RTFree-F5
Transcript-Free Flow-Matching Text-to-Speech via Speech Feature Conditioning
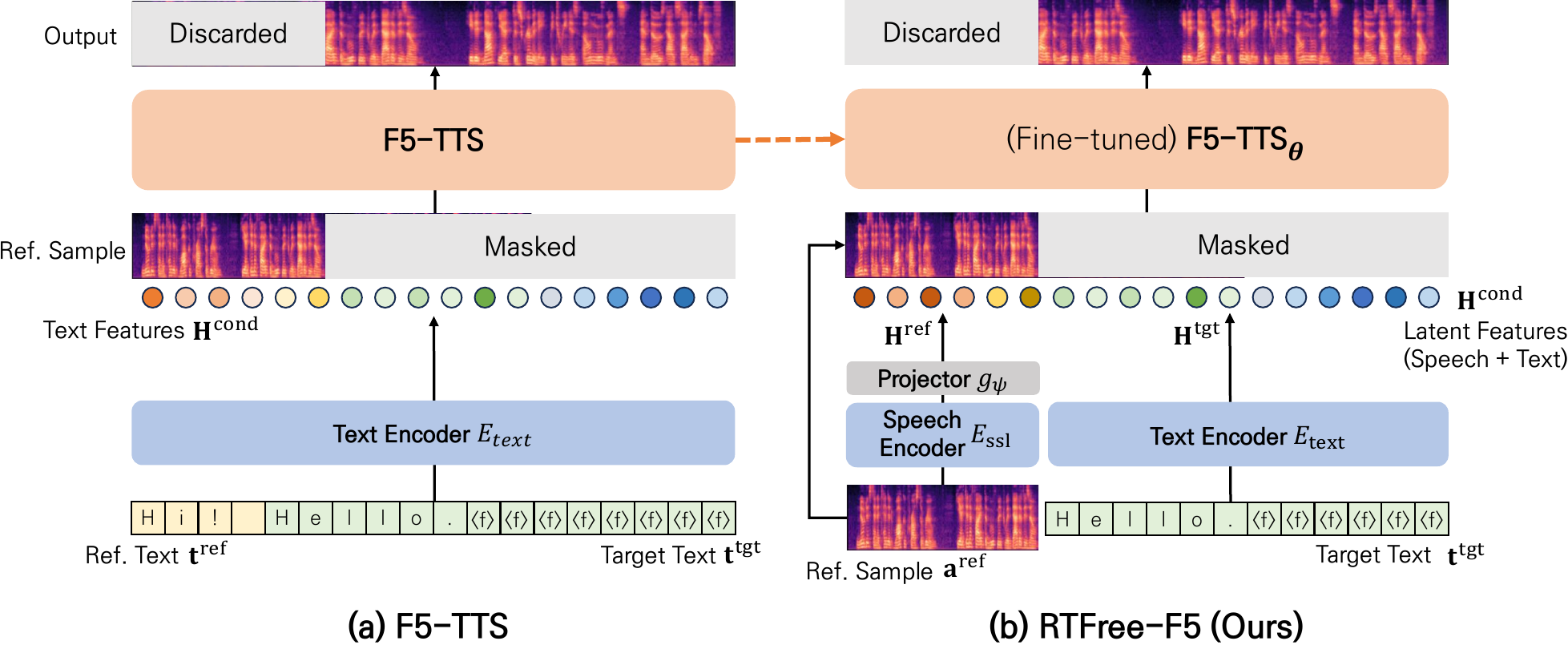
RTFree-F5 innovates flow-matching zero-shot TTS by using self-supervised speech features instead of reference transcripts at inference. This improves robustness and speech quality for atypical speakers like those with dysarthria, while keeping competitive performance on typical voices.
Links
Paper & demos
Code & resources
Abstract
Recent flow-matching text-to-speech (TTS) models, such as F5-TTS, rely on a reference transcript at inference time, obtained from an external ASR system. This dependency makes zero-shot TTS brittle for accented or dysarthric speakers, precisely the scenarios where it is most needed. Moreover, we find that text-based reference conditioning can propagate atypical acoustic patterns from atypical speech into synthesis, even when ground-truth transcripts are available. To address this, we propose RTFree-F5, which replaces the reference transcript with continuous self-supervised speech representations mapped into F5-TTS's text-conditioning space via a lightweight adapter, while reusing the pretrained checkpoint. On dysarthric speech, RTFree-F5 reduces WER from 24.6% to 10.4%, surpassing even the ground-truth reference transcript baselines, while improving naturalness and remaining competitive on standard benchmarks without requiring any reference transcript.
