ScenA
Reference-Driven Multi-Speaker Audio Scene Generation from In-the-Wild Priors
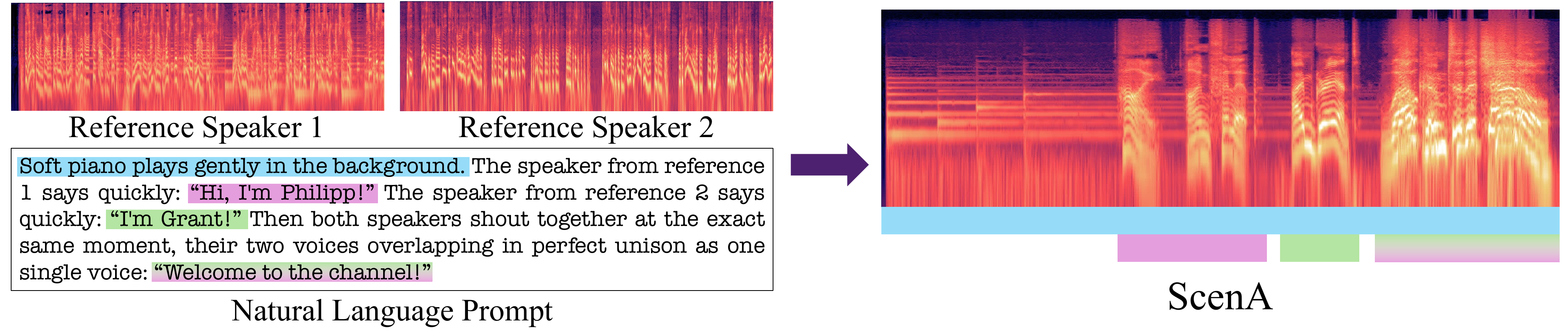
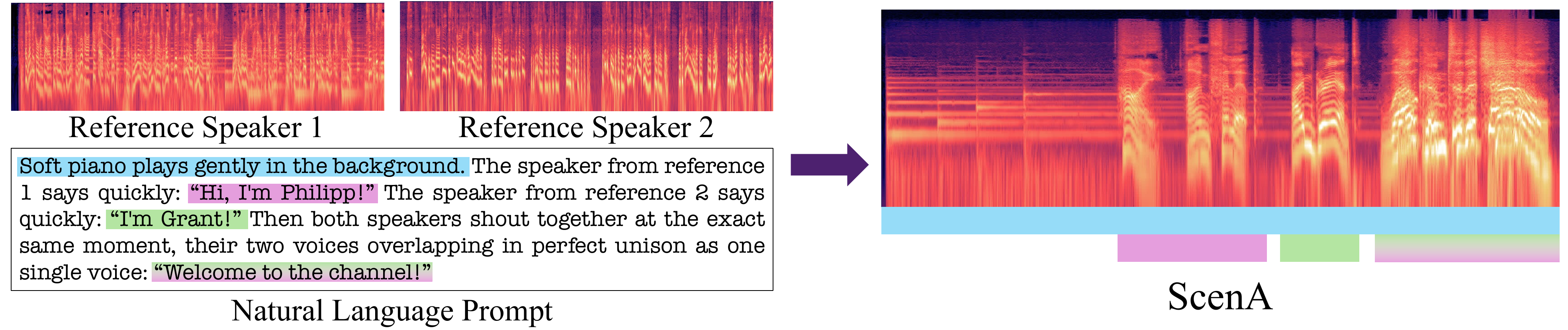
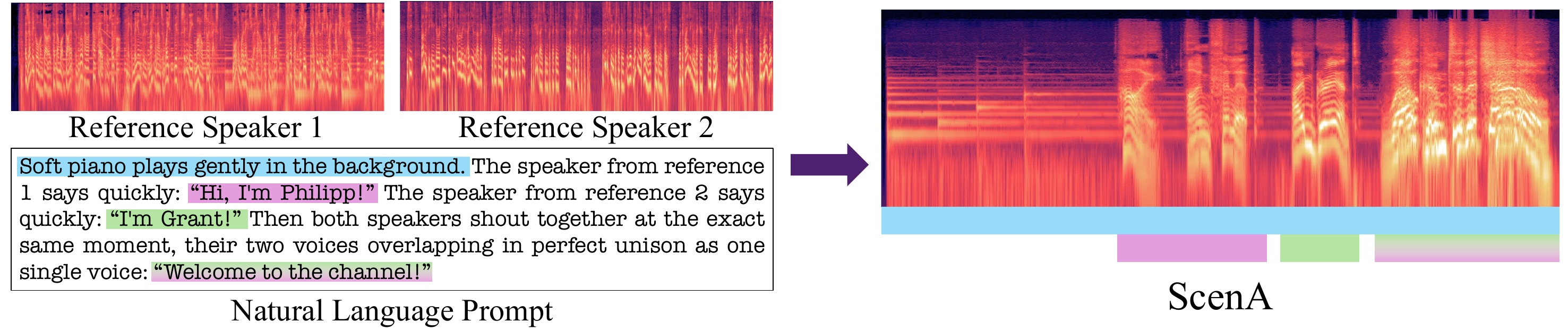
ScenA generates natural multi-speaker audio scenes from reference voices and free-form prompts without turn-based tags. It uses a high-noise training scheme ensuring speaker assignment via text, enabling rich overlapping dialogue, ambient sound, and paralinguistic events from real-world audio.
