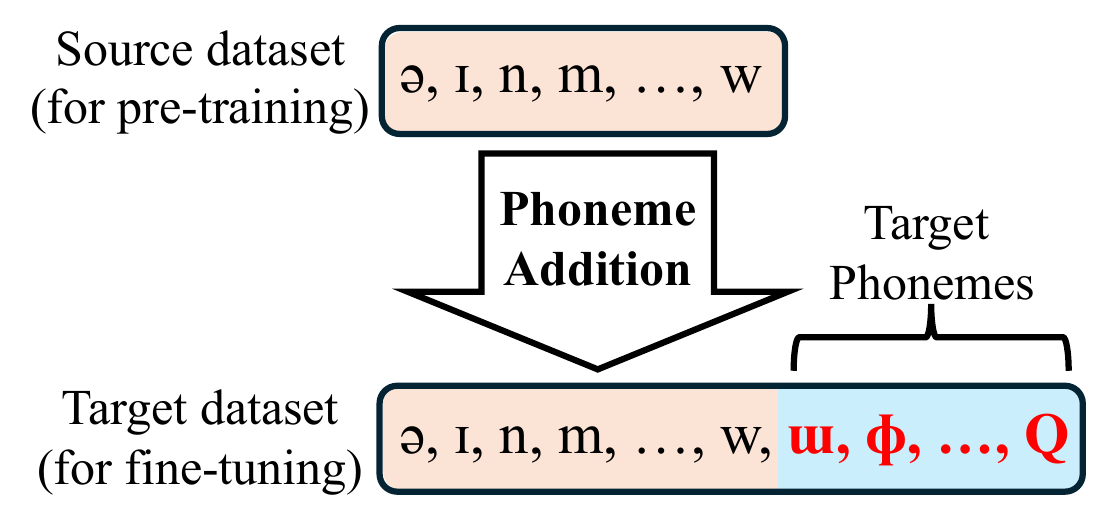
Phoneme Addition Transfer
Exploring Pre-training Benefits on Phoneme Addition through Fine-tuning in Speech Synthesis
This paper studies how pre-training impacts adding new phonemes during fine-tuning in text-to-speech. Using a synthetic phoneme-controlled setup and real cross-lingual transfer, it shows pre-training mainly boosts naturalness but offers limited help for learning new phonemes.
Links
Paper & demos
Abstract
Transfer learning is widely used for low-resource text-to-speech. When the target corpus contains phonemes unseen in pre-training, the model must expand its phoneme inventory during fine-tuning; we call the process "phoneme addition." However, it remains unclear whether the pre-trained ability to generate seen phonemes contributes to this process. This study investigates phoneme addition in two settings: (1) a simulation setup using LLM-generated phoneme-controlled corpora that enables investigation without considering confounding factors, and (2) a real-speech cross-lingual transfer setup (English to Japanese) to validate whether the findings hold in practice. Experiments in both settings showed that while fine-tuning achieved higher naturalness than training from scratch, it required as much or more data to achieve comparable PER for new phonemes. These results indicate that pre-training mainly contributes to naturalness improvement, but offers limited benefit for phoneme addition.
1. Problem Setting and Core Question
This paper studies phoneme addition in low-resource text-to-speech (TTS) transfer learning. The setting is common in practice: a model is pre-trained on a source language or source corpus, then fine-tuned on a target corpus that includes phonemes not present during pre-training. The central question is not simply whether transfer learning improves overall synthesis quality, but whether the pre-trained ability to generate already-seen phonemes actually helps the model learn new target phonemes during fine-tuning.
The authors define the pre-trained ability to generate seen phonemes as pre-trained phoneme knowledge. They argue that prior work on low-resource TTS often reports gains in naturalness and intelligibility, but does not isolate whether those gains come from easier acquisition of unseen phonemes or from other benefits of pre-training. This paper therefore compares fine-tuning against training from scratch on the same target data, with a focus on the target phoneme inventory expansion itself.
The headline conclusion is nuanced: across both a controlled synthetic setting and a real cross-lingual setting, fine-tuning consistently improves perceived naturalness, but it does not provide a strong advantage for learning new phonemes. In terms of target phoneme error rate, fine-tuning often needs as much or more target data than scratch training to reach comparable performance.
2. Main Idea and Contributions
The paper makes two contributions.
- It introduces an LLM-generated phoneme-controlled simulation framework that isolates phoneme addition from confounds such as language mismatch, speaker variation, and dataset-domain mismatch.
- It validates the same phenomenon in a real-speech cross-lingual transfer experiment from English to Japanese.
