Zero-VC
Zero-VC: Zero-Lookahead Streaming Voice Conversion via Speaker Anonymization
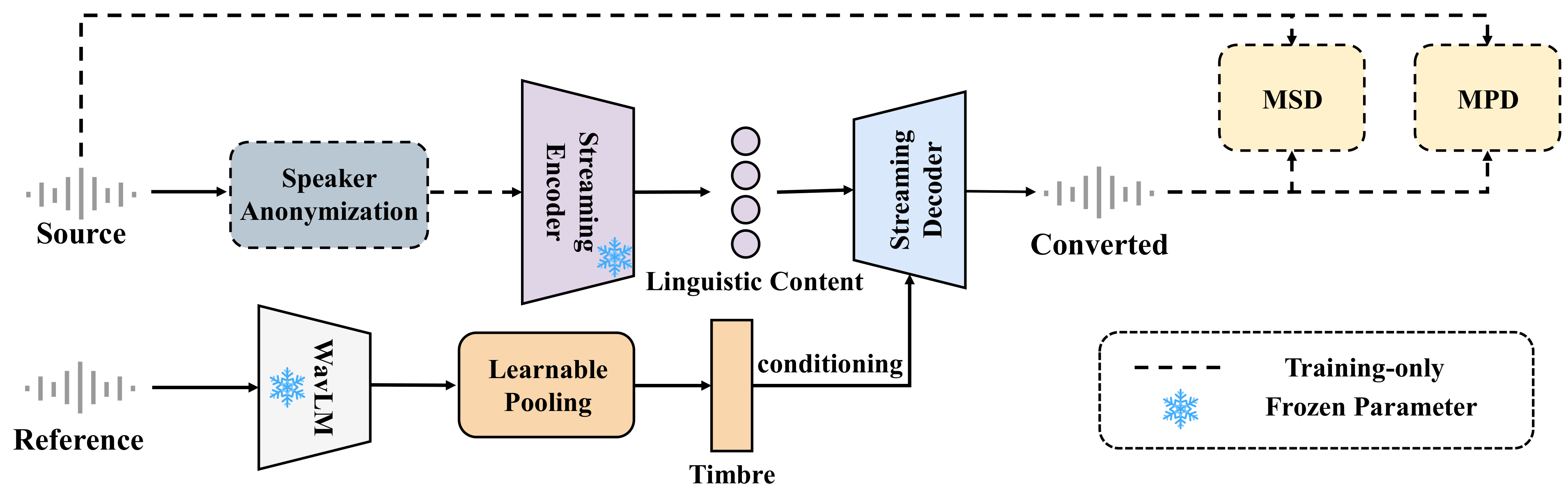
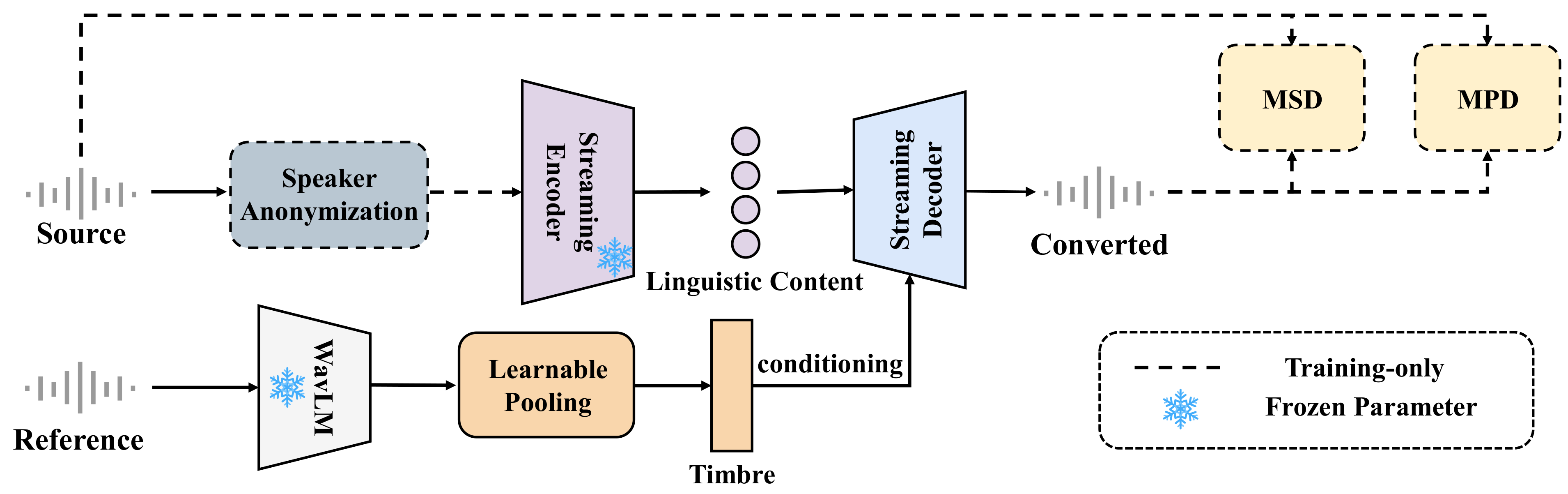
Zero-VC uses speaker anonymization to enable zero-lookahead streaming voice conversion that minimizes timbre leakage while preserving prosody. This real-time approach better balances identity hiding and utility, allowing low-latency conversion to unseen speakers without buffering future audio frames.
