | 2.72 |
| DASH | Noisy (0 to 15 dB) | Noisy (0 to 15 dB) | 1.96 | 4.15 | 10.27 | 4.88 | 3.00 | 11.16 | 4.40 | 2.71 | 13.11 | 4.51 | 2.64 |
| DASH | Noisy (-5 to 10 dB) | Noisy (-5 to 10 dB) | 2.02 | 4.25 | 10.34 | 4.81 | 3.05 | 10.92 | 4.42 | 2.76 | 12.78 | 4.42 | 2.68 |
The table shows several important trends. First, standard noisy fine-tuning improves robustness relative to clean fine-tuning, but it also weakens clean performance: for example, the clean-fine-tuned model reaches $2.00\%$ on test-clean, while the noisy-fine-tuned variants move to $2.07\%$ and $2.14\%$. Second, DASH reduces this trade-off. The configuration trained with noisy self-distillation and clean fine-tuning achieves $1.99\%$ on test-clean and $4.10\%$ on test-other, which is better than clean fine-tuning on test-other while preserving clean accuracy. Third, when fine-tuning is also performed on noisy data, DASH gives the best noisy-condition WERs among the reported methods, such as $10.27\%$ on white noise at $0$ dB, $11.16\%$ on pink noise at $0$ dB, and $13.11\%$ on babble at $0$ dB.
The paper also highlights a notable decoupling effect: DASH pre-training on noisy data followed by clean fine-tuning still yields substantial robustness gains. In other words, the label-free self-distillation stage appears to establish noise-invariant speech representations that persist even after a clean supervised adaptation stage.
4.2 Which noisy-view augmentation works best?
To choose the default construction of the noisy view during self-distillation, the authors compare several augmentation combinations. The reported pattern is that DASH is robust across all tested choices, but the combination of SpecAugment + additive noise gives the best overall trade-off and the best test-other result among the tested options. Using all three augmentations at once slightly hurts performance, which the authors interpret as overly strong corruption blurring phonetic cues.
| Method | SpecAug | Noise | RIR | test-clean | test-other |
|---|---|---|---|---|---|
| Baseline | 2.58 | 5.41 | |||
| Fine-tuning | 2.00 | 4.45 | |||
| DASH | ✓ | 2.01 | 4.16 | ||
| DASH | ✓ | ✓ | 1.99 | 4.10 | |
| DASH | ✓ | ✓ | 1.99 | 4.12 | |
| DASH | ✓ | ✓ | 1.97 | 4.18 | |
| DASH | ✓ | ✓ | ✓ | 2.01 | 4.18 |
This ablation matters because it isolates the pre-training view generator, independent of the later supervised ASR stage. The best reported balance is achieved when the noisy view uses SpecAugment together with additive noise. That choice becomes the default for the rest of the experiments.
4.3 EMA update frequency and distillation depth
The paper next studies whether the teacher should be updated step-by-step with EMA and whether aligning only the final layer is sufficient. The answer is no on both counts: the best results come from continuous EMA updates and multi-layer distillation. Slower teacher updates or a frozen teacher slightly worsen WER, and restricting distillation to the final layer causes the largest degradation, even falling behind the fine-tuning-only baseline on test-other.
| Method | test-clean | test-other |
|---|---|---|
| Baseline | 2.58 | 5.41 |
| Fine-tuning only | 2.14 | 4.40 |
| DASH (self-distillation) | 2.02 | 4.25 |
| DASH with EMA at 1000-step interval | 2.04 | 4.27 |
| DASH without EMA (frozen teacher) | 2.05 | 4.30 |
| DASH without EMA and with only the final layer (layer 17) | 2.10 | 4.45 |
The authors interpret this as evidence that the teacher must evolve smoothly during training, and that intermediate representations carry important robustness information. Distilling only the final encoder layer loses much of the benefit, suggesting that noise invariance is built progressively across the encoder hierarchy rather than emerging only at the top.