Demos
These demos showcase ScenA’s ability to generate multi-speaker audio scenes from natural language prompts and multiple reference voices. Notice overlapping speech, spontaneous vocal effects like laughter or coughing, and ambient sounds that create immersive conversations. The system achieves strong voice identity control and emotional expressiveness within complex acoustic settings.
Links
Paper & demos
Abstract
Existing multi-speaker dialogue systems bind speakers to utterances through structured supervision: per-turn tags, multi-stream transcriptions, or learnable speaker embeddings. These systems operate within speech-only pipelines that produce clean vocal sequences without the ambient texture of real conversations. We take a different approach. Our method, ScenA, conditions a text-to-audio flow-matching foundation model, pretrained on large-scale in-the-wild data, directly on multiple reference voices and a free-form natural language prompt that describes an entire multi-speaker audio scene. Leveraging such a foundational model allows us to inherit its capacity for natural, non-studio audio: background noise, room acoustics, overlapping dialogue, and spontaneous paralinguistic events, while adding multi-speaker control without any per-turn structure. Concretely, reference latents are concatenated into the model's token sequence and distinguished by lightweight identity-aware positional encodings. However, we identify a critical obstacle to this approach: the \textit{Reference Shortcut}. During training under standard noise schedules, the model can identify the matching reference by acoustic similarity to the noisy target, bypassing the text prompt entirely. We address this with a high-noise-biased timestep distribution that forces the model to rely on the text prompt for speaker assignment. We evaluate ScenA on the CoVoMix2-Dialogue benchmark, showing that it outperforms existing multi-speaker systems on speaker-binding metrics while generating rich conversational audio with overlapping speech, emotional vocalizations, and ambient sound. Our results demonstrate the advantage of using a general-purpose audio model conditioned on a free-form scene description, rather than passing structured dialog scripts through a speech-only pipeline.
Overview
ScenA is a reference-driven multi-speaker audio generation method that treats a whole conversation, plus its ambient context, as a single scene description rather than as a sequence of independently synthesized turns. The paper’s central claim is that a general-purpose text-to-audio flow-matching backbone, pretrained on large-scale in-the-wild audio, can be adapted to bind multiple reference voices to a free-form natural language prompt without per-turn speaker tags, multi-stream transcripts, speaker embeddings, or identity-preserving adapters.
The important conceptual shift is from a speech-only pipeline that concatenates separately generated utterances to a scene-level generator that can jointly produce overlapping dialogue, paralinguistic events such as laughter and breaths, and background acoustic texture. The method is intentionally minimal: reference latents are concatenated directly with the noisy target latent sequence, and a lightweight slot-specific positional signal tells the transformer which reference is which. The prompt then states, in ordinary language, how the scene unfolds and which reference speaks where.
The paper argues that this simple conditioning design is not enough by itself. During training, the model can exploit a shortcut: if the noisy target still contains enough acoustic information, it can identify the matching reference by similarity and ignore the text prompt entirely. The authors call this the reference shortcut. Their main technical contribution is showing that this shortcut can be diagnosed and broken by shifting the timestep distribution toward high noise, so that the model must use the prompt to assign speakers during training.
- A pretrained audio diffusion transformer is turned into a multi-reference scene generator.
- Reference binding is done with latent concatenation plus a tiny slot-identity embedding, not with dedicated speaker encoders.
- A high-noise-biased timestep schedule is introduced to defeat the reference shortcut.
- The model is evaluated on CoVoMix2-Dialogue and an in-the-wild reference robustness subset.
Architecture and Conditioning
ScenA builds on the LTX-2.3 audio diffusion transformer. The authors retain the audio stream, remove all video-to-audio cross-attention layers, and reuse the VAE, text encoder, and prompt-embedding adapter unchanged. The result is an audio-only transformer that operates on latent token sequences and can generate audio up to 20 seconds long.