Demos
These demos highlight Zero-VC's zero-lookahead streaming voice conversion system, which converts voices in real-time with minimal latency. Key evaluation points include how well the system balances reducing source timbre leakage with preserving target speaker similarity, the reduced need for future frame buffering through Speaker Anonymization, and its superior algorithmic latency versus other VC methods.
Links
Paper & demos
Code & resources
Abstract
Streaming zero-shot voice conversion struggles to disentangle timbre from linguistic content without degrading utility or inflating latency. Current methods rely on information bottleneck (IB) or speaker perturbation. While IB filters out timbre, it discards prosody, forcing models to explicitly inject features like fundamental frequency. This often requires buffering future frames, creating algorithmic lookahead latency. On the other hand, existing perturbation methods largely overlook the crucial trade-off between timbre leakage and utility preservation. Recognizing this neglected trade-off, we find that the inherent objective of Speaker Anonymization (SA) aligns well with balancing these factors. Thus, we introduce SA as a novel perturbation mechanism to explicitly mitigate timbre leakage while retaining prosodic utility. Crucially, SA's robust representations significantly alleviate the generator's reliance on future context, enabling our strictly causal, zero-lookahead network. Audio samples are available at https://amphionteam.github.io/Zero-VC-demo/.
Introduction
Zero-VC addresses streaming zero-shot voice conversion under a strict real-time constraint: the system must convert a source speaker to an unseen target speaker while preserving intelligibility and prosody, but without buffering future frames. The paper frames this as a disentanglement problem between source timbre and linguistic content under ultra-low latency. Its central claim is that prior streaming approaches have focused too narrowly on either information bottlenecks or generic perturbation, and that the missing design axis is the trade-off between timbre leakage and utility preservation.
The paper argues that information bottlenecks such as discrete units or articulatory features can suppress source identity, but they also discard useful paralinguistic information, especially prosody. In practice, this forces models to inject explicit acoustic side information such as $f_0$, which often requires future-frame buffering and therefore creates algorithmic lookahead. By contrast, existing perturbation methods may preserve more utility, but they are not explicitly designed to optimize the leakage-versus-utility balance.
Zero-VC’s core idea is to use Speaker Anonymization (SA) as the perturbation mechanism during training. The authors interpret SA as a better fit for voice conversion because it is intended to hide speaker identity while preserving linguistic and prosodic content. They report that SA-perturbed representations are informative enough that the downstream generator relies far less on future context, allowing a strictly causal architecture with zero lookahead. In the paper’s framing, the system reaches the single-frame latency floor of 20 ms.
The paper’s stated contributions are threefold: first, identifying the leakage-utility trade-off as a key issue for streaming perturbation methods and introducing SA as a better perturbation mechanism; second, showing that SA reduces dependence on future context enough to enable a strictly causal zero-lookahead design; and third, demonstrating strong conversion quality together with minimal latency.
