Full-Duplex Spoken Dialogue Survey
A Survey of Full-Duplex Spoken Dialogue Systems: Architectural Hierarchy, Interaction Ontology, and Decision State Machine
This paper surveys full-duplex spoken dialogue systems with a new framework that clarifies their architectural hierarchy, interaction types, and state behaviors. It audits systems and data to reveal gaps and outlines future research directions in full-duplex conversation.
Demos
These demos illustrate frameworks to analyze full-duplex spoken dialogue systems. Focus on the architectural hierarchy (L0-L3) localizing decision layers, the T x I x R ontology defining interaction types, and the decision state machine showing system states and transitions. Evaluate how these visualizations clarify system capabilities beyond basic speak/listen modes in complex conversational scenarios.
Links
Paper & demos
Code & resources
Abstract
More than a dozen spoken dialogue systems have recently claimed to be "full-duplex," yet the term has been used to describe substantially different capabilities. Existing surveys collapse them onto a single axis (cascaded/end-to-end, or engineered/learned) and miss the distinctions that matter most for builders. We argue that much of this ambiguity is taxonomical: current terminology does not specify where duplex decisions are made, which interaction types are supported, or how a system behaves moment by moment. This paper introduces three complementary frameworks: (i) an L0-L3 Architectural Hierarchy that locates where duplex decisions are made; (ii) a $T\times I\times R$ Interaction Ontology that specifies the temporal relation, user intent, and required system response for each interaction; and (iii) a Decision State Machine (IDLE/LISTEN/SPEAK/WAIT/DUAL) that describes how systems move between states. Across published systems and benchmarks, our audit documents a realization gap: although many architectures can in principle operate in full-duplex states, their observed behavior remains constrained by the interaction patterns represented in training and evaluation. We point to the limited public training-data coverage relative to the (largely undisclosed) industrial corpora, together with the still-unrealized goal of L3 representation-level modeling, as the key frontiers for future research on full-duplex dialogue. The related material is available at https://github.com/DuplexLM/DuplexSurvey.
Introduction and scope
This paper is a survey of full-duplex spoken dialogue systems (FD-SDS), but it is not a generic literature review. Its core claim is that the term full-duplex has been used to describe several distinct system behaviors, and that the literature has been underspecified along three axes: where the duplex decision is made in the stack, which interaction types are actually supported, and how the system behaves moment by moment during overlap, interruption, backchanneling, and silence.
The survey’s main contribution is a three-part analytical framework: an $L0$--$L3$ architectural hierarchy, a $T \times I \times R$ interaction ontology, and a five-state decision state machine. The paper uses these frameworks to audit published systems, training corpora, and benchmarks, and argues that observed behavior is limited by a realization gap between architectural capacity and what the available training/evaluation data actually teaches and measures.
