PIAvatar
PIAvatar: Physically Interactive Avatars via Deformation Gradient Decoupling
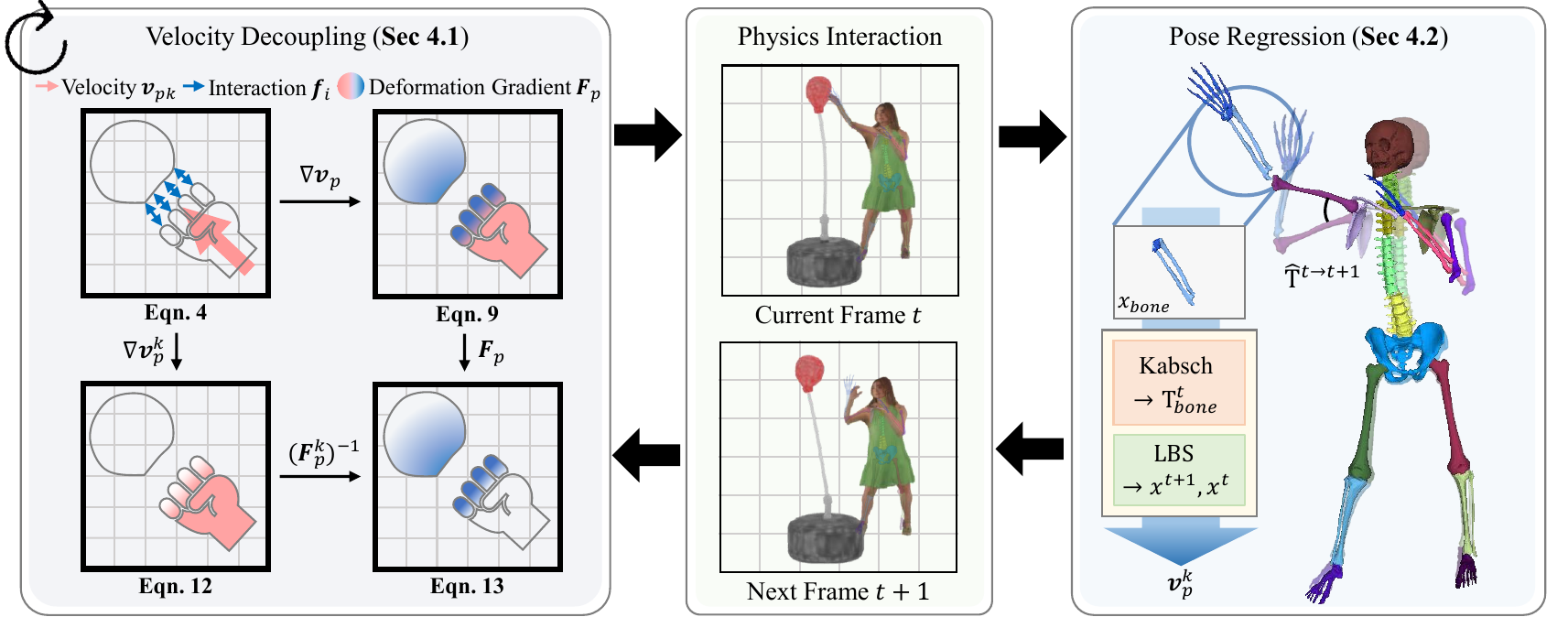
PIAvatar enables physically interactive 3D human avatars by decoupling kinematic movement from deformation, allowing realistic physical interactions with environments and other avatars. It combines a skeletal pose tracking system with a material simulation for real-time, controllable, non-rigid avatar deformation.
Links
Paper & demos
Abstract
3D human avatars have shown impressive visual fidelity driven by pose-conditioned models, yet they still lack the physical ability required for interactions with each other and environments. Although recent studies have made various attempts to incorporate physical characteristics into 3D avatars, they only exhibit limited physical deformations, often leading to constrained interaction behaviors. To resolve this issue, we present PIAvatar, a framework to simultaneously enable physically aware interactions between avatar-avatar and avatar-environment, and a non-rigid deformable human body simulation. In this work, our key insight is to decouple kinematic velocity from deformation gradient. When external forces act on avatars, the kinematic velocity induces stress which hinders the avatar's ability to achieve a desired pose. In addition, we integrate a skeletal framework within the avatar. It allows estimating its poses and real-time tracking in a closed form, even during non-rigid physical interactions. Our approach is implemented within a conventional Material Point Method framework to ensure physically consistent dynamics. We lastly evaluate the method on both human-object and human-human interaction scenarios to assess its behavior under diverse interaction settings.
1. Problem Setting and Core Idea
PIAvatar targets a gap in animatable 3D human avatars: they can look realistic and follow pose sequences, but they usually cannot participate in physically meaningful avatar-object or avatar-avatar interactions. The paper’s central claim is that physically interactive avatars need two properties at once: (1) bidirectional force exchange with the environment and other avatars, and (2) non-rigid body deformation that is consistent with those interactions.
