Score Subnet
Repurposing a Speech Classifier for Guided Diffusion-Based Speech Generation
Repurposes a pretrained noise-conditioned speech classifier for diffusion-based speech generation with a lightweight decoder. This unifies classifier guidance and score modeling in one backbone, cutting parameters and compute while delivering high-quality conditional speech synthesis.
Links
Paper & demos
Abstract
Classifier guidance is a way to control diffusion generation by using a noise-conditioned classifier to steer the sampling process toward a target class. One drawback of classifier guidance is that it requires two separately trained models: a classifier and a diffusion model. We therefore study a more compact alternative in which a conventionally trained speech classifier is repurposed as the backbone for diffusion generation. Starting from a frozen noise-conditioned classifier in log-Mel space, we attach a lightweight subnetwork that reuses intermediate classifier representations and train only this subnetwork under a Denoising Score Matching objective. Our work shows that a pretrained classifier can be repurposed for conditional generation, providing an appealing bridge between discriminative modeling and conditional speech synthesis resulting in high speech quality within a single-backbone model, with reduced memory footprint and computational cost.
Introduction and problem setting
This paper studies whether a conventional noise-conditioned speech classifier can be repurposed as the backbone for diffusion-based speech generation in log-Mel space. The motivation is to reduce the cost of the standard classifier-guidance pipeline, which normally requires two separately trained models: a diffusion score model and a classifier that provides guidance gradients during sampling. The authors ask whether a pretrained classifier already contains enough information to support score prediction if it is paired with a lightweight generative adapter trained only on top of frozen classifier features.
The key idea is to keep the classifier fixed, reuse its intermediate representations, and train only a small decoder-style subnet with Denoising Score Matching (DSM). At inference time, this yields a single-backbone generator that can be used unconditionally with its learned score subnet, and conditionally with standard classifier guidance. The resulting system aims to lower both the number of trainable parameters and the sampling-time compute relative to a full U-Net score model plus a separate classifier.
The paper’s main contributions are:
- showing that a conventionally trained noise-conditioned speech classifier can be repurposed for diffusion generation;
- proposing a parameter-efficient Score Subnet that freezes the classifier and trains only a lightweight decoder on intermediate representations; and
- evaluating the method on the SC09 spoken-digit benchmark, including ablations, guidance-strength sweeps, and low-data / restricted-label experiments.
Method overview
The method is formulated in a score-based diffusion framework operating on log-Mel spectrograms. Let $X_0 \in \mathbb{R}^{F \times N}$ be a clean log-Mel spectrogram sampled from the data distribution $p_0$. A forward stochastic differential equation (SDE) progressively corrupts the data:
$$dX_t = f(X_t,t)\,dt + g(t)\,dW_t, \qquad t \in [0,1].$$
The reverse-time SDE uses the score $\nabla_{X_t} \log p_t(X_t)$ to denoise samples:
$$dX_t = \Big(f(X_t,t) - g(t)^2 \nabla_{X_t} \log p_t(X_t)\Big)\,dt + g(t)\,d\bar W_t.$$
The score is approximated by a network $s_\theta(X_t,t)$ trained with DSM:
$$\mathcal{L}(\theta) = \mathbb{E}_{t \sim \mathcal{U}(0,1)}\,\mathbb{E}_{X_0 \sim p_0}\,\mathbb{E}_{X_t \sim q(X_t \mid X_0,t)} \left[\lVert s_\theta(X_t,t) - \nabla_{X_t} \log q(X_t \mid X_0,t) \rVert_2^2\right].$$
For conditional generation, the paper uses the standard classifier-guidance decomposition:
$$\nabla_{X_t} \log p_t(X_t \mid y) = \nabla_{X_t} \log p_t(X_t) + \nabla_{X_t} \log p_t(y \mid X_t).$$
The second term is obtained by backpropagating through a noise-conditioned classifier trained on noisy inputs with cross-entropy:
$$\mathcal{L}_{\mathrm{CE}}(\phi) = \mathbb{E}_{t,(X_0,y)}\,\mathbb{E}_{X_t \sim q(X_t \mid X_0,t)}\left[-\log p_{\phi,t}(y \mid X_t)\right].$$
The guided score used during sampling is therefore
$$\tilde{s}(X_t,t,y) = s_\theta(X_t,t) + \gamma\,\nabla_{X_t} \log p_{\phi,t}(y \mid X_t),$$
where $\gamma \ge 0$ controls guidance strength.
