Code-Mixing Guided TTS Alignment
Improving Code-Switching ASR with Code-Mixing Guided Synthetic Speech
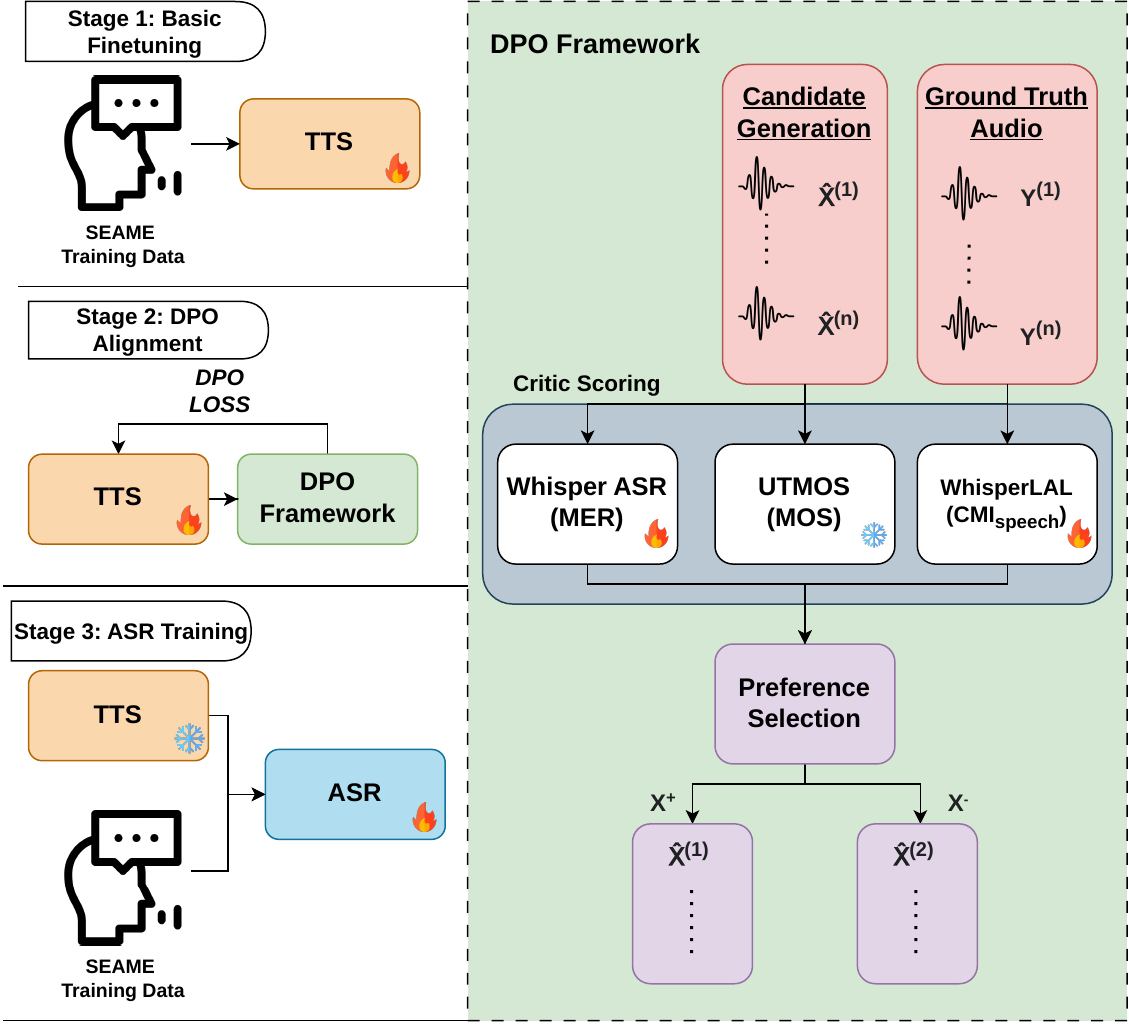
Introduces a preference-learning framework for synthetic speech generation that preserves code-switching patterns in conversational Mandarin-English. By incorporating a speech-based code-mixing metric into TTS training, it improves language-boundary consistency to enhance downstream code-switching ASR performance.