Because this is a survey rather than a new model paper, there are no train-time ablations or novel experimental metrics in the usual sense. The closest analogue is the paper’s cell-by-cell audit of systems, corpora, and benchmarks, which functions as an ablation-style decomposition of capabilities: if a system fails a particular ontology cell, the paper tries to localize whether the missing ingredient is architecture, data coverage, or evaluation design.
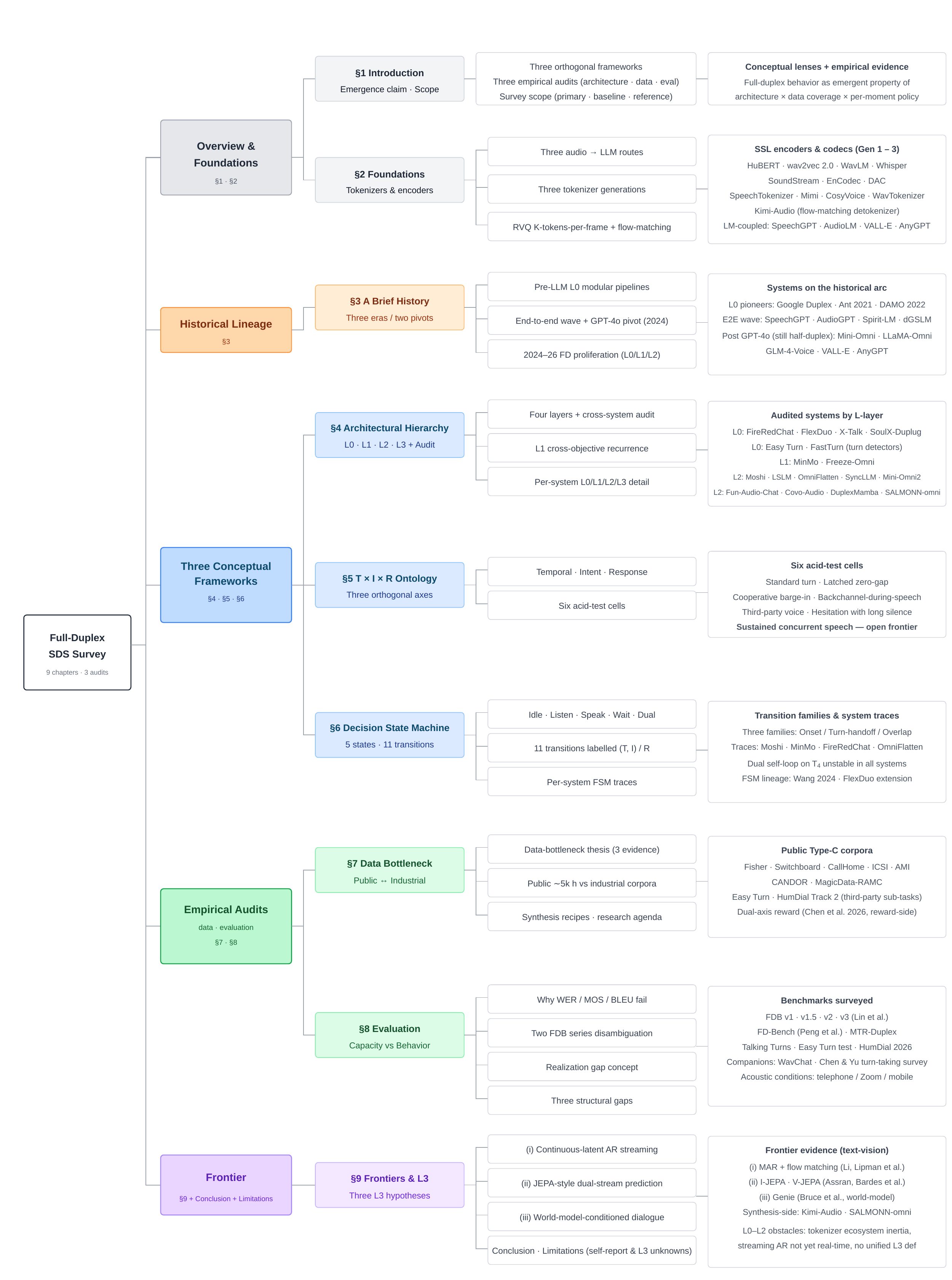
Historical trajectory and representation stack
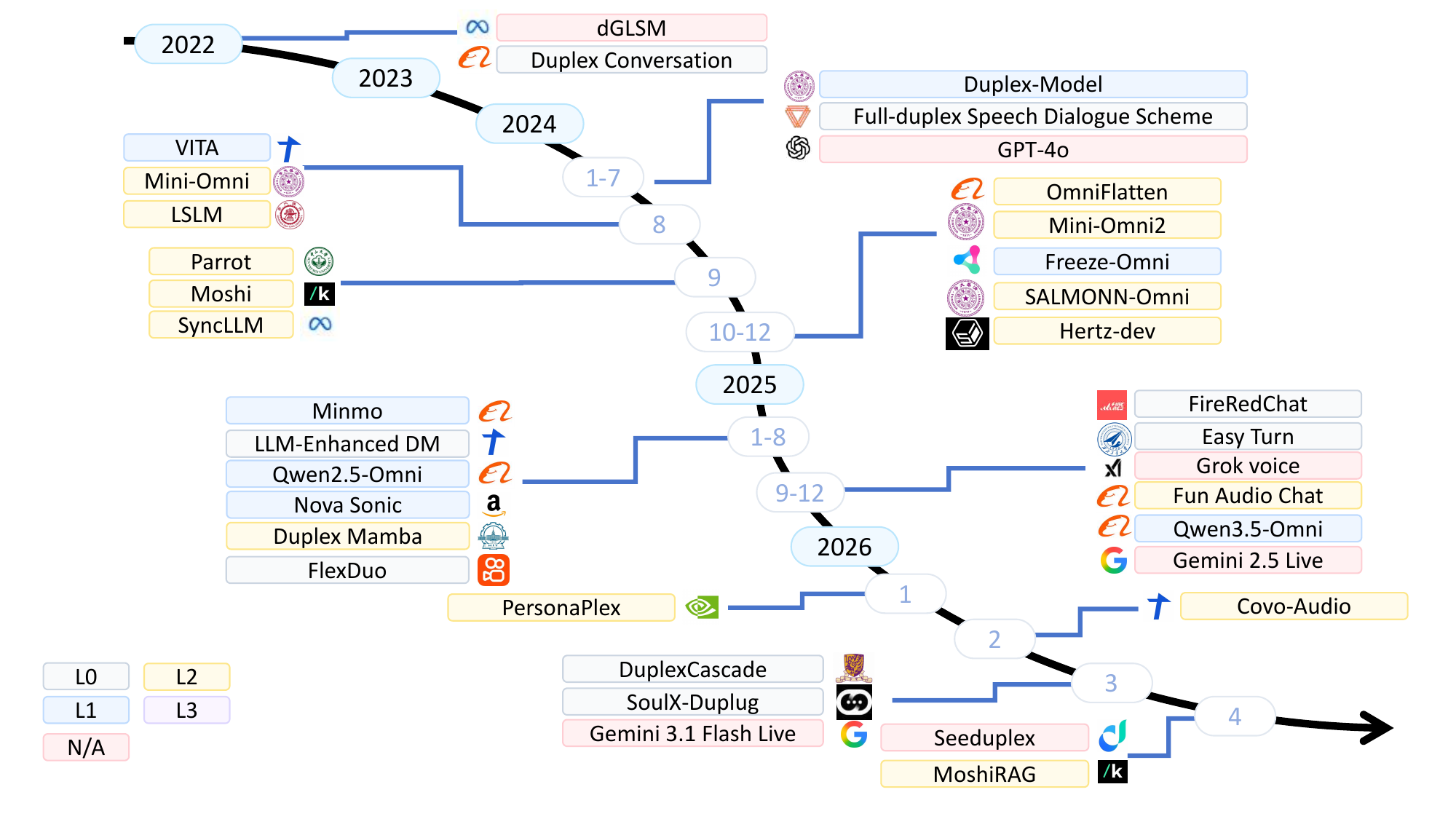
The paper reads the field as three eras separated by two pivots. In the pre-LLM era, industrial systems such as Google Duplex, Ant Group, and Alibaba DAMO implemented modular pipelines with voice activity detection (VAD), end-of-turn prediction, and dialogue management. In that regime, turn-taking was mostly a scheduling problem over speech activity.
The first technical pivot came when speech itself became tokenizable. The survey summarizes three generations of audio representation: (1) semantic units from self-supervised encoders, (2) neural audio codecs based on residual vector quantization, and (3) semantic-acoustic fused tokenizers that reserve the first codebook for semantic content and the rest for acoustic detail. This progression is important because it explains why token-level full-duplex systems proliferated only after generation-3 tokenizers matured.
The second pivot was commercial: GPT-4o made interruptible speech-to-speech interaction a product expectation, after which more than a dozen systems claimed full-duplex behavior. The paper argues that the resulting design space should not be collapsed into a single end-to-end versus cascaded axis, because systems differ in the location of the duplex decision and in the interaction behaviors they actually support.
The survey’s historical account divides systems into three broad classes: primary targets (post-GPT-4o systems explicitly claiming FD behavior), historical baselines (pre-2024 industrial modular pipelines), and taxonomy references (adjacent streaming speech-LMs that help contextualize the design space but are not audited as FD systems unless they explicitly claim the capability). Pure TTS-only, ASR-only, voice-cloning, or non-dialogue audio-generation systems are out of scope.
Audio-to-model routes and tokenizer constraints
The appendix background section identifies three routes from audio to an LLM: discrete audio tokens, continuous audio embeddings, and hybrid text-leads/audio-trails. The discrete-token route is the most common because it reuses the standard language-model stack. Continuous-embedding routes preserve more acoustic detail but require a projector into the LLM hidden space. Hybrid designs use text as the semantic backbone and attach audio realization in parallel or shortly after.
A key technical issue is the $K$-tokens-per-frame problem: RVQ-based tokenizers emit multiple tokens per audio frame, so naive autoregressive modeling multiplies sequence length and inference cost. The paper argues that many L2 design choices are best understood as different ways of ordering, parallelizing, or flattening those per-frame codebooks.