Why the paper invokes JEM-style scores, but does not train a full JEM
The paper uses a joint energy-based model (JEM) perspective as an interpretive tool rather than as the final training objective. If a classifier produces logits $f_{\phi,t}(X_t) \in \mathbb{R}^C$, then a JEM-style joint model over inputs and labels can be written as
$$p_{\phi,t}(X_t,y) = \frac{\exp\big(f_{\phi,t}(X_t)[y]\big)}{Z(\phi)}.$$
Marginalizing over labels yields an input density proportional to the log-sum-exp of the logits:
$$p_{\phi,t}(X_t) = \frac{\sum_y \exp\big(f_{\phi,t}(X_t)[y]\big)}{Z(\phi)}.$$
Differentiating this marginal gives a classifier-derived score surrogate:
$$\nabla_{X_t} \log p_{\phi,t}(X_t) = \nabla_{X_t} \log \sum_{y=1}^{C} \exp\big(f_{\phi,t}(X_t)[y]\big).$$
The paper explicitly notes that full JEM-style training is not used because the normalizing constant is intractable and optimization can be unstable. Instead, the JEM view is used only to justify extracting score-relevant signals from a frozen classifier. Those signals are then consumed by the Score Subnet, which is trained with DSM.
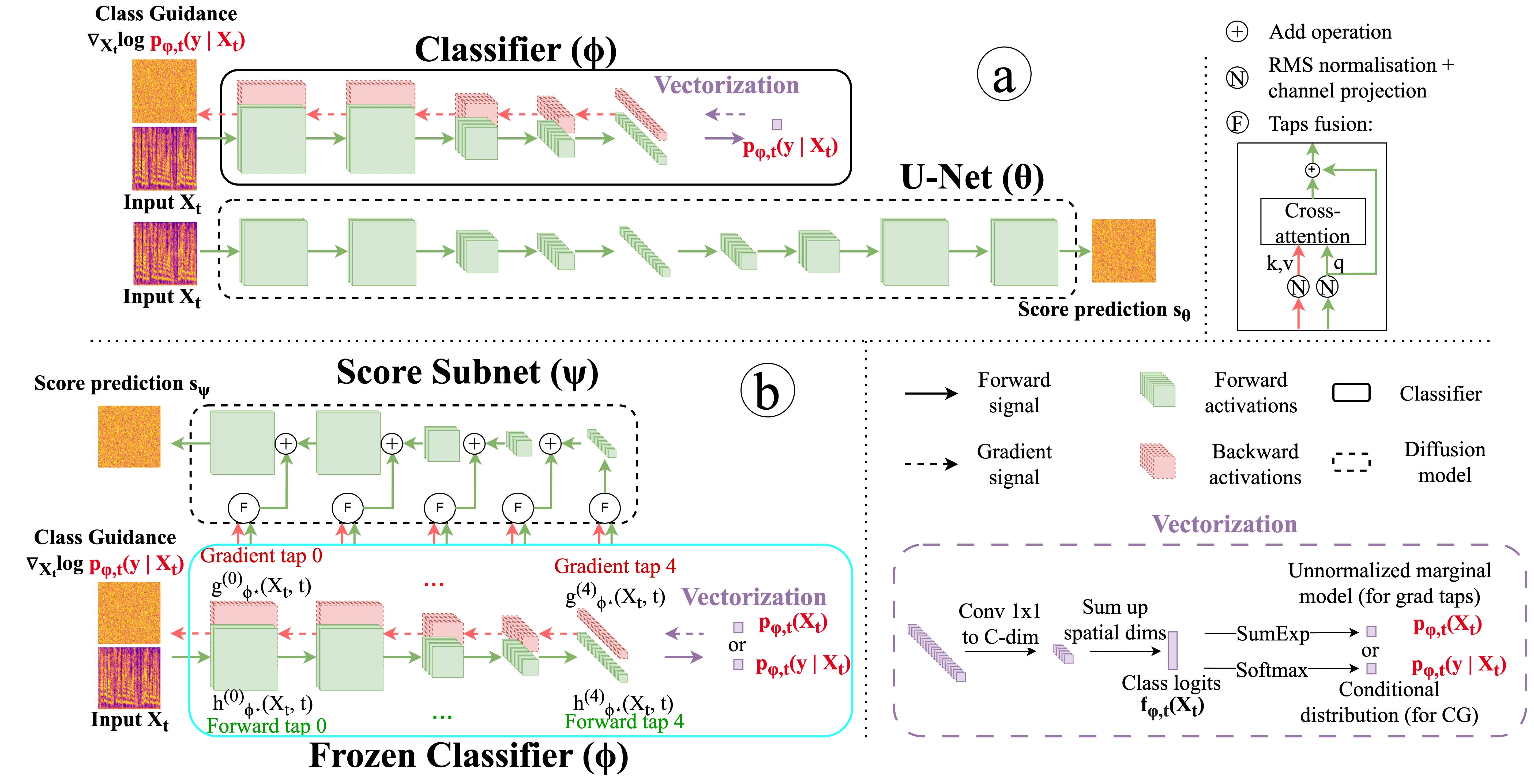
Score Subnet design
The proposed Score Subnet is a lightweight decoder attached to a frozen noise-conditioned classifier backbone. The classifier is treated as a fixed multi-scale feature extractor. Intermediate activations at multiple resolutions are tapped from the encoder path, and the paper also backpropagates through the classifier’s JEM-style marginal to obtain gradient taps at the same stages:
$$g^{(k)}_{\phi^\star}(X_t,t) = \frac{\partial \log p_{\phi^\star,t}(X_t)}{\partial h^{(k)}_{\phi^\star}(X_t,t)}, \qquad k=0,\ldots,K.$$