Links
Paper & demos
Abstract
Code-switch (CS) Automatic Speech Recognition (ASR) remains challenging due to limited availability of high quality CS text-speech pairs for training. Although synthetic data augmentation via Text-to-speech (TTS) has been explored, existing CS TTS approaches primarily optimise reconstruction fidelity and do not explicitly enforce language-boundary consistency, thereby limiting their effectiveness for CS ASR augmentation. This paper proposes a code-mixing guided preference-learning framework that steers synthetic speech generation toward improved code-switching fidelity using the Code Mixing Index (CMI). Experiments on the SEAME Mandarin-English conversational corpus demonstrate that the proposed method enhances the utility of synthetic data for ASR fine-tuning. Specifically, when fine-tuning Whisper Large, the proposed approach reduces Mixed Error Rate (MER) from 12.1%/17.8% to 8.9%/14.2% on the DevMAN and DevSGE sets, respectively.
Introduction and Problem Setting
This paper targets code-switching automatic speech recognition (CS ASR), specifically conversational Mandarin-English speech in the SEAME corpus. The core difficulty is not simply that data are scarce, but that high-quality paired CS text-speech data are scarce: the model must learn both acoustic variability and the correct alternation of languages inside an utterance. The authors argue that standard ASR training is weakened by three interacting issues: language alternation itself, cross-lingual phonetic interference, and informal conversational styles. Large pretrained ASR systems such as Whisper still struggle to generalize robustly in this setting when trained on limited transcribed CS speech.
To address data scarcity, the paper uses synthetic speech augmentation, but makes a key observation: prior CS TTS augmentation approaches mostly optimize for reconstruction fidelity, intelligibility, or perceptual naturalness, and do not explicitly enforce language-boundary consistency. In other words, a synthetic utterance can sound good while still getting the code-switching structure wrong. The main contribution is therefore a preference-learning framework for TTS that directly incorporates a code-mixing signal into data generation, so that the synthetic speech used for ASR fine-tuning better preserves the intended alternation pattern.
The paper’s central idea is to extend the text-based Code Mixing Index (CMI) into the speech domain via pseudo frame-level language labels. This yields a speech-level metric, $mathrm{CMI}_{\text{speech}}$, which can be used as an explicit critic during Direct Preference Optimization (DPO) for TTS. The claimed payoff is downstream: synthetic speech aligned not only with intelligibility and naturalness, but also with code-switching structure, improves ASR on SEAME.
Key Contributions
- A speech-domain code-mixing metric, $mathrm{CMI}_{\text{speech}}$, defined over pseudo frame-level language labels rather than discrete text tokens.
- A multi-critic DPO framework for CS TTS that combines intelligibility, perceptual quality, and code-switching fidelity.
- A preference-pair construction strategy that ranks synthetic candidates by normalized critic scores and uses threshold-based filtering to stabilize alignment.
- Demonstrated improvements on SEAME when synthetic data generated by the aligned TTS is used to fine-tune downstream ASR, including reductions in Mixed Error Rate (MER) for both Whisper Large v3 and a CTC-based Conformer.
Method Overview
The method is a three-stage pipeline: (1) fine-tune a multilingual TTS model on SEAME code-switched speech, (2) apply DPO alignment using multiple automatic critics, and (3) use the resulting TTS model to synthesize additional CS data for ASR training. The TTS backbone used in the experiments is CosyVoice2, and the downstream ASR back end used for primary evaluation is Whisper Large v3.