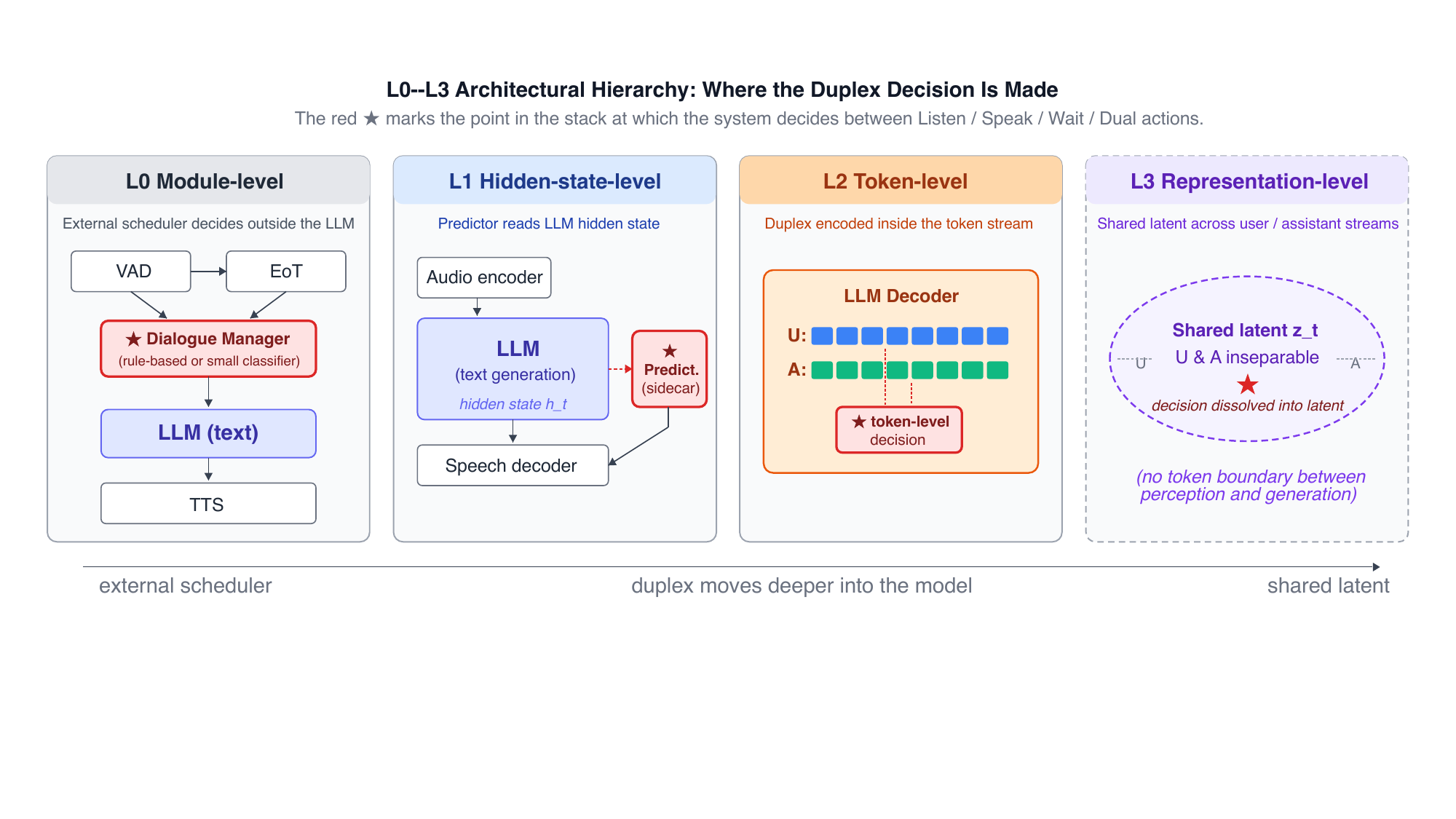
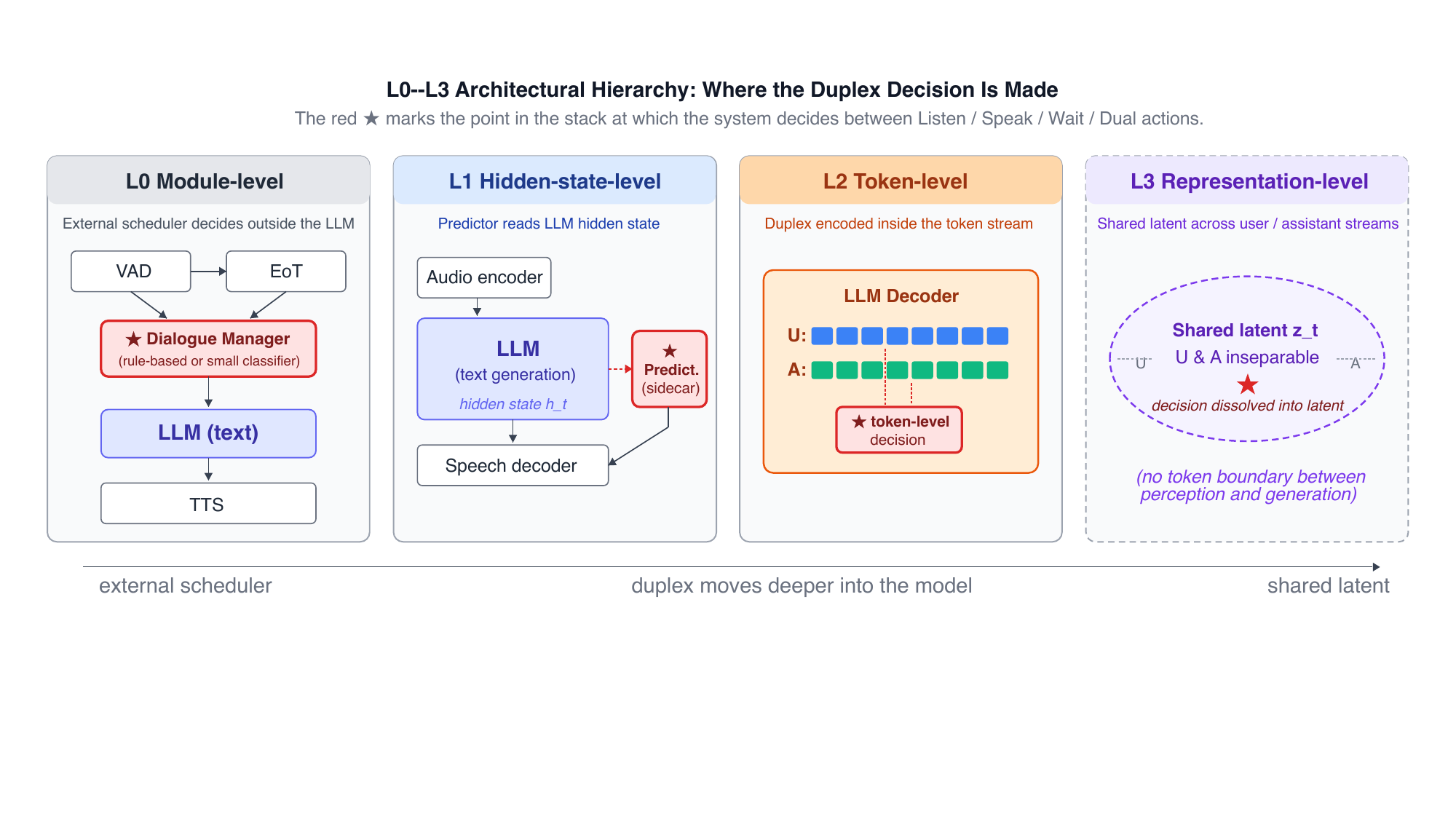
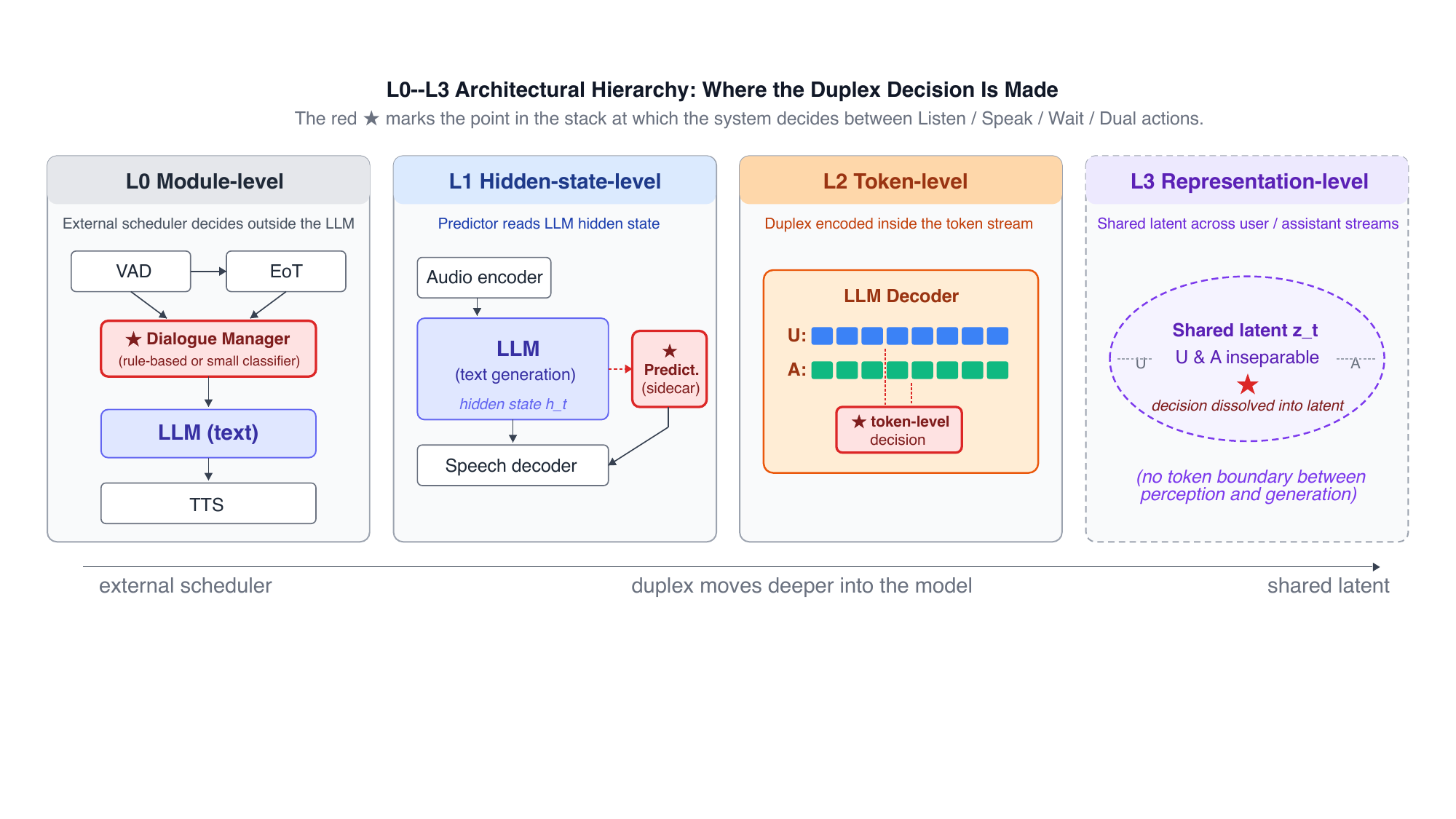
$L0$--$L3$ architectural hierarchy
The first framework is the architectural hierarchy. It asks where the system makes its duplex decision:
$L0$ places the decision in an external module or scheduler outside the LLM; $L1$ reads the LLM hidden state with a sidecar predictor; $L2$ encodes duplex behavior in the token stream itself; and $L3$ would move the decision into a shared latent representation, but no published system has yet realized this level.
| Layer | Where the duplex decision lives | States natively reachable | Representative systems |
|---|---|---|---|
| $L0$ | External modules such as VAD, end-of-turn prediction, and dialogue management | Idle, Listen, Speak; limited Wait; Dual effectively unreachable |
FireRedChat, FlexDuo, X-Talk, SoulX-Duplug, Easy Turn, FastTurn |
| $L1$ | A predictor reads the LLM hidden state and decides the duplex action | Idle, Listen, Speak, Wait; limited Dual |
MinMo, Freeze-Omni; plus structurally similar non-FD systems such as Qwen Thinker--Talker and Step-Audio R1.1 |
| $L2$ | Duplex control is encoded directly in token-level generation | All five states, including Dual |
Moshi, LSLM, OmniFlatten, SyncLLM, Mini-Omni2, Fun-Audio-Chat, Covo-Audio, DuplexMamba, SALMONN-omni |
| $L3$ | Shared representation-level latent | Not yet realized | Open frontier only |
The paper’s main architectural observations are twofold. First, $L1$ is a structural attractor: the same hidden-state-predictor shape appears in both full-duplex and non-full-duplex streaming systems, which suggests that the pattern is driven by modeling convenience rather than by the FD niche alone. Second, $L0$ is not a legacy dead-end; the paper highlights recent modular systems that argue for competitive latency, interpretability, and engineering cost. In other words, the hierarchy is not a progress ladder; it is a map of design choices.
The cross-system audit also makes an important distinction between capacity and realization: two $L2$ systems may both be capable of entering Dual architecturally, yet only one may actually demonstrate robust backchannel or concurrent behavior, depending on what the training data taught it to do.
$T \times I \times R$ interaction ontology
The second framework decomposes a full-duplex interaction moment into a triple $(T, I, R)$: temporal relation, user intent, and required system response. The paper explicitly uses this axis decomposition to avoid conflating timing, meaning, and policy.