Introduction
This paper addresses a practical weakness in modern zero-shot flow-matching text-to-speech (TTS) systems, especially F5-TTS-style models that use a reference utterance to condition synthesis. In the standard setup, the model needs a transcript for the reference audio at inference time, typically obtained from an external ASR system. That dependency is brittle when the reference speaker has strong accents, dysarthria, or otherwise atypical speech. The authors also argue that text-based reference conditioning can do more than fail due to ASR errors: even with perfect transcripts, it can inject normative phonetic expectations that conflict with the reference audio and can propagate atypical acoustic patterns into the generated speech.
To remove this dependency, the paper proposes RTFree-F5 ( Reference Transcript-Free F5-TTS), which reuses a pretrained F5-TTS checkpoint but replaces reference-transcript conditioning with continuous self-supervised speech representations extracted from the reference waveform. A lightweight projector maps these speech features into the same conditioning space used by F5-TTS text embeddings, allowing the original model architecture and checkpoint to be retained while eliminating the need for a reference transcript at inference time.
The paper’s main claim is that this speech-feature conditioning is not only transcript-free, but actually better for atypical speakers. On dysarthric speech, RTFree-F5 reduces word error rate (WER) from $24.62\%$ in the original speech to $10.39\%$, outperforming even oracle transcript baselines. It also improves predicted naturalness and remains competitive on standard zero-shot benchmarks.
Problem Setting and Motivation
The paper situates itself in the line of zero-shot TTS systems that synthesize speech for unseen speakers from a short reference sample. It contrasts autoregressive approaches, which can be strong but are slower and rely on discrete tokenizers, with non-autoregressive systems based on diffusion or flow matching, which are faster and have recently become competitive in quality. Within that family, E2-TTS and F5-TTS avoid complex duration modeling by conditioning directly on character sequences padded with filler tokens. F5-TTS improves alignment by refining this padded sequence with an additional text encoder.
