EmoInstruct-TTS
EmoInstruct-TTS: Dual-Path Instruction-Guided Emotional Speech Synthesis
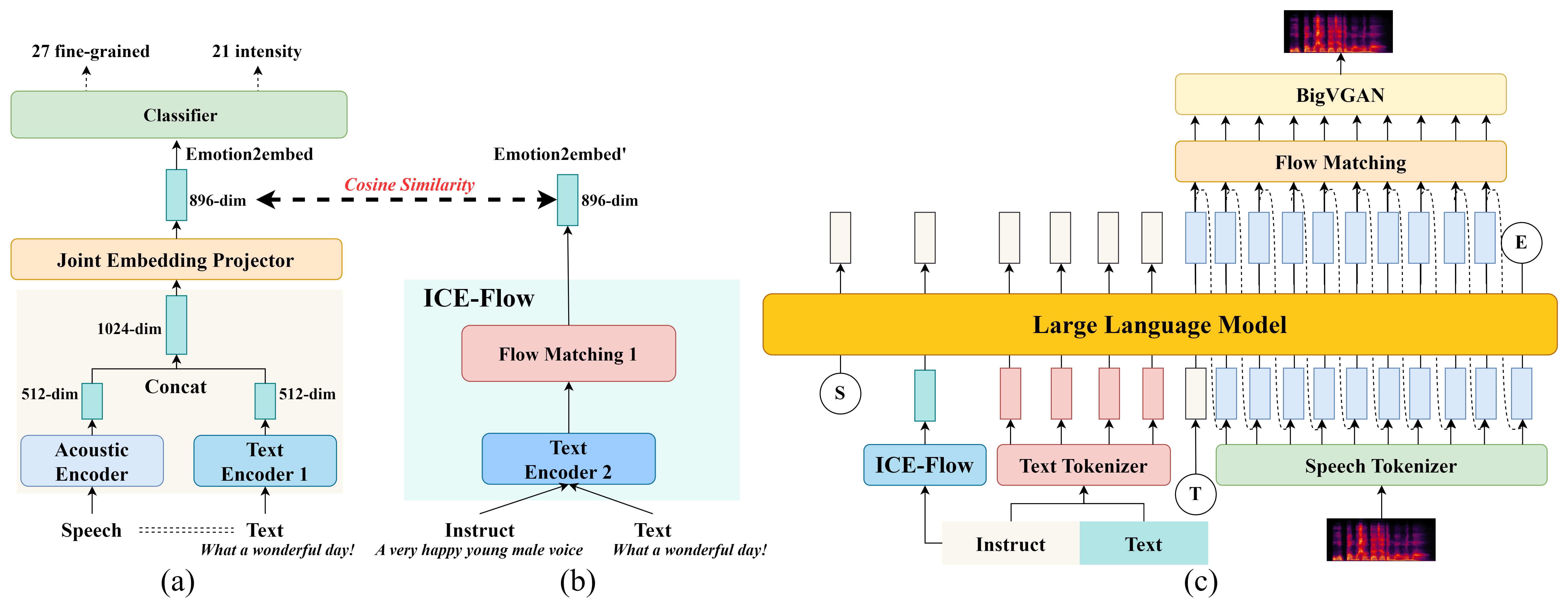
EmoInstruct-TTS is a dual-path emotional TTS system that separates semantic planning from fine-grained emotion control using natural language instructions and a rich emotion embedding. This approach improves emotion accuracy and speech naturalness beyond prior instruction-based systems.
Demos
The demos highlight EmoInstruct-TTS's capability to synthesize emotional speech guided by natural language instructions with fine-grained control over emotion type and intensity. Listen for naturalness and subtle emotional variations across 27 categories and 21 intensity levels, showcasing improvements over coarse-label methods. The overview image illustrates the model's dual-path framework combining semantic and acoustic emotion representations.
Links
Paper & demos
Abstract
Instruction-based controllable speech synthesis enables users to specify emotions through natural language. However, existing approaches often rely on coarse emotion labels and lack explicit modeling of fine-grained intensity. We propose EmoInstruct-TTS, a dual-path instruction-guided framework for emotional speech synthesis. We introduce Emotion2embed, a supervised semantic-acoustic emotion embedding covering 48 emotional states, including fine-grained categories and intensity levels. To infer embeddings from free-form instructions, we design an Instruction-Conditioned Emotion Flow Model (ICE-Flow) that generates acoustically grounded emotion representations. The inferred embeddings are integrated into an LLM-based synthesis pipeline to provide explicit emotional control while preserving semantic planning. Experiments show improved emotional controllability and speech naturalness over strong baselines.