The temporal axis contains five values: sequential, latched, overlap, concurrent, and silence. The intent axis contains seven values: information, backchannel, repair, floor-claim, floor-yield, disfluency, and third-party audio. The response axis contains six values: continue, stop, wait, backchannel, ignore, and initiate. The full Cartesian product therefore yields $5 \times 7 \times 6 = 210$ nominal cells, though many are physically impossible or redundant.
| Axis | Values |
|---|---|
| $T$ (temporal) | $T_1$ sequential, $T_2$ latched, $T_3$ overlap, $T_4$ concurrent, $T_5$ silence |
| $I$ (user intent) | $I_1$ information, $I_2$ backchannel, $I_3$ repair, $I_4$ floor-claim, $I_5$ floor-yield, $I_6$ disfluency, $I_7$ third-party |
| $R$ (system response) | $R_1$ continue, $R_2$ stop, $R_3$ wait, $R_4$ backchannel, $R_5$ ignore, $R_6$ initiate |
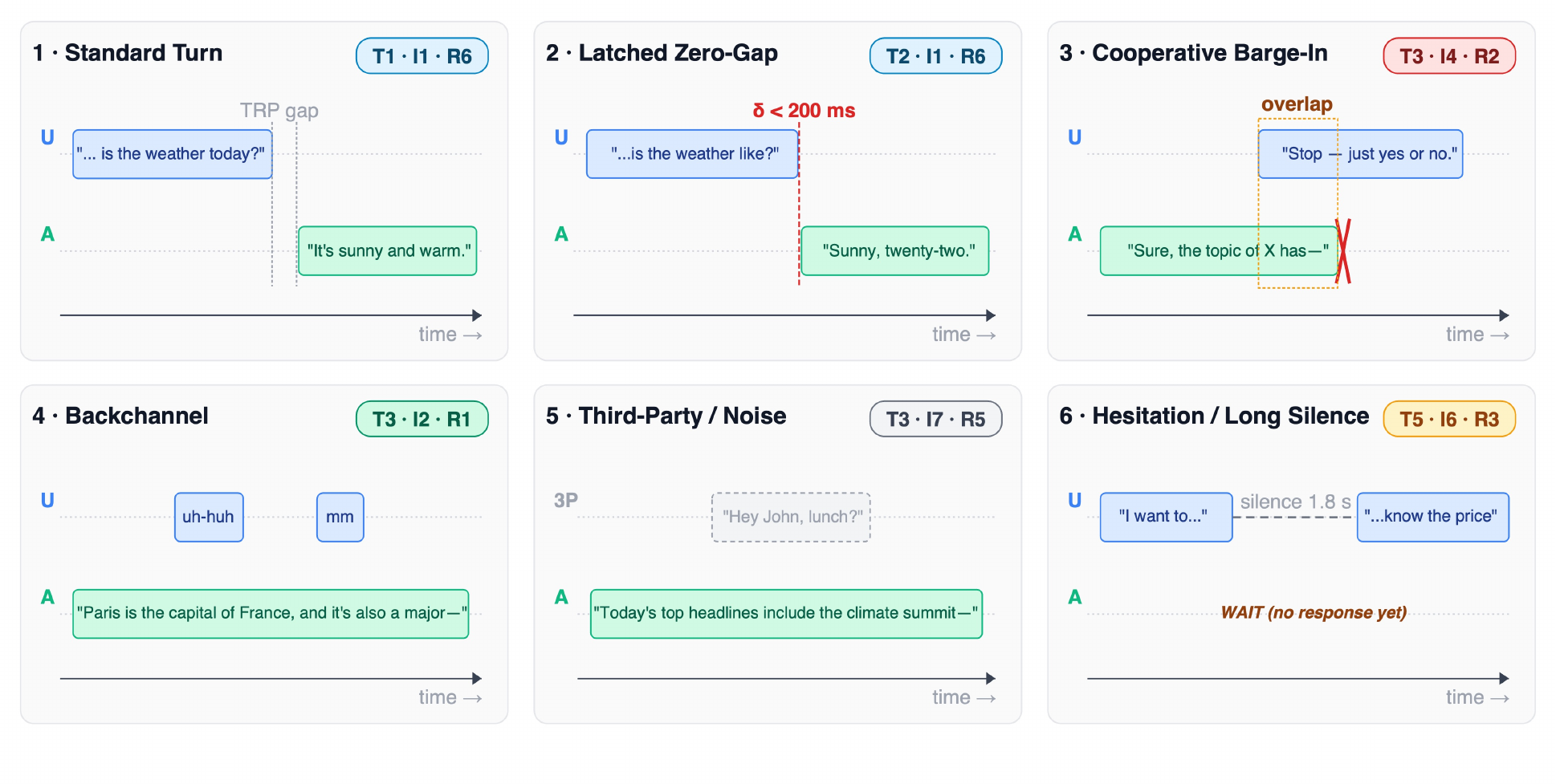
The paper singles out six acid-test cells that stress the system in qualitatively different ways: standard turn-taking, latched zero-gap handoff, cooperative barge-in, backchannel during system speech, third-party speech, and hesitation with long silence. These are the cells the survey uses repeatedly in its system audit, corpus audit, and benchmark audit.
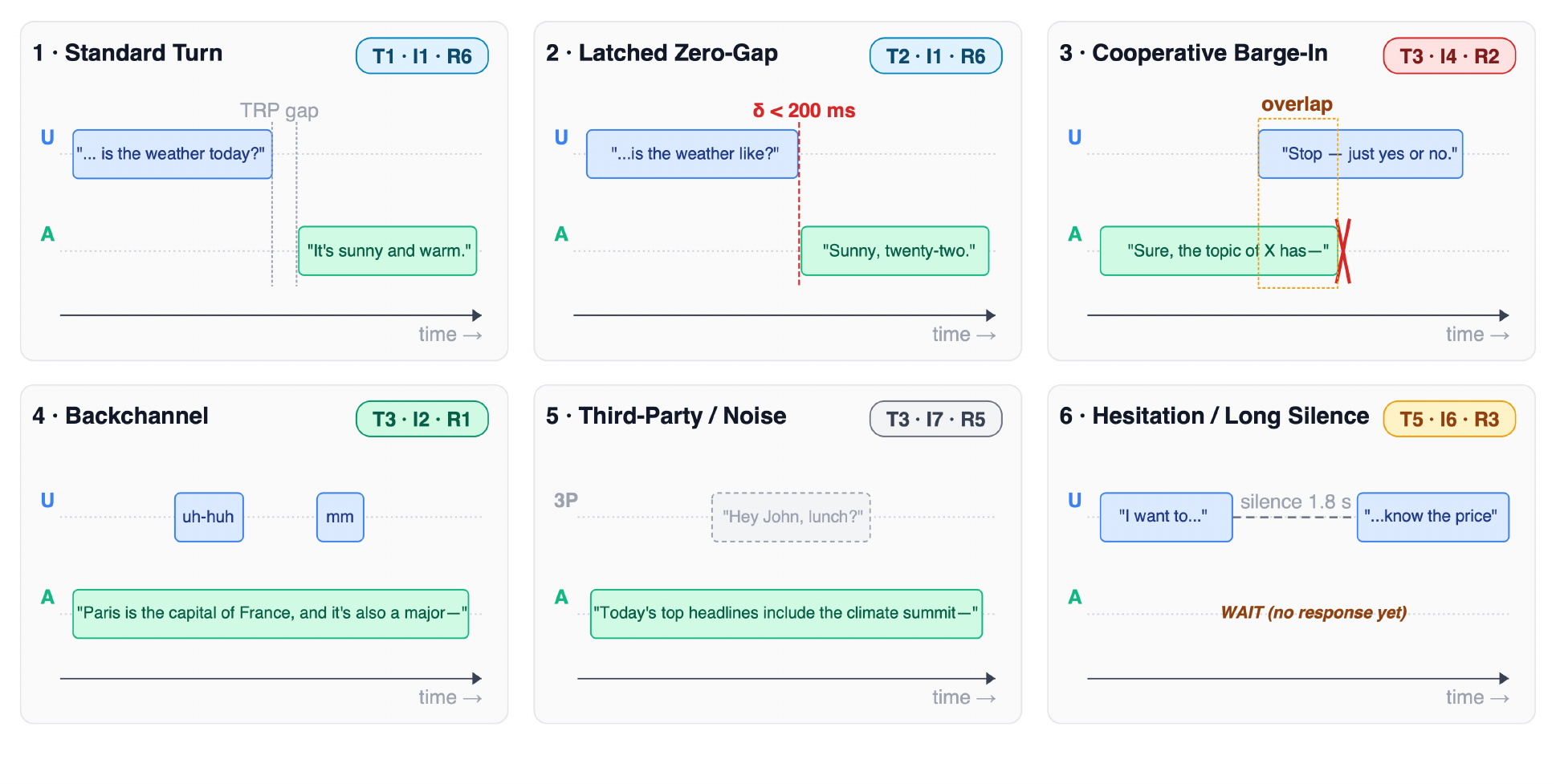
| Cell | Meaning | Typical failure mode the survey emphasizes |
|---|---|---|
| $(T_1, I_1, R_6)$ standard turn | Clean handoff at a transition-relevance point | Baseline; almost all systems handle it |
| $(T_2, I_1, R_6)$ latched zero-gap | Near-zero handoff with early generation | Requires speculative generation and semantic end-of-turn prediction |
| $(T_3, I_4, R_2)$ cooperative barge-in | User claims the floor while the assistant is speaking | Systems must stop within roughly 200 ms to feel substantive |
| $(T_3, I_2, R_1)$ backchannel during system speech | Listener acknowledgements such as “uh-huh” should not steal the floor | Naive VAD often mistakes this for interruption |