The key technical insight is that, in a standard Material Point Method (MPM) simulation, a user-imposed kinematic velocity can be absorbed into the deformation gradient $ \mathbf{F}$, which then generates internal stress and resists the intended pose. PIAvatar’s solution is to decouple kinematic motion from the deformation gradient update, so that the commanded pose motion drives the avatar without generating spurious stress, while physical contacts still produce ordinary stress responses.
The paper further embeds an internal skeletal structure inside the avatar and uses closed-form rigid alignment to recover pose during simulation. This is important because once the avatar deforms non-rigidly, pose tracking from the surface alone becomes ill-posed. PIAvatar therefore combines MPM continuum simulation with explicit skeleton-based pose regression to keep the avatar controllable in real time.
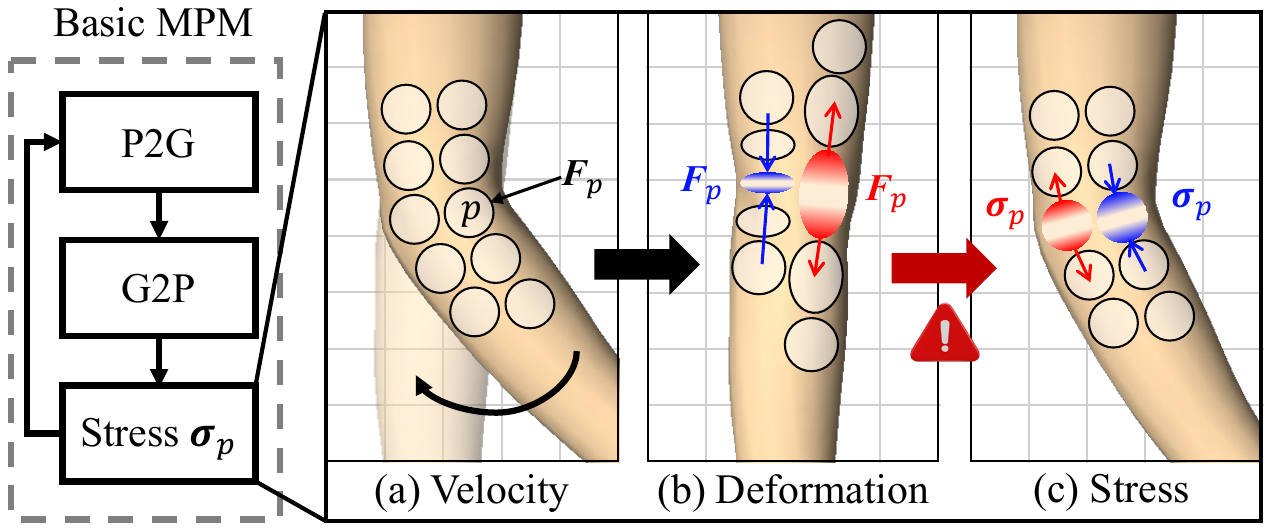
2. Background: Why Standard MPM Is Not Enough
The method builds on the standard continuum-mechanics formulation used by MPM. The paper restates conservation of mass and momentum as
$$ \frac{d\rho}{dt} + \rho \nabla \cdot \mathbf{v} = 0, \qquad \rho \frac{d\mathbf{v}}{dt} = \nabla \cdot \boldsymbol{\sigma} + \rho \mathbf{g}, $$
where $\rho$ is density, $\mathbf{v}$ is velocity, $\boldsymbol{\sigma}$ is Cauchy stress, and $\mathbf{g}$ is gravity. Each particle carries position $\mathbf{x}_p$, velocity $\mathbf{v}_p$, mass $m_p$, and deformation gradient $\mathbf{F}_p$. The stress is computed from a strain-energy density $\Psi$ via
$$ \boldsymbol{\sigma}_p = \frac{1}{J_p} \mathbf{F}_p \frac{\partial \Psi(\mathbf{F}_p)}{\partial \mathbf{F}_p^{\top}}, \qquad J_p = \det(\mathbf{F}_p). $$
In the default MPM update, particle quantities are transferred to a grid, grid forces are solved, and then particle states are updated again:
$$ m_i = \sum_p w_{ip} m_p, \qquad m_i \mathbf{v}_i = \sum_p w_{ip} m_p \mathbf{v}_p + \Delta t\, \mathbf{f}_i, $$
$$ \mathbf{f}_i = \mathbf{f}_i^{\mathrm{int}} + \mathbf{f}_i^{\mathrm{ext}}, \qquad \mathbf{f}_i^{\mathrm{int}} = -\sum_p V_p\, \boldsymbol{\sigma}_p \nabla w_{ip}, $$
and on the G2P step,
$$ \mathbf{v}_p \leftarrow \sum_i w_{ip} \mathbf{v}_i, \qquad \mathbf{x}_p \leftarrow \mathbf{x}_p + \Delta t\, \mathbf{v}_p, $$
$$ \nabla \mathbf{v}_p = \sum_i \mathbf{v}_i (\nabla w_{ip})^{\top}, \qquad \mathbf{F}_p \leftarrow \left(\mathbf{I} + \Delta t\, \nabla \mathbf{v}_p\right) \mathbf{F}_p. $$
The paper emphasizes that this last line is the source of the problem: when the avatar is driven by a pose-conditioned kinematic velocity, that velocity still contributes to $\mathbf{F}_p$, which in turn produces internal stress and resistance against the intended motion. For articulated humans, that resistance accumulates and causes pose drift or failure to reach the target pose.