Introduction
EmoInstruct-TTS addresses a practical gap in emotional text-to-speech (TTS): user-facing systems increasingly accept natural-language instructions such as “sound sad but calm” or “speak with high excitement,” yet existing instruction-driven approaches often treat emotion as a coarse label and do not explicitly model intensity. The paper argues that this leads to unstable emotional control, because the instruction text alone is too abstract to fully determine acoustic realization, while reference-speech approaches require curated exemplars and can suffer from speaker dependency and timbre mismatch.
The central idea is a dual-path instruction-guided framework that separates (1) semantic planning from (2) explicit emotional control. Natural-language instructions are still used to guide the LLM-based linguistic planner, but an additional learned emotion embedding provides an acoustically grounded control signal for emotion and intensity. This is the main novelty of the work: rather than expecting the language model to implicitly infer all prosodic details from text, EmoInstruct-TTS introduces a structured intermediate representation for emotion.
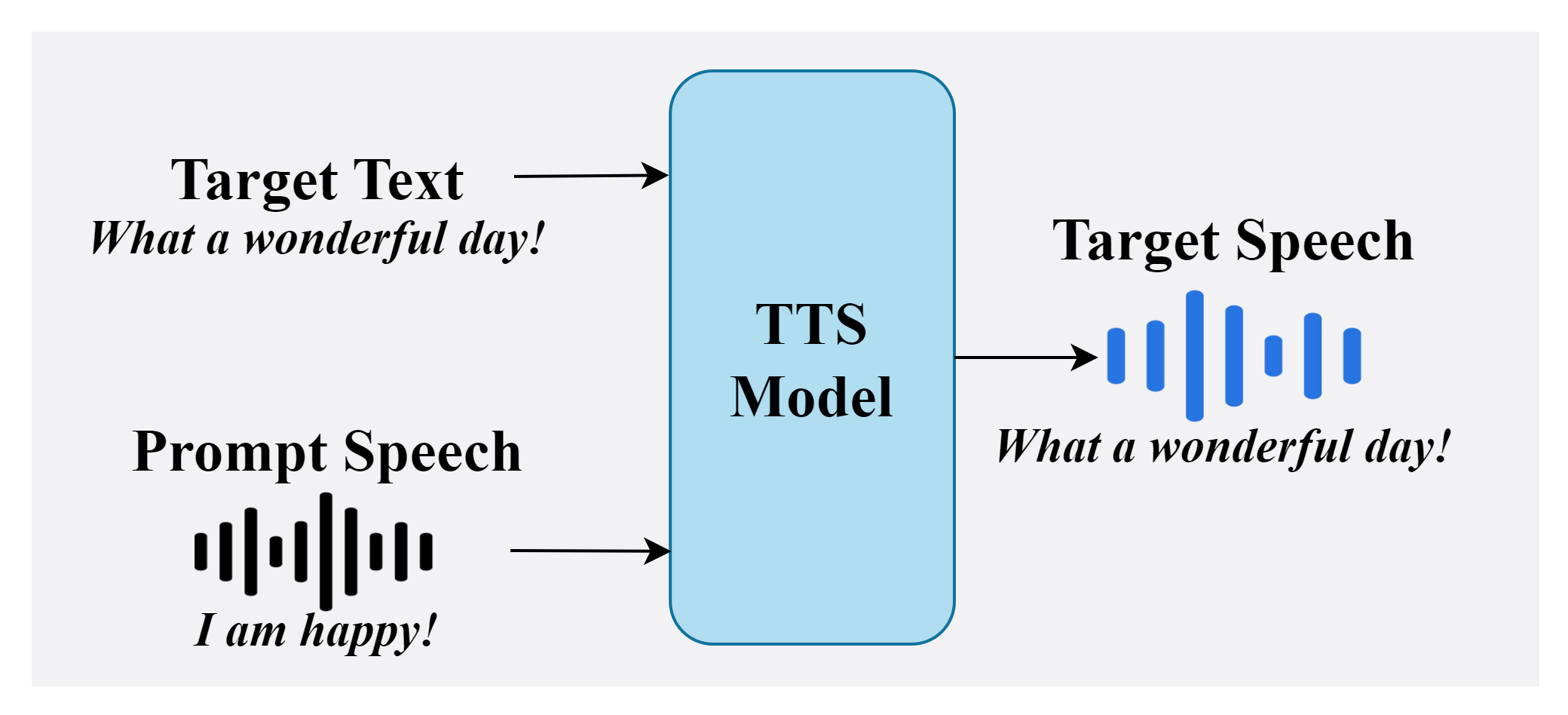
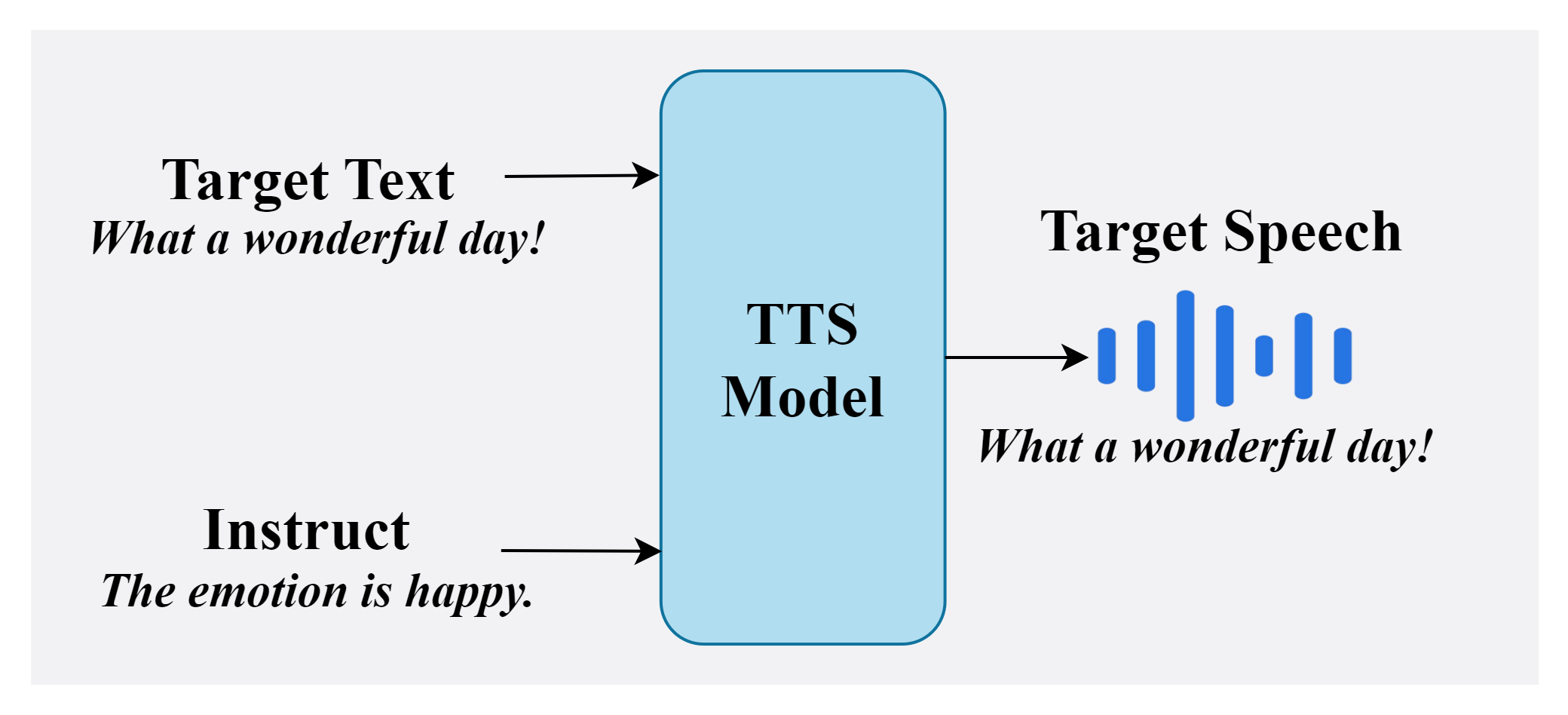
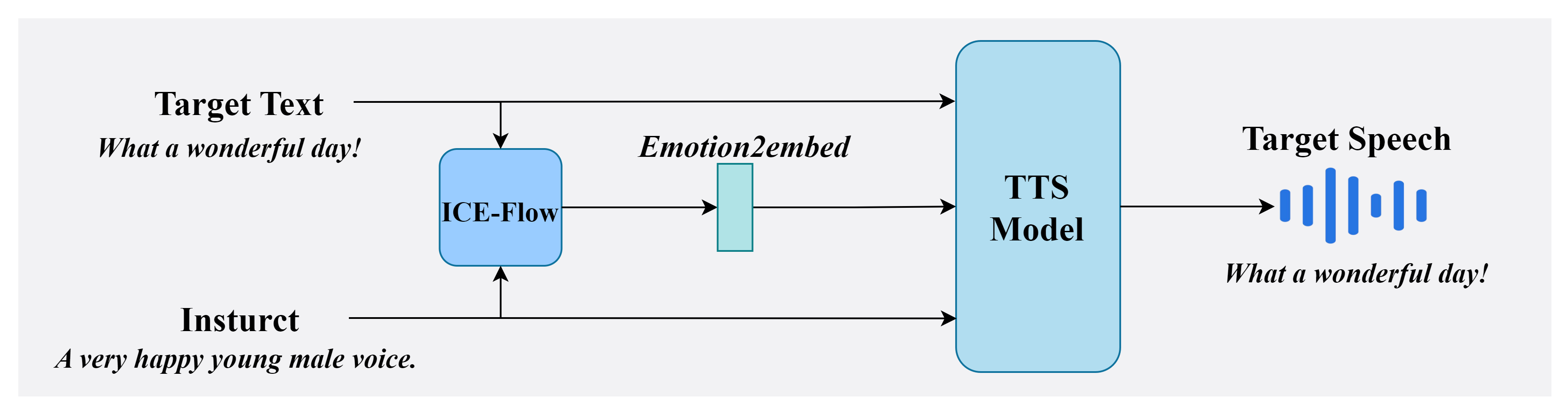
The paper positions EmoInstruct-TTS between two prior families of emotional TTS systems. The first family conditions synthesis on reference emotional speech or latent style embeddings extracted from recordings. The second family uses text instructions or prompts to steer the model, typically via LLMs. EmoInstruct-TTS combines the strengths of both: the instruction text handles content and high-level intent, while an explicit emotion representation handles fine-grained affective control, especially intensity.
Method
