FineCombo-TTS
FineCombo-TTS: Collaborative and Precise Controllable Speech Synthesis Using Text Descriptions and Reference Speech
FineCombo-TTS uniquely combines reference speech and text descriptions for precise, flexible control of speech synthesis, jointly modeling timbre, prosody, and emotion. It learns a unified acoustic embedding and uses a text-guided flow model to edit speech attributes based on relative changes from a reference.
Demos
The demos illustrate FineCombo-TTS's precise and flexible control over speech attributes using text descriptions and reference speech. They demonstrate changes in pitch, emotion, and timbre producing natural and expressive voice outputs. Focus on how well the synthesized speech matches the intended acoustic modifications and the seamless integration of joint controls.
Links
Paper & demos
Abstract
Controllable text-to-speech (TTS) has become a key research focus. However, methods based on either reference speech or text descriptions lack flexibility and precise control, and recent joint approaches remain loosely coupled, with speech modeling timbre and text controlling global style. We propose FineCombo-TTS, a unified framework for speech synthesis grounded in reference speech and guided by text descriptions, enabling flexible and precise control over acoustic attributes. Instead of explicit attribute disentanglement, we learn a unified acoustic representation and introduce a Conditional Flow Matching (CFM)-based Speech Variance Predictor to model fine-grained reference-to-target transformations guided by text descriptions. To support relative attribute control, we construct FineEdit, a structured paired dataset that explicitly encodes source-to-target attribute variations. Experiments demonstrate that our approach achieves flexible, precise, and expressive controllable TTS.
Introduction
FineCombo-TTS addresses a central limitation in controllable text-to-speech (TTS): existing systems usually support either reference-speech control or text-description control, but not a truly collaborative form of control that is both flexible and precise. The paper argues that reference-based methods are strong for zero-shot voice cloning but depend heavily on the reference sample, while description-based systems are more flexible but struggle to express fine acoustic nuances. Even recent joint methods tend to be loosely coupled, with reference speech mostly carrying timbre and text mostly overriding global style.
The core goal of FineCombo-TTS is to preserve the acoustic identity of a chosen reference speech while allowing a text instruction to refine specific attributes such as timbre, prosody, and emotion. Instead of explicitly disentangling speech factors, the model learns a unified acoustic attribute representation and then predicts how that representation should change under a control description. This design is paired with a structured paired dataset, FineEdit, that encodes source-to-target attribute changes directly.
The paper’s main contributions are:
- a controllable TTS architecture that jointly uses reference speech and text descriptions for joint and single-condition control;
- a Conditional Flow Matching (CFM)-based Speech Variance Predictor that models fine-grained transformations in a unified acoustic latent space;
- FineEdit, a large paired dataset of $angle$source speech, control description, target speech$angle$ triplets for relative attribute control.
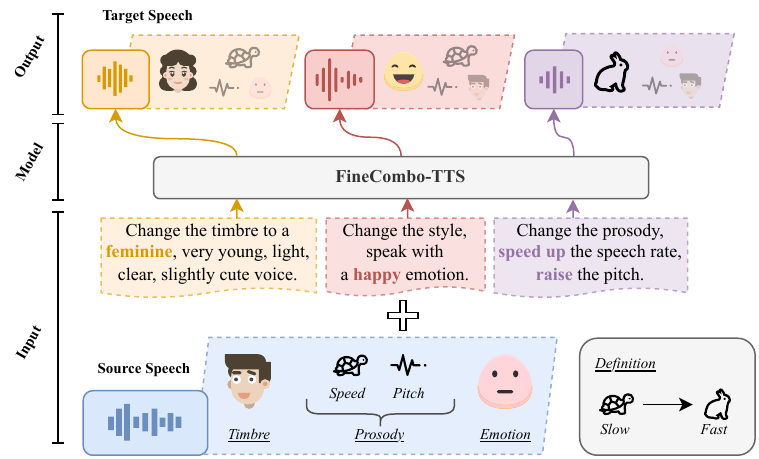
At a high level, the method treats reference speech as an acoustic baseline and uses the instruction text to specify a relative transformation. This is a departure from absolute style prompting: the model is trained to learn how to edit a reference condition, not only how to synthesize speech from a prompt in isolation.