Figure: Overall framework
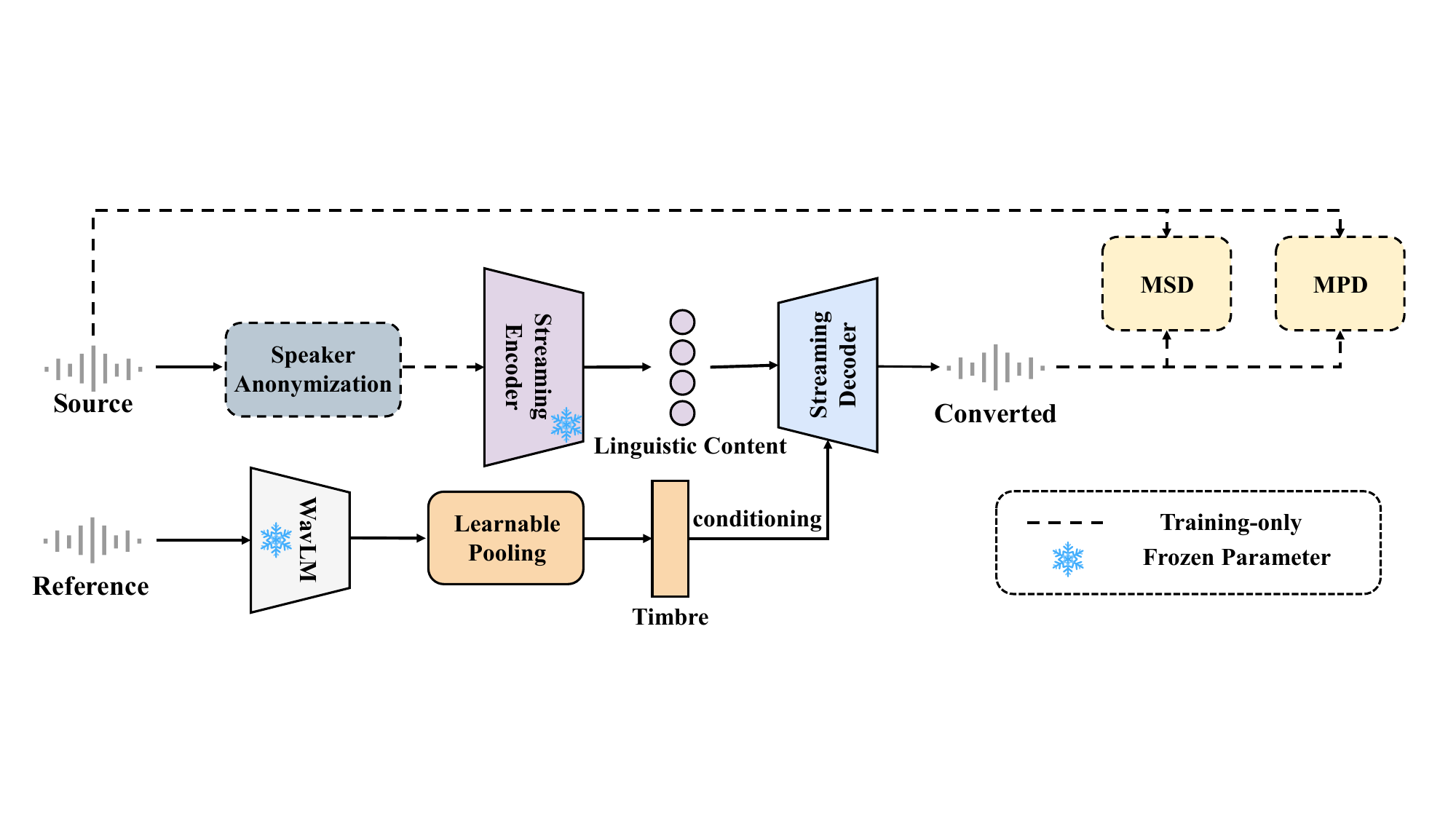
Method
System overview
Zero-VC is a strictly causal streaming VC model with three functional parts at inference time: a pretrained streaming encoder for content extraction, a timbre encoding module, and a streaming decoder. The SA module and the discriminators are used only during training and are removed after training. The system is designed to operate chunk-by-chunk with a frame shift of 20 ms and no future lookahead.
SA-based content extraction
Source speech is first processed by an off-the-shelf Speaker Anonymization module. The paper characterizes SA as mapping the speaker identity into a pseudo-speaker space while preserving temporal alignment, prosodic contours, and phonetic integrity. This differs from a destructive bottleneck: rather than compressing away information, SA perturbs the speaker identity itself so the downstream encoder sees audio that is largely stripped of source timbre but still useful for linguistic and prosodic modeling.