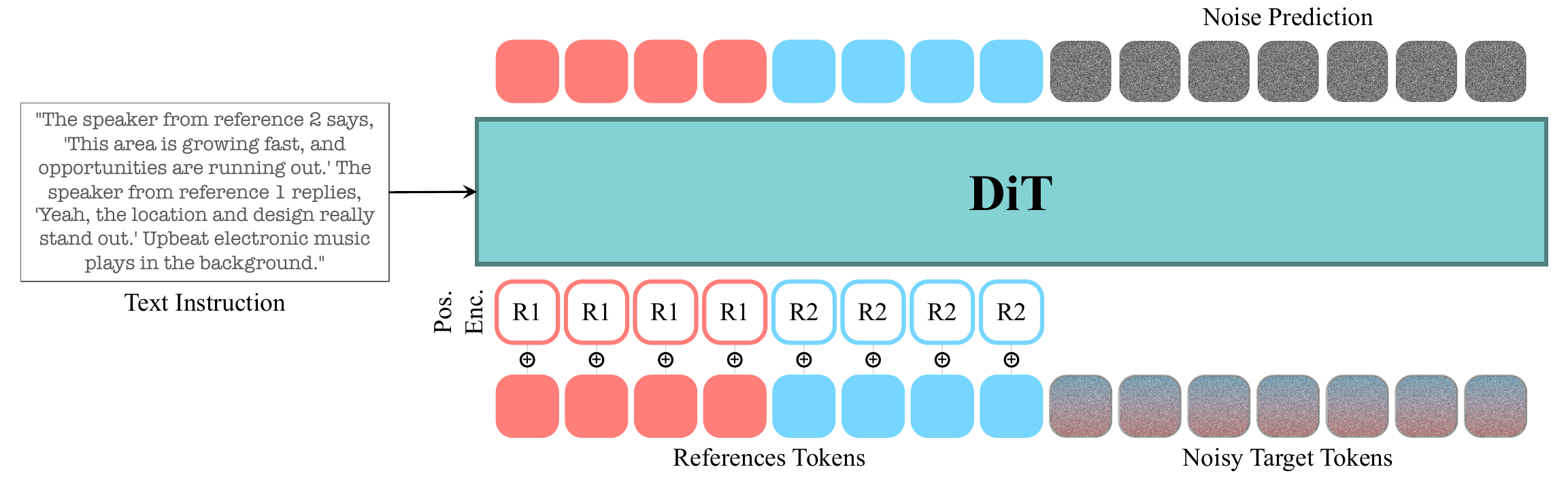
Let the clean target audio be encoded by the VAE as $\mathbf{z}_0 \in \mathbb{R}^{N \times D}$. Each reference clip is encoded by the same VAE into $\mathbf{r}_k \in \mathbb{R}^{N_k \times D}$ for $k = 1, \dots, K$. During training, only the target is noised. At timestep $t$, the noised target is
$$ \mathbf{z}_t = (1-t)\mathbf{z}_0 + t\boldsymbol{\epsilon}, \qquad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}). $$
The full self-attention input is the concatenation
$$ \mathbf{z}_{\text{input}} = [\mathbf{z}_t;\mathbf{r}_1;\ldots;\mathbf{r}_K]. $$
All tokens participate in self-attention, so the model can route information between the target and all references directly. The text prompt conditions the transformer through cross-attention and describes the entire scene holistically: who speaks, what is said, what is happening in the environment, and any paralinguistic behavior.
To distinguish references from one another, the paper uses a learned slot embedding $e_k$ for each reference slot. This embedding is broadcast across the tokens of $\mathbf{r}_k$ and added after projection into the transformer hidden space:
$$ \mathbf{r}_k \leftarrow \mathbf{r}_k + e_k. $$
The target receives no additive slot embedding. This keeps the architecture essentially unchanged while giving the model a minimal signal for reference identity. The paper also studies an alternative RoPE-based slot encoding, plus a baseline with no slot encoding at all.
The intended use of the prompt is indexed rather than content-based. Instead of requiring each speaker reference to be linguistically describable, the prompt can simply say “reference 1” and “reference 2.” That matters for dialogue, where the references may share similar content or may not be individually describable in words.
At inference, generation starts from pure noise and iteratively denoises. The same reference concatenation and slot encoding are used, and the prompt alone specifies how the references should be assigned to conversational roles. The paper emphasizes that no per-segment supervision, special binding tokens, spatial layouts, or identity adapters are introduced.