Overall Architecture
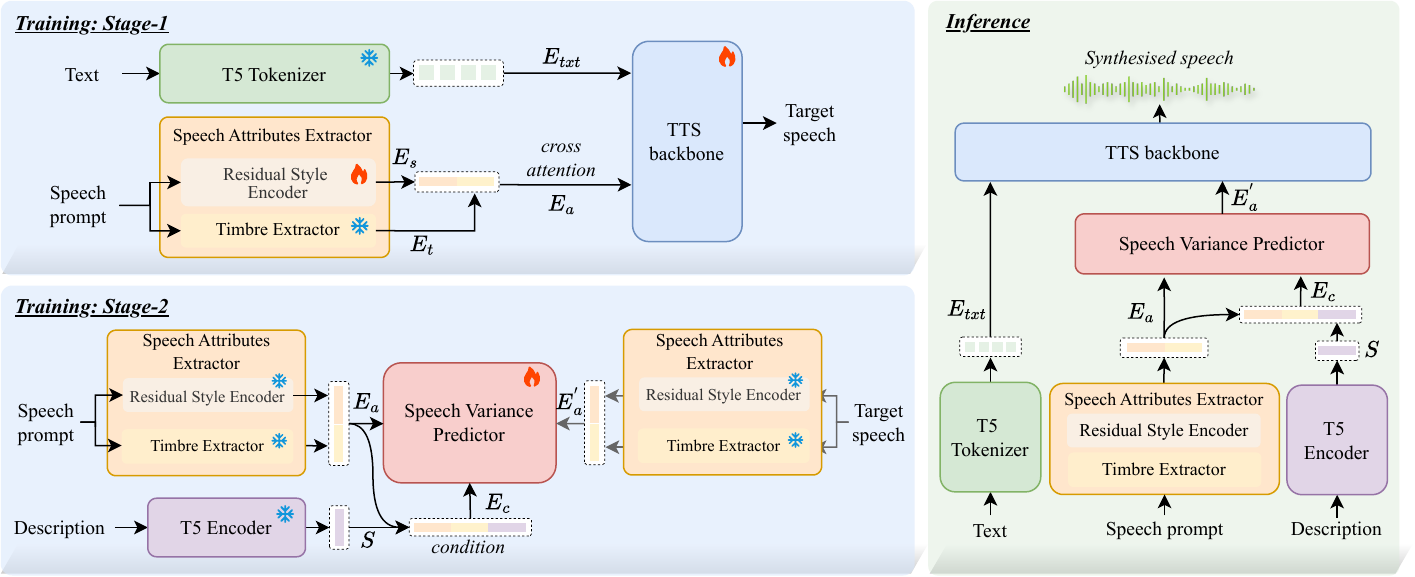
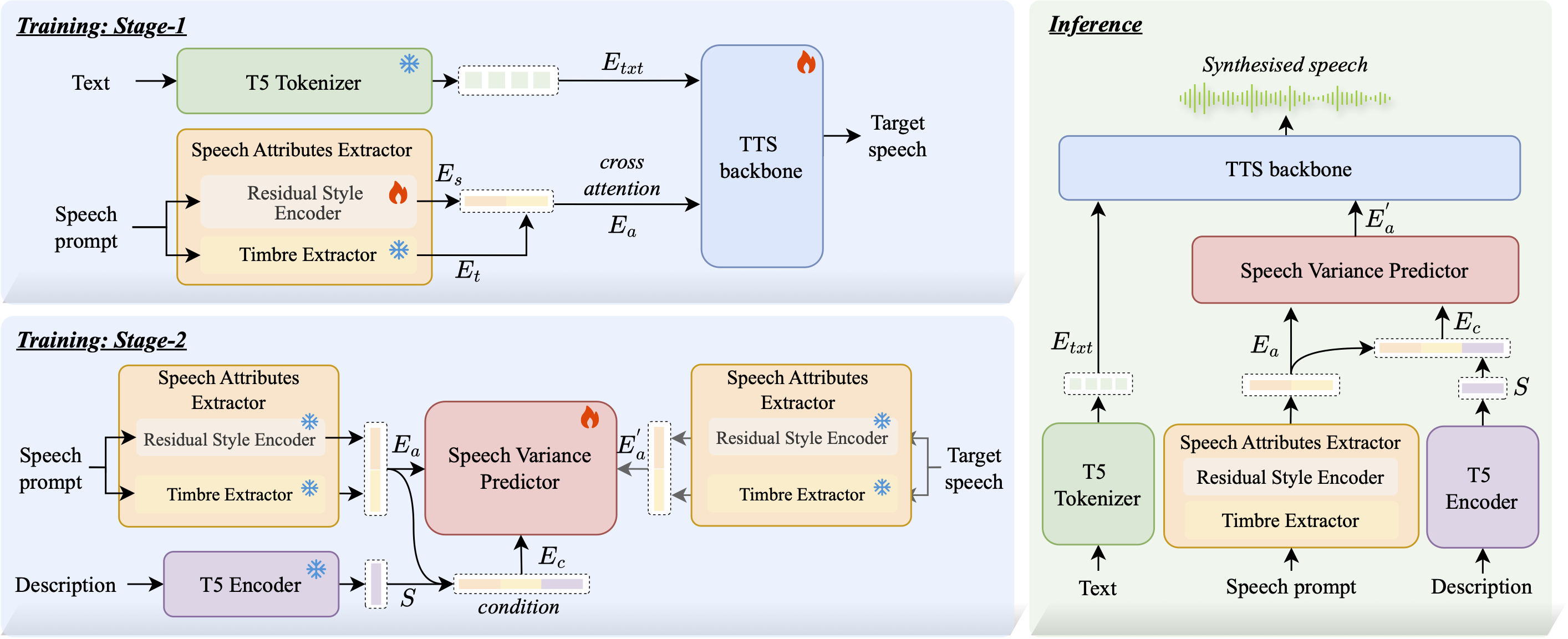
The system has three modules: a Speech Attributes Extractor, a Speech Variance Predictor, and a TTS backbone. The extractor converts prompt speech into a unified attribute embedding $E_a$. The Speech Variance Predictor transforms $E_a$ into a target embedding $E_a'$ under text guidance. The TTS backbone then generates multi-layer acoustic tokens conditioned on text and the target attribute embedding, and a codec decoder reconstructs waveform audio from those tokens.
Text descriptions are encoded with a pretrained T5 encoder; the paper specifically references flan-t5-small. The TTS backbone is a decoder-only Transformer codec language model with a delay-pattern autoregressive generation scheme, similar in spirit to MusicGen and ParlerTTS. The acoustic output is represented as multi-layer codec tokens and decoded by DAC.
A notable aspect of the design is that the model does not rely on explicit factor disentanglement. Instead, it learns a unified attribute space that retains natural couplings among speaker identity, prosody, and emotion, and then edits that representation with a text-conditioned flow model.
Speech Attribute Extraction
The paper argues that attempting to separate timbre, prosody, and emotion explicitly can be unstable and may introduce leakage or redundancy. To avoid this, FineCombo-TTS extracts a combined speech attribute embedding from prompt speech.
The embedding $E_a$ is built from two components:
