S-JEPA
S-JEPA : Soft Clustering Anchors for Self-Supervised Speech Representation Learning
S-JEPA uses soft Gaussian Mixture Model posteriors for self-supervised speech representation learning, avoiding hard cluster assignments and offline re-clustering. It continuously updates clusters online, preserving acoustic ambiguity and improving efficiency and performance on speech recognition and emotion tasks.
Links
Paper & demos
Code & resources
Abstract
Self-supervised speech encoders are predominantly trained by predicting discrete hard cluster IDs at masked positions, a recipe that collapses acoustic ambiguity at category boundaries and requires interrupting training to re-cluster the entire corpus between iterations. We introduce S-JEPA, a JEPA-style encoder-predictor pair trained to match the soft posteriors of a Gaussian Mixture Model at masked positions via KL divergence. Training runs as one continuous optimization trajectory in two phases: a fixed GMM over MFCC features, then an online GMM over encoder features, with the input layer selected adaptively from a label-free signal, removing both the offline re-cluster step and the hand-tuned choice of which transformer layer to cluster on. Under the SUPERB protocol, S-JEPA achieves the lowest WER among evaluated SSL methods below 90M parameters and matches HuBERT-Base on emotion recognition at roughly half its parameter count, establishing a new Pareto frontier without offline re-clustering or teacher distillation. An analysis of the predictor's per-frame entropy on held-out speech reveals a bimodal distribution with a substantial minority of frames near the entropy of a perfect two-cluster tie, providing direct empirical evidence that the soft-target objective preserves the acoustic ambiguity that hard targets would collapse. Code is available at https://github.com/gioannides/s-jepa.
Overview and Motivation
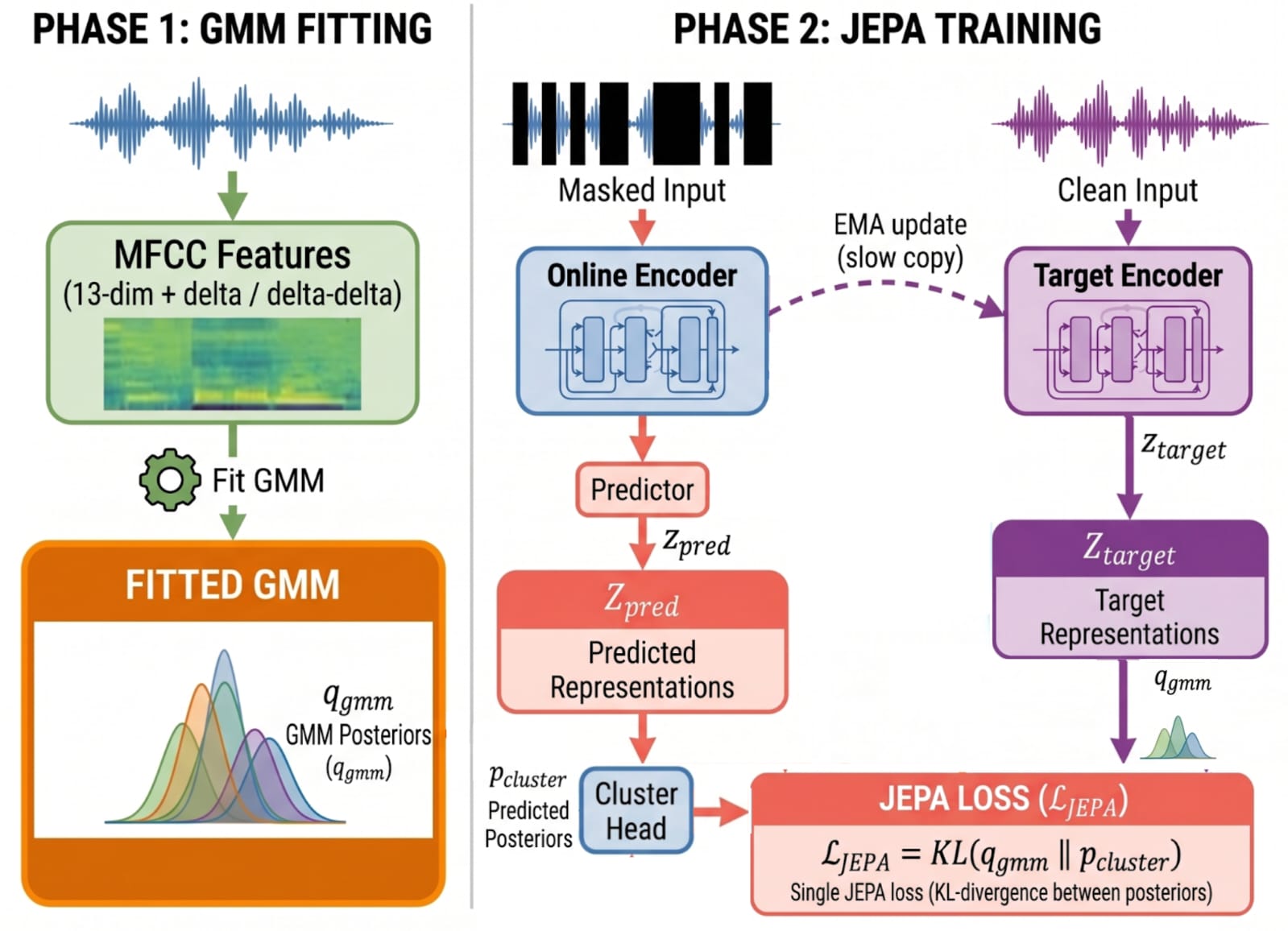
S-JEPA is a self-supervised speech representation learning method that replaces the standard hard-cluster masked-prediction recipe with a soft-target objective. The paper’s central observation is that common SSL speech systems such as HuBERT and WavLM rely on offline clustering and cross-entropy over discrete labels at masked positions. That setup has two drawbacks: it collapses acoustic ambiguity at category boundaries into a single ID, and it forces training to pause while the entire corpus is re-clustered between iterations. S-JEPA keeps the masked-prediction / JEPA-style architecture, but trains the predictor to match soft posteriors from a Gaussian Mixture Model (GMM) using KL divergence. The result is a single continuous training trajectory with no offline re-clustering step.