The limitation of F5-TTS relevant to this work is that its inference pipeline still requires a transcript for the reference audio. When the speaker is dysarthric or heavily accented, the ASR transcript can be inaccurate, and the mismatch between the transcript and the actual acoustics can degrade cloning quality. The authors emphasize that this is especially problematic for accessibility-oriented scenarios, where the system is meant to help exactly the users whose speech is hardest to transcribe.
The work also positions itself relative to textless voice conversion systems that reuse F5-TTS-like architectures with discrete speech units. Those approaches remove transcript dependence but cannot reuse the original character-based checkpoint directly and must be trained from scratch. RTFree-F5 instead aims to stay maximally compatible with the pretrained F5-TTS model by learning a modality bridge into the existing text-conditioning space.
Method Overview
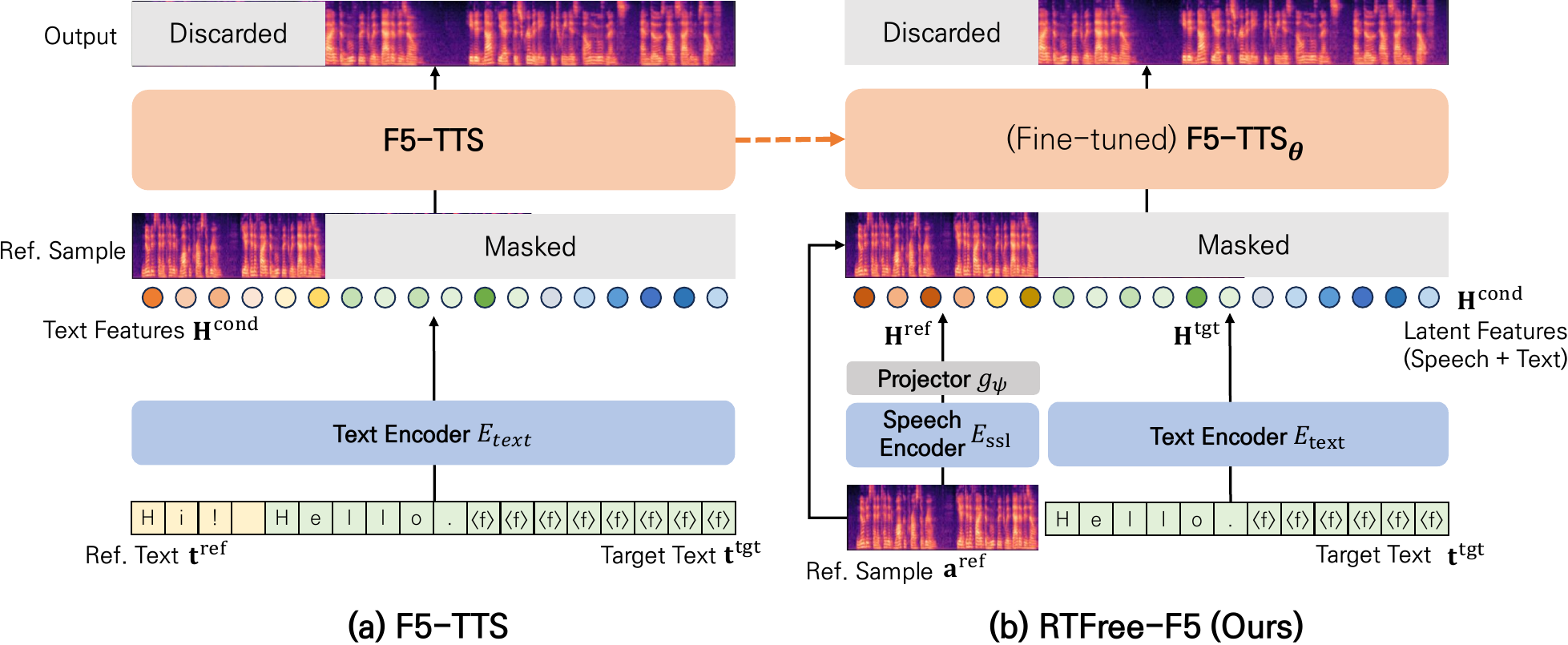
RTFree-F5 keeps the core F5-TTS flow-matching decoder and target-text conditioning intact, but substitutes the reference transcript path with frozen self-supervised speech features from the reference waveform. Let the reference transcript and target transcript be represented by padded token sequences $\mathbf{t}^{\mathrm{ref}}$ and $\mathbf{t}^{\mathrm{tgt}}$. In F5-TTS, both are encoded by a shared text encoder into a concatenated conditioning sequence:
$$ \mathbf{H}^{\mathrm{cond}} = E_{\mathrm{text}}\left( [\mathbf{t}^{\mathrm{ref}};\mathbf{t}^{\mathrm{tgt}}] \right) \in \mathbb{R}^{(T_{\mathrm{ref}} + T_{\mathrm{tgt}}) \times D}. $$
RTFree-F5 replaces the reference transcript with self-supervised speech representations. Given a reference waveform $\mathbf{a}^{\mathrm{ref}}$, a frozen SSL encoder produces frame-level features
$$ \mathbf{H}^{\mathrm{ssl}} = E_{\mathrm{ssl}}(\mathbf{a}^{\mathrm{ref}}) \in \mathbb{R}^{T_{\mathrm{ref}} \times D_{\mathrm{ssl}}}. $$
A learnable projector $g_\psi$ maps each SSL frame into the F5-TTS text-conditioning space:
$$ \mathbf{H}^{\mathrm{ref}} = g_\psi(\mathbf{H}^{\mathrm{ssl}}) \in \mathbb{R}^{T_{\mathrm{ref}} \times D}. $$
The target transcript still flows through the original text encoder:
$$ \mathbf{H}^{\mathrm{tgt}} = E_{\mathrm{text}}(\mathbf{t}^{\mathrm{tgt}}) \in \mathbb{R}^{T_{\mathrm{tgt}} \times D}. $$
The final conditioning is the temporal concatenation
$$ \mathbf{H}^{\mathrm{cond}} = [\mathbf{H}^{\mathrm{ref}};\mathbf{H}^{\mathrm{tgt}}]. $$
This design preserves the overall interface expected by the pretrained F5-TTS backbone: the model still receives conditioning in the same latent space and can therefore reuse the original checkpoint. The change is isolated to the conditioning channel for the reference side.