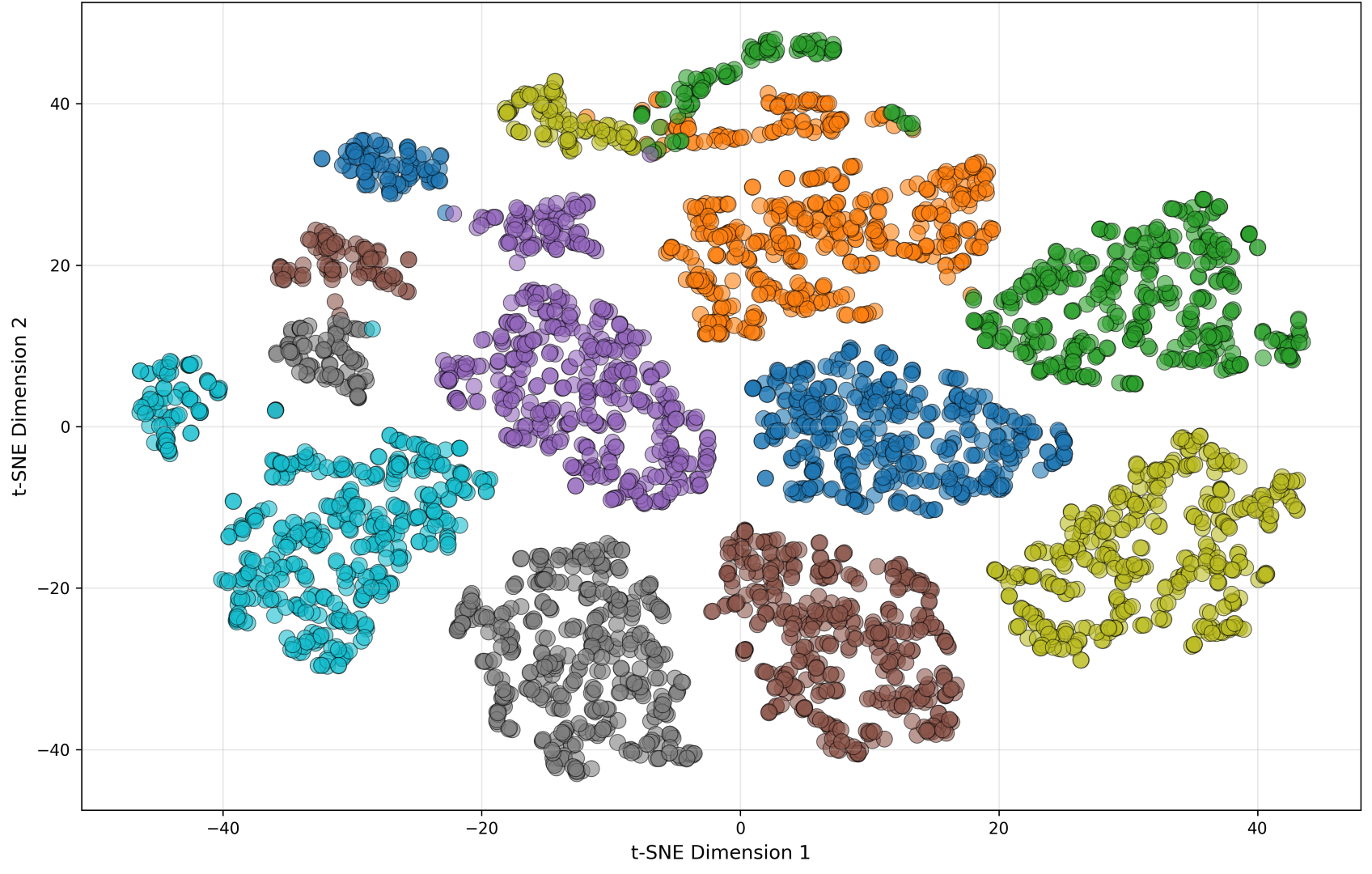
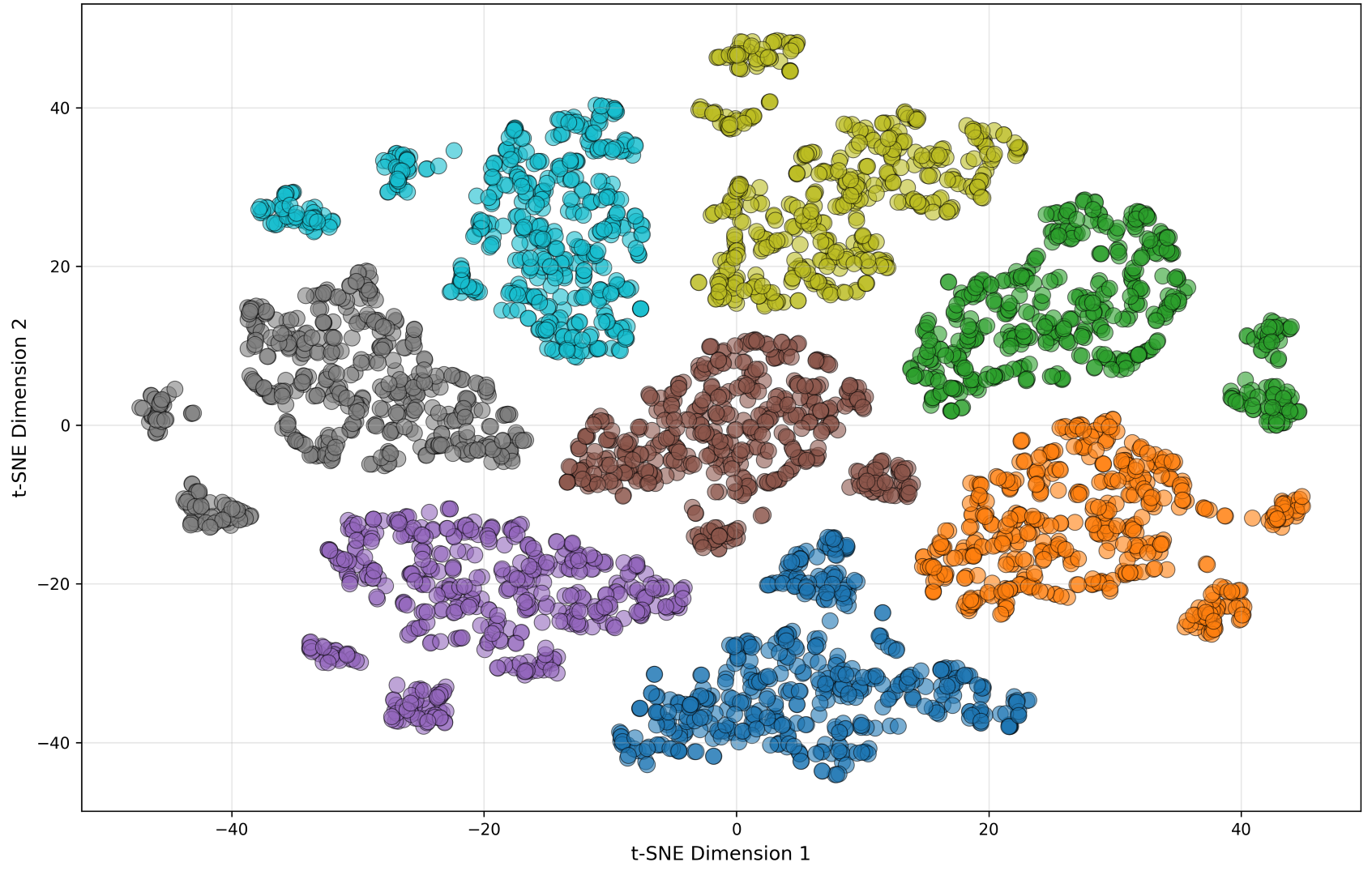
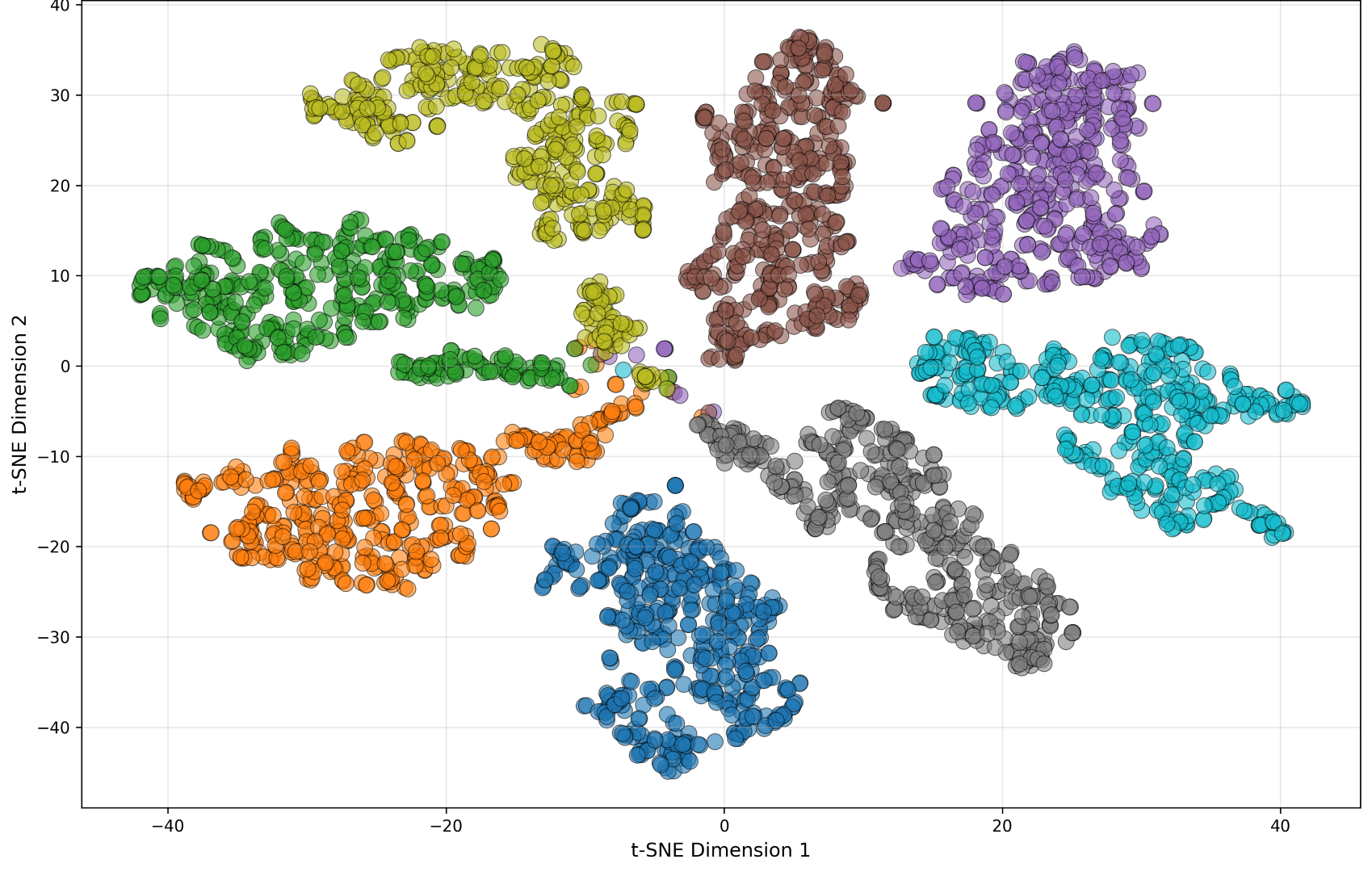
4.4 Qualitative representation analysis
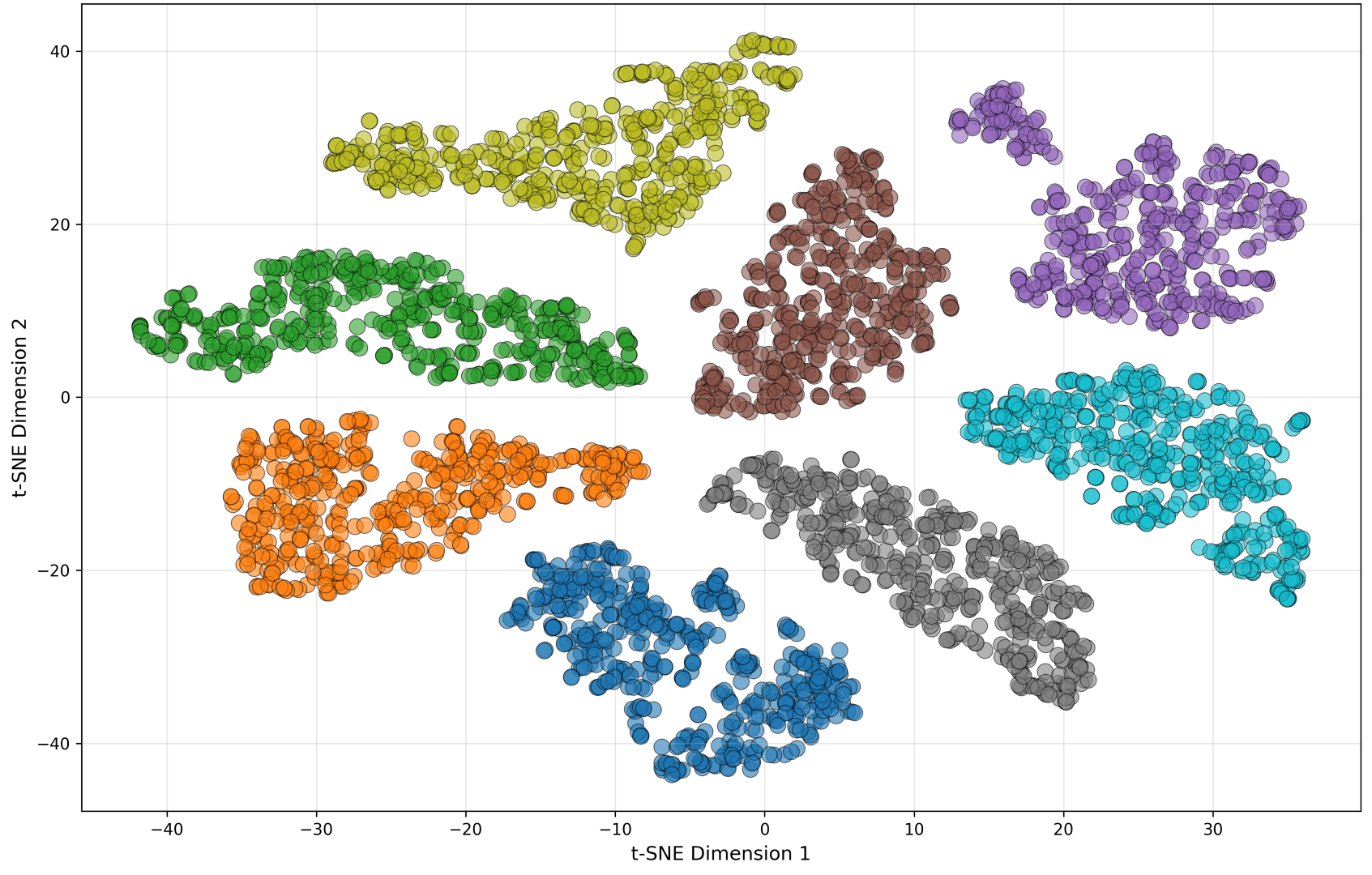
The paper supports the quantitative results with t-SNE visualizations of encoder embeddings extracted from layers 6 and 17 after adding NOISEX-92 noise at $0$ dB. The baseline fine-tuning model shows broader and sometimes fragmented clusters, whereas DASH groups utterances more tightly. At layer 6, DASH already yields more coherent clusters for low-level acoustic features. At layer 17, both systems produce more semantically organized embeddings, but DASH still exhibits tighter clusters and less residual noise entanglement.
5. What the paper claims DASH contributes