3. Method Overview
PIAvatar is built around two coupled components:
- Kinematic Deformation Decoupling: separate the user-defined motion from the deformation-gradient update so that commanded motion does not become elastic strain.
- Skeleton-based Pose Regression: embed a skeletal structure inside the avatar, estimate per-bone rigid transforms with Kabsch alignment, and derive the next kinematic velocity from consecutive posed avatars.
The overall system remains inside a conventional MPM pipeline, so contact handling, momentum exchange, and deformation are still governed by a physically consistent particle-grid continuum simulation.
4. Kinematic Deformation Decoupling
The first contribution is the explicit separation of kinematic velocity from the elastic deformation state. The paper observes that if the commanded avatar velocity is pushed through the standard MPM update, it contaminates $\mathbf{F}_p$ and creates restorative stress. PIAvatar instead computes a separate kinematic velocity field $\mathbf{v}_i^k$ and a separate kinematic deformation gradient $\mathbf{F}_p^k$.
The kinematic part is transferred to the grid using the same particle-to-grid weighting but with kinematic mass $m_p^k$:
$$ m_i^k = \sum_p w_{ip} m_p^k, \qquad m_i^k \mathbf{v}_i^k = \sum_p w_{ip} m_p^k \mathbf{v}_p^k. $$
The corresponding kinematic deformation is updated as
$$ \nabla \mathbf{v}_p^k = \sum_i \mathbf{v}_i^k (\nabla w_{ip})^{\top}, \qquad \mathbf{F}_p^k \leftarrow \left(\mathbf{I} + \Delta t\, \nabla \mathbf{v}_p^k\right) \mathbf{F}_p^k. $$
Finally, the paper removes this kinematic component from the total deformation gradient via a first-order multiplicative decomposition:
$$ \mathbf{F}_p \leftarrow \mathbf{F}_p (\mathbf{F}_p^k)^{-1}. $$
Conceptually, this makes the elastic state respond to physical interactions while excluding user-commanded motion from the stress-generating deformation path. The result is that the avatar can follow the target pose without the simulator generating an artificial restoring force against that motion.
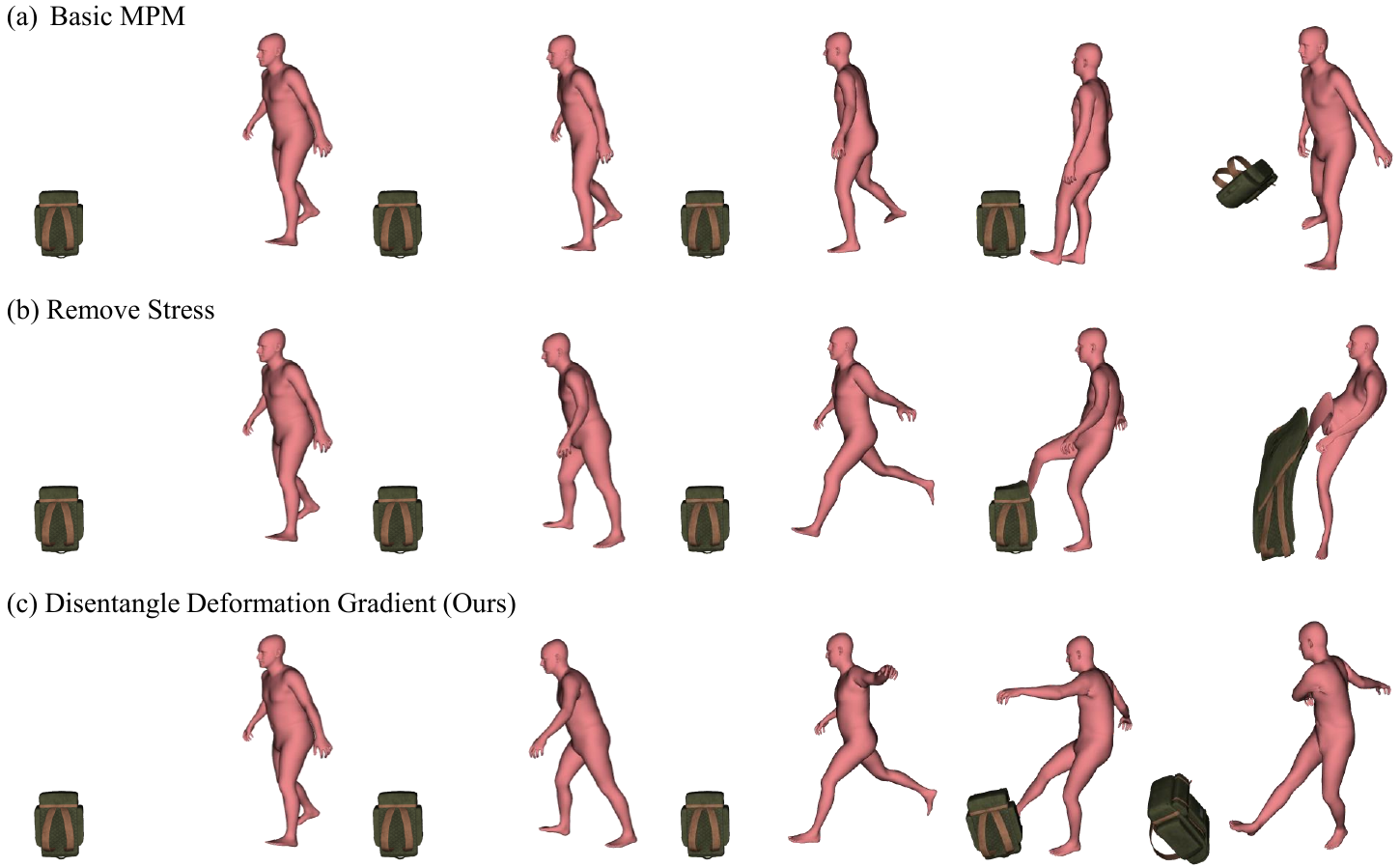
4.1 Why not simply remove all stress?
The supplementary material makes an important distinction: if all stress is removed, the avatar can follow pose commands more easily, but then it cannot push against objects or receive realistic contact feedback. In that case, the avatar simply merges with obstacles. PIAvatar therefore preserves stress induced by external contact while excluding only the stress induced by the kinematic command itself.
5. Skeleton-based Pose Regression and Kinematic Velocity Computation