The anonymized audio is then fed to a streaming encoder without future lookahead. The encoder generates acoustic representations every 20 ms. Because the input has already been anonymized rather than aggressively filtered, the resulting content features are intended to preserve utility dynamics that would otherwise be lost in a strict information bottleneck.
Timbre encoding
To condition conversion on the target voice, the paper uses WavLM-large to extract reference-speaker features. Specifically, hidden states from the seventh transformer layer are taken as frame-level representations $H = [h_1, h_2, \dots, h_L]$. An attention-based learnable pooling layer turns these variable-length features into a fixed-length timbre embedding. The attention weights are computed as
$$ \alpha_i = \frac{\exp(W_p h_i)}{\sum_{j=1}^{L} \exp(W_p h_j)}, \qquad c_{\text{timbre}} = \sum_{i=1}^{L} \alpha_i h_i. $$
The paper’s interpretation is that the attention mechanism lets the network focus on the most speaker-discriminative regions of the reference utterance, yielding a global target-speaker condition $c_{\text{timbre}}$.
Streaming decoder and training losses
The decoder is based on HiFi-GAN, but modified for zero-lookahead streaming. All standard convolutions are replaced with causal convolutions so that each output frame depends only on past and current frames. Timbre conditioning is injected through a three-layer Conv1D stack, following the style of prior HiFi-GAN conditioning. In the paper’s notation, an intermediate feature map $x$ is shifted by the timbre-conditioning network as
$$ x' = x + \operatorname{Convs}(c_{\text{timbre}}). $$
Training follows the adversarial recipe of HiFi-GAN with a Multi-Scale Discriminator and a Multi-Period Discriminator. The generator objective is a weighted sum of mel-spectrogram loss, feature matching loss, and adversarial loss:
$$ \mathcal{L}_G = \lambda_{\text{mel}} \mathcal{L}_{\text{mel}} + \sum_{k=1}^{K} \big[ \lambda_{\text{fm}} \mathcal{L}_{\text{fm}}(G; D_k) + \lambda_{\text{adv}} \mathcal{L}_{\text{adv}}(G; D_k) \big], $$
and the discriminator objective is
$$ \mathcal{L}_D = \sum_{k=1}^{K} \mathcal{L}_{\text{adv}}(D_k; G), $$
where $D_k$ denotes the $k$-th sub-discriminator across the MPD and MSD groups. The reported loss weights are $\lambda_{\text{fm}} = 3$, $\lambda_{\text{mel}} = 51$, and $\lambda_{\text{adv}} = 1$.
Streaming inference strategy
At inference time, Zero-VC processes audio in 20 ms chunks and maintains only the causal-convolution cache needed by the receptive field. The paper emphasizes that the per-frame computational complexity remains constant, $O(1)$ with respect to sequence length, because the model never requires a growing future-context buffer. This is the mechanism behind the claimed zero-lookahead latency.
Experimental setup
Training data
The model is trained on LibriTTS, an English corpus with 585 hours of speech. Utterances shorter than 4 seconds are removed, and all audio is resampled to 16 kHz, leaving approximately 460 hours of training data.
Evaluation data
Evaluation uses the English subset of seed-tts-eval, which the paper describes as containing approximately 1,000 pairs sampled from Common Voice.
Evaluation metrics
The paper reports objective and subjective metrics targeting different aspects of conversion quality. Speaker similarity is measured with a WavLM-large speaker-verification model through cosine similarity between embeddings of the converted speech and either the source or reference speech. These are reported as SS-S, where lower values indicate less source leakage, and SS-R, where higher values indicate better target similarity. Intelligibility is measured by Word Error Rate using Whisper-large-v3. Prosody preservation is measured with F0 Pearson Coefficient. Overall perceptual quality is estimated with DNSMOS P.835 as OVRL. Subjective evaluation includes NMOS and SMOS, each with 95% confidence intervals.
Implementation details
The final VC model is trained for 1.2 million steps, while ablation models are trained for 120k steps. Optimization uses AdamW with $\beta_1 = 0.8$, $\beta_2 = 0.99$, learning rate $6 \times 10^{-4}$, and weight decay 0.01, together with a cosine-annealing scheduler. Batch size is 30, and each batch contains a 2-second source segment and a 2-second reference segment.