At each stage, the forward tap $h^{(k)}_{\phi^\star}$ and gradient tap $g^{(k)}_{\phi^\star}$ are RMS-normalized, projected to a common channel dimension, and fused with cross-attention. The decoder then proceeds from the deepest fused representation toward the finest temporal-frequency resolution, repeatedly upsampling and adding stage-wise fused taps in a coarse-to-fine manner. Each stage contains three ResBlocks, and the subnet uses base width 32. A final GroupNorm, SiLU, and convolution head outputs a single-channel score estimate in log-Mel space.
A notable design choice is that the classifier backbone is not modified or jointly fine-tuned with the subnet. The subnet is the only trainable part of the generator, which is what enables the reduction in trainable parameters and compute. In conditional sampling, standard classifier guidance is still used, but the classifier that provides guidance is also the frozen backbone used for feature extraction.
Architecture of the classifier backbone
The backbone is derived from a standard U-Net with base width 64, three ResBlocks in the encoder, two ResBlocks in the bottleneck, and six ResBlocks in the decoder, using stride-2 convolutions for downsampling and upsampling. To obtain the classifier, the authors replace the U-Net up path with a classifier head, while keeping the input projection, time embedding, down path, and bottleneck. The bottleneck representation is flattened and projected to class logits.
This setup is important because it means the classifier already has a U-Net-like encoder and bottleneck structure, even though it was originally trained for classification. The Score Subnet then reuses the same intermediate stages as skip-like taps, which aligns the frozen classifier with a decoder-style generative adapter.
Training and sampling details
The paper reports three training procedures, all with fixed random seeds:
- U-Net diffusion baseline: a full score model is trained end-to-end with DSM to predict $s_\theta(X_t,t)$ directly.
- Noise-conditioned classifier: the classifier encoder is trained with cross-entropy on noisy inputs to estimate $p_{\phi,t}(y \mid X_t)$, and is later frozen.