Flow-Matching Objective and the Reference Shortcut
The model is trained with rectified flow matching. The target latent is interpolated between the clean sample and noise, and the transformer predicts the velocity field that maps noise back toward data. The loss is
$$ \mathcal{L} = \mathbb{E}_{t,\mathbf{z}_0,\boldsymbol{\epsilon}}\left[\lVert f_\theta(\mathbf{z}_t, t, \mathbf{c}) - \mathbf{v} \rVert^2\right], $$
with
$$ \mathbf{v} = \boldsymbol{\epsilon} - \mathbf{z}_0. $$
The key insight is that, under standard timestep sampling, the model can solve the binding problem in a cheaper way than learning to use the text. If the noisy target still preserves enough acoustic identity, then the target tokens can match the correct reference by similarity through self-attention, without consulting the prompt. This is the reference shortcut.
The paper frames the shortcut as a two-path problem. The intended path requires the text to point to “reference $k$,” the slot embedding to identify the corresponding reference tokens, and self-attention to connect the noisy target to the right reference. The shortcut path bypasses text: the noised target remains similar enough to the clean reference that self-attention can match them directly.
To quantify when this is possible, the authors train a probe on frozen backbone features. The probe takes a noised target $\mathbf{z}_t$ and two candidate references, one correct and one distractor, and predicts which reference matches the target. It uses the first 8 of the 48 transformer blocks plus a small MLP head. The probe is trained for 10,000 steps with batch size 128 and evaluated at 50 evenly spaced noise levels on 256 held-out examples per noise level.
The probe results show that the shortcut is available across a wide range of timesteps: accuracy is at least 98% for $t \leq 0.58$, at least 90% through about $t \approx 0.86$, and still around 75% at $t = 0.96$. Accuracy only collapses to chance as $t \to 1$. This is exactly the opposite of what the model needs at inference, where the first denoising steps start from pure noise and the prompt must determine the global binding before any acoustic structure exists.
![Reference-shortcut probe. Blue: probe binary-classification accuracy on the held-out set, measured at 50 evenly spaced target noise levels t; the gray dashed line marks chance (50%). Light curves show two training-time timestep distributions on the same t axis---our Beta+Uniform mixture (red) and a logit-normal distribution centered around t = 0.8 (green)---each independently rescaled to a fixed peak height. The small numbers above (red) and below (green) each blue marker give the fraction of training samples drawn at or above that noise level under each distribution, i.e., P[T >= t].](https://akapulu-public-assets.s3.us-west-1.amazonaws.com/blogs/research-digest/p/2606.19325/arxiv/fig/_preview/images__probe_accuracy.png)
The practical consequence is that a standard logit-normal or mildly high-noise-shifted schedule still spends most of its mass in the regime where similarity-based matching works. The model therefore learns the shortcut during training and then fails at inference, when the shortcut is unavailable.
High-Noise-Biased Timestep Distribution
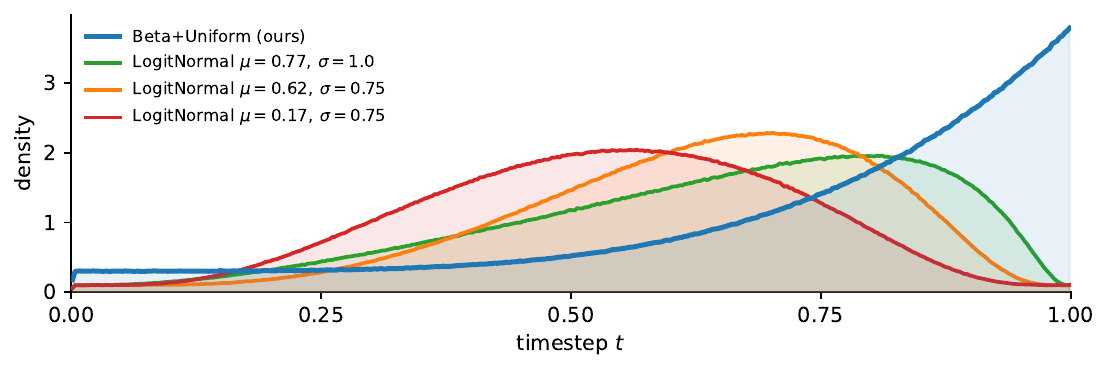
To force the model to learn prompt-based binding, the paper replaces the standard logit-normal sampling distribution with a mixture that puts more mass into the high-noise tail:
$$ p(t) = (1-\lambda)\,\mathrm{Beta}(t;\alpha,1) + \lambda\,\mathrm{Uniform}(t;\epsilon,1). $$
The Beta component concentrates samples toward large $t$, where the target carries little usable acoustic identity and the prompt is the only viable binding signal. The Uniform component retains some coverage across the rest of the range so the model still learns fine details at lower noise. The paper reports that simply shifting the logit-normal further upward is not enough: the shortcut region is wide, and aggressive shifts that fully close the shortcut can starve the model of low-noise training signal. The mixture is presented as a better compromise.
