SDP-Codec
SDP-Codec: A Speaker-Decoupled Speech Codec with Pitch Injection for Low-Bitrate Coding and Zero-Shot Voice Conversion

SDP-Codec is a low-bitrate speech codec that separates speaker identity from content and prosody to enable high-quality speech reconstruction and zero-shot voice conversion. It uses a single-stage training method with pitch injection to reduce speaker leakage and improve voice conversion accuracy.
Demos
These demos show SDP-Codec’s performance on low-bitrate speech coding and zero-shot voice conversion using 24 kHz LibriTTS data. They highlight key metrics including speech quality, pitch preservation, and speaker accuracy during reconstruction and voice conversion. Watch how well the codec maintains naturalness and speaker identity as claimed in the paper.

Links
Paper & demos
Code & resources
Abstract
Speaker-decoupled speech codecs can reduce bitrate by separating global speaker attributes from local content and prosody, while supporting voice conversion. Existing speaker-decoupled codecs face a trade-off: methods that explicitly suppress speaker leakage often rely on multi-stage or auxiliary training, whereas simpler designs can leave residual speaker information in local tokens. We propose SDP-Codec, a speaker-decoupled, pitch-injected codec trained with a single-stage optimization pipeline. SDP-Codec derives local tokens from continuous pre-quantization features of a pretrained self-supervised encoder and injects normalized F0 via a pitch encoder-decoder with global-conditioned denormalization and soft-label pitch reconstruction objective. Across 16 kHz and 24 kHz settings, SDP-Codec achieves competitive reconstruction and strong zero-shot voice conversion at comparable bitrates, with the lowest speaker-probing accuracy among compared systems, suggesting reduced speaker leakage.
Introduction
SDP-Codec is a neural speech codec designed to reduce bitrate by explicitly separating speech into a global speaker branch and a local content/prosody branch, while still supporting zero-shot voice conversion. The paper is motivated by a practical tension in speaker-decoupled codecs: systems that aggressively suppress speaker leakage often require multi-stage or auxiliary training, whereas simpler systems can leave residual speaker identity in the local tokens. The authors propose a single-stage alternative that combines three ideas: (1) re-quantizing continuous pre-quantization self-supervised features instead of using the already-discretized vq-wav2vec units, (2) injecting normalized $F_0$ into the local stream so prosody is preserved without carrying absolute speaker pitch range, and (3) using a global-conditioned pitch decoder that reconstructs the original pitch contour with a soft-label objective.
The paper reports results in both $16\,\text{kHz}$ and $24\,\text{kHz}$ settings. Across the evaluated conditions, SDP-Codec aims to preserve waveform fidelity and intelligibility at roughly $0.45$--$0.52$ kbps while also improving zero-shot voice conversion. A recurring theme in the experiments is that the model’s local tokens contain less speaker information than competing codecs, as measured by a speaker-probing classifier.
Problem Setting and Design Goals
The target setting is low-bitrate neural speech coding for both reconstruction and zero-shot voice conversion. The paper argues that a useful codec should not only compress speech aggressively, but also factorize the representation so that speaker identity can be supplied separately from the local stream. This makes the local tokens smaller and cleaner, lowers the cost of downstream autoregressive speech-language modeling, and enables voice conversion by swapping the global speaker conditioning while retaining content and relative prosody.
The authors position SDP-Codec against three broad classes of prior low-bitrate approaches: text-aligned tokenizers that need text at inference time, variable-frame-rate methods that require duration prediction, and VC-oriented codecs that sacrifice faithful reconstruction in favor of generative decoding. Their central claim is that a speaker-decoupled codec can avoid these constraints if it can disentangle speaker timbre from local content without resorting to heavy auxiliary training.