The framework has three major components: an instruction-conditioned emotion generator, an LLM-based semantic encoder, and a speaker-conditioned speech decoder followed by a neural vocoder. The design goal is to disentangle semantic planning from emotion-specific acoustic control.
Emotion2embed: structured semantic-acoustic emotion representation
The first core contribution is Emotion2embed, a supervised emotion embedding intended to be both semantically meaningful and acoustically grounded. It covers 48 emotional states in total: 27 fine-grained emotion categories plus 21 emotion-intensity combinations derived from seven primary emotions at three intensity levels: low, medium, and high. The representation is designed to remain speaker-invariant while preserving category structure and ordered intensity geometry.
To build this representation, the paper extracts complementary text and audio features from paired emotional speech and captions. The text side uses a Sentence-BERT model (bge-large-zh v1.5), and the acoustic side uses an ECAPA-TDNN encoder. These are concatenated and projected into a shared embedding space:
$$\mathbf{z}_{\text{emo}} = W[ f_{\text{text}}(t) ; f_{\text{acoustic}}(x) ] + b$$
The implementation uses an embedding dimensionality of $896$.
Training is multi-task. Emotion2embed is optimized with an emotion classification loss, an intensity classification loss, and an ordinal intensity regularizer:
$$\mathcal{L}_{\text{emo}} = \mathcal{L}_{\text{cls}}^{\text{emo}} + \lambda \mathcal{L}_{\text{cls}}^{\text{int}} + \beta \mathcal{L}_{\text{ord}}$$
The ordinal term encodes the idea that, within a fixed primary emotion, low, medium, and high intensity should lie in a monotonic progression along a learnable direction:
$$\mathcal{L}_{\text{ord}} = \max(0, m - (s_{\text{mid}} - s_{\text{low}})) + \max(0, m - (s_{\text{high}} - s_{\text{mid}}))$$