Figure: Architecture comparison
The figure below contrasts the original F5-TTS conditioning path with RTFree-F5. It shows that F5-TTS concatenates reference and target transcripts before text encoding, while RTFree-F5 uses SSL-derived reference features projected into the same latent text space.
Flow-Matching Objective and Training Strategy
The underlying generator is the pretrained F5-TTS diffusion transformer (DiT) trained with a flow-matching objective. For a target mel-spectrogram $\mathbf{x}^{\mathrm{tgt}}$ and Gaussian noise $\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$, the interpolated latent is
$$ \mathbf{z}_t = (1-t)\boldsymbol{\epsilon} + t\mathbf{x}^{\mathrm{tgt}}, $$
and the target vector field is
$$ \mathbf{v} = \mathbf{x}^{\mathrm{tgt}} - \boldsymbol{\epsilon}. $$
The model minimizes a mean-squared error between the true and predicted flow:
$$ \mathcal{L} = \mathbb{E}_{t,\mathbf{x}^{\mathrm{tgt}},\boldsymbol{\epsilon}} \left\| \mathbf{v} - \mathbf{v}_\theta(\mathbf{z}_t, t, \mathbf{H}^{\mathrm{cond}}) \right\|^2. $$
Two-stage adaptation
A key methodological choice is the two-stage training schedule, which is meant to stabilize the transition from transcript-based conditioning to speech-feature conditioning and to adapt the pretrained decoder to cross-utterance reference/target pairing.
- Stage 1: cross-modal alignment. Only the projector $g_\psi$ is trained, while the SSL encoder and the entire F5-TTS model are frozen. The conditioning is built from a reference utterance and a target utterance sampled from the same speaker but from different utterances, which is closer to inference than within-utterance infilling. The purpose is to align SSL features with the pretrained text-conditioning space.
- Stage 2: joint fine-tuning. The projector and the DiT backbone are jointly fine-tuned, while the SSL encoder and text encoder remain frozen. The paper argues this is necessary because Stage 1 alone can leave a distribution mismatch: the pretrained DiT was originally optimized for within-utterance infilling, but RTFree-F5 uses cross-utterance conditioning where the reference and target are acoustically disjoint. Joint fine-tuning adapts the generator to this new regime.
The same flow-matching loss is used in both stages; only the set of trainable parameters changes.
Inference
At inference time, the model takes reference audio and target text. The reference waveform is encoded by the frozen SSL encoder, projected into the F5-TTS conditioning space, concatenated with the target-text features, and passed to the flow-matching ODE solver. The paper states that the ODE is solved from $\mathbf{z}_0 \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$ to $t=1$ using classifier-free guidance. The resulting mel-spectrogram is then vocoded to waveform. Crucially, no transcript of the reference audio is required.
Implementation Details
RTFree-F5 is built on the pretrained F5-TTS v1 Base checkpoint. The SSL encoder is WavLM-Large, which remains frozen throughout training. The projector is a two-layer MLP with LayerNorm that maps $1024$-dimensional WavLM features to the $512$-dimensional F5-TTS conditioning space, with a $512$-dimensional hidden layer. This yields about $0.8$ million trainable parameters. To improve stability, the final projection layer is initialized with a weight scaling factor of $0.1$.
Because WavLM operates at $50$ Hz while the F5-TTS mel-spectrogram uses $24$ kHz audio with a $256$-sample hop size, corresponding to about $93.75$ Hz, the projected speech features are linearly interpolated to match the mel frame rate.
Optimization uses AdamW with linear warmup and linear decay. Stage 1 is trained for $10$ epochs and Stage 2 for $20$ epochs. The backbone uses a learning rate of $1\times10^{-5}$, while the projector uses $5\times10^{-5}$, reflecting the desire to preserve the pretrained linguistic prior while allowing the new conditioning bridge to adapt more quickly. Training runs on $4$ NVIDIA A100 GPUs; Stage 1 takes about $1$--$2$ days and Stage 2 about $2$--$3$ days.
Training pairs are sampled from the LibriTTS training set as cross-utterance speaker-matched pairs. Samples are filtered to durations between $0.3$ and $30$ seconds. The paper follows F5-TTS dropout settings with audio-drop probability $0.3$ and joint-drop probability $0.2$.
Inference follows the default F5-TTS settings: Euler ODE solver with $32$ function evaluations, sway coefficient $-1$, CFG strength $2.0$, and the Vocos vocoder for waveform synthesis at $24$ kHz.