Method
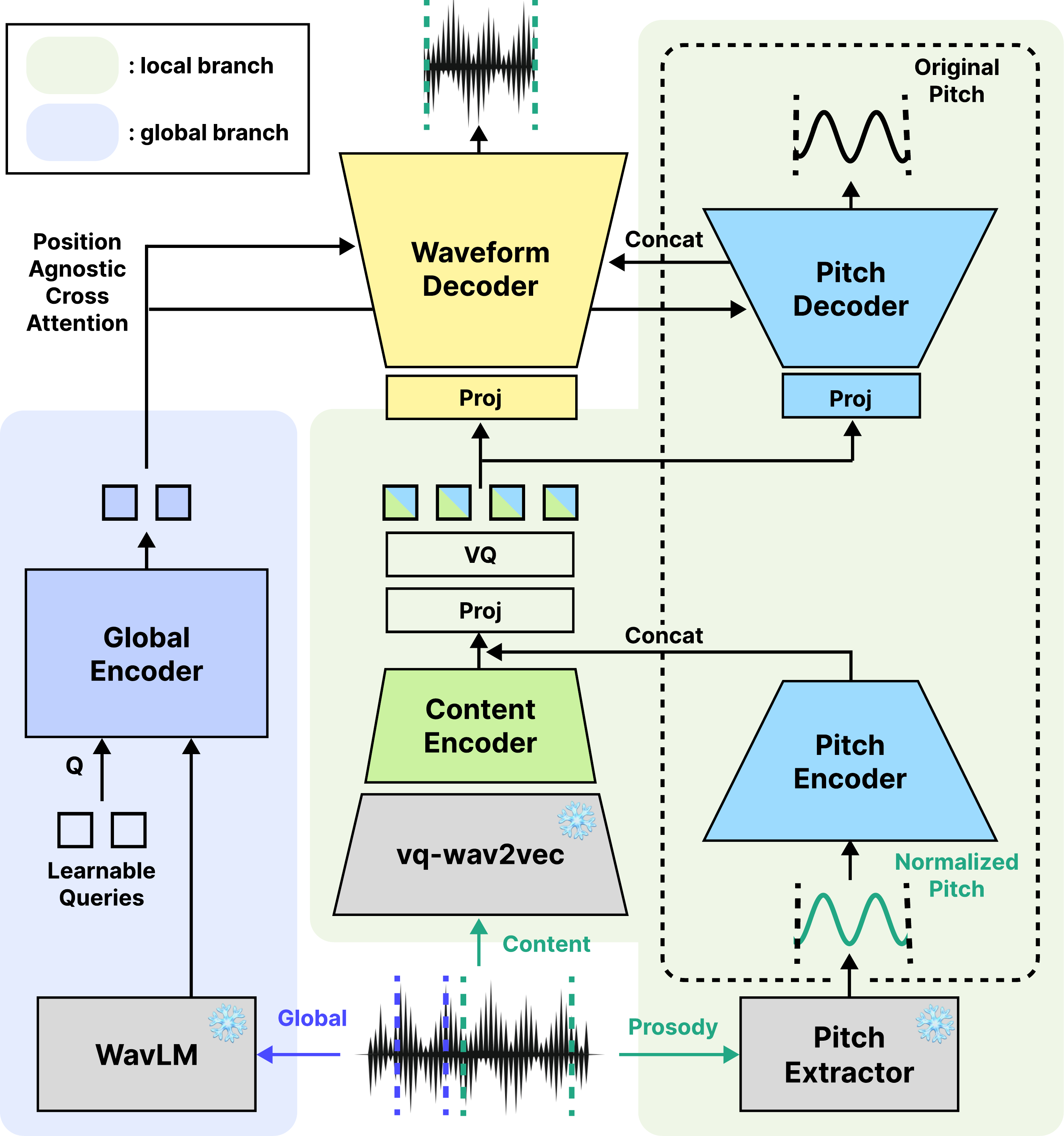
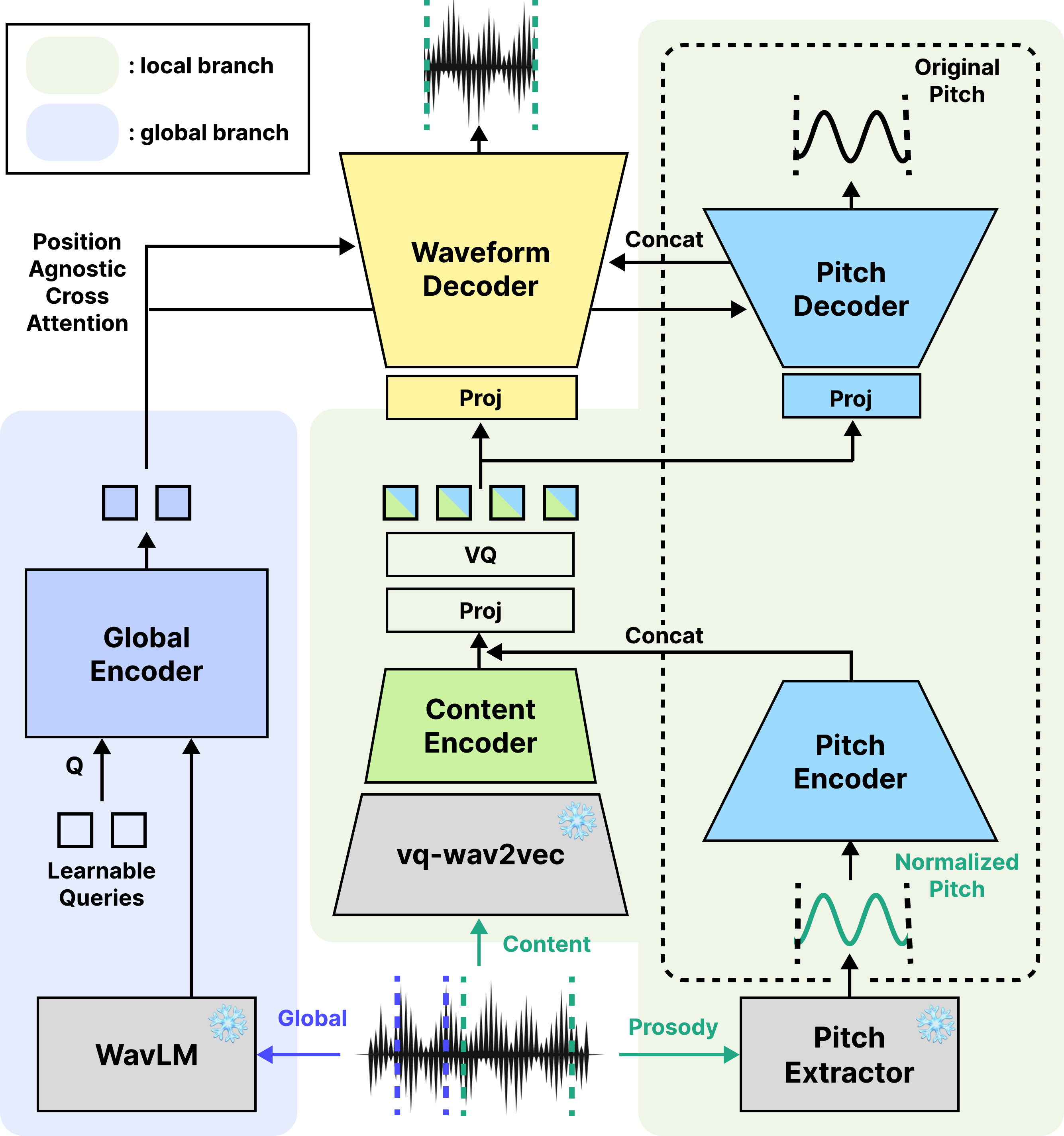
SDP-Codec has two branches. The local branch takes content and pitch information, fuses them, quantizes them with a single codebook, and decodes them into both waveform and pitch outputs. The global branch extracts a time-invariant speaker embedding and injects it into both decoders so that speaker timbre, and the speaker-dependent pitch range, are modeled outside the local tokens.