In the paper’s description, this geometry is important because it supports both discrete emotion control and smooth intensity interpolation. The representation is intended to be usable as an explicit acoustic prior rather than a purely categorical label.
ICE-Flow: instruction-to-emotion mapping
The second core contribution is ICE-Flow (Instruction-Conditioned Emotion Flow Model), which maps free-form natural-language instructions to an Emotion2embed vector. The instruction text is encoded by a multilingual MiniLM encoder into a semantic feature vector $\mathbf{h}_{\text{text}}$, and the model learns a conditional distribution over emotion embeddings:
$$p(\mathbf{z}_{\text{emo}} \mid \mathbf{h}_{\text{text}})$$
During training, ICE-Flow is supervised using sample-level Emotion2embed targets extracted from real emotional speech:
$$\mathbf{z}_{\text{emo}} = f_{\text{Emotion2embed}}(x, t)$$
The main learning objective is a regression loss between the predicted embedding and the acoustically grounded target:
$$\mathcal{L}_{\text{sample}} = \mathbb{E}_{(t,x)} \lVert f_{\text{ICE}}(\mathbf{h}_{\text{text}}(t)) - \mathbf{z}_{\text{emo}}(x) \rVert_2^2$$
To reduce mode collapse and preserve realistic variation, the paper adds a distribution-level term that matches the covariance of generated embeddings with the covariance of real embeddings from the same emotion-intensity class:
$$\mathcal{L}_{\text{dist}} = \lVert \operatorname{Cov}(\hat{\mathbf{z}}_{\text{emo}}) - \operatorname{Cov}(\mathbf{z}_{\text{emo}}^{\text{real}}) \rVert_F$$
The final ICE-Flow objective is:
$$\mathcal{L}_{\text{ICE}} = \mathcal{L}_{\text{sample}} + \gamma \mathcal{L}_{\text{dist}}$$
At inference time, ICE-Flow uses only the instruction semantics. The paper also states that classifier-free guidance is applied to control the strength of instruction adherence.