Ablation studies on speaker perturbation
The paper’s ablation strategy is organized around a central claim: the perturbation module should reduce source timbre leakage without collapsing prosodic utility. To test this, the authors compare the intermediate audio produced by LSCodec-style perturbation, Seed-VC perturbation, and SA. They also train identical VC models on these perturbed representations to study downstream utility preservation.
| Method | SS-S | WER (%) | FPC | OVRL |
|---|---|---|---|---|
| LSCodec-Perturb | 0.704 | 2.15 | 0.891 | 3.054 |
| Seed-VC-Perturb | 0.411 | 4.45 | 0.688 | 3.249 |
| SA | 0.119 | 8.33 | 0.718 | 3.175 |
The intermediate-audio results show a clear separation between leakage suppression and utility retention. LSCodec-Perturb has strong WER and F0 correlation, but very poor SS-S, indicating substantial timbre leakage. Seed-VC-Perturb reduces leakage, but its prosodic preservation drops. SA achieves the lowest SS-S by a wide margin, showing that it is the most aggressive at removing source identity while still retaining better F0 correlation than Seed-VC-Perturb. The paper notes that SA’s WER is relatively high at this intermediate stage, but argues that this does not prevent the downstream VC model from learning useful content representations.
| Method | WER | FPC | OVRL |