Physical interactions deform the avatar, which complicates pose recovery. PIAvatar avoids expensive inverse fitting or learned pose regression by embedding a skeleton inside the avatar and tracking that skeleton directly. The skeleton is represented by groups of bone particles; when the avatar is hit or compressed, force is transmitted to the internal bones, allowing the current pose to be inferred from their motion.
For each bone, the paper uses the Kabsch algorithm to compute the rigid transform between canonical bone particles and their current positions:
$$ \mathbf{T}^{t}_{\text{bone}} = [\mathbf{R}^{t}_{\text{bone}}, \mathbf{t}^{t}_{\text{bone}}] = K\!\left(\mathbf{x}^{\mathrm{cano}}_{\text{bone}}, \mathbf{x}^{t}_{\text{bone}}\right). $$
This is solved in closed form by centering the point sets, forming a correlation matrix, applying SVD, and correcting reflections if needed. The result is a rigid rotation $\mathbf{R}_{\text{bone}}$ and translation $\mathbf{t}_{\text{bone}}$ for each joint.
To maintain temporal consistency, PIAvatar does not infer the next pose independently from the current deformed state. Instead, it uses incremental transforms from the pose sequence:
$$ \hat{\mathbf{T}}^{t \to t+1} = (\hat{\mathbf{T}}^{t})^{-1} \hat{\mathbf{T}}^{t+1}, \qquad \mathbf{T}^{t+1}_{\text{bone}} = \hat{\mathbf{T}}^{t \to t+1} \mathbf{T}^{t}_{\text{bone}}. $$
The next posed avatar is then produced by Linear Blend Skinning (LBS):
$$ \mathbf{x}^{t} = \mathrm{LBS}(\mathbf{T}^{t}_{\text{bone}}, \mathbf{x}^{\mathrm{cano}}), \qquad \mathbf{x}^{t+1} = \mathrm{LBS}(\mathbf{T}^{t+1}_{\text{bone}}, \mathbf{x}^{\mathrm{cano}}), $$
and the kinematic velocity is the finite difference
$$ \mathbf{v}_p^k = \frac{\mathbf{x}^{t+1} - \mathbf{x}^{t}}{\Delta t}. $$
This velocity is then fed into the decoupled MPM update described above. The paper stresses that this computation is closed-form and not learning-based; in other words, there is no training objective or network optimization in the proposed avatar simulator.
5.1 Practical rationale for pose-based control
The supplementary material explains why the authors choose pose-based control rather than muscle-activation control. The activation-to-torque-to-pose mapping is highly nonlinear, making the inverse problem difficult and making some poses unattainable in practice. Pose sequences are therefore a more direct and controllable interface for physical avatar simulation.
6. Experimental Setup
The evaluation covers both avatar-object and avatar-avatar interactions, using two avatar representations:
- Animatable Gaussians (AG): a clothed Gaussian avatar trained on 7 ActorsHQ models, with about 300,000 particles on average.