The simulation framework is especially important because it allows the authors to vary dataset size and target phoneme type while keeping the language and target speaker fixed. This lets them study phoneme addition in a more controlled way than ordinary cross-lingual experiments, where multiple factors change at once.
Across both settings, the paper finds the same pattern: pre-training mainly helps naturalness, but offers limited benefit for phoneme addition.
3. Method: Phoneme-Controlled Corpus Generation with an LLM
The core methodological device is a pair of synthetic corpora generated with Claude Opus 4.6 and filtered at the phoneme level using espeak-ng IPA conversion.
3.1 Limited Corpus for pre-training
The Limited Corpus simulates pre-training on a source corpus that never exposes the model to the target phonemes. The authors first build an allowed word list of more than 23,000 words from the CMU Pronouncing Dictionary, keeping only words that contain none of the target phonemes. They then prompt the LLM to generate natural English sentences of 3 to 15 words using only this word list.
Each generated sentence is converted to IPA with espeak-ng and checked for the absence of target phonemes. Invalid sentences are discarded. From the verified pool, 1,000 sentences are sampled so that the text statistics approximately match VCTK in terms of phoneme count and word-count distribution. The sentences are then synthesized by a prepared TTS model to create speech--phoneme pairs for pre-training.
3.2 Full Corpus for fine-tuning
The Full Corpus simulates a target corpus that includes both seen and unseen phonemes. The LLM is prompted to generate natural English sentences with a word-count distribution matched to VCTK. After deduplication, each sentence is converted to IPA and required to contain at least one target phoneme. The authors report that this yields about 30,000 valid sentences. They then sample 2,000 sentences and synthesize speech from them using the same TTS pipeline.
The resulting corpora are intended to share the same language, speaker identity for the fine-tuning target, and synthesis pipeline, so that any difference between fine-tuning and scratch training can be attributed more directly to the role of pre-training.
3.3 Corpus statistics
The paper reports statistics for the synthetic corpora and the VCTK reference, computed over 1,000 randomly sampled sentences. The synthetic corpora are designed to closely match VCTK, while the Limited Corpus deliberately removes the target phonemes.
| Dataset | Target type | Unique phonemes | Unique words | Avg. phonemes / utterance | Avg. target phonemes / utterance | Avg. words / utterance |
|---|---|---|---|---|---|---|
| VCTK | Plosives | 40 | 1,743 | 26.1 | 4.83 | 7.4 |
| VCTK | Front vowels | 40 | 1,743 | 26.1 | 4.82 | 7.4 |
| Full | Plosives | 40 | 1,643 | 25.9 | 4.81 | 7.1 |
| Full | Front vowels | 40 | 1,686 | 26.3 | 4.79 | 7.1 |
| Limited | Plosives | 34 | 865 | 25.1 | 0 | 7.2 |
| Limited | Front vowels | 35 | 875 | 22.4 | 0 | 7.1 |
4. Model, Training, and Evaluation Protocol
4.1 TTS architecture and training recipe
The paper uses the Conformer-FastSpeech2 (CFS2) implementation from ESPnet. For pre-training, the authors follow the ESPnet configuration used for VCTK, except that they condition on speaker ID rather than x-vectors.
For fine-tuning, they adopt a naive fine-tuning strategy aligned with prior work: the phoneme inventory is expanded to include the unseen target phonemes, and only the embeddings for those new phonemes are randomly initialized. They also remove speaker conditioning so that fine-tuning is performed as a single-speaker model. The learning rate is reduced to one-tenth of the original value. The authors note that preliminary experiments showed only limited sensitivity to the learning rate choice.
The scratch baseline is a single-speaker CFS2 model trained from random initialization on the same target data used for fine-tuning. For waveform synthesis, the study uses a pre-trained HiFi-GAN vocoder from the ParallelWaveGAN repository, trained on VCTK.
4.2 Target phoneme error rate and naturalness
The paper evaluates two aspects of performance:
- Target PER: a phoneme error rate computed only on the newly added target phonemes, using a wav2vec 2.0-based phoneme recognizer. This is the key metric for phoneme addition.
- UTMOS: an automatic naturalness metric that estimates mean opinion score for synthesized speech.
Target PER is analogous to a biased error-rate metric: it focuses exclusively on the phonemes that were unseen in pre-training, so it measures whether the model actually learned the new inventory rather than merely sounding good overall.