|---|---|---|---|
| LSCodec-Perturb | 2.64 | 0.681 | 3.097 |
| Seed-VC-Perturb | 2.67 | 0.659 | 3.093 |
| SA | 3.82 | 0.671 | 3.040 |
When the VC systems are trained end-to-end on these different perturbation strategies, the trade-off becomes more nuanced. LSCodec-Perturb obtains the best WER, FPC, and OVRL in this isolated table, but the authors caution that these utility metrics are less informative when source leakage remains high, because the system can appear to preserve prosody simply by reconstructing source-like speech. SA yields slightly weaker WER and OVRL than the strongest baselines, but the paper emphasizes that it maintains competitive utility while producing a much better speaker-similarity balance overall.
Trade-off analysis and lookahead dependence
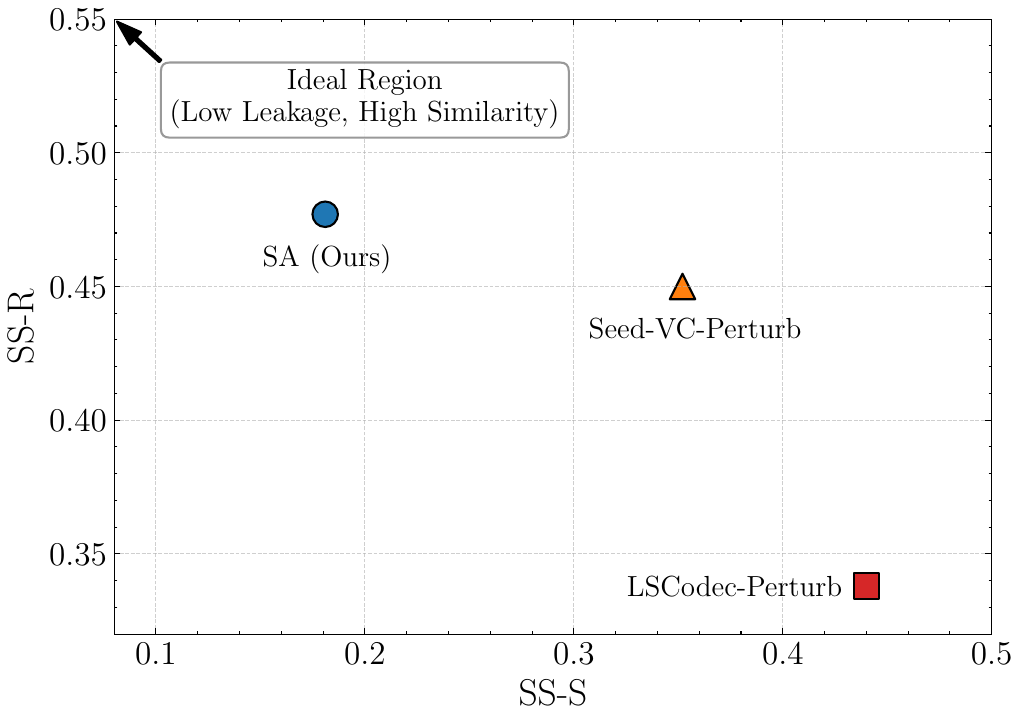
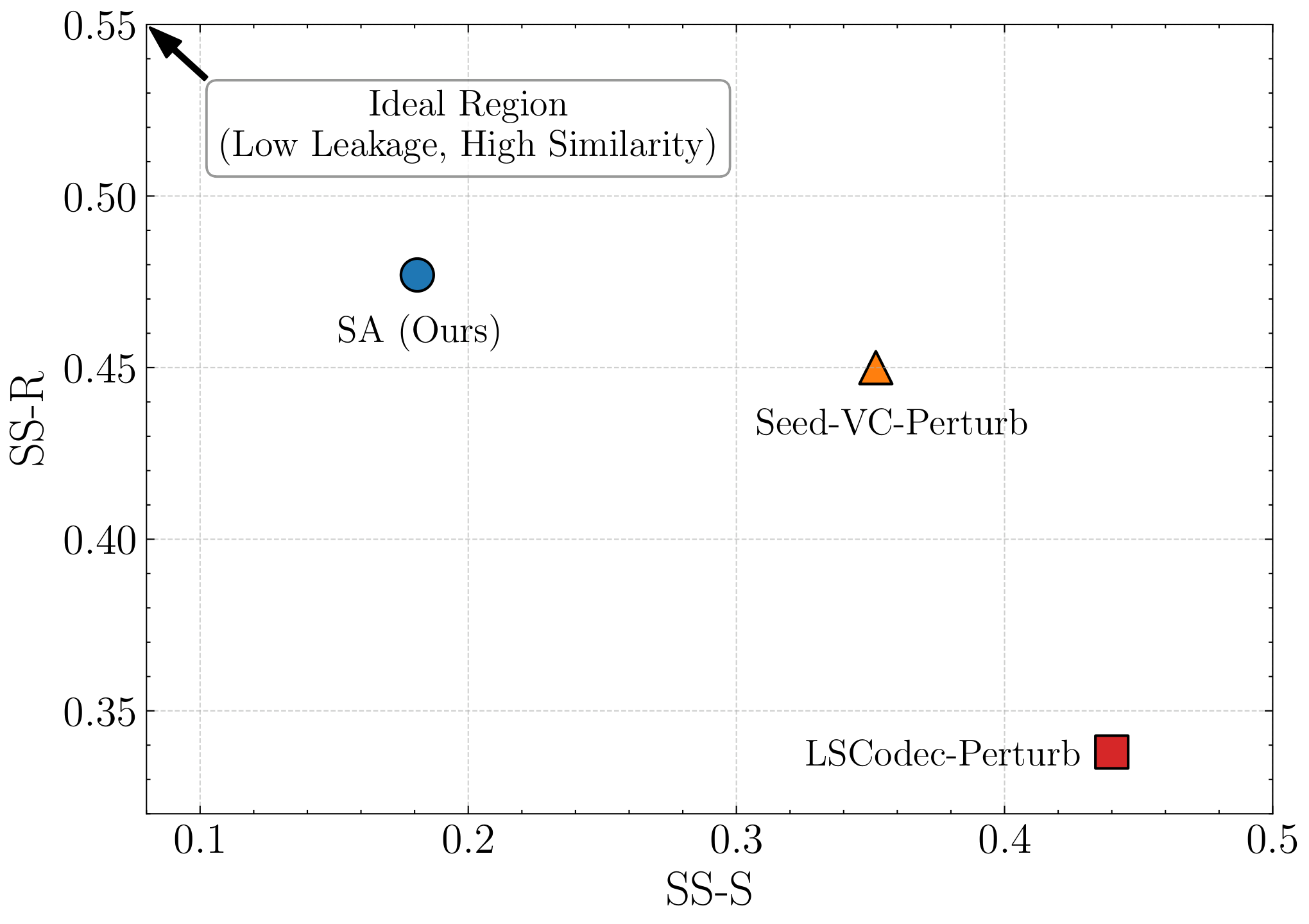
The scatter plot analysis positions SA closest to the desirable top-left region, meaning low source similarity and high reference similarity. This is the paper’s main empirical support for the claim that SA better balances timbre leakage and target conversion than LSCodec-Perturb or Seed-VC-Perturb. In the authors’ interpretation, SA is not just another perturbation method; it is explicitly optimized to hide identity while preserving the information needed by the generator.