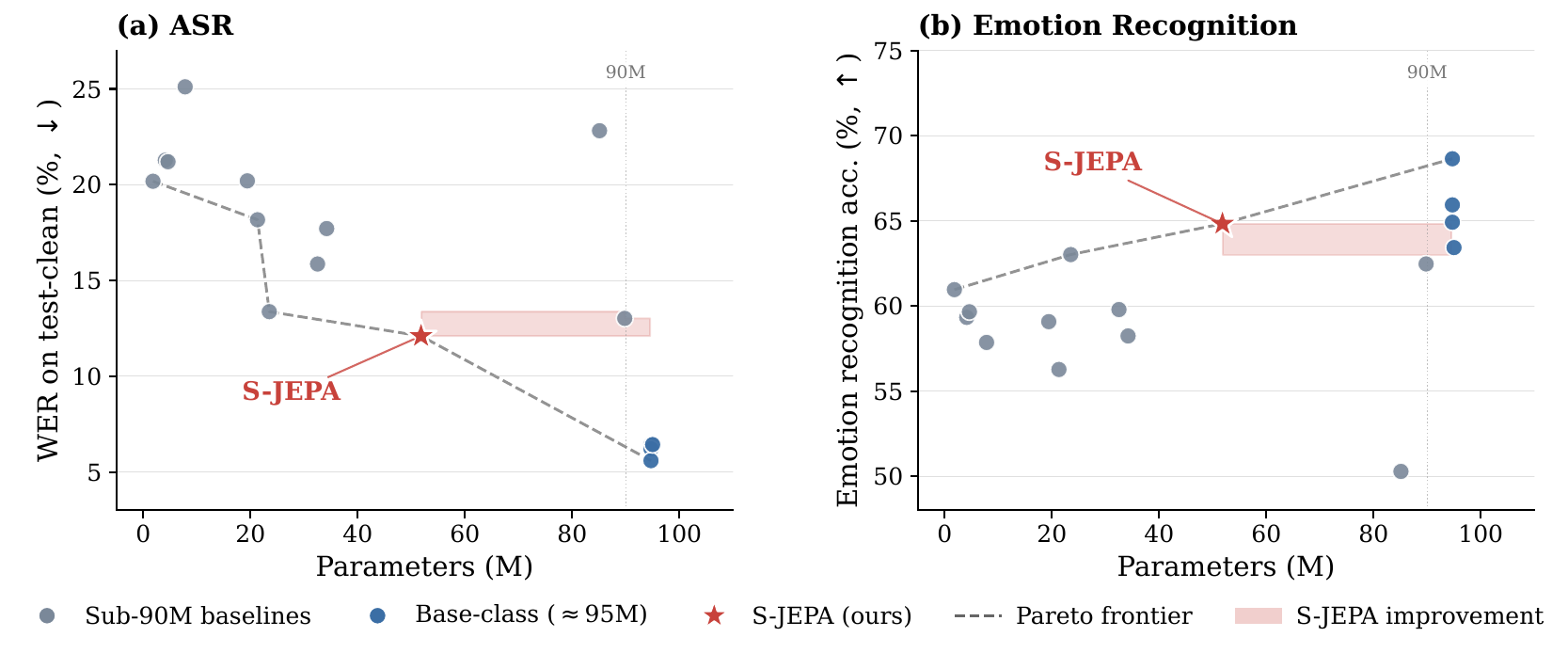
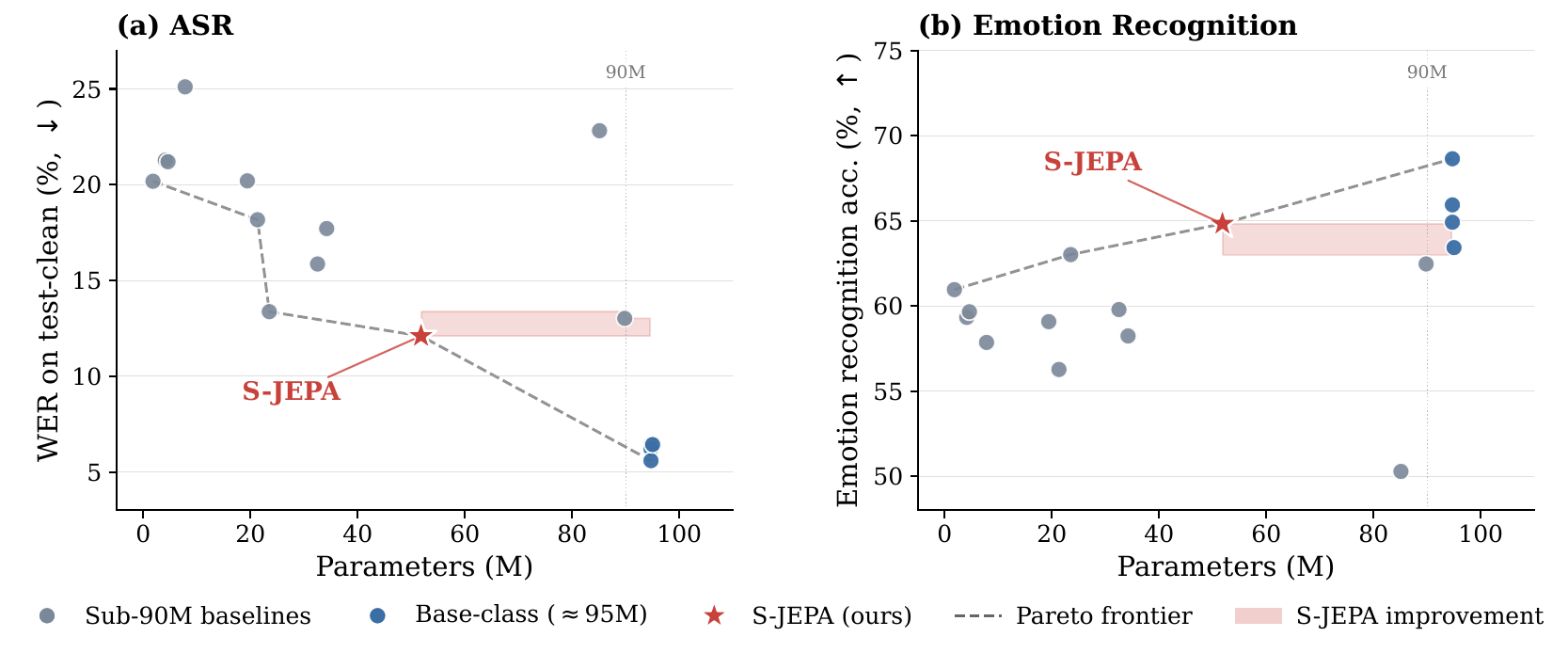
The paper’s claim is not that GMMs are novel, but that a specific combination of soft GMM targets, online GMM updates, adaptive layer selection, and a switched EMA teacher schedule produces a practical speech SSL recipe. In experiments, the learned encoder is evaluated under SUPERB with the encoder frozen, and the authors report that a 51.8M-parameter model reaches the lowest WER among SSL methods below 90M parameters while also matching HuBERT-Base on emotion recognition at roughly half the parameter count.
Problem Setting and Relation to Prior Speech SSL
The method is positioned against two broad families of speech SSL. Contrastive methods such as CPC and wav2vec predict future or masked latents using negative samples. Masked-prediction methods such as HuBERT treat SSL as classification over offline clusters at masked positions; WavLM adds denoising augmentation, and w2v-BERT combines contrastive and masked-prediction losses. A third line uses EMA teachers to regress continuous targets, as in data2vec. S-JEPA stays closest to the masked-prediction family, but changes the target space from hard IDs to soft categorical distributions.