- SMPL-X: a parametric mesh avatar with 10,475 particles.
Pose sequences come from AMASS. External objects are sourced from BlenderNeRF and Sketchfab. The internal skeleton is based on OSSO, which provides joint hierarchy, pose alignment, and skinning weights. The OSSO skeleton contains 74,496 particles, which the paper downsampled by 10× using voxel-grid downsampling to reduce simulation time and Kabsch cost.
PIAvatar is implemented on top of PhysGaussian and uses a $200^3$ background grid unless otherwise stated. Each rendered frame is simulated with 100 steps. The reported experiments run on an AMD Ryzen 9 7950X3D CPU and a single NVIDIA RTX 4090 GPU, with 3DGRUT used for visualization.
The paper also reports heterogeneous material settings, including a body modeled with a Neo-Hookean hyperelastic law ($E = 10^5$) and compliant regions such as garments and hair modeled with corotated linear elasticity ($E = 10^2$ to $10^3$). These are treated as effective engineering parameters chosen to keep the MPM discretization numerically stable.
7. Quantitative Results
The main quantitative comparison is against a basic MPM baseline, using target avatar positions computed from the pose sequence. The metrics are MSE, RMSE, and [email protected] m, evaluated at 100, 200, 300, and 400 simulation steps for both AG and SMPL-X. The reported numbers show large improvements from kinematic deformation decoupling.
| Method | Metric | Animatable Gaussians | SMPL-X | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 100 | 200 | 300 | 400 | 100 | 200 | 300 | 400 | ||
| Basic MPM | MSE ↓ | 0.079 | 0.198 | 0.275 | 0.332 | 0.089 | 0.138 | 0.206 | 0.248 |
| RMSE ↓ | 0.100 | 0.232 | 0.317 | 0.380 | 0.120 | 0.165 | 0.242 | 0.291 | |
| [email protected] ↑ | 0.097 | 0.041 | 0.020 | 0.020 | 0.358 | 0.181 | 0.086 | 0.036 | |
| PIAvatar | MSE ↓ | 0.019 | 0.027 | 0.036 | 0.046 | 0.013 | 0.022 | 0.031 | 0.039 |
| RMSE ↓ | 0.023 | 0.034 | 0.043 | 0.056 | 0.016 | 0.025 | 0.034 | 0.044 | |
| [email protected] ↑ | 0.844 | 0.719 | 0.606 | 0.534 | 0.908 | 0.823 | 0.670 | 0.583 | |
The paper’s interpretation is straightforward: the baseline MPM accumulates stress and increasingly diverges from the desired pose over time, whereas PIAvatar keeps the user-defined velocity aligned with the motion sequence.
A second quantitative evaluation measures pose-tracking accuracy through the embedded skeleton using Kabsch alignment. The authors report extremely small errors, on the order of floating-point precision, which supports the claim that the skeletal pose remains consistent even under non-rigid physical interactions.
| Metric | Animatable Gaussians | SMPL-X | ||||||
|---|---|---|---|---|---|---|---|---|
| 100 | 200 | 300 | 400 | 100 | 200 | 300 | 400 | |
| Root Rot. ($^\circ$) ↓ | 0.137 | 0.144 | 0.162 | 0.154 | 0.030 | 0.061 | 0.049 | 0.121 |
| Root Trl. (m) ↓ | 0.0006 | 0.0006 | 0.0006 | 0.0007 | 0.0002 | 0.0004 | 0.0003 | 0.0010 |
| Rel. Rot. ($^\circ$) ↓ | 0.632 | 0.616 | 0.663 | 0.642 | 0.097 | 0.205 | 0.202 | 0.320 |
| Rel. Trl. (m) ↓ | 0.0041 | 0.0038 | 0.0044 | 0.0042 | 0.0005 | 0.0011 | 0.0011 | 0.0021 |
| Distance Error (m) ↓ | 0.0057 | 0.0052 | 0.0056 | 0.0056 | 0.0022 | 0.0025 | 0.0034 | 0.0032 |
Runtime is also reported to show that the additional components remain modest. The velocity computation and the Kabsch alignment are run once per frame, and the paper explicitly amortizes them over the number of simulation steps per frame.
| Component | Single SMPL-X | Four SMPL-X | Single AG | Four AG |
|---|---|---|---|---|
| Basic MPM | 0.170 | 0.311 | 2.619 | 11.015 |
| Velocity Computation | 0.149 | 0.542 | 0.976 | 3.661 |
| Grid Initialization | 0.151 | 0.518 | 0.145 | 0.472 |
| P2G | 0.0068 | 0.0153 | 0.0076 | 0.0043 |
| G2P | 0.0068 | 0.0170 | 0.0085 | 0.0748 |
| Kabsch | 0.0085 | 0.0324 | 0.0082 | 0.0319 |
| Total time (ms) | 0.492 | 1.436 | 3.764 | 15.259 |
The supplementary table on the downsampled OSSO skeleton reports that reducing the skeleton particle count by 10× lowers the total runtime to $0.492$ ms, $1.436$ ms, $3.764$ ms, and $15.259$ ms in the single- and four-avatar SMPL-X and AG settings, while preserving similar distance error. The additional memory overhead is reported as about $122$ MB for an extra $200^3$ grid per avatar, which is small relative to the baseline memory usage of about $3.8$ GB for SMPL-X and $5.4$ GB for AG.