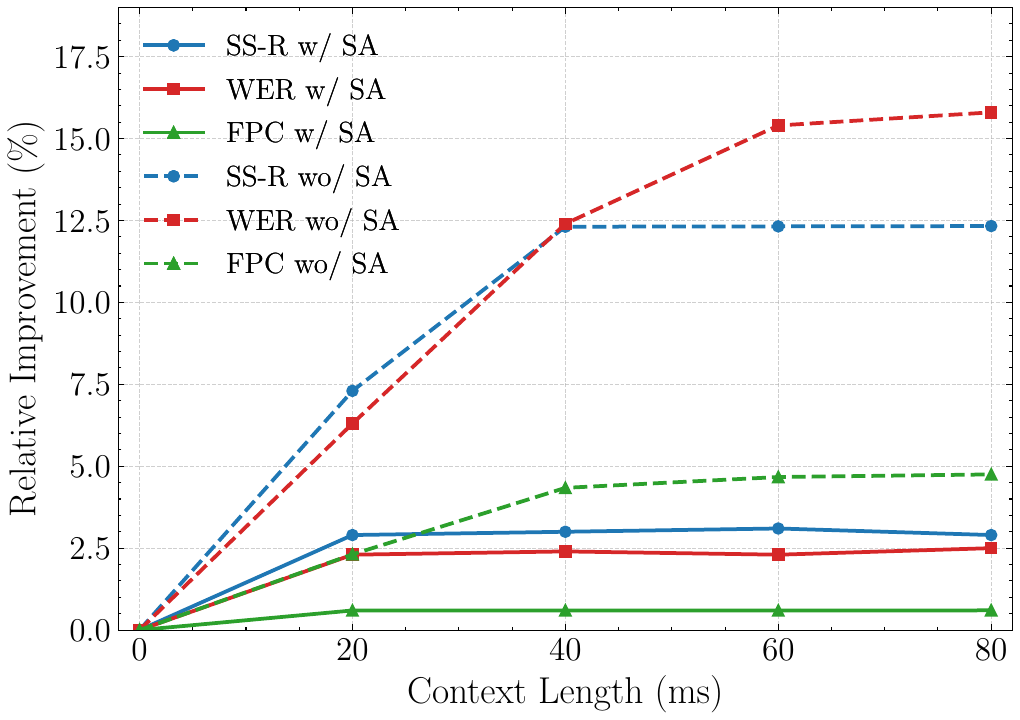
The lookahead analysis is one of the paper’s key architectural arguments. With SA-perturbed inputs, performance saturates almost immediately between 0 and 20 ms of lookahead, and the paper reports less than a 3% relative improvement even when lookahead is increased to 80 ms. By contrast, without SA the model depends much more strongly on future context; WER and SS-R improve by more than 12% to 15% only once 40 to 60 ms of future frames are available. The authors use this to justify the claim that SA reduces the generator’s need for future information, making a zero-lookahead decoder viable.
Zero-shot voice conversion results
The main comparison studies Zero-VC against several open-source non-streaming systems for quality, and against recent streaming systems for latency. The paper notes that a fair end-to-end comparison to many recent streaming baselines is difficult because several of them are closed source, so the authors report algorithmic latency separately.
| Group | Method | SS-S | SS-R | SMOS | WER (%) | FPC | OVRL | NMOS | RTF |
|---|---|---|---|---|---|---|---|---|---|
| Non-streaming | LSCodec | 0.277 | 0.426 | 3.64 ± 0.07 | 9.00 | 0.650 | 3.116 | 3.70 ± 0.06 | 0.077 |
| Non-streaming | CosyVoice | 0.313 | 0.502 | 3.78 ± 0.06 | 4.02 | 0.644 | 3.182 | 3.82 ± 0.05 | 2.441 |
| Non-streaming | Seed-VC-Small | 0.402 | 0.415 | 3.62 ± 0.09 | 2.47 | 0.661 | 3.141 | 3.77 ± 0.06 | 0.508 |
| Streaming | Zero-VC | 0.171 | 0.521 | 3.88 ± 0.05 | 3.96 | 0.688 | 3.044 | 3.81 ± 0.07 | 0.063 |
Zero-VC is the strongest system on source leakage and target similarity among the compared models, with the lowest SS-S at 0.171 and the highest SS-R at 0.521. It also attains the highest subjective speaker-similarity score, SMOS $3.88 \pm 0.05$, which the authors treat as evidence that zero-lookahead streaming does not prevent convincing zero-shot adaptation. In utility terms, Zero-VC is highly competitive: it obtains the best FPC at 0.688, second-best WER at 3.96%, and second-best NMOS at $3.81 \pm 0.07$, only slightly behind CosyVoice. The reported OVRL of 3.044 is lower than some non-streaming baselines, but the paper’s emphasis is that this result is achieved under a much stricter streaming constraint.