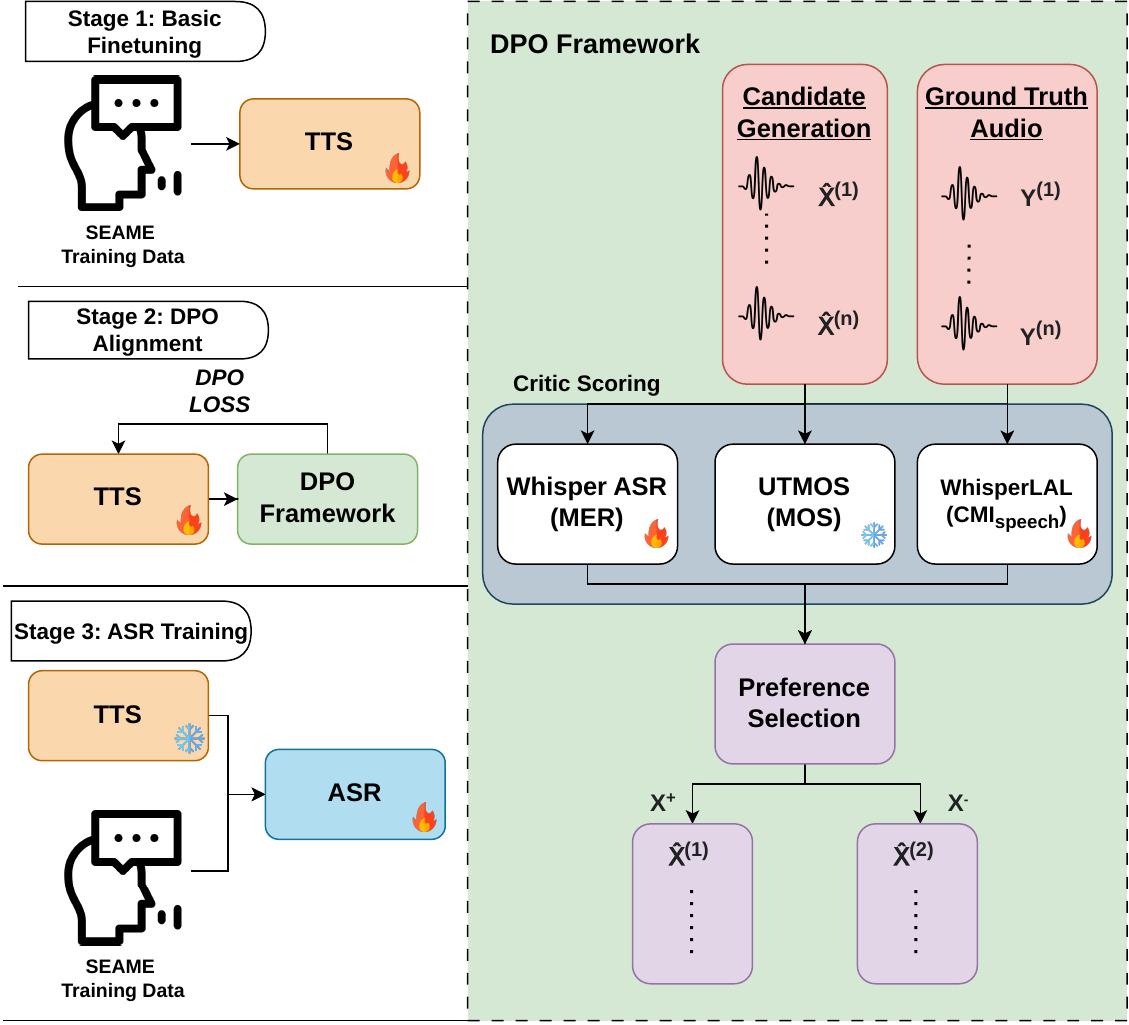
1. Preference Learning with DPO
The paper uses Direct Preference Optimization (DPO) as the optimization framework for TTS alignment. Given a transcript $A$, the model generates a preferred candidate $\hat{X}^+$ and a dis-preferred candidate $\hat{X}^-$ under the same conditioning input. DPO then maximizes the relative preference margin between the trainable TTS model $\pi_\theta$ and a frozen reference model $\pi_{\mathrm{ref}}$:
$$ \mathcal{L}_{\mathrm{DPO}} = -\mathbb{E}\left[ \log \sigma \left( \beta\log \frac{\pi_\theta(\hat{X}^{+}\mid A)}{\pi_{\mathrm{ref}}(\hat{X}^{+}\mid A)} -\beta\log \frac{\pi_\theta(\hat{X}^{-}\mid A)}{\pi_{\mathrm{ref}}(\hat{X}^{-}\mid A)} \right) \right]. $$
Here, $\beta$ controls the strength of the preference margin, and the reference model stabilizes optimization. The paper emphasizes that DPO is attractive because it avoids a separate reward model and reinforcement-learning loop, while still allowing task-specific signals to shape generation.