The paper emphasizes three distinctions from nearby clustering-based methods. First, unlike HuBERT, it does not assign each frame to a single hard cluster. Second, unlike offline iterative clustering systems, it updates the GMM online in Phase 2, so training does not stop to re-fit clusters over the full corpus. Third, unlike BEST-RQ, which removes iteration by fixing a random quantizer, S-JEPA keeps the iterative structure but lets it evolve continuously. The authors also contrast S-JEPA with an earlier related anchor-based JEPA speech method that used a frozen GMM on log-mels as an auxiliary target; here the GMM is online, the GMM posterior is the only training target, and the active layer is selected adaptively.
Method
S-JEPA follows the JEPA pattern with three trained components: an encoder $f_\phi$, a predictor $h_\psi$, and a cluster head $g_\omega$. In Phase 2 there is also a non-trained EMA encoder $\bar{f}$, which is an exponential-moving-average copy of the online encoder. The encoder maps raw waveform to frame-level representations. The predictor receives the encoder output with masked positions replaced by a learned mask token and enriched with positional embeddings. The cluster head maps frame representations to $K$ logits and is applied to both visible and masked positions, but only masked positions contribute to the loss.
The loss is the KL divergence between the GMM posterior and the predictor’s predicted categorical distribution over clusters. If $q_t$ denotes the GMM posterior at frame $t$ and $p_t = \operatorname{softmax}(g_\omega(h_\psi(\cdot)))$ the predictor output, the objective is
$$\mathcal{L} = \frac{1}{|S|} \sum_{t \in S} \operatorname{KL}(q_t \| p_t).$$
The set $S$ is either masked positions only or masked plus visible positions depending on stage. The essential modeling choice is that $q_t$ is not a one-hot label: multiple GMM components may receive nonzero probability, preserving uncertainty near phone boundaries, transitions, and silence changes.
Architecture details
The encoder backbone uses a 7-layer 1D convolutional feature extractor followed by a 6-layer Transformer. The CNN front-end operates at 16 kHz input, uses the same kernel sizes and strides as HuBERT, and produces 20 ms frame resolution with 512 channels. The Transformer stack has 768 hidden units, 12 attention heads, a 3072-dimensional feed-forward layer, GELU activations, and post-norm layout. The predictor is intentionally small: one Transformer encoder layer with 768 hidden size and 8 heads, followed by a 3-layer MLP cluster head $768 \rightarrow 768 \rightarrow 768 \rightarrow K$.
The model is fairly compact relative to the baselines it compares against. The final encoder used for downstream evaluation has 51.8M parameters. The predictor, cluster head, and GMM are discarded after pre-training, so parameter counts reported in SUPERB correspond to the retained encoder only.
Training hyperparameters
| Setting | Phase 1 | Phase 2 |
|---|---|---|
| Cluster count $K$ | 100 | 500 |
| GMM feature space | 39-dim MFCC + $\Delta$ + $\Delta\Delta$ | 768-dim EMA encoder features |
| Optimizer | AdamW | AdamW |
| Learning rate | $1 \times 10^{-4}$ | $2.5 \times 10^{-5}$ |
| Batch size | 192 | 192 |
| Mask ratio | 0.65 | 0.65 |
| Mask span length | 10 frames | 10 frames |
| Max input duration | 15 s | 15 s |
| EMA decay for target encoder | n/a | switched between 0.999 and 0.9999 |
| Augmentation | noise and utterance mixing on | early: on; later: off |
Two-Phase Training Recipe
Training is presented as two phases that together form one continuous optimization trajectory. Phase 1 mirrors HuBERT’s first clustering stage, but replaces hard labels with GMM soft posteriors computed from MFCC features. Phase 2 mirrors HuBERT’s second stage, but does so online: the GMM is fit on encoder features instead of MFCCs, and the target features come from an EMA encoder whose decay rate is switched periodically.
Phase 1: fixed MFCC GMM
In Phase 1, a diagonal-covariance GMM with $K = 100$ components is fit once over 39-dimensional MFCC features from the training corpus. The GMM is initialized with mini-batch $k$-means on a reservoir-sampled subset and then refined with expectation-maximization. Once fit, it remains frozen throughout Phase 1. The loss is applied at both masked and visible positions, and denoising augmentation is enabled.
The authors frame this as the soft-target analogue of the initial HuBERT clustering round. Rather than producing hard assignments over MFCCs, the GMM posterior can express multi-modality when acoustic evidence is ambiguous.
Phase 2: online encoder-feature GMM
At the Phase 1 to Phase 2 boundary, an EMA encoder is initialized from the trained encoder, and a new $K = 500$ GMM is initialized over the EMA encoder’s features at an active transformer layer. Phase 2 starts with the same loss and augmentation settings as Phase 1, then later transitions to masked-only loss and turns augmentation off. The paper notes that this transition was motivated by held-out development WER, but it does not provide a controlled ablation disentangling the two changes.