4.3 Data sizes compared
In both the simulated and real-speech experiments, the authors compare fine-tuning and scratch training at the same data budgets: $100$, $300$, $500$, $800$, $1000$, and $2000$ utterances, each randomly sampled from the target dataset.
| Setting | Pre-training data | Fine-tuning data | Target phonemes | Test texts |
|---|---|---|---|---|
| Simulated phoneme-controlled | Limited Corpus / synthetic speech from 107,000 utterances, 55 hours, 107 speakers excluding target speaker p299 | Full Corpus / 2,000 utterances from target speaker p299 | Plosives: /p/, /b/, /t/, /d/, /k/, /g/; Front vowels: /i/, /I/, /eI/, /E/, /ae/ | 1,000 VCTK sentences containing at least one target phoneme |
| Real-speech cross-lingual | VCTK English, about 44 hours from 108 speakers | JSUT basic5000, about 10 hours from one Japanese female speaker | 20 Japanese-specific phonemes added to the 40-symbol English inventory | 100 Japanese sentences from JVS |
5. Simulated Phoneme-Controlled Experiment
This is the paper’s main controlled study. Because both the pre-training and fine-tuning corpora are synthetic and share the same text-to-speech generation pipeline, the authors can focus on the specific effect of phoneme addition without confounding factors such as language mismatch, speaker change, or domain shift.
5.1 Target phoneme groups
The authors test two kinds of unseen target phonemes:
- Plosive consonants: /p/, /b/, /t/, /d/, /k/, /g/
- Front vowels: /i/, /I/, /eI/, /E/, /ae/
This choice lets them check whether the difficulty of phoneme addition depends on phoneme class, not just on data size.
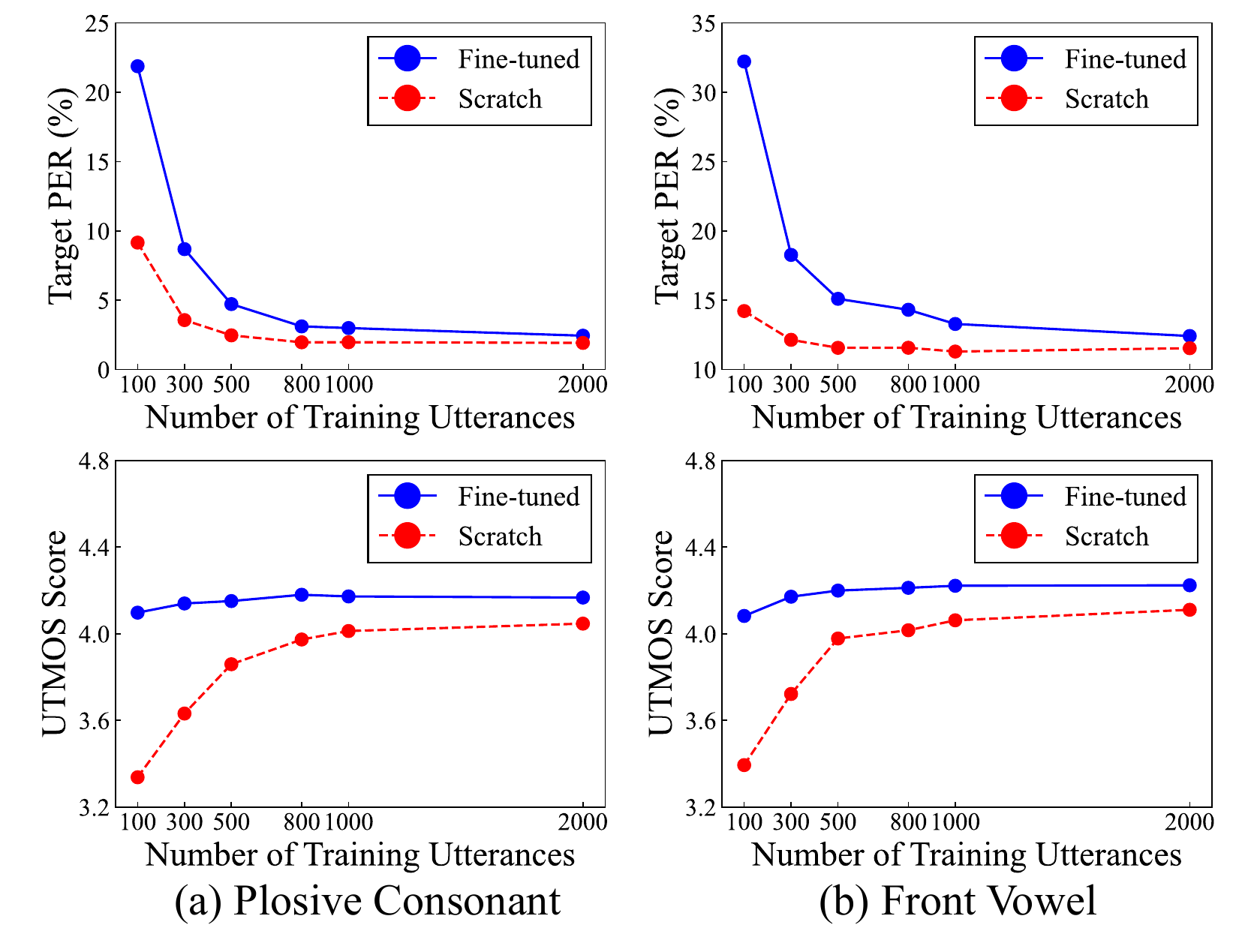
5.2 Main result on target phoneme acquisition
The key finding is that scratch training matches or outperforms fine-tuning on Target PER for both target phoneme groups across the evaluated data sizes. In other words, although fine-tuning starts from a model that already knows how to generate the source phonemes, that prior knowledge does not translate into a clear advantage for learning the new phonemes.