2. Acoustic-level Code-Mixing Metric
The paper extends CMI from text to speech by first obtaining pseudo frame-level language labels from the TTS/ASR alignment pipeline. The authors follow a language-alignment strategy in which averaged cross-attention from the last decoder layer provides a frame-to-token alignment, enabling token-level language identities to be projected onto encoder frames. This produces acoustic frame-level language labels without manual alignment or forced alignment.
Using those pseudo labels, the speech-level code-mixing index for an utterance $u$ is defined as:
$$ \mathrm{CMI}_{\text{speech}}(u) = \frac{T(u) - \max_{k \in \mathcal{L}} T_k(u)}{T(u)}, $$
where $T(u)$ is the total number of acoustic frames in the utterance, $T_k(u)$ is the number of frames assigned to language $k$, and $\mathcal{L}$ is the set of languages present in the utterance. Intuitively, the quantity measures how much of the utterance is not in the dominant language; higher values indicate stronger acoustic code-mixing.
To compare synthetic and real speech, the paper defines:
$$ \Delta_{\text{CMI}} = \left| \mathrm{CMI}_{\text{speech}}(\hat{X}) - \mathrm{CMI}_{\text{speech}}(y) \right|, $$
where $\hat{X}$ is the synthetic utterance and $y$ is the corresponding ground-truth utterance. Lower $\Delta_{\text{CMI}}$ means better preservation of the code-switching proportion and structure in the synthetic speech.
3. Multi-critic Candidate Scoring and Pair Construction
For each transcript and prompt, the fine-tuned TTS model samples $N$ synthetic candidates stochastically. The candidates differ in prosody and acoustic realization because of sampling randomness and temperature. Each candidate is scored by three critics:
- MER: a downstream ASR-based intelligibility score, where lower is better;
- UTMOS: a non-intrusive predicted MOS score, where higher is better;
- $\Delta_{\text{CMI}}$: the absolute mismatch between synthetic and reference code-mixing structure, where lower is better.
The paper normalizes each critic to a 0-to-1 scale and combines them into a ranking score:
$$ R(\hat{X}) = \lambda\tilde{S}_{\text{UTMOS}}(\hat{X}) - \gamma\tilde{S}_{\text{MER}}(\hat{X}) - \nu\tilde{S}_{\Delta\text{CMI}}(\hat{X}), $$
where the tilde indicates normalized scores and $\lambda,\gamma,\nu \ge 0$ are weights. Preference pairs are then formed by ranking candidates for each transcript and pairing the highest-ranked candidate with the lowest-ranked candidate. This creates a maximally contrasted supervision signal for DPO.
To improve stability, the paper filters out unreliable pairs when the preferred candidate has MER greater than $20\%$, UTMOS lower than $2.5$, or a $\mathrm{CMI}_{\text{speech}}$ difference exceeding $20\%$. The authors describe this as threshold-based filtering to avoid unstable alignment targets.
Experimental Setup
All experiments are conducted on the SEAME corpus, a benchmark for spontaneous Mandarin-English conversational code-switching speech. The corpus contains approximately 192 hours of speech from over 150 bilingual speakers in Singapore and Malaysia. The speech is informal and includes both intra-sentential and inter-sentential code-switching. Importantly, the paper states that both TTS training text and prompts are drawn only from SEAME, with no external text data.