The defining change in Phase 2 is that the GMM is updated online from minibatch sufficient statistics. After each minibatch, responsibility-weighted means, variances, and mixture weights are computed, and the GMM parameters are EMA-updated. No gradient flows through the GMM. This means the target generator evolves during training, but without a separate corpus-scale relabeling or re-clustering pass.
The EMA encoder itself uses a periodically switched decay: the paper alternates between $\alpha_{\text{fast}} = 0.999$ and $\alpha_{\text{slow}} = 0.9999$ at a cadence of roughly 20,000 steps. The idea is to alternate between a regime where the EMA encoder tracks improvements quickly, so the GMM input distribution can move, and a regime where the target vocabulary is relatively stationary so the predictor can learn against stable targets.
Adaptive layer selection via effective rank
A notable practical issue in iterative clustering methods is deciding which transformer layer to cluster on. S-JEPA removes that hand-tuned choice using an unsupervised signal: the effective rank of each layer’s frame embeddings. For a centered matrix $Z$ with singular values $\sigma_i$, the effective rank is defined as the exponential of the entropy of the normalized singular value spectrum. In standard notation, if $p_i = \sigma_i / \sum_j \sigma_j$, then
$$\operatorname{erank}(Z) = \exp\!\left(-\sum_i p_i \log p_i\right).$$
During Phase 2, the model periodically computes effective rank on sampled EMA-encoder features from each layer, smooths the scores, and chooses the layer with the highest rank as the active GMM input layer. When the argmax changes, the GMM simply continues updating from the new layer. The paper reports that in the 6-layer encoder, layer 2 is initially the highest-rank layer and later layer 4 takes over, after which training continues with layer 4 as the active anchor.
Data and Evaluation Setup
Pre-training uses a large English speech corpus formed by combining LibriLight and an English subset of Granary, for about 83,000 hours in total. All downstream evaluation follows the SUPERB protocol: the encoder is frozen and a small task-specific head is trained on top. The main benchmark tasks reported are automatic speech recognition, emotion recognition, and slot filling. The paper also includes additional probing experiments on LibriSpeech representations.
The model is evaluated in the sub-90M parameter regime, with the authors explicitly comparing against both smaller SSL baselines and Base-class encoders around 95M parameters, as well as larger reference models. The reported parameter count always refers to the inference-time encoder only.
Results on SUPERB
The headline result is that S-JEPA advances the Pareto frontier below 90M parameters. On frozen-encoder SUPERB evaluation, it achieves 12.10% WER on LibriSpeech test-clean under greedy CTC decoding, 64.83% emotion recognition accuracy, and 83.05 F1 / 33.17 CER on slot filling. The authors additionally report that standard 4-gram LM rescoring improves ASR to 8.50% WER and 2.90% CER, but the greedy number is the primary table value.
| Method | Params | ASR WER $$ | ER Acc. $$ | SF F1 $$ | SF CER $$ |
|---|---|---|---|---|---|
| modified CPC | 1.8M | 20.18 | 60.96 | 71.19 | 49.91 |
| APC | 4.1M | 21.28 | 59.33 | 70.46 | 50.89 |
| VQ-APC | 4.6M | 21.20 | 59.66 | 68.53 | 52.91 |
| PASE+ | 7.8M | 25.11 | 57.86 | 62.14 | 60.17 |
| NPC | 19.4M | 20.20 | 59.08 | 72.79 | 48.44 |
| TERA | 21.3M | 18.17 | 56.27 | 67.50 | 54.17 |
| DistilHuBERT | 23.5M | 13.37 | 63.02 | 82.57 | 35.59 |
| wav2vec | 32.5M | 15.86 | 59.79 | 76.37 | 43.71 |
| vq-wav2vec | 34.2M | 17.71 | 58.24 | 77.68 | 41.54 |
| Mockingjay | 85.1M | 22.82 | 50.28 | 61.59 | 58.89 |
| DeCoAR 2.0 | 89.8M | 13.02 | 62.47 | 83.28 | 34.73 |
| S-JEPA | 51.8M | 12.10 | 64.83 | 83.05 | 33.17 |
| HuBERT Base | 94.7M | 6.42 | 64.92 | 88.53 | 25.20 |
| WavLM Base | 94.7M | 6.21 | 65.94 | 89.38 | 22.86 |
| WavLM Base+ | 94.7M | 5.59 | 68.65 | 90.58 | 21.20 |
| wav2vec 2.0 Base | 95.0M | 6.43 | 63.43 | 88.30 | 24.77 |
The comparison is especially strong in the under-90M regime. Among the evaluated sub-90M models, S-JEPA has the best ASR WER, the best ER accuracy, and an SF F1 that is essentially tied with the best prior method. The paper is careful to note, however, that the Base-class encoders around 95M still achieve lower WER overall; S-JEPA is a new Pareto frontier within the sub-90M budget, not a universal win over much larger models.