| $(T_3, I_7, R_5)$ third-party speech | Non-addressee speech, TV, or ambient voices overlap the assistant | Requires speaker-conditioned VAD or relevance gating |
| $(T_5, I_6, R_3)$ hesitation with long silence | Silence does not imply the user has finished | Fixed-threshold VAD fires too early; semantic end-of-turn prediction is needed |
The ontology is used three ways in the paper: as a training-data slicing scheme, as an evaluation lens, and as a behavior audit. One of its most important practical uses is to make negative results legible. For example, saying that a system “fails on the backchannel cell” is more actionable than saying it is “not always full-duplex.”
Five-state decision state machine
The third framework describes what the system is doing at each instant. The state set is:
$$ \mathcal{S} = \{\text{Idle}, \text{Listen}, \text{Speak}, \text{Wait}, \text{Dual}\} $$
The transition notation is written as $s \xrightarrow{(T_i, I_j)/R_k} s'$, meaning that the system moves from state $s$ to state $s'$ under temporal class $T_i$ and intent class $I_j$, taking response class $R_k$.
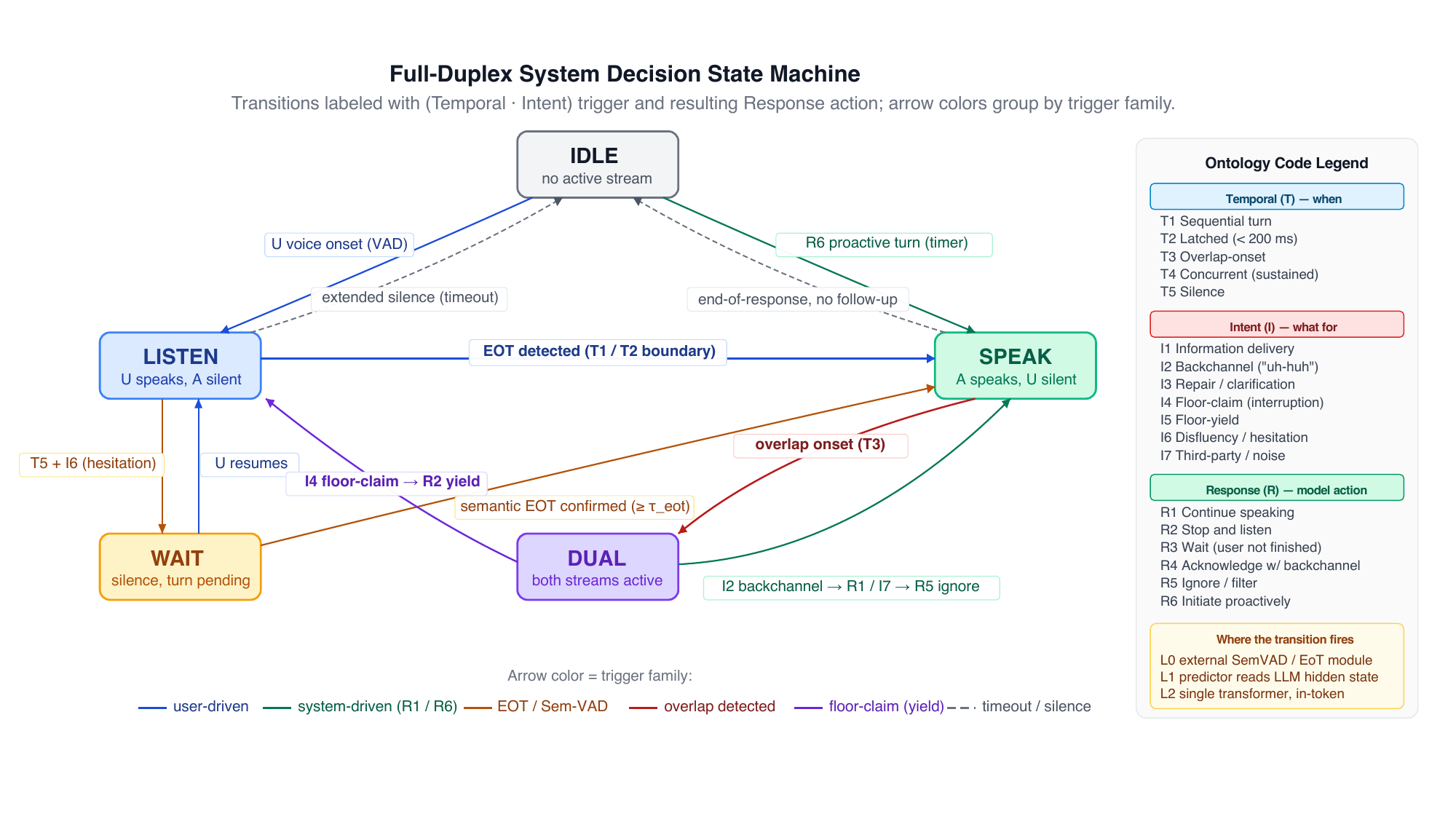
The paper extends earlier two-state and three-state formulations by adding two states that are important for full-duplex behavior: Wait, which captures semantic hesitation, and Dual, which captures active overlap-aware integration. The 11 transitions fall into three families:
- Onset transitions: entering
Listenon user onset, or enteringSpeakfrom silence when the system initiates. - Turn-handoff transitions: moving between
Listen,Wait,Speak, andIdlebased on end-of-turn prediction and semantic hesitation handling. - Overlap transitions: moving through
Dualwhen both parties are active, with different destinations depending on whether the overlap is a backchannel, a floor claim, or third-party speech.