- $E_t$: a timbre embedding from the pretrained FACodec timbre extractor, used to obtain a robust speaker-related representation;
- $E_s$: a residual style embedding from a Mel-Style Encoder style module, which uses convolution and self-attention to capture local and global patterns in the mel-spectrogram.
The final unified attribute embedding is formed by concatenation:
$$E_a = \operatorname{concat}(E_t, E_s).$$
This choice preserves natural coupling among acoustic factors while still giving the model an internal representation that can be edited. The paper’s ablation on the residual style encoder shows that adding this component slightly improves both speech quality and speaker similarity in first-stage zero-shot experiments.
Conditional Flow Matching for Speech Variance Prediction
The central modeling contribution is a CFM-based Speech Variance Predictor. Its role is to learn reference-to-target attribute transformations conditioned on both the reference speech embedding and the instruction text. Rather than generating speech directly, it predicts how the unified attribute vector should move in latent space.
During training, the source attribute embedding is used as $x_0$ and the target embedding from FineEdit is used as $x_1$. The paper defines a linear interpolation path:
$$x_t = t x_1 + (1-t)x_0, \quad u_t = x_1 - x_0, $$
where $t \in [0,1]$ and $u_t$ is the target velocity. A UNet backbone estimates the velocity field as
$$v_t = V_t(x_t, t \mid E_c),$$
with conditioning context $E_c = (E_a, S)$, where $S$ is the sentence-level text representation derived from the T5 encoder via cross-attention.