The ER result is particularly notable because S-JEPA roughly matches HuBERT-Base on emotion recognition while using about 55% of the parameters. On slot filling, it is close to DeCoAR 2.0 but still behind the strongest Base-class encoders. That pattern is consistent with the paper’s broader claim: the method is a strong size-efficiency tradeoff rather than a strict domination of larger backbones.
Representation Probing
The paper further probes frozen representations on LibriSpeech using four tasks: speaker identification, gender classification, chapter identification, and phoneme classification. For utterance-level tasks, frame features are mean-pooled; for phoneme classification, frame features are used directly. Linear probes use multinomial logistic regression, and the phoneme task is also evaluated with a small MLP probe.
| Task | WavLM | HuBERT | S-JEPA |
|---|---|---|---|
| Speaker ID | 91.1 ± 1.0 | 99.1 ± 0.3 | 99.7 ± 0.3 |
| Gender Classification | 96.3 ± 0.5 | 99.5 ± 0.3 | 99.6 ± 0.3 |
| Chapter ID | 59.5 ± 1.0 | 88.2 ± 1.0 | 93.2 ± 1.0 |
| Phoneme (linear) | 86.1 ± 0.2 | 84.8 ± 0.1 | 82.8 ± 0.1 |
| Phoneme (MLP) | 87.5 ± 0.1 | 86.5 ± 0.1 | 88.0 ± 0.1 |
The probing results show a mixed picture. S-JEPA is strongest on speaker identity, gender, and chapter identification, with the chapter-ID gap being especially large. On phoneme classification, the linear probe slightly prefers WavLM, but the MLP probe reverses the ranking and gives S-JEPA the best result. The authors interpret this as evidence that phonetic information is recoverable, but perhaps in a more nonlinear form than for the comparison encoders.