- Score Subnet on a frozen classifier: the classifier is frozen as $\phi^\star$, and only the subnet parameters $\psi$ are optimized with DSM using the tapped forward and gradient features.
Sampling uses the variance-preserving (VP) SDE, 100 reverse-time steps, and an Euler--Maruyama solver. The authors also clip intermediate score predictions to the interval $[-1,1]$ at each reverse step. For conditional generation, they apply classifier guidance with a sweep over $\gamma$.
The paper’s central claim is not that classifier guidance is discarded, but that the generative backbone can be compressed: a frozen classifier can provide the internal representations that a smaller decoder turns into a diffusion score. In other words, the system collapses the usual “classifier + diffusion model” stack into a single reused backbone plus a lightweight trainable adapter.
Experimental setup
Dataset and representation
The benchmark is SC09, the spoken-digit subset of the Speech Commands dataset containing the classes “zero” through “nine.” The authors follow the official train/validation/test split. Audio is represented as log-Mel filterbanks with FFT size $1024$, hop length $256$, and $80$ Mel bins. They compute global normalization statistics on the training split, subtract the training mean, and divide by the maximum absolute deviation so that features lie in $[-1,1]$. After normalization, the feature standard deviation is reported to be below $0.5$, which stabilizes training.
Generation happens in log-Mel space rather than waveform space. Waveforms are reconstructed with a pretrained 16 kHz HiFi-GAN vocoder.
Evaluation metrics
The paper reports the standard SC09 generation metrics based on an auxiliary ResNeXt classifier: FID, Inception Score (IS), class-balanced Inception Score (mIS), and Activation Maximization (AM). It also adds audio-specific metrics: Fréchet Audio Distance (FAD) computed from VGGish embeddings and SCOREQ, a non-intrusive speech-quality predictor intended to estimate MOS. Lower is better for FID, FAD, and AM; higher is better for ScoreQ, IS, and mIS.
The evaluation protocol uses 2048 generated samples per model and computes FAD against the full SC09 test split of 4107 utterances. The paper also reports parameter counts in total and trainable form, plus sampling-time compute in GMACs per diffusion step. Compute is estimated with THOP for a one-second input and one reverse diffusion step, including forward and selected backward terms for the classifier guidance path.
Main quantitative results
The table below reproduces the main SC09 results reported in the paper. The conditional rows use classifier guidance with $\gamma = 3.0$ and the same guidance classifier across methods. The Score Subnet reuses that classifier as part of its frozen backbone.
| Model | Params (M) total [trainable] |
GMACs | ScoreQ MOS | FAD | FID | IS | mIS | AM |
|---|---|---|---|---|---|---|---|---|
| Unconditional generation | ||||||||
| DiffWave | 24.2 | -- | 2.85 | 2.59 | 1.92 | 5.26 | 51.21 | 0.68 |
| SaShiMi | 23.0 | -- | 2.79 | 1.84 | 1.42 | 5.94 | 69.17 | 0.59 |
| EDMSound | 45.2 | -- | -- | -- | 0.14 | 7.17 | 160.2 | 0.33 |
| U-Net | 16.6 [16.6] | 14.56 | 3.06 | 0.74 | 0.17 | 7.51 | 168.98 | 0.30 |
| Score Subnet (ours) | 12.3 [4.4] | 12.07 | 3.10 | 0.84 | 0.17 | 7.82 | 195.65 | 0.26 |
| No gradient taps | 11.9 [4.0] | 7.71 | 3.04 | 0.90 | 0.28 | 7.02 | 126.95 | 0.37 |
| Conditional generation ($\gamma = 3.0$) | ||||||||
| U-Net + Classifier | 24.5 [16.6] | 22.74 | 3.25 | 0.82 | 0.03 | 8.36 | 260.50 | 0.19 |
| Score Subnet (ours) | 12.3 [4.4] | 16.44 | 3.26 | 1.02 | 0.03 | 8.65 | 287.19 | 0.15 |
| No gradient taps | 11.9 [4.0] | 11.50 | 3.23 | 0.94 | 0.02 | 8.05 | 223.98 | 0.22 |
The main trend is that the Score Subnet is substantially smaller in trainable parameters than the full U-Net baseline, while matching or improving several generation metrics. In unconditional generation, the Score Subnet matches the U-Net on FID at $0.17$ and improves ScoreQ, IS, mIS, and AM, though U-Net remains better on FAD. In conditional generation, the Score Subnet matches FID at $0.03$ and improves ScoreQ, IS, mIS, and AM again, while U-Net + Classifier is better on FAD.