Content encoder
The content path builds on a frozen pretrained vq-wav2vec encoder. Rather than using the encoder’s discrete units $\hat{\mathcal{Z}}$ directly, SDP-Codec uses the continuous pre-quantization features $\mathcal{Z}$ because they retain richer content detail. A post-encoder made of residual CNN blocks with snake activations downsamples these features to produce the content representation used by the codec.
The design choice here is important: $\hat{\mathcal{Z}}$ is already compressed and can discard subtle phonetic and prosodic information before SDP-Codec’s own bottleneck is applied, while $\mathcal{Z}$ provides a more informative starting point. The paper later confirms this in ablations, where using $\hat{\mathcal{Z}}$ improves voice-conversion speaker similarity slightly but worsens reconstruction fidelity.
Pitch injection into the local stream
SDP-Codec explicitly reinjects pitch into the local pathway. A pretrained pitch extractor first produces a framewise log-$F_0$ contour. The contour is normalized per segment using mean and variance normalization so that speaker-dependent pitch range is removed. Unvoiced frames are assigned the fixed value $-3$, which is outside the normalized pitch range. The normalized contour is then passed through a pitch encoder, producing a compressed pitch feature that is concatenated with the content feature.
The joint feature is projected once and quantized with a single compact codebook. The paper emphasizes that the codebook size is intentionally small, acting as a tight bottleneck that forces the local stream to carry mostly high-level content information, while discarding low-level speaker timbre and absolute pitch-range information. After quantization, separate projection layers feed a waveform decoder and a pitch decoder.
The pitch decoder predicts a $360$-bin cent histogram at each frame. The target histogram is formed by Gaussian-blurring a one-hot bin derived from the ground-truth log-$F_0$ contour, and the model is trained with a soft-label binary cross-entropy objective. This is the paper’s key pitch-specific supervision, and it differs from a plain $L_2$ regression target in a way that the authors later show is important for content fidelity.
The pitch decoder is also conditioned on global speaker embeddings, allowing it to reconstruct the speaker-dependent mean and variance of log-$F_0$ rather than forcing that information into the local tokens. At each waveform decoder layer, the pitch-decoder hidden states are interpolated to match the waveform-decoder resolution and concatenated with the waveform-decoder hidden states, so pitch information directly reinforces waveform synthesis throughout the decoding stack.
Global branch
The global branch extracts WavLM features, compresses them into fixed-length time-invariant embeddings using a perceiver resampler, and injects them into both decoders through position-agnostic cross-attention. In parallel, a temporally pooled speaker embedding derived from the same features conditions adaptive snake modules. The overall effect is to keep the global branch focused on speaker identity and away from local time-varying linguistic detail.
Frozen pretrained components
The paper states that the pretrained vq-wav2vec encoder, WavLM feature extractor, and FCPE pitch extractor are frozen during training. This keeps the optimization centered on the codec’s trainable components: the post-encoder, pitch encoder/decoder, quantizer, waveform decoder, and the global-conditioning pathways.
Training objective
SDP-Codec is trained with a single-stage objective composed of four terms: a multi-scale mel-spectrogram $L_1$ reconstruction loss, a commitment loss with the straight-through estimator for the joint content-$F_0$ codebook, an adversarial loss from a multi-scale time-domain discriminator with LSGAN, plus an $L_1$ feature-matching loss, and the soft-label pitch reconstruction loss.
The paper’s main optimization message is that explicit pitch supervision should be smooth and classification-like rather than direct regression-like. The soft-label formulation provides gradients around the true pitch bin, which the ablation later shows to be more effective than an $L_2$ target for both reconstruction quality and speaker-decoupling behavior.
Implementation Details
The paper reports three trained variants. SDP-Codec-16-S and SDP-Codec-24-S are small models trained on LibriSpeech and LibriTTS respectively, each using $3.36$-second input segments. SDP-Codec-16-L is a larger variant trained on LibriSpeech plus the English subset of Multilingual LibriSpeech, using $6$-second segments. The authors provide only a $16\,\text{kHz}$ large-scale model because of resource constraints and because most direct baselines are evaluated at $16\,\text{kHz}$.