Analysis of Soft-Target Behavior
A key part of the paper is the claim that the soft-target objective preserves acoustic ambiguity rather than collapsing it. The authors support this with two analyses: a per-utterance visualization of the predictor distribution and an aggregate entropy study over held-out speech.
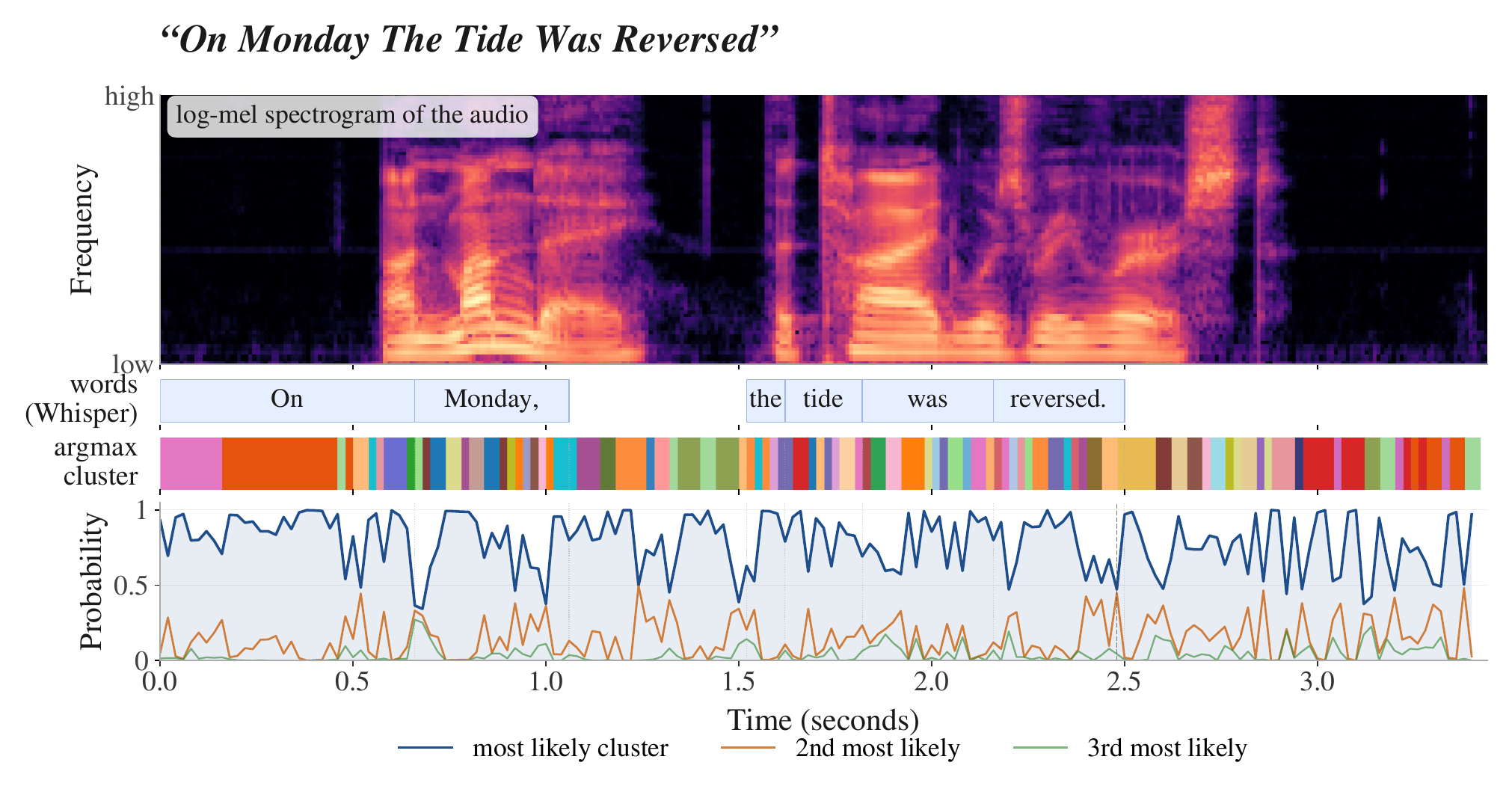
In the per-utterance plot, stable acoustic regions produce highly confident posteriors, while boundary regions show genuine competition between clusters. The authors stress that this is not diffuse uncertainty over many clusters; it is structured uncertainty concentrated in a small number of competing components.
The aggregate study uses 500 utterances from LibriSpeech dev-clean, yielding roughly 153K frames. For each frame, the predictor entropy is computed in bits as $H_t = -\sum_k p_{t,k} \log_2 p_{t,k}$. A value of 1 bit corresponds to a perfect two-way tie and 2 bits to a four-way uniform distribution, making the scale easy to interpret independent of $K$.
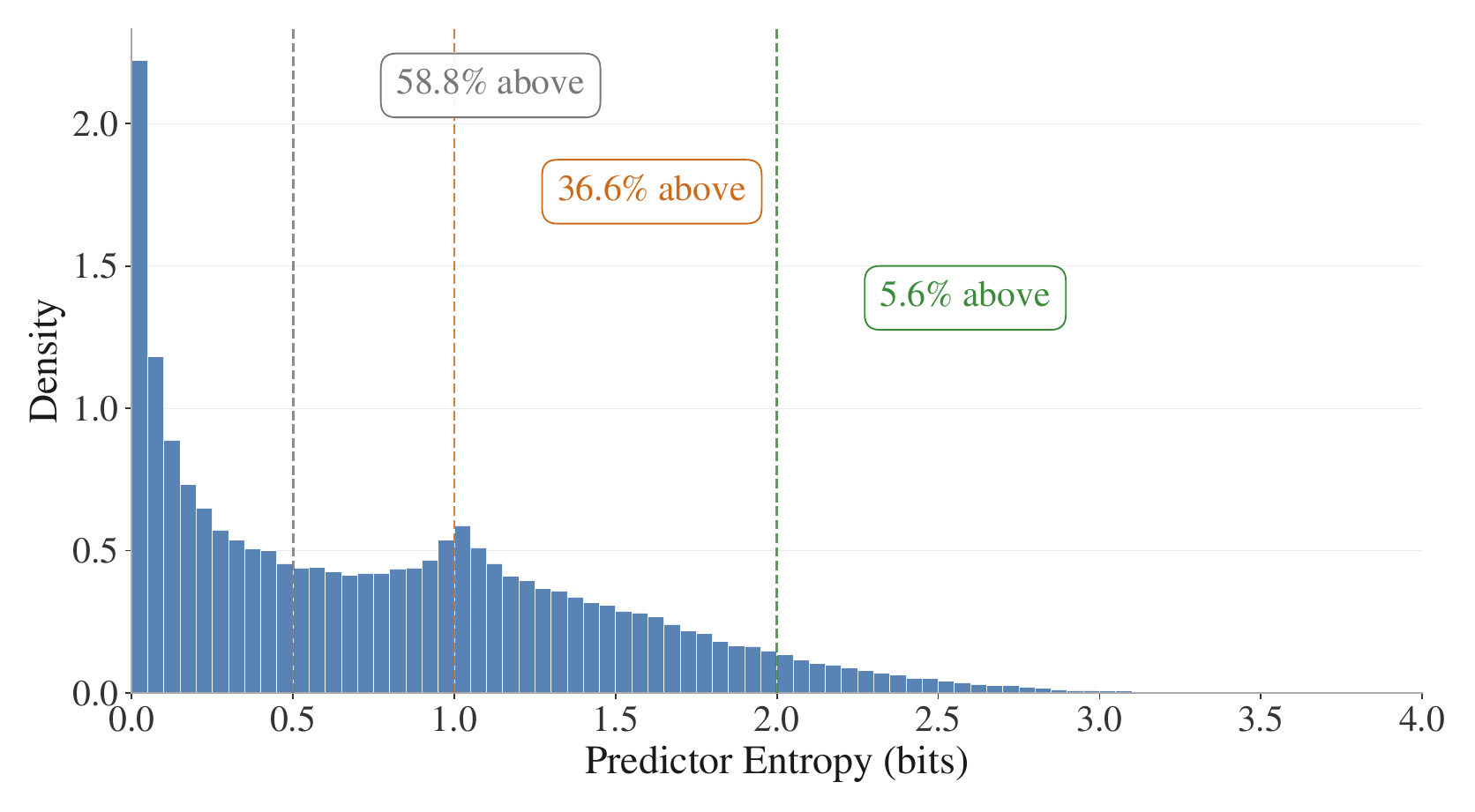
The entropy distribution is bimodal. One mode is a confident regime concentrated below 0.3 bits; the other is near 1 bit, corresponding to frames where two clusters are competing almost evenly. More than a third of frames exceed 1 bit of entropy. The authors interpret this as direct evidence that the soft-target objective preserves boundary ambiguity that hard labels would have collapsed into a single category.