The reported real-time factor is 0.063 on an Intel Xeon Platinum 8468V-2.4 GHz CPU, which indicates that the implementation is lightweight enough for real-time operation in the tested setting.
Algorithmic latency
| Method | DualVC3 | StreamVC | RT-VC | Zero-VC |
|---|---|---|---|---|
| Algorithmic latency (ms) | 40 | 60 | 47 | 20 |
The latency comparison isolates algorithmic latency and explicitly excludes inference latency. Under this definition, Zero-VC reaches the minimum possible value of 20 ms because it uses only one 20 ms frame and does not require buffering future acoustic context for pitch smoothing or other feature estimation. The paper contrasts this with the 40-60 ms range of recent streaming methods, especially those based on information bottlenecks.
Interpretation of why SA helps
The paper’s main conceptual argument is that SA produces a richer intermediate representation than a strict bottleneck while still suppressing the source identity sufficiently for conversion. That balance matters because the decoder no longer has to reconstruct prosodic detail from impoverished features or compensate using future frames. In the authors’ view, SA provides a better operating point on the perturbation spectrum: it reduces source timbre leakage enough to support conversion, but it does not erase the timing and prosodic information that a streaming generator needs.
This explanation is consistent with both the lookahead-ablation curve and the quality tables. The SA-trained model gains little from extra lookahead, implying that the representation already contains enough local information. At the same time, the zero-lookahead model remains competitive on reference similarity, intelligibility, and prosodic preservation, which supports the claim that the SA perturbation resolves the trade-off more effectively than either of the compared baselines.
Limitations and future work
The paper identifies one explicit limitation: the current training pipeline depends on an off-the-shelf SA module for preprocessing source audio during training, which may introduce additional training overhead depending on the implementation. The authors suggest two main directions for future work: integrating the SA objective directly into an end-to-end training pipeline to reduce total system latency, and extending the framework to cross-lingual zero-shot voice conversion.
Conclusion
Zero-VC is presented as a strictly causal streaming zero-shot VC system that uses speaker anonymization to solve a practical latency-quality trade-off. The method combines SA-based content extraction, WavLM-based timbre encoding, and a HiFi-GAN-style causal decoder trained with adversarial, mel, and feature-matching losses. Empirically, the paper reports that SA improves the leakage-utility balance, substantially reduces reliance on future context, and enables 20 ms algorithmic latency while remaining competitive with stronger non-streaming systems on quality metrics.
Code & Implementation
This repository implements the speaker anonymization system described in the paper "Zero-VC: Zero-Lookahead Streaming Voice Conversion via Speaker Anonymization" using a modular pipeline approach.
The core anonymization pipeline is implemented in the anonymization/pipelines/sttts_pipeline.py (inferred from imports in run_anonymization.py), which follows a three-step process:
- Extraction of linguistic content, prosody, and speaker embeddings from input speech.
- Anonymization of speaker embeddings by substituting original embeddings with artificial ones generated via GANs, minimizing speaker identity leakage.
- Synthesis of anonymized speech using a FastSpeech2-like text-to-speech system combined with a HiFiGAN vocoder, including multilingual support via integrated Whisper-large-v3 ASR and IMS Toucan TTS frameworks.
The main entrypoint for running anonymization is run_anonymization.py, which loads configuration files and manages device setup (CPU/GPU). Similarly, run_evaluation.py orchestrates evaluation tasks including privacy and utility measurements as related to anonymization quality.
The repo also contains multilingual evaluation datasets and utilities to facilitate benchmarking speaker anonymization performance.
In summary, the repo provides a comprehensive toolkit that directly corresponds to the method described in the paper, leveraging anonymization of speaker embeddings and multilingual TTS/ASR models to realize zero-lookahead streaming voice conversion.