The training objective is a mean-squared error loss between the predicted and target velocities:
$$\mathcal{L}_{\mathrm{CFM}} = \mathbb{E}_{t, x_0, x_1} \lVert v_t - u_t \rVert^2.$$
This setup lets the model learn a continuous transformation field rather than a discrete classification over attributes. The paper emphasizes that this is useful for fine-grained editing because the same reference speech can be transformed in multiple ways depending on the instruction.
For description-only control, the source speech embedding is replaced by random noise, allowing the predictor to operate even without a reference utterance. This is important because the full system supports both collaborative control and single-condition generation.
Classifier-free guidance is applied to strengthen instruction following. During training, the text condition is randomly dropped to create a null-conditioned path. At inference, the guided velocity is computed as
$$\hat{V}_t(x_t,t\mid E_c) = \alpha V_t(x_t,t\mid E_c) + (1-\alpha)V_t(x_t,t\mid E_c'),$$
where $E_c' = [E_a, \emptyset]$ and $\alpha$ is the guidance scale. The paper reports using $\alpha = 2$ at inference.
TTS Backbone and Text Guidance
The TTS backbone is a decoder-only Transformer codec language model. The text input is tokenized into $E_{txt}$ and used as conditioning tokens. The attribute embedding $E_a$ is injected through cross-attention in each Transformer block, with text features as queries and the attribute representation as keys and values.
The backbone autoregressively predicts multi-layer acoustic tokens using a delay pattern, which helps maintain coherent prosody across layers and time steps. In probabilistic form, the model defines
$$P(A \mid E_{txt}, E_a; \theta_{\mathrm{TTS}}),$$
where $A$ is the codec token sequence.
To improve text-speech alignment and reduce omissions or repetitions, the paper applies classifier-free guidance on the text condition as well. Training randomly drops the text input, and inference uses
$$\log \hat{P}(A \mid E_{txt}, E_a) = \beta \log P(A \mid E_{txt}, E_a) + (1-\beta) \log P(A \mid \emptyset, E_a),$$
with $\beta = 2$ at inference. In practice, the system therefore uses two layers of guidance: one to steer attribute transformation in the variance predictor and another to improve content fidelity in the TTS backbone.
Training Strategy
The model is trained in two stages. In stage 1, the FACodec timbre extractor is frozen, while the residual style encoder and TTS backbone are jointly trained on large-scale text-speech corpora. The paper then fine-tunes this stage on emotional datasets to improve expressiveness. This stage establishes the core speech synthesis ability and learns a stable unified speech attribute embedding for zero-shot usage.
In stage 2, the CFM-based Speech Variance Predictor is trained separately on paired data, where descriptions specify how the source speech should be transformed into the target speech. The goal of this stage is to learn the precise, controllable mapping between reference-grounded attributes and target variations.
Training details reported by the paper are:
- stage 1 pre-training on Multilingual LibriSpeech (MLS, 45k hours) and LibriTTS-R (585 hours);
- stage 1 fine-tuning on EmoVoice-DB (45 hours) and TextrolSpeech (330 hours);
- stage 2 training on 236K description-speech pairs from TextrolSpeech, plus about 600K pairs per FineEdit subset;
- 12-layer Transformer decoder as the TTS backbone;
- a 1D UNet for the CFM predictor;
- training on 8 NVIDIA A100 GPUs;
- stage 1: 250K steps with batch size 32 and learning rate $10^{-4}$, then 70K fine-tuning steps at $5 \times 10^{-4}$ for emotional data;
- stage 2: 140K steps with learning rate $10^{-4}$;
- random text/description masking probability of 0.1 for CFG training;
- inference guidance scales set to $\alpha = \beta = 2$.
FineEdit Dataset
The paper identifies a data mismatch in existing speech-description corpora: they typically provide isolated speech-text pairs that describe absolute acoustic properties, but they do not teach a model how to edit a specific reference utterance toward a target variation. FineEdit is introduced to address this gap.
Each FineEdit sample is a triplet $\langle$source speech, control description, target speech$\rangle$. The source and target differ in only one targeted attribute: prosody, emotion, or timbre. The control description specifies the relative change, enabling learning of attribute transformations rather than just static descriptions.