The open-source baselines show that the score-subnet approach is competitive with established speech generation models on the SC09 benchmark. In particular, the conventional U-Net already outperforms DiffWave and SaShiMi on perceptual and auxiliary-classifier metrics, and the Score Subnet improves on that U-Net in several metrics while using only $4.4$M trainable parameters instead of $16.6$M.
Ablation: removing gradient taps
A key ablation removes the gradient taps and keeps only the forward taps from the frozen classifier. This variant is consistently cheaper, but it underperforms the full Score Subnet on most metrics in both unconditional and conditional settings. For example, in unconditional generation it lowers GMACs from $12.07$ to $7.71$, but FID degrades from $0.17$ to $0.28$ and ScoreQ drops from $3.10$ to $3.04$. In conditional generation it reduces GMACs from $16.44$ to $11.50$, but again worsens the overall balance of metrics relative to the full subnet.
This supports the paper’s design intuition that the JEM-inspired gradient information is useful, not just the forward classifier activations.
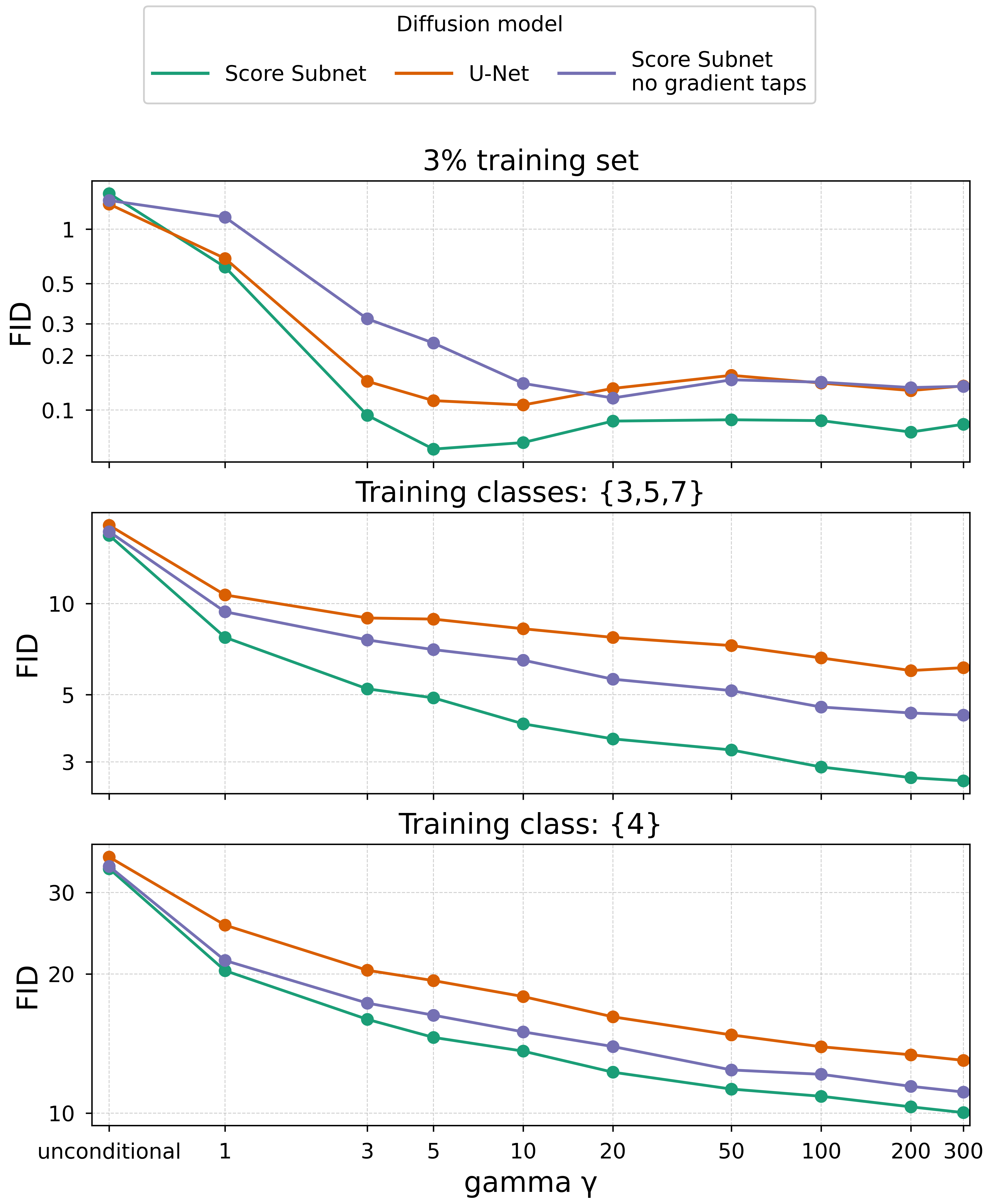
Low-data and zero-shot guidance study
The paper also studies guidance behavior in low-data and restricted-label regimes. Here, the guidance classifier is trained on full SC09, but the diffusion model or Score Subnet is trained on a restricted subset: $3\%$ of the training data, labels $\{3,5,7\}$ only, or a single label (label $4$ only). The same frozen guidance classifier is then used for guided sampling.
The reported trend is consistent across all regimes: increasing $\gamma$ improves FID, and the Score Subnet consistently outperforms the classifier-guided U-Net. The gains are already visible for $\gamma \ge 3$. This is an important result because it suggests that the method can leverage classifier representations even when the score model itself sees very limited data or a subset of classes.
The figure also includes the no-gradient-taps Score Subnet variant, which again serves as an ablation showing that the full method benefits from the additional backpropagated classifier signal.
Interpretation of the results