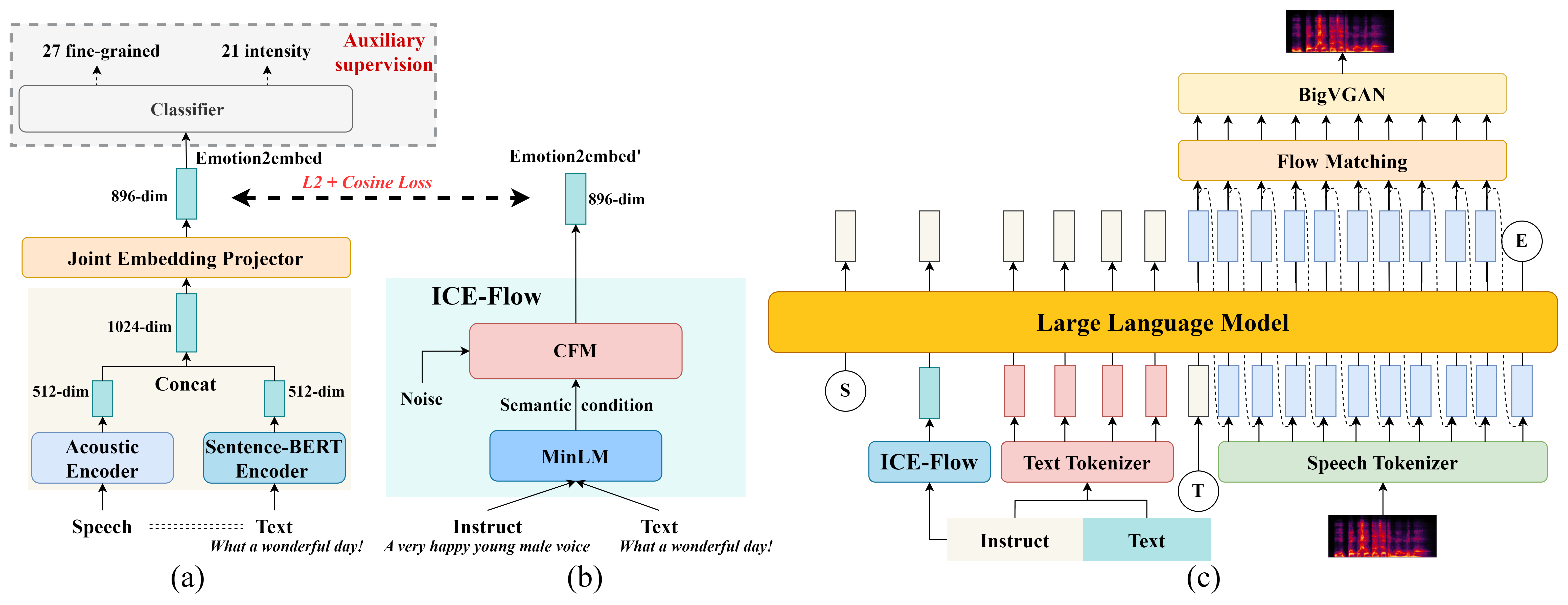
Dual-path instruction-guided speech synthesis
EmoInstruct-TTS injects instruction information into two complementary routes. The first route maps the instruction to an explicit emotion embedding:
$$\mathbf{E}_{\text{emo}} = f_{ \text{ICE-Flow}}(f_{\text{MiniLM}}(\text{instruction}))$$
The second route uses a large language model to produce semantic tokens from the instruction, target text, and the emotion embedding:
$$\mathbf{S} = f_{\text{LLM}}(\text{instruction}, \text{text}, \mathbf{E}_{\text{emo}})$$
The resulting semantic tokens, emotion embedding, and speaker embedding are then passed to a conditional flow matching TTS decoder to generate a mel-spectrogram:
$$\mathbf{M} = f_{\text{CFM\_TTS}}(\mathbf{S}, \mathbf{E}_{\text{emo}}, \mathbf{E}_{\text{spk}})$$
Finally, BigVGAN converts the mel-spectrogram into waveform audio:
$$\hat{\mathbf{x}} = f_{\text{BigVGAN}}(\mathbf{M})$$
The paper emphasizes that the LLM is used for semantic planning, while explicit emotion control is handled by Emotion2embed. This separation is intended to prevent the language model from having to implicitly infer all fine-grained prosodic details from raw instructions.