The dataset is organized into three paired subsets:
- Prosody pairs: source and target share speaker identity and text content, while prosodic attributes such as speed and pitch vary. These are built from LibriTTS-R by applying controlled speed and pitch modifications with FFmpeg, and all pairwise combinations among the generated versions are used. The paper reports 634,956 prosody pairs.
- Emotion pairs: speaker identity is fixed while emotional expression varies. These are built from the Emotional Speech Database (ESD), which contains 10 speakers across five emotions: Happy, Sad, Angry, Surprised, and Neutral. The paper reports 80,000,000 emotion pairs. In this subset, identical text is not required.
- Timbre pairs: cross-speaker pairs are created while keeping overall prosody and style as consistent as possible. This subset is split into an emotion-neutral part from LibriTTS-R and an emotion-rich part from ESD with prosody/emotion annotations from TextrolSpeech. The paper reports 16,392,828 timbre pairs.
For timbre control, target speaker descriptions are used as annotations prefixed with a timbre-change instruction. The paper also notes that manual speaker descriptions are added in the emotion-rich timbre subset to support more expressive control.
| Dataset Type | Prosody | Emotion | Timbre | Text | Number of pairs |
|---|---|---|---|---|---|
| Prosody Pair | modified | unchanged | unchanged | unchanged | 634,956 |
| Emotion Pair | unchanged | modified | unchanged | modified | 80,000,000 |
| Timbre Pair | unchanged | unchanged | modified | modified | 16,392,828 |
Experimental Setup
The paper evaluates controllability across prosody, emotion, and timbre, using test samples from FineEdit that are held out from training. Since no prior model directly supports joint processing of reference speech and text descriptions under the same training setup, the authors re-implement VoxInstruct as VoxInstruct-Joint. The baseline is modified by prepending acoustic tokens from reference speech to its input sequence, and it is trained on the same data as FineCombo-TTS with the same strategy.
Evaluation combines subjective and objective measures. The subjective metrics are:
- MOS-S: speaker similarity;
- MOS-I: instruction following;
- MOS-P: prosodic consistency, used for timbre control.
The objective metrics are:
- WER: intelligibility via Whisper-large-v3;
- SECS: speaker encoder cosine similarity via WavLM-base-plus-sv;
- FPC: pitch correlation;
- Emotion-A and Emotion-S: emotion accuracy and emotion embedding similarity using emotion2vec;
- Controlled Accuracy: whether the generated change matches the instruction;
- Uncontrolled Variation: how much non-target attributes drift from the reference, where lower is better.
The experimental emphasis is on whether the model can alter only the requested attribute while preserving the rest of the speech characteristics.
Results
Prosody Control
| Model | MOS-S | MOS-I | WER | SECS | Uncontrolled Speed Variation | Uncontrolled Pitch Variation | Controlled Speed Accuracy | Controlled Pitch Accuracy |
|---|---|---|---|---|---|---|---|---|
| VoxInstruct-Joint | 2.00 ± 0.38 | 3.26 ± 0.37 | 11.12 | 56.79 | 19.00 | 42.81 | 91.35 | 63.81 |
| FineCombo-TTS | 4.04 ± 0.34 | 4.05 ± 0.31 | 12.87 | 70.20 | 14.62 | 6.71 | 98.00 | 93.33 |
For prosody control, FineCombo-TTS is clearly stronger on instruction adherence and precise attribute editing. It improves MOS-I and controlled accuracy, and it dramatically reduces uncontrolled pitch and speed drift relative to the baseline. The paper also reports higher MOS-S and SECS, suggesting that timbre is better preserved while prosody is edited.
The WER is slightly higher than VoxInstruct-Joint in this table, but the authors interpret the overall result as a better tradeoff between precise control, similarity, and audio quality.
Emotion Control and Timbre Control
| Model | Emotion Control | Timbre Control | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MOS-S | MOS-I | WER | SECS | Emotion-A | MOS-P | MOS-I | WER | FPC | Emotion-S | |
| VoxInstruct-Joint | 2.64 ± 0.24 | 2.96 ± 0.34 | 20.18 | 63.99 | 47.00 | 3.04 ± 0.36 | 3.32 ± 0.32 | 19.24 | 47.46 | 52.15 |
| FineCombo-TTS | 3.34 ± 0.36 | 3.83 ± 0.18 | 11.22 | 66.56 | 85.00 | 3.66 ± 0.32 | 3.75 ± 0.27 | 18.59 | 52.67 | 55.38 |
On emotion control, FineCombo-TTS delivers a large improvement in emotion accuracy: 85% versus 47% for VoxInstruct-Joint. It also improves MOS-S, MOS-I, WER, and SECS, indicating that stronger emotion transfer does not come at the cost of severe speaker degradation or poor intelligibility.