All models are trained for $600{,}000$ steps. The small models use $4\times$ RTX 4090 GPUs with effective batch size $24$, while the large model uses $4\times$ RTX 5090 GPUs with effective batch size $16$. The full models have $406$ million parameters, of which $74$ million are trainable.
The local codebook size is $300$ entries for the small models, corresponding to about $0.45$ kbps, and $1{,}536$ entries for the large model, corresponding to about $0.52$ kbps. The vq-wav2vec encoder runs at $100$ Hz; the post-encoder downsamples by a factor of $2$ to reach the $50$ Hz target rate. The waveform decoder upsamples in four stages with strides $[2,4,5,8]$ for $16\,\text{kHz}$ output and $[3,4,5,8]$ for $24\,\text{kHz}$ output. The pitch extractor yields a $100$ Hz contour at $16\,\text{kHz}$ input and a $150$ Hz contour at $24\,\text{kHz}$ input after interpolation. The pitch encoder downsamples once at the final layer, with strides $[1,1,1,2]$ for $16\,\text{kHz}$ and $[1,1,1,3]$ for $24\,\text{kHz}$; the pitch decoder mirrors this structure.
Datasets, Baselines, and Evaluation
For reconstruction, the paper evaluates on LibriSpeech test-clean for the $16\,\text{kHz}$ setting and LibriTTS test-clean for the $24\,\text{kHz}$ setting. For zero-shot voice conversion, each source utterance is assigned a different target speaker, and a reference utterance from the target speaker is provided for global conditioning.
Objective metrics are UTMOS for perceptual naturalness, SECS for speaker similarity using Resemblyzer, WER from a HuBERT-based CTC ASR model fine-tuned on LibriSpeech, F0 correlation as the Pearson correlation over voiced frames using Harvest-extracted contours, and STOI for intelligibility. The paper explicitly omits PESQ, noting that it is less suitable for modern neural-codec artifacts.
For subjective evaluation, the authors conduct MOS tests for voice conversion: naturalness MOS (NMOS) on a $5$-point ACR scale for utterances longer than $3$ seconds, and speaker similarity MOS (SMOS) on a $4$-point scale with a target-speaker reference. They collect ratings from $27$ listeners over $30$ random samples for the $16\,\text{kHz}$ and $24\,\text{kHz}$ models, and report the mean and $95\%$ confidence intervals.
The paper compares against recent open-source low-bitrate codecs and VC systems, including LSCodec, DualCodec, VARSTok, vec2wav2.0, Vevo, XCodec, FocalCodec, FlexiCodec, BiCodec, MSRCodec, and EZ-VC depending on sample rate and task. The authors note that strict comparison is difficult because the baselines vary in training data, bitrate, and evaluation protocol, so they configure some baselines to approximate SDP-Codec’s bitrate as closely as possible.
Main Objective Results
The tables below summarize the main numeric results reported in the paper. The authors’ overall claim is that SDP-Codec reaches competitive reconstruction quality and strong zero-shot voice conversion at comparable bitrates, while also achieving the lowest speaker-probing accuracy among the compared systems.