Evaluation Setup
The experiments cover both typical and atypical speakers. For typical speakers, the paper uses LibriSpeech-PC test-clean and SeedTTS test-en. For atypical speakers, it uses the Speech Accessibility Project (SAP) dev split for dysarthric speech and L2-ARCTIC for accented non-native speech, selecting two speakers per language background.
The reported metrics are:
- WER, computed from Whisper large-v3 transcripts, as an intelligibility proxy;
- SIM, speaker similarity measured as cosine similarity between ECAPA-TDNN embeddings;
- MOS, predicted naturalness from UTMOS.
Baselines are the pretrained F5-TTS model conditioned on either oracle reference transcripts or Whisper ASR transcripts. For atypical-speaker experiments, the paper also reports the metrics of the original source speech as a reference point, with SIM computed against same-speaker utterances.
Results on Typical Speakers
On the standard zero-shot benchmarks, RTFree-F5 remains competitive with the transcript-based F5-TTS baselines and often improves predicted naturalness. The paper reports the following numbers:
| Model | LibriSpeech-PC WER ↓ | LibriSpeech-PC SIM ↑ | LibriSpeech-PC MOS ↑ | SeedTTS WER ↓ | SeedTTS SIM ↑ | SeedTTS MOS ↑ |
|---|---|---|---|---|---|---|
| Baseline (oracle) | 2.08% | 0.67 | 3.83 | 1.43% | 0.68 | 3.66 |
| Baseline (ASR) | 2.17% | 0.68 | 3.84 | 1.45% | 0.68 | 3.66 |
| RTFree Stage 1 | 4.68% | 0.64 | 3.91 | 2.86% | 0.62 | 3.80 |
| RTFree Stage 2 | 1.77% | 0.66 | 4.13 | 1.56% | 0.63 | 3.94 |
The main takeaway is that Stage 2 recovers and often improves upon the transcript-based baselines. On LibriSpeech-PC, RTFree-F5 achieves $1.77\%$ WER, beating both the oracle baseline at $2.08\%$ and the ASR baseline at $2.17\%$. It also obtains the best MOS of $4.13$. On SeedTTS, RTFree-F5 achieves the best MOS at $3.94$ and WER of $1.56\%$, which is close to the transcript-based baselines. Speaker similarity remains comparable but not uniformly higher than the baselines, indicating that the method is primarily competitive on typical speakers rather than dramatically changing the zero-shot cloning regime.
Stage 1 alone is noticeably weaker, with WER degrading to $4.68\%$ on LibriSpeech-PC and $2.86\%$ on SeedTTS. The authors interpret this as evidence that learning only the projection layer is insufficient; the DiT backbone must also adapt to the new conditioning distribution.
Results on Atypical Speakers
The most important results are on dysarthric SAP speech and accented L2-ARCTIC speech, where transcript dependence is most likely to fail. The paper reports the following table:
| Model | SAP WER ↓ | SAP SIM ↑ | SAP MOS ↑ | L2-ARCTIC WER ↓ | L2-ARCTIC SIM ↑ | L2-ARCTIC MOS ↑ |
|---|---|---|---|---|---|---|
| Original | 24.62% | 0.71 | 2.16 | 10.75% | 0.73 | 3.82 |
| Baseline (oracle) | 20.71% | 0.60 | 2.27 | 2.00% | 0.59 | 3.92 |
| Baseline (ASR) | 20.46% | 0.60 | 2.27 | 1.99% | 0.60 | 3.92 |
| RTFree Stage 1 | 90.00% | 0.52 | 2.19 | 7.53% | 0.49 | 4.00 |
| RTFree Stage 2 | 10.39% | 0.50 | 2.85 | 1.44% | 0.61 | 4.08 |
On SAP, RTFree-F5 reduces WER from $24.62\%$ in the original speech to $10.39\%$, a $58\%$ relative reduction. More importantly, it outperforms even the oracle baseline with perfect reference transcripts, which reaches only $20.71\%$ WER. The MOS improves from $2.16$ to $2.85$, showing a substantial quality gain. Speaker similarity drops from $0.71$ in the original recordings to $0.50$ in the synthesized output, and the paper discusses this as a likely intelligibility-versus-identity trade-off: some normalization of atypical articulation may be necessary to make the speech easier to understand.