On timbre control, FineCombo-TTS again outperforms the baseline on the paper’s reported metrics. It achieves better MOS-P, MOS-I, FPC, and Emotion-S, with a slightly lower WER, suggesting that timbre transfer is effective while prosody and emotional style remain comparatively stable.
Ablation Studies
Classifier-Free Guidance Strategy
| Model | WER | SECS | Emotion-A |
|---|---|---|---|
| w/o CFG on description and text | 14.17 | 71.08 | 76.00 |
| w/o CFG on description | 9.06 | 72.53 | 81.00 |
| proposed | 8.82 | 69.16 | 86.00 |
The ablation suggests that guidance on the description condition is critical for instruction following. Removing description CFG reduces emotion accuracy, while adding text CFG improves WER and overall naturalness. The full multi-CFG setup yields the best instruction adherence, though it slightly lowers SECS compared with the no-description-CFG variant. The paper interprets this as a tradeoff: stronger emotional expression can slightly reduce similarity to the original timbre.
Residual Style Encoder
| Model | MCD | SECS |
|---|---|---|
| w/o residual style encoder | 11.08 | 90.00 |
| proposed | 10.83 | 90.20 |
Adding the residual style encoder slightly improves both mel-cepstral distortion and speaker similarity, which supports the paper’s claim that modeling residual style beyond timbre helps the unified attribute representation.
What the Results Show
Across prosody, emotion, and timbre control, the reported results support the paper’s central claim: reference speech and text descriptions can be made truly collaborative rather than functionally separated. The model consistently shows higher instruction-following scores than the VoxInstruct-based baseline, and it often preserves or improves similarity and intelligibility while making targeted changes.
The strongest empirical signal is the reduction in uncontrolled variation. In the prosody experiments, FineCombo-TTS substantially reduces unintended drift in pitch and speed, which is exactly the behavior expected from a method that edits a reference-grounded latent representation instead of overwriting the global style. In the emotion experiments, the large gain in emotion accuracy indicates that the paired dataset and CFM predictor do help the model learn relative attribute transformations. In timbre control, the method can change speaker identity while keeping prosody and emotional style relatively stable.
Discussion and Limitations
One of the main conceptual contributions of the paper is its rejection of hard disentanglement. Rather than forcing timbre, prosody, and emotion into strictly separate channels, FineCombo-TTS learns a shared acoustic representation and then edits it using text-guided flow matching. This is a pragmatic design for speech, where these factors are naturally correlated and difficult to separate cleanly.
The paper also demonstrates that data design matters as much as architecture. FineEdit is important because it teaches relative control directly: the model sees source-target pairs that differ in only one intended attribute and learns to map one to the other under description guidance. Without such paired supervision, description prompts alone are often too vague to teach fine-grained editing.
The paper does not include a dedicated limitations section. Based strictly on what is reported, a few practical constraints are visible: the method relies on substantial paired data construction; the best results come from a two-stage training pipeline that is computationally heavy; and the approach is evaluated mainly on English data and on the three attributes of prosody, emotion, and timbre. These observations are not stated as formal limitations by the authors, but they are the main boundaries that can be inferred from the reported setup.
Conclusion
FineCombo-TTS presents a unified approach to controllable TTS that combines reference speech and text descriptions for collaborative speech editing. Its key technical ingredients are a unified acoustic attribute embedding, a CFM-based Speech Variance Predictor, a decoder-only codec TTS backbone, and the FineEdit paired dataset. The experimental results show strong gains in precise attribute control across prosody, emotion, and timbre, with improved instruction following and reduced unintended variation compared with the adapted VoxInstruct baseline.
For a talking-head or conversational-AI team, the main takeaway is that the paper is less about prompt-based style transfer and more about reference-conditioned speech editing: a reference utterance anchors identity and acoustic context, while the text description acts as a precise edit instruction. That combination is what enables the reported improvements in flexibility and controllability.