Datasets and Training Setup
The experiments use the Emotional Speech Dataset (ESD) and the Chinese Natural Complex Emotion Dataset (CNCED). The training data are split into two subsets constructed with a semi-automatic annotation pipeline:
- Dataset-Base: 49,903 utterances with automatically generated emotion captions produced by Gemini-2.5 Pro from audio and metadata such as gender, age, and emotion. This subset provides weak supervision for large-scale pretraining.
- Dataset-Annotation: 28,402 utterances with manually verified emotion labels. High-expressiveness samples are selected and annotated with fine-grained emotion categories and intensity levels.
The final label space includes 27 emotion categories and three intensity levels for seven primary emotions, giving 21 emotion-intensity combinations. The paper reserves 7,600 utterances for evaluation.
ICE-Flow is trained on Dataset-Base for 100 epochs with batch size 2048, using Adam with cosine annealing and initial learning rate $10^{-4}$, then fine-tuned on Dataset-Annotation. The LLM backbone is Qwen2.5-0.5B, adapted with LoRA of rank 32, resulting in 9.87M trainable parameters. Acoustic features are produced with CFM and converted to waveforms using BigVGAN. Speaker embeddings and reference speech are used to preserve speaker identity.
The paper compares against CosyVoice2 and CosyVoice3 as strong instruction-driven baselines. It also evaluates an emotion-embedding baseline, Emotion2vec, in the representation analysis.
Emotion Representation Analysis
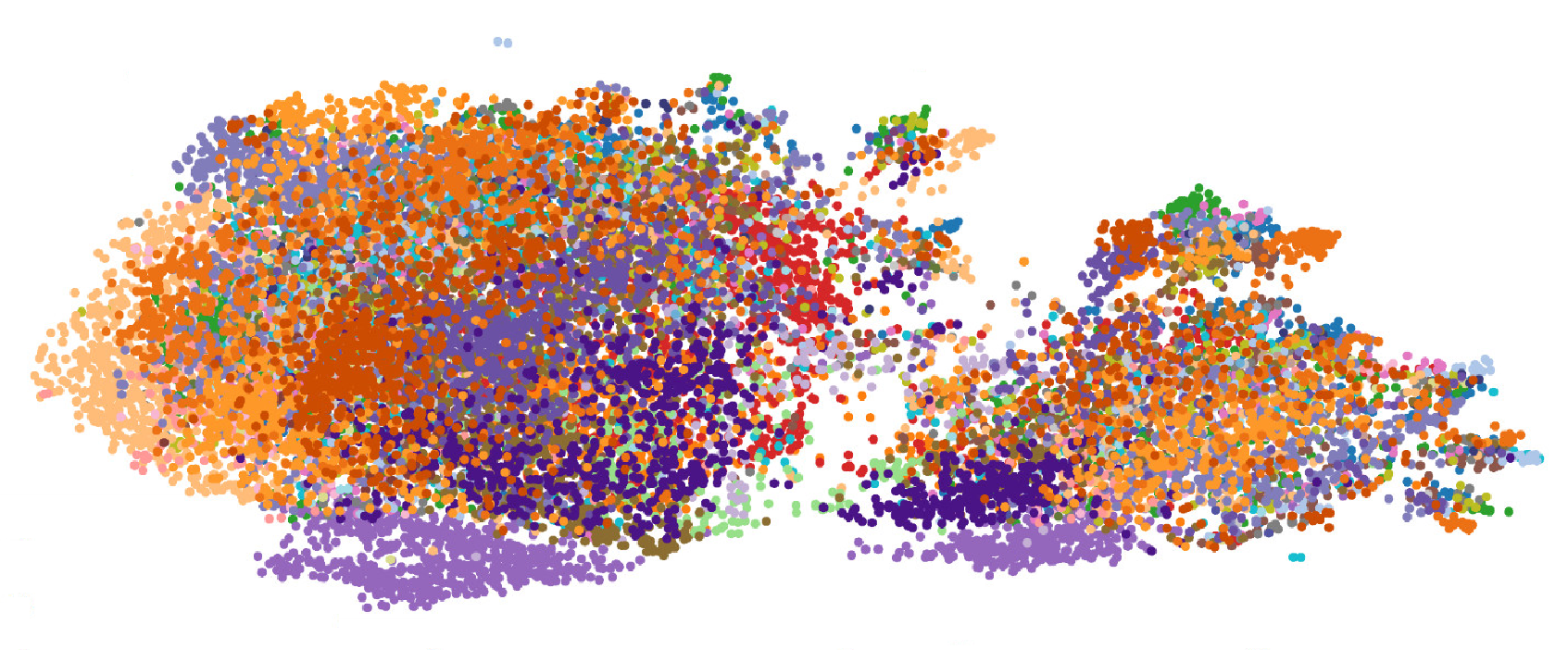
The paper first studies whether Emotion2embed and ICE-Flow actually organize emotion space in a more useful way than an existing self-supervised speech representation. The qualitative comparison uses t-SNE visualizations for 27 emotion categories and 21 intensity levels.