Ablations later in the paper show that speaker-binding metrics improve monotonically as more training mass is moved toward high noise. This is one of the paper’s central empirical findings: binding quality is controlled less by architectural complexity than by whether the training distribution prevents the model from exploiting the shortcut.
Dataset Construction and Training Setup
The training data is a multi-reference dataset in which each example contains a target clip, $K$ reference clips, and a caption explaining how the target scene is related to the references. The target is a multi-speaker conversational audio clip that can include both speech and non-speech sounds. Each reference is a distinct single-speaker clip. This lets the caption describe a full conversational scene while grounding each voice in a specific reference.
The paper constructs this dataset through a multi-stage pipeline. First, speaker embeddings are extracted from each target clip with a diarization pipeline. These embeddings are used to search for separate reference clips in which each speaker appears. Only clips for which every speaker has a matching reference are kept as target clips. This ensures that the references and the target speakers are aligned.
Second, the target is captioned independently, without conditioning on the references. The resulting intermediate caption is meant to be a grounded scene description with fewer hallucinations than a direct reference-conditioned caption would have. Third, a final caption is generated conditioned on the reference clips, the intermediate caption, and speaker-level timestamps from diarization. The timestamp supervision helps the captioner describe who speaks when, while the intermediate caption keeps the scene description faithful to the actual audio.
This dataset construction is important because the paper is not training on per-turn transcripts with explicit speaker tags. Instead, the supervision is assembled from diarization, reference matching, and captioning into a scene-level prompt that naturally mentions “reference 1,” “reference 2,” and so on.
For training, the authors fine-tune the LTX-2.3 backbone with up to $K_{\max} = 3$ references per example. Reference clips can be any length up to the model’s 20-second maximum. The target is the only element noised during training; the references remain clean. Training uses AdamW with $\beta_1 = 0.9$, $\beta_2 = 0.95$, $\epsilon = 10^{-8}$, weight decay $0.01$, and a peak learning rate of $10^{-4}$ after a 1,000-step linear warmup. An exponential moving average with decay $0.9999$ is maintained, and evaluation uses the EMA weights.
The run length is 20,000 steps, with global batch size 128 on 16 NVIDIA GB200 GPUs, taking about 24 hours. This is a relatively modest adaptation budget for a scene-generation capability that would otherwise require much more elaborate binding machinery.
Two auxiliary training-time augmentations are also used:
- Adversarial reference injection: empty reference slots are filled with distractor references that are not mentioned in the prompt, forcing the model to bind according to the text rather than copy from whatever reference happens to be present.
- Slot-shuffle augmentation: the order of the references in the self-attention sequence is permuted, and the prompt is rewritten so that the reference indices stay aligned. A curriculum is used: no shuffling for the first 10,000 steps, then shuffling afterward.
The default recipe uses both augmentations. The paper argues that these augmentations do not replace the timestep fix; they complement it by reducing positional bias and further tightening the link between text mentions and reference slots.
Experimental Evaluation
The main evaluation benchmark is CoVoMix2-Dialogue-20s, derived from the public CoVoMix2-Dialogue test set. The full benchmark pairs 1,000 DailyDialog two-speaker transcripts with reference clips from LibriSpeech test-clean. The paper restricts to the 291 dialogs whose target audio fits within the model’s 20-second budget. The same speaker-gender mix and reference-similarity distribution are preserved in the filtered subset. Each example is rendered into the paper’s standard prompt format using “reference 1” and “reference 2.”
To test robustness to non-studio conditions, the authors build CoVoMix2-Dialogue-WildRef by keeping the dialogs fixed and replacing the clean LibriSpeech prompts with 30 in-the-wild English reference clips that include crowd noise, background music, street ambience, wind, and cartoon voices. Fifty dialogs are re-paired, producing 100 examples total, with each wild clip used at least three times.
The evaluation metrics are:
- WER: word error rate from Whisper-large-v3.
- cpWER: speaker-aware WER with diarization and best-permutation alignment, so speaker attribution errors count.
- SIM-O: cosine similarity between generated and reference speaker embeddings.
- cpSIM: a strict per-speaker version of embedding similarity, more sensitive to speaker-binding correctness.
- ACC: the fraction of words whose generated speaker label matches the prompt label after forced alignment and per-segment speaker assignment.
- UTMOS and SQUIM: general speech/audio quality estimators.