The central empirical message is that a classifier can be more than a guidance model: once frozen, it can provide reusable intermediate representations that support a separate score-prediction subnet. This gives the paper a bridge between discriminative and generative modeling. Rather than training a full diffusion U-Net from scratch, the method leverages the classifier’s encoder-like structure and only learns a lightweight decoder on top.
Relative to standard classifier guidance, the approach is attractive because it reduces the size of the trainable generator while keeping the ability to do conditional sampling. Relative to a conventional U-Net score model, it is more parameter-efficient and cheaper at inference, although the reported advantage is not uniform across every metric. In particular, FAD is sometimes better for the full U-Net, while the Score Subnet tends to improve the auxiliary classifier-based fidelity, diversity, and speech-quality metrics.
The results also indicate that gradient taps matter. The paper’s ablation suggests that forward activations alone are not enough to fully recover the best performance; the JEM-inspired backpropagated signal provides additional information that improves sample quality and FID.
Scope and practical caveats
The paper’s experiments are focused on SC09 spoken digits and log-Mel spectrogram generation. The system is therefore validated on a relatively compact benchmark rather than on large-vocabulary speech or text-to-speech tasks. Waveform generation is indirect, because the model operates in feature space and relies on a pretrained HiFi-GAN vocoder for reconstruction.
Another practical caveat is that the strongest conditional results still use classifier guidance at sampling time. The novelty is not that guidance disappears, but that the score model itself becomes much more compact by reusing a frozen classifier backbone. In addition, several of the reported metrics depend on auxiliary pretrained models, so the conclusions are best interpreted within the SC09 benchmark protocol used by the paper.
Within those bounds, the paper presents a clean and technically plausible recipe for repurposing a discriminative speech classifier into a diffusion generator: freeze the classifier, extract multi-scale activations and their gradient taps, train only a small DSM subnet, and combine the result with standard guidance when conditional control is needed.