The Stage 1 model fails catastrophically on SAP, with WER at $90.00\%$, reinforcing the claim that merely learning the projection layer is not enough under severe distribution shift.
On L2-ARCTIC, RTFree-F5 reduces WER from $10.75\%$ in the original speech to $1.44\%$, an $87\%$ relative reduction. It also outperforms the oracle baseline ($2.00\%$ WER) and the ASR baseline ($1.99\%$ WER). Speaker similarity is preserved reasonably well at $0.61$, and MOS improves to $4.08$. This is a particularly important result because it shows that SSL-based reference conditioning can beat transcript-based conditioning even when transcripts are accurate.
Analysis and Interpretation
The paper’s interpretation of the results is that transcript-based reference conditioning creates a mismatch between what the conditioning signal expects and what the reference acoustics actually contain. With atypical speech, the transcript encodes an idealized phonetic sequence, while the reference mel-spectrogram contains disfluencies, altered timing, unusual coarticulation, accented pronunciations, or dysarthric realizations. The model then has to reconcile incompatible cues: a text condition that says what the utterance should sound like and an acoustic context that reveals how the speaker actually sounds. The authors argue that this mismatch can encourage the model to reproduce atypical surface patterns in the synthesized output.
RTFree-F5 is designed to avoid that conflict. The SSL representations produced by WavLM are aligned with the actual acoustics of the reference audio rather than with an external linguistic transcription. In the authors’ framing, the projected SSL features act like a kind of latent text: they sit in the same conditioning space as the original F5-TTS text features, but they are grounded in speech content and speaker characteristics extracted directly from audio. That gives the generator a conditioning signal that is compatible with the acoustic prompt while still preserving target-text control.
The performance differences between Stage 1 and Stage 2 are also informative. Stage 1 alone exposes a major domain mismatch between the SSL-to-text projection and the pretrained DiT backbone, especially for dysarthric speech. Stage 2 fine-tuning resolves much of this mismatch by adapting the backbone to the new cross-utterance conditioning regime, which is why the paper treats joint fine-tuning as essential rather than optional.
Contributions and Novelty
- It removes the need for a reference transcript at inference time in an F5-TTS-style flow-matching TTS system.
- It does so without retraining the entire model from scratch, instead reusing the pretrained F5-TTS checkpoint and learning only a lightweight projector plus limited backbone fine-tuning.
- It introduces a continuous speech-feature conditioning path based on frozen WavLM representations mapped into the text-conditioning space of the pretrained model.
- It trains on cross-utterance same-speaker pairs to better match the inference setting.
- It demonstrates that transcript-free speech conditioning is especially beneficial for atypical speakers, where oracle transcript conditioning is not necessarily optimal.
Limitations and Practical Trade-offs
The paper is optimistic overall, but it does report some limitations and trade-offs. First, Stage 1 alone is not sufficient; the method depends on Stage 2 joint fine-tuning to obtain good results. Second, on SAP the synthesized speech attains lower speaker similarity than the reference recordings, suggesting that intelligibility improvements may come at the cost of some speaker-identity preservation, at least under the ECAPA-TDNN similarity metric used here. Third, the method still relies on a reference audio clip at inference time, so it is transcript-free rather than reference-free. Fourth, the paper evaluates a specific pretrained backbone, WavLM-Large for SSL features, and the reported gains are tied to that design choice and the F5-TTS conditioning interface.
The authors also note that their training setup is based on cross-utterance pairs from LibriTTS and on the specific benchmark set they evaluate; the paper does not claim that the same gains automatically transfer to every TTS backbone or every speech encoder without modification.
Conclusion
RTFree-F5 shows that a pretrained flow-matching TTS system can be made transcript-free at inference by replacing reference-transcript conditioning with continuous self-supervised speech features projected into the model’s existing text-conditioning space. The method preserves the reusable F5-TTS architecture, uses only a small number of additional parameters, and is trained in two stages to align the new conditioning signal before jointly adapting the generator. Empirically, it is competitive on typical zero-shot benchmarks and substantially stronger on atypical speakers, where it outperforms both ASR-based and oracle transcript baselines. The paper’s central result is that for dysarthric and accented speech, matching the conditioning signal to the actual acoustics of the reference utterance can be more effective than conditioning on a transcript, even when that transcript is perfect.