8. Qualitative Findings
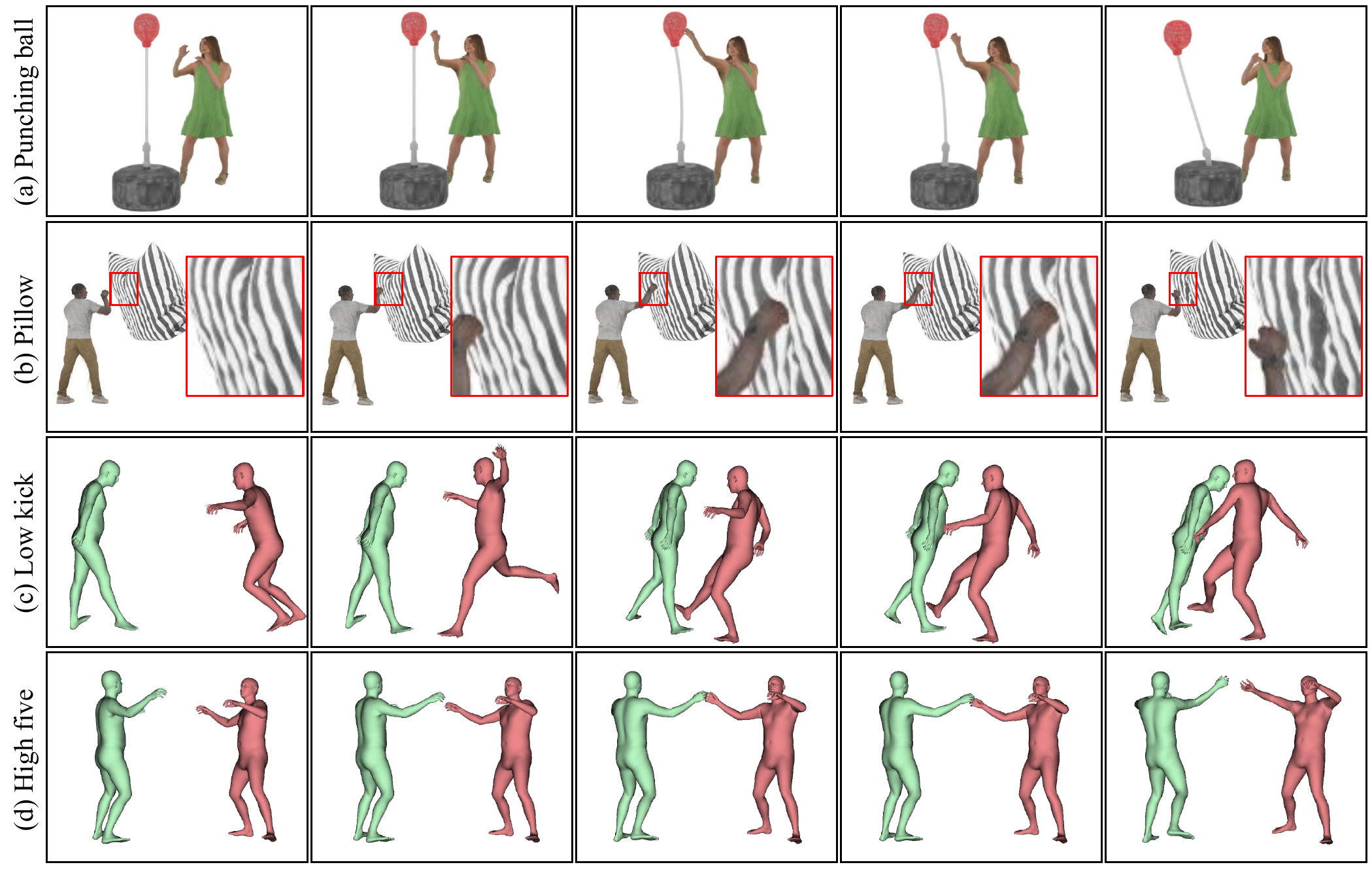
The paper’s qualitative results emphasize that PIAvatar supports both human-object and human-human interactions with bidirectional force transfer. The avatar can push objects away, be pushed in return, and undergo localized non-rigid deformation when impacted.