Comparison to multi-speaker dialogue baselines
ScenA is compared against MOSS-TTSD, VibeVoice-7B, VibeVoice-1.5B, ZipVoice-Dialog, and Dia using the public default settings of each system. On CoVoMix2-Dialogue-20s, ScenA achieves the best binding-aware scores and also the best word error rate, while remaining competitive on general audio-quality measures.
| System | cpWER ↓ | cpSIM ↑ | ACC ↑ | WER ↓ | SIM-O ↑ | UTMOS ↑ | SQUIM ↑ |
|---|---|---|---|---|---|---|---|
| MOSS-TTSD | 0.232 | 0.547 | 0.855 | 0.109 | 0.443 | 3.76 | 4.28 |
| VibeVoice-7B | 0.206 | 0.527 | 0.821 | 0.044 | 0.451 | 3.58 | 4.28 |
| VibeVoice-1.5B | 0.212 | 0.503 | 0.830 | 0.050 | 0.423 | 3.56 | 4.27 |
| ZipVoice-Dialog | 0.176 | 0.538 | 0.847 | 0.032 | 0.446 | 3.57 | 4.34 |
| Dia | 0.303 | 0.339 | 0.757 | 0.133 | 0.312 | 2.69 | 4.09 |
| ScenA | 0.145 | 0.567 | 0.866 | 0.020 | 0.451 | 3.44 | 4.32 |
On the clean-reference benchmark, ScenA has the best cpWER, cpSIM, ACC, and WER, ties for best SIM-O, and is near the top on SQUIM. The paper notes that UTMOS is slightly lower than MOSS-TTSD, which the authors attribute to the in-the-wild acoustic profile inherited from the LTX-2.3 backbone; SQUIM is still strong.
Robustness to in-the-wild references
The WildRef benchmark is the more revealing test for the paper’s thesis, because it stresses the model with noisy and diverse reference clips rather than clean studio-style speakers. The paper reports that all baselines lose reference similarity substantially, with cpSIM dropping by roughly 0.15 absolute and falling below 0.40 for every baseline, while ScenA remains above 0.42. ScenA retains the best cpSIM, SIM-O, WER, and SQUIM, and stays close to the leader on cpWER and ACC.
| System | cpWER ↓ | cpSIM ↑ | ACC ↑ | WER ↓ | SIM-O ↑ | UTMOS ↑ | SQUIM ↑ |
|---|---|---|---|---|---|---|---|
| MOSS-TTSD | 0.156 | 0.390 | 0.844 | 0.059 | 0.295 | 3.45 | 4.21 |
| VibeVoice-7B | 0.172 | 0.386 | 0.841 | 0.045 | 0.317 | 2.56 | 2.91 |
| VibeVoice-1.5B | 0.202 | 0.365 | 0.826 | 0.089 | 0.293 | 2.33 | 2.85 |
| ZipVoice-Dialog | 0.173 | 0.396 | 0.825 | 0.038 | 0.315 | 3.20 | 4.19 |
| Dia | 0.272 | 0.278 | 0.752 | 0.086 | 0.256 | 2.45 | 3.92 |
| ScenA | 0.167 | 0.424 | 0.819 | 0.022 | 0.348 | 3.30 | 4.28 |
Human preference evaluation
The paper also runs a blind side-by-side A/B preference test on a mixture of CoVoMix2-Dialogue-20s and WildRef items. Evaluators hear the original speakers, then two synthesized dialog versions, and choose which dialog better matches the voices and sounds more natural. ScenA is preferred over every baseline at conventional significance levels.
| Opponent | ScenA preferred |
|---|---|
| ZipVoice-Dialog | 84.6% |
| Dia | 74.2% |
| VibeVoice-7B | 68.3% |
| MOSS-TTSD | 59.8% |
Ablations and Diagnostic Studies
The ablation section is important because it separates what actually matters from what is merely convenient. The diagnosis is consistent across experiments: architecture alone is not enough, and the training recipe must be designed around the reference shortcut.
Noise schedule ablation
The paper compares the Beta+Uniform schedule to three logit-normal schedules that span the range used in standard flow-matching practice. The first logit-normal is closest to typical audio FM training, while the others shift progressively toward higher noise. Binding-aware metrics improve monotonically as the schedule shifts toward more high-noise mass. This supports the paper’s claim that the shortcut is a training-distribution problem.
| Schedule | cpWER ↓ | cpSIM ↑ | ACC ↑ | WER ↓ | SIM-O ↑ | UTMOS ↑ | SQUIM ↑ |
|---|---|---|---|---|---|---|---|
| Logit-normal $\mu = 0.17, \sigma = 0.75$ | 0.167 | 0.503 | 0.830 | 0.019 | 0.402 | 3.64 | 4.29 |
| Logit-normal $\mu = 0.62, \sigma = 0.75$ | 0.158 | 0.500 | 0.850 | 0.019 | 0.402 | 3.65 | 4.30 |
| Logit-normal $\mu = 0.77, \sigma = 1.0$ | 0.154 | 0.549 | 0.859 | 0.018 | 0.438 | 3.54 | 4.30 |
| ScenA (Beta+Uniform) | 0.145 | 0.567 | 0.866 | 0.020 | 0.451 | 3.44 | 4.32 |
The pattern is straightforward: the more the training distribution forces the model into the high-noise regime, the better it learns to use the text prompt to decide which reference speaks where. The final Beta+Uniform mixture is not dramatically better on general speech quality, but it is clearly best on binding.