Selected reconstruction and zero-shot voice conversion results at $24\,\text{kHz}$
| Method | Bitrate | Train set | Test set | UTMOS | SECS | WER | F0 corr. | STOI |
|---|---|---|---|---|---|---|---|---|
| DualCodec (25 Hz) | $0.60$ kbps | Emilia (100k) | LibriTTS | 3.9503 | 0.8997 | 3.12 | 0.6537 | 0.8887 |
| VARSTok | $0.43$ kbps | LibriTTS | LibriTTS | 3.6498 | 0.8917 | 15.18 | 0.6097 | 0.8552 |
| LSCodec | $0.45$ kbps | LibriTTS | LibriTTS | 4.0629 | 0.9356 | 5.71 | 0.6245 | 0.7511 |
| SDP-Codec-24-S | $0.45$ kbps | LibriTTS | LibriTTS | 4.0542 | 0.9353 | 5.54 | 0.6522 | 0.8798 |
| vec2wav2.0 | $1.66$ kbps | LibriTTS | LibriTTS | 3.9349 | 0.8080 | 6.45 | 0.6143 | --- |
| Vevo | $0.65$ kbps | Internal (60k) | LibriTTS | 3.6749 | 0.7887 | 9.66 | 0.5002 | --- |
| LSCodec | $0.45$ kbps | LibriTTS | LibriTTS | 3.9034 | 0.7965 | 7.48 | 0.5357 | --- |
| SDP-Codec-24-S | $0.45$ kbps | LibriTTS | LibriTTS | 4.0055 | 0.8133 | 7.04 | 0.6162 | --- |
The paper’s text emphasizes that at $24\,\text{kHz}$, SDP-Codec-24-S matches LSCodec on UTMOS and SECS while improving WER, F0 correlation, and STOI for reconstruction. The largest gains are reported in STOI and F0 correlation. In zero-shot voice conversion, SDP-Codec-24-S improves every listed objective metric relative to LSCodec and also approaches the larger-scale VC reference Vevo on NMOS and SMOS.
Selected reconstruction and zero-shot voice conversion results at $16\,\text{kHz}$
| Method | Bitrate | Train set | Test set | UTMOS | SECS | WER | F0 corr. | STOI |
|---|---|---|---|---|---|---|---|---|
| FocalCodec (50 Hz) | $0.65$ kbps | LibriTTS | LibriSpeech | 4.0591 | 0.8947 | 1.43 | 0.6287 | 0.8602 |
| XCodec | $0.50$ kbps | LibriSpeech | LibriSpeech | 3.8416 | 0.8487 | 3.00 | 0.6218 | 0.8354 |
| SDP-Codec-16-S | $0.45$ kbps | LibriSpeech | LibriSpeech | 4.0124 | 0.9372 | 4.44 | 0.6643 | 0.8724 |
| FlexiCodec | $0.52$ kbps | LL (52k) | LibriSpeech | 4.0834 | 0.9249 | 2.49 | 0.6519 | 0.8842 |
| BiCodec | $0.65$ kbps | Emilia+LS (3k) | LibriSpeech | 4.1853 | 0.9171 | 1.98 | 0.6879 | 0.9220 |
| MSRCodec | $0.52$ kbps | MLS+TS+Vox (53.6k) | LibriSpeech | 4.1382 | 0.9392 | 1.69 | 0.6366 | 0.8876 |
| SDP-Codec-16-L | $0.52$ kbps | MLS+LS (45.5k) | LibriSpeech | 3.9954 | 0.9436 | 3.08 | 0.6690 | 0.8881 |
| EZ-VC | $0.45$ kbps | En (3.1k)+IN5 (9.8k) | LibriSpeech | 4.0557 | 0.6871 | 14.18 | 0.2041 | --- |
| BiCodec | $0.65$ kbps | Emilia+LS (3k) | LibriSpeech | 3.9103 | 0.7577 | 3.43 | 0.5517 | --- |
| MSRCodec | $0.52$ kbps | MLS+TS+Vox (53.6k) | LibriSpeech | 3.8966 | 0.7396 | 2.18 | 0.5806 | --- |
| SDP-Codec-16-L | $0.52$ kbps | MLS+LS (45.5k) | LibriSpeech | 3.9832 | 0.8405 | 4.11 | 0.6088 | --- |
The authors characterize the $16\,\text{kHz}$ results as a trade-off: SDP-Codec-16-L sacrifices some reconstruction fidelity relative to the strongest reconstruction-focused codecs, but it delivers stronger zero-shot voice conversion than the closest codec-based baselines. SDP-Codec-16-L reports the highest VC speaker similarity among the codec-based systems in their comparison and also reaches the highest F0 correlation in that group. For subjective VC evaluation, it achieves the strongest naturalness and among the strongest speaker similarity scores.