8.1 Human-object interaction
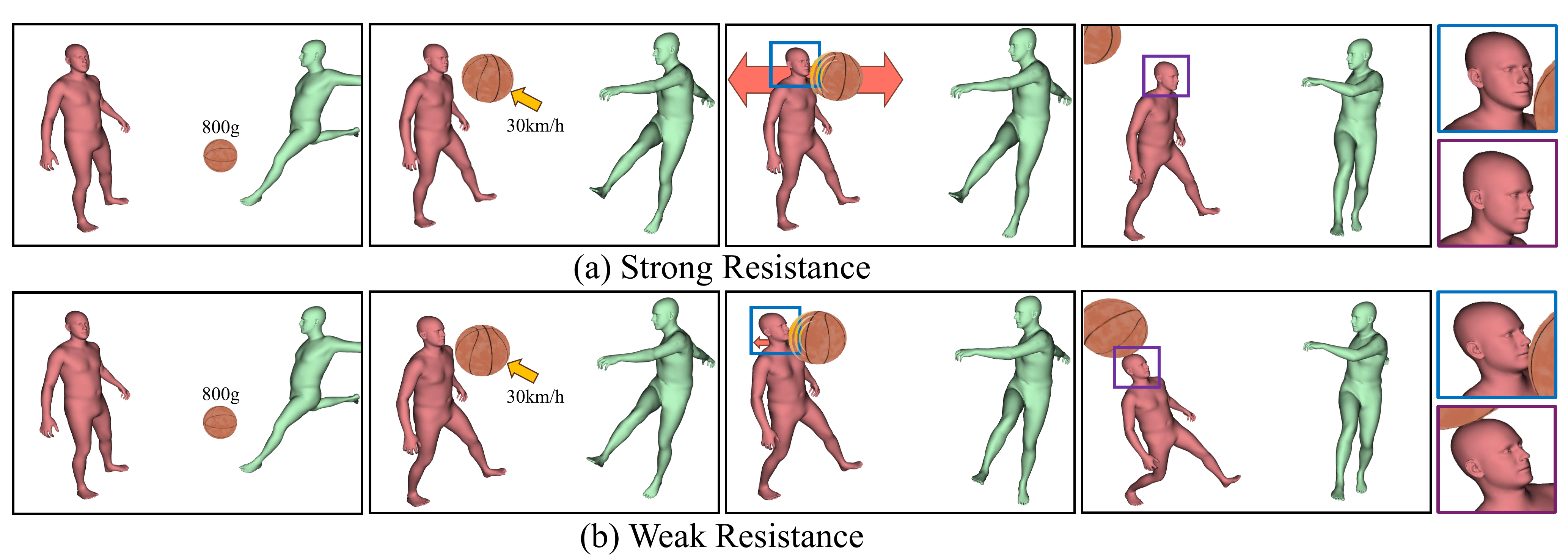
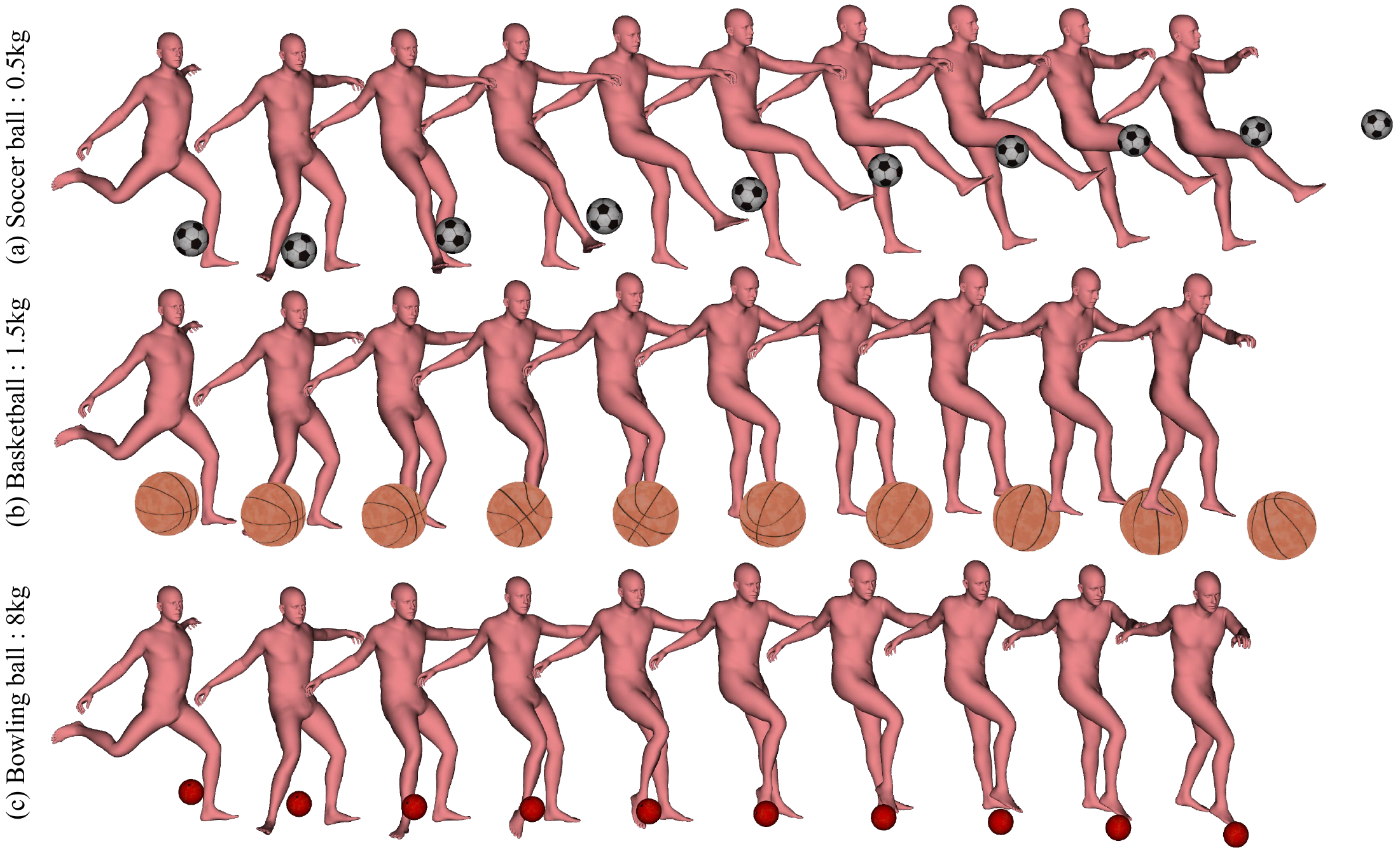
In the reported examples, changing object mass alters both object trajectories and avatar pose response. A heavier object transfers more momentum and induces larger pose deviations. The paper also demonstrates a mass-dependent kicking sequence with a soccer ball, basketball, and bowling ball, showing increasingly strong reaction forces as mass increases.


A notable detail is that the paper does not rely on any dedicated hair or soft-tissue simulator. Instead, secondary effects such as hair fluttering and belly jiggling emerge from particle-based force propagation. In one soft-tissue experiment, the authors slightly attenuate the kinematic velocity in the belly region so that stress develops through neighboring interactions, leading to natural wobbling.
8.2 Human-human interaction
For avatar-avatar contacts, the momentum generated by one avatar is transmitted to the other, changing its pose. The paper shows striking and pushing behaviors, including cases where the struck avatar recoils or is knocked off balance depending on the resistive force induced by the decoupled dynamics.
8.3 Material dependence and heterogeneous avatars
The method is also used to demonstrate material-dependent response. In the heterogeneous-material example, the body, garments, and hair use different constitutive models and stiffness values, leading to different deformation magnitudes under the same motion. This supports the claim that PIAvatar can represent spatially varying material properties without breaking pose consistency.



8.4 Deformation-gradient visualization
The paper visualizes how deformation propagates from the contact point outward through changes in $\mathbf{F}_p$. This is used to illustrate that PIAvatar’s stress response is not merely a pose correction mechanism; it is a continuum-mechanics response that spreads through the simulated body and can be interpreted as the simulator’s way of distributing impact forces.

9. Design Implications and What the Paper Claims as Novel
- The paper claims to be the first to explicitly decouple user-prescribed kinematic motion from deformation-gradient computation inside MPM for articulated human avatars.