The central insight is that the state machine is not a controller; it is a behavior taxonomy. It turns the question “what does the system do right now?” into a structured lookup over ontology cells, and it makes clear which transitions a given architecture can even attempt.
How the ontology and state machine compose
The survey maps ontology cells to traces. Cooperative barge-in is Speak $\to$ Dual $\to$ Listen; backchannel during speech is Speak $\to$ Dual $\to$ Speak; third-party speech is the same structural trace but with a different intent classifier; hesitation is Listen $\to$ Wait $\to$ Speak or Listen depending on re-confirmation; sustained concurrent speech would be a Dual self-loop, but no audited system stably realizes it.
Training-data audit and the data bottleneck
A major thesis of the paper is that architecture is not the only bottleneck. Across the audited $L0$--$L2$ systems, the binding constraint on actual duplex behavior is the cell-coverage distribution of training data. The paper distinguishes three data types: type A single-stream speech, type B single-stream dialogue/instruction data, and type C two-stream time-synchronous dialogue. Only type C directly teaches duplex behavior.
The public type-C corpus inventory is small relative to industrial proprietary corpora and is heavily skewed toward English telephone audio. The paper estimates the public pool at roughly 5,000 hours total, with Fisher the dominant source. It also emphasizes that industrial data is both larger and undisclosed, which creates a reproducibility gap between open and closed systems.
| Corpus | Hours | Language / format | Why it matters in the survey |
|---|---|---|---|
| Switchboard | ~260 h | English, 2-channel telephone | Classic dyadic turn-taking source |
| CallHome | ~60 h (English subset) | Multilingual telephone, 2-channel | Pre-structured dialogue across several languages |
| Fisher | ~2000 h | English, 2-channel telephone | Empirically dominant training source for FD work |
| ICSI Meeting | ~72 h | English, multi-channel meeting | Useful for diarization-like overlap phenomena |
| AMI Meeting | ~100 h | English, multi-channel + video | Meeting-style conversational dynamics |
| MagicData-RAMC | 180 h | Mandarin, smartphone mono | Modern mobile-acoustic Chinese coverage |
| CANDOR | ~850 h | English, 2-channel Zoom calls | Modern conversational acoustics |
| Easy Turn train | 1145 h | English + Mandarin, turn-taking labels | Large open turn-taking detection corpus |
| HumDial Track 2 | 107 h | English + Mandarin, 2-channel, 100+ speakers | Public corpus explicitly designed around FD sub-scenarios |
The paper separates the data landscape into two tracks. Track A is public, relatively small, and biased toward $T_1$, $T_2$, and $T_5$ cells, with $T_3$ appearing at natural conversational frequency and $T_4$ essentially absent. Track B is industrial and proprietary, with larger scale but undisclosed cell coverage and no reproducibility. This asymmetry is used to explain why open-source systems tend to underperform industrial deployments on subtle overlap behavior.
What the training data actually teaches
The survey argues that the training stage where full-duplex competence is acquired is the duplex interaction alignment stage, not the earlier ASR or TTS phases. In the systems it reviews, this stage often relies on synthetic or auto-labeled data because real two-channel full-duplex recordings are scarce. The common pattern is a four-stage pipeline: general LLM pretraining, ASR alignment, TTS alignment, and duplex alignment, sometimes followed by reinforcement learning with interaction-quality rewards.
The paper also catalogs several synthetic augmentation recipes: dual-role TTS for standard turns, overlap injection for latched handoffs and barge-in, backchannel insertion for listener acknowledgements, silent-token augmentation for explicit silence behavior, and time-anchor self-supervision for chunk timing. A central conclusion is that these recipes do not solve two difficult cells on their own: sustained concurrent speech ($T_4$) and third-party speech ($T_3, I_7$) remain underrepresented or effectively absent in public training data.
Representative system-level training details
The paper reports several recurring training patterns across systems. Moshi uses large-scale pretraining, multi-stream post-training, Fisher-based full-duplex fine-tuning, and synthetic-dialogue instruction tuning. MinMo uses a 4,000-hour mix of real and simulated dialogue and a multi-stage curriculum with heuristic turn-taking labels. Freeze-Omni is trained around a frozen LLM with staged ASR, TTS, and duplex objectives. The broader message is that the duplex stage is data-hungry, and most open systems fill the gap with self-generated or automatically labeled examples.
System audit by architecture and cell coverage
The paper’s architecture audit is the empirical core of the survey. It places representative systems on the $L0$--$L3$ axis and then checks which state-machine regions each system can reach by construction. The result is not just a taxonomy; it is a capability map.
The main patterns are: (1) $L2$ is the most populous family, but internally heterogeneous; (2) $L1$ is a confirmed structural attractor because different teams independently converged on hidden-state sidecar designs; and (3) $L0$ remains active rather than obsolete, especially where latency, cost, and interpretability matter. The audit also emphasizes that architectural reachability is necessary but not sufficient: a model may be able to enter Dual in principle but still fail on backchannel-during-speech or third-party noise because its training data never covered those situations.
Representative systems and their role in the survey include FireRedChat (streaming pVAD + EoT + dialogue manager), FlexDuo (pluggable modular control), X-Talk (an explicit argument for the modular path), SoulX-Duplug (plug-and-play modularity), MinMo (hidden-state predictor), Freeze-Omni (frozen-LM duplex training), Moshi (parallel multi-stream token prediction), LSLM (fusion-based duplex modelling), OmniFlatten (flattened streams), SyncLLM (chunk alternation), Mini-Omni/2 (parallel heads with keyword-triggered interruption), Fun-Audio-Chat and Covo-Audio (industrial token-level duplex systems), DuplexMamba (Mamba/SSM backbone), and SALMONN-omni (codec-free continuous embeddings).