For the 27-category view, Emotion2vec shows substantial overlap between emotion classes and weak structure across categories. Emotion2embed produces tighter clusters and clearer category separation. ICE-Flow-generated embeddings preserve the ordinal intensity geometry while smoothing category boundaries. For the 21-level intensity view, Emotion2vec again lacks consistent ordering, while Emotion2embed and ICE-Flow show more regular progression across low, medium, and high intensity.



The quantitative analysis of instruction-generated embeddings focuses on whether ICE-Flow collapses to class prototypes or retains realistic variability. The paper reports four metrics: Prototype Collapse Score (PCS), Variance Ratio (VR), Sliced Wasserstein Distance (SWD), and Intensity Ordering Accuracy (IOA). Lower PCS and SWD are better, VR should be close to $1$, and higher IOA is better.
| Variant | PCS ↓ | VR ≈ 1 | SWD ↓ | IOA ↑ |
|---|---|---|---|---|
| ICE-Mean | 0.89 | 0.65 | 0.58 | 0.78 |
| ICE-Sample | 0.73 | 0.88 | 0.35 | 0.86 |
| ICE-Sample+Dist | 0.67 | 0.96 | 0.22 | 0.91 |
The trend is clear: prototype regression in ICE-Mean is reduced by sample-level supervision, and distribution regularization further improves the match to real embedding variability. The paper’s interpretation is that acoustically grounded supervision helps ICE-Flow preserve both realistic spread and intensity ordering, instead of generating a single prototype per emotion.
Subjective Evaluation
Listening tests are performed by 20 speech experts, with three raters per sample. The paper reports three human metrics: MOS for overall quality, ESMOS for emotion similarity, and SSMOS for speaker similarity. Two zero-shot task sets are evaluated: 21 emotion-intensity tasks and 27 fine-grained emotion tasks, each tested for male and female speakers.
21 emotion-intensity tasks
| Speaker | Model | MOS ↑ | ESMOS ↑ | SSMOS ↑ |
|---|---|---|---|---|
| Female | CosyVoice2 | 4.18 ± 0.09 | 3.92 ± 0.14 | 4.46 ± 0.10 |
| CosyVoice3 | 4.15 ± 0.10 | 3.98 ± 0.15 | 4.47 ± 0.09 | |
| EmoInstruct-TTS (Dual-Path) | 4.28 ± 0.08 | 4.25 ± 0.12 | 4.52 ± 0.09 | |
| -w/o Emo2emb (Text-Only) | 4.12 ± 0.10 | 3.78 ± 0.16 | 4.40 ± 0.10 | |
| -w/o Text Instruct (Emo2emb-Only) | 4.16 ± 0.11 | 3.99 ± 0.14 | 4.44 ± 0.11 | |
| Male | CosyVoice2 | 4.14 ± 0.10 | 3.80 ± 0.16 | 4.50 ± 0.09 |
| CosyVoice3 | 4.08 ± 0.11 | 3.92 ± 0.15 | 4.55 ± 0.08 | |
| EmoInstruct-TTS (Dual-Path) | 4.25 ± 0.09 | 4.10 ± 0.13 | 4.48 ± 0.10 | |
| -w/o Emo2emb (Text-Only) | 4.05 ± 0.11 | 3.70 ± 0.17 | 4.42 ± 0.11 | |
| -w/o Text Instruct (Emo2emb-Only) | 4.09 ± 0.10 | 3.86 ± 0.16 | 4.44 ± 0.10 |
On these tasks, the dual-path model achieves the best MOS and ESMOS across both genders. CosyVoice3 remains competitive in SSMOS, especially for male speakers, but the paper emphasizes that EmoInstruct-TTS is better at emotion control while maintaining strong naturalness. The ablations show that removing either the explicit emotion path or the text-instruction path hurts performance, which supports the claim that the two paths are complementary rather than redundant.