- It combines bidirectional interaction, non-rigid deformation, and skeletal pose recovery in a single learning-free framework.
- It preserves contact-driven stress while removing kinematic-induced stress, which is the essential trade-off that enables both pose fidelity and physical interaction.
- It uses closed-form rigid alignment rather than optimization-heavy pose fitting or a learned regressor to recover skeletal motion in real time.
The paper repeatedly contrasts this with prior physically aware avatar work: RL-based methods often rely on rigid or simplified physics representations, while simulation-based avatar methods have typically focused on one-way coupling, cloth-only dynamics, or pose-level responses rather than non-rigid body deformation.
10. Limitations
The authors are explicit about several limitations. Self-penetration can occur in folding regions such as armpits, and raising an arm can lead to mesh tearing in the MPM simulation. Rapid collisions between objects can cause them to stick before stress has time to develop. Creating desired interaction scenarios still requires manual setup of avatar placements and object properties. The pose data used in the paper, such as AMASS, does not provide torque control under external forces like gravity, and friction is not implemented, which makes posture maintenance difficult.
The paper suggests that possible next steps include PID control or reinforcement learning for torque control, and adding friction and richer object properties through larger physics engines such as Genesis. In other words, PIAvatar is presented as a strong physical foundation, but not yet a full scene-understanding or force-control system.
11. Conclusion
PIAvatar is a physically grounded avatar simulation framework that uses MPM to support bidirectional interactions and non-rigid deformation. Its main technical contribution is deformation-gradient decoupling: kinematic motion is kept out of the stress-generating deformation path, while external contacts remain physically meaningful. Combined with embedded skeleton tracking and closed-form pose recovery, this yields avatars that can both follow a desired motion and react plausibly to objects and other avatars.