Reference slot encoding ablation
The paper compares three ways to encode reference slots: no positional signal, a RoPE-based slot dimension, and the default additive embedding. The no-positional baseline collapses on binding, while the RoPE variant recovers most of the performance but still trails the additive method on the strictest speaker-fidelity metrics. This shows that some explicit slot signal is necessary, but the exact form is not critical as long as it gives the model a stable way to tell references apart.
| Encoding | cpWER ↓ | cpSIM ↑ | ACC ↑ | WER ↓ | SIM-O ↑ | UTMOS ↑ | SQUIM ↑ |
|---|---|---|---|---|---|---|---|
| No positional | 0.232 | 0.403 | 0.513 | 0.018 | 0.333 | 3.60 | 4.28 |
| RoPE-based slot dimension | 0.181 | 0.547 | 0.835 | 0.020 | 0.449 | 3.58 | 4.32 |
| Additive slot embedding | 0.145 | 0.567 | 0.866 | 0.020 | 0.451 | 3.44 | 4.32 |
The no-positional baseline is especially telling: the model can still produce coherent speech, but the binding signal becomes nearly random for two speakers. In other words, good acoustics do not imply correct speaker assignment.
Training recipe ablation
The auxiliary augmentations are also ablated. Removing adversarial reference injection hurts speaker fidelity substantially, while leaving the shuffling augmentation on from the start causes collapse because the model never gets a stable initial slot-to-speaker mapping. A no-shuffle variant is competitive, but the paper’s curriculum wins on the strictest binding metrics in the default setting and is intended to improve robustness under positional perturbations.
| Recipe | cpWER ↓ | cpSIM ↑ | ACC ↑ | WER ↓ | SIM-O ↑ | UTMOS ↑ | SQUIM ↑ |
|---|---|---|---|---|---|---|---|
| No adversarial references | 0.157 | 0.467 | 0.859 | 0.018 | 0.368 | 3.52 | 4.29 |
| Always shuffle | 0.232 | 0.402 | 0.502 | 0.019 | 0.334 | 3.68 | 4.26 |
| No shuffle | 0.131 | 0.491 | 0.886 | 0.018 | 0.380 | 3.68 | 4.28 |
| Default ScenA | 0.145 | 0.567 | 0.866 | 0.020 | 0.451 | 3.44 | 4.32 |
The interpretation the authors give is nuanced. Adversarial references specifically improve the model’s reliance on text instead of on accidental sequence contents, while shuffle curriculum prevents a premature destabilization of the slot mapping. The recipe is therefore less about a single best number and more about preserving a stable binding curriculum.
Qualitative Capabilities
Beyond the standard two-speaker transcript setting, the paper highlights generation regimes that are difficult for turn-by-turn TTS pipelines. Because the model produces an entire scene in a single pass, the prompt can request overlapping speech, scene-level ambience, mid-utterance interruptions, and spontaneous paralinguistic events. These are not separate post-processing steps; they are generated jointly with the dialog.
The appendix shows spectrogram examples for two such cases. One is a rapid-fire quiz that is closed by a non-speech buzzer. The other is a scene-level prompt with a mid-utterance ambient interruption and paralinguistic events. These examples are important because they illustrate the practical consequence of scene-level conditioning: the output is not merely a clean transcript read aloud by voices, but an integrated audio event.