Subjective Voice Conversion Results
| Sample rate | Method | NMOS | SMOS |
|---|---|---|---|
| $24\,\text{kHz}$ | Vevo | 3.88 $\pm$ 0.19 | 3.43 $\pm$ 0.14 |
| LSCodec | 3.76 $\pm$ 0.21 | 2.34 $\pm$ 0.19 | |
| vec2wav2.0 | 3.68 $\pm$ 0.20 | 2.63 $\pm$ 0.16 | |
| SDP-Codec-24-S | 3.89 $\pm$ 0.18 | 3.20 $\pm$ 0.17 | |
| $16\,\text{kHz}$ | EZ-VC | 3.19 $\pm$ 0.21 | 3.51 $\pm$ 0.12 |
| BiCodec | 3.37 $\pm$ 0.23 | 2.04 $\pm$ 0.19 | |
| MSRCodec | 3.77 $\pm$ 0.20 | 1.93 $\pm$ 0.17 | |
| SDP-Codec-16-L | 3.95 $\pm$ 0.18 | 3.46 $\pm$ 0.14 |
Subjectively, SDP-Codec-24-S obtains the highest NMOS among the $24\,\text{kHz}$ systems reported, matching the larger-scale reference Vevo on naturalness and coming close on speaker similarity. At $16\,\text{kHz}$, SDP-Codec-16-L achieves the highest NMOS among the evaluated systems and the highest SMOS among the codec-based baselines, while EZ-VC attains slightly higher SMOS but substantially lower NMOS and much worse content preservation.
Ablation Studies
The ablations isolate three design choices: the use of continuous pre-quantization features $\mathcal{Z}$ versus discrete units $\hat{\mathcal{Z}}$, the pitch loss formulation, and whether explicit $F_0$ injection is used at all. The paper reports these ablations primarily for the $24\,\text{kHz}$ small model.
| Variant | UTMOS | SECS | WER | F0 corr. | STOI |
|---|---|---|---|---|---|
| Reconstruction | |||||
| SDP-Codec-24-S w/ $\hat{\mathcal{Z}}$ | 4.0659 | 0.9295 | 6.45 | 0.6378 | 0.8541 |
| SDP-Codec-24-S w/ $L_2$ | 4.0251 | 0.9326 | 6.45 | 0.6498 | 0.8731 |
| SDP-Codec-24-S w/o $F_0$ | 4.0107 | 0.9305 | 5.79 | 0.6367 | 0.8718 |
| SDP-Codec-24-S | 4.0542 | 0.9353 | 5.54 | 0.6522 | 0.8798 |
| Zero-shot voice conversion | |||||
| SDP-Codec-24-S w/ $\hat{\mathcal{Z}}$ | 3.9940 | 0.8315 | 8.17 | 0.6072 | --- |
| SDP-Codec-24-S w/ $L_2$ | 3.9709 | 0.8146 | 8.42 | 0.6178 | --- |
| SDP-Codec-24-S w/o $F_0$ | 3.9670 | 0.8123 | 7.41 | 0.6023 | --- |
| SDP-Codec-24-S | 4.0055 | 0.8133 | 7.04 | 0.6162 | --- |
The paper draws two main conclusions from the ablation study. First, explicit pitch injection helps both reconstruction and voice conversion, but only when the pitch loss is formulated as a soft-label classification problem over $360$ cent bins; replacing that loss with $L_2$ degrades WER and weakens the intended benefits. Second, using continuous $\mathcal{Z}$ is better for content fidelity than using the already-discrete $\hat{\mathcal{Z}}$, even though $\hat{\mathcal{Z}}$ can slightly help voice-conversion similarity by removing more detail early.