Design Choices, Ablation Signals, and What the Paper Does Not Yet Prove
The paper contains some informative design observations, but not a full controlled ablation grid. The main nontrivial choices are: using soft GMM posteriors instead of hard cluster IDs; moving from a frozen MFCC GMM to an online encoder-feature GMM; switching the EMA decay between fast and slow values; and selecting the GMM input layer by effective rank rather than fixing a transformer layer by hand. The authors also mention that, during Phase 2, they changed masked/visible loss placement and turned augmentation off together because development WER improved, but they did not isolate these effects independently.
The effective-rank analysis is a useful empirical indicator rather than a proof of causality. The paper notes that in their 6-layer encoder, layer 2 was initially highest in effective rank and later layer 4 took over, with continued WER improvement after the switch. The authors explicitly avoid claiming that higher rank causes better downstream performance; they only claim that the argmax-based layer anchor is correlated with continued progress in their setup.
Likewise, the entropy analysis supports the idea that soft targets retain structured ambiguity, but it does not by itself establish that this is the mechanism behind the improved Pareto frontier. The paper frames that connection as plausible and consistent with distillation literature, but leaves a matched hard-target baseline for future work.
Limitations
The limitations section is concise but important. First, the periodically switched EMA schedule does not have a controlled comparison against a more principled alternative. Second, all training and evaluation are in English, so extension to tonal languages, low-resource conditions, and non-speech audio remains open. Third, the relationship between the GMM-based target generator and SIGReg-style JEPA formulations is identified as promising but unexplored. More broadly, the paper does not include a direct head-to-head ablation that isolates every design element under matched compute.
Takeaways
The paper’s core message is that soft clustering can be made practical for large-scale speech SSL without giving up the masked-prediction paradigm. S-JEPA uses a JEPA-style encoder-predictor architecture, but replaces hard cluster labels with soft GMM posteriors and removes the expensive stop-restart re-clustering pipeline by updating the target GMM online. Its strongest reported advantage is efficiency: at 51.8M parameters it achieves the best WER among sub-90M SSL systems on SUPERB, and it matches HuBERT-Base on emotion recognition at about half the size. The entropy analysis provides a nice interpretability result: the model does not merely become less certain everywhere; it concentrates uncertainty into a meaningful two-cluster competition at acoustically ambiguous frames.
Code & Implementation
This repository implements the S-JEPA method for self-supervised speech representation learning described in the paper. It contains Python source files primarily for model definition, offline and online Gaussian Mixture Model (GMM) fitting, and training.
Key components include:
model.py: Defines the convolutional-transformer encoder architecture, the JEPA predictor, and associated cluster heads mapping predicted embeddings to soft cluster logits.fit_gmm.py: Implements the offline GMM fitting on MFCC features for the initial training iteration and supports seeding and updating GMM parameters as needed.train.py: Main training script orchestrating the two-phase training. It supports both iteration 1 with a frozen offline GMM target, as well as iteration 2+ with an online GMM updated from EMA encoder features, matching the paper's continuous optimization trajectory without offline re-clustering.
The design strictly follows the method described: initial GMM targets on MFCCs guide the first phase pretraining, then subsequent phases use an online GMM from an exponential moving average encoder. The training optimizes a KL divergence loss at masked positions to softly match posterior distributions.
Training is configured via JSONL manifests for audio data and DeepSpeed for distribution, as detailed in the README. The repository includes scripts and configurations for fitting GMMs, training with frozen and online GMM modes, and managing checkpoints.