- Dual-view consistency learning for ASR robustness: the method learns from paired clean and noisy views of the same utterance, rather than relying only on supervised noise augmentation.
- Multi-layer hidden-state distillation: the model aligns intermediate encoder representations, not only the final layer, so it can capture both acoustic and semantic invariances.
- Prototype-based KL alignment: continuous features are quantized into discrete prototypes, which the authors use to reduce shortcut learning and representational collapse.
- Decoupled two-stage training: the label-free self-distillation stage can exploit unlabeled speech and adds only modest compute overhead before standard ASR fine-tuning.
- Better robustness-clean balance: across the reported LibriSpeech and noise-mixing experiments, DASH mitigates the usual trade-off between noisy robustness and clean accuracy.
6. Reported scope and limitations
The paper does not present a dedicated limitations section, but its reported scope is clear. The evaluation is limited to LibriSpeech for ASR and LibriLight Medium for unlabeled pre-training, with synthetic noisy mixtures built from NOISEX-92, MUSAN, and DNS Challenge 2021 RIRs. The test-time setup uses greedy decoding without an external language model. As a result, the evidence is strong for the reported English speech-recognition setting, but the paper does not claim broader multilingual, cross-domain, or real-device deployment validation.
Another practical constraint is that DASH still requires a separate self-distillation stage before fine-tuning, even though the additional cost is small. The method is therefore lightweight relative to the baseline training pipeline, but it is not free. Finally, the ablation showing reduced performance when the teacher is frozen or distillation is limited to the final layer suggests that the method depends on the specific EMA-and-multi-layer design choices rather than on self-distillation in the abstract.
7. Bottom line
DASH is a cleanly motivated robustness method for ASR: it uses a teacher-student dual-view setup, prototype-based KL distillation, and multi-layer hidden-state matching to make noisy speech representations line up with clean ones. On LibriSpeech, the method improves noise robustness across several corruption types and SNRs, keeps clean accuracy competitive, and does so with a relatively modest pre-training overhead.