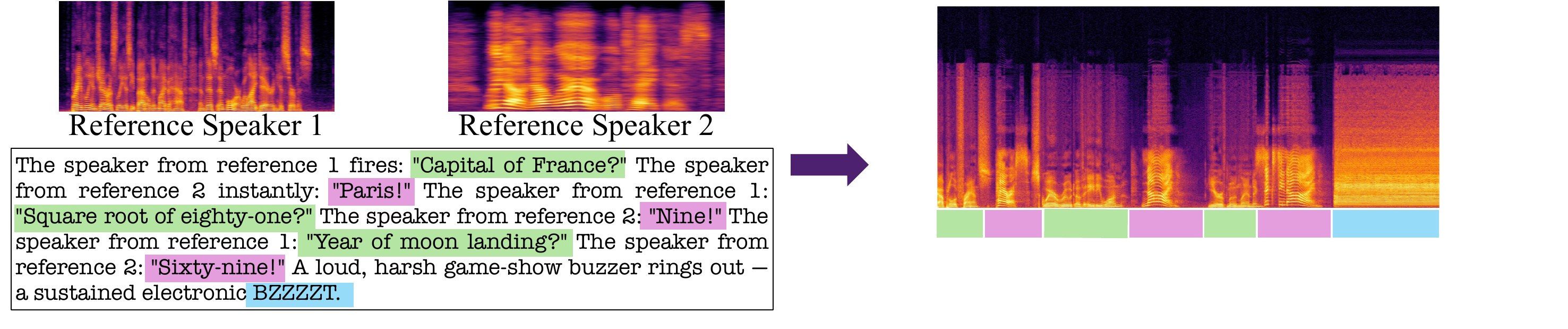
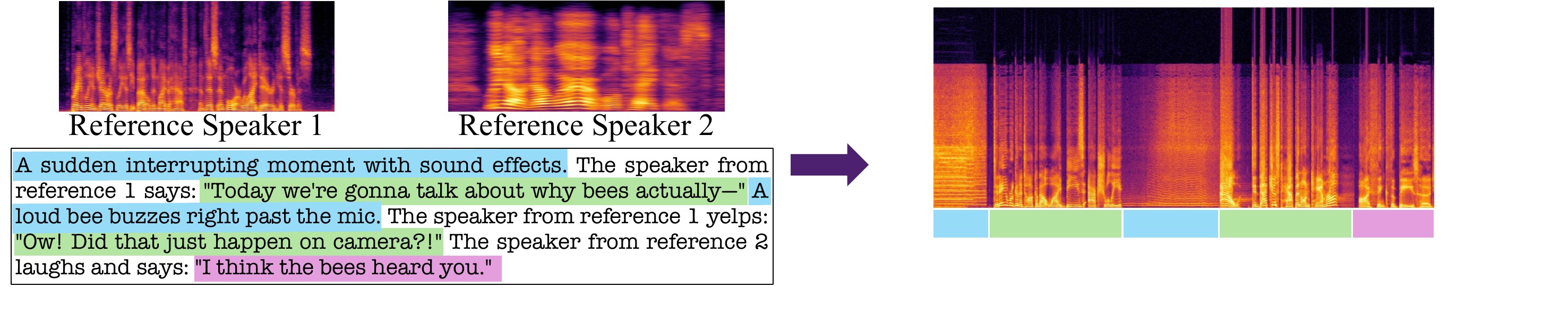
The paper also notes that the prompt format supports multiple references per speaker, which can help characterize a voice more richly. This capability is a direct consequence of the reference-latent concatenation design: the scene prompt can name a reference index, and that reference can itself be backed by more than one clip during synthesis.
Limitations and Scope
The paper is explicit about the practical limits inherited from the backbone. First, generation is capped at 20 seconds. Second, the model is limited to $K_{\max} = 3$ reference speakers, and the self-attention sequence length grows linearly with the number of references. The authors argue that these are soft constraints rather than fundamental barriers, especially for an audio-only backbone where token counts are much lower than in video.
A third limitation is more fundamental to flow matching: the generation duration must be set before sampling, so duration control still relies on heuristics or user input. This is not unique to ScenA, but it constrains how the system can be deployed in interactive settings.
The discussion section also generalizes the reference-shortcut diagnosis beyond audio. The authors argue that any reference-conditioned flow-matching system with clean references concatenated to a noised target can be vulnerable when the target remains similarity-discriminable at moderate noise and the training schedule over-samples that regime. They suggest that the high-noise-biased fix may transfer to image and video reference conditioning, though they do not validate that claim experimentally here.
Technical Takeaways
- ScenA reframes multi-speaker generation as a single audio-scene synthesis problem conditioned on a free-form prompt plus multiple reference clips.
- The architecture is deliberately minimal: concatenate clean reference latents with the noised target, add a slot-identity signal, and let the transformer learn the binding.
- The main failure mode is the reference shortcut, where the model uses acoustic similarity rather than the prompt to match references to the target.
- A high-noise-biased timestep distribution is the key fix, because it forces the model to rely on the prompt during the part of denoising that determines global speaker assignment.
- On CoVoMix2-Dialogue-20s and WildRef, ScenA leads the binding metrics and is preferred by human listeners over all compared baselines.
- The method’s strongest qualitative advantage is that it can generate conversational audio with overlapping speech and ambient sound, instead of just clean concatenated utterances.