Representative cell-level findings
- Standard turns are universally covered and therefore not very diagnostic.
- Latched zero-gap handoff is supported by systems with speculative generation and semantic end-of-turn prediction; cascaded baselines struggle because they only respond after silence is observed.
- Cooperative barge-in is one of the central FD tests; the survey highlights response latency on the order of 200 ms as a perceptual threshold.
- Backchannel during system speech is the classic failure mode: many systems confuse listener acknowledgements with interruptions.
- Third-party speech is primarily handled by speaker-conditioned VAD or equivalent filtering; the paper treats this as a particularly clean case for modular systems.
- Hesitation with long silence requires semantic end-of-turn prediction; fixed-threshold VAD is not enough.
- Sustained concurrent speech is the major open cell: no surveyed system stably demonstrates it, and it remains absent from public training/evaluation in a way that makes the gap structural, not accidental.
Evaluation audit and the realization gap
The evaluation section argues that conventional speech metrics are inadequate for full-duplex systems by construction. WER evaluates ASR, MOS evaluates TTS, BLEU evaluates response generation, and end-of-turn latency evaluates scheduling; none of them asks the full-duplex question, namely, what should the system do frame by frame while the user is still speaking? The paper’s answer is that the field needs interaction-level benchmarks, not just module-level metrics.
A notable contribution of the survey is the disambiguation of two benchmark lines that are often conflated: Full-Duplex-Bench (FDB), a versioned behavioral suite, and FD-Bench, an independent configurable benchmark generator. The paper stresses that they are not interchangeable and should be cited precisely.
| Benchmark family | What it is | What it is good for | Key limitation emphasized by the survey |
|---|---|---|---|
| Talking Turns | Judge model trained on Switchboard turn-taking statistics | Anchoring evaluation in human-human dialogue distributions | Does not cover backchannel-as-listener or third-party speech |
| FDB v1 | Static benchmark with pause, backchannel, turn-taking, and interruption metrics | Basic overlap and handoff behavior | English-dominant and single-turn in spirit |
| FDB v1.5 | Decomposes overlap into interruption, backchannel, talking-to-others, and background speech | Best public coverage of the $T_3$ row | Still not a primary concurrent-speech test |
| FDB v2 | Multi-turn automated examiner | Active probing of correction, entity tracking, and interaction dynamics | Only partially reaches $T_4$; still scripted rather than truly adaptive |
| FDB v3 | Tool-using voice-agent evaluation | Interaction in a larger agent stack | Less about core FD behavior in isolation |
| Easy Turn test set | Four-class turn classification benchmark | Large public open-source turn-taking evaluation | Does not test barge-in or concurrent speech directly |
| HumDial Challenge 2026 | Dual-channel real-human corpus and leaderboard | Standardized public evaluation event | Still leaves sustained concurrency as the largest gap |
The evaluation section introduces the term realization gap for the discrepancy between what a system can do architecturally and what it actually does on the benchmark after training. The paper gives a representative example: two $L2$ flattened-family systems can share architectural reach, but one may demonstrate backchannel or concurrent capability on FDB while another does not. The explanation is not architecture alone; it is the interaction between architecture and training-data cell coverage.
The survey’s recommendation is therefore that every FD system be reported with a three-part profile: its $L$-layer, its training-data cell-coverage profile, and its benchmark-documented per-cell behavior. A single aggregate score is too coarse because it hides whether the bottleneck is architecture, data, or benchmark design.
The paper also identifies three regime-level gaps: the heavy reliance on static pre-recorded scenarios, the dominance of English telephone or Zoom acoustics in public tests, and the absence of explicit causal-influence probes that would distinguish substantive FD behavior from apparent FD behavior. The last of these is highlighted as the most actionable benchmark frontier.
Evaluation-side summary of the realization gap
In the paper’s framing, architecture sets the ceiling, data realizes some fraction of that ceiling, and evaluation reports the fraction realized. This is why the authors argue that evaluating only latency or only turn-taking accuracy is insufficient: those numbers cannot tell you whether the system is fundamentally incapable, insufficiently trained, or simply poorly benchmarked.
Frontiers: toward $L3$ representation-level modeling
The survey treats $T_4$ sustained concurrent speech as the main residual gap within the $L0$--$L2$ frame, but it argues that the deeper frontier is $L3$, where the duplex decision would live in a shared latent representation rather than in tokens or sidecar modules.
The paper proposes three concrete hypothesis families for $L3$. First is continuous-latent autoregressive streaming, which uses continuous-valued tokens or flow-matching-style detokenization to remove the codebook bottleneck. Second is JEPA-style dual-stream prediction, where a latent representation is learned by predicting masked future regions from visible context. Third is world-model-conditioned dialogue, where the latent encodes dialogue state such as floor ownership, recent content, and expected next action.
The obstacles are also explicit: the discrete-tokenizer ecosystem is entrenched; real-time continuous-latent streaming is not yet at the latency of the best $L2$ systems; and there is no agreed mathematical definition of what a dialogue latent should encode. For that reason, the paper treats $L3$ as a live research hypothesis rather than an existing class of models.
Conclusions and limitations
The paper’s final conclusion is that the field needs to stop asking the binary question “is it full-duplex?” and start asking structured questions: where is the decision made, which interaction cells are covered, and what evidence exists that those cells are realized in practice? The three frameworks proposed in the survey are intended to make those answers comparable across systems, corpora, and benchmarks.
The limitations section is concise but important. First, the per-system and cell-coverage audits rely on self-reported behaviors and published evidence rather than independent end-to-end reproductions, and some industrial systems are closed-source. Second, the framework is calibrated to current $L0$--$L2$ systems; if a genuine $L3$ system introduces novel interaction primitives, the ontology and state machine will need to be extended rather than simply applied.
Overall, the survey’s technical contribution is a shared vocabulary for a rapidly proliferating area: a hierarchy that locates the duplex decision, an ontology that defines interaction cells, and a state machine that turns those cells into operational traces. Its empirical contribution is the realization-gap diagnosis, which explains why architecture alone cannot predict full-duplex performance and why future gains likely depend on better type-C corpora, sharper benchmarks, and eventually a representation-level $L3$ design.
Code & Implementation
This repository serves as a comprehensive survey and empirical audit of full-duplex spoken dialogue systems rather than a source of original code implementations. It provides a rich collection of conceptual frameworks, visual summaries, and an organized audit of existing full-duplex systems categorized by architectural hierarchy, interaction ontology, and decision state machine.
The repo contains extensive documentation and visual assets that illustrate the paper's core contributions, including the L0-L3 architectural hierarchy, the T x I x R interaction ontology, and the full-duplex decision state machine. However, it does not contain runnable source code or implementations of dialogue systems themselves.
Instead, this repository functions as a structured resource collecting public models, datasets, and benchmarks to support future research in full-duplex dialogue. Users interested in reproducing or extending experiments should refer to the linked external repositories and datasets listed in the Appendix section.