27 fine-grained emotion tasks
| Speaker | Model | MOS ↑ | ESMOS ↑ | SSMOS ↑ |
|---|---|---|---|---|
| Female | CosyVoice2 | 3.98 ± 0.11 | 3.55 ± 0.18 | 4.30 ± 0.12 |
| CosyVoice3 | 3.92 ± 0.12 | 3.50 ± 0.19 | 4.36 ± 0.11 | |
| EmoInstruct-TTS (Dual-Path) | 4.12 ± 0.10 | 3.92 ± 0.16 | 4.31 ± 0.12 | |
| -w/o Emo2emb (Text-Only) | 3.85 ± 0.12 | 3.32 ± 0.20 | 4.22 ± 0.12 | |
| -w/o Text Instruct (Emo2emb-Only) | 3.88 ± 0.12 | 3.48 ± 0.19 | 4.24 ± 0.12 | |
| Male | CosyVoice2 | 3.90 ± 0.12 | 3.48 ± 0.19 | 4.28 ± 0.12 |
| CosyVoice3 | 3.86 ± 0.12 | 3.44 ± 0.19 | 4.34 ± 0.11 | |
| EmoInstruct-TTS (Dual-Path) | 4.05 ± 0.11 | 3.78 ± 0.17 | 4.30 ± 0.12 | |
| -w/o Emo2emb (Text-Only) | 3.78 ± 0.13 | 3.26 ± 0.21 | 4.18 ± 0.13 | |
| -w/o Text Instruct (Emo2emb-Only) | 3.70 ± 0.14 | 3.20 ± 0.22 | 4.15 ± 0.13 |
The paper reports larger gains on the more difficult 27-category setting than on the 21-intensity setting. This is consistent with the claim that structured emotion embeddings are especially helpful when the target emotion space is fine-grained and the instruction-to-acoustics mapping is underdetermined. Again, removing either path degrades performance, and the text-only variant especially suffers on ESMOS.
Objective Evaluation
For 48-category emotional speech synthesis, the paper reports Emotion2embed Cosine Similarity (ECS) and Word Error Rate (WER). Here, higher ECS is better, and lower WER is better.
| Model | ECS ↑ | WER ↓ |
|---|---|---|
| CosyVoice2 | 0.855 | 0.0357 |
| CosyVoice3 | 0.865 | 0.0197 |
| EmoInstruct-TTS (Dual-Path) | 0.870 | 0.0259 |
| -w/o Emo2emb (Text-Only) | 0.859 | 0.0329 |
| -w/o Text Instruct (Emo2emb-Only) | 0.867 | 0.0486 |
The objective results show a strong emotional-alignment advantage for the dual-path model: it achieves the best ECS, while CosyVoice3 retains the lowest WER. The ablations are informative: the text-only variant degrades both ECS and WER, while the emotion-embedding-only variant keeps ECS relatively high but sharply worsens WER, suggesting that semantic guidance is necessary for stable linguistic realization.
Inference Efficiency
The paper explicitly notes that ICE-Flow adds only negligible overhead to the baseline synthesis pipeline. The MiniLM encoder is a single non-autoregressive forward pass of about $2$ ms, and the conditional flow matching sampler adds about $3$ ms using $25$ Euler steps. The total runtime increase is reported as less than $1\%$ for typical utterances and about $1$–$2\%$ for very short sentences.
What the Results Mean
Across qualitative, subjective, and objective analyses, the paper’s main story is consistent: explicit, structured emotion embeddings improve controllability in a way that pure instruction text does not. Emotion2embed provides a target space that is compact enough to be learned, yet structured enough to express fine-grained categories and intensity progression. ICE-Flow then makes this space usable from free-form language instructions. The LLM consumes both the instruction and the inferred emotion embedding, preserving the language model’s role in content planning while making emotional control more explicit.
Importantly, the work does not claim that emotion embeddings alone are sufficient. The ablations show that the emotion-only path can preserve emotional alignment but loses linguistic robustness, while the text-only path maintains better linguistic faithfulness but weakens emotion control. The full dual-path system is therefore presented as a balance between these two failure modes.
Conclusion and Stated Future Direction
The paper concludes that EmoInstruct-TTS improves emotional controllability and speech naturalness over strong baselines, especially for fine-grained emotion categories and intensity variations under zero-shot conditions. The authors’ stated future work is to extend the system toward open-ended natural-language emotional speech synthesis without predefined emotion categories. The paper does not include a separate limitations section, so this future direction is the clearest explicit boundary of the current method.