Speaker Probing
To directly test speaker leakage in the local tokens, the authors train an MLP speaker classifier on the full LibriTTS training set with a per-speaker $9{:}1$ train/test split. For MSRCodec, they probe the content-related streams separately. The resulting accuracies are:
| Model / stream | Speaker-probing accuracy |
|---|---|
| BiCodec | 9.00% |
| LSCodec | 15.5% |
| SDP-Codec-24-S | 6.87% |
| MSRCodec (H) | 15.2% |
| MSRCodec (H+p) | 39.4% |
| MSRCodec (H+p+r) | 46.1% |
| SDP-Codec-16-L | 4.45% |
This probe strongly supports the paper’s disentanglement claim: SDP-Codec yields the lowest speaker-probing accuracy among the evaluated systems, suggesting that the local tokens retain the least speaker information. The large gap between SDP-Codec and the prosody/residual streams in MSRCodec is used as evidence that merely splitting streams does not guarantee effective leakage suppression.
Interpretation of the Results
The paper’s results consistently point to the same mechanism: a compact codebook applied after continuous SSL features, coupled with explicit normalized pitch injection, can compress away unwanted speaker detail while preserving enough content and prosody for both reconstruction and voice conversion. Compared with LSCodec, SDP-Codec is more faithful in several reconstruction metrics at $24\,\text{kHz}$ and substantially stronger in F0 correlation and STOI, while also improving zero-shot VC. Compared with codec systems such as BiCodec and MSRCodec at $16\,\text{kHz}$, SDP-Codec’s reconstruction is not always the strongest, but its VC behavior and speaker separation are better aligned with the goal of clean speaker decoupling.
The subjective MOS results reinforce the objective findings. SDP-Codec-24-S reaches the highest naturalness among the $24\,\text{kHz}$ methods in the paper, and SDP-Codec-16-L reaches the highest naturalness among the $16\,\text{kHz}$ methods. The speaker-similarity scores are also strong, especially when compared with other codec-based approaches.
Limitations and Stated Future Work
The paper is explicit that content fidelity remains the main limitation of the current system. This is visible in the $16\,\text{kHz}$ large-scale setting, where SDP-Codec-16-L trades reconstruction quality for stronger zero-shot VC behavior. The authors also note that using $\hat{\mathcal{Z}}$ is not ideal because it discards content detail before the codec’s own bottleneck can act, which is why the final model uses continuous $\mathcal{Z}$.
In the conclusion, the authors state that future work will focus on improving content fidelity further and on applying SDP-Codec tokens to downstream speech language models.
Takeaway
SDP-Codec is a single-stage, speaker-decoupled neural codec that combines continuous SSL content features, a compact single codebook, normalized pitch injection, and global-conditioned pitch denormalization. The reported experiments show that this design can reduce speaker leakage in the local tokens, maintain competitive reconstruction quality, and deliver strong zero-shot voice conversion at comparable bitrates across both $16\,\text{kHz}$ and $24\,\text{kHz}$ settings.
Code & Implementation
This repository provides the official implementation of SDP-Codec, a speaker-decoupled speech codec with pitch injection for low-bitrate coding and zero-shot voice conversion as described in the paper.
The code base is organized around reproducing the main experimental setup from the paper, utilizing pretrained models (VQ-Wav2Vec for content and WavLM Large for speaker encoding) alongside a residual vector quantizer (RVQ) with a codebook size of 300. Training, inference, and testing are implemented under the sdpcodec/ folder, with PyTorch Lightning modules and dataloaders in ptl/, and codec-specific encoder and decoder logic in vq/.
The repository includes comprehensive scripts for training (sdpcodec.train) and inference (sdpcodec.infer), supporting source reconstruction and reference-based voice conversion modes. Configuration files using Hydra are provided in configs/ to replicate the paper's settings, particularly the 24 kHz LibriTTS experiment.
Large pretrained weights (WavLM Large and VQ-Wav2Vec k-means) are required for operation and must be downloaded separately, as documented in docs/pretrained_assets.md. The repository supports a streamlined installation and a quick single-GPU smoke test, easing reproduction of the paper’s results.