TTS Training
The TTS backbone is CosyVoice2, a multilingual auto-regressive LLM-based TTS system. The model is first fine-tuned on SEAME to adapt it to conversational Mandarin-English speech. The fine-tuning uses AdamW with a learning rate of $2\times10^{-4}$ and a linear warm-up schedule, for about 50k steps, with a batch size of 4 utterances. Early stopping is applied based on validation loss. The fine-tuned model is then used for DPO alignment and for synthesizing augmentation data.
ASR Training
The downstream ASR system is Whisper Large v3. It is fine-tuned on SEAME with and without synthetic speech augmentation. The optimizer is Adam with learning rate $1\times10^{-5}$, batch size 1 utterance per A40 GPU, and training continues until convergence. The paper explicitly keeps the training and decoding configurations identical across augmentation strategies, and also keeps the total duration of real plus synthetic speech consistent for fair comparison.
Scoring Models
- MER scoring: a SEAME fine-tuned Whisper Large v3 ASR model decodes synthesized speech and compares it to the reference transcript.
- UTMOS scoring: a pretrained UTMOS predictor estimates speech quality without human annotation.
- $\Delta_{\text{CMI}}$ scoring: a SEAME-based fine-tuned Whisper model with language alignment loss provides pseudo frame-level language labels from synthesized speech, which are then used to compute $\mathrm{CMI}_{\text{speech}}$.
Results: TTS Alignment and Speech Quality
The first results table evaluates how progressively adding critics changes the quality of the synthesized speech. The baseline is plain CosyVoice fine-tuning; then DPO is applied with MER only, MER + UTMOS, and MER + UTMOS + $\Delta_{\text{CMI}}$.
| Model / Reward | UTMOS ↑ | MER ↓ | $\Delta_{\text{CMI}}$ ↓ |
|---|---|---|---|
| CosyVoice | 3.1 | 16.2 | 28.1 |
| DPO with MER | 3.2 | 14.9 | 25.7 |
| DPO with MER + UTMOS | 3.8 | 13.2 | 21.9 |
| DPO with MER + UTMOS + $\Delta_{\text{CMI}}$ | 3.8 | 10.3 | 16.1 |
The trend is clear: MER-only DPO improves intelligibility but only modestly reduces the code-mixing discrepancy. Adding UTMOS improves perceptual quality substantially and continues to reduce MER. The strongest effect comes from incorporating $\Delta_{\text{CMI}}$, which yields the largest reduction in code-switch mismatch while also producing the lowest MER, without sacrificing UTMOS. The authors interpret this as evidence that explicitly aligning acoustic language-mixing structure makes synthetic speech more useful for CS ASR.
Results: Downstream ASR Fine-tuning
The central downstream evaluation asks whether better TTS actually translates into better ASR. The paper reports Mixed Error Rate on SEAME DevMAN and DevSGE for two ASR back ends: Whisper ASR and a CTC-based Conformer. The augmentation setting uses 100 hours of real SEAME training speech plus 100 hours of synthetic speech for the CosyVoice-based systems.
| Train Configuration | DevMAN | DevSGE |
|---|---|---|
| Whisper ASR | ||
| Real (100h) | 12.1 | 17.8 |
| + CosyVoice | 10.1 | 16.0 |
| + DPO (UTMOS, MER) | 9.6 | 15.1 |
| + DPO (UTMOS, MER, $\Delta_{\text{CMI}}$) | 8.9 | 14.2 |
| CTC-based Conformer | ||
| Real (100h) | 16.8 | 23.6 |
| + CosyVoice | 16.1 | 22.8 |
| + DPO (UTMOS, MER) | 15.8 | 22.3 |
| + DPO (UTMOS, MER, $\Delta_{\text{CMI}}$) | 15.4 | 21.9 |
For Whisper, adding plain synthetic speech already improves MER over the 100-hour real-data baseline, showing that the generated data is useful augmentation. DPO further improves the results, and the full multi-critic version performs best, reaching 8.9\% MER on DevMAN and 14.2\% on DevSGE. The same ordering holds for the CTC-based Conformer, where the full method achieves 15.4\% and 21.9\%. The consistent gains across two architectures support the authors’ claim that the benefit is not specific to Whisper.