The paper states that fine-tuning requires approximately the same or more data than scratch training to reach comparable target phoneme recognition error, regardless of whether the target phones are plosives or front vowels. This is the central empirical result that challenges the common intuition that pre-training should directly accelerate phoneme addition.
5.3 Main result on naturalness
In contrast to the target-phoneme accuracy results, fine-tuning consistently achieves better UTMOS than scratch training across both phoneme groups and across all data budgets. The advantage is especially visible in the lower-resource conditions. This suggests that pre-training still matters, but its benefit is concentrated in global speech quality and naturalness rather than in the acquisition of unseen phonemes.
5.4 Qualitative spectrogram analysis
The authors also inspect spectrograms for the plosive case. In the low-resource regime with $100$ utterances, the scratch-trained model more clearly produces plosive closure patterns. With more than $1000$ utterances, the two approaches become more comparable. The paper uses this observation to argue that scratch training can learn all phonemes jointly without the constraint of preserving prior knowledge, whereas fine-tuning must both retain previously learned phoneme behavior and acquire new target phones, which may make phoneme addition harder.
6. Real-Speech Cross-Lingual Experiment
The second experiment checks whether the simulated findings also appear in a practical cross-lingual TTS transfer scenario.
6.1 Setup: English to Japanese
The source language is English with VCTK as the pre-training corpus. The target language is Japanese with JSUT basic5000 as the fine-tuning corpus. The Japanese text is converted into phoneme sequences using pyopenjtalk and mapped to IPA symbols.
During fine-tuning, the authors expand the English phoneme vocabulary of 40 symbols by adding 20 Japanese-specific phonemes that were unseen in English pre-training. These include vowels, stops, affricates, fricatives, nasals, a flap, and a geminate consonant.
The evaluation uses $100$ Japanese sentences from the JVS corpus as test texts, and a wav2vec 2.0-based Japanese phoneme recognizer fine-tuned on JSUT basic5000 to compute PER.
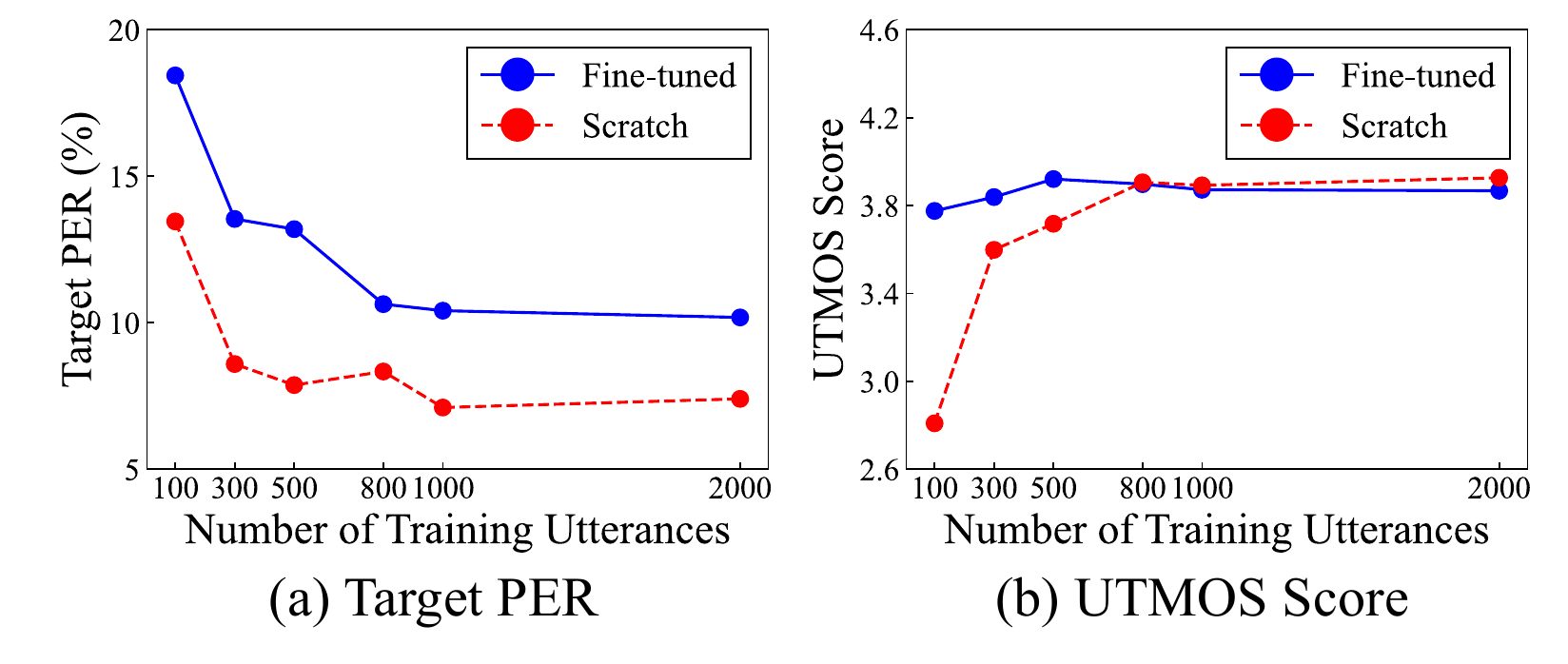
6.2 Cross-lingual results
The cross-lingual results replicate the main pattern from the controlled experiment. For the Japanese-specific target phonemes, scratch training consistently achieves better Target PER than fine-tuning across all data sizes. This indicates that the limited usefulness of pre-trained phoneme knowledge is not just an artifact of synthetic data generation; it also appears in a real speech adaptation setting.