Ablation and Qualitative Analysis
The paper includes a qualitative table showing example synthesized outputs under different training strategies. The examples illustrate a recurring failure mode of plain fine-tuning: English words are often acoustically or linguistically shifted into Mandarin-like forms, and language boundaries become unstable. DPO with MER and UTMOS improves the utterances overall, but some cross-language substitutions remain. Adding $\Delta_{\text{CMI}}$ restores the intended language segments more faithfully, with examples that better preserve the original code-switching pattern.
The qualitative analysis is consistent with the quantitative results: reward signals based only on recognition and perceptual naturalness are not sufficient to constrain code-switch structure. The additional speech-level code-mixing critic addresses this gap.
| Observed behavior | Interpretation |
|---|---|
| Plain fine-tuning | Some English words are shifted into Mandarin-like realizations; language boundaries are unstable. |
| DPO with MER and UTMOS | Overall intelligibility and naturalness improve, but cross-language substitutions still appear. |
| DPO with MER, UTMOS, and $\Delta_{\text{CMI}}$ | Language boundaries are better preserved and intended code-switching structure is more faithfully reproduced. |
Interpretation of the Method’s Novelty
The novelty of the paper is not merely the use of DPO for TTS, but the way DPO is guided by a linguistically grounded signal that is specific to code-switching. Prior preference-guided TTS work, as characterized by the authors, tends to focus on general speech quality, naturalness, or intelligibility. Here, the new idea is to use a metric tied to language mixing itself. That makes the preference objective sensitive to the structure that matters most for CS ASR: whether the synthesized utterance preserves the alternation pattern and dominant-language proportions of the original speech.
Another important design choice is the use of pseudo frame-level language labels extracted from cross-attention rather than requiring human segmentation or forced alignment. This allows the metric to be computed automatically from speech and makes it usable as a critic during preference learning. The method therefore bridges an otherwise awkward gap between symbolic CMI and continuous speech generation.
Stated Conclusions
The paper concludes that code-switching ASR can benefit substantially from synthetic speech, but only when the synthetic data is aligned not just with intelligibility and perceptual quality, but also with realistic language-mixing structure. On SEAME, the proposed multi-critic DPO strategy consistently improves downstream ASR performance and achieves the best MER when $\Delta_{\text{CMI}}$ is included in the preference construction.
The authors present this as evidence that code-switching-aware TTS alignment is a promising direction for data augmentation in low-resource CS ASR. In the reported experiments, preserving acoustic-level code-mixing structure is the key factor that distinguishes the best synthetic augmentation from more conventional quality-only approaches.
Limitations and Scope, as Reflected by the Paper
The paper does not include a dedicated limitations section, but its reported scope is fairly narrow. The experiments are limited to the SEAME Mandarin-English corpus, and all TTS training text and prompts are taken from SEAME only. The code-mixing metric also depends on pseudo frame-level language labels derived from an ASR/alignment model, so the quality of $\Delta_{\text{CMI}}$ is tied to the reliability of that labeling pipeline. Finally, the reported downstream evaluation is on two ASR back ends, Whisper Large v3 and a CTC-based Conformer, so the generality beyond SEAME and these two systems is not established in the paper.
Bottom Line
The paper proposes a practical and targeted idea: use preference learning to make synthetic CS speech not only more intelligible and natural, but also more faithful to the original code-switching structure. In the reported SEAME experiments, adding the speech-level code-mixing critic improves both TTS quality metrics and downstream ASR MER, with the best results coming from the full multi-critic DPO setup.