At the same time, fine-tuning improves naturalness. UTMOS is higher or comparable for fine-tuning, especially in the lower-resource regimes of $100$, $300$, and $500$ utterances. So the practical trade-off is the same as in the simulation: pre-training helps the acoustic and perceptual quality of the synthesized speech, but does not strongly speed up acquisition of unseen target phones.
7. Interpretation and Takeaways
The paper’s results lead to a clear interpretation. Pre-training does provide useful knowledge for TTS transfer learning, but that knowledge seems to be more about producing pleasant-sounding speech than about efficiently incorporating new phonemes into the inventory. In the specific task of phoneme addition, the model appears to face a strong constraint: it must add new categories while preserving old ones, and this may reduce the advantage of pre-training compared with learning everything jointly from scratch.
This is an important caution for low-resource and cross-lingual TTS. A better overall MOS after fine-tuning does not necessarily imply better phoneme learning. If the goal is accurate generation of previously unseen phonemes, then naively fine-tuning a pre-trained model may be no better than, and sometimes worse than, training from scratch on the same target data.
8. Limitations and Future Directions
The paper’s limitations are mainly implicit in its experimental design and discussion:
- The controlled simulation uses synthetic speech synthesized from text generated by an LLM, so it isolates the phoneme-addition effect but does not fully represent all complexities of natural speech corpora.
- The real-speech validation covers a single cross-lingual direction, English to Japanese, so the generality to other language pairs is not tested here.
- The evaluation relies on automatic metrics: a phoneme recognizer for Target PER and UTMOS for naturalness. These are useful proxies, but they are not a substitute for direct human perception judgments.
- The paper studies the naive fine-tuning baseline. More specialized mechanisms for phoneme addition may behave differently.
In the conclusion, the authors suggest two future directions: using pre-trained models with broad phoneme inventories so that fewer target phones are unseen, and adding an auxiliary loss that explicitly encourages learning the new phonemes. They frame both as possible ways to make pre-training more effective for tiny target datasets.
9. Bottom-Line Summary
The paper provides a careful, two-setting analysis of phoneme addition in TTS transfer learning. Its main result is that pre-training is valuable for improving the overall naturalness of synthesized speech, but it offers limited direct benefit for adding unseen phonemes. In both the controlled simulation and the English-to-Japanese real-speech transfer setting, fine-tuning did not reduce the amount of data needed to learn the new phonemes, and scratch training often matched or outperformed it on target phoneme accuracy.